Preface:
Recently I read a series of MySQL articles. The understanding of Mysql's basic knowledge is consistent with practice. mark it.
Text:
The basic knowledge of MySql is divided into four parts: first, concurrency control (read/write lock); second, transaction; third, multi-version concurrency control (MVCC); fourth, storage engine.
Concurrency control:
Overall, there are only two types of locks:
Shared Lock/Read Lock
Exclusive locks/write locks
We often hear about all kinds of locks: for example, InnoDB has seven types of locks as follows. Both can be classified into two types of shared/exclusive locks.
- Shared and Exclusive Locks
- Intention Locks
- Gap Locks
- Record Locks
- Next-key Locks
- Insert Intention Locks
- Auto-inc Locks
Two, several concurrent examples (where the engine is InnoDB and the isolation level is the default isolation level RR).
Insertion concurrency:
Initialization: Table structure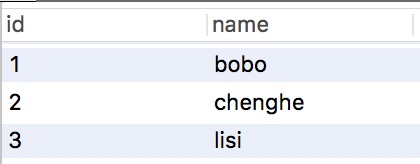
SET NAMES utf8;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for `test`
-- ----------------------------
DROP TABLE IF EXISTS `test`;
CREATE TABLE `test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=latin1;
-- ----------------------------
-- Records of `test`
-- ----------------------------
BEGIN;
INSERT INTO `test` VALUES ('1', 'bobo'), ('2', 'chenghe'), ('3', 'lisi');
COMMIT;
SET FOREIGN_KEY_CHECKS = 1;
Transaction A: insert in test (name) values ('xxx');
set session autocommit=0;
start transaction;
insert into test(name) values('xxx');Transaction B: insert in test (name) values ('ooo');
set session autocommit=0;
start transaction;
insert into test(name) values('ooo');Test Sequence: Transaction A -) Transaction B: Transaction B is not blocked by A under isolation level RR.
What is the actual situation? If the following is executed again, it will be known that:
Transaction C:
set session autocommit=0;
start transaction;
insert into test(name) values('qqq');
commit;
select * from test;The results are as follows: the middle id is 4,5 missing.
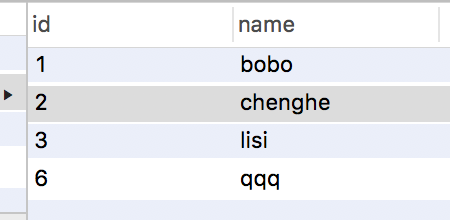
Note: And even if you roll back the data with id 4,5, the location will not be inserted subsequently.
Insertion concurrency (supplement):
Initialization: Table structure

SET NAMES utf8;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for `test`
-- ----------------------------
DROP TABLE IF EXISTS `test`;
CREATE TABLE `test` (
`id` int(11) NOT NULL,
`name` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `un_id` (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
-- ----------------------------
-- Records of `test`
-- ----------------------------
BEGIN;
INSERT INTO `test` VALUES ('10', 'bobo'), ('20', 'chenghe'), ('30', 'lisi');
COMMIT;
SET FOREIGN_KEY_CHECKS = 1;Transaction A: insert in test (id, name) values (11,'xxxxx');
set session autocommit = 0; start TRANSACTION; insert into test(id,name) values (11,'xxxxx');
Transaction B: insert in test (id, name) values (12,'yyyyyy');
set session autocommit = 0; start TRANSACTION; insert into test(id,name) values (12,'yyyyy');
Test Sequence: Transaction A -) Transaction B: Test result: Transaction B is not blocked.
Summary: Examples 1 and 2 show that when concurrent insertion occurs, the line in which the primary key id is locked.
Example 3. Concurrent Reading and Writing
create table `t_2`( `id` int(10) not null, `name` VARCHAR(10) not null default '', `sex` VARCHAR(10) not null default '', PRIMARY key(`id`) )ENGINE = INNODB DEFAULT CHARACTER SET utf8; insert into `t_2` VALUES(1,'bobo','male'),(3,'hebe','female'), (5,'selina','female'),(9,'ella','female'),(10,'robot','male');

Transaction A: Read transaction: select * from t_2 where id BETWEEN 1 and 7 lock in share mode; (manual plus s lock/read lock, follow-up will also talk about read-write lock)
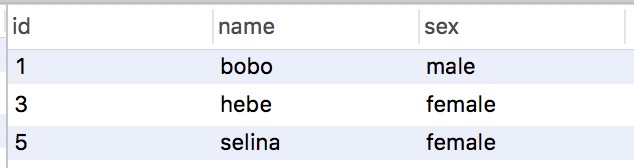
set session autocommit = 0; start TRANSACTION; select * from t_2 where id BETWEEN 1 and 7 lock in share mode;
Transaction B: Write transaction: insert into `t_2 `VALUES (2, `robot', `male');
set session autocommit = 0; start TRANSACTION; insert into `t_2` VALUES(2,'robot','male');
Execution order: Transaction A -) Transaction B: Result transaction B is blocked.
Conjecture 1: The whole table is locked here by transaction A. Causes transaction B to be unenforceable;
Conjecture 2: Transaction A locks the id interval (1-7) here.
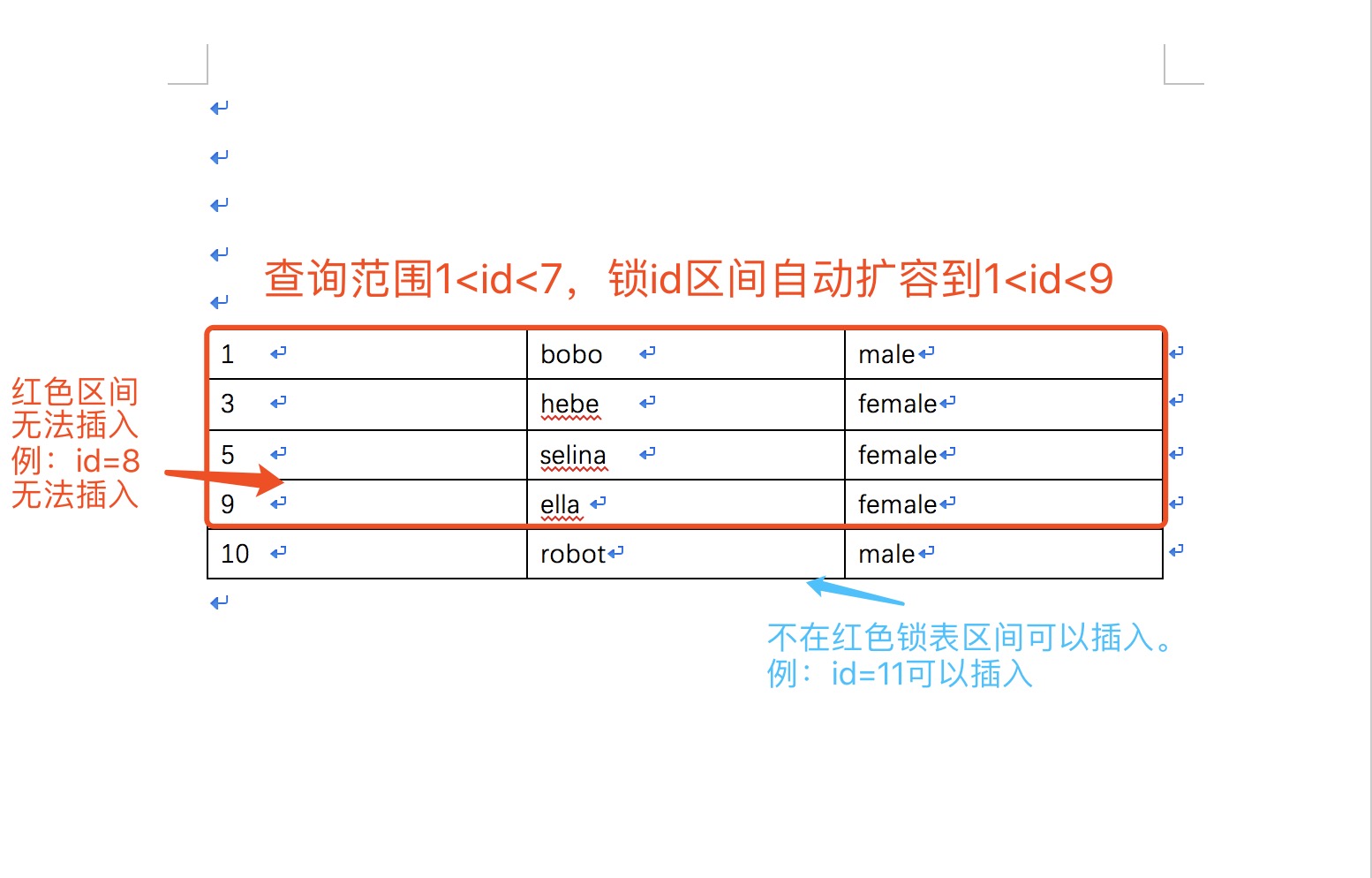
To prove these two conjectures, I did several experiments and found that not only 1-7 was locked, but even ID 8 could not be inserted. However, id=10 can be inserted. In fact, the lock interval of transaction A is not ID (1-7) but Id (1-9), as shown below.
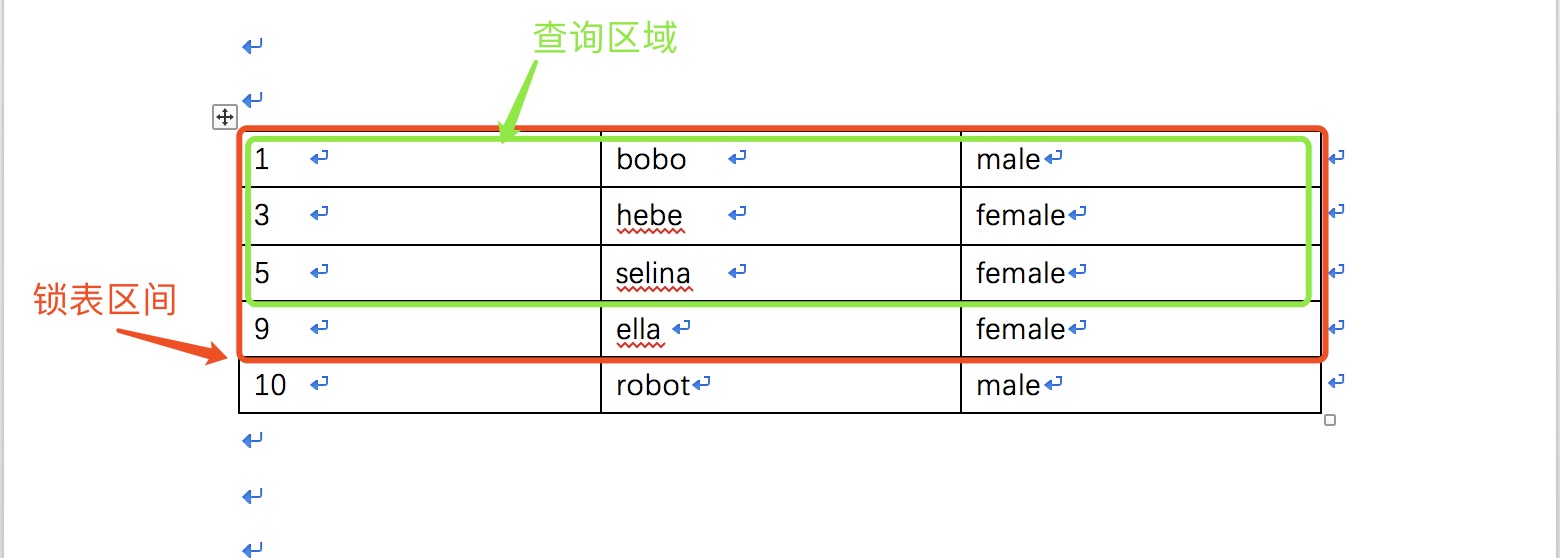
Summary: Lock ID 1-9 interval. The reason is that when transaction A executes, the record id=7 cannot be found in the table. So lock the interval from id=1 to the last record, id=9. That is to say, if my transaction A query range is ID (1, 13), when id=13 cannot be found and 13 is larger than the maximum id, it will lock 1 to positive infinity. And vice versa. Draw a picture for easy understanding.
Example 4. Concurrent Reading and Writing (continued)
Table structure: Table or example 3 table.

Transaction A: select * from t_2 where id=14 lock in share mode; add S lock to query a non-existent data.
set session autocommit = 0; start TRANSACTION; select * from t_2 where id=14 lock in share mode;
Transaction B: insert into `t_2 `VALUES (11,'robot','male'); insert a data id=11.
set session autocommit = 0; start TRANSACTION; insert into `t_2` VALUES(11,'robot','male');
Execution order: Transaction A -) Transaction B: Transaction B is blocked.
Conclusion: in the third case, the interval of 10 < ID is locked.
Plus: I don't know if there are any small partners who found that I manually add S lock/read lock to the query of Example 3 and Example 4. What if we don't add S locks? In innodb engines, unlocked snapshots are read because of multiversion concurrency control (MVCC). After that, I will elaborate on snapshot reading. Now I just need to understand that the result of the query is a snapshot of the query database at the query time point. It is not the original data and will not block the writing operation.
3. Several examples of dirty reading/unrepeatable reading/hallucination/lock reading are used to analyze the four isolation levels RU/RC/RR/S of transactions.
Attached here is the code for modifying transaction isolation levels and problem relationships:
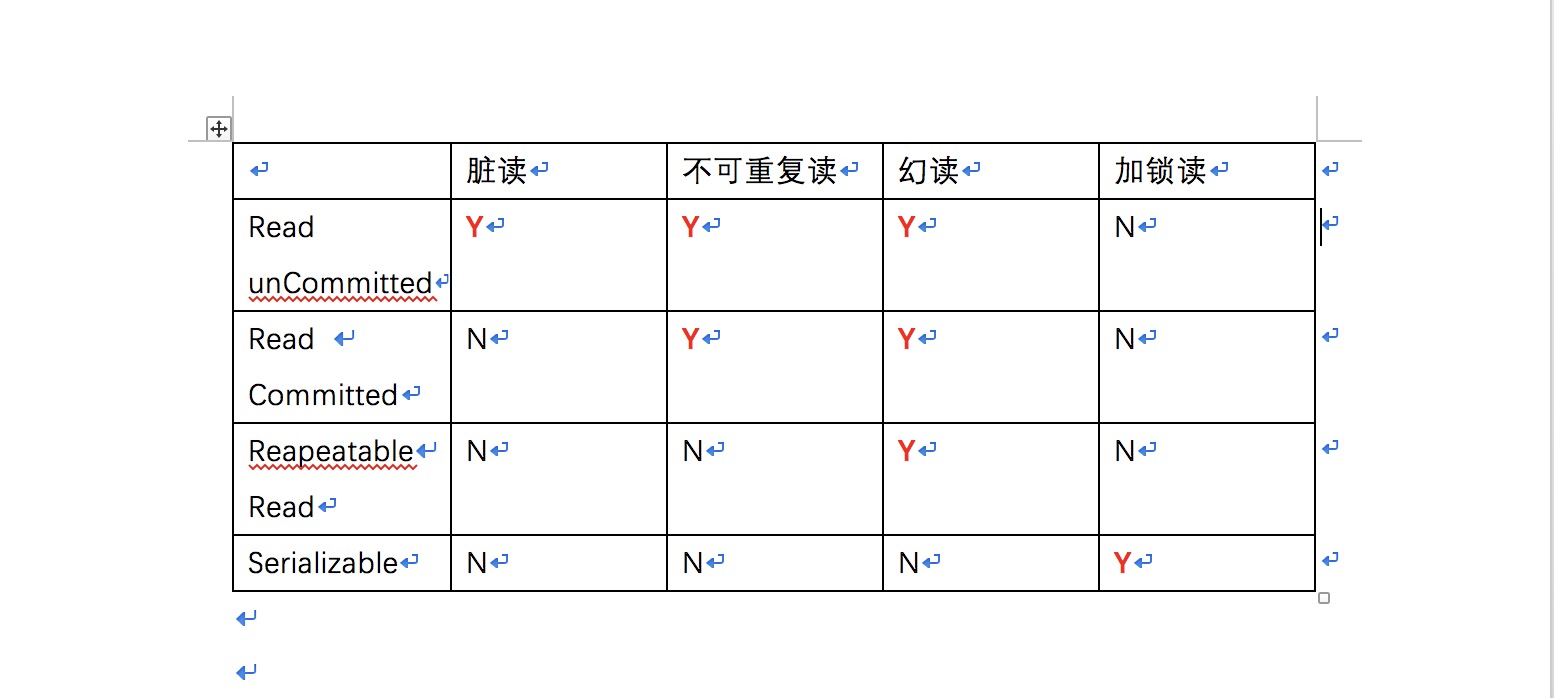
000,Query isolation level: Modify isolation level: select @@global.tx_isolation,@@tx_isolation; set global transaction isolation level read committed; set session transaction isolation level read committed; set global transaction isolation level repeatable read; set session transaction isolation level repeatable read;
Dirty reading: Transactions can read uncommitted data.
The isolation level is READ UNCOMMITTED. For instance:
The third example of table structure is as follows:
Transaction A: Insert uncommitted.
set global transaction isolation level read UNCOMMITTED; set session transaction isolation level read UNCOMMITTED; select @@global.tx_isolation,@@tx_isolation; set session autocommit = 0; start TRANSACTION; insert into `t_2` VALUES(11,'robot','male');
Transaction B: Query ID > 10.
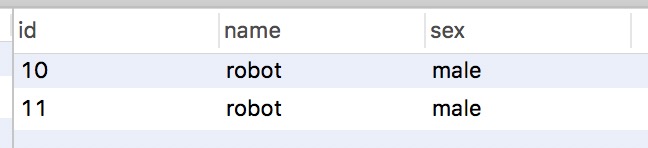
set global transaction isolation level read UNCOMMITTED; set session transaction isolation level read UNCOMMITTED; select @@global.tx_isolation,@@tx_isolation; set session autocommit = 0; start TRANSACTION; select * from t_2 where id>9;
Execution order: Transaction A -) Transaction B: Transaction B can be found as follows: produce dirty reading.
This is rarely the case in practice, after all, the use of read uncommitted isolation level has never been seen in earnest.
Unrepeatable: Because two executions of the same query may yield different results.
Isolation level below or equal to READ COMMITTED will occur. The hard part about this concept is that you assume by default that as long as commit has been submitted, it should be visible to other transactions. In fact, this will result in the same transaction, and two queries will produce different results. For better understanding, because RR isolation level can avoid this situation, so I made a comparison.
For instance:
Transaction RR isolation level:
set global transaction isolation level REPEATABLE read ; set session transaction isolation level REPEATABLE read; select @@global.tx_isolation,@@tx_isolation;
Transaction A: Two query statements;
set session autocommit = 0; start TRANSACTION; select * from t_2 where id>9; --There is a delay in the middle.--- select * from t_2 where id>9;
Transaction B: Insert and submit.
set session autocommit = 0; start TRANSACTION; insert into `t_2` VALUES(11,'robot','male'); commit;
Execution order: Transaction A executes the third line query, transaction B executes, and transaction A executes the fifth line query. View the results twice. No result of id=11 was seen. For the same transaction, there is no modification in the two queries, and the query results are the same. Perfect!
Change isolation level to transaction RC isolation level:
set global transaction isolation level read COMMITTED; set session transaction isolation level read COMMITTED; select @@global.tx_isolation,@@tx_isolation;
Execution order: Transaction A executes the third line query, transaction B executes, and transaction A executes the fifth line query. (Ibid.) View the results twice. The first time you can't see it, the second time you can see the result of id=11. In the same transaction, there is no modification in the two queries, and the query results are different. No repetition.
PS: Actually, it depends on the requirement to see the submitted results in the same transaction.
Hallucination: When transaction A reads a range record, transaction B inserts a new record in that range. When transaction A reads the same range record again, hallucination will occur.
Isolation level below or equal to REPEATABLE READ will occur. (i.e., basically unavoidable unless the last isolation level is used)
In fact, in the first instance, we have seen the illusion reading. I just didn't care at that time. Take it out here and talk about it separately.
Initialization: Table structure (id self-increasing)
SET NAMES utf8;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for `test`
-- ----------------------------
DROP TABLE IF EXISTS `t_3`;
CREATE TABLE `t_3` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=latin1;
-- ----------------------------
-- Records of `test`
-- ----------------------------
BEGIN;
INSERT INTO `t_3` VALUES ('1', 'bobo'), ('2', 'chenghe'), ('3', 'lisi');
COMMIT;
SET FOREIGN_KEY_CHECKS = 1;Because this feature is not readable repeatedly, it has been processed at the rc level. However, after insertion. Something very strange will happen.
Transaction A:
set global transaction isolation level REPEATABLE read ;
set session transaction isolation level REPEATABLE read;
select @@global.tx_isolation,@@tx_isolation;
set session autocommit = 0;
start TRANSACTION;
select * from t_3;
insert into t_3(name) values('simayi');
--Delay in the middle: insertion of other transactions---
insert into t_3(name) values('zhugeliang');
select * from t_3;
commit;Transaction B:
set global transaction isolation level REPEATABLE read ;
set session transaction isolation level REPEATABLE read;
select @@global.tx_isolation,@@tx_isolation;
set session autocommit = 0;
start TRANSACTION;
select * from t_3;
insert into t_3(name) values('caocao');Execution order: Transaction B delays between two inserts of transaction A.
The query results show that there are two consecutive inserts of the same transaction, and there are empty rows in the middle. What about id=5? Was it eaten by transaction B? Although transaction B did not even commit, it ate the ID. Illusions occur.
Locked Read: Each row of records read is locked.
Locked reading can solve all the problems ahead: dirty reading/non-repeatable reading/hallucination. But it's a problem in itself. Every transaction is locked. That's bound to be a performance bottleneck in concurrency. So it's a trade-off between needs and needs.
set global transaction isolation level SERIALIZABLE; set session transaction isolation level SERIALIZABLE; select @@global.tx_isolation,@@tx_isolation;
IV. Multi-Version Concurrency Control (MVCC):
In the book, MVCC defines snapshot reading as looking up only rows earlier than the current transaction version.
I've been talking about snapshot reading. What's the matter with snapshot reading? Snapshot reading works only at RR/RC isolation level. Moreover, when read and write concurrently before, read and write concurrently are not snapshot reading, which shows that snapshot reading is a non-blocking reading. For instance.
Initialization: Table structure
Example 1. In the same transaction:
Transaction A-1:
select @@global.tx_isolation,@@tx_isolation; set session autocommit = 0; start TRANSACTION; select * from t_3;
View the current transaction id/transaction version number by following code: transaction A-1 completed, transaction id=15800
SELECT * FROM INFORMATION_SCHEMA.INNODB_TRX;
Transaction A-2:
-----Transaction A-1
insert into t_3(name) values('simayi');
select * from t_3;Look at the current transaction id / transaction version number from the above code: After transaction A-2 is executed, the transaction id is still = 15800
Execution order: Transaction A-1 - > Transaction A-2. Implementation results. Transaction A-1: Query results and table structure are the same. Transaction A-2: The query result inserts one more piece of data.
Conclusion: The transaction version number of different statements in the same transaction is unique.
Example 2. Within different transactions (default isolation level RR):
Transaction A:
select @@global.tx_isolation,@@tx_isolation; set session autocommit = 0; start TRANSACTION; select * from t_3; ----Delay transaction B Execute here----- select * from t_3;
View the current transaction id/transaction version number by code: Execute transaction A, transaction id=15805;
Transaction B:
select @@global.tx_isolation,@@tx_isolation;
set session autocommit = 0;
start TRANSACTION;
select * from t_3;
insert into t_3(name) values('simayi');
select * from t_3;View the current transaction id/transaction version number by code: execute transaction B, transaction id=15806 when uncommitted;
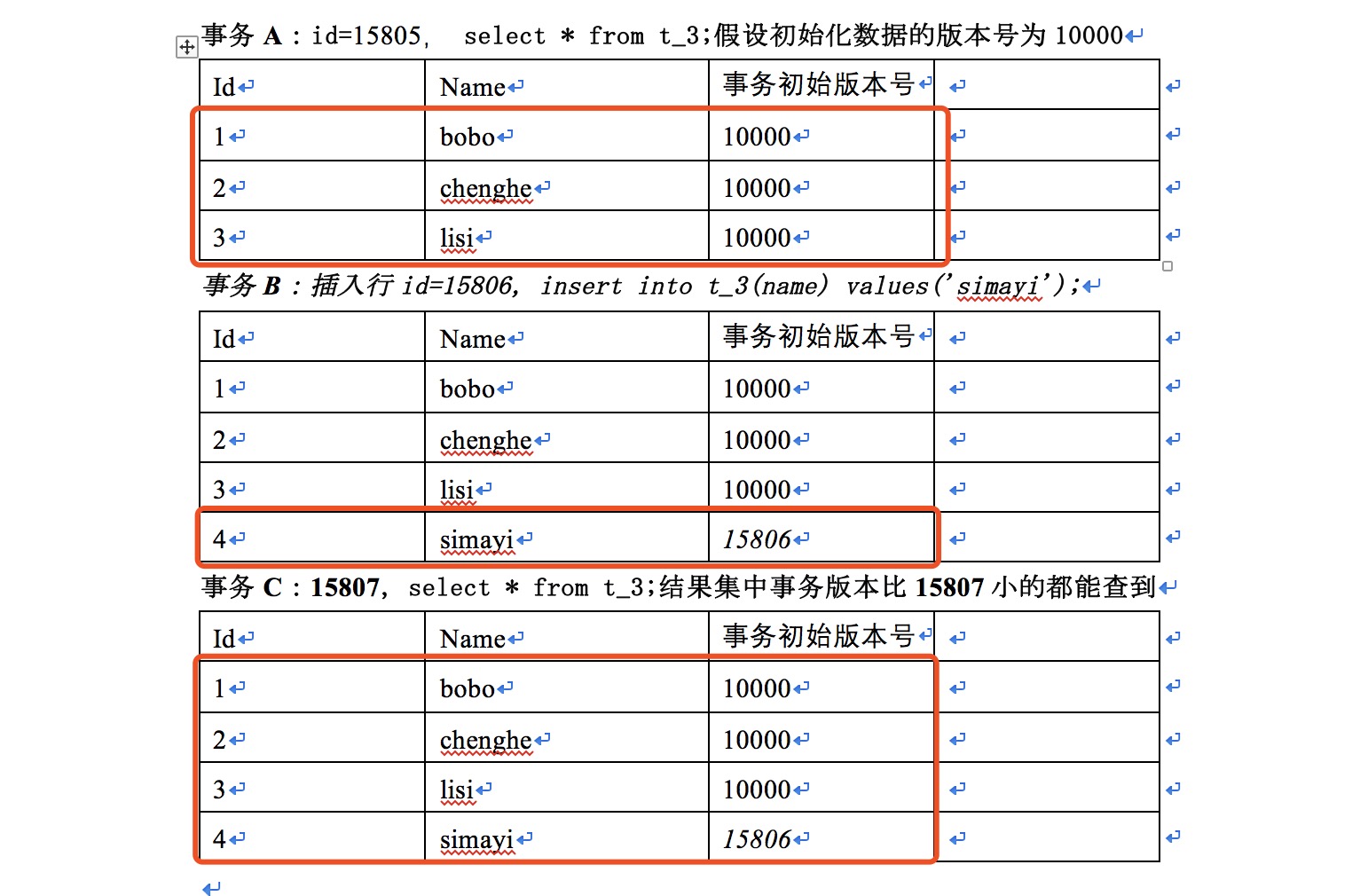
Execution order: Transaction A -"Transaction B (+commit) -" Transaction A, found that transaction A always transaction id=15805, so no data larger than transaction ID 15805 will be found.
Transaction C:
select @@global.tx_isolation,@@tx_isolation; set session autocommit = 0; start TRANSACTION; select * from t_3;
Execution order: Re-execute transaction C: Transaction C transaction ID is 15807. You can see the result of transaction B's commit.
Draw a picture. The dry code looks puzzling.
PS: If the isolation level is RC: then the two query results of transaction A will be different. The second query will query the newly inserted data. Because the RR level always reads the transaction snapshot at the start of the transaction (15805). The RC level always reads the latest snapshot of the current data row (15807).
Here is another point of knowledge: UNDO, REDO logs. Slightly.
5. Storage Engine:
The storage engine is not going to talk about it. Probably the routine of the interview questions. Two InnoDB and MysAm engines are commonly used. The differences, advantages, disadvantages and application scenarios between the two storage engines. By default InnoDB is enough. Slightly.
6. Aggregated Index:
First of all, I don't want to talk about the difference and connection between clustered index and ordinary index. I want to talk about the difference between index and no index. Although we usually read and write MVCC snapshots, resulting in reading and writing will not block each other. But if we use S-lock reading. Examples are as follows:
Initialization: Data table: id is primary key, name is common field, not indexed. (RR isolation level)
Transaction A: S locks query a non-existent data.
select @@global.tx_isolation,@@tx_isolation; set session autocommit = 0; start TRANSACTION; select * from t_3 where name = 'zhugeliang' lock in share mode;
Transaction B: Any operation that reads or writes to a known index cannot be performed. For example, adding a row requires adding an index. To delete a row, you need to delete the index. Updating a row requires locking the current index row.
select @@global.tx_isolation,@@tx_isolation;
set session autocommit = 0;
start TRANSACTION;
insert into t_3(name) values('caocao');CONCLUSION: When s locks a non-existent record, when the condition field is not indexed, the known whole table index will be requested. All write operations (additions, deletions and modifications) will be blocked.
Solution: Add a common index to the name field. In this way, when the index of name='non-existent record'is not found, the corresponding aggregate index will not be requested.
Conversely, the use of clustered index is introduced. When the query condition is a common index, the corresponding aggregate index will be searched according to the common index, and then the value value will be searched through the aggregate index. If name is a normal index, id is a clustered index. The query condition is select * from t_3 where name = bobobo';
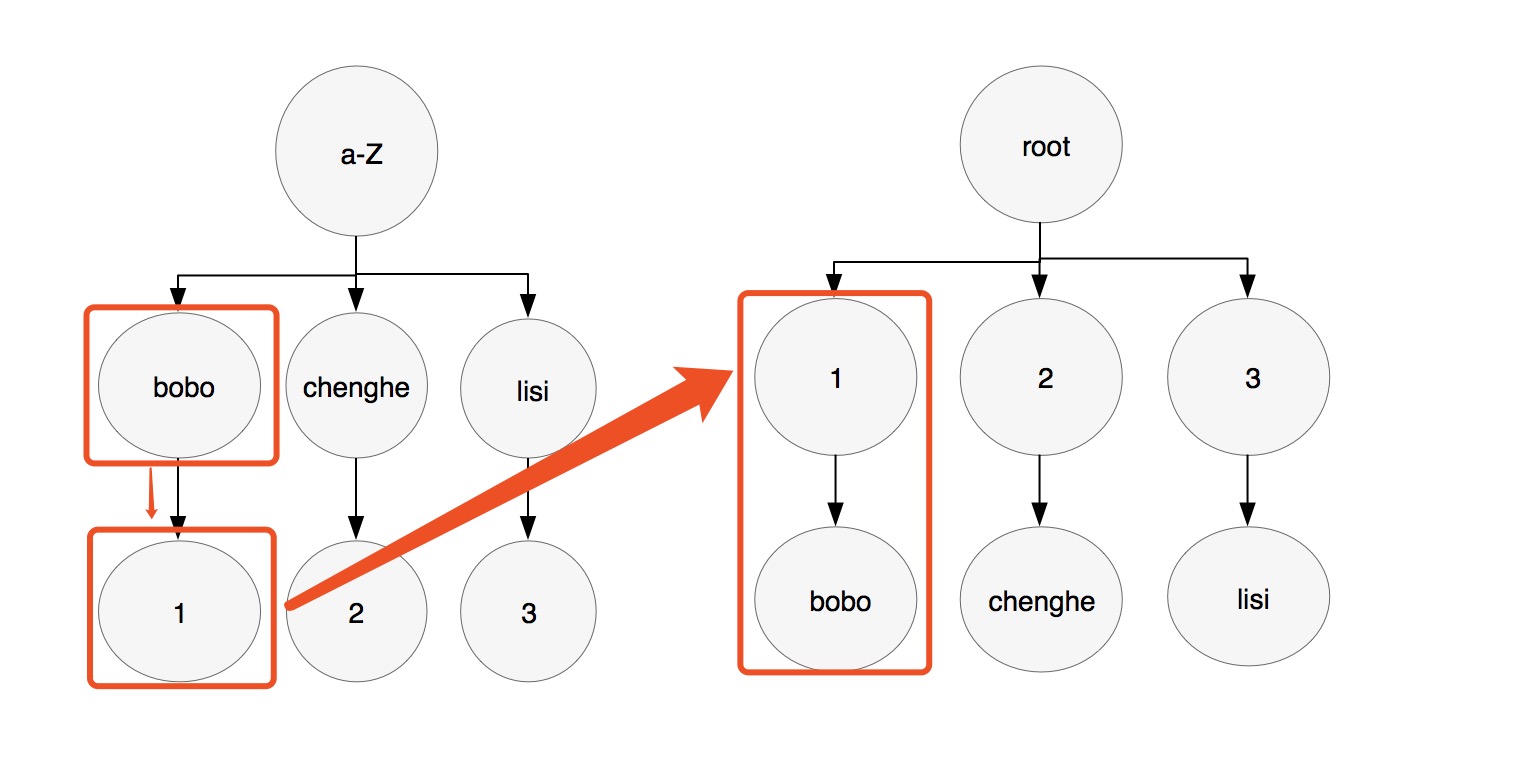
As above, the left figure shows that the general index bobo bo finds the aggregate index id=1, and then finds the other information of this data on the aggregate index by the aggregate index id=1.
Write a little tired, there are problems. ~ over