Google Bert model
Environment and installation
Environmental requirements
Google Bert model download address: https://github.com/google-research/bert
Environmental requirements: TensorFlow 1.11.0, python 2 and or Python 3 (TensorFlow 1.12.0, python 3.6 are actually operable)
Project deployment
First, download the relevant files on github, including: compressed package of bert program, pre training model (download the corresponding pre training model according to the actual demand, this paper uses the model: uncased_L-12_H-768_A-12), relevant data set (download the data set of the corresponding task according to the actual demand, this paper takes MRPC task, that is, judge whether two sentences express one meaning? As an explanation example) .
Download all the required data and place it in the corresponding project folder. The project folder directory constructed in this paper is as follows:
--BERT --bert-master --GLUE --BERT_BASE_DIR --uncased_L-12_H-768_A-12 --glue_data --MRPC --output
Project operation
After the project deployment is completed, we start running run_ The running parameters of classifier.py program are set as follows:
python run_classifier.py/ --task_name=MRPC --do_train=true --do_eval=true --data_dir=../GLUE/glue_data/MRPC --vocab_file=../GLUE/BERT_BASE_DIR/uncased_L-12_H-768_A-12/vocab.txt --bert_config_file=../GLUE/BERT_BASE_DIR/uncased_L-12_H-768_A-12/bert_config.json --init_checkpoint=../GLUE/BERT_BASE_DIR/uncased_L-12_H-768_A-12/bert_model.ckpt --max_seq_length=128 --train_batch_size=32 --learning_rate=2e-5 --num_train_epochs=3.0 --output_dir=../GLUE/output
After the program runs, we can see: eval_accuracy,eval_loss,global_step, loss and other related information.
Next, we will formally explain the core program of the model.
Core program explanation
data processing module
First, read the train.tsv file required for training and access the train_ In the examples parameter
//main()
train_examples = processor.get_train_examples(FLAGS.data_dir)
//get_train_examples()
def get_train_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "train.tsv")), "train")
//_create_examples()
def _create_examples(self, lines, set_type):
"""Creates examples for the training and dev sets."""
examples = []
for (i, line) in enumerate(lines):
if i == 0:
continue
guid = "%s-%s" % (set_type, i)
text_a = tokenization.convert_to_unicode(line[3]) //Read in the first sentence, tokenization.convert_to_unicode converts text into utf-8 encoding;
//Eg:text_a:'Amrozi accused his brother, whom he called "the witness", of deliberately distorting his evidence.'
text_b = tokenization.convert_to_unicode(line[4]) //Read in the second sentence
//Eg:text_b:'Referring to him as only "the witness", Amrozi accused his brother of deliberately distorting his evidence.'
if set_type == "test":
label = "0" //If it is a model prediction, the corresponding label is marked "0"
else:
label = tokenization.convert_to_unicode(line[0]) //If it is model training, read the label corresponding to the example
examples.append(
InputExample(guid=guid, text_a=text_a, text_b=text_b, label=label)) //Convert the read data into bert model input format and store it in the examples list
//Eg:example:(guid:'train1',text_a,text_b,label=1)
return examples
After obtaining the training data, calculate the total number of iterations required for the training
//train_batch_size = 32
//num_train_epochs = 3.0
num_train_steps = int(
len(train_examples) / FLAGS.train_batch_size * FLAGS.num_train_epochs)
num_warmup_steps = int(num_train_steps * FLAGS.warmup_proportion)
Preprocess the read in original data (focus)
//Data preprocessing module in main() function
file_based_convert_examples_to_features(
train_examples, label_list, FLAGS.max_seq_length, tokenizer, train_file)
In file_ based_ convert_ examples_ to_ In the features () function, preprocess the read data in turn, and save the processed word vector information as defined InputFeatures type data
//file_based_convert_examples_to_features()
for (ex_index, example) in enumerate(examples):
if ex_index % 10000 == 0:
tf.logging.info("Writing example %d of %d" % (ex_index, len(examples)))
feature = convert_single_example(ex_index, example, label_list,
max_seq_length, tokenizer)
Via convert_ single_ The example () function divides the input data into words, maps it into word vectors, and adds relevant information
def convert_single_example(ex_index, example, label_list, max_seq_length,
tokenizer):
"""Converts a single `InputExample` into a single `InputFeatures`."""
if isinstance(example, PaddingInputExample):
return InputFeatures(
input_ids=[0] * max_seq_length,
input_mask=[0] * max_seq_length,
segment_ids=[0] * max_seq_length,
label_id=0,
is_real_example=False)
label_map = {}
for (i, label) in enumerate(label_list):
label_map[label] = i //Mapping labels to numeric values; Eg:label_map:{'0':0,'1':1}
tokens_a = tokenizer.tokenize(example.text_a) //Right text_a participle
//Eg:tokens_a: ['am', '##ro', '##zi', 'accused', 'his', 'brother', ',', 'whom', 'he', 'called', '"', 'the', 'witness', '"', ',', 'of', 'deliberately', 'di', '##stor', '##ting', 'his', 'evidence', '.']
tokens_b = None
if example.text_b:
tokens_b = tokenizer.tokenize(example.text_b) //If there is a second sentence, text_b participle
//Eg: ['referring', 'to', 'him', 'as', 'only', '"', 'the', 'witness', '"', ',', 'am', '##ro', '##zi', 'accused', 'his', 'brother', 'of', 'deliberately', 'di', '##stor', '##ting', 'his', 'evidence', '.']
if tokens_b:
//If tokens_ B exists. Modify "tokens_a" and "tokens_b" to make the total length less than the specified length. Due to the labels of [CLS], [SEP], [SEP], the maximum limit is: max_seq_length-3
_truncate_seq_pair(tokens_a, tokens_b, max_seq_length - 3)
else:
//On the contrary, the maximum is: max_seq_length-2
if len(tokens_a) > max_seq_length - 2:
tokens_a = tokens_a[0:(max_seq_length - 2)]
tokens = [] //[CLS] tokens_a [SEP] tokens_b
segment_ids = [] //Mark whether it is the first sentence or the second sentence, 0: the first sentence; 1: Second sentence
tokens.append("[CLS]") //Add beginning tag [CLS]
segment_ids.append(0) //Add label 0 for [CLS]
for token in tokens_a:
tokens.append(token) //Set tokens_a add to tokens
segment_ids.append(0) //Add tag 0, and the identification is the first sentence
tokens.append("[SEP]") //Add a connector [SEP] between two sentences
segment_ids.append(0) //Add label 0 for [SEP]
if tokens_b:
for token in tokens_b:
tokens.append(token) //Set tokens_b add to tokens
segment_ids.append(1) //Add tag 1. The identification is the second sentence
tokens.append("[SEP]") //Add tag [SEP] after sentence
segment_ids.append(1) //Label [SEP] 1
//Eg: tokens: ['[CLS]', 'am', '##ro', '##zi', 'accused', 'his', 'brother', ',', 'whom', 'he', 'called', '"', 'the', 'witness', '"', ',', 'of', 'deliberately', 'di', '##stor', '##ting', 'his', 'evidence', '.', '[SEP]', 'referring', 'to', 'him', 'as', 'only', '"', 'the', 'witness', '"', ',', 'am', '##ro', '##zi', 'accused', 'his', 'brother', 'of', 'deliberately', 'di', '##stor', '##ting', 'his', 'evidence', '.', '[SEP]']
//Eg: segment_ids: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
input_ids = tokenizer.convert_tokens_to_ids(tokens) //Apply the word in tokens to the id corresponding to the range
//Eg: input_ids: [101, 2572, 3217, 5831, 5496, 2010, 2567, 1010, 3183, 2002, 2170, 1000, 1996, 7409, 1000, 1010, 1997, 9969, 4487, 23809, 3436, 2010, 3350, 1012, 102, 7727, 2000, 2032, 2004, 2069, 1000, 1996, 7409, 1000, 1010, 2572, 3217, 5831, 5496, 2010, 2567, 1997, 9969, 4487, 23809, 3436, 2010, 3350, 1012, 102]
//Add mask coding. A mask of 1 indicates that the word vector has practical meaning, and a mask of 0 indicates that the word vector does not have practical meaning, which is a meaningless 0 for unified length supplement
input_mask = [1] * len(input_ids) //Add 1 of the actual length of the input sequence to the mask list
//Add 0 to complete sequence length
while len(input_ids) < max_seq_length: //Specify the length of the sequence. If the length is not enough, supplement 0
input_ids.append(0)
input_mask.append(0)
segment_ids.append(0)
//Eg: input_ids: [101, 2572, 3217, 5831, 5496, 2010, 2567, 1010, 3183, 2002, 2170, 1000, 1996, 7409, 1000, 1010, 1997, 9969, 4487, 23809, 3436, 2010, 3350, 1012, 102, 7727, 2000, 2032, 2004, 2069, 1000, 1996, 7409, 1000, 1010, 2572, 3217, 5831, 5496, 2010, 2567, 1997, 9969, 4487, 23809, 3436, 2010, 3350, 1012, 102, 0, 0 ...]
//Eg: input_mask: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0 ...]
//Eg: segment_ids: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0 ...]
//Judge input_ids,input_mask,segment_ Are IDS equal to the maximum sequence length
assert len(input_ids) == max_seq_length
assert len(input_mask) == max_seq_length
assert len(segment_ids) == max_seq_length
//Get the value corresponding to the label
label_id = label_map[example.label]
//Eg: label_id: 1
//Printout related information
if ex_index < 5:
tf.logging.info("*** Example ***")
tf.logging.info("guid: %s" % (example.guid))
tf.logging.info("tokens: %s" % " ".join(
[tokenization.printable_text(x) for x in tokens]))
tf.logging.info("input_ids: %s" % " ".join([str(x) for x in input_ids]))
tf.logging.info("input_mask: %s" % " ".join([str(x) for x in input_mask]))
tf.logging.info("segment_ids: %s" % " ".join([str(x) for x in segment_ids]))
tf.logging.info("label: %s (id = %d)" % (example.label, label_id))
//Stores all feature vectors into an instance object feature of the InputFeatures class
feature = InputFeatures(
input_ids=input_ids,
input_mask=input_mask,
segment_ids=segment_ids,
label_id=label_id,
is_real_example=True)
return feature
It should be noted that in convert_ single_ Several special lists and characters in the example() function:
- input_ids: store the word vector sequence after word segmentation, mapping, adding special characters [CLS] and [SEP] (Format: [CLS, text_a, Sep, text_b, Sep]) of the input sequence
- input_mask: the tag that stores whether the corresponding word vector of the tag has actual meaning. 0 or 1, 0 means no actual meaning, and 1 means actual meaning (Format: [1,1..., 0...])
- segment_ids: store the tag that marks which sentence the corresponding word vector belongs to. 0 or 1, 0 means it belongs to the first sentence, and 1 means it belongs to the second sentence (Format: [0,0,..., 1...])
- label_id: store the value corresponding to the tag, store the read actual tag during training, and store tag 0 during prediction (Format: 0 or 1)
- [CLS]: identify the beginning of a task sentence and add it at the beginning of the input sequence
- [SEP]: sentence separator, added between two sentences and at the end of the sentence
model building
Input the preprocessed data into the training model
model = modeling.BertModel(
config=bert_config,
is_training=is_training,
input_ids=input_ids, //Word vector sequence dimension (batch_size, the maximum length of each sentence); Eg: (8,128)
input_mask=input_mask, //Word vector sequence dimension (batch_size, the maximum length of each sentence); Eg: (8,128)
token_type_ids=segment_ids, //Word vector sequence dimension (batch_size, the maximum length of each sentence); Eg: (8,128)
use_one_hot_embeddings=use_one_hot_embeddings)
//modeling/BertModel()
config = copy.deepcopy(config)
if not is_training:
config.hidden_dropout_prob = 0.0
config.attention_probs_dropout_prob = 0.0
input_shape = get_shape_list(input_ids, expected_rank=2)
batch_size = input_shape[0] //Read batch_size value; Eg: 8
seq_length = input_shape[1] //Read the maximum sequence length; Eg: 128
if input_mask is None: //If there is no mask code, the default mask code is 1
input_mask = tf.ones(shape=[batch_size, seq_length], dtype=tf.int32)
if token_type_ids is None: //If there is no sentence classification coding, there is only one sentence by default
token_type_ids = tf.zeros(shape=[batch_size, seq_length], dtype=tf.int32)
Embeddings floor
The BERT model maps the input sequence into the word vector sequence defining the dimension through the Embeddings layer, and adds type_id, location code and other information.
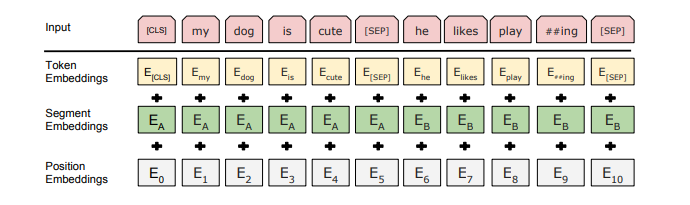
The program implementation of Embeddings layer is as follows:
with tf.variable_scope(scope, default_name="bert"): //Build bert model
with tf.variable_scope("embeddings"): //Building the embedding layer
# Perform embedding lookup on the word ids.
(self.embedding_output, self.embedding_table) = embedding_lookup(
input_ids=input_ids, //Input sequence vector
vocab_size=config.vocab_size, //Pre training model corpus
embedding_size=config.hidden_size, //Specifies the dimension that maps words to word vectors
initializer_range=config.initializer_range, //Initialization value range
word_embedding_name="word_embeddings",
use_one_hot_embeddings=use_one_hot_embeddings)
//Add location code and other information
self.embedding_output = embedding_postprocessor(
input_tensor=self.embedding_output, //In the previous step, embedding output word vector sequence (batch_size, seq_length, embedding_size)
use_token_type=True, //Use type_ids identifies which sentence
token_type_ids=token_type_ids, //Enter type_ids
token_type_vocab_size=config.type_vocab_size,
token_type_embedding_name="token_type_embeddings",
use_position_embeddings=True, //Add location information
position_embedding_name="position_embeddings",
initializer_range=config.initializer_range,
max_position_embeddings=config.max_position_embeddings, //Define the maximum length of location information
dropout_prob=config.hidden_dropout_prob)
First, explain embedding in the Embeddings layer_ The lookup () function converts a word into a word vector
Input values: (batch_size, seq_length), for example (8128), that is, there are 8 samples, and one sample has 128 words
Output values: (batch_size, seq_length, embedding_size), for example (8128768), that is, there are 8 samples, one sample has 128 words, and one word is mapped into a 768 dimensional vector
def embedding_lookup(input_ids,
vocab_size,
embedding_size=128,
initializer_range=0.02,
word_embedding_name="word_embeddings",
use_one_hot_embeddings=False):
//return shape [batch_size, seq_length, embedding_size];Eg: [8,128,768]
if input_ids.shape.ndims == 2: //The input is 2D and the output is 3D. Add a 1D vector to facilitate subsequent processing
input_ids = tf.expand_dims(input_ids, axis=[-1])
//Get corpus table
embedding_table = tf.get_variable(
name=word_embedding_name,
shape=[vocab_size, embedding_size], //[corpus table size, mapping word vector dimension]
initializer=create_initializer(initializer_range))
flat_input_ids = tf.reshape(input_ids, [-1]) //Calculate the total number of words to be queried in the corpus table; batch_size * maximum sequence length; Eg: 8*128=1024
if use_one_hot_embeddings:
one_hot_input_ids = tf.one_hot(flat_input_ids, depth=vocab_size)
output = tf.matmul(one_hot_input_ids, embedding_table)
else:
output = tf.gather(embedding_table, flat_input_ids) //Query the word vector of the corresponding word and return (flat_input_ids, which defines the dimension of the word vector); Eg: (1024768) that is, there are 1024 words in total, and the dimension of a word is 768
input_shape = get_shape_list(input_ids)
output = tf.reshape(output,
input_shape[0:-1] + [input_shape[-1] * embedding_size]) //Build the returned result (batch_size, total number of words, word vector dimension of word mapping); Eg: (8128768) that is, there are 8 samples. There are 128 words in one sample, and each word is mapped into a 768 dimensional vector
return (output, embedding_table)
The second is embedding in the Embeddings layer_ The postprocessor () function adds type to the input sequence_ IDS and location code information. The input value and output value are the same. They are (batch_size, seq_length, embedding_size)
def embedding_postprocessor(input_tensor,
use_token_type=False,
token_type_ids=None,
token_type_vocab_size=16,
token_type_embedding_name="token_type_embeddings",
use_position_embeddings=True,
position_embedding_name="position_embeddings",
initializer_range=0.02,
max_position_embeddings=512,
dropout_prob=0.1):
input_shape = get_shape_list(input_tensor, expected_rank=3) //Input the word vector sequence constructed by the embedding of the previous layer; Eg: (8,128,768)
batch_size = input_shape[0] //batch_size;Eg: 8
seq_length = input_shape[1] //The number of word vectors in a sample; Eg: 128
width = input_shape[2] //The dimension of a word vector; Eg: 768
output = input_tensor //Initialization output; Eg: (8,128,768)
if use_token_type:
if token_type_ids is None: //Judgment type_ Whether IDS exists. If it exists, it will be converted into the corresponding word vector
raise ValueError("`token_type_ids` must be specified if"
"`use_token_type`
//Get corpus table
token_type_table = tf.get_variable(
name=token_type_embedding_name,
shape=[token_type_vocab_size, width],
initializer=create_initializer(initializer_range)) //[2, word vector dimension], there are only two possibilities (0, 1), 0: the first sentence, 1: the second sentence; Eg: (2,768)
flat_token_type_ids = tf.reshape(token_type_ids, [-1]) //Calculate the number to be searched; batch_size*seq_length; Eg: 8*128=1024
one_hot_ids = tf.one_hot(flat_token_type_ids, depth=token_type_vocab_size) //one_hot_ids (total number of words, 2), 2: only 0,1
token_type_embeddings = tf.matmul(one_hot_ids, token_type_table) //Multiply the matrix to obtain the word vectors encoded by all word positions (the total number of words and the dimension of word vectors); Eg: (1024,768)
token_type_embeddings = tf.reshape(token_type_embeddings,
[batch_size, seq_length, width]) //Implement the same format as the previous output (batch_size, number of word vectors, word vector dimension); Eg: (8,128,768)
output += token_type_embeddings //Input word vector plus type_ The word vector of IDS is encoded. At this time, the word vector includes both the word vector information of the input word and the type_ Word vector information of IDS
if use_position_embeddings: //Add word vector position coding information
assert_op = tf.assert_less_equal(seq_length, max_position_embeddings) //Position coding vector, dimension (seq_length, max_position_embeddings), i.e. (input sequence length, defined maximum number of positions); Eg: (128,512)
with tf.control_dependencies([assert_op]):
full_position_embeddings = tf.get_variable(
name=position_embedding_name,
shape=[max_position_embeddings, width],
initializer=create_initializer(initializer_range)) //(512, dimension of word vector), define 512 location information, and encode the location information into the same dimension of word vector; Eg: (512,768)
position_embeddings = tf.slice(full_position_embeddings, [0, 0],
[seq_length, -1]) //Intercept the actual number of position codes according to the number of word vectors; Eg: (128,768)
num_dims = len(output.shape.as_list())
position_broadcast_shape = []
for _ in range(num_dims - 2):
position_broadcast_shape.append(1)
position_broadcast_shape.extend([seq_length, width])
position_embeddings = tf.reshape(position_embeddings,
position_broadcast_shape) //Add a dimension to the location coding information mapping and convert it into a vector with the same dimension as the word vector coding information. Because the location coding has nothing to do with different sentences, the added vector is represented by 1, i.e. (1, seq_length, embedding_size); Eg: (1,128,768)
output += position_embeddings //Add location information and coding information
output = layer_norm_and_dropout(output, dropout_prob) //Add location code and type_ Word vector sequence of IDS
return output
Embeddings layer mainly has the following three functions:
- Map the incoming and outgoing id sequence into the word vector sequence of the specified dimension
- Add type_ Mapping vector of IDS, type_id (identifying which sentence a word belongs to) information is added to the input word vector sequence
- Add the position coding information, convert the position information of each word into a vector of the corresponding dimension, and add it to the output word vector sequence
Through Embeddings, the output contains input information and type_ The multidimensional tensor of IDS information and location coding information. The tensor dimension is (batch_size, seq_length, embedding_size)
Encoder layer
with tf.variable_scope("encoder"):
//Add a dimension to the mask and convert the two-dimensional mask into a three-dimensional mask. The added dimension is used to indicate the number of Attention calculations for each word with other words
attention_mask = create_attention_mask_from_input_mask(
input_ids, input_mask)
//`sequence_output` shape = [batch_size, seq_length, hidden_size].
//Input Transformer model for training
self.all_encoder_layers = transformer_model(
input_tensor=self.embedding_output, //Embedding layer output word vector
attention_mask=attention_mask, //mask tag
hidden_size=config.hidden_size, //Dimension of vector; Eg: 768
num_hidden_layers=config.num_hidden_layers, //Number of neurons in the model
num_attention_heads=config.num_attention_heads,//Number of multi head mechanism headers in Transformer model
intermediate_size=config.intermediate_size, //Number of neurons in the whole junction layer
intermediate_act_fn=get_activation(config.hidden_act),
hidden_dropout_prob=config.hidden_dropout_prob,
attention_probs_dropout_prob=config.attention_probs_dropout_prob,
initializer_range=config.initializer_range,
do_return_all_layers=True)
self.sequence_output = self.all_encoder_layers[-1]
Transformer module
def transformer_model(input_tensor,
attention_mask=None,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12, #Number of multi head mechanism headers
intermediate_size=3072,
intermediate_act_fn=gelu,
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
initializer_range=0.02,
do_return_all_layers=False):
if hidden_size % num_attention_heads != 0: //Judge whether the defined vector dimension can divide the number of headers
raise ValueError(
"The hidden size (%d) is not a multiple of the number of attention "
"heads (%d)" % (hidden_size, num_attention_heads))
attention_head_size = int(hidden_size / num_attention_heads) //Calculate how many dimensions of vector features are required for each header
input_shape = get_shape_list(input_tensor, expected_rank=3) //Input model vector (batch_size, length of sentence, dimension of word vector)
batch_size = input_shape[0] //How many samples are there in total
seq_length = input_shape[1] //Length of sentences in a sample
input_width = input_shape[2] //Vector dimension corresponding to a word
if input_width != hidden_size: //Judge whether the input and output word vector dimensions are the same, so that the residual links can be added correctly
raise ValueError("The width of the input tensor (%d) != hidden size (%d)" %
(input_width, hidden_size))
prev_output = reshape_to_matrix(input_tensor) //Reduce the input tensor dimension from 3 to 2 dimensions, (batch_size, seq_length, embedding_size) - > (batch_size * seq_length, embedding_size); Eg:(8,128,768)->(1024,768)
//Perform Attention calculation
all_layer_outputs = []
for layer_idx in range(num_hidden_layers): //attention mechanism. The model has 12 layers, and each layer is traversed
with tf.variable_scope("layer_%d" % layer_idx):
layer_input = prev_output //The output of each layer is used as the input of the next layer
with tf.variable_scope("attention"):
attention_heads = []
with tf.variable_scope("self"):
attention_head = attention_layer(
from_tensor=layer_input, //From in self attention_ Tensor and to_ Tensors are equal, which are the input vectors of the model
to_tensor=layer_input,
attention_mask=attention_mask, //To mark which words have practical meaning, attention operation is required
num_attention_heads=num_attention_heads,//How many headers does the attention mechanism have
size_per_head=attention_head_size, //How many dimensional vector features does each head have
attention_probs_dropout_prob=attention_probs_dropout_prob,
initializer_range=initializer_range,
do_return_2d_tensor=True,
batch_size=batch_size,
from_seq_length=seq_length,
to_seq_length=seq_length)
attention_heads.append(attention_head)
attention_output = None
if len(attention_heads) == 1:
attention_output = attention_heads[0]
else:
attention_output = tf.concat(attention_heads, axis=-1)
//Add full connection layer: with `layer_input`.
with tf.variable_scope("output"):
attention_output = tf.layers.dense(
attention_output,
hidden_size,
kernel_initializer=create_initializer(initializer_range))
attention_output = dropout(attention_output, hidden_dropout_prob)
attention_output = layer_norm(attention_output + layer_input) //Make residual connection
// The activation is only applied to the "intermediate" hidden layer.
with tf.variable_scope("intermediate"):
intermediate_output = tf.layers.dense(
attention_output,
intermediate_size,
activation=intermediate_act_fn,
kernel_initializer=create_initializer(initializer_range))
///Convert the feature dimension through the full connection layer into 3072 feature vector, reduce the dimension to 768 dimension, and down project back to ` hidden_ size` then add the residual.
with tf.variable_scope("output"):
layer_output = tf.layers.dense(
intermediate_output,
hidden_size,
kernel_initializer=create_initializer(initializer_range))
layer_output = dropout(layer_output, hidden_dropout_prob)
layer_output = layer_norm(layer_output + attention_output)
prev_output = layer_output
all_layer_outputs.append(layer_output)
//Determine whether all results need to be returned
if do_return_all_layers:
final_outputs = []
for layer_output in all_layer_outputs:
final_output = reshape_from_matrix(layer_output, input_shape)
final_outputs.append(final_output)
return final_outputs
else:
final_output = reshape_from_matrix(prev_output, input_shape)
return final_output
Self atention calculation
In the self attention calculation, three special matrices are introduced to calculate the feature vectors, namely, Query, Key and Value. The Query vector represents the vector to be queried and calculated in the subsequent area, the Key vector represents the vector to be queried and calculated in the subsequent area, and the Value vector represents the current actual feature.
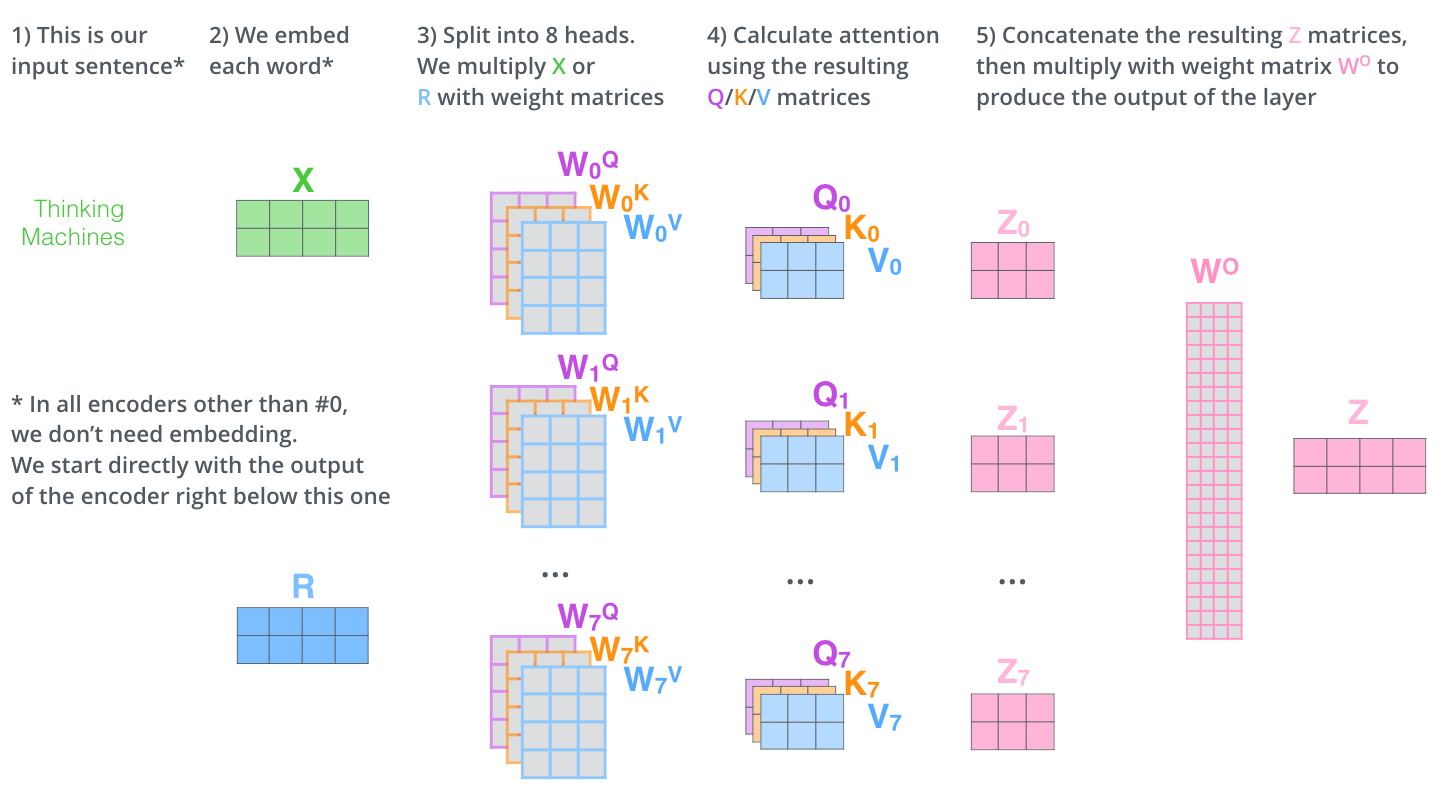
The program implementation of self attention calculation is as follows:
def attention_layer(from_tensor,
to_tensor,
attention_mask=None,
num_attention_heads=1,
size_per_head=512,
query_act=None, #Q matrix
key_act=None, #K matrix
value_act=None, #V matrix
attention_probs_dropout_prob=0.0,
initializer_range=0.02,
do_return_2d_tensor=False,
batch_size=None,
from_seq_length=None,
to_seq_length=None):
def transpose_for_scores(input_tensor, batch_size, num_attention_heads,
seq_length, width):
output_tensor = tf.reshape(
input_tensor, [batch_size, seq_length, num_attention_heads, width])
output_tensor = tf.transpose(output_tensor, [0, 2, 1, 3])
return output_tensor
from_shape = get_shape_list(from_tensor, expected_rank=[2, 3]) //(batch_size*seq_length,embedding_size);Eg: (1024,768)
to_shape = get_shape_list(to_tensor, expected_rank=[2, 3])//(batch_size*seq_length,embedding_size);Eg: (1024,768)
if len(from_shape) != len(to_shape): //Judge from_shape and to_ Is the shape the same dimension
raise ValueError(
"The rank of `from_tensor` must match the rank of `to_tensor`.")
if len(from_shape) == 3:
batch_size = from_shape[0]
from_seq_length = from_shape[1]
to_seq_length = to_shape[1]
elif len(from_shape) == 2: //Judge whether all parameters required for calculation exist
if (batch_size is None or from_seq_length is None or to_seq_length is None):
raise ValueError(
"When passing in rank 2 tensors to attention_layer, the values "
"for `batch_size`, `from_seq_length`, and `to_seq_length` "
"must all be specified.")
// Scalar dimensions referenced here:
// B = batch size (number of sequences) ;Eg: 8
// F = `from_tensor` sequence length;Eg: 128
// T = `to_tensor` sequence length;Eg: 128
// N = `num_attention_heads`; The number of headers in the attention mechanism; Eg: 12
// H = `size_per_head`; How many dimensional eigenvectors a head has; Eg: 64
from_tensor_2d = reshape_to_matrix(from_tensor) //Convert to 2D vector; Eg: (1024,768)
to_tensor_2d = reshape_to_matrix(to_tensor) //Convert to 2D vector; Eg: (1024,768)
//Build query matrix Q: ` query_layer` = [B*F, N*H]; Eg: [8*128,12*64]:[1024,768]
query_layer = tf.layers.dense(
from_tensor_2d,
num_attention_heads * size_per_head,
activation=query_act,
name="query",
kernel_initializer=create_initializer(initializer_range))
//Build memo matrix K: ` key_layer` = [B*T, N*H]; Eg: [8*128,12*64]:[1024,768]
key_layer = tf.layers.dense(
to_tensor_2d,
num_attention_heads * size_per_head,
activation=key_act,
name="key",
kernel_initializer=create_initializer(initializer_range))
//Construct the actual characteristic matrix V (exactly the same as the K matrix): ` value_layer` = [B*T, N*H]; Eg: [8*128,12*64]
value_layer = tf.layers.dense(
to_tensor_2d,
num_attention_heads * size_per_head,
activation=value_act,
name="value",
kernel_initializer=create_initializer(initializer_range))
// `query_layer` = [B, N, F, H]; Change the dimension, and only calculate the attention of each sentence with yourself; Eg: [8,12,128,64]
query_layer = transpose_for_scores(query_layer, batch_size,
num_attention_heads, from_seq_length,
size_per_head)
//`key_layer` = [B, N, T, H]; Eg: [8,12,128,64]; Transform dimension and Q matrix to do inner product
key_layer = transpose_for_scores(key_layer, batch_size, num_attention_heads,
to_seq_length, size_per_head)
//`attention_scores` = [B, N, F, T]
attention_scores = tf.matmul(query_layer, key_layer, transpose_b=True) //Matrix Q and matrix K are inner products
attention_scores = tf.multiply(attention_scores,
1.0 / math.sqrt(float(size_per_head))) //Do softmax to eliminate the impact of dimensions on the results
if attention_mask is not None: //mask mechanism is introduced to consider the actual sentence length
//`attention_mask` = [B, 1, F, T];Eg: [8,1,128,128]
attention_mask = tf.expand_dims(attention_mask, axis=[1])
adder = (1.0 - tf.cast(attention_mask, tf.float32)) * -10000.0 //The conversion result of mask marked with 1 is 0, and the conversion result marked with 0 is infinitesimal. In subsequent softmax calculations, 0 is converted to 1, and infinitesimal is converted to 0
attention_scores += adder //Inner product value plus mask tag
// Probability value matrix of inner product of Q and K: ` attention_probs` = [B, N, F, T]; Eg: [8,12,128,128]
attention_probs = tf.nn.softmax(attention_scores) //softmax mechanism converts the inner product of Q and K into probability value
attention_probs = dropout(attention_probs, attention_probs_dropout_prob)
//#Convert the V matrix into the same dimension as the probability value matrix to calculate
//`value_layer` = [B, T, N, H]
value_layer = tf.reshape(
value_layer,
[batch_size, to_seq_length, num_attention_heads, size_per_head])
// `value_layer` = [B, N, T, H]
value_layer = tf.transpose(value_layer, [0, 2, 1, 3])
//The final eigenvector is calculated by matrix multiplication of V matrix and probability value matrix
// `context_layer` = [B, N, F, H]
context_layer = tf.matmul(attention_probs, value_layer)
//`context_layer` = [B, F, N, H]
context_layer = tf.transpose(context_layer, [0, 2, 1, 3])
//Build return matrix
if do_return_2d_tensor:
//`context_layer` = [B*F, N*H]
context_layer = tf.reshape(
context_layer,
[batch_size * from_seq_length, num_attention_heads * size_per_head]) //Convert the matrix operation result to the result with the same input matrix dimension
else:
// `context_layer` = [B, F, N*H]
context_layer = tf.reshape(
context_layer,
[batch_size, from_seq_length, num_attention_heads * size_per_head])
return context_layer
Model output
//Only eigenvectors of [CLS] are returned
def get_pooled_output(self):
return self.pooled_output
//Returns the eigenvectors of all words in the sequence
def get_sequence_output(self):
return self.sequence_output
Model downstream tasks
def create_model(bert_config, is_training, input_ids, input_mask, segment_ids,
labels, num_labels, use_one_hot_embeddings):
"""Creates a classification model."""
model = modeling.BertModel(
config=bert_config,
is_training=is_training,
input_ids=input_ids, //Convert to encoded input sequence
input_mask=input_mask, //Do markers have practical meaning
token_type_ids=segment_ids, //Which sentence does the marker belong to
use_one_hot_embeddings=use_one_hot_embeddings)
output_layer = model.get_pooled_output() //Gets the eigenvector returned by [CLS]
hidden_size = output_layer.shape[-1].value //Obtain the dimension of feature vector; Eg: 768
//Create classification probability matrix, dimension (number of labels, vector dimension); Eg: (2,768)
output_weights = tf.get_variable(
"output_weights", [num_labels, hidden_size],
initializer=tf.truncated_normal_initializer(stddev=0.02))
//Build bias matrix
output_bias = tf.get_variable(
"output_bias", [num_labels], initializer=tf.zeros_initializer())
with tf.variable_scope("loss"):
if is_training:
output_layer = tf.nn.dropout(output_layer, keep_prob=0.9)
logits = tf.matmul(output_layer, output_weights, transpose_b=True) //Output characteristic matrix multiplied by classification weight matrix
logits = tf.nn.bias_add(logits, output_bias) //Plus offset matrix
probabilities = tf.nn.softmax(logits, axis=-1) //Calculate probability value
log_probs = tf.nn.log_softmax(logits, axis=-1)
one_hot_labels = tf.one_hot(labels, depth=num_labels, dtype=tf.float32)
per_example_loss = -tf.reduce_sum(one_hot_labels * log_probs, axis=-1)
loss = tf.reduce_mean(per_example_loss)
return (loss, per_example_loss, logits, probabilities)
summary
So far, we have finished the core procedures in the BERT model, including:
- Preprocess the input data, segment the input sequence and map it into the corresponding coded numerical sequence input_ids, build a sequence segment to identify which sentence the corresponding word belongs to_ IDS and sequence input identifying whether the corresponding word has practical meaning_ mask
- The Embedding layer maps the preprocessed input sequence into word vector sequence and adds type_ids, location code and other information
- The Transformer layer calculates the actual feature vector through self attention and continuously optimizes the weight parameters of the model
According to the requirements of the actual project, we can adjust the data processing module and downstream tasks, and use the BERT model to realize natural language processing tasks such as multi label text classification, QA question answering and machine translation.