Read and write operations on MongoDB on SparkSql (Python version)
1.1 Read mongodb data
The python approach requires the use of pyspark or spark-submit for submission.
- Here's how pyspark starts:
1.1.1 Start the command line with pyspark
# Locally installed version of spark is 2.3.1, if other versions need to be modified version number and scala version number pyspark --packages org.mongodb.spark:mongo-spark-connector_2.11:2.3.1
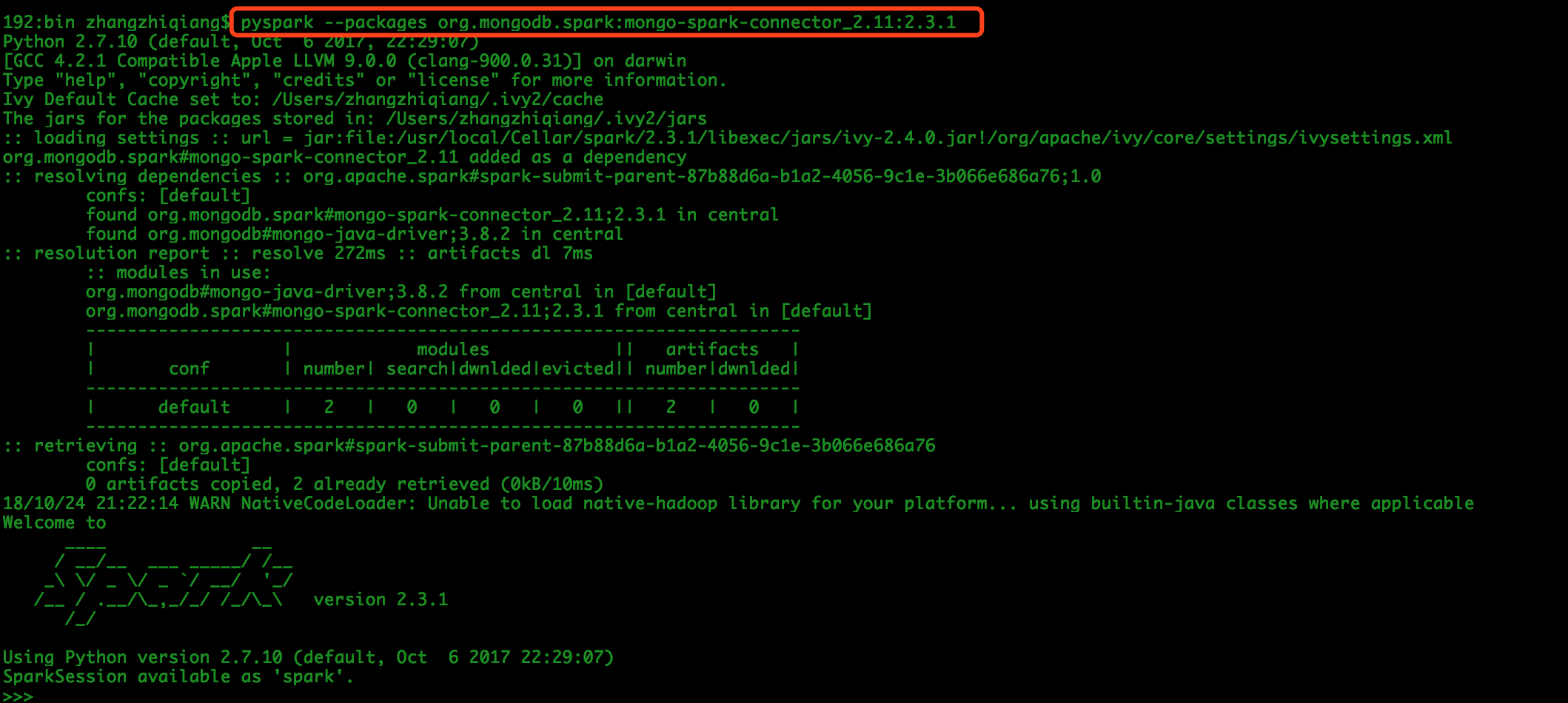
1.1.2 Enter the following code in the pyspark shell script:
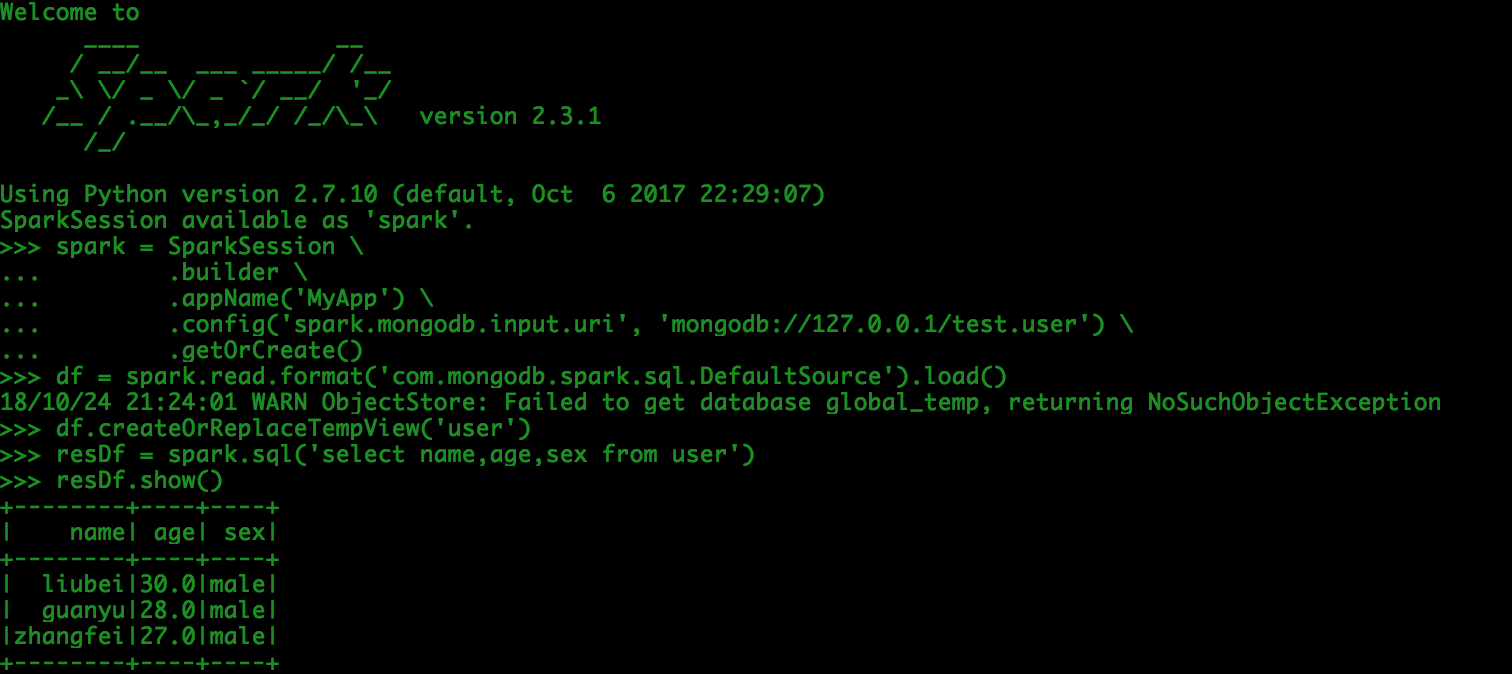
spark = SparkSession \
.builder \
.appName('MyApp') \
.config('spark.mongodb.input.uri', 'mongodb://127.0.0.1/test.user') \
.getOrCreate()
df = spark.read.format('com.mongodb.spark.sql.DefaultSource').load()
df.createOrReplaceTempView('user')
resDf = spark.sql('select name,age,sex from user')
resDf.show()
spark.stop()
exit(0)
Results Output:
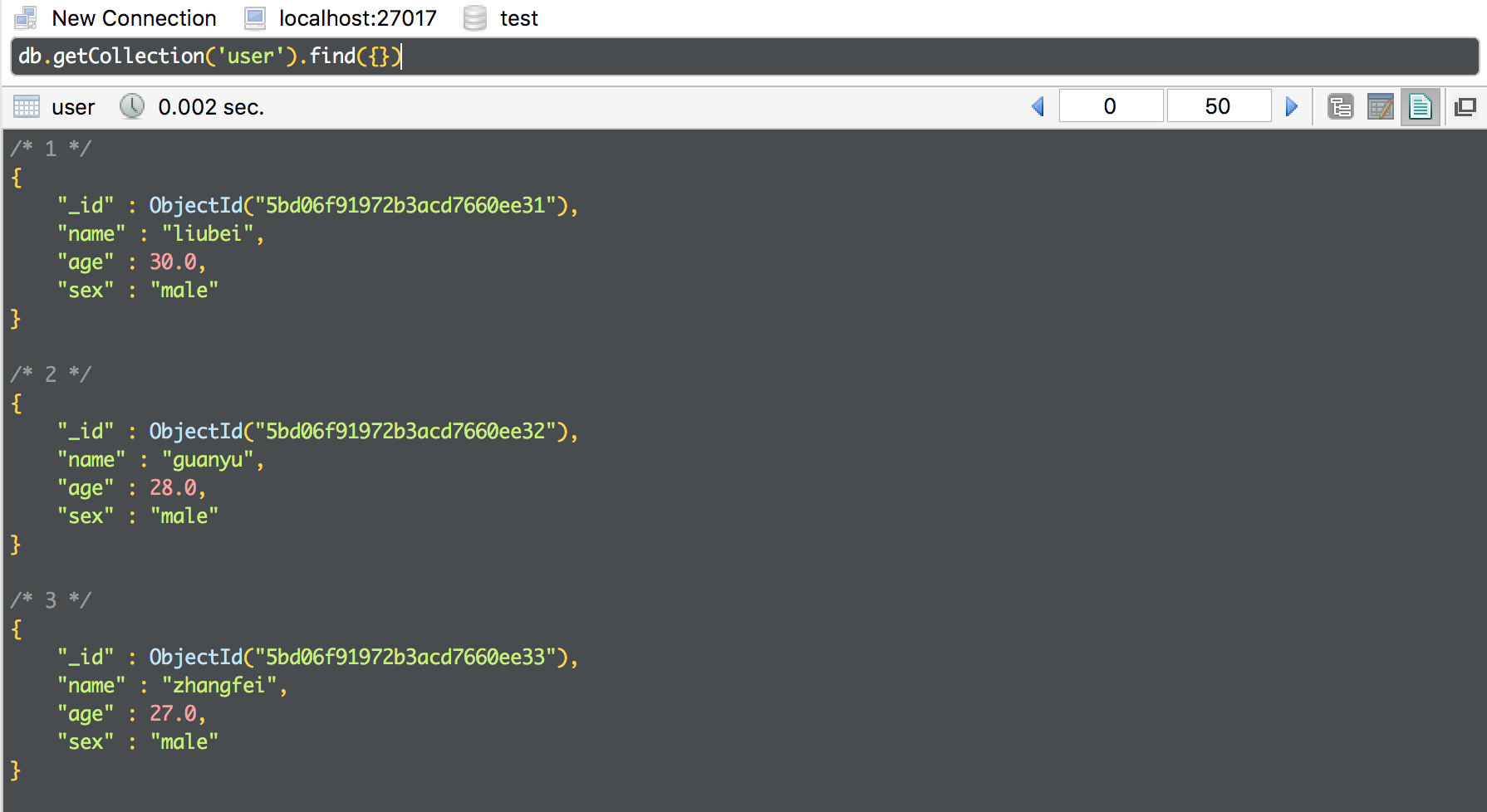
The results of the query in mongo:
- Start with spark-submit
1.1.3 Write the read_mongo.py script, which is as follows:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
from pyspark.sql import SparkSession
# The pyspark way starts, here my local spark uses the spark 2.3.1 version. For other spark versions, the version number of mongo-spark-connector is different. See the official document of mongodb specifically.
# pyspark --packages org.mongodb.spark:mongo-spark-connector_2.11:2.3.1
# spark-submit submission, I only use nohup submission
# nohup spark-submit --packages org.mongodb.spark:mongo-spark-connector_2.11:2.3.1 /Users/zhangzhiqiang/Documents/pythonproject/demo/mongodb-on-spark/read_mongo.py >> /Users/zhangzhiqiang/Documents/pythonproject/demo/mongodb-on-spark/read_mongo.log &
if __name__ == '__main__':
spark = SparkSession \
.builder \
.appName('MyApp') \
.config('spark.mongodb.input.uri', 'mongodb://127.0.0.1/test.user') \
.getOrCreate()
df = spark.read.format('com.mongodb.spark.sql.DefaultSource').load()
df.createOrReplaceTempView('user')
resDf = spark.sql('select name,age,sex from user')
resDf.show()
spark.stop()
exit(0)
1.1.4 Submit using spark-submit
Here I submit in nohup mode and output the result in log file.
nohup spark-submit --packages org.mongodb.spark:mongo-spark-connector_2.11:2.3.1 /Users/zhangzhiqiang/Documents/pythonproject/demo/mongodb-on-spark/read_mongo.py >> /Users/zhangzhiqiang/Documents/pythonproject/demo/mongodb-on-spark/read_mongo.log &
1.2 Read mongo data using Schema constraints
1.2.1 adopts pyspark mode
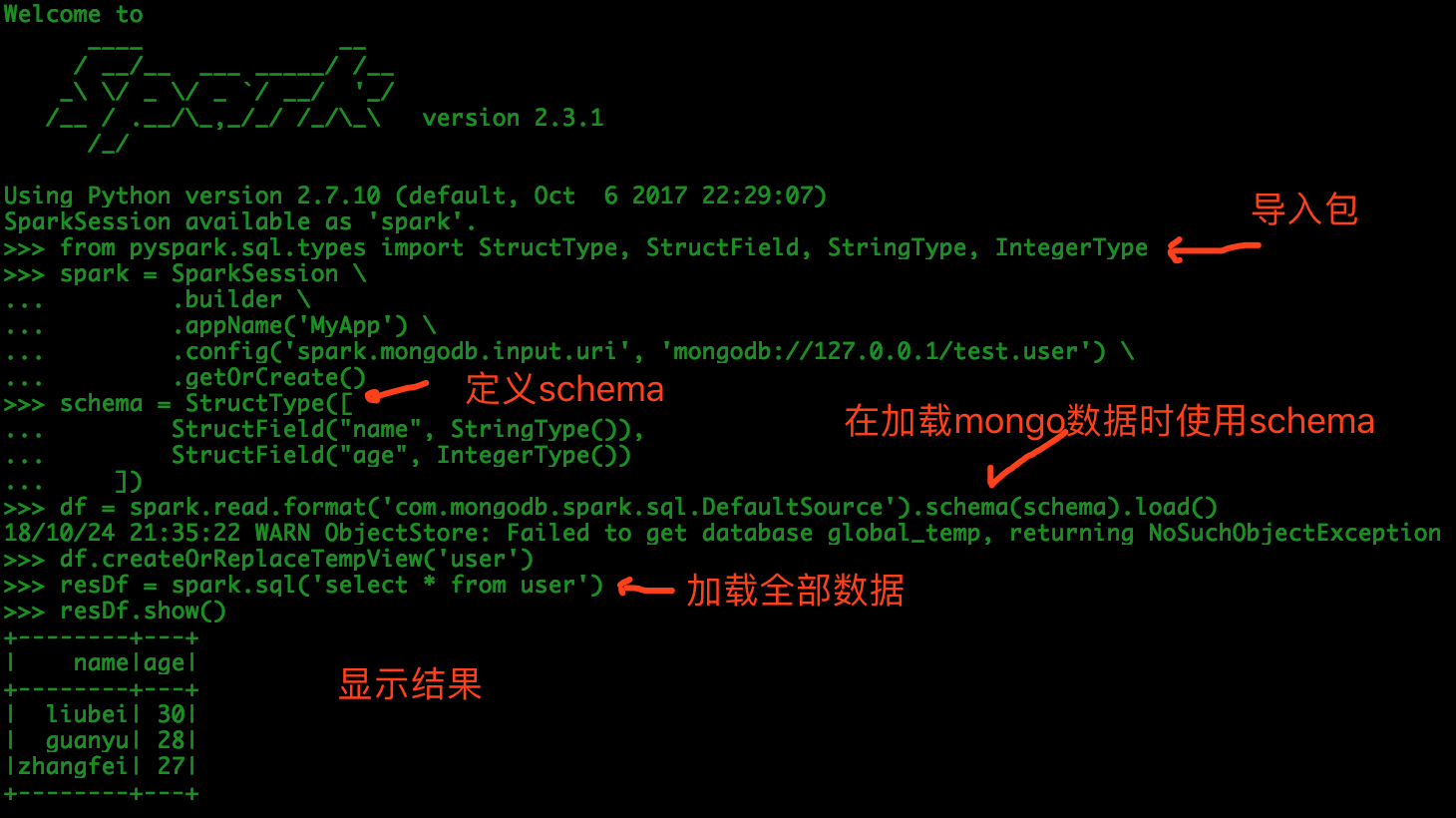
Write the following code on the command line:
# Import package
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
spark = SparkSession \
.builder \
.appName('MyApp') \
.config('spark.mongodb.input.uri', 'mongodb://127.0.0.1/test.user') \
.getOrCreate()
# If there are too many json fields in mongodb, we can also filter out unwanted data through schema restrictions
# name is set to StringType
# age is set to IntegerType
schema = StructType([
StructField("name", StringType()),
StructField("age", IntegerType())
])
df = spark.read.format('com.mongodb.spark.sql.DefaultSource').schema(schema).load()
df.createOrReplaceTempView('user')
resDf = spark.sql('select * from user')
resDf.show()
spark.stop()
exit(0)
Output results:
1.3 Write mongodb data
1.3.1 in pyspark
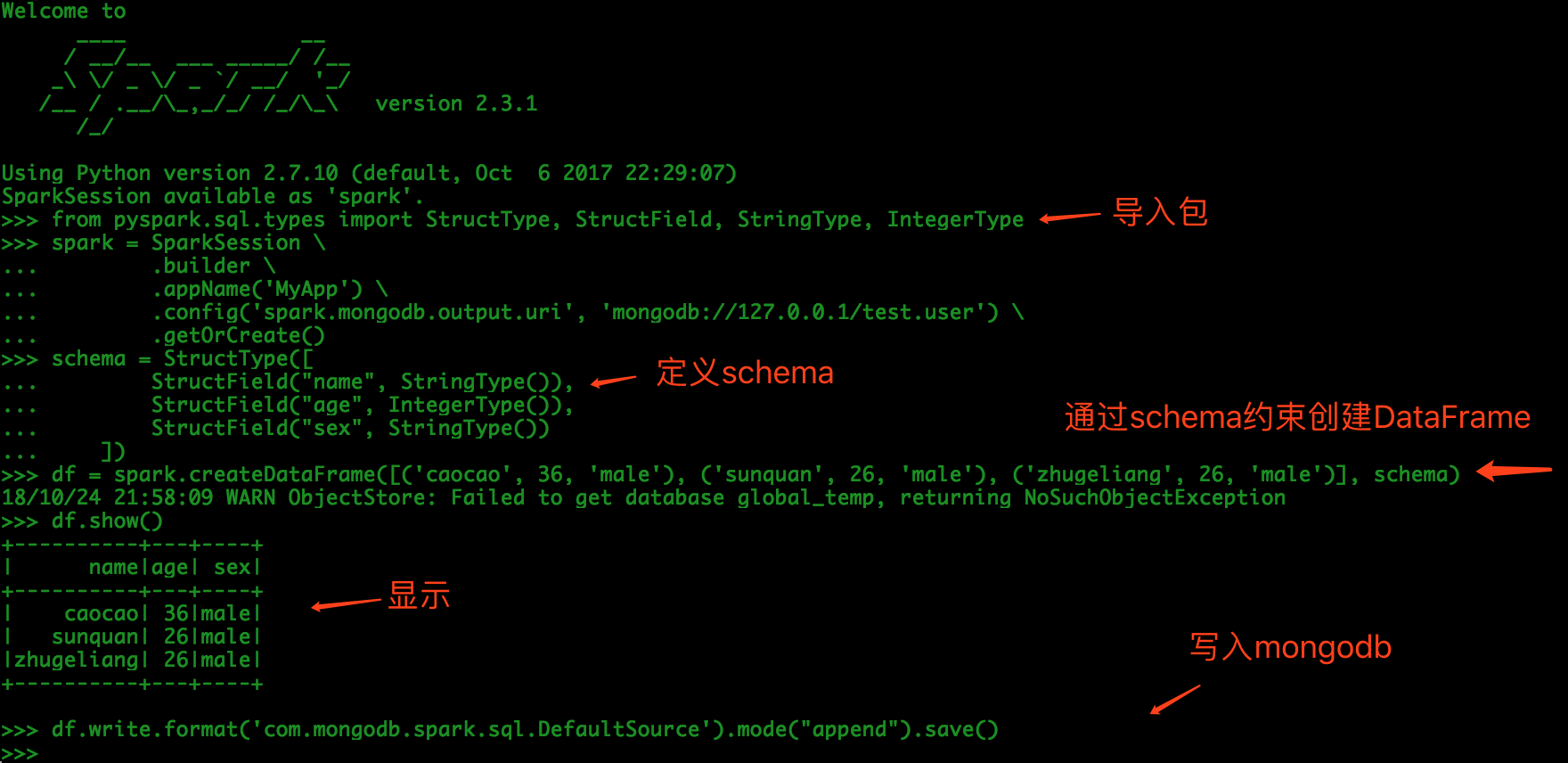
# Import package
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
spark = SparkSession \
.builder \
.appName('MyApp') \
.config('spark.mongodb.output.uri', 'mongodb://127.0.0.1/test.user') \
.getOrCreate()
schema = StructType([
StructField("name", StringType()),
StructField("age", IntegerType()),
StructField("sex", StringType())
])
df = spark.createDataFrame([('caocao', 36, 'male'), ('sunquan', 26, 'male'), ('zhugeliang', 26, 'male')], schema)
df.show()
df.write.format('com.mongodb.spark.sql.DefaultSource').mode("append").save()
spark.stop()
exit(0)
Result:
The results of the query in mongo:

Reference documents: Mongo on Spark Python