preparation:
import pyspark
from pyspark import SparkContext
from pyspark import SparkConf
conf=SparkConf().setAppName("lg").setMaster('local[4]') #local[4] means to run 4 kernels locally
sc=SparkContext.getOrCreate(conf)1. Parallel and collect
The parallelize function converts the list object to an RDD object; the collect() function returns the list data type corresponding to the RDD object
words = sc.parallelize(
["scala",
"java",
"spark",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"
])
print(words)
print(words.collect())ParallelCollectionRDD[139] at parallelize at PythonRDD.scala:184 ['scala', 'java', 'spark', 'hadoop', 'spark', 'akka', 'spark vs hadoop', 'pyspark', 'pyspark and spark']
2. Two ways to define / generate rdd: parallel function and textFile function
The first way is to use the parallelize method. The second way is to use the textFile function to read the file directly. Note that if the file is a folder, all the files under the folder will be read (if there is a folder under the folder, an error will be reported).
path = 'G:\\pyspark\\rddText.txt' rdd = sc.textFile(path) rdd.collect()
3. Partition setting and display: repartition,defaultParallelism and glom
You can set the global default partition number through SparkContext.defaultParallelism, or you can set the partition number of a specific rdd through repartition.
When calling glom() before calling the collect() function, the result will be displayed by partition.
SparkContext.defaultParallelism=5 print(sc.parallelize([0, 2, 3, 4, 6]).glom().collect()) SparkContext.defaultParallelism=8 print(sc.parallelize([0, 2, 3, 4, 6]).glom().collect()) rdd = sc.parallelize([0, 2, 3, 4, 6]) rdd.repartition(2).glom().collect()
[[0], [2], [3], [4], [6]] [[], [0], [], [2], [3], [], [4], [6]] Out[105]: [[2, 4], [0, 3, 6]]
Note: setting SparkContext.defaultParallelism only affects the rdd defined later, but not the previously generated rdd
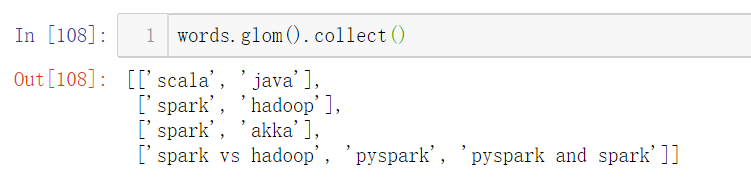
4. count and countByValue
Count returns the number of elements in rdd and an int. countByValue returns the number of different element values in rdd. It returns a dictionary. If the element in rdd is not a dictionary type, such as the string in this case (if it is an int, an error will be reported), countByKey will count the number of different keys by using the initial of each element as the key
counts = words.count()
print("Number of elements in RDD -> %i" % counts)
print("Number of every elements in RDD -> %s" % words.countByKey())
print("Number of every elements in RDD -> %s" % words.countByValue())Number of elements in RDD -> 9
Number of every elements in RDD -> defaultdict(<class 'int'>, {'s': 4, 'j': 1, 'h': 1, 'a': 1, 'p': 2})
Number of every elements in RDD -> defaultdict(<class 'int'>, {'scala': 1, 'java': 1, 'spark': 2, 'hadoop': 1, 'akka': 1, 'spark vs hadoop': 1, 'pyspark': 1, 'pyspark and spark': 1})5. filter filter function
filter(func) filters the elements in each partition of rdd (each partition as a whole) according to func function
words_filter = words.filter(lambda x: 'spark' in x)
filtered = words_filter.glom().collect()
print("Fitered RDD -> %s" % (filtered))Fitered RDD -> [[], ['spark'], ['spark'], ['spark vs hadoop', 'pyspark', 'pyspark and spark']]
6.map and flatMap
The new RDD is returned by applying the map function to each element in the RDD. The difference between flatMap() and map(): flatMap() returns an RDD consisting of the elements in each list instead of a RDD consisting of a list.
words_map = words.map(lambda x: (x, len(x)))
mapping = words_map.collect()
print("Key value pair -> %s" % (mapping))
words.flatMap(lambda x: (x, len(x))).collect()Key value pair -> [('scala', 5), ('java', 4), ('spark', 5), ('hadoop', 6), ('spark', 5), ('akka', 4), ('spark vs hadoop', 15), ('pyspark', 7), ('pyspark and spark', 17)]
['scala',5,'java', 4,'spark', 5,'hadoop',6,'spark',5,'akka',4,'spark vs hadoop',15,'pyspark',7,'pyspark and spark',17]7 reduce and fold
reduce function; after performing the specified swappable and associated binary operation, the elements in RDD will be returned
If there is a set of integers [x1,x2,x3], use reduce to perform the add operation. After the first element is added, the result is sum=x1,
Then add sum and X2, sum=x1+x2, and add x2 and sum, sum=x1+x2+x3.
The difference between fold and reduce: fold passes one more parameter than reduce. In the following example, nums.fold(1,add) means that each element in nums executes add(e,1) first and then reduce
def add(a,b):
c = a + b
print(str(a) + ' + ' + str(b) + ' = ' + str(c))
return c
nums = sc.parallelize([1, 2, 3, 4, 5])
adding = nums.reduce(add)
print("Adding all the elements -> %i" % (adding))
adding2 = nums.fold(1,add) #The first parameter 1 indicates that each element in nums executes add(e,1) first and then fold
print("Adding all the elements -> %i" % (adding2))1 + 2 = 3 3 + 3 = 6 6 + 4 = 10 10 + 5 = 15 Adding all the elements -> 15 1 + 1 = 2 2 + 2 = 4 4 + 1 = 5 5 + 3 = 8 8 + 4 = 12 12 + 1 = 13 13 + 5 = 18 18 + 6 = 24 Adding all the elements -> 24
8. distinct de duplication

9. Union, intersection, subcontract and cartesian among multiple RDDS
Equivalent to the operations of union, intersection, difference and Cartesian product
rdd1 = sc.parallelize(["spark","hadoop","hive","spark"]) rdd2 = sc.parallelize(["spark","hadoop","hbase","hadoop"]) rdd3 = rdd1.union(rdd2) rdd3.collect() ['spark', 'hadoop', 'hive', 'spark', 'spark', 'hadoop', 'hbase', 'hadoop']
rdd3 = rdd1.intersection(rdd2) rdd3.collect() ['spark', 'hadoop']
rdd3 = rdd1.subtract(rdd2) rdd3.collect() ['hive']
rdd3 = rdd1.cartesian(rdd2)
rdd3.collect()
[('spark', 'spark'),
('spark', 'hadoop'),
('spark', 'hbase'),
('spark', 'hadoop'),
('hadoop', 'spark'),
('hadoop', 'hadoop'),
('hadoop', 'hbase'),
('hadoop', 'hadoop'),
('hive', 'spark'),
('hive', 'hadoop'),
('hive', 'hbase'),
('hive', 'hadoop'),
('spark', 'spark'),
('spark', 'hadoop'),
('spark', 'hbase'),
('spark', 'hadoop')]10 top,take,takeOrdered
The return value is list, and there is no need to collect(). In which, take does not take the elements by order, that is, take the original of the first n positions in the original rdd; top takes the first n positions by default by large to small; takeOrdered takes the first n positions by default by small to large
rdd1 = sc.parallelize(["spark","hadoop","hive","spark","kafka"]) print(rdd1.top(3)) print(rdd1.take(3)) print(rdd1.takeOrdered(3)) ['spark', 'spark', 'kafka'] ['spark', 'hadoop', 'hive'] ['hadoop', 'hive', 'kafka']
11. join operation
join(other, numPartitions = None) returns RDD, which contains a pair of elements with matching keys and all the values of that particular key
x = sc.parallelize([("spark", 1), ("hadoop", 4)])
y = sc.parallelize([("spark", 2), ("hadoop", 5)])
joined = x.join(y)
final = joined.collect()
print( "Join RDD -> %s" % (final))
Join RDD -> [('hadoop', (4, 5)), ('spark', (1, 2))]12 aggregate
In aggregate, the former function is the function calculated in each partition, and the latter function is the function aggregating the results of each partition
def add2(a,b):
c = a + b
print(str(a) + " add " + str(b) + ' = ' + str(c))
return c
def mul(a,b):
c = a*b
print(str(a) + " mul " + str(b) + ' = ' + str(c))
return c
print(nums.glom().collect())
#It is equivalent to adding 2 to the sum of the values of each partition, that is to say, it is converted to [[3], [4], [5], [11]]
#Then multiply 2 by the number of each partition, i.e. 2 * 3 = 6, 6 * 4 = 24, 24 * 5 = 120120 * 11 = 1320
print(nums.aggregate(2,add2,mul))
#It is equivalent to multiplying the value of each partition by 2, which is converted to [[2], [4], [6], [40], where 40 = 2 * 4 * 5
#Then use 2 and the number of each partition to add, that is, 2 + 2 = 4,4 + 4 = 8,8 + 6 = 14,14 + 40 = 54
print(nums.aggregate(2,mul,add2))
[[1], [2], [3], [4, 5]]
2 mul 3 = 6
6 mul 4 = 24
24 mul 5 = 120
120 mul 11 = 1320
1320
2 add 2 = 4
4 add 4 = 8
8 add 6 = 14
14 add 40 = 54
54

