1, RabbitMQ cluster architecture
RabbitMQ cluster architecture has the following types: active / standby mode, remote mode, mirror mode and multi active mode.
Active standby mode
It is an active / standby scheme (if the primary node hangs, the slave node only provides services)
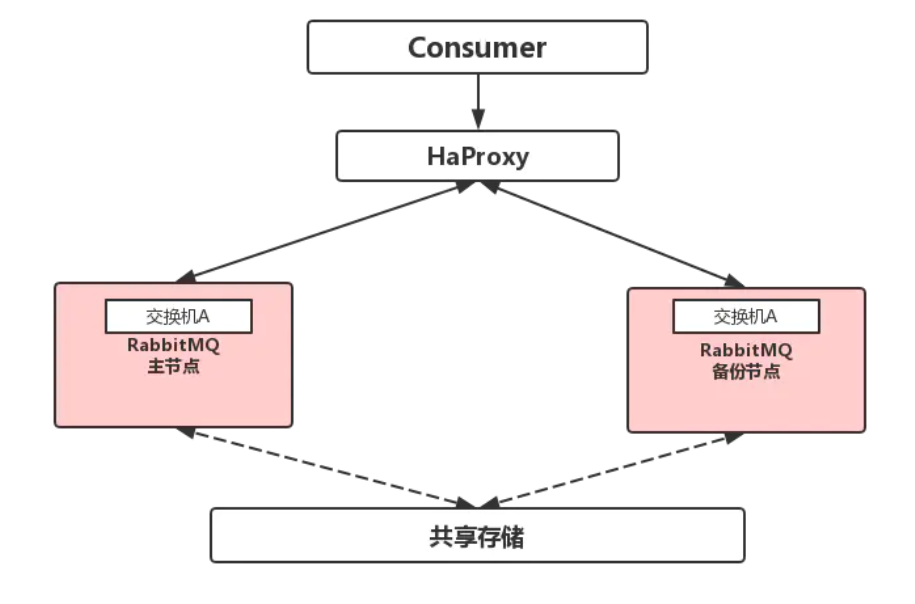
HaProxy configuration:
listen rabbitmq_cluster bind 0.0.0.0:5672 mode tcp #Configure TCP mode balance roundrobin #Simple polling server bhz76 192.168.11.12:5672 check inter 5000 rise 2 fall 3 #Master node server bhz77 192.168.11.13:5672 backup check inter 5000 rise 2 fall 3 #Standby node
Note: rabbitmq cluster nodes are configured #inter to perform health checks on mq clusters every 5 seconds. The server is proved to be available for 2 times, and the server is proved to be unavailable for 3 times. The active and standby mechanisms are configured.
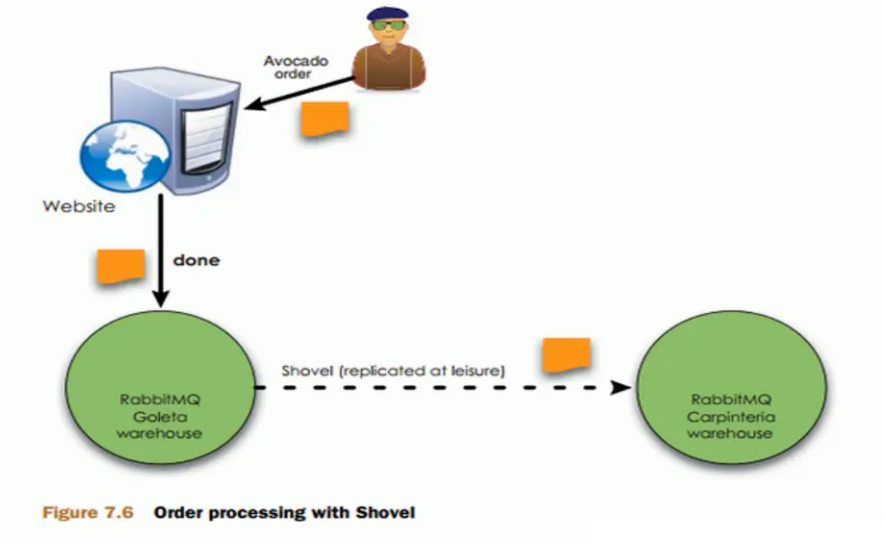
Remote mode (not commonly used)
Long distance communication and replication means that we can replicate messages in different data centers. We can interconnect two mq clusters across regions.
The model has become a near end synchronous confirmation and a far end asynchronous confirmation, which greatly improves the order confirmation speed and ensures the reliability.
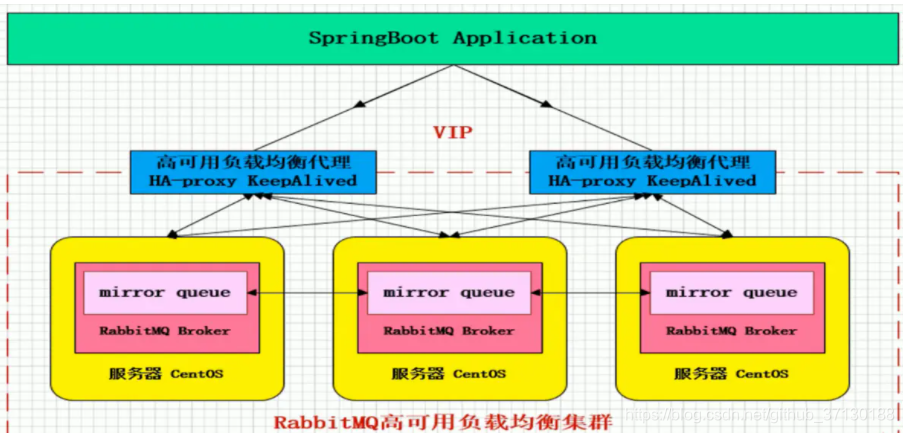
Mirror mode (common)
It is to realize data synchronization. Generally speaking, it is 2-3 nodes to realize data synchronization (for 100% data reliability solution, it is generally 3 nodes) to ensure that 100% data is not lost. It is most used in practical work.
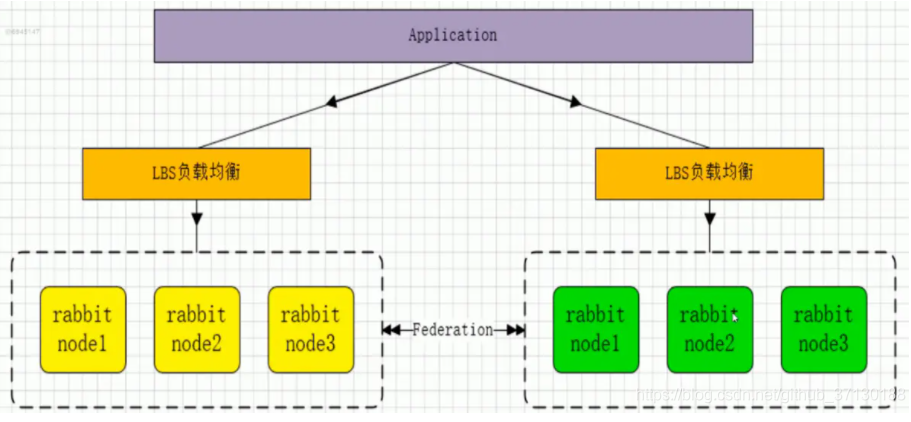
Multi active mode
If the dual center mode (multi center) is adopted, one RabbitMQ cluster is deployed in each of the two (or more) data centers, and some queue message sharing needs to be realized among the centers. The mainstream mode to realize remote data replication. Because the configuration of remote mode is complex, generally speaking, the implementation of remote cluster is realized by using double live or multi live mode.
This mode needs to rely on the federation plug-in of rabbitmq to realize continuous reliable AMQP data communication. The multi live mode is very simple in actual configuration and application.
remarks:
Differences between active / standby mode and active / slave mode:
- Active standby mode: the primary node provides read-write services, while the slave node does not provide read-write services, but is only responsible for providing backup services. The main function of the backup node is to automatically switch from -- > the primary node when the primary node goes down
- Master-slave mode: the master node provides read-write and the slave node is read-only
Federation plug-in
- The Federation plug-in is a high-performance plug-in that transmits messages between Brokers without building clusters,
- The Federation plug-in can transmit messages between Brokers or clusters. The two sides of the connection can use different users and visual hosts,
- Both parties can also use different versions of RabbitMQ and Erlang. The Federation plug-in communicates using the AMQP protocol and can receive discontinuous transmissions.
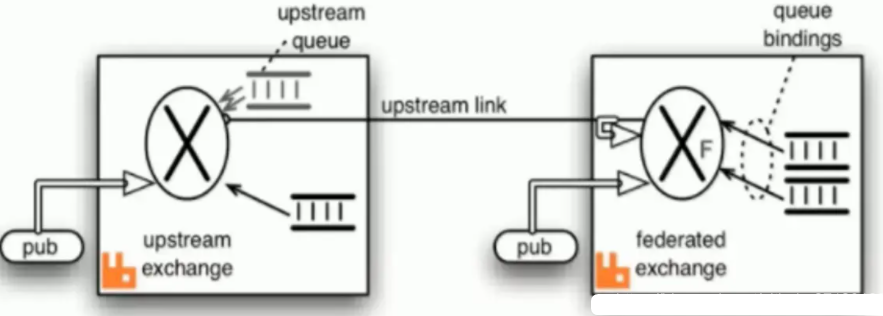
Federation Exchanges can be regarded as downstream actively pulling messages from Upstream, but not all messages. Only Exchange that has clearly defined the Bindings relationship on downstream, that is, there is an actual physical Queue to receive messages, can pull messages from Upstream to downstream. Use AMQP protocol to implement inter agent communication. Downstream will combine the binding relationships, and the bind / unbind command will be sent to the Upstream switch. Therefore, FederationExchange only receives messages with subscriptions.
2, How does RabbitMQ ensure the reliability of messages
First, let's take a look at why RabbitMQ is not reliable
RabbitMQ is lost in the following three cases:
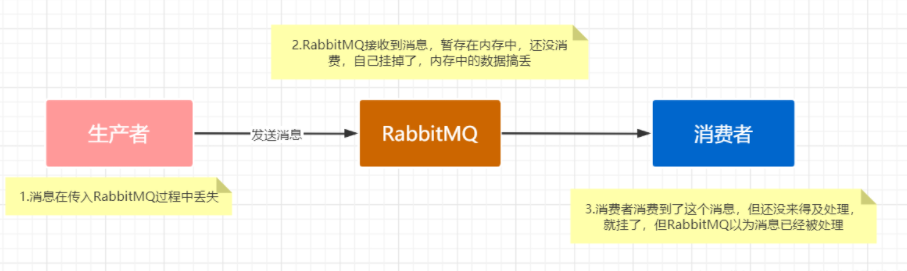
- On the producer side: the data sent by the producer to MQ is lost
- RabbitMQ: when MQ receives a message, it is temporarily stored in memory and has not been consumed. If it hangs up, all data will be lost
- On the consumer side: the consumer just got the message and hasn't handled it yet. He hung up. MQ thought the consumer had handled it again
Solutions to unreliable problems
We list solutions to these problems.
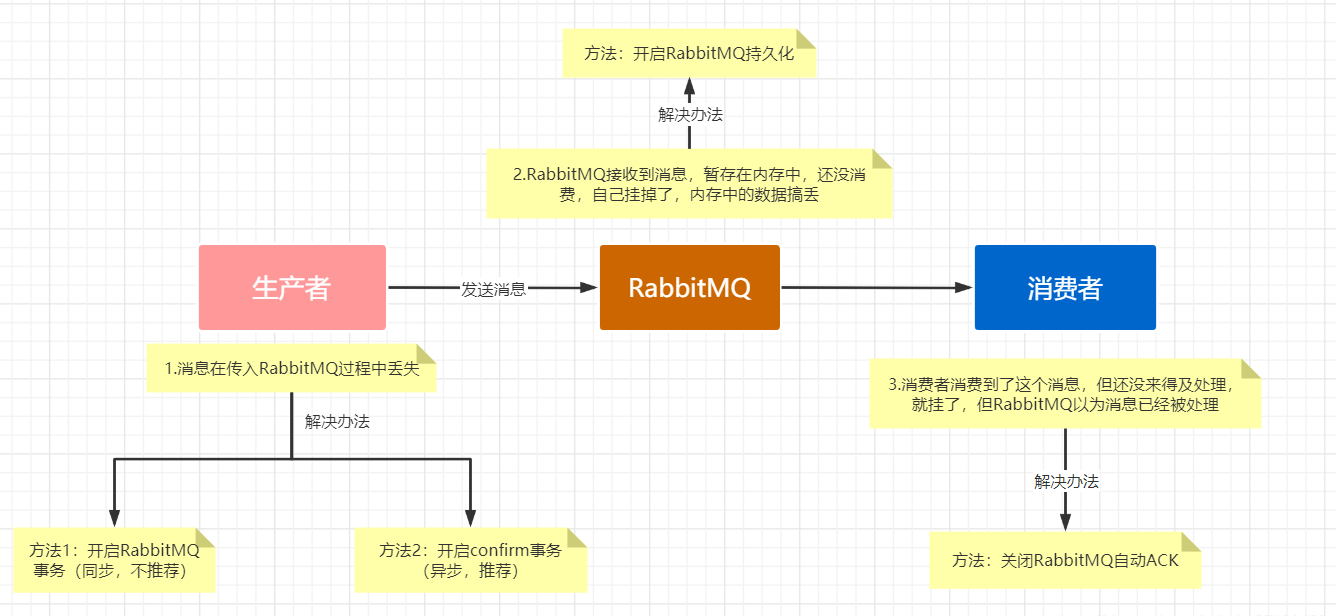
(1) Producer side
Producers: there are two schemes: one is to enable RabbitMQ transaction (not recommended), and the other is to enable confirm mode (asynchronous, recommended)
Start RabbitMQ transaction
AMQP protocol provides a transaction mechanism to enable transaction support when delivering messages. If message delivery fails, the transaction will be rolled back.
// 1. Custom transaction manager
@Configuration
public class RabbitTranscation {
@Bean
public RabbitTransactionManager rabbitTransactionManager(ConnectionFactory connectionFactory){
return new RabbitTransactionManager(connectionFactory);
}
@Bean
public RabbitTemplate rabbitTemplate(ConnectionFactory connectionFactory){
return new RabbitTemplate(connectionFactory);
}
}
// 2. Modify yml
spring:
rabbitmq:
# The message is returned without being received by the queue
publisher-returns: true
// 3. Enable transaction support
rabbitTemplate.setChannelTransacted(true);
// 4. Call ReturnCallback when the message is not received
rabbitTemplate.setMandatory(true);
// 5. Producer delivery message
@Service
public class ProviderTranscation implements RabbitTemplate.ReturnCallback {
@Autowired
RabbitTemplate rabbitTemplate;
@PostConstruct
public void init(){
// Set channel to start transaction
rabbitTemplate.setChannelTransacted(true);
rabbitTemplate.setReturnCallback(this);
}
@Override
public void returnedMessage(Message message, int replyCode, String replyText, String exchange, String routingKey) {
System.out.println("This message failed to send"+message+",Please handle");
}
@Transactional(rollbackFor = Exception.class,transactionManager = "rabbitTransactionManager")
public void publishMessage(String message) throws Exception {
rabbitTemplate.setMandatory(true);
rabbitTemplate.convertAndSend("javatrip",message);
}
}
However, few people do this because it is a synchronous operation. After a message is sent, the sender will block to wait for the response of rabbitmq server before continuing to send the next message. The throughput and performance of the producer's production messages will be greatly reduced.
Enable confirm mode
When sending a message, set the channel to confirm mode. After the message enters the channel, it will be assigned a unique ID. once the message is delivered to the matched queue, RabbitMQ will send a confirmation to the producer.
// 1. Enable the message confirmation mechanism
spring:
rabbitmq:
# The message is returned without being received by the queue
publisher-returns: true
# Enable message confirmation mechanism
publisher-confirm-type: correlated
// 2. Call ReturnCallback when the message is not received
rabbitTemplate.setMandatory(true);
// 3. Producer delivery message
@Service
public class ConfirmProvider implements RabbitTemplate.ConfirmCallback,RabbitTemplate.ReturnCallback {
@Autowired
RabbitTemplate rabbitTemplate;
@PostConstruct
public void init() {
rabbitTemplate.setReturnCallback(this);
rabbitTemplate.setConfirmCallback(this);
}
@Override
public void confirm(CorrelationData correlationData, boolean ack, String cause) {
if(ack){
System.out.println("Confirmed this message:"+correlationData);
}else{
System.out.println("Confirmation failed:"+correlationData+";Exception occurred:"+cause);
}
}
@Override
public void returnedMessage(Message message, int replyCode, String replyText, String exchange, String routingKey) {
System.out.println("This message failed to send"+message+",Please handle");
}
public void publisMessage(String message){
rabbitTemplate.setMandatory(true);
rabbitTemplate.convertAndSend("javatrip",message);
}
}
// 4. If the message confirmation fails, we can compensate the message, that is, the message retry mechanism. When the confirmation information is not received, the message is redelivered. The following configuration can be set.
spring:
rabbitmq:
# It supports returning to the queue after message sending fails
publisher-returns: true
# Enable message confirmation mechanism
publisher-confirm-type: correlated
listener:
simple:
retry:
# Turn on Retry
enabled: true
# max retries
max-attempts: 5
# Retry interval
(2) RabbitMQ
Enable RabbitMQ persistence to persist memory data to disk.
When creating a queue, set the persistent attribute durable to true and autoDelete to false
@Queue(value = "javatrip",durable = "false",autoDelete = "false")
Persistent message: when sending a message, set the deliveryMode of the message to 2. In Spring Boot, the message is persistent by default.
(3) Consumer side
Turn off RabbitMQ automatic ACK. The consumer has just consumed the message and has not yet processed the business. The result is abnormal. At this time, you need to turn off automatic confirmation and change to manual confirmation.
// 1. Modify yml to manual sign in mode
spring:
rabbitmq:
listener:
simple:
# Manual sign in mode
acknowledge-mode: manual
# Sign one message at a time
prefetch: 1
// 2. Consumers sign in manually
@Component
@RabbitListener(queuesToDeclare = @Queue(value = "javatrip", durable = "true"))
public class Consumer {
@RabbitHandler
public void receive(String message, @Headers Map<String,Object> headers, Channel channel) throws Exception{
System.out.println(message);
// Unique message ID
Long deliverTag = (Long) headers.get(AmqpHeaders.DELIVERY_TAG);
// Confirm this message
if(...){
channel.basicAck(deliverTag,false);
}else{
// Consumption failed. The message returns to the queue
channel.basicNack(deliverTag,false,true);
}
}
3, RabbitMQ idempotent problem
Generally speaking, idempotency is to ensure that the data is not consumed repeatedly, and the data cannot be less (that is, the above reliability), that is, the problem of data consistency.
The problem of data duplication is much simpler, that is, judge whether the data has been consumed on the consumer side
- For example, if you want to write a data to the library, you first check it according to the primary key. If you have all the data, don't insert it. update it.
- For example, if you write Redis, it's no problem. Anyway, it's set every time, natural idempotency.
- For example, if you are not in the above two scenarios, it is a little more complicated. When you need to ask the producer to send each data, you need to add a globally unique id, such as an order id, and then after you consume it here, first check it in Redis according to this id. have you consumed it before? If you haven't consumed it, you can handle it, and then write this id to Redis. If you spend too much, don't deal with it. Just make sure you don't deal with the same message again.
- For example, based on the unique key of the database to ensure that duplicate data will not be repeatedly inserted into multiple entries. Because there is only one key constraint, duplicate data insertion will only report errors and will not lead to dirty data in the database.