LinkedBlockingQueue
Blocking queue is one of the common implementations of BlockingQueue interface. It is an optional (queue length can be manually specified) bounded blocking queue based on linked list
public class LinkedBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
The construction method limits the queue length by setting the attribute capacity. The default capacity is Integer.MAX_VALUE. And use the attribute count to record the current number of elements in the queue.
/** The capacity bound, or Integer.MAX_VALUE if none */
private final int capacity;
/** Current number of elements */
private final AtomicInteger count = new AtomicInteger();
/**
* Head of linked list.
* Invariant: head.item == null
* The item (actual queued element) of the header node is always null
*/
transient Node<E> head;
/**
* Tail of linked list.
* Invariant: last.next == null
* The next of the tail node is always null
*/
private transient Node<E> last;
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
// Note that the head and tail nodes of the linked list point to a pseudo node whose attribute item is null
last = head = new Node<E>(null);
}
/**
* Linked list node class
*/
static class Node<E> {
E item;
Node<E> next;
Node(E x) { item = x; }
}
Lock related. Two groups of locks correspond to (take, poll) and (put, offer) operations respectively
/** Lock held by take, poll, etc */
private final ReentrantLock takeLock = new ReentrantLock();
/** Wait queue for waiting takes */
private final Condition notEmpty = takeLock.newCondition();
/** Lock held by put, offer, etc */
private final ReentrantLock putLock = new ReentrantLock();
/** Wait queue for waiting puts */
private final Condition notFull = putLock.newCondition();
Compared with ArrayBlockingQueue, it can be found that only one lock is used in ArrayBlockingQueue. Adding and removing the shared lock for concurrency control, so the two operations are mutually exclusive and cannot be carried out at the same time. The LinkedBlockingQueue uses takeLock and putLock to control concurrency. Add and delete operations can be carried out at the same time, so the throughput is greatly improved. As a result, LinkedBlockingQueue has poor predictable performance in most concurrent applications.
As for the implementation schematic diagram of LinkedBlockingQueue, it is similar to ArrayBlockingQueue. In addition to using separate lock control for add and remove methods, they both use different Condition condition objects as waiting queues to suspend take threads and put threads.
However, if no capacity size is specified for LinkedBlockingQueue, its default value will be Integer.MAX_VALUE. If the adding speed is faster than the deleting speed, there may be memory overflow. Please consider this carefully before using.
Understand the application of the two locks by observing the queue in and out operations:
public boolean offer(E e, long timeout, TimeUnit unit)
throws InterruptedException {
if (e == null) throw new NullPointerException();
long nanos = unit.toNanos(timeout);
int c = -1;
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
putLock.lockInterruptibly();
try {
while (count.get() == capacity) {
if (nanos <= 0)
return false;
nanos = notFull.awaitNanos(nanos);
}
enqueue(new Node<E>(e));
c = count.getAndIncrement();
// Doubt 1
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
// Doubt point 2
if (c == 0)
signalNotEmpty();
return true;
}
private void enqueue(Node<E> node) {
// assert putLock.isHeldByCurrentThread();
// assert last.next == null;
last = last.next = node;
}
The logic is relatively simple. Thread queue operation enqueue analysis. Here, steal A diagram to see the process of putting element A and element B in the queue in turn. As mentioned earlier, the head node of the queue is A pseudo node with null item.
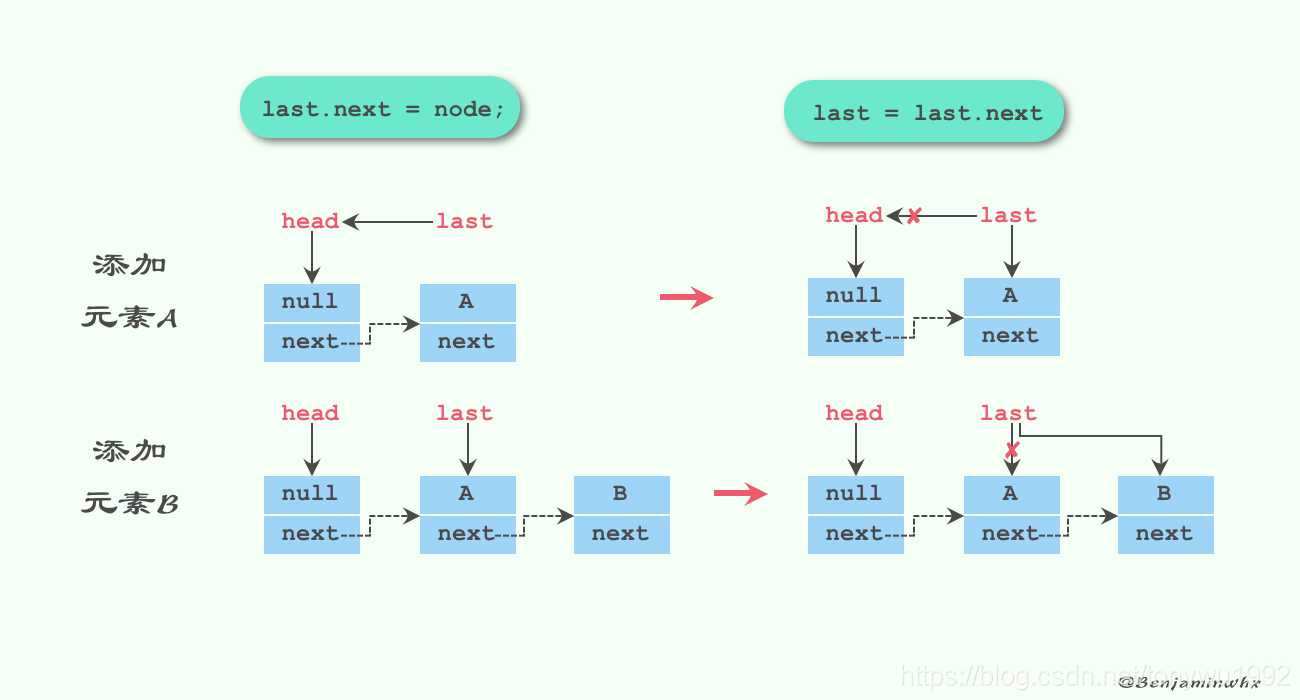 There are two main doubts about the offer method:
There are two main doubts about the offer method:
- Why continue to wake up the add thread on the condition object notFull after the addition is completed?
In the ArrayBlockingQueue, after adding, it will not check whether the queue capacity is full again, so as to continue to wake up other adding threads. This is because the adding and removing operations of ArrayBlockingQueue are controlled by the same lock and mutually exclusive, that is, the number of elements will not be reduced during the adding process, so there is no need to wake up other adding threads. Similarly, other adding threads cannot be awakened after adding, which will cause the lock contention behavior between adding threads and consuming threads, which may lead to never being able to consume.
In LinkedBlockingQueue, add and remove operations can be performed simultaneously without mutual exclusion. You will see later that in the removal method, the added thread will wake up only when the queue is full, and the removal operation will wake up other removal threads by itself, which means that multiple removal operations may be performed and only one wake-up is performed, so self wake-up is very necessary.
So why does the remove operation wake up the add thread only when the queue is full? First, the wake-up needs to be locked, which can reduce the number of locks. Second, normally, when the queue is full, there may be multiple add threads such as a and B blocking. After removing thread a wakes up one a, the other remove thread B that subsequently wakes up will not actively wake up add thread B if it works first. After judging that the queue is dissatisfied, but the self wake-up mechanism of adding thread a will wake up B. therefore, on the whole, Perform their respective duties and improve the throughput.
- Why wake up the consuming thread when judging if (c == 0)?
After the consumption thread is awakened, it will wake itself up and consume all the time on the premise that there is data in the queue. Therefore, the value of c is always changing. The value of c is the size of the queue before adding elements. At this time, c can only be 0 or c > 0. If c=0, it indicates that the previous consumption thread has stopped and there may be waiting consumption threads on the condition object, After adding data, wake up the consumption thread directly. If c > 0, the consumption thread will not wake up and can only wait for the call of the next consumption operation (poll, take, remove). Why not wake up when c > 0? What we need to understand is that once the consumer thread is awakened, it will wake up other consumer threads like the added thread. If c > 0 before adding, it is likely that the data has not been consumed since the consumer thread was called last time, and there are no waiting consumer threads in the condition queue. Therefore, it is not of great significance to wake up the consumer thread with c > 0.
So far, learning LinkedBlockingQueue is mainly about the use of locks and the processing of concurrency. The follow-up will not be in-depth.
public E poll(long timeout, TimeUnit unit) throws InterruptedException {
E x = null;
int c = -1;
long nanos = unit.toNanos(timeout);
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly();
try {
while (count.get() == 0) {
if (nanos <= 0)
return null;
nanos = notEmpty.awaitNanos(nanos);
}
x = dequeue();
c = count.getAndDecrement();
if (c > 1)
notEmpty.signal();
} finally {
takeLock.unlock();
}
if (c == capacity)
signalNotFull();
return x;
}
private E dequeue() {
// assert takeLock.isHeldByCurrentThread();
// assert head.item == null;
Node<E> h = head;
Node<E> first = h.next;
h.next = h; // help GC
head = first;
E x = first.item;
first.item = null;
return x;
}
LinkedBlockingQueue is very different from ArrayBlockingQueue
Through the above analysis, we are familiar with the basic use and internal implementation principles of LinkedBlockingQueue and ArrayBlockingQueue. Here we will summarize their differences
-
The queue size is different. ArrayBlockingQueue is bounded. The initialization must specify the size, while LinkedBlockingQueue can be bounded or unbounded (Integer.MAX_VALUE). For the latter, when the addition speed is faster than the removal speed, problems such as memory overflow may occur in the case of unbounded.
-
Different from data storage containers, ArrayBlockingQueue uses arrays as data storage containers, while LinkedBlockingQueue uses linked lists with Node nodes as connection objects.
-
Because ArrayBlockingQueue uses the storage container of array, no additional object instances will be generated or destroyed when inserting or deleting elements, while LinkedBlockingQueue will generate an additional Node object. This may have a great impact on GC when it is necessary to process large quantities of data efficiently and concurrently for a long time.
-
The locks added or removed in the queues implemented by ArrayBlockingQueue are different. The locks in the queues implemented by ArrayBlockingQueue are not separated, that is, the same reentrock lock is used for adding and removing operations, while the locks in the queues implemented by LinkedBlockingQueue are separated. putLock is used for adding and takeLock is used for removing, which can greatly improve the throughput of the queue, It also means that in the case of high concurrency, producers and consumers can operate the data in the queue in parallel, so as to improve the concurrency performance of the whole queue.