Thank you for your reference- http://bjbsair.com/2020-03-27/tech-info/7154/ The simplest way to accelerate the training of neural network is to use GPU. The speed of GPU in the normal operation (matrix multiplication and addition) of neural network is twice faster than that of CPU. As models or datasets grow larger, a GPU will soon become inadequate. For example, large language models such as BERT and GPT-2 are trained on hundreds of GPUs. For multi GPU training, a method of model and data segmentation and scheduling between different GPUs is needed.
Pytorch is a very popular deep learning framework, which has the best balance between flexibility and ease of use in the mainstream framework. There are two ways for Python to segment models and data on multiple GPUs: NN. DataParallel and nn.distributedataparallel. DataParallel is easier to use (simply wrap the single GPU model). However, since it uses a process to calculate model weights and then distribute them to each GPU during each batch, communication quickly becomes a bottleneck and GPU utilization is usually low. Moreover, nn.DataParallel requires all GPUs to be on the same node (distributed is not supported), and Apex cannot be used for mixed precision training. The main differences between NN. DataParallel and nn.distributedataparallel can be summarized as follows:
- DistributedDataParallel supports model parallelism, but DataParallel does not, which means that if the model is too large and the single card does not have enough memory, the former can only be used;
- DataParallel is single process and multi thread, only used for single card situation, while DistributedDataParallel is multi process, suitable for single machine and multi machine situation, and truly realizes distributed training;
- The training of distributed DataParallel is more efficient, because each process is an independent Python interpreter to avoid GIL problems, and its training speed is faster with low communication cost. Basically, DataParallel has been abandoned;
- It must be noted that each process in the distributed data parallel has its own optimizer, which performs its own update process, but the gradient is passed to each process through communication, and all executed contents are the same;
Generally speaking, the python document is quite complete and clear, especially after version 1.0x. However, there are few introductions about DistributedDataParallel. The main documents are as follows:
- Writing Distributed Applications with PyTorch: mainly introduces distributed API, distributed configuration, different communication mechanisms and internal mechanisms, but to be honest, most people don't agree to understand them, and they seldom use them directly;
- Getting Started with Distributed Data Parallel: it briefly introduces how to use distributed data parallel, but the use case is not clear and complete;
- ImageNet training in PyTorch: a relatively complete use case, but only code, lack of detailed description; (apex also provides a similar training case Mixed Precision ImageNet Training in PyTorch)
- (advanced) PyTorch 1.0 Distributed Trainer with Amazon AWS: how to conduct distributed training on Amazon cloud, but it is estimated that many people can't use it.
This tutorial will show you how to use PyTorch's distributed training with an example of MNISI. Here is a section of code for explanation, and it also includes any mixed precision training with apex.
Distributed data parallel internal mechanism
Distributed data parallel replicates models among multiple GPUs through multiple processes. Each GPU is controlled by one process (of course, each process can control multiple GPUs, but this is obviously slower than each process has one GPU; multiple processes can also run on one GPU). GPUs can be on the same node or distributed on multiple nodes. Each process performs the same tasks, and each process communicates with all other processes. Process or GPU only transfer gradient, so network communication is no longer the bottleneck.
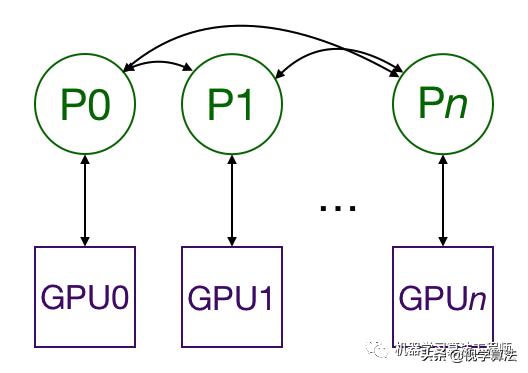
During training, each process loads batch data from disk and passes them to its GPU. Each GPU has its own forward process, and then the gradient performs all reduce among GPUs. The gradient of each layer does not depend on the previous layer, so all reduce and backward process of the gradient are calculated at the same time to further alleviate the network bottleneck. At the end of the backward process, each node gets an average gradient, so that the model parameters keep synchronous.
This requires multiple processes (possibly on multiple nodes) to synchronize and communicate. Python does this through the distributed. Init? Process? Group function. He needs to know the location of process 0 so that all processes can be synchronized, as well as the expected total number of processes. Each process needs to know the total number of processes, their order in the process, and which GPU to use. Generally, the total number of processes is called world_size.python. nn.utils.data.DistributedSampler is provided to segment data for each process to ensure that the training data does not overlap.
Example explanation
This is explained by an example of MNIST. We first change it to distributed training, and then add hybrid precision training.
Ordinary single card training
First, import the required libraries:
import os from datetime import datetime import argparse import torch.multiprocessing as mp import torchvision import torchvision.transforms as transforms import torch import torch.nn as nn import torch.distributed as dist from apex.parallel import DistributedDataParallel as DDP from apex import amp
Then we define a simple CNN model to process MNIST data:
class ConvNet(nn.Module): def __init__(self, num_classes=10): super(ConvNet, self).__init__() self.layer1 = nn.Sequential( nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(16), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.layer2 = nn.Sequential( nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(32), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.fc = nn.Linear(7*7*32, num_classes) def forward(self, x): out = self.layer1(x) out = self.layer2(out) out = out.reshape(out.size(0), -1) out = self.fc(out) return out
The main function main() takes parameters and performs training:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() train(0, args)
The main function of the training part is:
def train(gpu, args): torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Data loading code train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True) train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True) start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() loss.backward() optimizer.step() if (i + 1) % 100 == 0 and gpu == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format( epoch + 1, args.epochs, i + 1, total_step, loss.item()) ) if gpu == 0: print("Training complete in: " + str(datetime.now() - start))
Start training by starting the main function:
if __name__ == '__main__': main()
You may notice that some parameters are redundant, but they are useful for later distributed training. We can train on a single stand-alone card by executing the following statements:
python src/mnist.py -n 1 -g 1 -nr 0
Distributed training
Using multi process for distributed training, we need to start a process for each GPU. Each process needs to know which GPU it is running on and its sequence number in all processes. For multiple nodes, we need to start scripts at each node.
First, we need to configure the basic parameters:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() ######################################################### args.world_size = args.gpus * args.nodes # os.environ['MASTER_ADDR'] = '10.57.23.164' # os.environ['MASTER_PORT'] = '8888' # mp.spawn(train, nprocs=args.gpus, args=(args,)) # #########################################################
Where args.nodes is the total number of nodes, while args.gpus is the total number of GPU per node (the number of GPU per node is the same), and args.nr is the serial number of the current node at all nodes. The total number of nodes multiplied by the number of GPUs of each node can get the world_size, that is, the total number of processes. All processes need to know the IP address and port of process 0, so that all processes can be synchronized at the beginning. Generally speaking, process 0 is the master process. For example, we will print information or save models in process 0. PyTorch provides mp.spawn to start all processes of the node at a node. Each process runs train(i, args), where i goes from 0 to args.gpus - 1.
Similarly, we need to modify the training function:
def train(gpu, args): ############################################################ rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank ) ############################################################ torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) ############################################################### # Wrap the model model = nn.parallel.DistributedDataParallel(model, device_ids=[gpu]) ############################################################### # Data loading code train_dataset = torchvision.datasets.MNIST( root='./data', train=True, transform=transforms.ToTensor(), download=True ) ################################################################ train_sampler = torch.utils.data.distributed.DistributedSampler( train_dataset, num_replicas=args.world_size, rank=rank ) ################################################################ train_loader = torch.utils.data.DataLoader( dataset=train_dataset, batch_size=batch_size, ############################## shuffle=False, # ############################## num_workers=0, pin_memory=True, ############################# sampler=train_sampler) # ############################# ...
Here we first calculate the forward program number: rank = args.nr * args.gpus + gpu, and then initialize the distributed environment through dist.init process group, where the backend parameter specifies the communication backend, including mpi, gloo, nccl. Here, nccl is selected, which is the official multi card communication framework provided by Nvidia, which is relatively efficient. MPI is also a common communication protocol for high-performance computing, but you need to install your own MPI implementation framework, such as OpenMPI. gloo is built-in communication backend, but it is not efficient enough. Init? Method refers to how to initialize to complete the process synchronization at the beginning; here we set env: / /, which refers to the initialization mode of environment variables. Four parameters need to be configured in the environment variables: Master ﹐ port, master ﹐ addr, world ﹐ size, rank. The first two parameters have been configured. The last two parameters can also be configured through the world ﹐ size and rank parameters in the dist.init ﹐ process ﹐ group function. Other initialization methods include shared file system and TCP, such as init method = tcp://10.1.1.20:23456 ', which also provides the IP address and port of the master. Note that this call is blocked and must wait for all processes to synchronize. If any process fails, it will fail.
For the model side, we just need to wrap the original model with distributed data parallel, which will support gradient all reduce operation. For the data side, we nn.utils.data.DistributedSampler to segment data for each process, just use this sampler in dataloader. It is worth noting that you need to call train train ﹐ sampler.set ﹐ epoch (epoch) at the beginning of each epoch in the cyclic process (mainly to ensure that the partition of each epoch is different). Other training codes remain unchanged.
Finally, the code can be executed. For example, if we are a 4-node and each node is an 8-card, we need to execute the code on four nodes respectively:
python src/mnist-distributed.py -n 4 -g 8 -nr i
It should be noted that the effective batch size at this time is actually batch size per GPU * world size. For models with BN, synchronous BN can also be used to achieve better results:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
The distributed training process described above is also applicable to the evaluation or test process. For example, we can divide the data into different processes for prediction, which can accelerate the prediction process. The implementation code is exactly the same as the above process, but if we want to calculate an indicator, we need to perform all reduce from the statistical results of each process, because each process is only the content of the calculated part of the data. For example, if we want to calculate the classification accuracy, we can count the total data of each process and the number of correctly classified counts, and then aggregate them. The point to be mentioned here is that when using dist.init ﹣ process ﹣ group to initialize the distributed environment, it is actually to establish a default distributed process group, which will also initialize the torch.distributed package of Python. In this way, we can directly use the torch.distributed API to perform basic distributed operations. The following is the specific implementation:
# define tensor on GPU, count and total is the result at each GPU t = torch.tensor([count, total], dtype=torch.float64, device='cuda') dist.barrier() # synchronizes all processes dist.all_reduce(t, op=torch.distributed.ReduceOp.SUM,) # Reduces the tensor data across all machines in such a way that all get the final result. t = t.tolist() all_count = int(t[0]) all_total = int(t[1]) acc = all_count / all_total
Mixed precision training (with apex)
Hybrid precision training (hybrid FP32 and FP16 training) can be applied to larger batch size, and can use NVIDIA Tensor Cores to accelerate calculation. Using NVIDIA's apex for hybrid precision training is very simple, only part of the code needs to be modified:
rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank) torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Wrap the model ############################################################## model, optimizer = amp.initialize(model, optimizer, opt_level='O2') model = DDP(model) ############################################################## # Data loading code ... start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() ############################################################## with amp.scale_loss(loss, optimizer) as scaled_loss: scaled_loss.backward() ############################################################## optimizer.step() ...
In fact, there are two changes. First, amp.initialize is used to package model and optimizer to support mixed precision training, in which opt'u level refers to the optimization level. If O0 or O3 is not the real mixed precision, but it can be used to determine the baseline of model effect and speed, and O1 and O2 are two settings of mixed precision, and one can be selected for mixed precision training. The other is that before updating the parameters according to the gradient, the gradient should be scaled through amp.scale'loss to prevent underflow. In addition, you can replace nn.DistributedDataParallel with apex.parallel.DistributedDataParallel.
Digression
I think the official distributed implementation of PyTorch has been relatively perfect, and the performance and effect are good. The alternative is horovod. It supports not only PyTorch but also TensorFlow and MXNet framework. It is easy to implement, and the speed should be comparable.
Reference resources
- Distributed data parallel training in Pytorch https://yangkky.github.io/2019/07/08/distributed-pytorch-tutorial.html (most content comes from here)
- torch.distributed Https://python.org/docs/stable/distributed.html thank you for your reference - http://bjbsair.com/2020-03-27/tech-info/7154/ The simplest way to accelerate the training of neural network is to use GPU. The speed of GPU in the normal operation (matrix multiplication and addition) of neural network is twice faster than that of CPU. As models or datasets grow larger, a GPU will soon become inadequate. For example, large language models such as BERT and GPT-2 are trained on hundreds of GPUs. For multi GPU training, a method of model and data segmentation and scheduling between different GPUs is needed.
Pytorch is a very popular deep learning framework, which has the best balance between flexibility and ease of use in the mainstream framework. There are two ways for Python to segment models and data on multiple GPUs: NN. DataParallel and nn.distributedataparallel. DataParallel is easier to use (simply wrap the single GPU model). However, since it uses a process to calculate model weights and then distribute them to each GPU during each batch, communication quickly becomes a bottleneck and GPU utilization is usually low. Moreover, nn.DataParallel requires all GPUs to be on the same node (distributed is not supported), and Apex cannot be used for mixed precision training. The main differences between NN. DataParallel and nn.distributedataparallel can be summarized as follows:
- DistributedDataParallel supports model parallelism, but DataParallel does not, which means that if the model is too large and the single card does not have enough memory, the former can only be used;
- DataParallel is single process and multi thread, only used for single card situation, while DistributedDataParallel is multi process, suitable for single machine and multi machine situation, and truly realizes distributed training;
- The training of distributed DataParallel is more efficient, because each process is an independent Python interpreter to avoid GIL problems, and its training speed is faster with low communication cost. Basically, DataParallel has been abandoned;
- It must be noted that each process in the distributed data parallel has its own optimizer, which performs its own update process, but the gradient is passed to each process through communication, and all executed contents are the same;
Generally speaking, the python document is quite complete and clear, especially after version 1.0x. However, there are few introductions about DistributedDataParallel. The main documents are as follows:
- Writing Distributed Applications with PyTorch: mainly introduces distributed API, distributed configuration, different communication mechanisms and internal mechanisms, but to be honest, most people don't agree to understand them, and they seldom use them directly;
- Getting Started with Distributed Data Parallel: it briefly introduces how to use distributed data parallel, but the use case is not clear and complete;
- ImageNet training in PyTorch: a relatively complete use case, but only code, lack of detailed description; (apex also provides a similar training case Mixed Precision ImageNet Training in PyTorch)
- (advanced) PyTorch 1.0 Distributed Trainer with Amazon AWS: how to conduct distributed training on Amazon cloud, but it is estimated that many people can't use it.
This tutorial will show you how to use PyTorch's distributed training with an example of MNISI. Here is a section of code for explanation, and it also includes any mixed precision training with apex.
Distributed data parallel internal mechanism
Distributed data parallel replicates models among multiple GPUs through multiple processes. Each GPU is controlled by one process (of course, each process can control multiple GPUs, but this is obviously slower than each process has one GPU; multiple processes can also run on one GPU). GPUs can be on the same node or distributed on multiple nodes. Each process performs the same tasks, and each process communicates with all other processes. Process or GPU only transfer gradient, so network communication is no longer the bottleneck.
During training, each process loads batch data from disk and passes them to its GPU. Each GPU has its own forward process, and then the gradient performs all reduce among GPUs. The gradient of each layer does not depend on the previous layer, so all reduce and backward process of the gradient are calculated at the same time to further alleviate the network bottleneck. At the end of the backward process, each node gets an average gradient, so that the model parameters keep synchronous.
This requires multiple processes (possibly on multiple nodes) to synchronize and communicate. Python does this through the distributed. Init? Process? Group function. He needs to know the location of process 0 so that all processes can be synchronized, as well as the expected total number of processes. Each process needs to know the total number of processes, their order in the process, and which GPU to use. Generally, the total number of processes is called world_size.python. nn.utils.data.DistributedSampler is provided to segment data for each process to ensure that the training data does not overlap.
Example explanation
This is explained by an example of MNIST. We first change it to distributed training, and then add hybrid precision training.
Ordinary single card training
First, import the required libraries:
import os from datetime import datetime import argparse import torch.multiprocessing as mp import torchvision import torchvision.transforms as transforms import torch import torch.nn as nn import torch.distributed as dist from apex.parallel import DistributedDataParallel as DDP from apex import amp
Then we define a simple CNN model to process MNIST data:
class ConvNet(nn.Module): def __init__(self, num_classes=10): super(ConvNet, self).__init__() self.layer1 = nn.Sequential( nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(16), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.layer2 = nn.Sequential( nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(32), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.fc = nn.Linear(7*7*32, num_classes) def forward(self, x): out = self.layer1(x) out = self.layer2(out) out = out.reshape(out.size(0), -1) out = self.fc(out) return out
The main function main() takes parameters and performs training:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() train(0, args)
The main function of the training part is:
def train(gpu, args): torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Data loading code train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True) train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True) start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() loss.backward() optimizer.step() if (i + 1) % 100 == 0 and gpu == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format( epoch + 1, args.epochs, i + 1, total_step, loss.item()) ) if gpu == 0: print("Training complete in: " + str(datetime.now() - start))
Start training by starting the main function:
if __name__ == '__main__': main()
You may notice that some parameters are redundant, but they are useful for later distributed training. We can train on a single stand-alone card by executing the following statements:
python src/mnist.py -n 1 -g 1 -nr 0
Distributed training
Using multi process for distributed training, we need to start a process for each GPU. Each process needs to know which GPU it is running on and its sequence number in all processes. For multiple nodes, we need to start scripts at each node.
First, we need to configure the basic parameters:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() ######################################################### args.world_size = args.gpus * args.nodes # os.environ['MASTER_ADDR'] = '10.57.23.164' # os.environ['MASTER_PORT'] = '8888' # mp.spawn(train, nprocs=args.gpus, args=(args,)) # #########################################################
Where args.nodes is the total number of nodes, while args.gpus is the total number of GPU per node (the number of GPU per node is the same), and args.nr is the serial number of the current node at all nodes. The total number of nodes multiplied by the number of GPUs of each node can get the world_size, that is, the total number of processes. All processes need to know the IP address and port of process 0, so that all processes can be synchronized at the beginning. Generally speaking, process 0 is the master process. For example, we will print information or save models in process 0. PyTorch provides mp.spawn to start all processes of the node at a node. Each process runs train(i, args), where i goes from 0 to args.gpus - 1.
Similarly, we need to modify the training function:
def train(gpu, args): ############################################################ rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank ) ############################################################ torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) ############################################################### # Wrap the model model = nn.parallel.DistributedDataParallel(model, device_ids=[gpu]) ############################################################### # Data loading code train_dataset = torchvision.datasets.MNIST( root='./data', train=True, transform=transforms.ToTensor(), download=True ) ################################################################ train_sampler = torch.utils.data.distributed.DistributedSampler( train_dataset, num_replicas=args.world_size, rank=rank ) ################################################################ train_loader = torch.utils.data.DataLoader( dataset=train_dataset, batch_size=batch_size, ############################## shuffle=False, # ############################## num_workers=0, pin_memory=True, ############################# sampler=train_sampler) # ############################# ...
Here we first calculate the forward program number: rank = args.nr * args.gpus + gpu, and then initialize the distributed environment through dist.init process group, where the backend parameter specifies the communication backend, including mpi, gloo, nccl. Here, nccl is selected, which is the official multi card communication framework provided by Nvidia, which is relatively efficient. MPI is also a common communication protocol for high-performance computing, but you need to install your own MPI implementation framework, such as OpenMPI. gloo is built-in communication backend, but it is not efficient enough. Init? Method refers to how to initialize to complete the process synchronization at the beginning; here we set env: / /, which refers to the initialization mode of environment variables. Four parameters need to be configured in the environment variables: Master ﹐ port, master ﹐ addr, world ﹐ size, rank. The first two parameters have been configured. The last two parameters can also be configured through the world ﹐ size and rank parameters in the dist.init ﹐ process ﹐ group function. Other initialization methods include shared file system and TCP, such as init method = tcp://10.1.1.20:23456 ', which also provides the IP address and port of the master. Note that this call is blocked and must wait for all processes to synchronize. If any process fails, it will fail.
For the model side, we just need to wrap the original model with distributed data parallel, which will support gradient all reduce operation. For the data side, we nn.utils.data.DistributedSampler to segment data for each process, just use this sampler in dataloader. It is worth noting that you need to call train train ﹐ sampler.set ﹐ epoch (epoch) at the beginning of each epoch in the cyclic process (mainly to ensure that the partition of each epoch is different). Other training codes remain unchanged.
Finally, the code can be executed. For example, if we are a 4-node and each node is an 8-card, we need to execute the code on four nodes respectively:
python src/mnist-distributed.py -n 4 -g 8 -nr i
It should be noted that the effective batch size at this time is actually batch size per GPU * world size. For models with BN, synchronous BN can also be used to achieve better results:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
The distributed training process described above is also applicable to the evaluation or test process. For example, we can divide the data into different processes for prediction, which can accelerate the prediction process. The implementation code is exactly the same as the above process, but if we want to calculate an indicator, we need to perform all reduce from the statistical results of each process, because each process is only the content of the calculated part of the data. For example, if we want to calculate the classification accuracy, we can count the total data of each process and the number of correctly classified counts, and then aggregate them. The point to be mentioned here is that when using dist.init ﹣ process ﹣ group to initialize the distributed environment, it is actually to establish a default distributed process group, which will also initialize the torch.distributed package of Python. In this way, we can directly use the torch.distributed API to perform basic distributed operations. The following is the specific implementation:
# define tensor on GPU, count and total is the result at each GPU t = torch.tensor([count, total], dtype=torch.float64, device='cuda') dist.barrier() # synchronizes all processes dist.all_reduce(t, op=torch.distributed.ReduceOp.SUM,) # Reduces the tensor data across all machines in such a way that all get the final result. t = t.tolist() all_count = int(t[0]) all_total = int(t[1]) acc = all_count / all_total
Mixed precision training (with apex)
Hybrid precision training (hybrid FP32 and FP16 training) can be applied to larger batch size, and can use NVIDIA Tensor Cores to accelerate calculation. Using NVIDIA's apex for hybrid precision training is very simple, only part of the code needs to be modified:
rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank) torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Wrap the model ############################################################## model, optimizer = amp.initialize(model, optimizer, opt_level='O2') model = DDP(model) ############################################################## # Data loading code ... start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() ############################################################## with amp.scale_loss(loss, optimizer) as scaled_loss: scaled_loss.backward() ############################################################## optimizer.step() ...
In fact, there are two changes. First, amp.initialize is used to package model and optimizer to support mixed precision training, in which opt'u level refers to the optimization level. If O0 or O3 is not the real mixed precision, but it can be used to determine the baseline of model effect and speed, and O1 and O2 are two settings of mixed precision, and one can be selected for mixed precision training. The other is that before updating the parameters according to the gradient, the gradient should be scaled through amp.scale'loss to prevent underflow. In addition, you can replace nn.DistributedDataParallel with apex.parallel.DistributedDataParallel.
Digression
I think the official distributed implementation of PyTorch has been relatively perfect, and the performance and effect are good. The alternative is horovod. It supports not only PyTorch but also TensorFlow and MXNet framework. It is easy to implement, and the speed should be comparable.
Reference resources
- Distributed data parallel training in Pytorch https://yangkky.github.io/2019/07/08/distributed-pytorch-tutorial.html (most content comes from here)
- torch.distributed Https://python.org/docs/stable/distributed.html thank you for your reference - http://bjbsair.com/2020-03-27/tech-info/7154/ The simplest way to accelerate the training of neural network is to use GPU. The speed of GPU in the normal operation (matrix multiplication and addition) of neural network is twice faster than that of CPU. As models or datasets grow larger, a GPU will soon become inadequate. For example, large language models such as BERT and GPT-2 are trained on hundreds of GPUs. For multi GPU training, a method of model and data segmentation and scheduling between different GPUs is needed.
Pytorch is a very popular deep learning framework, which has the best balance between flexibility and ease of use in the mainstream framework. There are two ways for Python to segment models and data on multiple GPUs: NN. DataParallel and nn.distributedataparallel. DataParallel is easier to use (simply wrap the single GPU model). However, since it uses a process to calculate model weights and then distribute them to each GPU during each batch, communication quickly becomes a bottleneck and GPU utilization is usually low. Moreover, nn.DataParallel requires all GPUs to be on the same node (distributed is not supported), and Apex cannot be used for mixed precision training. The main differences between NN. DataParallel and nn.distributedataparallel can be summarized as follows:
- DistributedDataParallel supports model parallelism, but DataParallel does not, which means that if the model is too large and the single card does not have enough memory, the former can only be used;
- DataParallel is single process and multi thread, only used for single card situation, while DistributedDataParallel is multi process, suitable for single machine and multi machine situation, and truly realizes distributed training;
- The training of distributed DataParallel is more efficient, because each process is an independent Python interpreter to avoid GIL problems, and its training speed is faster with low communication cost. Basically, DataParallel has been abandoned;
- It must be noted that each process in the distributed data parallel has its own optimizer, which performs its own update process, but the gradient is passed to each process through communication, and all executed contents are the same;
Generally speaking, the python document is quite complete and clear, especially after version 1.0x. However, there are few introductions about DistributedDataParallel. The main documents are as follows:
- Writing Distributed Applications with PyTorch: mainly introduces distributed API, distributed configuration, different communication mechanisms and internal mechanisms, but to be honest, most people don't agree to understand them, and they seldom use them directly;
- Getting Started with Distributed Data Parallel: it briefly introduces how to use distributed data parallel, but the use case is not clear and complete;
- ImageNet training in PyTorch: a relatively complete use case, but only code, lack of detailed description; (apex also provides a similar training case Mixed Precision ImageNet Training in PyTorch)
- (advanced) PyTorch 1.0 Distributed Trainer with Amazon AWS: how to conduct distributed training on Amazon cloud, but it is estimated that many people can't use it.
This tutorial will show you how to use PyTorch's distributed training with an example of MNISI. Here is a section of code for explanation, and it also includes any mixed precision training with apex.
Distributed data parallel internal mechanism
Distributed data parallel replicates models among multiple GPUs through multiple processes. Each GPU is controlled by one process (of course, each process can control multiple GPUs, but this is obviously slower than each process has one GPU; multiple processes can also run on one GPU). GPUs can be on the same node or distributed on multiple nodes. Each process performs the same tasks, and each process communicates with all other processes. Process or GPU only transfer gradient, so network communication is no longer the bottleneck.
During training, each process loads batch data from disk and passes them to its GPU. Each GPU has its own forward process, and then the gradient performs all reduce among GPUs. The gradient of each layer does not depend on the previous layer, so all reduce and backward process of the gradient are calculated at the same time to further alleviate the network bottleneck. At the end of the backward process, each node gets an average gradient, so that the model parameters keep synchronous.
This requires multiple processes (possibly on multiple nodes) to synchronize and communicate. Python does this through the distributed. Init? Process? Group function. He needs to know the location of process 0 so that all processes can be synchronized, as well as the expected total number of processes. Each process needs to know the total number of processes, their order in the process, and which GPU to use. Generally, the total number of processes is called world_size.python. nn.utils.data.DistributedSampler is provided to segment data for each process to ensure that the training data does not overlap.
Example explanation
This is explained by an example of MNIST. We first change it to distributed training, and then add hybrid precision training.
Ordinary single card training
First, import the required libraries:
import os from datetime import datetime import argparse import torch.multiprocessing as mp import torchvision import torchvision.transforms as transforms import torch import torch.nn as nn import torch.distributed as dist from apex.parallel import DistributedDataParallel as DDP from apex import amp
Then we define a simple CNN model to process MNIST data:
class ConvNet(nn.Module): def __init__(self, num_classes=10): super(ConvNet, self).__init__() self.layer1 = nn.Sequential( nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(16), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.layer2 = nn.Sequential( nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(32), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.fc = nn.Linear(7*7*32, num_classes) def forward(self, x): out = self.layer1(x) out = self.layer2(out) out = out.reshape(out.size(0), -1) out = self.fc(out) return out
The main function main() takes parameters and performs training:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() train(0, args)
The main function of the training part is:
def train(gpu, args): torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Data loading code train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True) train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True) start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() loss.backward() optimizer.step() if (i + 1) % 100 == 0 and gpu == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format( epoch + 1, args.epochs, i + 1, total_step, loss.item()) ) if gpu == 0: print("Training complete in: " + str(datetime.now() - start))
Start training by starting the main function:
if __name__ == '__main__': main()
You may notice that some parameters are redundant, but they are useful for later distributed training. We can train on a single stand-alone card by executing the following statements:
python src/mnist.py -n 1 -g 1 -nr 0
Distributed training
Using multi process for distributed training, we need to start a process for each GPU. Each process needs to know which GPU it is running on and its sequence number in all processes. For multiple nodes, we need to start scripts at each node.
First, we need to configure the basic parameters:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() ######################################################### args.world_size = args.gpus * args.nodes # os.environ['MASTER_ADDR'] = '10.57.23.164' # os.environ['MASTER_PORT'] = '8888' # mp.spawn(train, nprocs=args.gpus, args=(args,)) # #########################################################
Where args.nodes is the total number of nodes, while args.gpus is the total number of GPU per node (the number of GPU per node is the same), and args.nr is the serial number of the current node at all nodes. The total number of nodes multiplied by the number of GPUs of each node can get the world_size, that is, the total number of processes. All processes need to know the IP address and port of process 0, so that all processes can be synchronized at the beginning. Generally speaking, process 0 is the master process. For example, we will print information or save models in process 0. PyTorch provides mp.spawn to start all processes of the node at a node. Each process runs train(i, args), where i goes from 0 to args.gpus - 1.
Similarly, we need to modify the training function:
def train(gpu, args): ############################################################ rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank ) ############################################################ torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) ############################################################### # Wrap the model model = nn.parallel.DistributedDataParallel(model, device_ids=[gpu]) ############################################################### # Data loading code train_dataset = torchvision.datasets.MNIST( root='./data', train=True, transform=transforms.ToTensor(), download=True ) ################################################################ train_sampler = torch.utils.data.distributed.DistributedSampler( train_dataset, num_replicas=args.world_size, rank=rank ) ################################################################ train_loader = torch.utils.data.DataLoader( dataset=train_dataset, batch_size=batch_size, ############################## shuffle=False, # ############################## num_workers=0, pin_memory=True, ############################# sampler=train_sampler) # ############################# ...
Here we first calculate the forward program number: rank = args.nr * args.gpus + gpu, and then initialize the distributed environment through dist.init process group, where the backend parameter specifies the communication backend, including mpi, gloo, nccl. Here, nccl is selected, which is the official multi card communication framework provided by Nvidia, which is relatively efficient. MPI is also a common communication protocol for high-performance computing, but you need to install your own MPI implementation framework, such as OpenMPI. gloo is built-in communication backend, but it is not efficient enough. Init? Method refers to how to initialize to complete the process synchronization at the beginning; here we set env: / /, which refers to the initialization mode of environment variables. Four parameters need to be configured in the environment variables: Master ﹐ port, master ﹐ addr, world ﹐ size, rank. The first two parameters have been configured. The last two parameters can also be configured through the world ﹐ size and rank parameters in the dist.init ﹐ process ﹐ group function. Other initialization methods include shared file system and TCP, such as init method = tcp://10.1.1.20:23456 ', which also provides the IP address and port of the master. Note that this call is blocked and must wait for all processes to synchronize. If any process fails, it will fail.
For the model side, we just need to wrap the original model with distributed data parallel, which will support gradient all reduce operation. For the data side, we nn.utils.data.DistributedSampler to segment data for each process, just use this sampler in dataloader. It is worth noting that you need to call train train ﹐ sampler.set ﹐ epoch (epoch) at the beginning of each epoch in the cyclic process (mainly to ensure that the partition of each epoch is different). Other training codes remain unchanged.
Finally, the code can be executed. For example, if we are a 4-node and each node is an 8-card, we need to execute the code on four nodes respectively:
python src/mnist-distributed.py -n 4 -g 8 -nr i
It should be noted that the effective batch size at this time is actually batch size per GPU * world size. For models with BN, synchronous BN can also be used to achieve better results:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
The distributed training process described above is also applicable to the evaluation or test process. For example, we can divide the data into different processes for prediction, which can accelerate the prediction process. The implementation code is exactly the same as the above process, but if we want to calculate an indicator, we need to perform all reduce from the statistical results of each process, because each process is only the content of the calculated part of the data. For example, if we want to calculate the classification accuracy, we can count the total data of each process and the number of correctly classified counts, and then aggregate them. The point to be mentioned here is that when using dist.init ﹣ process ﹣ group to initialize the distributed environment, it is actually to establish a default distributed process group, which will also initialize the torch.distributed package of Python. In this way, we can directly use the torch.distributed API to perform basic distributed operations. The following is the specific implementation:
# define tensor on GPU, count and total is the result at each GPU t = torch.tensor([count, total], dtype=torch.float64, device='cuda') dist.barrier() # synchronizes all processes dist.all_reduce(t, op=torch.distributed.ReduceOp.SUM,) # Reduces the tensor data across all machines in such a way that all get the final result. t = t.tolist() all_count = int(t[0]) all_total = int(t[1]) acc = all_count / all_total
Mixed precision training (with apex)
Hybrid precision training (hybrid FP32 and FP16 training) can be applied to larger batch size, and can use NVIDIA Tensor Cores to accelerate calculation. Using NVIDIA's apex for hybrid precision training is very simple, only part of the code needs to be modified:
rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank) torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Wrap the model ############################################################## model, optimizer = amp.initialize(model, optimizer, opt_level='O2') model = DDP(model) ############################################################## # Data loading code ... start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() ############################################################## with amp.scale_loss(loss, optimizer) as scaled_loss: scaled_loss.backward() ############################################################## optimizer.step() ...
In fact, there are two changes. First, amp.initialize is used to package model and optimizer to support mixed precision training, in which opt'u level refers to the optimization level. If O0 or O3 is not the real mixed precision, but it can be used to determine the baseline of model effect and speed, and O1 and O2 are two settings of mixed precision, and one can be selected for mixed precision training. The other is that before updating the parameters according to the gradient, the gradient should be scaled through amp.scale'loss to prevent underflow. In addition, you can replace nn.DistributedDataParallel with apex.parallel.DistributedDataParallel.
Digression
I think the official distributed implementation of PyTorch has been relatively perfect, and the performance and effect are good. The alternative is horovod. It supports not only PyTorch but also TensorFlow and MXNet framework. It is easy to implement, and the speed should be comparable.
Reference resources
- Distributed data parallel training in Pytorch https://yangkky.github.io/2019/07/08/distributed-pytorch-tutorial.html (most content comes from here)
- torch.distributed Https://python.org/docs/stable/distributed.html thank you for your reference - http://bjbsair.com/2020-03-27/tech-info/7154/ The simplest way to accelerate the training of neural network is to use GPU. The speed of GPU in the normal operation (matrix multiplication and addition) of neural network is twice faster than that of CPU. As models or datasets grow larger, a GPU will soon become inadequate. For example, large language models such as BERT and GPT-2 are trained on hundreds of GPUs. For multi GPU training, a method of model and data segmentation and scheduling between different GPUs is needed.
Pytorch is a very popular deep learning framework, which has the best balance between flexibility and ease of use in the mainstream framework. There are two ways for Python to segment models and data on multiple GPUs: NN. DataParallel and nn.distributedataparallel. DataParallel is easier to use (simply wrap the single GPU model). However, since it uses a process to calculate model weights and then distribute them to each GPU during each batch, communication quickly becomes a bottleneck and GPU utilization is usually low. Moreover, nn.DataParallel requires all GPUs to be on the same node (distributed is not supported), and Apex cannot be used for mixed precision training. The main differences between NN. DataParallel and nn.distributedataparallel can be summarized as follows:
- DistributedDataParallel supports model parallelism, but DataParallel does not, which means that if the model is too large and the single card does not have enough memory, the former can only be used;
- DataParallel is single process and multi thread, only used for single card situation, while DistributedDataParallel is multi process, suitable for single machine and multi machine situation, and truly realizes distributed training;
- The training of distributed DataParallel is more efficient, because each process is an independent Python interpreter to avoid GIL problems, and its training speed is faster with low communication cost. Basically, DataParallel has been abandoned;
- It must be noted that each process in the distributed data parallel has its own optimizer, which performs its own update process, but the gradient is passed to each process through communication, and all executed contents are the same;
Generally speaking, the python document is quite complete and clear, especially after version 1.0x. However, there are few introductions about DistributedDataParallel. The main documents are as follows:
- Writing Distributed Applications with PyTorch: mainly introduces distributed API, distributed configuration, different communication mechanisms and internal mechanisms, but to be honest, most people don't agree to understand them, and they seldom use them directly;
- Getting Started with Distributed Data Parallel: it briefly introduces how to use distributed data parallel, but the use case is not clear and complete;
- ImageNet training in PyTorch: a relatively complete use case, but only code, lack of detailed description; (apex also provides a similar training case Mixed Precision ImageNet Training in PyTorch)
- (advanced) PyTorch 1.0 Distributed Trainer with Amazon AWS: how to conduct distributed training on Amazon cloud, but it is estimated that many people can't use it.
This tutorial will show you how to use PyTorch's distributed training with an example of MNISI. Here is a section of code for explanation, and it also includes any mixed precision training with apex.
Distributed data parallel internal mechanism
Distributed data parallel replicates models among multiple GPUs through multiple processes. Each GPU is controlled by one process (of course, each process can control multiple GPUs, but this is obviously slower than each process has one GPU; multiple processes can also run on one GPU). GPUs can be on the same node or distributed on multiple nodes. Each process performs the same tasks, and each process communicates with all other processes. Process or GPU only transfer gradient, so network communication is no longer the bottleneck.
During training, each process loads batch data from disk and passes them to its GPU. Each GPU has its own forward process, and then the gradient performs all reduce among GPUs. The gradient of each layer does not depend on the previous layer, so all reduce and backward process of the gradient are calculated at the same time to further alleviate the network bottleneck. At the end of the backward process, each node gets an average gradient, so that the model parameters keep synchronous.
This requires multiple processes (possibly on multiple nodes) to synchronize and communicate. Python does this through the distributed. Init? Process? Group function. He needs to know the location of process 0 so that all processes can be synchronized, as well as the expected total number of processes. Each process needs to know the total number of processes, their order in the process, and which GPU to use. Generally, the total number of processes is called world_size.python. nn.utils.data.DistributedSampler is provided to segment data for each process to ensure that the training data does not overlap.
Example explanation
This is explained by an example of MNIST. We first change it to distributed training, and then add hybrid precision training.
Ordinary single card training
First, import the required libraries:
import os from datetime import datetime import argparse import torch.multiprocessing as mp import torchvision import torchvision.transforms as transforms import torch import torch.nn as nn import torch.distributed as dist from apex.parallel import DistributedDataParallel as DDP from apex import amp
Then we define a simple CNN model to process MNIST data:
class ConvNet(nn.Module): def __init__(self, num_classes=10): super(ConvNet, self).__init__() self.layer1 = nn.Sequential( nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(16), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.layer2 = nn.Sequential( nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(32), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.fc = nn.Linear(7*7*32, num_classes) def forward(self, x): out = self.layer1(x) out = self.layer2(out) out = out.reshape(out.size(0), -1) out = self.fc(out) return out
The main function main() takes parameters and performs training:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() train(0, args)
The main function of the training part is:
def train(gpu, args): torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Data loading code train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True) train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True) start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() loss.backward() optimizer.step() if (i + 1) % 100 == 0 and gpu == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format( epoch + 1, args.epochs, i + 1, total_step, loss.item()) ) if gpu == 0: print("Training complete in: " + str(datetime.now() - start))
Start training by starting the main function:
if __name__ == '__main__': main()
You may notice that some parameters are redundant, but they are useful for later distributed training. We can train on a single stand-alone card by executing the following statements:
python src/mnist.py -n 1 -g 1 -nr 0
Distributed training
Using multi process for distributed training, we need to start a process for each GPU. Each process needs to know which GPU it is running on and its sequence number in all processes. For multiple nodes, we need to start scripts at each node.
First, we need to configure the basic parameters:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() ######################################################### args.world_size = args.gpus * args.nodes # os.environ['MASTER_ADDR'] = '10.57.23.164' # os.environ['MASTER_PORT'] = '8888' # mp.spawn(train, nprocs=args.gpus, args=(args,)) # #########################################################
Where args.nodes is the total number of nodes, while args.gpus is the total number of GPU per node (the number of GPU per node is the same), and args.nr is the serial number of the current node at all nodes. The total number of nodes multiplied by the number of GPUs of each node can get the world_size, that is, the total number of processes. All processes need to know the IP address and port of process 0, so that all processes can be synchronized at the beginning. Generally speaking, process 0 is the master process. For example, we will print information or save models in process 0. PyTorch provides mp.spawn to start all processes of the node at a node. Each process runs train(i, args), where i goes from 0 to args.gpus - 1.
Similarly, we need to modify the training function:
def train(gpu, args): ############################################################ rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank ) ############################################################ torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) ############################################################### # Wrap the model model = nn.parallel.DistributedDataParallel(model, device_ids=[gpu]) ############################################################### # Data loading code train_dataset = torchvision.datasets.MNIST( root='./data', train=True, transform=transforms.ToTensor(), download=True ) ################################################################ train_sampler = torch.utils.data.distributed.DistributedSampler( train_dataset, num_replicas=args.world_size, rank=rank ) ################################################################ train_loader = torch.utils.data.DataLoader( dataset=train_dataset, batch_size=batch_size, ############################## shuffle=False, # ############################## num_workers=0, pin_memory=True, ############################# sampler=train_sampler) # ############################# ...
Here we first calculate the forward program number: rank = args.nr * args.gpus + gpu, and then initialize the distributed environment through dist.init process group, where the backend parameter specifies the communication backend, including mpi, gloo, nccl. Here, nccl is selected, which is the official multi card communication framework provided by Nvidia, which is relatively efficient. MPI is also a common communication protocol for high-performance computing, but you need to install your own MPI implementation framework, such as OpenMPI. gloo is built-in communication backend, but it is not efficient enough. Init? Method refers to how to initialize to complete the process synchronization at the beginning; here we set env: / /, which refers to the initialization mode of environment variables. Four parameters need to be configured in the environment variables: Master ﹐ port, master ﹐ addr, world ﹐ size, rank. The first two parameters have been configured. The last two parameters can also be configured through the world ﹐ size and rank parameters in the dist.init ﹐ process ﹐ group function. Other initialization methods include shared file system and TCP, such as init method = tcp://10.1.1.20:23456 ', which also provides the IP address and port of the master. Note that this call is blocked and must wait for all processes to synchronize. If any process fails, it will fail.
For the model side, we just need to wrap the original model with distributed data parallel, which will support gradient all reduce operation. For the data side, we nn.utils.data.DistributedSampler to segment data for each process, just use this sampler in dataloader. It is worth noting that you need to call train train ﹐ sampler.set ﹐ epoch (epoch) at the beginning of each epoch in the cyclic process (mainly to ensure that the partition of each epoch is different). Other training codes remain unchanged.
Finally, the code can be executed. For example, if we are a 4-node and each node is an 8-card, we need to execute the code on four nodes respectively:
python src/mnist-distributed.py -n 4 -g 8 -nr i
It should be noted that the effective batch size at this time is actually batch size per GPU * world size. For models with BN, synchronous BN can also be used to achieve better results:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
The distributed training process described above is also applicable to the evaluation or test process. For example, we can divide the data into different processes for prediction, which can accelerate the prediction process. The implementation code is exactly the same as the above process, but if we want to calculate an indicator, we need to perform all reduce from the statistical results of each process, because each process is only the content of the calculated part of the data. For example, if we want to calculate the classification accuracy, we can count the total data of each process and the number of correctly classified counts, and then aggregate them. The point to be mentioned here is that when using dist.init ﹣ process ﹣ group to initialize the distributed environment, it is actually to establish a default distributed process group, which will also initialize the torch.distributed package of Python. In this way, we can directly use the torch.distributed API to perform basic distributed operations. The following is the specific implementation:
# define tensor on GPU, count and total is the result at each GPU t = torch.tensor([count, total], dtype=torch.float64, device='cuda') dist.barrier() # synchronizes all processes dist.all_reduce(t, op=torch.distributed.ReduceOp.SUM,) # Reduces the tensor data across all machines in such a way that all get the final result. t = t.tolist() all_count = int(t[0]) all_total = int(t[1]) acc = all_count / all_total
Mixed precision training (with apex)
Hybrid precision training (hybrid FP32 and FP16 training) can be applied to larger batch size, and can use NVIDIA Tensor Cores to accelerate calculation. Using NVIDIA's apex for hybrid precision training is very simple, only part of the code needs to be modified:
rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank) torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Wrap the model ############################################################## model, optimizer = amp.initialize(model, optimizer, opt_level='O2') model = DDP(model) ############################################################## # Data loading code ... start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() ############################################################## with amp.scale_loss(loss, optimizer) as scaled_loss: scaled_loss.backward() ############################################################## optimizer.step() ...
In fact, there are two changes. First, amp.initialize is used to package model and optimizer to support mixed precision training, in which opt'u level refers to the optimization level. If O0 or O3 is not the real mixed precision, but it can be used to determine the baseline of model effect and speed, and O1 and O2 are two settings of mixed precision, and one can be selected for mixed precision training. The other is that before updating the parameters according to the gradient, the gradient should be scaled through amp.scale'loss to prevent underflow. In addition, you can replace nn.DistributedDataParallel with apex.parallel.DistributedDataParallel.
Digression
I think the official distributed implementation of PyTorch has been relatively perfect, and the performance and effect are good. The alternative is horovod. It supports not only PyTorch but also TensorFlow and MXNet framework. It is easy to implement, and the speed should be comparable.
Reference resources
- Distributed data parallel training in Pytorch https://yangkky.github.io/2019/07/08/distributed-pytorch-tutorial.html (most content comes from here)
- torch.distributed Https://python.org/docs/stable/distributed.html thank you for your reference - http://bjbsair.com/2020-03-27/tech-info/7154/ The simplest way to accelerate the training of neural network is to use GPU. The speed of GPU in the normal operation (matrix multiplication and addition) of neural network is twice faster than that of CPU. As models or datasets grow larger, a GPU will soon become inadequate. For example, large language models such as BERT and GPT-2 are trained on hundreds of GPUs. For multi GPU training, a method of model and data segmentation and scheduling between different GPUs is needed.
Pytorch is a very popular deep learning framework, which has the best balance between flexibility and ease of use in the mainstream framework. There are two ways for Python to segment models and data on multiple GPUs: NN. DataParallel and nn.distributedataparallel. DataParallel is easier to use (simply wrap the single GPU model). However, since it uses a process to calculate model weights and then distribute them to each GPU during each batch, communication quickly becomes a bottleneck and GPU utilization is usually low. Moreover, nn.DataParallel requires all GPUs to be on the same node (distributed is not supported), and Apex cannot be used for mixed precision training. The main differences between NN. DataParallel and nn.distributedataparallel can be summarized as follows:
- DistributedDataParallel supports model parallelism, but DataParallel does not, which means that if the model is too large and the single card does not have enough memory, the former can only be used;
- DataParallel is single process and multi thread, only used for single card situation, while DistributedDataParallel is multi process, suitable for single machine and multi machine situation, and truly realizes distributed training;
- The training of distributed DataParallel is more efficient, because each process is an independent Python interpreter to avoid GIL problems, and its training speed is faster with low communication cost. Basically, DataParallel has been abandoned;
- It must be noted that each process in the distributed data parallel has its own optimizer, which performs its own update process, but the gradient is passed to each process through communication, and all executed contents are the same;
Generally speaking, the python document is quite complete and clear, especially after version 1.0x. However, there are few introductions about DistributedDataParallel. The main documents are as follows:
- Writing Distributed Applications with PyTorch: mainly introduces distributed API, distributed configuration, different communication mechanisms and internal mechanisms, but to be honest, most people don't agree to understand them, and they seldom use them directly;
- Getting Started with Distributed Data Parallel: it briefly introduces how to use distributed data parallel, but the use case is not clear and complete;
- ImageNet training in PyTorch: a relatively complete use case, but only code, lack of detailed description; (apex also provides a similar training case Mixed Precision ImageNet Training in PyTorch)
- (advanced) PyTorch 1.0 Distributed Trainer with Amazon AWS: how to conduct distributed training on Amazon cloud, but it is estimated that many people can't use it.
This tutorial will show you how to use PyTorch's distributed training with an example of MNISI. Here is a section of code for explanation, and it also includes any mixed precision training with apex.
Distributed data parallel internal mechanism
Distributed data parallel replicates models among multiple GPUs through multiple processes. Each GPU is controlled by one process (of course, each process can control multiple GPUs, but this is obviously slower than each process has one GPU; multiple processes can also run on one GPU). GPUs can be on the same node or distributed on multiple nodes. Each process performs the same tasks, and each process communicates with all other processes. Process or GPU only transfer gradient, so network communication is no longer the bottleneck.
During training, each process loads batch data from disk and passes them to its GPU. Each GPU has its own forward process, and then the gradient performs all reduce among GPUs. The gradient of each layer does not depend on the previous layer, so all reduce and backward process of the gradient are calculated at the same time to further alleviate the network bottleneck. At the end of the backward process, each node gets an average gradient, so that the model parameters keep synchronous.
This requires multiple processes (possibly on multiple nodes) to synchronize and communicate. Python does this through the distributed. Init? Process? Group function. He needs to know the location of process 0 so that all processes can be synchronized, as well as the expected total number of processes. Each process needs to know the total number of processes, their order in the process, and which GPU to use. Generally, the total number of processes is called world_size.python. nn.utils.data.DistributedSampler is provided to segment data for each process to ensure that the training data does not overlap.
Example explanation
This is explained by an example of MNIST. We first change it to distributed training, and then add hybrid precision training.
Ordinary single card training
First, import the required libraries:
import os from datetime import datetime import argparse import torch.multiprocessing as mp import torchvision import torchvision.transforms as transforms import torch import torch.nn as nn import torch.distributed as dist from apex.parallel import DistributedDataParallel as DDP from apex import amp
Then we define a simple CNN model to process MNIST data:
class ConvNet(nn.Module): def __init__(self, num_classes=10): super(ConvNet, self).__init__() self.layer1 = nn.Sequential( nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(16), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.layer2 = nn.Sequential( nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(32), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.fc = nn.Linear(7*7*32, num_classes) def forward(self, x): out = self.layer1(x) out = self.layer2(out) out = out.reshape(out.size(0), -1) out = self.fc(out) return out
The main function main() takes parameters and performs training:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() train(0, args)
The main function of the training part is:
def train(gpu, args): torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Data loading code train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True) train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True) start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() loss.backward() optimizer.step() if (i + 1) % 100 == 0 and gpu == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format( epoch + 1, args.epochs, i + 1, total_step, loss.item()) ) if gpu == 0: print("Training complete in: " + str(datetime.now() - start))
Start training by starting the main function:
if __name__ == '__main__': main()
You may notice that some parameters are redundant, but they are useful for later distributed training. We can train on a single stand-alone card by executing the following statements:
python src/mnist.py -n 1 -g 1 -nr 0
Distributed training
Using multi process for distributed training, we need to start a process for each GPU. Each process needs to know which GPU it is running on and its sequence number in all processes. For multiple nodes, we need to start scripts at each node.
First, we need to configure the basic parameters:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() ######################################################### args.world_size = args.gpus * args.nodes # os.environ['MASTER_ADDR'] = '10.57.23.164' # os.environ['MASTER_PORT'] = '8888' # mp.spawn(train, nprocs=args.gpus, args=(args,)) # #########################################################
Where args.nodes is the total number of nodes, while args.gpus is the total number of GPU per node (the number of GPU per node is the same), and args.nr is the serial number of the current node at all nodes. The total number of nodes multiplied by the number of GPUs of each node can get the world_size, that is, the total number of processes. All processes need to know the IP address and port of process 0, so that all processes can be synchronized at the beginning. Generally speaking, process 0 is the master process. For example, we will print information or save models in process 0. PyTorch provides mp.spawn to start all processes of the node at a node. Each process runs train(i, args), where i goes from 0 to args.gpus - 1.
Similarly, we need to modify the training function:
def train(gpu, args): ############################################################ rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank ) ############################################################ torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) ############################################################### # Wrap the model model = nn.parallel.DistributedDataParallel(model, device_ids=[gpu]) ############################################################### # Data loading code train_dataset = torchvision.datasets.MNIST( root='./data', train=True, transform=transforms.ToTensor(), download=True ) ################################################################ train_sampler = torch.utils.data.distributed.DistributedSampler( train_dataset, num_replicas=args.world_size, rank=rank ) ################################################################ train_loader = torch.utils.data.DataLoader( dataset=train_dataset, batch_size=batch_size, ############################## shuffle=False, # ############################## num_workers=0, pin_memory=True, ############################# sampler=train_sampler) # ############################# ...
Here we first calculate the forward program number: rank = args.nr * args.gpus + gpu, and then initialize the distributed environment through dist.init process group, where the backend parameter specifies the communication backend, including mpi, gloo, nccl. Here, nccl is selected, which is the official multi card communication framework provided by Nvidia, which is relatively efficient. MPI is also a common communication protocol for high-performance computing, but you need to install your own MPI implementation framework, such as OpenMPI. gloo is built-in communication backend, but it is not efficient enough. Init? Method refers to how to initialize to complete the process synchronization at the beginning; here we set env: / /, which refers to the initialization mode of environment variables. Four parameters need to be configured in the environment variables: Master ﹐ port, master ﹐ addr, world ﹐ size, rank. The first two parameters have been configured. The last two parameters can also be configured through the world ﹐ size and rank parameters in the dist.init ﹐ process ﹐ group function. Other initialization methods include shared file system and TCP, such as init method = tcp://10.1.1.20:23456 ', which also provides the IP address and port of the master. Note that this call is blocked and must wait for all processes to synchronize. If any process fails, it will fail.
For the model side, we just need to wrap the original model with distributed data parallel, which will support gradient all reduce operation. For the data side, we nn.utils.data.DistributedSampler to segment data for each process, just use this sampler in dataloader. It is worth noting that you need to call train train ﹐ sampler.set ﹐ epoch (epoch) at the beginning of each epoch in the cyclic process (mainly to ensure that the partition of each epoch is different). Other training codes remain unchanged.
Finally, the code can be executed. For example, if we are a 4-node and each node is an 8-card, we need to execute the code on four nodes respectively:
python src/mnist-distributed.py -n 4 -g 8 -nr i
It should be noted that the effective batch size at this time is actually batch size per GPU * world size. For models with BN, synchronous BN can also be used to achieve better results:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
The distributed training process described above is also applicable to the evaluation or test process. For example, we can divide the data into different processes for prediction, which can accelerate the prediction process. The implementation code is exactly the same as the above process, but if we want to calculate an indicator, we need to perform all reduce from the statistical results of each process, because each process is only the content of the calculated part of the data. For example, if we want to calculate the classification accuracy, we can count the total data of each process and the number of correctly classified counts, and then aggregate them. The point to be mentioned here is that when using dist.init ﹣ process ﹣ group to initialize the distributed environment, it is actually to establish a default distributed process group, which will also initialize the torch.distributed package of Python. In this way, we can directly use the torch.distributed API to perform basic distributed operations. The following is the specific implementation:
# define tensor on GPU, count and total is the result at each GPU t = torch.tensor([count, total], dtype=torch.float64, device='cuda') dist.barrier() # synchronizes all processes dist.all_reduce(t, op=torch.distributed.ReduceOp.SUM,) # Reduces the tensor data across all machines in such a way that all get the final result. t = t.tolist() all_count = int(t[0]) all_total = int(t[1]) acc = all_count / all_total
Mixed precision training (with apex)
Hybrid precision training (hybrid FP32 and FP16 training) can be applied to larger batch size, and can use NVIDIA Tensor Cores to accelerate calculation. Using NVIDIA's apex for hybrid precision training is very simple, only part of the code needs to be modified:
rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank) torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Wrap the model ############################################################## model, optimizer = amp.initialize(model, optimizer, opt_level='O2') model = DDP(model) ############################################################## # Data loading code ... start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() ############################################################## with amp.scale_loss(loss, optimizer) as scaled_loss: scaled_loss.backward() ############################################################## optimizer.step() ...
In fact, there are two changes. First, amp.initialize is used to package model and optimizer to support mixed precision training, in which opt'u level refers to the optimization level. If O0 or O3 is not the real mixed precision, but it can be used to determine the baseline of model effect and speed, and O1 and O2 are two settings of mixed precision, and one can be selected for mixed precision training. The other is that before updating the parameters according to the gradient, the gradient should be scaled through amp.scale'loss to prevent underflow. In addition, you can replace nn.DistributedDataParallel with apex.parallel.DistributedDataParallel.
Digression
I think the official distributed implementation of PyTorch has been relatively perfect, and the performance and effect are good. The alternative is horovod. It supports not only PyTorch but also TensorFlow and MXNet framework. It is easy to implement, and the speed should be comparable.
Reference resources
- Distributed data parallel training in Pytorch https://yangkky.github.io/2019/07/08/distributed-pytorch-tutorial.html (most content comes from here)
- torch.distributed Https://python.org/docs/stable/distributed.html thank you for your reference - http://bjbsair.com/2020-03-27/tech-info/7154/ The simplest way to accelerate the training of neural network is to use GPU. The speed of GPU in the normal operation (matrix multiplication and addition) of neural network is twice faster than that of CPU. As models or datasets grow larger, a GPU will soon become inadequate. For example, large language models such as BERT and GPT-2 are trained on hundreds of GPUs. For multi GPU training, a method of model and data segmentation and scheduling between different GPUs is needed.
Pytorch is a very popular deep learning framework, which has the best balance between flexibility and ease of use in the mainstream framework. There are two ways for Python to segment models and data on multiple GPUs: NN. DataParallel and nn.distributedataparallel. DataParallel is easier to use (simply wrap the single GPU model). However, since it uses a process to calculate model weights and then distribute them to each GPU during each batch, communication quickly becomes a bottleneck and GPU utilization is usually low. Moreover, nn.DataParallel requires all GPUs to be on the same node (distributed is not supported), and Apex cannot be used for mixed precision training. The main differences between NN. DataParallel and nn.distributedataparallel can be summarized as follows:
- DistributedDataParallel supports model parallelism, but DataParallel does not, which means that if the model is too large and the single card does not have enough memory, the former can only be used;
- DataParallel is single process and multi thread, only used for single card situation, while DistributedDataParallel is multi process, suitable for single machine and multi machine situation, and truly realizes distributed training;
- The training of distributed DataParallel is more efficient, because each process is an independent Python interpreter to avoid GIL problems, and its training speed is faster with low communication cost. Basically, DataParallel has been abandoned;
- It must be noted that each process in the distributed data parallel has its own optimizer, which performs its own update process, but the gradient is passed to each process through communication, and all executed contents are the same;
Generally speaking, the python document is quite complete and clear, especially after version 1.0x. However, there are few introductions about DistributedDataParallel. The main documents are as follows:
- Writing Distributed Applications with PyTorch: mainly introduces distributed API, distributed configuration, different communication mechanisms and internal mechanisms, but to be honest, most people don't agree to understand them, and they seldom use them directly;
- Getting Started with Distributed Data Parallel: it briefly introduces how to use distributed data parallel, but the use case is not clear and complete;
- ImageNet training in PyTorch: a relatively complete use case, but only code, lack of detailed description; (apex also provides a similar training case Mixed Precision ImageNet Training in PyTorch)
- (advanced) PyTorch 1.0 Distributed Trainer with Amazon AWS: how to conduct distributed training on Amazon cloud, but it is estimated that many people can't use it.
This tutorial will show you how to use PyTorch's distributed training with an example of MNISI. Here is a section of code for explanation, and it also includes any mixed precision training with apex.
Distributed data parallel internal mechanism
Distributed data parallel replicates models among multiple GPUs through multiple processes. Each GPU is controlled by one process (of course, each process can control multiple GPUs, but this is obviously slower than each process has one GPU; multiple processes can also run on one GPU). GPUs can be on the same node or distributed on multiple nodes. Each process performs the same tasks, and each process communicates with all other processes. Process or GPU only transfer gradient, so network communication is no longer the bottleneck.
During training, each process loads batch data from disk and passes them to its GPU. Each GPU has its own forward process, and then the gradient performs all reduce among GPUs. The gradient of each layer does not depend on the previous layer, so all reduce and backward process of the gradient are calculated at the same time to further alleviate the network bottleneck. At the end of the backward process, each node gets an average gradient, so that the model parameters keep synchronous.
This requires multiple processes (possibly on multiple nodes) to synchronize and communicate. Python does this through the distributed. Init? Process? Group function. He needs to know the location of process 0 so that all processes can be synchronized, as well as the expected total number of processes. Each process needs to know the total number of processes, their order in the process, and which GPU to use. Generally, the total number of processes is called world_size.python. nn.utils.data.DistributedSampler is provided to segment data for each process to ensure that the training data does not overlap.
Example explanation
This is explained by an example of MNIST. We first change it to distributed training, and then add hybrid precision training.
Ordinary single card training
First, import the required libraries:
import os from datetime import datetime import argparse import torch.multiprocessing as mp import torchvision import torchvision.transforms as transforms import torch import torch.nn as nn import torch.distributed as dist from apex.parallel import DistributedDataParallel as DDP from apex import amp
Then we define a simple CNN model to process MNIST data:
class ConvNet(nn.Module): def __init__(self, num_classes=10): super(ConvNet, self).__init__() self.layer1 = nn.Sequential( nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(16), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.layer2 = nn.Sequential( nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(32), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.fc = nn.Linear(7*7*32, num_classes) def forward(self, x): out = self.layer1(x) out = self.layer2(out) out = out.reshape(out.size(0), -1) out = self.fc(out) return out
The main function main() takes parameters and performs training:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() train(0, args)
The main function of the training part is:
def train(gpu, args): torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Data loading code train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True) train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True) start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() loss.backward() optimizer.step() if (i + 1) % 100 == 0 and gpu == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format( epoch + 1, args.epochs, i + 1, total_step, loss.item()) ) if gpu == 0: print("Training complete in: " + str(datetime.now() - start))
Start training by starting the main function:
if __name__ == '__main__': main()
You may notice that some parameters are redundant, but they are useful for later distributed training. We can train on a single stand-alone card by executing the following statements:
python src/mnist.py -n 1 -g 1 -nr 0
Distributed training
Using multi process for distributed training, we need to start a process for each GPU. Each process needs to know which GPU it is running on and its sequence number in all processes. For multiple nodes, we need to start scripts at each node.
First, we need to configure the basic parameters:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() ######################################################### args.world_size = args.gpus * args.nodes # os.environ['MASTER_ADDR'] = '10.57.23.164' # os.environ['MASTER_PORT'] = '8888' # mp.spawn(train, nprocs=args.gpus, args=(args,)) # #########################################################
Where args.nodes is the total number of nodes, while args.gpus is the total number of GPU per node (the number of GPU per node is the same), and args.nr is the serial number of the current node at all nodes. The total number of nodes multiplied by the number of GPUs of each node can get the world_size, that is, the total number of processes. All processes need to know the IP address and port of process 0, so that all processes can be synchronized at the beginning. Generally speaking, process 0 is the master process. For example, we will print information or save models in process 0. PyTorch provides mp.spawn to start all processes of the node at a node. Each process runs train(i, args), where i goes from 0 to args.gpus - 1.
Similarly, we need to modify the training function:
def train(gpu, args): ############################################################ rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank ) ############################################################ torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) ############################################################### # Wrap the model model = nn.parallel.DistributedDataParallel(model, device_ids=[gpu]) ############################################################### # Data loading code train_dataset = torchvision.datasets.MNIST( root='./data', train=True, transform=transforms.ToTensor(), download=True ) ################################################################ train_sampler = torch.utils.data.distributed.DistributedSampler( train_dataset, num_replicas=args.world_size, rank=rank ) ################################################################ train_loader = torch.utils.data.DataLoader( dataset=train_dataset, batch_size=batch_size, ############################## shuffle=False, # ############################## num_workers=0, pin_memory=True, ############################# sampler=train_sampler) # ############################# ...
Here we first calculate the forward program number: rank = args.nr * args.gpus + gpu, and then initialize the distributed environment through dist.init process group, where the backend parameter specifies the communication backend, including mpi, gloo, nccl. Here, nccl is selected, which is the official multi card communication framework provided by Nvidia, which is relatively efficient. MPI is also a common communication protocol for high-performance computing, but you need to install your own MPI implementation framework, such as OpenMPI. gloo is built-in communication backend, but it is not efficient enough. Init? Method refers to how to initialize to complete the process synchronization at the beginning; here we set env: / /, which refers to the initialization mode of environment variables. Four parameters need to be configured in the environment variables: Master ﹐ port, master ﹐ addr, world ﹐ size, rank. The first two parameters have been configured. The last two parameters can also be configured through the world ﹐ size and rank parameters in the dist.init ﹐ process ﹐ group function. Other initialization methods include shared file system and TCP, such as init method = tcp://10.1.1.20:23456 ', which also provides the IP address and port of the master. Note that this call is blocked and must wait for all processes to synchronize. If any process fails, it will fail.
For the model side, we just need to wrap the original model with distributed data parallel, which will support gradient all reduce operation. For the data side, we nn.utils.data.DistributedSampler to segment data for each process, just use this sampler in dataloader. It is worth noting that you need to call train train ﹐ sampler.set ﹐ epoch (epoch) at the beginning of each epoch in the cyclic process (mainly to ensure that the partition of each epoch is different). Other training codes remain unchanged.
Finally, the code can be executed. For example, if we are a 4-node and each node is an 8-card, we need to execute the code on four nodes respectively:
python src/mnist-distributed.py -n 4 -g 8 -nr i
It should be noted that the effective batch size at this time is actually batch size per GPU * world size. For models with BN, synchronous BN can also be used to achieve better results:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
The distributed training process described above is also applicable to the evaluation or test process. For example, we can divide the data into different processes for prediction, which can accelerate the prediction process. The implementation code is exactly the same as the above process, but if we want to calculate an indicator, we need to perform all reduce from the statistical results of each process, because each process is only the content of the calculated part of the data. For example, if we want to calculate the classification accuracy, we can count the total data of each process and the number of correctly classified counts, and then aggregate them. The point to be mentioned here is that when using dist.init ﹣ process ﹣ group to initialize the distributed environment, it is actually to establish a default distributed process group, which will also initialize the torch.distributed package of Python. In this way, we can directly use the torch.distributed API to perform basic distributed operations. The following is the specific implementation:
# define tensor on GPU, count and total is the result at each GPU t = torch.tensor([count, total], dtype=torch.float64, device='cuda') dist.barrier() # synchronizes all processes dist.all_reduce(t, op=torch.distributed.ReduceOp.SUM,) # Reduces the tensor data across all machines in such a way that all get the final result. t = t.tolist() all_count = int(t[0]) all_total = int(t[1]) acc = all_count / all_total
Mixed precision training (with apex)
Hybrid precision training (hybrid FP32 and FP16 training) can be applied to larger batch size, and can use NVIDIA Tensor Cores to accelerate calculation. Using NVIDIA's apex for hybrid precision training is very simple, only part of the code needs to be modified:
rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank) torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Wrap the model ############################################################## model, optimizer = amp.initialize(model, optimizer, opt_level='O2') model = DDP(model) ############################################################## # Data loading code ... start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() ############################################################## with amp.scale_loss(loss, optimizer) as scaled_loss: scaled_loss.backward() ############################################################## optimizer.step() ...
In fact, there are two changes. First, amp.initialize is used to package model and optimizer to support mixed precision training, in which opt'u level refers to the optimization level. If O0 or O3 is not the real mixed precision, but it can be used to determine the baseline of model effect and speed, and O1 and O2 are two settings of mixed precision, and one can be selected for mixed precision training. The other is that before updating the parameters according to the gradient, the gradient should be scaled through amp.scale'loss to prevent underflow. In addition, you can replace nn.DistributedDataParallel with apex.parallel.DistributedDataParallel.
Digression
I think the official distributed implementation of PyTorch has been relatively perfect, and the performance and effect are good. The alternative is horovod. It supports not only PyTorch but also TensorFlow and MXNet framework. It is easy to implement, and the speed should be comparable.
Reference resources
- Distributed data parallel training in Pytorch https://yangkky.github.io/2019/07/08/distributed-pytorch-tutorial.html (most content comes from here)
- torch.distributed Https://python.org/docs/stable/distributed.html thank you for your reference - http://bjbsair.com/2020-03-27/tech-info/7154/ The simplest way to accelerate the training of neural network is to use GPU. The speed of GPU in the normal operation (matrix multiplication and addition) of neural network is twice faster than that of CPU. As models or datasets grow larger, a GPU will soon become inadequate. For example, large language models such as BERT and GPT-2 are trained on hundreds of GPUs. For multi GPU training, a method of model and data segmentation and scheduling between different GPUs is needed.
Pytorch is a very popular deep learning framework, which has the best balance between flexibility and ease of use in the mainstream framework. There are two ways for Python to segment models and data on multiple GPUs: NN. DataParallel and nn.distributedataparallel. DataParallel is easier to use (simply wrap the single GPU model). However, since it uses a process to calculate model weights and then distribute them to each GPU during each batch, communication quickly becomes a bottleneck and GPU utilization is usually low. Moreover, nn.DataParallel requires all GPUs to be on the same node (distributed is not supported), and Apex cannot be used for mixed precision training. The main differences between NN. DataParallel and nn.distributedataparallel can be summarized as follows:
- DistributedDataParallel supports model parallelism, but DataParallel does not, which means that if the model is too large and the single card does not have enough memory, the former can only be used;
- DataParallel is single process and multi thread, only used for single card situation, while DistributedDataParallel is multi process, suitable for single machine and multi machine situation, and truly realizes distributed training;
- The training of distributed DataParallel is more efficient, because each process is an independent Python interpreter to avoid GIL problems, and its training speed is faster with low communication cost. Basically, DataParallel has been abandoned;
- It must be noted that each process in the distributed data parallel has its own optimizer, which performs its own update process, but the gradient is passed to each process through communication, and all executed contents are the same;
Generally speaking, the python document is quite complete and clear, especially after version 1.0x. However, there are few introductions about DistributedDataParallel. The main documents are as follows:
- Writing Distributed Applications with PyTorch: mainly introduces distributed API, distributed configuration, different communication mechanisms and internal mechanisms, but to be honest, most people don't agree to understand them, and they seldom use them directly;
- Getting Started with Distributed Data Parallel: it briefly introduces how to use distributed data parallel, but the use case is not clear and complete;
- ImageNet training in PyTorch: a relatively complete use case, but only code, lack of detailed description; (apex also provides a similar training case Mixed Precision ImageNet Training in PyTorch)
- (advanced) PyTorch 1.0 Distributed Trainer with Amazon AWS: how to conduct distributed training on Amazon cloud, but it is estimated that many people can't use it.
This tutorial will show you how to use PyTorch's distributed training with an example of MNISI. Here is a section of code for explanation, and it also includes any mixed precision training with apex.
Distributed data parallel internal mechanism
Distributed data parallel replicates models among multiple GPUs through multiple processes. Each GPU is controlled by one process (of course, each process can control multiple GPUs, but this is obviously slower than each process has one GPU; multiple processes can also run on one GPU). GPUs can be on the same node or distributed on multiple nodes. Each process performs the same tasks, and each process communicates with all other processes. Process or GPU only transfer gradient, so network communication is no longer the bottleneck.
During training, each process loads batch data from disk and passes them to its GPU. Each GPU has its own forward process, and then the gradient performs all reduce among GPUs. The gradient of each layer does not depend on the previous layer, so all reduce and backward process of the gradient are calculated at the same time to further alleviate the network bottleneck. At the end of the backward process, each node gets an average gradient, so that the model parameters keep synchronous.
This requires multiple processes (possibly on multiple nodes) to synchronize and communicate. Python does this through the distributed. Init? Process? Group function. He needs to know the location of process 0 so that all processes can be synchronized, as well as the expected total number of processes. Each process needs to know the total number of processes, their order in the process, and which GPU to use. Generally, the total number of processes is called world_size.python. nn.utils.data.DistributedSampler is provided to segment data for each process to ensure that the training data does not overlap.
Example explanation
This is explained by an example of MNIST. We first change it to distributed training, and then add hybrid precision training.
Ordinary single card training
First, import the required libraries:
import os from datetime import datetime import argparse import torch.multiprocessing as mp import torchvision import torchvision.transforms as transforms import torch import torch.nn as nn import torch.distributed as dist from apex.parallel import DistributedDataParallel as DDP from apex import amp
Then we define a simple CNN model to process MNIST data:
class ConvNet(nn.Module): def __init__(self, num_classes=10): super(ConvNet, self).__init__() self.layer1 = nn.Sequential( nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(16), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.layer2 = nn.Sequential( nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(32), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.fc = nn.Linear(7*7*32, num_classes) def forward(self, x): out = self.layer1(x) out = self.layer2(out) out = out.reshape(out.size(0), -1) out = self.fc(out) return out
The main function main() takes parameters and performs training:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() train(0, args)
The main function of the training part is:
def train(gpu, args): torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Data loading code train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True) train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True) start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() loss.backward() optimizer.step() if (i + 1) % 100 == 0 and gpu == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format( epoch + 1, args.epochs, i + 1, total_step, loss.item()) ) if gpu == 0: print("Training complete in: " + str(datetime.now() - start))
Start training by starting the main function:
if __name__ == '__main__': main()
You may notice that some parameters are redundant, but they are useful for later distributed training. We can train on a single stand-alone card by executing the following statements:
python src/mnist.py -n 1 -g 1 -nr 0
Distributed training
Using multi process for distributed training, we need to start a process for each GPU. Each process needs to know which GPU it is running on and its sequence number in all processes. For multiple nodes, we need to start scripts at each node.
First, we need to configure the basic parameters:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() ######################################################### args.world_size = args.gpus * args.nodes # os.environ['MASTER_ADDR'] = '10.57.23.164' # os.environ['MASTER_PORT'] = '8888' # mp.spawn(train, nprocs=args.gpus, args=(args,)) # #########################################################
Where args.nodes is the total number of nodes, while args.gpus is the total number of GPU per node (the number of GPU per node is the same), and args.nr is the serial number of the current node at all nodes. The total number of nodes multiplied by the number of GPUs of each node can get the world_size, that is, the total number of processes. All processes need to know the IP address and port of process 0, so that all processes can be synchronized at the beginning. Generally speaking, process 0 is the master process. For example, we will print information or save models in process 0. PyTorch provides mp.spawn to start all processes of the node at a node. Each process runs train(i, args), where i goes from 0 to args.gpus - 1.
Similarly, we need to modify the training function:
def train(gpu, args): ############################################################ rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank ) ############################################################ torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) ############################################################### # Wrap the model model = nn.parallel.DistributedDataParallel(model, device_ids=[gpu]) ############################################################### # Data loading code train_dataset = torchvision.datasets.MNIST( root='./data', train=True, transform=transforms.ToTensor(), download=True ) ################################################################ train_sampler = torch.utils.data.distributed.DistributedSampler( train_dataset, num_replicas=args.world_size, rank=rank ) ################################################################ train_loader = torch.utils.data.DataLoader( dataset=train_dataset, batch_size=batch_size, ############################## shuffle=False, # ############################## num_workers=0, pin_memory=True, ############################# sampler=train_sampler) # ############################# ...
Here we first calculate the forward program number: rank = args.nr * args.gpus + gpu, and then initialize the distributed environment through dist.init process group, where the backend parameter specifies the communication backend, including mpi, gloo, nccl. Here, nccl is selected, which is the official multi card communication framework provided by Nvidia, which is relatively efficient. MPI is also a common communication protocol for high-performance computing, but you need to install your own MPI implementation framework, such as OpenMPI. gloo is built-in communication backend, but it is not efficient enough. Init? Method refers to how to initialize to complete the process synchronization at the beginning; here we set env: / /, which refers to the initialization mode of environment variables. Four parameters need to be configured in the environment variables: Master ﹐ port, master ﹐ addr, world ﹐ size, rank. The first two parameters have been configured. The last two parameters can also be configured through the world ﹐ size and rank parameters in the dist.init ﹐ process ﹐ group function. Other initialization methods include shared file system and TCP, such as init method = tcp://10.1.1.20:23456 ', which also provides the IP address and port of the master. Note that this call is blocked and must wait for all processes to synchronize. If any process fails, it will fail.
For the model side, we just need to wrap the original model with distributed data parallel, which will support gradient all reduce operation. For the data side, we nn.utils.data.DistributedSampler to segment data for each process, just use this sampler in dataloader. It is worth noting that you need to call train train ﹐ sampler.set ﹐ epoch (epoch) at the beginning of each epoch in the cyclic process (mainly to ensure that the partition of each epoch is different). Other training codes remain unchanged.
Finally, the code can be executed. For example, if we are a 4-node and each node is an 8-card, we need to execute the code on four nodes respectively:
python src/mnist-distributed.py -n 4 -g 8 -nr i
It should be noted that the effective batch size at this time is actually batch size per GPU * world size. For models with BN, synchronous BN can also be used to achieve better results:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
The distributed training process described above is also applicable to the evaluation or test process. For example, we can divide the data into different processes for prediction, which can accelerate the prediction process. The implementation code is exactly the same as the above process, but if we want to calculate an indicator, we need to perform all reduce from the statistical results of each process, because each process is only the content of the calculated part of the data. For example, if we want to calculate the classification accuracy, we can count the total data of each process and the number of correctly classified counts, and then aggregate them. The point to be mentioned here is that when using dist.init ﹣ process ﹣ group to initialize the distributed environment, it is actually to establish a default distributed process group, which will also initialize the torch.distributed package of Python. In this way, we can directly use the torch.distributed API to perform basic distributed operations. The following is the specific implementation:
# define tensor on GPU, count and total is the result at each GPU t = torch.tensor([count, total], dtype=torch.float64, device='cuda') dist.barrier() # synchronizes all processes dist.all_reduce(t, op=torch.distributed.ReduceOp.SUM,) # Reduces the tensor data across all machines in such a way that all get the final result. t = t.tolist() all_count = int(t[0]) all_total = int(t[1]) acc = all_count / all_total
Mixed precision training (with apex)
Hybrid precision training (hybrid FP32 and FP16 training) can be applied to larger batch size, and can use NVIDIA Tensor Cores to accelerate calculation. Using NVIDIA's apex for hybrid precision training is very simple, only part of the code needs to be modified:
rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank) torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Wrap the model ############################################################## model, optimizer = amp.initialize(model, optimizer, opt_level='O2') model = DDP(model) ############################################################## # Data loading code ... start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() ############################################################## with amp.scale_loss(loss, optimizer) as scaled_loss: scaled_loss.backward() ############################################################## optimizer.step() ...
In fact, there are two changes. First, amp.initialize is used to package model and optimizer to support mixed precision training, in which opt'u level refers to the optimization level. If O0 or O3 is not the real mixed precision, but it can be used to determine the baseline of model effect and speed, and O1 and O2 are two settings of mixed precision, and one can be selected for mixed precision training. The other is that before updating the parameters according to the gradient, the gradient should be scaled through amp.scale'loss to prevent underflow. In addition, you can replace nn.DistributedDataParallel with apex.parallel.DistributedDataParallel.
Digression
I think the official distributed implementation of PyTorch has been relatively perfect, and the performance and effect are good. The alternative is horovod. It supports not only PyTorch but also TensorFlow and MXNet framework. It is easy to implement, and the speed should be comparable.
Reference resources
- Distributed data parallel training in Pytorch https://yangkky.github.io/2019/07/08/distributed-pytorch-tutorial.html (most content comes from here)
- torch.distributed Https://python.org/docs/stable/distributed.html thank you for your reference - http://bjbsair.com/2020-03-27/tech-info/7154/ The simplest way to accelerate the training of neural network is to use GPU. The speed of GPU in the normal operation (matrix multiplication and addition) of neural network is twice faster than that of CPU. As models or datasets grow larger, a GPU will soon become inadequate. For example, large language models such as BERT and GPT-2 are trained on hundreds of GPUs. For multi GPU training, a method of model and data segmentation and scheduling between different GPUs is needed.
Pytorch is a very popular deep learning framework, which has the best balance between flexibility and ease of use in the mainstream framework. There are two ways for Python to segment models and data on multiple GPUs: NN. DataParallel and nn.distributedataparallel. DataParallel is easier to use (simply wrap the single GPU model). However, since it uses a process to calculate model weights and then distribute them to each GPU during each batch, communication quickly becomes a bottleneck and GPU utilization is usually low. Moreover, nn.DataParallel requires all GPUs to be on the same node (distributed is not supported), and Apex cannot be used for mixed precision training. The main differences between NN. DataParallel and nn.distributedataparallel can be summarized as follows:
- DistributedDataParallel supports model parallelism, but DataParallel does not, which means that if the model is too large and the single card does not have enough memory, the former can only be used;
- DataParallel is single process and multi thread, only used for single card situation, while DistributedDataParallel is multi process, suitable for single machine and multi machine situation, and truly realizes distributed training;
- The training of distributed DataParallel is more efficient, because each process is an independent Python interpreter to avoid GIL problems, and its training speed is faster with low communication cost. Basically, DataParallel has been abandoned;
- It must be noted that each process in the distributed data parallel has its own optimizer, which performs its own update process, but the gradient is passed to each process through communication, and all executed contents are the same;
Generally speaking, the python document is quite complete and clear, especially after version 1.0x. However, there are few introductions about DistributedDataParallel. The main documents are as follows:
- Writing Distributed Applications with PyTorch: mainly introduces distributed API, distributed configuration, different communication mechanisms and internal mechanisms, but to be honest, most people don't agree to understand them, and they seldom use them directly;
- Getting Started with Distributed Data Parallel: it briefly introduces how to use distributed data parallel, but the use case is not clear and complete;
- ImageNet training in PyTorch: a relatively complete use case, but only code, lack of detailed description; (apex also provides a similar training case Mixed Precision ImageNet Training in PyTorch)
- (advanced) PyTorch 1.0 Distributed Trainer with Amazon AWS: how to conduct distributed training on Amazon cloud, but it is estimated that many people can't use it.
This tutorial will show you how to use PyTorch's distributed training with an example of MNISI. Here is a section of code for explanation, and it also includes any mixed precision training with apex.
Distributed data parallel internal mechanism
Distributed data parallel replicates models among multiple GPUs through multiple processes. Each GPU is controlled by one process (of course, each process can control multiple GPUs, but this is obviously slower than each process has one GPU; multiple processes can also run on one GPU). GPUs can be on the same node or distributed on multiple nodes. Each process performs the same tasks, and each process communicates with all other processes. Process or GPU only transfer gradient, so network communication is no longer the bottleneck.
During training, each process loads batch data from disk and passes them to its GPU. Each GPU has its own forward process, and then the gradient performs all reduce among GPUs. The gradient of each layer does not depend on the previous layer, so all reduce and backward process of the gradient are calculated at the same time to further alleviate the network bottleneck. At the end of the backward process, each node gets an average gradient, so that the model parameters keep synchronous.
This requires multiple processes (possibly on multiple nodes) to synchronize and communicate. Python does this through the distributed. Init? Process? Group function. He needs to know the location of process 0 so that all processes can be synchronized, as well as the expected total number of processes. Each process needs to know the total number of processes, their order in the process, and which GPU to use. Generally, the total number of processes is called world_size.python. nn.utils.data.DistributedSampler is provided to segment data for each process to ensure that the training data does not overlap.
Example explanation
This is explained by an example of MNIST. We first change it to distributed training, and then add hybrid precision training.
Ordinary single card training
First, import the required libraries:
import os from datetime import datetime import argparse import torch.multiprocessing as mp import torchvision import torchvision.transforms as transforms import torch import torch.nn as nn import torch.distributed as dist from apex.parallel import DistributedDataParallel as DDP from apex import amp
Then we define a simple CNN model to process MNIST data:
class ConvNet(nn.Module): def __init__(self, num_classes=10): super(ConvNet, self).__init__() self.layer1 = nn.Sequential( nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(16), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.layer2 = nn.Sequential( nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(32), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.fc = nn.Linear(7*7*32, num_classes) def forward(self, x): out = self.layer1(x) out = self.layer2(out) out = out.reshape(out.size(0), -1) out = self.fc(out) return out
The main function main() takes parameters and performs training:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() train(0, args)
The main function of the training part is:
def train(gpu, args): torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Data loading code train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True) train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True) start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() loss.backward() optimizer.step() if (i + 1) % 100 == 0 and gpu == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format( epoch + 1, args.epochs, i + 1, total_step, loss.item()) ) if gpu == 0: print("Training complete in: " + str(datetime.now() - start))
Start training by starting the main function:
if __name__ == '__main__': main()
You may notice that some parameters are redundant, but they are useful for later distributed training. We can train on a single stand-alone card by executing the following statements:
python src/mnist.py -n 1 -g 1 -nr 0
Distributed training
Using multi process for distributed training, we need to start a process for each GPU. Each process needs to know which GPU it is running on and its sequence number in all processes. For multiple nodes, we need to start scripts at each node.
First, we need to configure the basic parameters:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() ######################################################### args.world_size = args.gpus * args.nodes # os.environ['MASTER_ADDR'] = '10.57.23.164' # os.environ['MASTER_PORT'] = '8888' # mp.spawn(train, nprocs=args.gpus, args=(args,)) # #########################################################
Where args.nodes is the total number of nodes, while args.gpus is the total number of GPU per node (the number of GPU per node is the same), and args.nr is the serial number of the current node at all nodes. The total number of nodes multiplied by the number of GPUs of each node can get the world_size, that is, the total number of processes. All processes need to know the IP address and port of process 0, so that all processes can be synchronized at the beginning. Generally speaking, process 0 is the master process. For example, we will print information or save models in process 0. PyTorch provides mp.spawn to start all processes of the node at a node. Each process runs train(i, args), where i goes from 0 to args.gpus - 1.
Similarly, we need to modify the training function:
def train(gpu, args): ############################################################ rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank ) ############################################################ torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) ############################################################### # Wrap the model model = nn.parallel.DistributedDataParallel(model, device_ids=[gpu]) ############################################################### # Data loading code train_dataset = torchvision.datasets.MNIST( root='./data', train=True, transform=transforms.ToTensor(), download=True ) ################################################################ train_sampler = torch.utils.data.distributed.DistributedSampler( train_dataset, num_replicas=args.world_size, rank=rank ) ################################################################ train_loader = torch.utils.data.DataLoader( dataset=train_dataset, batch_size=batch_size, ############################## shuffle=False, # ############################## num_workers=0, pin_memory=True, ############################# sampler=train_sampler) # ############################# ...
Here we first calculate the forward program number: rank = args.nr * args.gpus + gpu, and then initialize the distributed environment through dist.init process group, where the backend parameter specifies the communication backend, including mpi, gloo, nccl. Here, nccl is selected, which is the official multi card communication framework provided by Nvidia, which is relatively efficient. MPI is also a common communication protocol for high-performance computing, but you need to install your own MPI implementation framework, such as OpenMPI. gloo is built-in communication backend, but it is not efficient enough. Init? Method refers to how to initialize to complete the process synchronization at the beginning; here we set env: / /, which refers to the initialization mode of environment variables. Four parameters need to be configured in the environment variables: Master ﹐ port, master ﹐ addr, world ﹐ size, rank. The first two parameters have been configured. The last two parameters can also be configured through the world ﹐ size and rank parameters in the dist.init ﹐ process ﹐ group function. Other initialization methods include shared file system and TCP, such as init method = tcp://10.1.1.20:23456 ', which also provides the IP address and port of the master. Note that this call is blocked and must wait for all processes to synchronize. If any process fails, it will fail.
For the model side, we just need to wrap the original model with distributed data parallel, which will support gradient all reduce operation. For the data side, we nn.utils.data.DistributedSampler to segment data for each process, just use this sampler in dataloader. It is worth noting that you need to call train train ﹐ sampler.set ﹐ epoch (epoch) at the beginning of each epoch in the cyclic process (mainly to ensure that the partition of each epoch is different). Other training codes remain unchanged.
Finally, the code can be executed. For example, if we are a 4-node and each node is an 8-card, we need to execute the code on four nodes respectively:
python src/mnist-distributed.py -n 4 -g 8 -nr i
It should be noted that the effective batch size at this time is actually batch size per GPU * world size. For models with BN, synchronous BN can also be used to achieve better results:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
The distributed training process described above is also applicable to the evaluation or test process. For example, we can divide the data into different processes for prediction, which can accelerate the prediction process. The implementation code is exactly the same as the above process, but if we want to calculate an indicator, we need to perform all reduce from the statistical results of each process, because each process is only the content of the calculated part of the data. For example, if we want to calculate the classification accuracy, we can count the total data of each process and the number of correctly classified counts, and then aggregate them. The point to be mentioned here is that when using dist.init ﹣ process ﹣ group to initialize the distributed environment, it is actually to establish a default distributed process group, which will also initialize the torch.distributed package of Python. In this way, we can directly use the torch.distributed API to perform basic distributed operations. The following is the specific implementation:
# define tensor on GPU, count and total is the result at each GPU t = torch.tensor([count, total], dtype=torch.float64, device='cuda') dist.barrier() # synchronizes all processes dist.all_reduce(t, op=torch.distributed.ReduceOp.SUM,) # Reduces the tensor data across all machines in such a way that all get the final result. t = t.tolist() all_count = int(t[0]) all_total = int(t[1]) acc = all_count / all_total
Mixed precision training (with apex)
Hybrid precision training (hybrid FP32 and FP16 training) can be applied to larger batch size, and can use NVIDIA Tensor Cores to accelerate calculation. Using NVIDIA's apex for hybrid precision training is very simple, only part of the code needs to be modified:
rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank) torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Wrap the model ############################################################## model, optimizer = amp.initialize(model, optimizer, opt_level='O2') model = DDP(model) ############################################################## # Data loading code ... start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() ############################################################## with amp.scale_loss(loss, optimizer) as scaled_loss: scaled_loss.backward() ############################################################## optimizer.step() ...
In fact, there are two changes. First, amp.initialize is used to package model and optimizer to support mixed precision training, in which opt'u level refers to the optimization level. If O0 or O3 is not the real mixed precision, but it can be used to determine the baseline of model effect and speed, and O1 and O2 are two settings of mixed precision, and one can be selected for mixed precision training. The other is that before updating the parameters according to the gradient, the gradient should be scaled through amp.scale'loss to prevent underflow. In addition, you can replace nn.DistributedDataParallel with apex.parallel.DistributedDataParallel.
Digression
I think the official distributed implementation of PyTorch has been relatively perfect, and the performance and effect are good. The alternative is horovod. It supports not only PyTorch but also TensorFlow and MXNet framework. It is easy to implement, and the speed should be comparable.
Reference resources
- Distributed data parallel training in Pytorch https://yangkky.github.io/2019/07/08/distributed-pytorch-tutorial.html (most content comes from here)
- torch.distributed Https://python.org/docs/stable/distributed.html thank you for your reference - http://bjbsair.com/2020-03-27/tech-info/7154/ The simplest way to accelerate the training of neural network is to use GPU. The speed of GPU in the normal operation (matrix multiplication and addition) of neural network is twice faster than that of CPU. As models or datasets grow larger, a GPU will soon become inadequate. For example, large language models such as BERT and GPT-2 are trained on hundreds of GPUs. For multi GPU training, a method of model and data segmentation and scheduling between different GPUs is needed.
Pytorch is a very popular deep learning framework, which has the best balance between flexibility and ease of use in the mainstream framework. There are two ways for Python to segment models and data on multiple GPUs: NN. DataParallel and nn.distributedataparallel. DataParallel is easier to use (simply wrap the single GPU model). However, since it uses a process to calculate model weights and then distribute them to each GPU during each batch, communication quickly becomes a bottleneck and GPU utilization is usually low. Moreover, nn.DataParallel requires all GPUs to be on the same node (distributed is not supported), and Apex cannot be used for mixed precision training. The main differences between NN. DataParallel and nn.distributedataparallel can be summarized as follows:
- DistributedDataParallel supports model parallelism, but DataParallel does not, which means that if the model is too large and the single card does not have enough memory, the former can only be used;
- DataParallel is single process and multi thread, only used for single card situation, while DistributedDataParallel is multi process, suitable for single machine and multi machine situation, and truly realizes distributed training;
- The training of distributed DataParallel is more efficient, because each process is an independent Python interpreter to avoid GIL problems, and its training speed is faster with low communication cost. Basically, DataParallel has been abandoned;
- It must be noted that each process in the distributed data parallel has its own optimizer, which performs its own update process, but the gradient is passed to each process through communication, and all executed contents are the same;
Generally speaking, the python document is quite complete and clear, especially after version 1.0x. However, there are few introductions about DistributedDataParallel. The main documents are as follows:
- Writing Distributed Applications with PyTorch: mainly introduces distributed API, distributed configuration, different communication mechanisms and internal mechanisms, but to be honest, most people don't agree to understand them, and they seldom use them directly;
- Getting Started with Distributed Data Parallel: it briefly introduces how to use distributed data parallel, but the use case is not clear and complete;
- ImageNet training in PyTorch: a relatively complete use case, but only code, lack of detailed description; (apex also provides a similar training case Mixed Precision ImageNet Training in PyTorch)
- (advanced) PyTorch 1.0 Distributed Trainer with Amazon AWS: how to conduct distributed training on Amazon cloud, but it is estimated that many people can't use it.
This tutorial will show you how to use PyTorch's distributed training with an example of MNISI. Here is a section of code for explanation, and it also includes any mixed precision training with apex.
Distributed data parallel internal mechanism
Distributed data parallel replicates models among multiple GPUs through multiple processes. Each GPU is controlled by one process (of course, each process can control multiple GPUs, but this is obviously slower than each process has one GPU; multiple processes can also run on one GPU). GPUs can be on the same node or distributed on multiple nodes. Each process performs the same tasks, and each process communicates with all other processes. Process or GPU only transfer gradient, so network communication is no longer the bottleneck.
During training, each process loads batch data from disk and passes them to its GPU. Each GPU has its own forward process, and then the gradient performs all reduce among GPUs. The gradient of each layer does not depend on the previous layer, so all reduce and backward process of the gradient are calculated at the same time to further alleviate the network bottleneck. At the end of the backward process, each node gets an average gradient, so that the model parameters keep synchronous.
This requires multiple processes (possibly on multiple nodes) to synchronize and communicate. Python does this through the distributed. Init? Process? Group function. He needs to know the location of process 0 so that all processes can be synchronized, as well as the expected total number of processes. Each process needs to know the total number of processes, their order in the process, and which GPU to use. Generally, the total number of processes is called world_size.python. nn.utils.data.DistributedSampler is provided to segment data for each process to ensure that the training data does not overlap.
Example explanation
This is explained by an example of MNIST. We first change it to distributed training, and then add hybrid precision training.
Ordinary single card training
First, import the required libraries:
import os from datetime import datetime import argparse import torch.multiprocessing as mp import torchvision import torchvision.transforms as transforms import torch import torch.nn as nn import torch.distributed as dist from apex.parallel import DistributedDataParallel as DDP from apex import amp
Then we define a simple CNN model to process MNIST data:
class ConvNet(nn.Module): def __init__(self, num_classes=10): super(ConvNet, self).__init__() self.layer1 = nn.Sequential( nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(16), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.layer2 = nn.Sequential( nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(32), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.fc = nn.Linear(7*7*32, num_classes) def forward(self, x): out = self.layer1(x) out = self.layer2(out) out = out.reshape(out.size(0), -1) out = self.fc(out) return out
The main function main() takes parameters and performs training:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() train(0, args)
The main function of the training part is:
def train(gpu, args): torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Data loading code train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True) train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True) start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() loss.backward() optimizer.step() if (i + 1) % 100 == 0 and gpu == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format( epoch + 1, args.epochs, i + 1, total_step, loss.item()) ) if gpu == 0: print("Training complete in: " + str(datetime.now() - start))
Start training by starting the main function:
if __name__ == '__main__': main()
You may notice that some parameters are redundant, but they are useful for later distributed training. We can train on a single stand-alone card by executing the following statements:
python src/mnist.py -n 1 -g 1 -nr 0
Distributed training
Using multi process for distributed training, we need to start a process for each GPU. Each process needs to know which GPU it is running on and its sequence number in all processes. For multiple nodes, we need to start scripts at each node.
First, we need to configure the basic parameters:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() ######################################################### args.world_size = args.gpus * args.nodes # os.environ['MASTER_ADDR'] = '10.57.23.164' # os.environ['MASTER_PORT'] = '8888' # mp.spawn(train, nprocs=args.gpus, args=(args,)) # #########################################################
Where args.nodes is the total number of nodes, while args.gpus is the total number of GPU per node (the number of GPU per node is the same), and args.nr is the serial number of the current node at all nodes. The total number of nodes multiplied by the number of GPUs of each node can get the world_size, that is, the total number of processes. All processes need to know the IP address and port of process 0, so that all processes can be synchronized at the beginning. Generally speaking, process 0 is the master process. For example, we will print information or save models in process 0. PyTorch provides mp.spawn to start all processes of the node at a node. Each process runs train(i, args), where i goes from 0 to args.gpus - 1.
Similarly, we need to modify the training function:
def train(gpu, args): ############################################################ rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank ) ############################################################ torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) ############################################################### # Wrap the model model = nn.parallel.DistributedDataParallel(model, device_ids=[gpu]) ############################################################### # Data loading code train_dataset = torchvision.datasets.MNIST( root='./data', train=True, transform=transforms.ToTensor(), download=True ) ################################################################ train_sampler = torch.utils.data.distributed.DistributedSampler( train_dataset, num_replicas=args.world_size, rank=rank ) ################################################################ train_loader = torch.utils.data.DataLoader( dataset=train_dataset, batch_size=batch_size, ############################## shuffle=False, # ############################## num_workers=0, pin_memory=True, ############################# sampler=train_sampler) # ############################# ...
Here we first calculate the forward program number: rank = args.nr * args.gpus + gpu, and then initialize the distributed environment through dist.init process group, where the backend parameter specifies the communication backend, including mpi, gloo, nccl. Here, nccl is selected, which is the official multi card communication framework provided by Nvidia, which is relatively efficient. MPI is also a common communication protocol for high-performance computing, but you need to install your own MPI implementation framework, such as OpenMPI. gloo is built-in communication backend, but it is not efficient enough. Init? Method refers to how to initialize to complete the process synchronization at the beginning; here we set env: / /, which refers to the initialization mode of environment variables. Four parameters need to be configured in the environment variables: Master ﹐ port, master ﹐ addr, world ﹐ size, rank. The first two parameters have been configured. The last two parameters can also be configured through the world ﹐ size and rank parameters in the dist.init ﹐ process ﹐ group function. Other initialization methods include shared file system and TCP, such as init method = tcp://10.1.1.20:23456 ', which also provides the IP address and port of the master. Note that this call is blocked and must wait for all processes to synchronize. If any process fails, it will fail.
For the model side, we just need to wrap the original model with distributed data parallel, which will support gradient all reduce operation. For the data side, we nn.utils.data.DistributedSampler to segment data for each process, just use this sampler in dataloader. It is worth noting that you need to call train train ﹐ sampler.set ﹐ epoch (epoch) at the beginning of each epoch in the cyclic process (mainly to ensure that the partition of each epoch is different). Other training codes remain unchanged.
Finally, the code can be executed. For example, if we are a 4-node and each node is an 8-card, we need to execute the code on four nodes respectively:
python src/mnist-distributed.py -n 4 -g 8 -nr i
It should be noted that the effective batch size at this time is actually batch size per GPU * world size. For models with BN, synchronous BN can also be used to achieve better results:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
The distributed training process described above is also applicable to the evaluation or test process. For example, we can divide the data into different processes for prediction, which can accelerate the prediction process. The implementation code is exactly the same as the above process, but if we want to calculate an indicator, we need to perform all reduce from the statistical results of each process, because each process is only the content of the calculated part of the data. For example, if we want to calculate the classification accuracy, we can count the total data of each process and the number of correctly classified counts, and then aggregate them. The point to be mentioned here is that when using dist.init ﹣ process ﹣ group to initialize the distributed environment, it is actually to establish a default distributed process group, which will also initialize the torch.distributed package of Python. In this way, we can directly use the torch.distributed API to perform basic distributed operations. The following is the specific implementation:
# define tensor on GPU, count and total is the result at each GPU t = torch.tensor([count, total], dtype=torch.float64, device='cuda') dist.barrier() # synchronizes all processes dist.all_reduce(t, op=torch.distributed.ReduceOp.SUM,) # Reduces the tensor data across all machines in such a way that all get the final result. t = t.tolist() all_count = int(t[0]) all_total = int(t[1]) acc = all_count / all_total
Mixed precision training (with apex)
Hybrid precision training (hybrid FP32 and FP16 training) can be applied to larger batch size, and can use NVIDIA Tensor Cores to accelerate calculation. Using NVIDIA's apex for hybrid precision training is very simple, only part of the code needs to be modified:
rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank) torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Wrap the model ############################################################## model, optimizer = amp.initialize(model, optimizer, opt_level='O2') model = DDP(model) ############################################################## # Data loading code ... start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() ############################################################## with amp.scale_loss(loss, optimizer) as scaled_loss: scaled_loss.backward() ############################################################## optimizer.step() ...
In fact, there are two changes. First, amp.initialize is used to package model and optimizer to support mixed precision training, in which opt'u level refers to the optimization level. If O0 or O3 is not the real mixed precision, but it can be used to determine the baseline of model effect and speed, and O1 and O2 are two settings of mixed precision, and one can be selected for mixed precision training. The other is that before updating the parameters according to the gradient, the gradient should be scaled through amp.scale'loss to prevent underflow. In addition, you can replace nn.DistributedDataParallel with apex.parallel.DistributedDataParallel.
Digression
I think the official distributed implementation of PyTorch has been relatively perfect, and the performance and effect are good. The alternative is horovod. It supports not only PyTorch but also TensorFlow and MXNet framework. It is easy to implement, and the speed should be comparable.
Reference resources
- Distributed data parallel training in Pytorch https://yangkky.github.io/2019/07/08/distributed-pytorch-tutorial.html (most content comes from here)
- torch.distributed Https://python.org/docs/stable/distributed.html thank you for your reference - http://bjbsair.com/2020-03-27/tech-info/7154/ The simplest way to accelerate the training of neural network is to use GPU. The speed of GPU in the normal operation (matrix multiplication and addition) of neural network is twice faster than that of CPU. As models or datasets grow larger, a GPU will soon become inadequate. For example, large language models such as BERT and GPT-2 are trained on hundreds of GPUs. For multi GPU training, a method of model and data segmentation and scheduling between different GPUs is needed.
Pytorch is a very popular deep learning framework, which has the best balance between flexibility and ease of use in the mainstream framework. There are two ways for Python to segment models and data on multiple GPUs: NN. DataParallel and nn.distributedataparallel. DataParallel is easier to use (simply wrap the single GPU model). However, since it uses a process to calculate model weights and then distribute them to each GPU during each batch, communication quickly becomes a bottleneck and GPU utilization is usually low. Moreover, nn.DataParallel requires all GPUs to be on the same node (distributed is not supported), and Apex cannot be used for mixed precision training. The main differences between NN. DataParallel and nn.distributedataparallel can be summarized as follows:
- DistributedDataParallel supports model parallelism, but DataParallel does not, which means that if the model is too large and the single card does not have enough memory, the former can only be used;
- DataParallel is single process and multi thread, only used for single card situation, while DistributedDataParallel is multi process, suitable for single machine and multi machine situation, and truly realizes distributed training;
- The training of distributed DataParallel is more efficient, because each process is an independent Python interpreter to avoid GIL problems, and its training speed is faster with low communication cost. Basically, DataParallel has been abandoned;
- It must be noted that each process in the distributed data parallel has its own optimizer, which performs its own update process, but the gradient is passed to each process through communication, and all executed contents are the same;
Generally speaking, the python document is quite complete and clear, especially after version 1.0x. However, there are few introductions about DistributedDataParallel. The main documents are as follows:
- Writing Distributed Applications with PyTorch: mainly introduces distributed API, distributed configuration, different communication mechanisms and internal mechanisms, but to be honest, most people don't agree to understand them, and they seldom use them directly;
- Getting Started with Distributed Data Parallel: it briefly introduces how to use distributed data parallel, but the use case is not clear and complete;
- ImageNet training in PyTorch: a relatively complete use case, but only code, lack of detailed description; (apex also provides a similar training case Mixed Precision ImageNet Training in PyTorch)
- (advanced) PyTorch 1.0 Distributed Trainer with Amazon AWS: how to conduct distributed training on Amazon cloud, but it is estimated that many people can't use it.
This tutorial will show you how to use PyTorch's distributed training with an example of MNISI. Here is a section of code for explanation, and it also includes any mixed precision training with apex.
Distributed data parallel internal mechanism
Distributed data parallel replicates models among multiple GPUs through multiple processes. Each GPU is controlled by one process (of course, each process can control multiple GPUs, but this is obviously slower than each process has one GPU; multiple processes can also run on one GPU). GPUs can be on the same node or distributed on multiple nodes. Each process performs the same tasks, and each process communicates with all other processes. Process or GPU only transfer gradient, so network communication is no longer the bottleneck.
During training, each process loads batch data from disk and passes them to its GPU. Each GPU has its own forward process, and then the gradient performs all reduce among GPUs. The gradient of each layer does not depend on the previous layer, so all reduce and backward process of the gradient are calculated at the same time to further alleviate the network bottleneck. At the end of the backward process, each node gets an average gradient, so that the model parameters keep synchronous.
This requires multiple processes (possibly on multiple nodes) to synchronize and communicate. Python does this through the distributed. Init? Process? Group function. He needs to know the location of process 0 so that all processes can be synchronized, as well as the expected total number of processes. Each process needs to know the total number of processes, their order in the process, and which GPU to use. Generally, the total number of processes is called world_size.python. nn.utils.data.DistributedSampler is provided to segment data for each process to ensure that the training data does not overlap.
Example explanation
This is explained by an example of MNIST. We first change it to distributed training, and then add hybrid precision training.
Ordinary single card training
First, import the required libraries:
import os from datetime import datetime import argparse import torch.multiprocessing as mp import torchvision import torchvision.transforms as transforms import torch import torch.nn as nn import torch.distributed as dist from apex.parallel import DistributedDataParallel as DDP from apex import amp
Then we define a simple CNN model to process MNIST data:
class ConvNet(nn.Module): def __init__(self, num_classes=10): super(ConvNet, self).__init__() self.layer1 = nn.Sequential( nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(16), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.layer2 = nn.Sequential( nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(32), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.fc = nn.Linear(7*7*32, num_classes) def forward(self, x): out = self.layer1(x) out = self.layer2(out) out = out.reshape(out.size(0), -1) out = self.fc(out) return out
The main function main() takes parameters and performs training:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() train(0, args)
The main function of the training part is:
def train(gpu, args): torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Data loading code train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True) train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True) start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() loss.backward() optimizer.step() if (i + 1) % 100 == 0 and gpu == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format( epoch + 1, args.epochs, i + 1, total_step, loss.item()) ) if gpu == 0: print("Training complete in: " + str(datetime.now() - start))
Start training by starting the main function:
if __name__ == '__main__': main()
You may notice that some parameters are redundant, but they are useful for later distributed training. We can train on a single stand-alone card by executing the following statements:
python src/mnist.py -n 1 -g 1 -nr 0
Distributed training
Using multi process for distributed training, we need to start a process for each GPU. Each process needs to know which GPU it is running on and its sequence number in all processes. For multiple nodes, we need to start scripts at each node.
First, we need to configure the basic parameters:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() ######################################################### args.world_size = args.gpus * args.nodes # os.environ['MASTER_ADDR'] = '10.57.23.164' # os.environ['MASTER_PORT'] = '8888' # mp.spawn(train, nprocs=args.gpus, args=(args,)) # #########################################################
Where args.nodes is the total number of nodes, while args.gpus is the total number of GPU per node (the number of GPU per node is the same), and args.nr is the serial number of the current node at all nodes. The total number of nodes multiplied by the number of GPUs of each node can get the world_size, that is, the total number of processes. All processes need to know the IP address and port of process 0, so that all processes can be synchronized at the beginning. Generally speaking, process 0 is the master process. For example, we will print information or save models in process 0. PyTorch provides mp.spawn to start all processes of the node at a node. Each process runs train(i, args), where i goes from 0 to args.gpus - 1.
Similarly, we need to modify the training function:
def train(gpu, args): ############################################################ rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank ) ############################################################ torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) ############################################################### # Wrap the model model = nn.parallel.DistributedDataParallel(model, device_ids=[gpu]) ############################################################### # Data loading code train_dataset = torchvision.datasets.MNIST( root='./data', train=True, transform=transforms.ToTensor(), download=True ) ################################################################ train_sampler = torch.utils.data.distributed.DistributedSampler( train_dataset, num_replicas=args.world_size, rank=rank ) ################################################################ train_loader = torch.utils.data.DataLoader( dataset=train_dataset, batch_size=batch_size, ############################## shuffle=False, # ############################## num_workers=0, pin_memory=True, ############################# sampler=train_sampler) # ############################# ...
Here we first calculate the forward program number: rank = args.nr * args.gpus + gpu, and then initialize the distributed environment through dist.init process group, where the backend parameter specifies the communication backend, including mpi, gloo, nccl. Here, nccl is selected, which is the official multi card communication framework provided by Nvidia, which is relatively efficient. MPI is also a common communication protocol for high-performance computing, but you need to install your own MPI implementation framework, such as OpenMPI. gloo is built-in communication backend, but it is not efficient enough. Init? Method refers to how to initialize to complete the process synchronization at the beginning; here we set env: / /, which refers to the initialization mode of environment variables. Four parameters need to be configured in the environment variables: Master ﹐ port, master ﹐ addr, world ﹐ size, rank. The first two parameters have been configured. The last two parameters can also be configured through the world ﹐ size and rank parameters in the dist.init ﹐ process ﹐ group function. Other initialization methods include shared file system and TCP, such as init method = tcp://10.1.1.20:23456 ', which also provides the IP address and port of the master. Note that this call is blocked and must wait for all processes to synchronize. If any process fails, it will fail.
For the model side, we just need to wrap the original model with distributed data parallel, which will support gradient all reduce operation. For the data side, we nn.utils.data.DistributedSampler to segment data for each process, just use this sampler in dataloader. It is worth noting that you need to call train train ﹐ sampler.set ﹐ epoch (epoch) at the beginning of each epoch in the cyclic process (mainly to ensure that the partition of each epoch is different). Other training codes remain unchanged.
Finally, the code can be executed. For example, if we are a 4-node and each node is an 8-card, we need to execute the code on four nodes respectively:
python src/mnist-distributed.py -n 4 -g 8 -nr i
It should be noted that the effective batch size at this time is actually batch size per GPU * world size. For models with BN, synchronous BN can also be used to achieve better results:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
The distributed training process described above is also applicable to the evaluation or test process. For example, we can divide the data into different processes for prediction, which can accelerate the prediction process. The implementation code is exactly the same as the above process, but if we want to calculate an indicator, we need to perform all reduce from the statistical results of each process, because each process is only the content of the calculated part of the data. For example, if we want to calculate the classification accuracy, we can count the total data of each process and the number of correctly classified counts, and then aggregate them. The point to be mentioned here is that when using dist.init ﹣ process ﹣ group to initialize the distributed environment, it is actually to establish a default distributed process group, which will also initialize the torch.distributed package of Python. In this way, we can directly use the torch.distributed API to perform basic distributed operations. The following is the specific implementation:
# define tensor on GPU, count and total is the result at each GPU t = torch.tensor([count, total], dtype=torch.float64, device='cuda') dist.barrier() # synchronizes all processes dist.all_reduce(t, op=torch.distributed.ReduceOp.SUM,) # Reduces the tensor data across all machines in such a way that all get the final result. t = t.tolist() all_count = int(t[0]) all_total = int(t[1]) acc = all_count / all_total
Mixed precision training (with apex)
Hybrid precision training (hybrid FP32 and FP16 training) can be applied to larger batch size, and can use NVIDIA Tensor Cores to accelerate calculation. Using NVIDIA's apex for hybrid precision training is very simple, only part of the code needs to be modified:
rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank) torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Wrap the model ############################################################## model, optimizer = amp.initialize(model, optimizer, opt_level='O2') model = DDP(model) ############################################################## # Data loading code ... start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() ############################################################## with amp.scale_loss(loss, optimizer) as scaled_loss: scaled_loss.backward() ############################################################## optimizer.step() ...
In fact, there are two changes. First, amp.initialize is used to package model and optimizer to support mixed precision training, in which opt'u level refers to the optimization level. If O0 or O3 is not the real mixed precision, but it can be used to determine the baseline of model effect and speed, and O1 and O2 are two settings of mixed precision, and one can be selected for mixed precision training. The other is that before updating the parameters according to the gradient, the gradient should be scaled through amp.scale'loss to prevent underflow. In addition, you can replace nn.DistributedDataParallel with apex.parallel.DistributedDataParallel.
Digression
I think the official distributed implementation of PyTorch has been relatively perfect, and the performance and effect are good. The alternative is horovod. It supports not only PyTorch but also TensorFlow and MXNet framework. It is easy to implement, and the speed should be comparable.
Reference resources
- Distributed data parallel training in Pytorch https://yangkky.github.io/2019/07/08/distributed-pytorch-tutorial.html (most content comes from here)
- torch.distributed Https://python.org/docs/stable/distributed.html thank you for your reference - http://bjbsair.com/2020-03-27/tech-info/7154/ The simplest way to accelerate the training of neural network is to use GPU. The speed of GPU in the normal operation (matrix multiplication and addition) of neural network is twice faster than that of CPU. As models or datasets grow larger, a GPU will soon become inadequate. For example, large language models such as BERT and GPT-2 are trained on hundreds of GPUs. For multi GPU training, a method of model and data segmentation and scheduling between different GPUs is needed.
Pytorch is a very popular deep learning framework, which has the best balance between flexibility and ease of use in the mainstream framework. There are two ways for Python to segment models and data on multiple GPUs: NN. DataParallel and nn.distributedataparallel. DataParallel is easier to use (simply wrap the single GPU model). However, since it uses a process to calculate model weights and then distribute them to each GPU during each batch, communication quickly becomes a bottleneck and GPU utilization is usually low. Moreover, nn.DataParallel requires all GPUs to be on the same node (distributed is not supported), and Apex cannot be used for mixed precision training. The main differences between NN. DataParallel and nn.distributedataparallel can be summarized as follows:
- DistributedDataParallel supports model parallelism, but DataParallel does not, which means that if the model is too large and the single card does not have enough memory, the former can only be used;
- DataParallel is single process and multi thread, only used for single card situation, while DistributedDataParallel is multi process, suitable for single machine and multi machine situation, and truly realizes distributed training;
- The training of distributed DataParallel is more efficient, because each process is an independent Python interpreter to avoid GIL problems, and its training speed is faster with low communication cost. Basically, DataParallel has been abandoned;
- It must be noted that each process in the distributed data parallel has its own optimizer, which performs its own update process, but the gradient is passed to each process through communication, and all executed contents are the same;
Generally speaking, the python document is quite complete and clear, especially after version 1.0x. However, there are few introductions about DistributedDataParallel. The main documents are as follows:
- Writing Distributed Applications with PyTorch: mainly introduces distributed API, distributed configuration, different communication mechanisms and internal mechanisms, but to be honest, most people don't agree to understand them, and they seldom use them directly;
- Getting Started with Distributed Data Parallel: it briefly introduces how to use distributed data parallel, but the use case is not clear and complete;
- ImageNet training in PyTorch: a relatively complete use case, but only code, lack of detailed description; (apex also provides a similar training case Mixed Precision ImageNet Training in PyTorch)
- (advanced) PyTorch 1.0 Distributed Trainer with Amazon AWS: how to conduct distributed training on Amazon cloud, but it is estimated that many people can't use it.
This tutorial will show you how to use PyTorch's distributed training with an example of MNISI. Here is a section of code for explanation, and it also includes any mixed precision training with apex.
Distributed data parallel internal mechanism
Distributed data parallel replicates models among multiple GPUs through multiple processes. Each GPU is controlled by one process (of course, each process can control multiple GPUs, but this is obviously slower than each process has one GPU; multiple processes can also run on one GPU). GPUs can be on the same node or distributed on multiple nodes. Each process performs the same tasks, and each process communicates with all other processes. Process or GPU only transfer gradient, so network communication is no longer the bottleneck.
During training, each process loads batch data from disk and passes them to its GPU. Each GPU has its own forward process, and then the gradient performs all reduce among GPUs. The gradient of each layer does not depend on the previous layer, so all reduce and backward process of the gradient are calculated at the same time to further alleviate the network bottleneck. At the end of the backward process, each node gets an average gradient, so that the model parameters keep synchronous.
This requires multiple processes (possibly on multiple nodes) to synchronize and communicate. Python does this through the distributed. Init? Process? Group function. He needs to know the location of process 0 so that all processes can be synchronized, as well as the expected total number of processes. Each process needs to know the total number of processes, their order in the process, and which GPU to use. Generally, the total number of processes is called world_size.python. nn.utils.data.DistributedSampler is provided to segment data for each process to ensure that the training data does not overlap.
Example explanation
This is explained by an example of MNIST. We first change it to distributed training, and then add hybrid precision training.
Ordinary single card training
First, import the required libraries:
import os from datetime import datetime import argparse import torch.multiprocessing as mp import torchvision import torchvision.transforms as transforms import torch import torch.nn as nn import torch.distributed as dist from apex.parallel import DistributedDataParallel as DDP from apex import amp
Then we define a simple CNN model to process MNIST data:
class ConvNet(nn.Module): def __init__(self, num_classes=10): super(ConvNet, self).__init__() self.layer1 = nn.Sequential( nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(16), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.layer2 = nn.Sequential( nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(32), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.fc = nn.Linear(7*7*32, num_classes) def forward(self, x): out = self.layer1(x) out = self.layer2(out) out = out.reshape(out.size(0), -1) out = self.fc(out) return out
The main function main() takes parameters and performs training:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() train(0, args)
The main function of the training part is:
def train(gpu, args): torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Data loading code train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True) train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True) start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() loss.backward() optimizer.step() if (i + 1) % 100 == 0 and gpu == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format( epoch + 1, args.epochs, i + 1, total_step, loss.item()) ) if gpu == 0: print("Training complete in: " + str(datetime.now() - start))
Start training by starting the main function:
if __name__ == '__main__': main()
You may notice that some parameters are redundant, but they are useful for later distributed training. We can train on a single stand-alone card by executing the following statements:
python src/mnist.py -n 1 -g 1 -nr 0
Distributed training
Using multi process for distributed training, we need to start a process for each GPU. Each process needs to know which GPU it is running on and its sequence number in all processes. For multiple nodes, we need to start scripts at each node.
First, we need to configure the basic parameters:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() ######################################################### args.world_size = args.gpus * args.nodes # os.environ['MASTER_ADDR'] = '10.57.23.164' # os.environ['MASTER_PORT'] = '8888' # mp.spawn(train, nprocs=args.gpus, args=(args,)) # #########################################################
Where args.nodes is the total number of nodes, while args.gpus is the total number of GPU per node (the number of GPU per node is the same), and args.nr is the serial number of the current node at all nodes. The total number of nodes multiplied by the number of GPUs of each node can get the world_size, that is, the total number of processes. All processes need to know the IP address and port of process 0, so that all processes can be synchronized at the beginning. Generally speaking, process 0 is the master process. For example, we will print information or save models in process 0. PyTorch provides mp.spawn to start all processes of the node at a node. Each process runs train(i, args), where i goes from 0 to args.gpus - 1.
Similarly, we need to modify the training function:
def train(gpu, args): ############################################################ rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank ) ############################################################ torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) ############################################################### # Wrap the model model = nn.parallel.DistributedDataParallel(model, device_ids=[gpu]) ############################################################### # Data loading code train_dataset = torchvision.datasets.MNIST( root='./data', train=True, transform=transforms.ToTensor(), download=True ) ################################################################ train_sampler = torch.utils.data.distributed.DistributedSampler( train_dataset, num_replicas=args.world_size, rank=rank ) ################################################################ train_loader = torch.utils.data.DataLoader( dataset=train_dataset, batch_size=batch_size, ############################## shuffle=False, # ############################## num_workers=0, pin_memory=True, ############################# sampler=train_sampler) # ############################# ...
Here we first calculate the forward program number: rank = args.nr * args.gpus + gpu, and then initialize the distributed environment through dist.init process group, where the backend parameter specifies the communication backend, including mpi, gloo, nccl. Here, nccl is selected, which is the official multi card communication framework provided by Nvidia, which is relatively efficient. MPI is also a common communication protocol for high-performance computing, but you need to install your own MPI implementation framework, such as OpenMPI. gloo is built-in communication backend, but it is not efficient enough. Init? Method refers to how to initialize to complete the process synchronization at the beginning; here we set env: / /, which refers to the initialization mode of environment variables. Four parameters need to be configured in the environment variables: Master ﹐ port, master ﹐ addr, world ﹐ size, rank. The first two parameters have been configured. The last two parameters can also be configured through the world ﹐ size and rank parameters in the dist.init ﹐ process ﹐ group function. Other initialization methods include shared file system and TCP, such as init method = tcp://10.1.1.20:23456 ', which also provides the IP address and port of the master. Note that this call is blocked and must wait for all processes to synchronize. If any process fails, it will fail.
For the model side, we just need to wrap the original model with distributed data parallel, which will support gradient all reduce operation. For the data side, we nn.utils.data.DistributedSampler to segment data for each process, just use this sampler in dataloader. It is worth noting that you need to call train train ﹐ sampler.set ﹐ epoch (epoch) at the beginning of each epoch in the cyclic process (mainly to ensure that the partition of each epoch is different). Other training codes remain unchanged.
Finally, the code can be executed. For example, if we are a 4-node and each node is an 8-card, we need to execute the code on four nodes respectively:
python src/mnist-distributed.py -n 4 -g 8 -nr i
It should be noted that the effective batch size at this time is actually batch size per GPU * world size. For models with BN, synchronous BN can also be used to achieve better results:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
The distributed training process described above is also applicable to the evaluation or test process. For example, we can divide the data into different processes for prediction, which can accelerate the prediction process. The implementation code is exactly the same as the above process, but if we want to calculate an indicator, we need to perform all reduce from the statistical results of each process, because each process is only the content of the calculated part of the data. For example, if we want to calculate the classification accuracy, we can count the total data of each process and the number of correctly classified counts, and then aggregate them. The point to be mentioned here is that when using dist.init ﹣ process ﹣ group to initialize the distributed environment, it is actually to establish a default distributed process group, which will also initialize the torch.distributed package of Python. In this way, we can directly use the torch.distributed API to perform basic distributed operations. The following is the specific implementation:
# define tensor on GPU, count and total is the result at each GPU t = torch.tensor([count, total], dtype=torch.float64, device='cuda') dist.barrier() # synchronizes all processes dist.all_reduce(t, op=torch.distributed.ReduceOp.SUM,) # Reduces the tensor data across all machines in such a way that all get the final result. t = t.tolist() all_count = int(t[0]) all_total = int(t[1]) acc = all_count / all_total
Mixed precision training (with apex)
Hybrid precision training (hybrid FP32 and FP16 training) can be applied to larger batch size, and can use NVIDIA Tensor Cores to accelerate calculation. Using NVIDIA's apex for hybrid precision training is very simple, only part of the code needs to be modified:
rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank) torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Wrap the model ############################################################## model, optimizer = amp.initialize(model, optimizer, opt_level='O2') model = DDP(model) ############################################################## # Data loading code ... start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() ############################################################## with amp.scale_loss(loss, optimizer) as scaled_loss: scaled_loss.backward() ############################################################## optimizer.step() ...
In fact, there are two changes. First, amp.initialize is used to package model and optimizer to support mixed precision training, in which opt'u level refers to the optimization level. If O0 or O3 is not the real mixed precision, but it can be used to determine the baseline of model effect and speed, and O1 and O2 are two settings of mixed precision, and one can be selected for mixed precision training. The other is that before updating the parameters according to the gradient, the gradient should be scaled through amp.scale'loss to prevent underflow. In addition, you can replace nn.DistributedDataParallel with apex.parallel.DistributedDataParallel.
Digression
I think the official distributed implementation of PyTorch has been relatively perfect, and the performance and effect are good. The alternative is horovod. It supports not only PyTorch but also TensorFlow and MXNet framework. It is easy to implement, and the speed should be comparable.
Reference resources
- Distributed data parallel training in Pytorch https://yangkky.github.io/2019/07/08/distributed-pytorch-tutorial.html (most content comes from here)
- torch.distributed Https://python.org/docs/stable/distributed.html thank you for your reference - http://bjbsair.com/2020-03-27/tech-info/7154/ The simplest way to accelerate the training of neural network is to use GPU. The speed of GPU in the normal operation (matrix multiplication and addition) of neural network is twice faster than that of CPU. As models or datasets grow larger, a GPU will soon become inadequate. For example, large language models such as BERT and GPT-2 are trained on hundreds of GPUs. For multi GPU training, a method of model and data segmentation and scheduling between different GPUs is needed.
Pytorch is a very popular deep learning framework, which has the best balance between flexibility and ease of use in the mainstream framework. There are two ways for Python to segment models and data on multiple GPUs: NN. DataParallel and nn.distributedataparallel. DataParallel is easier to use (simply wrap the single GPU model). However, since it uses a process to calculate model weights and then distribute them to each GPU during each batch, communication quickly becomes a bottleneck and GPU utilization is usually low. Moreover, nn.DataParallel requires all GPUs to be on the same node (distributed is not supported), and Apex cannot be used for mixed precision training. The main differences between NN. DataParallel and nn.distributedataparallel can be summarized as follows:
- DistributedDataParallel supports model parallelism, but DataParallel does not, which means that if the model is too large and the single card does not have enough memory, the former can only be used;
- DataParallel is single process and multi thread, only used for single card situation, while DistributedDataParallel is multi process, suitable for single machine and multi machine situation, and truly realizes distributed training;
- The training of distributed DataParallel is more efficient, because each process is an independent Python interpreter to avoid GIL problems, and its training speed is faster with low communication cost. Basically, DataParallel has been abandoned;
- It must be noted that each process in the distributed data parallel has its own optimizer, which performs its own update process, but the gradient is passed to each process through communication, and all executed contents are the same;
Generally speaking, the python document is quite complete and clear, especially after version 1.0x. However, there are few introductions about DistributedDataParallel. The main documents are as follows:
- Writing Distributed Applications with PyTorch: mainly introduces distributed API, distributed configuration, different communication mechanisms and internal mechanisms, but to be honest, most people don't agree to understand them, and they seldom use them directly;
- Getting Started with Distributed Data Parallel: it briefly introduces how to use distributed data parallel, but the use case is not clear and complete;
- ImageNet training in PyTorch: a relatively complete use case, but only code, lack of detailed description; (apex also provides a similar training case Mixed Precision ImageNet Training in PyTorch)
- (advanced) PyTorch 1.0 Distributed Trainer with Amazon AWS: how to conduct distributed training on Amazon cloud, but it is estimated that many people can't use it.
This tutorial will show you how to use PyTorch's distributed training with an example of MNISI. Here is a section of code for explanation, and it also includes any mixed precision training with apex.
Distributed data parallel internal mechanism
Distributed data parallel replicates models among multiple GPUs through multiple processes. Each GPU is controlled by one process (of course, each process can control multiple GPUs, but this is obviously slower than each process has one GPU; multiple processes can also run on one GPU). GPUs can be on the same node or distributed on multiple nodes. Each process performs the same tasks, and each process communicates with all other processes. Process or GPU only transfer gradient, so network communication is no longer the bottleneck.
During training, each process loads batch data from disk and passes them to its GPU. Each GPU has its own forward process, and then the gradient performs all reduce among GPUs. The gradient of each layer does not depend on the previous layer, so all reduce and backward process of the gradient are calculated at the same time to further alleviate the network bottleneck. At the end of the backward process, each node gets an average gradient, so that the model parameters keep synchronous.
This requires multiple processes (possibly on multiple nodes) to synchronize and communicate. Python does this through the distributed. Init? Process? Group function. He needs to know the location of process 0 so that all processes can be synchronized, as well as the expected total number of processes. Each process needs to know the total number of processes, their order in the process, and which GPU to use. Generally, the total number of processes is called world_size.python. nn.utils.data.DistributedSampler is provided to segment data for each process to ensure that the training data does not overlap.
Example explanation
This is explained by an example of MNIST. We first change it to distributed training, and then add hybrid precision training.
Ordinary single card training
First, import the required libraries:
import os from datetime import datetime import argparse import torch.multiprocessing as mp import torchvision import torchvision.transforms as transforms import torch import torch.nn as nn import torch.distributed as dist from apex.parallel import DistributedDataParallel as DDP from apex import amp
Then we define a simple CNN model to process MNIST data:
class ConvNet(nn.Module): def __init__(self, num_classes=10): super(ConvNet, self).__init__() self.layer1 = nn.Sequential( nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(16), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.layer2 = nn.Sequential( nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(32), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.fc = nn.Linear(7*7*32, num_classes) def forward(self, x): out = self.layer1(x) out = self.layer2(out) out = out.reshape(out.size(0), -1) out = self.fc(out) return out
The main function main() takes parameters and performs training:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() train(0, args)
The main function of the training part is:
def train(gpu, args): torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Data loading code train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True) train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True) start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() loss.backward() optimizer.step() if (i + 1) % 100 == 0 and gpu == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format( epoch + 1, args.epochs, i + 1, total_step, loss.item()) ) if gpu == 0: print("Training complete in: " + str(datetime.now() - start))
Start training by starting the main function:
if __name__ == '__main__': main()
You may notice that some parameters are redundant, but they are useful for later distributed training. We can train on a single stand-alone card by executing the following statements:
python src/mnist.py -n 1 -g 1 -nr 0
Distributed training
Using multi process for distributed training, we need to start a process for each GPU. Each process needs to know which GPU it is running on and its sequence number in all processes. For multiple nodes, we need to start scripts at each node.
First, we need to configure the basic parameters:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() ######################################################### args.world_size = args.gpus * args.nodes # os.environ['MASTER_ADDR'] = '10.57.23.164' # os.environ['MASTER_PORT'] = '8888' # mp.spawn(train, nprocs=args.gpus, args=(args,)) # #########################################################
Where args.nodes is the total number of nodes, while args.gpus is the total number of GPU per node (the number of GPU per node is the same), and args.nr is the serial number of the current node at all nodes. The total number of nodes multiplied by the number of GPUs of each node can get the world_size, that is, the total number of processes. All processes need to know the IP address and port of process 0, so that all processes can be synchronized at the beginning. Generally speaking, process 0 is the master process. For example, we will print information or save models in process 0. PyTorch provides mp.spawn to start all processes of the node at a node. Each process runs train(i, args), where i goes from 0 to args.gpus - 1.
Similarly, we need to modify the training function:
def train(gpu, args): ############################################################ rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank ) ############################################################ torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) ############################################################### # Wrap the model model = nn.parallel.DistributedDataParallel(model, device_ids=[gpu]) ############################################################### # Data loading code train_dataset = torchvision.datasets.MNIST( root='./data', train=True, transform=transforms.ToTensor(), download=True ) ################################################################ train_sampler = torch.utils.data.distributed.DistributedSampler( train_dataset, num_replicas=args.world_size, rank=rank ) ################################################################ train_loader = torch.utils.data.DataLoader( dataset=train_dataset, batch_size=batch_size, ############################## shuffle=False, # ############################## num_workers=0, pin_memory=True, ############################# sampler=train_sampler) # ############################# ...
Here we first calculate the forward program number: rank = args.nr * args.gpus + gpu, and then initialize the distributed environment through dist.init process group, where the backend parameter specifies the communication backend, including mpi, gloo, nccl. Here, nccl is selected, which is the official multi card communication framework provided by Nvidia, which is relatively efficient. MPI is also a common communication protocol for high-performance computing, but you need to install your own MPI implementation framework, such as OpenMPI. gloo is built-in communication backend, but it is not efficient enough. Init? Method refers to how to initialize to complete the process synchronization at the beginning; here we set env: / /, which refers to the initialization mode of environment variables. Four parameters need to be configured in the environment variables: Master ﹐ port, master ﹐ addr, world ﹐ size, rank. The first two parameters have been configured. The last two parameters can also be configured through the world ﹐ size and rank parameters in the dist.init ﹐ process ﹐ group function. Other initialization methods include shared file system and TCP, such as init method = tcp://10.1.1.20:23456 ', which also provides the IP address and port of the master. Note that this call is blocked and must wait for all processes to synchronize. If any process fails, it will fail.
For the model side, we just need to wrap the original model with distributed data parallel, which will support gradient all reduce operation. For the data side, we nn.utils.data.DistributedSampler to segment data for each process, just use this sampler in dataloader. It is worth noting that you need to call train train ﹐ sampler.set ﹐ epoch (epoch) at the beginning of each epoch in the cyclic process (mainly to ensure that the partition of each epoch is different). Other training codes remain unchanged.
Finally, the code can be executed. For example, if we are a 4-node and each node is an 8-card, we need to execute the code on four nodes respectively:
python src/mnist-distributed.py -n 4 -g 8 -nr i
It should be noted that the effective batch size at this time is actually batch size per GPU * world size. For models with BN, synchronous BN can also be used to achieve better results:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
The distributed training process described above is also applicable to the evaluation or test process. For example, we can divide the data into different processes for prediction, which can accelerate the prediction process. The implementation code is exactly the same as the above process, but if we want to calculate an indicator, we need to perform all reduce from the statistical results of each process, because each process is only the content of the calculated part of the data. For example, if we want to calculate the classification accuracy, we can count the total data of each process and the number of correctly classified counts, and then aggregate them. The point to be mentioned here is that when using dist.init ﹣ process ﹣ group to initialize the distributed environment, it is actually to establish a default distributed process group, which will also initialize the torch.distributed package of Python. In this way, we can directly use the torch.distributed API to perform basic distributed operations. The following is the specific implementation:
# define tensor on GPU, count and total is the result at each GPU t = torch.tensor([count, total], dtype=torch.float64, device='cuda') dist.barrier() # synchronizes all processes dist.all_reduce(t, op=torch.distributed.ReduceOp.SUM,) # Reduces the tensor data across all machines in such a way that all get the final result. t = t.tolist() all_count = int(t[0]) all_total = int(t[1]) acc = all_count / all_total
Mixed precision training (with apex)
Hybrid precision training (hybrid FP32 and FP16 training) can be applied to larger batch size, and can use NVIDIA Tensor Cores to accelerate calculation. Using NVIDIA's apex for hybrid precision training is very simple, only part of the code needs to be modified:
rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank) torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Wrap the model ############################################################## model, optimizer = amp.initialize(model, optimizer, opt_level='O2') model = DDP(model) ############################################################## # Data loading code ... start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() ############################################################## with amp.scale_loss(loss, optimizer) as scaled_loss: scaled_loss.backward() ############################################################## optimizer.step() ...
In fact, there are two changes. First, amp.initialize is used to package model and optimizer to support mixed precision training, in which opt'u level refers to the optimization level. If O0 or O3 is not the real mixed precision, but it can be used to determine the baseline of model effect and speed, and O1 and O2 are two settings of mixed precision, and one can be selected for mixed precision training. The other is that before updating the parameters according to the gradient, the gradient should be scaled through amp.scale'loss to prevent underflow. In addition, you can replace nn.DistributedDataParallel with apex.parallel.DistributedDataParallel.
Digression
I think the official distributed implementation of PyTorch has been relatively perfect, and the performance and effect are good. The alternative is horovod. It supports not only PyTorch but also TensorFlow and MXNet framework. It is easy to implement, and the speed should be comparable.
Reference resources
- Distributed data parallel training in Pytorch https://yangkky.github.io/2019/07/08/distributed-pytorch-tutorial.html (most content comes from here)
- torch.distributed Https://python.org/docs/stable/distributed.html thank you for your reference - http://bjbsair.com/2020-03-27/tech-info/7154/ The simplest way to accelerate the training of neural network is to use GPU. The speed of GPU in the normal operation (matrix multiplication and addition) of neural network is twice faster than that of CPU. As models or datasets grow larger, a GPU will soon become inadequate. For example, large language models such as BERT and GPT-2 are trained on hundreds of GPUs. For multi GPU training, a method of model and data segmentation and scheduling between different GPUs is needed.
Pytorch is a very popular deep learning framework, which has the best balance between flexibility and ease of use in the mainstream framework. There are two ways for Python to segment models and data on multiple GPUs: NN. DataParallel and nn.distributedataparallel. DataParallel is easier to use (simply wrap the single GPU model). However, since it uses a process to calculate model weights and then distribute them to each GPU during each batch, communication quickly becomes a bottleneck and GPU utilization is usually low. Moreover, nn.DataParallel requires all GPUs to be on the same node (distributed is not supported), and Apex cannot be used for mixed precision training. The main differences between NN. DataParallel and nn.distributedataparallel can be summarized as follows:
- DistributedDataParallel supports model parallelism, but DataParallel does not, which means that if the model is too large and the single card does not have enough memory, the former can only be used;
- DataParallel is single process and multi thread, only used for single card situation, while DistributedDataParallel is multi process, suitable for single machine and multi machine situation, and truly realizes distributed training;
- The training of distributed DataParallel is more efficient, because each process is an independent Python interpreter to avoid GIL problems, and its training speed is faster with low communication cost. Basically, DataParallel has been abandoned;
- It must be noted that each process in the distributed data parallel has its own optimizer, which performs its own update process, but the gradient is passed to each process through communication, and all executed contents are the same;
Generally speaking, the python document is quite complete and clear, especially after version 1.0x. However, there are few introductions about DistributedDataParallel. The main documents are as follows:
- Writing Distributed Applications with PyTorch: mainly introduces distributed API, distributed configuration, different communication mechanisms and internal mechanisms, but to be honest, most people don't agree to understand them, and they seldom use them directly;
- Getting Started with Distributed Data Parallel: it briefly introduces how to use distributed data parallel, but the use case is not clear and complete;
- ImageNet training in PyTorch: a relatively complete use case, but only code, lack of detailed description; (apex also provides a similar training case Mixed Precision ImageNet Training in PyTorch)
- (advanced) PyTorch 1.0 Distributed Trainer with Amazon AWS: how to conduct distributed training on Amazon cloud, but it is estimated that many people can't use it.
This tutorial will show you how to use PyTorch's distributed training with an example of MNISI. Here is a section of code for explanation, and it also includes any mixed precision training with apex.
Distributed data parallel internal mechanism
Distributed data parallel replicates models among multiple GPUs through multiple processes. Each GPU is controlled by one process (of course, each process can control multiple GPUs, but this is obviously slower than each process has one GPU; multiple processes can also run on one GPU). GPUs can be on the same node or distributed on multiple nodes. Each process performs the same tasks, and each process communicates with all other processes. Process or GPU only transfer gradient, so network communication is no longer the bottleneck.
During training, each process loads batch data from disk and passes them to its GPU. Each GPU has its own forward process, and then the gradient performs all reduce among GPUs. The gradient of each layer does not depend on the previous layer, so all reduce and backward process of the gradient are calculated at the same time to further alleviate the network bottleneck. At the end of the backward process, each node gets an average gradient, so that the model parameters keep synchronous.
This requires multiple processes (possibly on multiple nodes) to synchronize and communicate. Python does this through the distributed. Init? Process? Group function. He needs to know the location of process 0 so that all processes can be synchronized, as well as the expected total number of processes. Each process needs to know the total number of processes, their order in the process, and which GPU to use. Generally, the total number of processes is called world_size.python. nn.utils.data.DistributedSampler is provided to segment data for each process to ensure that the training data does not overlap.
Example explanation
This is explained by an example of MNIST. We first change it to distributed training, and then add hybrid precision training.
Ordinary single card training
First, import the required libraries:
import os from datetime import datetime import argparse import torch.multiprocessing as mp import torchvision import torchvision.transforms as transforms import torch import torch.nn as nn import torch.distributed as dist from apex.parallel import DistributedDataParallel as DDP from apex import amp
Then we define a simple CNN model to process MNIST data:
class ConvNet(nn.Module): def __init__(self, num_classes=10): super(ConvNet, self).__init__() self.layer1 = nn.Sequential( nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(16), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.layer2 = nn.Sequential( nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(32), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.fc = nn.Linear(7*7*32, num_classes) def forward(self, x): out = self.layer1(x) out = self.layer2(out) out = out.reshape(out.size(0), -1) out = self.fc(out) return out
The main function main() takes parameters and performs training:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() train(0, args)
The main function of the training part is:
def train(gpu, args): torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Data loading code train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True) train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True) start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() loss.backward() optimizer.step() if (i + 1) % 100 == 0 and gpu == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format( epoch + 1, args.epochs, i + 1, total_step, loss.item()) ) if gpu == 0: print("Training complete in: " + str(datetime.now() - start))
Start training by starting the main function:
if __name__ == '__main__': main()
You may notice that some parameters are redundant, but they are useful for later distributed training. We can train on a single stand-alone card by executing the following statements:
python src/mnist.py -n 1 -g 1 -nr 0
Distributed training
Using multi process for distributed training, we need to start a process for each GPU. Each process needs to know which GPU it is running on and its sequence number in all processes. For multiple nodes, we need to start scripts at each node.
First, we need to configure the basic parameters:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() ######################################################### args.world_size = args.gpus * args.nodes # os.environ['MASTER_ADDR'] = '10.57.23.164' # os.environ['MASTER_PORT'] = '8888' # mp.spawn(train, nprocs=args.gpus, args=(args,)) # #########################################################
Where args.nodes is the total number of nodes, while args.gpus is the total number of GPU per node (the number of GPU per node is the same), and args.nr is the serial number of the current node at all nodes. The total number of nodes multiplied by the number of GPUs of each node can get the world_size, that is, the total number of processes. All processes need to know the IP address and port of process 0, so that all processes can be synchronized at the beginning. Generally speaking, process 0 is the master process. For example, we will print information or save models in process 0. PyTorch provides mp.spawn to start all processes of the node at a node. Each process runs train(i, args), where i goes from 0 to args.gpus - 1.
Similarly, we need to modify the training function:
def train(gpu, args): ############################################################ rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank ) ############################################################ torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) ############################################################### # Wrap the model model = nn.parallel.DistributedDataParallel(model, device_ids=[gpu]) ############################################################### # Data loading code train_dataset = torchvision.datasets.MNIST( root='./data', train=True, transform=transforms.ToTensor(), download=True ) ################################################################ train_sampler = torch.utils.data.distributed.DistributedSampler( train_dataset, num_replicas=args.world_size, rank=rank ) ################################################################ train_loader = torch.utils.data.DataLoader( dataset=train_dataset, batch_size=batch_size, ############################## shuffle=False, # ############################## num_workers=0, pin_memory=True, ############################# sampler=train_sampler) # ############################# ...
Here we first calculate the forward program number: rank = args.nr * args.gpus + gpu, and then initialize the distributed environment through dist.init process group, where the backend parameter specifies the communication backend, including mpi, gloo, nccl. Here, nccl is selected, which is the official multi card communication framework provided by Nvidia, which is relatively efficient. MPI is also a common communication protocol for high-performance computing, but you need to install your own MPI implementation framework, such as OpenMPI. gloo is built-in communication backend, but it is not efficient enough. Init? Method refers to how to initialize to complete the process synchronization at the beginning; here we set env: / /, which refers to the initialization mode of environment variables. Four parameters need to be configured in the environment variables: Master ﹐ port, master ﹐ addr, world ﹐ size, rank. The first two parameters have been configured. The last two parameters can also be configured through the world ﹐ size and rank parameters in the dist.init ﹐ process ﹐ group function. Other initialization methods include shared file system and TCP, such as init method = tcp://10.1.1.20:23456 ', which also provides the IP address and port of the master. Note that this call is blocked and must wait for all processes to synchronize. If any process fails, it will fail.
For the model side, we just need to wrap the original model with distributed data parallel, which will support gradient all reduce operation. For the data side, we nn.utils.data.DistributedSampler to segment data for each process, just use this sampler in dataloader. It is worth noting that you need to call train train ﹐ sampler.set ﹐ epoch (epoch) at the beginning of each epoch in the cyclic process (mainly to ensure that the partition of each epoch is different). Other training codes remain unchanged.
Finally, the code can be executed. For example, if we are a 4-node and each node is an 8-card, we need to execute the code on four nodes respectively:
python src/mnist-distributed.py -n 4 -g 8 -nr i
It should be noted that the effective batch size at this time is actually batch size per GPU * world size. For models with BN, synchronous BN can also be used to achieve better results:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
The distributed training process described above is also applicable to the evaluation or test process. For example, we can divide the data into different processes for prediction, which can accelerate the prediction process. The implementation code is exactly the same as the above process, but if we want to calculate an indicator, we need to perform all reduce from the statistical results of each process, because each process is only the content of the calculated part of the data. For example, if we want to calculate the classification accuracy, we can count the total data of each process and the number of correctly classified counts, and then aggregate them. The point to be mentioned here is that when using dist.init ﹣ process ﹣ group to initialize the distributed environment, it is actually to establish a default distributed process group, which will also initialize the torch.distributed package of Python. In this way, we can directly use the torch.distributed API to perform basic distributed operations. The following is the specific implementation:
# define tensor on GPU, count and total is the result at each GPU t = torch.tensor([count, total], dtype=torch.float64, device='cuda') dist.barrier() # synchronizes all processes dist.all_reduce(t, op=torch.distributed.ReduceOp.SUM,) # Reduces the tensor data across all machines in such a way that all get the final result. t = t.tolist() all_count = int(t[0]) all_total = int(t[1]) acc = all_count / all_total
Mixed precision training (with apex)
Hybrid precision training (hybrid FP32 and FP16 training) can be applied to larger batch size, and can use NVIDIA Tensor Cores to accelerate calculation. Using NVIDIA's apex for hybrid precision training is very simple, only part of the code needs to be modified:
rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank) torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Wrap the model ############################################################## model, optimizer = amp.initialize(model, optimizer, opt_level='O2') model = DDP(model) ############################################################## # Data loading code ... start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() ############################################################## with amp.scale_loss(loss, optimizer) as scaled_loss: scaled_loss.backward() ############################################################## optimizer.step() ...
In fact, there are two changes. First, amp.initialize is used to package model and optimizer to support mixed precision training, in which opt'u level refers to the optimization level. If O0 or O3 is not the real mixed precision, but it can be used to determine the baseline of model effect and speed, and O1 and O2 are two settings of mixed precision, and one can be selected for mixed precision training. The other is that before updating the parameters according to the gradient, the gradient should be scaled through amp.scale'loss to prevent underflow. In addition, you can replace nn.DistributedDataParallel with apex.parallel.DistributedDataParallel.
Digression
I think the official distributed implementation of PyTorch has been relatively perfect, and the performance and effect are good. The alternative is horovod. It supports not only PyTorch but also TensorFlow and MXNet framework. It is easy to implement, and the speed should be comparable.
Reference resources
- Distributed data parallel training in Pytorch https://yangkky.github.io/2019/07/08/distributed-pytorch-tutorial.html (most content comes from here)
- torch.distributed Https://python.org/docs/stable/distributed.html thank you for your reference - http://bjbsair.com/2020-03-27/tech-info/7154/ The simplest way to accelerate the training of neural network is to use GPU. The speed of GPU in the normal operation (matrix multiplication and addition) of neural network is twice faster than that of CPU. As models or datasets grow larger, a GPU will soon become inadequate. For example, large language models such as BERT and GPT-2 are trained on hundreds of GPUs. For multi GPU training, a method of model and data segmentation and scheduling between different GPUs is needed.
Pytorch is a very popular deep learning framework, which has the best balance between flexibility and ease of use in the mainstream framework. There are two ways for Python to segment models and data on multiple GPUs: NN. DataParallel and nn.distributedataparallel. DataParallel is easier to use (simply wrap the single GPU model). However, since it uses a process to calculate model weights and then distribute them to each GPU during each batch, communication quickly becomes a bottleneck and GPU utilization is usually low. Moreover, nn.DataParallel requires all GPUs to be on the same node (distributed is not supported), and Apex cannot be used for mixed precision training. The main differences between NN. DataParallel and nn.distributedataparallel can be summarized as follows:
- DistributedDataParallel supports model parallelism, but DataParallel does not, which means that if the model is too large and the single card does not have enough memory, the former can only be used;
- DataParallel is single process and multi thread, only used for single card situation, while DistributedDataParallel is multi process, suitable for single machine and multi machine situation, and truly realizes distributed training;
- The training of distributed DataParallel is more efficient, because each process is an independent Python interpreter to avoid GIL problems, and its training speed is faster with low communication cost. Basically, DataParallel has been abandoned;
- It must be noted that each process in the distributed data parallel has its own optimizer, which performs its own update process, but the gradient is passed to each process through communication, and all executed contents are the same;
Generally speaking, the python document is quite complete and clear, especially after version 1.0x. However, there are few introductions about DistributedDataParallel. The main documents are as follows:
- Writing Distributed Applications with PyTorch: mainly introduces distributed API, distributed configuration, different communication mechanisms and internal mechanisms, but to be honest, most people don't agree to understand them, and they seldom use them directly;
- Getting Started with Distributed Data Parallel: it briefly introduces how to use distributed data parallel, but the use case is not clear and complete;
- ImageNet training in PyTorch: a relatively complete use case, but only code, lack of detailed description; (apex also provides a similar training case Mixed Precision ImageNet Training in PyTorch)
- (advanced) PyTorch 1.0 Distributed Trainer with Amazon AWS: how to conduct distributed training on Amazon cloud, but it is estimated that many people can't use it.
This tutorial will show you how to use PyTorch's distributed training with an example of MNISI. Here is a section of code for explanation, and it also includes any mixed precision training with apex.
Distributed data parallel internal mechanism
Distributed data parallel replicates models among multiple GPUs through multiple processes. Each GPU is controlled by one process (of course, each process can control multiple GPUs, but this is obviously slower than each process has one GPU; multiple processes can also run on one GPU). GPUs can be on the same node or distributed on multiple nodes. Each process performs the same tasks, and each process communicates with all other processes. Process or GPU only transfer gradient, so network communication is no longer the bottleneck.
During training, each process loads batch data from disk and passes them to its GPU. Each GPU has its own forward process, and then the gradient performs all reduce among GPUs. The gradient of each layer does not depend on the previous layer, so all reduce and backward process of the gradient are calculated at the same time to further alleviate the network bottleneck. At the end of the backward process, each node gets an average gradient, so that the model parameters keep synchronous.
This requires multiple processes (possibly on multiple nodes) to synchronize and communicate. Python does this through the distributed. Init? Process? Group function. He needs to know the location of process 0 so that all processes can be synchronized, as well as the expected total number of processes. Each process needs to know the total number of processes, their order in the process, and which GPU to use. Generally, the total number of processes is called world_size.python. nn.utils.data.DistributedSampler is provided to segment data for each process to ensure that the training data does not overlap.
Example explanation
This is explained by an example of MNIST. We first change it to distributed training, and then add hybrid precision training.
Ordinary single card training
First, import the required libraries:
import os from datetime import datetime import argparse import torch.multiprocessing as mp import torchvision import torchvision.transforms as transforms import torch import torch.nn as nn import torch.distributed as dist from apex.parallel import DistributedDataParallel as DDP from apex import amp
Then we define a simple CNN model to process MNIST data:
class ConvNet(nn.Module): def __init__(self, num_classes=10): super(ConvNet, self).__init__() self.layer1 = nn.Sequential( nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(16), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.layer2 = nn.Sequential( nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(32), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.fc = nn.Linear(7*7*32, num_classes) def forward(self, x): out = self.layer1(x) out = self.layer2(out) out = out.reshape(out.size(0), -1) out = self.fc(out) return out
The main function main() takes parameters and performs training:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() train(0, args)
The main function of the training part is:
def train(gpu, args): torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Data loading code train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True) train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True) start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() loss.backward() optimizer.step() if (i + 1) % 100 == 0 and gpu == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format( epoch + 1, args.epochs, i + 1, total_step, loss.item()) ) if gpu == 0: print("Training complete in: " + str(datetime.now() - start))
Start training by starting the main function:
if __name__ == '__main__': main()
You may notice that some parameters are redundant, but they are useful for later distributed training. We can train on a single stand-alone card by executing the following statements:
python src/mnist.py -n 1 -g 1 -nr 0
Distributed training
Using multi process for distributed training, we need to start a process for each GPU. Each process needs to know which GPU it is running on and its sequence number in all processes. For multiple nodes, we need to start scripts at each node.
First, we need to configure the basic parameters:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() ######################################################### args.world_size = args.gpus * args.nodes # os.environ['MASTER_ADDR'] = '10.57.23.164' # os.environ['MASTER_PORT'] = '8888' # mp.spawn(train, nprocs=args.gpus, args=(args,)) # #########################################################
Where args.nodes is the total number of nodes, while args.gpus is the total number of GPU per node (the number of GPU per node is the same), and args.nr is the serial number of the current node at all nodes. The total number of nodes multiplied by the number of GPUs of each node can get the world_size, that is, the total number of processes. All processes need to know the IP address and port of process 0, so that all processes can be synchronized at the beginning. Generally speaking, process 0 is the master process. For example, we will print information or save models in process 0. PyTorch provides mp.spawn to start all processes of the node at a node. Each process runs train(i, args), where i goes from 0 to args.gpus - 1.
Similarly, we need to modify the training function:
def train(gpu, args): ############################################################ rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank ) ############################################################ torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) ############################################################### # Wrap the model model = nn.parallel.DistributedDataParallel(model, device_ids=[gpu]) ############################################################### # Data loading code train_dataset = torchvision.datasets.MNIST( root='./data', train=True, transform=transforms.ToTensor(), download=True ) ################################################################ train_sampler = torch.utils.data.distributed.DistributedSampler( train_dataset, num_replicas=args.world_size, rank=rank ) ################################################################ train_loader = torch.utils.data.DataLoader( dataset=train_dataset, batch_size=batch_size, ############################## shuffle=False, # ############################## num_workers=0, pin_memory=True, ############################# sampler=train_sampler) # ############################# ...
Here we first calculate the forward program number: rank = args.nr * args.gpus + gpu, and then initialize the distributed environment through dist.init process group, where the backend parameter specifies the communication backend, including mpi, gloo, nccl. Here, nccl is selected, which is the official multi card communication framework provided by Nvidia, which is relatively efficient. MPI is also a common communication protocol for high-performance computing, but you need to install your own MPI implementation framework, such as OpenMPI. gloo is built-in communication backend, but it is not efficient enough. Init? Method refers to how to initialize to complete the process synchronization at the beginning; here we set env: / /, which refers to the initialization mode of environment variables. Four parameters need to be configured in the environment variables: Master ﹐ port, master ﹐ addr, world ﹐ size, rank. The first two parameters have been configured. The last two parameters can also be configured through the world ﹐ size and rank parameters in the dist.init ﹐ process ﹐ group function. Other initialization methods include shared file system and TCP, such as init method = tcp://10.1.1.20:23456 ', which also provides the IP address and port of the master. Note that this call is blocked and must wait for all processes to synchronize. If any process fails, it will fail.
For the model side, we just need to wrap the original model with distributed data parallel, which will support gradient all reduce operation. For the data side, we nn.utils.data.DistributedSampler to segment data for each process, just use this sampler in dataloader. It is worth noting that you need to call train train ﹐ sampler.set ﹐ epoch (epoch) at the beginning of each epoch in the cyclic process (mainly to ensure that the partition of each epoch is different). Other training codes remain unchanged.
Finally, the code can be executed. For example, if we are a 4-node and each node is an 8-card, we need to execute the code on four nodes respectively:
python src/mnist-distributed.py -n 4 -g 8 -nr i
It should be noted that the effective batch size at this time is actually batch size per GPU * world size. For models with BN, synchronous BN can also be used to achieve better results:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
The distributed training process described above is also applicable to the evaluation or test process. For example, we can divide the data into different processes for prediction, which can accelerate the prediction process. The implementation code is exactly the same as the above process, but if we want to calculate an indicator, we need to perform all reduce from the statistical results of each process, because each process is only the content of the calculated part of the data. For example, if we want to calculate the classification accuracy, we can count the total data of each process and the number of correctly classified counts, and then aggregate them. The point to be mentioned here is that when using dist.init ﹣ process ﹣ group to initialize the distributed environment, it is actually to establish a default distributed process group, which will also initialize the torch.distributed package of Python. In this way, we can directly use the torch.distributed API to perform basic distributed operations. The following is the specific implementation:
# define tensor on GPU, count and total is the result at each GPU t = torch.tensor([count, total], dtype=torch.float64, device='cuda') dist.barrier() # synchronizes all processes dist.all_reduce(t, op=torch.distributed.ReduceOp.SUM,) # Reduces the tensor data across all machines in such a way that all get the final result. t = t.tolist() all_count = int(t[0]) all_total = int(t[1]) acc = all_count / all_total
Mixed precision training (with apex)
Hybrid precision training (hybrid FP32 and FP16 training) can be applied to larger batch size, and can use NVIDIA Tensor Cores to accelerate calculation. Using NVIDIA's apex for hybrid precision training is very simple, only part of the code needs to be modified:
rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank) torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Wrap the model ############################################################## model, optimizer = amp.initialize(model, optimizer, opt_level='O2') model = DDP(model) ############################################################## # Data loading code ... start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() ############################################################## with amp.scale_loss(loss, optimizer) as scaled_loss: scaled_loss.backward() ############################################################## optimizer.step() ...
In fact, there are two changes. First, amp.initialize is used to package model and optimizer to support mixed precision training, in which opt'u level refers to the optimization level. If O0 or O3 is not the real mixed precision, but it can be used to determine the baseline of model effect and speed, and O1 and O2 are two settings of mixed precision, and one can be selected for mixed precision training. The other is that before updating the parameters according to the gradient, the gradient should be scaled through amp.scale'loss to prevent underflow. In addition, you can replace nn.DistributedDataParallel with apex.parallel.DistributedDataParallel.
Digression
I think the official distributed implementation of PyTorch has been relatively perfect, and the performance and effect are good. The alternative is horovod. It supports not only PyTorch but also TensorFlow and MXNet framework. It is easy to implement, and the speed should be comparable.
Reference resources
- Distributed data parallel training in Pytorch https://yangkky.github.io/2019/07/08/distributed-pytorch-tutorial.html (most content comes from here)
- torch.distributed Https://python.org/docs/stable/distributed.html thank you for your reference - http://bjbsair.com/2020-03-27/tech-info/7154/ The simplest way to accelerate the training of neural network is to use GPU. The speed of GPU in the normal operation (matrix multiplication and addition) of neural network is twice faster than that of CPU. As models or datasets grow larger, a GPU will soon become inadequate. For example, large language models such as BERT and GPT-2 are trained on hundreds of GPUs. For multi GPU training, a method of model and data segmentation and scheduling between different GPUs is needed.
Pytorch is a very popular deep learning framework, which has the best balance between flexibility and ease of use in the mainstream framework. There are two ways for Python to segment models and data on multiple GPUs: NN. DataParallel and nn.distributedataparallel. DataParallel is easier to use (simply wrap the single GPU model). However, since it uses a process to calculate model weights and then distribute them to each GPU during each batch, communication quickly becomes a bottleneck and GPU utilization is usually low. Moreover, nn.DataParallel requires all GPUs to be on the same node (distributed is not supported), and Apex cannot be used for mixed precision training. The main differences between NN. DataParallel and nn.distributedataparallel can be summarized as follows:
- DistributedDataParallel supports model parallelism, but DataParallel does not, which means that if the model is too large and the single card does not have enough memory, the former can only be used;
- DataParallel is single process and multi thread, only used for single card situation, while DistributedDataParallel is multi process, suitable for single machine and multi machine situation, and truly realizes distributed training;
- The training of distributed DataParallel is more efficient, because each process is an independent Python interpreter to avoid GIL problems, and its training speed is faster with low communication cost. Basically, DataParallel has been abandoned;
- It must be noted that each process in the distributed data parallel has its own optimizer, which performs its own update process, but the gradient is passed to each process through communication, and all executed contents are the same;
Generally speaking, the python document is quite complete and clear, especially after version 1.0x. However, there are few introductions about DistributedDataParallel. The main documents are as follows:
- Writing Distributed Applications with PyTorch: mainly introduces distributed API, distributed configuration, different communication mechanisms and internal mechanisms, but to be honest, most people don't agree to understand them, and they seldom use them directly;
- Getting Started with Distributed Data Parallel: it briefly introduces how to use distributed data parallel, but the use case is not clear and complete;
- ImageNet training in PyTorch: a relatively complete use case, but only code, lack of detailed description; (apex also provides a similar training case Mixed Precision ImageNet Training in PyTorch)
- (advanced) PyTorch 1.0 Distributed Trainer with Amazon AWS: how to conduct distributed training on Amazon cloud, but it is estimated that many people can't use it.
This tutorial will show you how to use PyTorch's distributed training with an example of MNISI. Here is a section of code for explanation, and it also includes any mixed precision training with apex.
Distributed data parallel internal mechanism
Distributed data parallel replicates models among multiple GPUs through multiple processes. Each GPU is controlled by one process (of course, each process can control multiple GPUs, but this is obviously slower than each process has one GPU; multiple processes can also run on one GPU). GPUs can be on the same node or distributed on multiple nodes. Each process performs the same tasks, and each process communicates with all other processes. Process or GPU only transfer gradient, so network communication is no longer the bottleneck.
During training, each process loads batch data from disk and passes them to its GPU. Each GPU has its own forward process, and then the gradient performs all reduce among GPUs. The gradient of each layer does not depend on the previous layer, so all reduce and backward process of the gradient are calculated at the same time to further alleviate the network bottleneck. At the end of the backward process, each node gets an average gradient, so that the model parameters keep synchronous.
This requires multiple processes (possibly on multiple nodes) to synchronize and communicate. Python does this through the distributed. Init? Process? Group function. He needs to know the location of process 0 so that all processes can be synchronized, as well as the expected total number of processes. Each process needs to know the total number of processes, their order in the process, and which GPU to use. Generally, the total number of processes is called world_size.python. nn.utils.data.DistributedSampler is provided to segment data for each process to ensure that the training data does not overlap.
Example explanation
This is explained by an example of MNIST. We first change it to distributed training, and then add hybrid precision training.
Ordinary single card training
First, import the required libraries:
import os from datetime import datetime import argparse import torch.multiprocessing as mp import torchvision import torchvision.transforms as transforms import torch import torch.nn as nn import torch.distributed as dist from apex.parallel import DistributedDataParallel as DDP from apex import amp
Then we define a simple CNN model to process MNIST data:
class ConvNet(nn.Module): def __init__(self, num_classes=10): super(ConvNet, self).__init__() self.layer1 = nn.Sequential( nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(16), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.layer2 = nn.Sequential( nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(32), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.fc = nn.Linear(7*7*32, num_classes) def forward(self, x): out = self.layer1(x) out = self.layer2(out) out = out.reshape(out.size(0), -1) out = self.fc(out) return out
The main function main() takes parameters and performs training:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() train(0, args)
The main function of the training part is:
def train(gpu, args): torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Data loading code train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True) train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True) start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() loss.backward() optimizer.step() if (i + 1) % 100 == 0 and gpu == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format( epoch + 1, args.epochs, i + 1, total_step, loss.item()) ) if gpu == 0: print("Training complete in: " + str(datetime.now() - start))
Start training by starting the main function:
if __name__ == '__main__': main()
You may notice that some parameters are redundant, but they are useful for later distributed training. We can train on a single stand-alone card by executing the following statements:
python src/mnist.py -n 1 -g 1 -nr 0
Distributed training
Using multi process for distributed training, we need to start a process for each GPU. Each process needs to know which GPU it is running on and its sequence number in all processes. For multiple nodes, we need to start scripts at each node.
First, we need to configure the basic parameters:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() ######################################################### args.world_size = args.gpus * args.nodes # os.environ['MASTER_ADDR'] = '10.57.23.164' # os.environ['MASTER_PORT'] = '8888' # mp.spawn(train, nprocs=args.gpus, args=(args,)) # #########################################################
Where args.nodes is the total number of nodes, while args.gpus is the total number of GPU per node (the number of GPU per node is the same), and args.nr is the serial number of the current node at all nodes. The total number of nodes multiplied by the number of GPUs of each node can get the world_size, that is, the total number of processes. All processes need to know the IP address and port of process 0, so that all processes can be synchronized at the beginning. Generally speaking, process 0 is the master process. For example, we will print information or save models in process 0. PyTorch provides mp.spawn to start all processes of the node at a node. Each process runs train(i, args), where i goes from 0 to args.gpus - 1.
Similarly, we need to modify the training function:
def train(gpu, args): ############################################################ rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank ) ############################################################ torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) ############################################################### # Wrap the model model = nn.parallel.DistributedDataParallel(model, device_ids=[gpu]) ############################################################### # Data loading code train_dataset = torchvision.datasets.MNIST( root='./data', train=True, transform=transforms.ToTensor(), download=True ) ################################################################ train_sampler = torch.utils.data.distributed.DistributedSampler( train_dataset, num_replicas=args.world_size, rank=rank ) ################################################################ train_loader = torch.utils.data.DataLoader( dataset=train_dataset, batch_size=batch_size, ############################## shuffle=False, # ############################## num_workers=0, pin_memory=True, ############################# sampler=train_sampler) # ############################# ...
Here we first calculate the forward program number: rank = args.nr * args.gpus + gpu, and then initialize the distributed environment through dist.init process group, where the backend parameter specifies the communication backend, including mpi, gloo, nccl. Here, nccl is selected, which is the official multi card communication framework provided by Nvidia, which is relatively efficient. MPI is also a common communication protocol for high-performance computing, but you need to install your own MPI implementation framework, such as OpenMPI. gloo is built-in communication backend, but it is not efficient enough. Init? Method refers to how to initialize to complete the process synchronization at the beginning; here we set env: / /, which refers to the initialization mode of environment variables. Four parameters need to be configured in the environment variables: Master ﹐ port, master ﹐ addr, world ﹐ size, rank. The first two parameters have been configured. The last two parameters can also be configured through the world ﹐ size and rank parameters in the dist.init ﹐ process ﹐ group function. Other initialization methods include shared file system and TCP, such as init method = tcp://10.1.1.20:23456 ', which also provides the IP address and port of the master. Note that this call is blocked and must wait for all processes to synchronize. If any process fails, it will fail.
For the model side, we just need to wrap the original model with distributed data parallel, which will support gradient all reduce operation. For the data side, we nn.utils.data.DistributedSampler to segment data for each process, just use this sampler in dataloader. It is worth noting that you need to call train train ﹐ sampler.set ﹐ epoch (epoch) at the beginning of each epoch in the cyclic process (mainly to ensure that the partition of each epoch is different). Other training codes remain unchanged.
Finally, the code can be executed. For example, if we are a 4-node and each node is an 8-card, we need to execute the code on four nodes respectively:
python src/mnist-distributed.py -n 4 -g 8 -nr i
It should be noted that the effective batch size at this time is actually batch size per GPU * world size. For models with BN, synchronous BN can also be used to achieve better results:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
The distributed training process described above is also applicable to the evaluation or test process. For example, we can divide the data into different processes for prediction, which can accelerate the prediction process. The implementation code is exactly the same as the above process, but if we want to calculate an indicator, we need to perform all reduce from the statistical results of each process, because each process is only the content of the calculated part of the data. For example, if we want to calculate the classification accuracy, we can count the total data of each process and the number of correctly classified counts, and then aggregate them. The point to be mentioned here is that when using dist.init ﹣ process ﹣ group to initialize the distributed environment, it is actually to establish a default distributed process group, which will also initialize the torch.distributed package of Python. In this way, we can directly use the torch.distributed API to perform basic distributed operations. The following is the specific implementation:
# define tensor on GPU, count and total is the result at each GPU t = torch.tensor([count, total], dtype=torch.float64, device='cuda') dist.barrier() # synchronizes all processes dist.all_reduce(t, op=torch.distributed.ReduceOp.SUM,) # Reduces the tensor data across all machines in such a way that all get the final result. t = t.tolist() all_count = int(t[0]) all_total = int(t[1]) acc = all_count / all_total
Mixed precision training (with apex)
Hybrid precision training (hybrid FP32 and FP16 training) can be applied to larger batch size, and can use NVIDIA Tensor Cores to accelerate calculation. Using NVIDIA's apex for hybrid precision training is very simple, only part of the code needs to be modified:
rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank) torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Wrap the model ############################################################## model, optimizer = amp.initialize(model, optimizer, opt_level='O2') model = DDP(model) ############################################################## # Data loading code ... start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() ############################################################## with amp.scale_loss(loss, optimizer) as scaled_loss: scaled_loss.backward() ############################################################## optimizer.step() ...
In fact, there are two changes. First, amp.initialize is used to package model and optimizer to support mixed precision training, in which opt'u level refers to the optimization level. If O0 or O3 is not the real mixed precision, but it can be used to determine the baseline of model effect and speed, and O1 and O2 are two settings of mixed precision, and one can be selected for mixed precision training. The other is that before updating the parameters according to the gradient, the gradient should be scaled through amp.scale'loss to prevent underflow. In addition, you can replace nn.DistributedDataParallel with apex.parallel.DistributedDataParallel.
Digression
I think the official distributed implementation of PyTorch has been relatively perfect, and the performance and effect are good. The alternative is horovod. It supports not only PyTorch but also TensorFlow and MXNet framework. It is easy to implement, and the speed should be comparable.
Reference resources
- Distributed data parallel training in Pytorch https://yangkky.github.io/2019/07/08/distributed-pytorch-tutorial.html (most content comes from here)
- torch.distributed Https://python.org/docs/stable/distributed.html thank you for your reference - http://bjbsair.com/2020-03-27/tech-info/7154/ The simplest way to accelerate the training of neural network is to use GPU. The speed of GPU in the normal operation (matrix multiplication and addition) of neural network is twice faster than that of CPU. As models or datasets grow larger, a GPU will soon become inadequate. For example, large language models such as BERT and GPT-2 are trained on hundreds of GPUs. For multi GPU training, a method of model and data segmentation and scheduling between different GPUs is needed.
Pytorch is a very popular deep learning framework, which has the best balance between flexibility and ease of use in the mainstream framework. There are two ways for Python to segment models and data on multiple GPUs: NN. DataParallel and nn.distributedataparallel. DataParallel is easier to use (simply wrap the single GPU model). However, since it uses a process to calculate model weights and then distribute them to each GPU during each batch, communication quickly becomes a bottleneck and GPU utilization is usually low. Moreover, nn.DataParallel requires all GPUs to be on the same node (distributed is not supported), and Apex cannot be used for mixed precision training. The main differences between NN. DataParallel and nn.distributedataparallel can be summarized as follows:
- DistributedDataParallel supports model parallelism, but DataParallel does not, which means that if the model is too large and the single card does not have enough memory, the former can only be used;
- DataParallel is single process and multi thread, only used for single card situation, while DistributedDataParallel is multi process, suitable for single machine and multi machine situation, and truly realizes distributed training;
- The training of distributed DataParallel is more efficient, because each process is an independent Python interpreter to avoid GIL problems, and its training speed is faster with low communication cost. Basically, DataParallel has been abandoned;
- It must be noted that each process in the distributed data parallel has its own optimizer, which performs its own update process, but the gradient is passed to each process through communication, and all executed contents are the same;
Generally speaking, the python document is quite complete and clear, especially after version 1.0x. However, there are few introductions about DistributedDataParallel. The main documents are as follows:
- Writing Distributed Applications with PyTorch: mainly introduces distributed API, distributed configuration, different communication mechanisms and internal mechanisms, but to be honest, most people don't agree to understand them, and they seldom use them directly;
- Getting Started with Distributed Data Parallel: it briefly introduces how to use distributed data parallel, but the use case is not clear and complete;
- ImageNet training in PyTorch: a relatively complete use case, but only code, lack of detailed description; (apex also provides a similar training case Mixed Precision ImageNet Training in PyTorch)
- (advanced) PyTorch 1.0 Distributed Trainer with Amazon AWS: how to conduct distributed training on Amazon cloud, but it is estimated that many people can't use it.
This tutorial will show you how to use PyTorch's distributed training with an example of MNISI. Here is a section of code for explanation, and it also includes any mixed precision training with apex.
Distributed data parallel internal mechanism
Distributed data parallel replicates models among multiple GPUs through multiple processes. Each GPU is controlled by one process (of course, each process can control multiple GPUs, but this is obviously slower than each process has one GPU; multiple processes can also run on one GPU). GPUs can be on the same node or distributed on multiple nodes. Each process performs the same tasks, and each process communicates with all other processes. Process or GPU only transfer gradient, so network communication is no longer the bottleneck.
During training, each process loads batch data from disk and passes them to its GPU. Each GPU has its own forward process, and then the gradient performs all reduce among GPUs. The gradient of each layer does not depend on the previous layer, so all reduce and backward process of the gradient are calculated at the same time to further alleviate the network bottleneck. At the end of the backward process, each node gets an average gradient, so that the model parameters keep synchronous.
This requires multiple processes (possibly on multiple nodes) to synchronize and communicate. Python does this through the distributed. Init? Process? Group function. He needs to know the location of process 0 so that all processes can be synchronized, as well as the expected total number of processes. Each process needs to know the total number of processes, their order in the process, and which GPU to use. Generally, the total number of processes is called world_size.python. nn.utils.data.DistributedSampler is provided to segment data for each process to ensure that the training data does not overlap.
Example explanation
This is explained by an example of MNIST. We first change it to distributed training, and then add hybrid precision training.
Ordinary single card training
First, import the required libraries:
import os from datetime import datetime import argparse import torch.multiprocessing as mp import torchvision import torchvision.transforms as transforms import torch import torch.nn as nn import torch.distributed as dist from apex.parallel import DistributedDataParallel as DDP from apex import amp
Then we define a simple CNN model to process MNIST data:
class ConvNet(nn.Module): def __init__(self, num_classes=10): super(ConvNet, self).__init__() self.layer1 = nn.Sequential( nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(16), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.layer2 = nn.Sequential( nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(32), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.fc = nn.Linear(7*7*32, num_classes) def forward(self, x): out = self.layer1(x) out = self.layer2(out) out = out.reshape(out.size(0), -1) out = self.fc(out) return out
The main function main() takes parameters and performs training:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() train(0, args)
The main function of the training part is:
def train(gpu, args): torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Data loading code train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True) train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True) start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() loss.backward() optimizer.step() if (i + 1) % 100 == 0 and gpu == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format( epoch + 1, args.epochs, i + 1, total_step, loss.item()) ) if gpu == 0: print("Training complete in: " + str(datetime.now() - start))
Start training by starting the main function:
if __name__ == '__main__': main()
You may notice that some parameters are redundant, but they are useful for later distributed training. We can train on a single stand-alone card by executing the following statements:
python src/mnist.py -n 1 -g 1 -nr 0
Distributed training
Using multi process for distributed training, we need to start a process for each GPU. Each process needs to know which GPU it is running on and its sequence number in all processes. For multiple nodes, we need to start scripts at each node.
First, we need to configure the basic parameters:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() ######################################################### args.world_size = args.gpus * args.nodes # os.environ['MASTER_ADDR'] = '10.57.23.164' # os.environ['MASTER_PORT'] = '8888' # mp.spawn(train, nprocs=args.gpus, args=(args,)) # #########################################################
Where args.nodes is the total number of nodes, while args.gpus is the total number of GPU per node (the number of GPU per node is the same), and args.nr is the serial number of the current node at all nodes. The total number of nodes multiplied by the number of GPUs of each node can get the world_size, that is, the total number of processes. All processes need to know the IP address and port of process 0, so that all processes can be synchronized at the beginning. Generally speaking, process 0 is the master process. For example, we will print information or save models in process 0. PyTorch provides mp.spawn to start all processes of the node at a node. Each process runs train(i, args), where i goes from 0 to args.gpus - 1.
Similarly, we need to modify the training function:
def train(gpu, args): ############################################################ rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank ) ############################################################ torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) ############################################################### # Wrap the model model = nn.parallel.DistributedDataParallel(model, device_ids=[gpu]) ############################################################### # Data loading code train_dataset = torchvision.datasets.MNIST( root='./data', train=True, transform=transforms.ToTensor(), download=True ) ################################################################ train_sampler = torch.utils.data.distributed.DistributedSampler( train_dataset, num_replicas=args.world_size, rank=rank ) ################################################################ train_loader = torch.utils.data.DataLoader( dataset=train_dataset, batch_size=batch_size, ############################## shuffle=False, # ############################## num_workers=0, pin_memory=True, ############################# sampler=train_sampler) # ############################# ...
Here we first calculate the forward program number: rank = args.nr * args.gpus + gpu, and then initialize the distributed environment through dist.init process group, where the backend parameter specifies the communication backend, including mpi, gloo, nccl. Here, nccl is selected, which is the official multi card communication framework provided by Nvidia, which is relatively efficient. MPI is also a common communication protocol for high-performance computing, but you need to install your own MPI implementation framework, such as OpenMPI. gloo is built-in communication backend, but it is not efficient enough. Init? Method refers to how to initialize to complete the process synchronization at the beginning; here we set env: / /, which refers to the initialization mode of environment variables. Four parameters need to be configured in the environment variables: Master ﹐ port, master ﹐ addr, world ﹐ size, rank. The first two parameters have been configured. The last two parameters can also be configured through the world ﹐ size and rank parameters in the dist.init ﹐ process ﹐ group function. Other initialization methods include shared file system and TCP, such as init method = tcp://10.1.1.20:23456 ', which also provides the IP address and port of the master. Note that this call is blocked and must wait for all processes to synchronize. If any process fails, it will fail.
For the model side, we just need to wrap the original model with distributed data parallel, which will support gradient all reduce operation. For the data side, we nn.utils.data.DistributedSampler to segment data for each process, just use this sampler in dataloader. It is worth noting that you need to call train train ﹐ sampler.set ﹐ epoch (epoch) at the beginning of each epoch in the cyclic process (mainly to ensure that the partition of each epoch is different). Other training codes remain unchanged.
Finally, the code can be executed. For example, if we are a 4-node and each node is an 8-card, we need to execute the code on four nodes respectively:
python src/mnist-distributed.py -n 4 -g 8 -nr i
It should be noted that the effective batch size at this time is actually batch size per GPU * world size. For models with BN, synchronous BN can also be used to achieve better results:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
The distributed training process described above is also applicable to the evaluation or test process. For example, we can divide the data into different processes for prediction, which can accelerate the prediction process. The implementation code is exactly the same as the above process, but if we want to calculate an indicator, we need to perform all reduce from the statistical results of each process, because each process is only the content of the calculated part of the data. For example, if we want to calculate the classification accuracy, we can count the total data of each process and the number of correctly classified counts, and then aggregate them. The point to be mentioned here is that when using dist.init ﹣ process ﹣ group to initialize the distributed environment, it is actually to establish a default distributed process group, which will also initialize the torch.distributed package of Python. In this way, we can directly use the torch.distributed API to perform basic distributed operations. The following is the specific implementation:
# define tensor on GPU, count and total is the result at each GPU t = torch.tensor([count, total], dtype=torch.float64, device='cuda') dist.barrier() # synchronizes all processes dist.all_reduce(t, op=torch.distributed.ReduceOp.SUM,) # Reduces the tensor data across all machines in such a way that all get the final result. t = t.tolist() all_count = int(t[0]) all_total = int(t[1]) acc = all_count / all_total
Mixed precision training (with apex)
Hybrid precision training (hybrid FP32 and FP16 training) can be applied to larger batch size, and can use NVIDIA Tensor Cores to accelerate calculation. Using NVIDIA's apex for hybrid precision training is very simple, only part of the code needs to be modified:
rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank) torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Wrap the model ############################################################## model, optimizer = amp.initialize(model, optimizer, opt_level='O2') model = DDP(model) ############################################################## # Data loading code ... start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() ############################################################## with amp.scale_loss(loss, optimizer) as scaled_loss: scaled_loss.backward() ############################################################## optimizer.step() ...
In fact, there are two changes. First, amp.initialize is used to package model and optimizer to support mixed precision training, in which opt'u level refers to the optimization level. If O0 or O3 is not the real mixed precision, but it can be used to determine the baseline of model effect and speed, and O1 and O2 are two settings of mixed precision, and one can be selected for mixed precision training. The other is that before updating the parameters according to the gradient, the gradient should be scaled through amp.scale'loss to prevent underflow. In addition, you can replace nn.DistributedDataParallel with apex.parallel.DistributedDataParallel.
Digression
I think the official distributed implementation of PyTorch has been relatively perfect, and the performance and effect are good. The alternative is horovod. It supports not only PyTorch but also TensorFlow and MXNet framework. It is easy to implement, and the speed should be comparable.
Reference resources
- Distributed data parallel training in Pytorch https://yangkky.github.io/2019/07/08/distributed-pytorch-tutorial.html (most content comes from here)
- torch.distributed Https://python.org/docs/stable/distributed.html thank you for your reference - http://bjbsair.com/2020-03-27/tech-info/7154/ The simplest way to accelerate the training of neural network is to use GPU. The speed of GPU in the normal operation (matrix multiplication and addition) of neural network is twice faster than that of CPU. As models or datasets grow larger, a GPU will soon become inadequate. For example, large language models such as BERT and GPT-2 are trained on hundreds of GPUs. For multi GPU training, a method of model and data segmentation and scheduling between different GPUs is needed.
Pytorch is a very popular deep learning framework, which has the best balance between flexibility and ease of use in the mainstream framework. There are two ways for Python to segment models and data on multiple GPUs: NN. DataParallel and nn.distributedataparallel. DataParallel is easier to use (simply wrap the single GPU model). However, since it uses a process to calculate model weights and then distribute them to each GPU during each batch, communication quickly becomes a bottleneck and GPU utilization is usually low. Moreover, nn.DataParallel requires all GPUs to be on the same node (distributed is not supported), and Apex cannot be used for mixed precision training. The main differences between NN. DataParallel and nn.distributedataparallel can be summarized as follows:
- DistributedDataParallel supports model parallelism, but DataParallel does not, which means that if the model is too large and the single card does not have enough memory, the former can only be used;
- DataParallel is single process and multi thread, only used for single card situation, while DistributedDataParallel is multi process, suitable for single machine and multi machine situation, and truly realizes distributed training;
- The training of distributed DataParallel is more efficient, because each process is an independent Python interpreter to avoid GIL problems, and its training speed is faster with low communication cost. Basically, DataParallel has been abandoned;
- It must be noted that each process in the distributed data parallel has its own optimizer, which performs its own update process, but the gradient is passed to each process through communication, and all executed contents are the same;
Generally speaking, the python document is quite complete and clear, especially after version 1.0x. However, there are few introductions about DistributedDataParallel. The main documents are as follows:
- Writing Distributed Applications with PyTorch: mainly introduces distributed API, distributed configuration, different communication mechanisms and internal mechanisms, but to be honest, most people don't agree to understand them, and they seldom use them directly;
- Getting Started with Distributed Data Parallel: it briefly introduces how to use distributed data parallel, but the use case is not clear and complete;
- ImageNet training in PyTorch: a relatively complete use case, but only code, lack of detailed description; (apex also provides a similar training case Mixed Precision ImageNet Training in PyTorch)
- (advanced) PyTorch 1.0 Distributed Trainer with Amazon AWS: how to conduct distributed training on Amazon cloud, but it is estimated that many people can't use it.
This tutorial will show you how to use PyTorch's distributed training with an example of MNISI. Here is a section of code for explanation, and it also includes any mixed precision training with apex.
Distributed data parallel internal mechanism
Distributed data parallel replicates models among multiple GPUs through multiple processes. Each GPU is controlled by one process (of course, each process can control multiple GPUs, but this is obviously slower than each process has one GPU; multiple processes can also run on one GPU). GPUs can be on the same node or distributed on multiple nodes. Each process performs the same tasks, and each process communicates with all other processes. Process or GPU only transfer gradient, so network communication is no longer the bottleneck.
During training, each process loads batch data from disk and passes them to its GPU. Each GPU has its own forward process, and then the gradient performs all reduce among GPUs. The gradient of each layer does not depend on the previous layer, so all reduce and backward process of the gradient are calculated at the same time to further alleviate the network bottleneck. At the end of the backward process, each node gets an average gradient, so that the model parameters keep synchronous.
This requires multiple processes (possibly on multiple nodes) to synchronize and communicate. Python does this through the distributed. Init? Process? Group function. He needs to know the location of process 0 so that all processes can be synchronized, as well as the expected total number of processes. Each process needs to know the total number of processes, their order in the process, and which GPU to use. Generally, the total number of processes is called world_size.python. nn.utils.data.DistributedSampler is provided to segment data for each process to ensure that the training data does not overlap.
Example explanation
This is explained by an example of MNIST. We first change it to distributed training, and then add hybrid precision training.
Ordinary single card training
First, import the required libraries:
import os from datetime import datetime import argparse import torch.multiprocessing as mp import torchvision import torchvision.transforms as transforms import torch import torch.nn as nn import torch.distributed as dist from apex.parallel import DistributedDataParallel as DDP from apex import amp
Then we define a simple CNN model to process MNIST data:
class ConvNet(nn.Module): def __init__(self, num_classes=10): super(ConvNet, self).__init__() self.layer1 = nn.Sequential( nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(16), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.layer2 = nn.Sequential( nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(32), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.fc = nn.Linear(7*7*32, num_classes) def forward(self, x): out = self.layer1(x) out = self.layer2(out) out = out.reshape(out.size(0), -1) out = self.fc(out) return out
The main function main() takes parameters and performs training:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() train(0, args)
The main function of the training part is:
def train(gpu, args): torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Data loading code train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True) train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True) start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() loss.backward() optimizer.step() if (i + 1) % 100 == 0 and gpu == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format( epoch + 1, args.epochs, i + 1, total_step, loss.item()) ) if gpu == 0: print("Training complete in: " + str(datetime.now() - start))
Start training by starting the main function:
if __name__ == '__main__': main()
You may notice that some parameters are redundant, but they are useful for later distributed training. We can train on a single stand-alone card by executing the following statements:
python src/mnist.py -n 1 -g 1 -nr 0
Distributed training
Using multi process for distributed training, we need to start a process for each GPU. Each process needs to know which GPU it is running on and its sequence number in all processes. For multiple nodes, we need to start scripts at each node.
First, we need to configure the basic parameters:
def main(): parser = argparse.ArgumentParser() parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N') parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node') parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes') parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run') args = parser.parse_args() ######################################################### args.world_size = args.gpus * args.nodes # os.environ['MASTER_ADDR'] = '10.57.23.164' # os.environ['MASTER_PORT'] = '8888' # mp.spawn(train, nprocs=args.gpus, args=(args,)) # #########################################################
Where args.nodes is the total number of nodes, while args.gpus is the total number of GPU per node (the number of GPU per node is the same), and args.nr is the serial number of the current node at all nodes. The total number of nodes multiplied by the number of GPUs of each node can get the world_size, that is, the total number of processes. All processes need to know the IP address and port of process 0, so that all processes can be synchronized at the beginning. Generally speaking, process 0 is the master process. For example, we will print information or save models in process 0. PyTorch provides mp.spawn to start all processes of the node at a node. Each process runs train(i, args), where i goes from 0 to args.gpus - 1.
Similarly, we need to modify the training function:
def train(gpu, args): ############################################################ rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank ) ############################################################ torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) ############################################################### # Wrap the model model = nn.parallel.DistributedDataParallel(model, device_ids=[gpu]) ############################################################### # Data loading code train_dataset = torchvision.datasets.MNIST( root='./data', train=True, transform=transforms.ToTensor(), download=True ) ################################################################ train_sampler = torch.utils.data.distributed.DistributedSampler( train_dataset, num_replicas=args.world_size, rank=rank ) ################################################################ train_loader = torch.utils.data.DataLoader( dataset=train_dataset, batch_size=batch_size, ############################## shuffle=False, # ############################## num_workers=0, pin_memory=True, ############################# sampler=train_sampler) # ############################# ...
Here we first calculate the forward program number: rank = args.nr * args.gpus + gpu, and then initialize the distributed environment through dist.init process group, where the backend parameter specifies the communication backend, including mpi, gloo, nccl. Here, nccl is selected, which is the official multi card communication framework provided by Nvidia, which is relatively efficient. MPI is also a common communication protocol for high-performance computing, but you need to install your own MPI implementation framework, such as OpenMPI. gloo is built-in communication backend, but it is not efficient enough. Init? Method refers to how to initialize to complete the process synchronization at the beginning; here we set env: / /, which refers to the initialization mode of environment variables. Four parameters need to be configured in the environment variables: Master ﹐ port, master ﹐ addr, world ﹐ size, rank. The first two parameters have been configured. The last two parameters can also be configured through the world ﹐ size and rank parameters in the dist.init ﹐ process ﹐ group function. Other initialization methods include shared file system and TCP, such as init method = tcp://10.1.1.20:23456 ', which also provides the IP address and port of the master. Note that this call is blocked and must wait for all processes to synchronize. If any process fails, it will fail.
For the model side, we just need to wrap the original model with distributed data parallel, which will support gradient all reduce operation. For the data side, we nn.utils.data.DistributedSampler to segment data for each process, just use this sampler in dataloader. It is worth noting that you need to call train train ﹐ sampler.set ﹐ epoch (epoch) at the beginning of each epoch in the cyclic process (mainly to ensure that the partition of each epoch is different). Other training codes remain unchanged.
Finally, the code can be executed. For example, if we are a 4-node and each node is an 8-card, we need to execute the code on four nodes respectively:
python src/mnist-distributed.py -n 4 -g 8 -nr i
It should be noted that the effective batch size at this time is actually batch size per GPU * world size. For models with BN, synchronous BN can also be used to achieve better results:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
The distributed training process described above is also applicable to the evaluation or test process. For example, we can divide the data into different processes for prediction, which can accelerate the prediction process. The implementation code is exactly the same as the above process, but if we want to calculate an indicator, we need to perform all reduce from the statistical results of each process, because each process is only the content of the calculated part of the data. For example, if we want to calculate the classification accuracy, we can count the total data of each process and the number of correctly classified counts, and then aggregate them. The point to be mentioned here is that when using dist.init ﹣ process ﹣ group to initialize the distributed environment, it is actually to establish a default distributed process group, which will also initialize the torch.distributed package of Python. In this way, we can directly use the torch.distributed API to perform basic distributed operations. The following is the specific implementation:
# define tensor on GPU, count and total is the result at each GPU t = torch.tensor([count, total], dtype=torch.float64, device='cuda') dist.barrier() # synchronizes all processes dist.all_reduce(t, op=torch.distributed.ReduceOp.SUM,) # Reduces the tensor data across all machines in such a way that all get the final result. t = t.tolist() all_count = int(t[0]) all_total = int(t[1]) acc = all_count / all_total
Mixed precision training (with apex)
Hybrid precision training (hybrid FP32 and FP16 training) can be applied to larger batch size, and can use NVIDIA Tensor Cores to accelerate calculation. Using NVIDIA's apex for hybrid precision training is very simple, only part of the code needs to be modified:
rank = args.nr * args.gpus + gpu dist.init_process_group( backend='nccl', init_method='env://', world_size=args.world_size, rank=rank) torch.manual_seed(0) model = ConvNet() torch.cuda.set_device(gpu) model.cuda(gpu) batch_size = 100 # define loss function (criterion) and optimizer criterion = nn.CrossEntropyLoss().cuda(gpu) optimizer = torch.optim.SGD(model.parameters(), 1e-4) # Wrap the model ############################################################## model, optimizer = amp.initialize(model, optimizer, opt_level='O2') model = DDP(model) ############################################################## # Data loading code ... start = datetime.now() total_step = len(train_loader) for epoch in range(args.epochs): for i, (images, labels) in enumerate(train_loader): images = images.cuda(non_blocking=True) labels = labels.cuda(non_blocking=True) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() ############################################################## with amp.scale_loss(loss, optimizer) as scaled_loss: scaled_loss.backward() ############################################################## optimizer.step() ...
In fact, there are two changes. First, amp.initialize is used to package model and optimizer to support mixed precision training, in which opt'u level refers to the optimization level. If O0 or O3 is not the real mixed precision, but it can be used to determine the baseline of model effect and speed, and O1 and O2 are two settings of mixed precision, and one can be selected for mixed precision training. The other is that before updating the parameters according to the gradient, the gradient should be scaled through amp.scale'loss to prevent underflow. In addition, you can replace nn.DistributedDataParallel with apex.parallel.DistributedDataParallel.
Digression
I think the official distributed implementation of PyTorch has been relatively perfect, and the performance and effect are good. The alternative is horovod. It supports not only PyTorch but also TensorFlow and MXNet framework. It is easy to implement, and the speed should be comparable.
Reference resources
- Distributed data parallel training in Pytorch https://yangkky.github.io/2019/07/08/distributed-pytorch-tutorial.html (most content comes from here)
- torch.distributed https://pytorch.org/docs/stable/distributed.html