Stick to blogging and share your gains in study and work
- Make a note of yourself
- Record and summarize knowledge points to deepen understanding
- Give some help to people in need, step less on a pit and take more steps
Try to arrange the layout in an appropriate way, with both graphics and text
If you write wrong or don't understand, you can leave a message in the comment area
If the content is helpful to you, you are welcome to like it 👍 Collection ⭐ Leaving a message. 📝.
Although the platform will not have any reward, I will be very happy and can keep my enthusiasm for blogging
TORCH.OPTIM
torch.optim is a package that implements various optimization algorithms. Most common methods have been supported
How to use the optimizer
To use torch.optim, you must construct an optimizer object that will save the current state and update the parameters according to the calculated gradient.
Construct optimizer
In order to construct an optimizer, you must give it an iteratable object containing parameters (all should be variables s) for optimization. You can then specify optimizer specific options, such as learning rate, weight attenuation, and so on.
Note: if you need to move the model to the GPU through. cuda(), do so before building the optimizer for it. The model parameters after. cuda() are different objects from those before the call.
In general, when constructing and using an optimizer, you should ensure that the optimization parameters are in a consistent position.
For example:
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9) optimizer = optim.Adam([var1, var2], lr=0.0001)
Specify learning rate per layer
In the above optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9), the optimizer is constructed to set the same learning rate for the parameters of the whole model;
When you need to specify different learning rates for each layer, you can use optimizer = optim.Adam([var1, var2], lr=0.0001), where var1 and var2 should be defined as dict and should contain a params key
optim.Adam([
{'params': model.base.parameters()},
{'params': model.classifier.parameters(), 'lr': 1e-3}
], lr=1e-2)
The default learning rate 1e-2 will be used for the parameters of model.base and 1e-3 will be used for the parameters of model.classifier
optimization step
All optimizers implement a step() method to update parameters.
Once the gradient is calculated using backward(), you can call this function.
loss.backward() optimizer.step()
Base class torch.optim.Optimizer
torch.optim.Optimizer(params, defaults) is the base class of the optimizer
method
The Optimizer base class implements the following main methods:
Optimizer.add_param_group(param_group): param to the optimizer_ Groups add a parameter group. This is very useful when fine tuning the pre training network. The frozen layer is set to be trainable and added to the optimizer during the training process. param_ Group is a dict
Optimizer.load_state_dict(state_dict): load optimizer state. state_ Dict is a dict. It should call optimizer.state_ Return value of dict()
Optimizer.state_dict(): returns the status of the optimizer as a dictionary.
Optimizer.step(): perform a single optimization step to update parameters.
Optimizer.zero_grad(set_to_none=False): set the gradient to 0. set_ to_ None: set the gradient value to none instead of 0. This usually results in lower memory footprint and modest performance improvements. However, it changes some behavior. For example: 1. When the user tries to access the gradient and perform manual operation on it, the none attribute behaves differently from the tensor of all zeros. 2. If the user calls zero_grad(set_to_none=True) and back propagation, then. grad is guaranteed to be none for parameters that do not receive a gradient. 3. If the gradient is 0 or none, the torch.optim optimizer will have different behavior (in one case, it executes the step with a gradient of 0, and in another case, it skips the step completely).
algorithm
SGD
torch.optim.SGD(params, lr=<required parameter>, momentum=0, dampening=0, weight_decay=0, nesterov=False)
Adam
torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)
more
https://pytorch.org/docs/stable/optim.html#algorithms
Adjust learning rate
torch.optim.Lr_scheduler provides several methods to adjust learning rate based on epoch number.
Learning rate scheduling should be applied after the optimizer is updated
model = [Parameter(torch.randn(2, 2, requires_grad=True))]
optimizer = SGD(model, 0.1)
scheduler = ExponentialLR(optimizer, gamma=0.9)
for epoch in range(20):
for input, target in dataset:
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
scheduler.step()
You can use the following template to reference the scheduler algorithm:
scheduler = ...
for epoch in range(100):
train(...)
validate(...)
scheduler.step()
Note: before PyTorch 1.1.0, the learning rate scheduler should be called before the optimizer is updated. 1.1.0 changed this behavior in a BC breaking way. If you use the learning rate scheduler (call scheduler.step()) before the optimizer updates (call optimizer.step()), this skips the first value of the learning rate scheduler. If you cannot copy the results after upgrading to pytorch 1.1.0, check whether scheduler.step() was called at the wrong time.
Dynamic learning rate application
Can refer to Dynamically adjust learning rate , change strategies with different learning rates.
The following code runs in Jupiter
import torch import torchvision from torchvision.datasets import CIFAR10 from torchvision import transforms from torch import optim import torch.nn as nn import torch.nn.functional as F import numpy as np import matplotlib.pyplot as plt
Testing equipment
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
Data download and processing
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
batch_size = 4
trainset = CIFAR10(root='./CIFAR10', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size,
shuffle=True, num_workers=2)
testset = CIFAR10(root='./CIFAR10', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
Define network
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = torch.flatten(x, 1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
net.to(device)
Define optimizer and train
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
scheduler = optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.9)
lrs = []
steps = []
for epoch in range(20):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data[0].to(device), data[1].to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
steps.append(epoch)
lrs.append(scheduler.get_last_lr()[0])
scheduler.step()
print('Finished Training')
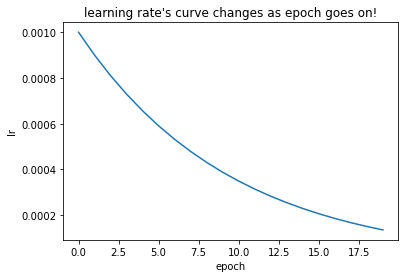
Visual learning rate
plt.plot(steps, lrs)
plt.xlabel("epoch")
plt.ylabel("lr")
plt.title("learning rate's curve changes as epoch goes on!")
plt.show()
reference resources: https://pytorch.org/docs/stable/optim.html
If the content is helpful to you, or you think it is well written
🏳️🌈 Welcome to praise 👍 Collection ⭐ Leaving a message. 📝
If you have any questions, please leave a message in the comment area