This article is about GitHub https://github.com/Jack-Cherish/PythonPark Has included, there are technical dry goods articles, collated learning materials, interview experience sharing of first-line large factories, etc., welcome to Star and improve.
1, Waste classification
Do you remember the garbage classification policy in full swing in Shanghai last year?
From May 1, 2020, Beijing has begun to implement "garbage classification"!
Beijing's garbage classification standard is slightly different from that of Shanghai. The garbage is divided into four categories: kitchen waste, recyclable matter, hazardous waste and other garbage, corresponding to four different colors of garbage cans, namely green, blue, red and gray.

After Shanghai, Beijing has also entered the "mandatory garbage classification era".

Garbage classification, the most abnormal place is Japan.
Japan divides garbage into seven categories: resources, combustible, non combustible, dangerous, plastic, metal and coarse.
It also specifies the types of garbage allowed to be recycled by the recycling station every day, such as those collecting resources on Monday and plastic collecting on Tuesday. Residents should throw garbage at designated time and place. Big pieces of rubbish like desks and closets have to be paid before they can be thrown away.
You can be punished with garbage for 50 years!
However, there are 24 hours of housewives who do housework online, and they can spend half an hour each day to tiktok the garbage, and then have time to brush, shake, and see what little movies are.
Now, the "social animals" in China's first tier cities are doing the work of "996" and taking "the heart of Japanese housewives".
One yard farmer for a family is miserable enough. For a double farmer family, it's "miserable plus miserable". One farmer leaves work later than the other.
It has been nearly a year since the implementation of "garbage classification" in Shanghai. What is the latest situation?
Before the epidemic, I went to Shanghai once. I felt that garbage sorting was going on in an orderly way. There were 4 garbage cans in the rented B & B, and we needed to use our brains to know how to dispose the leftover garbage.
However, we can also see the unclassified garbage that is randomly piled up next to the sorting garbage can near the community.

It has been several months since Beijing announced the implementation of "garbage sorting". The community I live in is in the center of the city. I haven't seen any garbage bins in the area. However, many notices have been posted and should still be in the publicity stage.
However, in the company, garbage sorting has started. It seems that it starts from the enterprise and then to the individual.
With the improvement of the policy and the increase of support, I wonder whether there will be a domestic service company providing garbage sorting service in a few years?
2, Garbage sorting assistant
People make complaints about make complaints about their own.
Fortunately, some apps or small programs have prepared query tools for us.
There are no more than three forms of inquiry: text, voice and picture.
Many have similar products.
You can query "what's the rubbish of hair lost from working overtime in 996" or "what kind of garbage is the necessary crayfish for supper".
For example, Tencent has a wechat app called "garbage sorting Wizard";
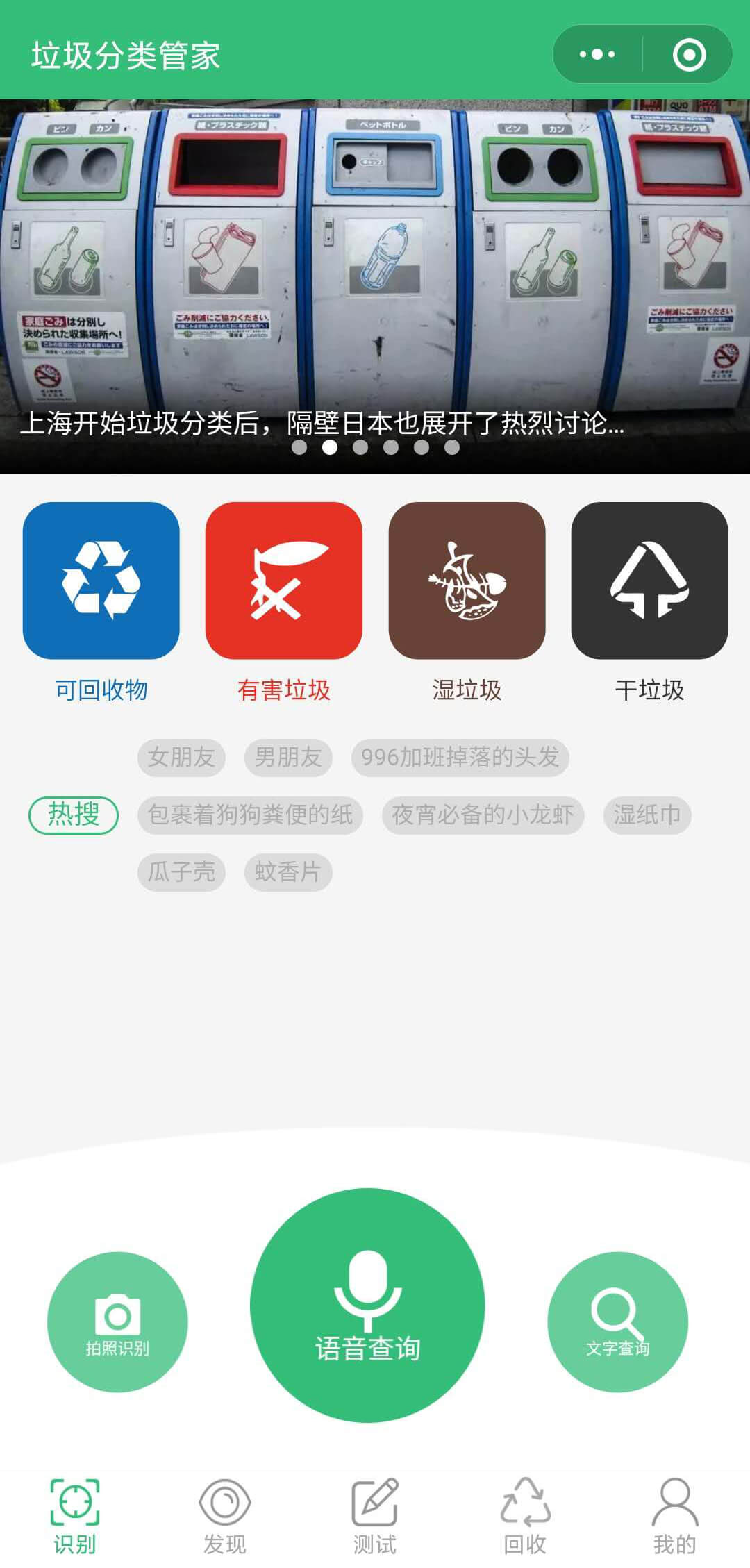
Baidu APP camera recognition entrance has a tag, called "identify garbage.".

Alipay has a small program called "junk classification guide".
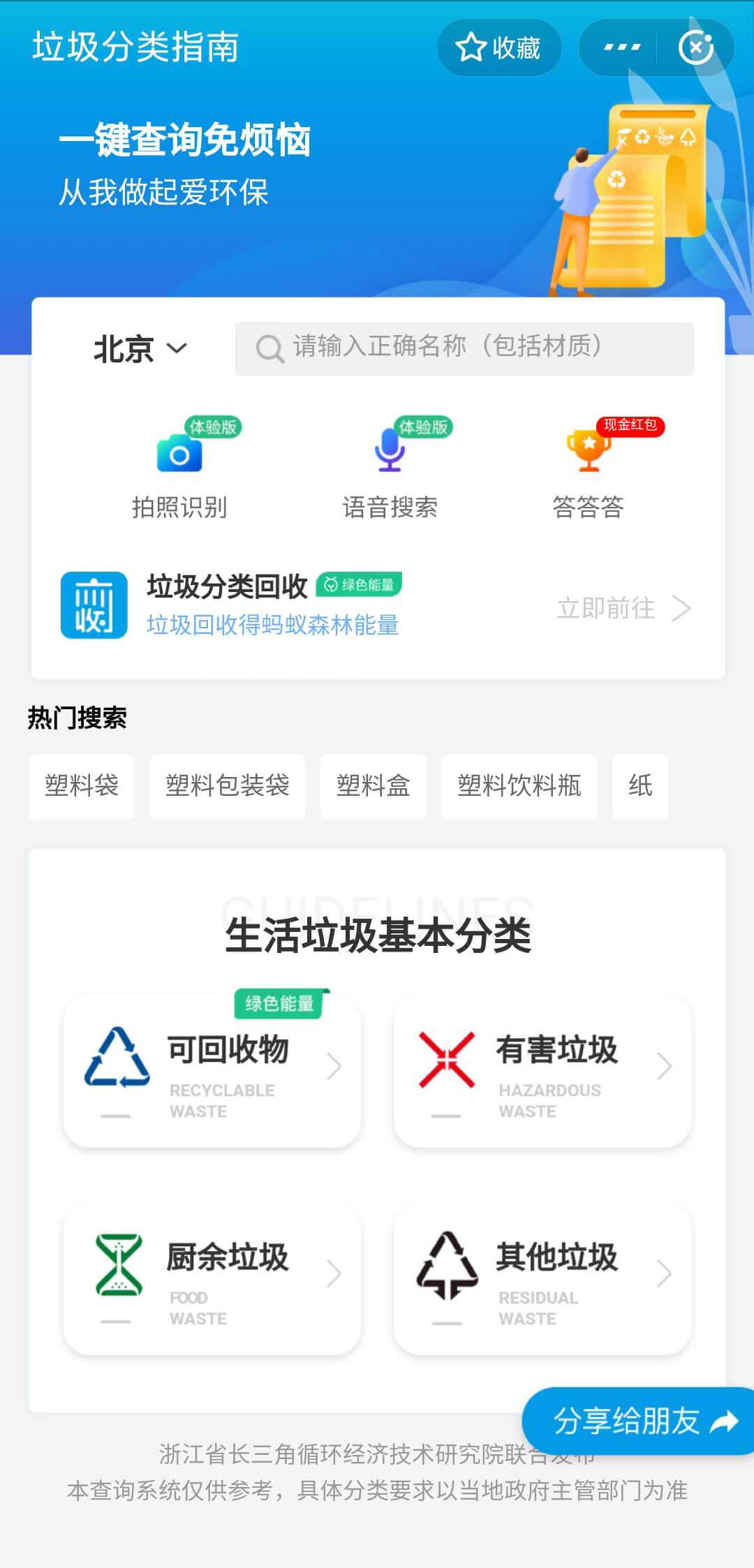
All of them support the garbage classification and recognition of text, voice and picture.
When Shanghai just implemented garbage sorting, Taobao's "Pai Li Tao" also had a garbage classification and identification entry, but now it seems to be offline.
It's easy to know which one is better at garbage sorting.
3, Waste classification technology
What is the technology behind garbage identification?
Text and voice are relatively simple, text matching can be done, voice has an audio to text step.
Image based spam identification is much more difficult.
For example, toilet paper can be made into various shapes, rolled together, or torn into strips.
Even, the cake can be made into "poop" in a bad way.
Let the algorithm through the image to identify these things, obviously some difficult algorithm.
At present, it is difficult to use deep learning classification algorithm to identify the types of garbage.
Generally, multi-level classification model or retrieval is used to build a super large classification network, such as recognition of more than 10000 objects, or even 100000.
Then, map to the final garbage category according to the category label.
The implementation of the underlying technology is actually multi classification.
Garbage classification is different from general image recognition. The "fish" of general image recognition may be a goldfish playing freely in the water.
The "fish" identified by garbage classification is likely to be a fish bone lying in the dining plate with only trunk bone left.
Getting a suitable data set is also a technical activity.
Generally, data sets can be obtained through the following three channels:
- Write crawlers, crawl the image data of major websites, and then use their own interface to clean or manually mark;
- Submit the requirements to the data tagging team and spend money to annotate the data.
The first two are either skilled or rich.
- The last way is to take a chance. Search for open data sets, or go to AI competition website or AI open platform to take a chance.
For example, you can go to Kaggle and search the dataset.
AI open platform, you can visit AI Studio.
URL: https://aistudio.baidu.com/aistudio/datasetoverview

In AI Studio, I found a good garbage sorting dataset.
A total of 56528 images, 214 categories, a total of 7.13 GB.
URL: https://aistudio.baidu.com/aistudio/datasetdetail/30982
Look, good luck. We found a good dataset.
Download speed is awesome, 10 MB/s.
This paper uses this data set to train a simple garbage classification model.
4, Data processing
The junk data is in a folder called "junk image library".
First of all, we need to write a script to generate the corresponding label file (DIR) according to the folder name_ label.txt ).
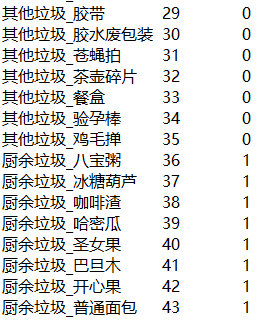
The front is the small category label, and the back is the large category label.
Then the data set is divided into training set( train.txt ), validation set( val.txt ), test set( test.txt ).
The training set and verification set are used to train the model, and the test set is used to check and accept the final model effect.
In addition, before using the Image training, we need to check the Image quality, read the Image of PIL, capture the Error and Warning exception, and delete the problematic Image directly.
Write a script to generate three txt files, including 48045 training sets, 5652 verification sets and 2826 test sets.
The script is very simple, the code will not be pasted, and the processed file will be provided directly.
The processed four txt files can be downloaded directly.
Download address: Click to view
Put the four txt files in the same directory as the junk image library.
With the basis of the previous several tutorials, it should be easy to write a data reading code.
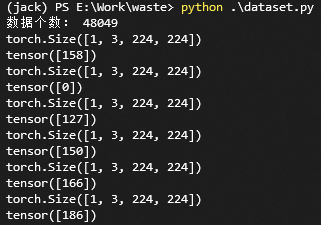
to write dataset.py Read the data and see how it works.
import torch
from PIL import Image
import os
import glob
from torch.utils.data import Dataset
import random
import torchvision.transforms as transforms
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
class Garbage_Loader(Dataset):
def __init__(self, txt_path, train_flag=True):
self.imgs_info = self.get_images(txt_path)
self.train_flag = train_flag
self.train_tf = transforms.Compose([
transforms.Resize(224),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
])
self.val_tf = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
])
def get_images(self, txt_path):
with open(txt_path, 'r', encoding='utf-8') as f:
imgs_info = f.readlines()
imgs_info = list(map(lambda x:x.strip().split('\t'), imgs_info))
return imgs_info
def padding_black(self, img):
w, h = img.size
scale = 224. / max(w, h)
img_fg = img.resize([int(x) for x in [w * scale, h * scale]])
size_fg = img_fg.size
size_bg = 224
img_bg = Image.new("RGB", (size_bg, size_bg))
img_bg.paste(img_fg, ((size_bg - size_fg[0]) // 2,
(size_bg - size_fg[1]) // 2))
img = img_bg
return img
def __getitem__(self, index):
img_path, label = self.imgs_info[index]
img = Image.open(img_path)
img = img.convert('RGB')
img = self.padding_black(img)
if self.train_flag:
img = self.train_tf(img)
else:
img = self.val_tf(img)
label = int(label)
return img, label
def __len__(self):
return len(self.imgs_info)
if __name__ == "__main__":
train_dataset = Garbage_Loader("train.txt", True)
print("Number of data:", len(train_dataset))
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=1,
shuffle=True)
for image, label in train_loader:
print(image.shape)
print(label)Read train.txt File, load data. Data preprocessing is to fill the pure black image with the size of 280 * 280 in equal proportion, and then re size it to 224 * 224.
This is a very conventional preprocessing method in image classification.
In addition, for the training set, we use Python's transforms to add the random operations of horizontal flip and vertical flip, which is also a very common data enhancement method.
Operation results:
OK, it's done! Start writing training code!
5, Initial experience of garbage classification
We use a conventional network ResNet50, which is a very common feature extraction network structure.
The whole training process is also very simple, the training steps are not clear, can see my last two tutorials:
<Practical course of pytoch deep learning (3): UNet model training>
<Pytoch in-depth learning practical course (4): Alchemy magic weapon>
establish train.py File, write the following code:
from dataset import Garbage_Loader
from torch.utils.data import DataLoader
from torchvision import models
import torch.nn as nn
import torch.optim as optim
import torch
import time
import os
import shutil
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
"""
Author : Jack Cui
Wechat : https://mp.weixin.qq.com/s/OCWwRVDFNslIuKyiCVUoTA
"""
from tensorboardX import SummaryWriter
def accuracy(output, target, topk=(1,)):
"""
//The accuracy of topk calculation
"""
with torch.no_grad():
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
class_to = pred[0].cpu().numpy()
res = []
for k in topk:
correct_k = correct[:k].view(-1).float().sum(0, keepdim=True)
res.append(correct_k.mul_(100.0 / batch_size))
return res, class_to
def save_checkpoint(state, is_best, filename='checkpoint.pth.tar'):
"""
//According to is_best storage model, generally save the best model of valid acc
"""
torch.save(state, filename)
if is_best:
shutil.copyfile(filename, 'model_best_' + filename)
def train(train_loader, model, criterion, optimizer, epoch, writer):
"""
//Training code
//Parameters:
train_loader - Training set DataLoader
model - Model
criterion - loss function
optimizer - optimizer
epoch - How many epoch
writer - For writing tensorboardX
"""
batch_time = AverageMeter()
data_time = AverageMeter()
losses = AverageMeter()
top1 = AverageMeter()
top5 = AverageMeter()
# switch to train mode
model.train()
end = time.time()
for i, (input, target) in enumerate(train_loader):
# measure data loading time
data_time.update(time.time() - end)
input = input.cuda()
target = target.cuda()
# compute output
output = model(input)
loss = criterion(output, target)
# measure accuracy and record loss
[prec1, prec5], class_to = accuracy(output, target, topk=(1, 5))
losses.update(loss.item(), input.size(0))
top1.update(prec1[0], input.size(0))
top5.update(prec5[0], input.size(0))
# compute gradient and do SGD step
optimizer.zero_grad()
loss.backward()
optimizer.step()
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % 10 == 0:
print('Epoch: [{0}][{1}/{2}]\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Data {data_time.val:.3f} ({data_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Prec@1 {top1.val:.3f} ({top1.avg:.3f})\t'
'Prec@5 {top5.val:.3f} ({top5.avg:.3f})'.format(
epoch, i, len(train_loader), batch_time=batch_time,
data_time=data_time, loss=losses, top1=top1, top5=top5))
writer.add_scalar('loss/train_loss', losses.val, global_step=epoch)
def validate(val_loader, model, criterion, epoch, writer, phase="VAL"):
"""
//Validation code
//Parameters:
val_loader - Of validation set DataLoader
model - Model
criterion - loss function
epoch - How many epoch
writer - For writing tensorboardX
"""
batch_time = AverageMeter()
losses = AverageMeter()
top1 = AverageMeter()
top5 = AverageMeter()
# switch to evaluate mode
model.eval()
with torch.no_grad():
end = time.time()
for i, (input, target) in enumerate(val_loader):
input = input.cuda()
target = target.cuda()
# compute output
output = model(input)
loss = criterion(output, target)
# measure accuracy and record loss
[prec1, prec5], class_to = accuracy(output, target, topk=(1, 5))
losses.update(loss.item(), input.size(0))
top1.update(prec1[0], input.size(0))
top5.update(prec5[0], input.size(0))
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % 10 == 0:
print('Test-{0}: [{1}/{2}]\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Prec@1 {top1.val:.3f} ({top1.avg:.3f})\t'
'Prec@5 {top5.val:.3f} ({top5.avg:.3f})'.format(
phase, i, len(val_loader),
batch_time=batch_time,
loss=losses,
top1=top1, top5=top5))
print(' * {} Prec@1 {top1.avg:.3f} Prec@5 {top5.avg:.3f}'
.format(phase, top1=top1, top5=top5))
writer.add_scalar('loss/valid_loss', losses.val, global_step=epoch)
return top1.avg, top5.avg
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
if __name__ == "__main__":
# --------------------------------------------step 1/4: load data---------------------------
train_dir_list = 'train.txt'
valid_dir_list = 'val.txt'
batch_size = 64
epochs = 80
num_classes = 214
train_data = Garbage_Loader(train_dir_list, train_flag=True)
valid_data = Garbage_Loader(valid_dir_list, train_flag=False)
train_loader = DataLoader(dataset=train_data, num_workers=8, pin_memory=True, batch_size=batch_size, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, num_workers=8, pin_memory=True, batch_size=batch_size)
train_data_size = len(train_data)
print('Number of training sets:%d' % train_data_size)
valid_data_size = len(valid_data)
print('Number of validation sets:%d' % valid_data_size)
# ------------------------------------step 2/4: define network------------------------------------
model = models.resnet50(pretrained=True)
fc_inputs = model.fc.in_features
model.fc = nn.Linear(fc_inputs, num_classes)
model = model.cuda()
# ------------------------------------step 3/4: define loss function and optimizer, etc-------------------------
lr_init = 0.0001
lr_stepsize = 20
weight_decay = 0.001
criterion = nn.CrossEntropyLoss().cuda()
optimizer = optim.Adam(model.parameters(), lr=lr_init, weight_decay=weight_decay)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=lr_stepsize, gamma=0.1)
writer = SummaryWriter('runs/resnet50')
# ------------------------------------step 4/4: Training-----------------------------------------
best_prec1 = 0
for epoch in range(epochs):
scheduler.step()
train(train_loader, model, criterion, optimizer, epoch, writer)
# Test the effect on the verification set
valid_prec1, valid_prec5 = validate(valid_loader, model, criterion, epoch, writer, phase="VAL")
is_best = valid_prec1 > best_prec1
best_prec1 = max(valid_prec1, best_prec1)
save_checkpoint({
'epoch': epoch + 1,
'arch': 'resnet50',
'state_dict': model.state_dict(),
'best_prec1': best_prec1,
'optimizer' : optimizer.state_dict(),
}, is_best,
filename='checkpoint_resnet50.pth.tar')
writer.close()The code is not complicated. The network structure directly makes the ResNet50 model of torchvision, and adopts the pre training model of ResNet50. The algorithm uses cross entropy loss function, optimizer selects Adam, and uses StepLR to reduce learning rate.
The strategy to save the model is to select the model with the highest accuracy in the validation set.
If the batch size is set to 64, the GPU memory accounts for about 8G. If the video memory is not enough, the batch size can be adjusted.
Model training completed, you can write test code, see the effect!
establish infer.py File, write the following code:
from dataset import Garbage_Loader
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torchvision import models
import torch.nn as nn
import torch
import os
import numpy as np
import matplotlib.pyplot as plt
#%matplotlib inline
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
def softmax(x):
exp_x = np.exp(x)
softmax_x = exp_x / np.sum(exp_x, 0)
return softmax_x
with open('dir_label.txt', 'r', encoding='utf-8') as f:
labels = f.readlines()
labels = list(map(lambda x:x.strip().split('\t'), labels))
if __name__ == "__main__":
test_list = 'test.txt'
test_data = Garbage_Loader(test_list, train_flag=False)
test_loader = DataLoader(dataset=test_data, num_workers=1, pin_memory=True, batch_size=1)
model = models.resnet50(pretrained=False)
fc_inputs = model.fc.in_features
model.fc = nn.Linear(fc_inputs, 214)
model = model.cuda()
# Loading trained models
checkpoint = torch.load('model_best_checkpoint_resnet50.pth.tar')
model.load_state_dict(checkpoint['state_dict'])
model.eval()
for i, (image, label) in enumerate(test_loader):
src = image.numpy()
src = src.reshape(3, 224, 224)
src = np.transpose(src, (1, 2, 0))
image = image.cuda()
label = label.cuda()
pred = model(image)
pred = pred.data.cpu().numpy()[0]
score = softmax(pred)
pred_id = np.argmax(score)
plt.imshow(src)
print('The prediction results are as follows', labels[pred_id][0])
plt.show()It should be noted here that the data read by DataLoader needs to be converted into channels before it can be displayed.
The prediction results are as follows
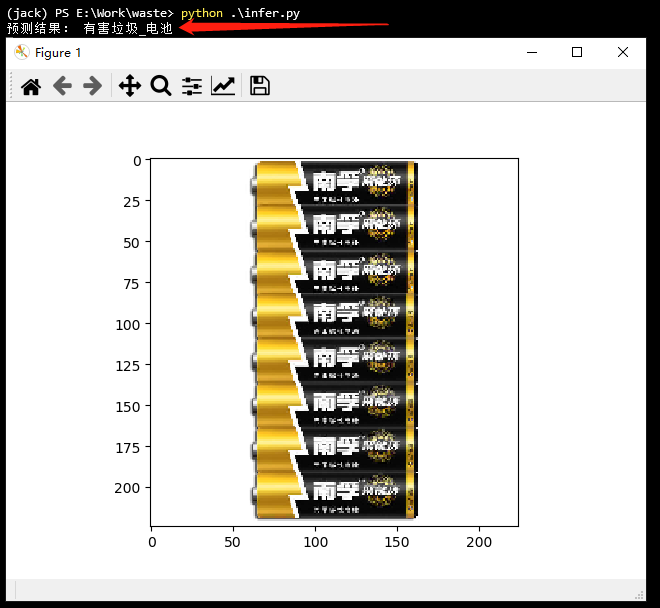
What about? Is it easy?
Train a garbage classifier and experience it!
6, Summary
- Starting from the actual combat, this paper explains how to train one's own "garbage Classifier".
- baseline has provided that to improve the accuracy, it is to optimize some details.
- Trained models, focus on WeChat official account, and reply to junk classification.
PS: all the codes in this article can be downloaded from my github. Welcome to Follow, Star: Click to view
