1. xml.etree.ElementTree XML Manipulation API
The ElementTree library provides tools for parsing XML using event-based and document-based API s, searching for parsed documents using XPath expressions, and creating new documents or modifying existing ones.
1.1 Parsing XML documents
Parsed XML documents are represented in memory by ElementTree and Element objects that are connected in a tree structure based on the nesting of nodes in the XML document.
Parsing a complete document with parse() returns an instance of ElementTree.This tree knows all the data in the input document, plus it can search or manipulate nodes in the tree in place.Based on this flexibility, parsed documents can be handled more easily, but this method tends to require more memory than event-based parsing because the entire document must be loaded at once.
For simple small documents (such as the podcast list below, represented as an OPML outline), there is little memory requirement.
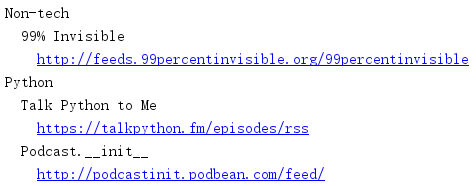
podcasts.opml:
<?xml version="1.0" encoding="UTF-8"?> <opml version="1.0"> <head> <title>My Podcasts</title> <dateCreated>Sat, 06 Aug 2016 15:53:26 GMT</dateCreated> <dateModified>Sat, 06 Aug 2016 15:53:26 GMT</dateModified> </head> <body> <outline text="Non-tech"> <outline text="99% Invisible" type="rss" xmlUrl="http://feeds.99percentinvisible.org/99percentinvisible" htmlUrl="http://99percentinvisible.org" /> </outline> <outline text="Python"> <outline text="Talk Python to Me" type="rss" xmlUrl="https://talkpython.fm/episodes/rss" htmlUrl="https://talkpython.fm" /> <outline text="Podcast.__init__" type="rss" xmlUrl="http://podcastinit.podbean.com/feed/" htmlUrl="http://podcastinit.com" /> </outline> </body> </opml>
To parse this document, you need to pass an open file handle to parse().
from xml.etree import ElementTree with open('podcasts.opml', 'rt') as f: tree = ElementTree.parse(f) print(tree)
This method reads the data, parses the XML, and returns an ElementTree object.
1.2 Traversing Parse Tree
To access all the child nodes sequentially, you can use iter() to create a generator that iterates over this ElementTree instance.
from xml.etree import ElementTree with open('podcasts.opml', 'rt') as f: tree = ElementTree.parse(f) for node in tree.iter(): print(node.tag)
This example prints the entire tree, one marker at a time.

If you only print the podcast's name group and feed URL, you can iterate through the outline nodes (regardless of all the data in the header) and print the text and xmlUrl attributes by looking up the values in the attrib dictionary.
from xml.etree import ElementTree with open('podcasts.opml', 'rt') as f: tree = ElementTree.parse(f) for node in tree.iter('outline'): name = node.attrib.get('text') url = node.attrib.get('xmlUrl') if name and url: print(' %s' % name) print(' %s' % url) else: print(name)
The'outline'parameter of iter() means that only nodes marked'outline' are processed.
1.3 Find Nodes in Documents
Viewing the entire tree and searching for related nodes can be error prone.The previous example had to look at each outline node to determine whether it was a group (nodes with only a text attribute) or a podcast (nodes with text and xmlUrl).To generate a simple list of podcast feed URL s without names or groups, you can simplify the logic by using findall() to find nodes with more descriptive search features.
Make the first modification to the first version above, using an XPath parameter to find all outline nodes.
from xml.etree import ElementTree with open('podcasts.opml', 'rt') as f: tree = ElementTree.parse(f) for node in tree.findall('.//outline'): url = node.attrib.get('xmlUrl') if url: print(url)
The logic in this version is not significantly different from the version using getiterator().You still have to check for URLs, but if no URLs are found, it will not print the group name.

Outline nodes have only two levels of nesting, which can be used to modify the search path to. //outline/outline, which means that the loop only processes the second level of outline nodes.
from xml.etree import ElementTree with open('podcasts.opml', 'rt') as f: tree = ElementTree.parse(f) for node in tree.findall('.//outline/outline'): url = node.attrib.get('xmlUrl') print(url)
All outline nodes with two levels of nesting depth in the input assume that there is an xmlURL attribute pointing to the podcast feed, so the loop can leave it unchecked before using this attribute.

However, this version is limited to the current structure, so if the outline node is reorganized into a deeper tree, this version will not work properly.
1.4 Parse Node Properties
The elements returned by findall() and iter() are Element objects, each representing a node in the XML parsing tree.Each Element has properties that can be used to obtain data in XML.This behavior can be illustrated with a slightly more forceful example input file, data.xml.(
<?xml version="1.0" encoding="UTF-8"?> <top> <child>Regular text.</child> <child_with_tail>Regular text.</child_with_tail>"Tail" text. <with_attributes name="value" foo="bar"/> <entity_expansion attribute="This & That"> That & This </entity_expansion> </top>
The attrib attribute can be used to get the XML attribute of the node, which is like a dictionary.
from xml.etree import ElementTree with open('data.xml', 'rt') as f: tree = ElementTree.parse(f) node = tree.find('./with_attributes') print(node.tag) for name,value in sorted(node.attrib.items()): print(name,value)
The node on line 5 of the input file has two attributes, name and foo.

You can also get the text content of the node and tail text after the end tag.
from xml.etree import ElementTree with open('data.xml', 'rt') as f: tree = ElementTree.parse(f) for path in ['./child','./child_with_tail']: node = tree.find(path) print(node.tag) print('child node text:',node.text) print('and tail text:',node.tail)
The child node on line 3 contains embedded text, and the node on line 4 contains text with tail (including whitespace).

The embedded XML entity reference in the document is converted to the appropriate character before the value is returned.
from xml.etree import ElementTree with open('data.xml', 'rt') as f: tree = ElementTree.parse(f) node = tree.find('entity_expansion') print(node.tag) print('in attribute:',node.attrib['attribute']) print('in text:',node.text.strip())
This automatic conversion means that implementation details representing certain characters in an XML document can be ignored.

1.5 Monitor events when parsing
Another API for processing XML documents is event based.The parser generates a start event for the start tag and an end event for the end tag.Event-based APIs are convenient in the parsing phase when it is not necessary to process the entire document later or to save the parsed document in memory by iteratively processing the event stream.
There are the following event types:
start encountered a new tag.End angle brackets for tags are processed, but content is not processed.
End has handled the end angle brackets for the end tag.All child nodes have been processed.
start-ns ends a namespace declaration.
end-ns ends a namespace declaration.
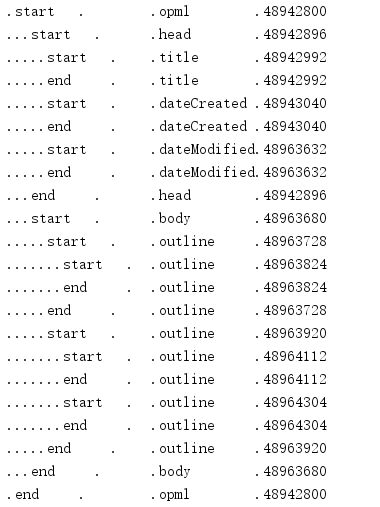
iterparse() returns an iterable that generates a tuple containing the event name and the node that triggered the event.(
from xml.etree.ElementTree import iterparse depth = 0 prefix_width = 8 prefix_dots = '.' * prefix_width line_template = '.'.join([ '{prefix:<0.{prefix_len}}', '{event:<8}', '{suffix:<{suffix_len}}', '{node.tag:<12}', '{node_id}', ]) EVENT_NAMES = ['start','end','start-ns','end-ns'] for (event,node) in iterparse('podcasts.opml',EVENT_NAMES): if event == 'end': depth -= 1 prefix_len = depth * 2 print(line_template.format( prefix = prefix_dots, prefix_len = prefix_len, suffix = '', suffix_len = (prefix_width - prefix_len), node = node, node_id = id(node), event = event, )) if event == 'start': depth += 1
By default, only end events are generated.To view other events, you can pass the list of event names you want into iterparse().
Processing as an event is more natural for some operations, such as converting an XML input to another format.You can use this technique to convert broadcast lists (from the previous examples) from XML files to CSV files so that they can be loaded into a spreadsheet or database application.
import csv import sys from xml.etree.ElementTree import iterparse writer = csv.writer(sys.stdout,quoting=csv.QUOTE_NONNUMERIC) group_name = '' parsing = iterparse('podcasts.opml',events=['start']) for (event,node) in parsing: if node.tag != 'outline': # Ignore anything not part of the outline. continue if not node.attrib.get('xmlUrl'): #Remember the current group. group_name = node.attrib['text'] else: #Output a podcast entry. writer.writerow( (group_name,node.attrib['text'], node.attrib['xmlUrl'], node.attrib.get('htmlUrl','')) )
This converter does not need to save the entire parsed input file in memory; it is more efficient to process each node in the input when it encounters it.

1.6 Create a custom tree constructor
A potentially more efficient way to handle parsing events is to replace the standard tree constructor behavior with a custom behavior.The XMLParser parser uses a TreeBuilder to process the XML and calls the method of the target class to save the results.Typically, the output is an ElementTree instance created by the default TreeBuilder class.You can save this split by replacing TreeBuilder with another class so that it receives events before instantiating Element nodes.(
The XML-CSV converter can be re-implemented as a tree constructor.
import io import csv import sys from xml.etree.ElementTree import XMLParser class PodcastListToCSV(object): def __init__(self,outputFile): self.writer = csv.writer( outputFile, quoting = csv.QUOTE_NONNUMERIC, ) self.group_name = '' def start(self,tag,attrib): if tag != 'outline': # Ignore anything not part of the outline. return if not attrib.get('xmlUrl'): #Remember the current group. self.group_name = attrib['text'] else: #Output a pddcast entry. self.writer.writerow( (self.group_name, attrib['text'], attrib['xmlUrl'], attrib.get('htmlUrl','')) ) def end(self,tag): "Ignore closing tags" def data(self,data): "Ignore data inside nodes" def close(self): "Nothing special to do here" target = PodcastListToCSV(sys.stdout) parser = XMLParser(target=target) with open('podcasts.opml','rt') as f: for line in f: parser.feed(line) parser.close()
PodcastListToCSV implements the TreeBuilder protocol.Each time a new XML tag is encountered, start() is called and the tag name and attributes are provided.When you see an end tag, end() is called based on the tag name.In between, data () is called if a node has content (it is generally assumed that the tree constructor tracks the Current node).Clo() is called when all inputs have been processed.It returns a value to the user of the XMLTreeBuilder.

1.7 Constructing documents with element nodes
In addition to parsing, xml.etree.ElementTree supports the creation of well-structured XML documents from Element objects constructed in applications.Element classes used when parsing documents also know how to generate a serialized form of their content, which can then be written to a file or other data stream.
There are three auxiliary functions that are useful for creating an Element node hierarchy.Element() creates a standard node, SubElement() associates a new node to a parent node, and Comment() creates a node that serializes data using XML comment syntax.
from xml.etree.ElementTree import Element,SubElement,Comment,tostring top = Element('top') comment = Comment('Generated for PyMOTW') top.append(comment) child = SubElement(top,'child') child.text = 'This child contains text.' child_with_tail = SubElement(top,'child_with_tail') child_with_tail.text = 'This child has text.' child_with_tail.tail = 'And "tail" text.' child_with_entity_ref = SubElement(top,'child_with_entity_ref') child_with_entity_ref.text = 'This & that' print(tostring(top))
This output contains only XML nodes in the tree, not versions and coded XML declarations.
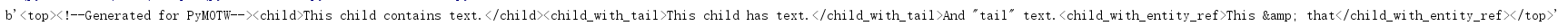
1.8 Beautiful Printing XML
ElementTree does not improve readability by formatting the output of tostring(), because adding extra white space changes the content of the document.To make the output easier to read, the following example parses the XML using xml.dom.minidom and then uses its toprettyxml() method.
from xml.etree import ElementTree from xml.dom import minidom from xml.etree.ElementTree import Element,SubElement,Comment,tostring def prettify(elem): """ Return a pretty-printed XML string for the Element. """ rough_string = ElementTree.tostring(elem,'utf-8') reparsed = minidom.parseString(rough_string) return reparsed.toprettyxml(indent=" ") top = Element('top') comment = Comment('Generated for PyMOTW') top.append(comment) child = SubElement(top,'child') child.text = 'This child contains text.' child_with_tail = SubElement(top,'child_with_tail') child_with_tail.text = 'This child has text.' child_with_tail.tail = 'And "tail" text.' child_with_entity_ref = SubElement(top,'child_with_entity_ref') child_with_entity_ref.text = 'This & that' print(prettify(top))
The output becomes more readable.

In addition to adding extra white space for formatting, the xml.dom.minidom aesthetic printer adds an XML declaration to the output.(