1. Multprocessing manages processes like threads
The multiprocessing module contains an API that is based on the threading API and divides work into multiple processes.In some cases, multiprocessing can replace threading as a temporary replacement to utilize multiple CPU cores, thereby avoiding computing bottlenecks caused by Python global interpreter locks.
Because of this similarity between multiprocessing and threading modules, the first few examples here have been modified from the threading example.Features in multiprocessing that are not provided by threading are described later.
1.1 multiprocessing Base
The easiest way to create a second process is to instantiate a Process object with a target function and call start() to get it working.
import multiprocessing def worker(): """worker function""" print('Worker') if __name__ == '__main__': jobs = [] for i in range(5): p = multiprocessing.Process(target=worker) jobs.append(p) p.start()
The word "Worker" in the output will be printed five times, but depending on the order of execution, it is not clear which is first because each process is competing to access the output stream.

In most cases, it is more useful to provide parameters to tell a process what to do when it is created.Unlike threading, to pass a parameter to a multiprocessing Process, the parameter must be able to be serialized using pickle.The following example passes a number to be printed to each worker process.
import multiprocessing def worker(num): """thread worker function""" print('Worker:', num) if __name__ == '__main__': jobs = [] for i in range(5): p = multiprocessing.Process(target=worker, args=(i,)) jobs.append(p) p.start()
Integer parameters are now included in messages printed by each worker process.

1.2 Importable Target Functions
There is a difference between the threading and multiprocessing examples, where extra protection is used for the main.Based on how the new process is started, it is required that the child process be able to import scripts containing the target function.The main parts of the application can be wrapped in a u main_check to ensure that modules do not run recursively across subprocesses when imported.Another way is to import the target function from a separate script.
import multiprocessing def worker(): """worker function""" print('Worker') return if __name__ == '__main__': jobs = [] for i in range(5): p = multiprocessing.Process( target=worker, ) jobs.append(p) p.start()
Calling the main program produces output similar to the first example.

1.3 Identify the current process
Identifying or naming processes by passing parameters is cumbersome and unnecessary.Each Process instance has a name that can be changed from its default value when a process is created.Naming processes is useful for tracking processes, especially if there are multiple types of processes running simultaneously in the application.
import multiprocessing import time def worker(): name = multiprocessing.current_process().name print(name, 'Starting') time.sleep(2) print(name, 'Exiting') def my_service(): name = multiprocessing.current_process().name print(name, 'Starting') time.sleep(3) print(name, 'Exiting') if __name__ == '__main__': service = multiprocessing.Process( name='my_service', target=my_service, ) worker_1 = multiprocessing.Process( name='worker 1', target=worker, ) worker_2 = multiprocessing.Process( # default name target=worker, ) worker_1.start() worker_2.start() service.start()
In the debug output, each line contains the name of the current process.Rows with process name column Process-3 correspond to unnamed
Process worker_1.

1.4 Daemon
By default, the main program does not exit until all subprocesses exit.In some cases, you may need to start a background process that can run all the time without blocking the main program from exiting. If a service cannot interrupt the process in an easy way, or if you want the process to stop in half without losing or destroying data (such as generating a "heartbeat" task for a service monitoring tool), then use daemon for these servicesProcesses are useful.
To mark a process as a daemon, set its daemon property to True.Processes are not daemons by default.
import multiprocessing import time import sys def daemon(): p = multiprocessing.current_process() print('Starting:', p.name, p.pid) sys.stdout.flush() time.sleep(2) print('Exiting :', p.name, p.pid) sys.stdout.flush() def non_daemon(): p = multiprocessing.current_process() print('Starting:', p.name, p.pid) sys.stdout.flush() print('Exiting :', p.name, p.pid) sys.stdout.flush() if __name__ == '__main__': d = multiprocessing.Process( name='daemon', target=daemon, ) d.daemon = True n = multiprocessing.Process( name='non-daemon', target=non_daemon, ) n.daemon = False d.start() time.sleep(1) n.start()
There is no "Exiting" message from the daemon in the output because all non-daemon processes (including the main program) have exited before the daemon wakes up from its 2-second sleep.

The daemon automatically terminates before the main program exits to avoid leaving the "orphaned" process running.To verify this, you can find the process ID value printed when the program is running and examine the process with a ps-like command.
1.5 Waiting Process
To wait for a process to complete its work and exit, you can use the join() method.
import multiprocessing import time def daemon(): name = multiprocessing.current_process().name print('Starting:', name) time.sleep(2) print('Exiting :', name) def non_daemon(): name = multiprocessing.current_process().name print('Starting:', name) print('Exiting :', name) if __name__ == '__main__': d = multiprocessing.Process( name='daemon', target=daemon, ) d.daemon = True n = multiprocessing.Process( name='non-daemon', target=non_daemon, ) n.daemon = False d.start() time.sleep(1) n.start() d.join() n.join()
Since the main process uses join() to wait for the daemon to exit, this time an "Exiting" message will be printed.

By default, join() is blocked indefinitely.You can pass a timeout parameter to this module (this is a floating-point number indicating the number of seconds to wait before the process becomes inactive).join() returns even if the process has not completed within this timeout period.
import multiprocessing import time def daemon(): name = multiprocessing.current_process().name print('Starting:', name) time.sleep(2) print('Exiting :', name) def non_daemon(): name = multiprocessing.current_process().name print('Starting:', name) print('Exiting :', name) if __name__ == '__main__': d = multiprocessing.Process( name='daemon', target=daemon, ) d.daemon = True n = multiprocessing.Process( name='non-daemon', target=non_daemon, ) n.daemon = False d.start() n.start() d.join(1) print('d.is_alive()', d.is_alive()) n.join()
Since the incoming timeout value is less than the time the daemon sleeps, the process remains "alive" after join() returns.

1.6 Terminate process
Although a poison pill is best used to signal a process that it should exit, it can be useful to force a process to end if it appears to have been suspended or deadlocked.Calling terminate() on a process object terminates the child process.
import multiprocessing import time def slow_worker(): print('Starting worker') time.sleep(0.1) print('Finished worker') if __name__ == '__main__': p = multiprocessing.Process(target=slow_worker) print('BEFORE:', p, p.is_alive()) p.start() print('DURING:', p, p.is_alive()) p.terminate() print('TERMINATED:', p, p.is_alive()) p.join() print('JOINED:', p, p.is_alive())

1.7 Process Exit Status
The status code generated when the process exits can be accessed through the exitcode property.The table below lists the range of values available for this property.(
| Exit Code | Meaning |
|---|---|
| == 0 | No errors occurred |
| > 0 | The process has an error and exits with that error code |
| < 0 | Process as a -1 * exitcode |
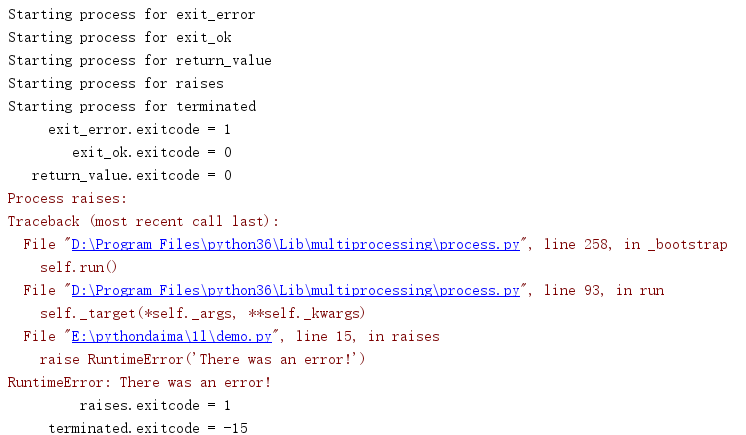
import multiprocessing import sys import time def exit_error(): sys.exit(1) def exit_ok(): return def return_value(): return 1 def raises(): raise RuntimeError('There was an error!') def terminated(): time.sleep(3) if __name__ == '__main__': jobs = [] funcs = [ exit_error, exit_ok, return_value, raises, terminated, ] for f in funcs: print('Starting process for', f.__name__) j = multiprocessing.Process(target=f, name=f.__name__) jobs.append(j) j.start() jobs[-1].terminate() for j in jobs: j.join() print('{:>15}.exitcode = {}'.format(j.name, j.exitcode))
The process that generated the exception automatically gets exitcode 1.
1.8 Log
When debugging concurrency problems, this can be useful if you have access to the internal state of the object provided by multiprocessing.Logging can be enabled using a convenient module-level function called log_to_stderr().It uses logging to create a logger object and an additional processor to send log messages to standard error channels.
import multiprocessing import logging import sys def worker(): print('Doing some work') sys.stdout.flush() if __name__ == '__main__': multiprocessing.log_to_stderr(logging.DEBUG) p = multiprocessing.Process(target=worker) p.start() p.join()
By default, the log level is set to NOTSET, meaning no messages are generated.By passing in a different log level, you can initialize the logger and specify the required level of detail.

To process the logger directly (modify its log level or increase the processor), you can use get_logger().
import multiprocessing import logging import sys def worker(): print('Doing some work') sys.stdout.flush() if __name__ == '__main__': multiprocessing.log_to_stderr() logger = multiprocessing.get_logger() logger.setLevel(logging.INFO) p = multiprocessing.Process(target=worker) p.start() p.join()
Using the name multiprocessing, you can also configure the logger through the logging configuration file API.

1.9 Derived Processes
To start working in a separate process, although the easiest way is to use Process and pass along a target function, you can also use a custom subclass.
import multiprocessing class Worker(multiprocessing.Process): def run(self): print('In {}'.format(self.name)) return if __name__ == '__main__': jobs = [] for i in range(5): p = Worker() jobs.append(p) p.start() for j in jobs: j.join()
Derived classes should override run() to complete their work.

1.10 Delivering messages to processes
Similar to threads, a common usage pattern for multiple processes is to divide one work into multiple work processes and run in parallel.Effective use of multiple processes often requires some kind of communication between them so that work can be broken down and results can be aggregated.An easy way to accomplish interprocess communication with multiprocessing is to use a Queue to pass messages back and forth.Any object that can be serialized with a pickle can be passed through a Queue.
import multiprocessing class MyFancyClass: def __init__(self, name): self.name = name def do_something(self): proc_name = multiprocessing.current_process().name print('Doing something fancy in {} for {}!'.format( proc_name, self.name)) def worker(q): obj = q.get() obj.do_something() if __name__ == '__main__': queue = multiprocessing.Queue() p = multiprocessing.Process(target=worker, args=(queue,)) p.start() queue.put(MyFancyClass('Fancy Dan')) # Wait for the worker to finish queue.close() queue.join_thread() p.join()
This small example simply sends a message to a worker process, and the main process waits for the worker process to complete.
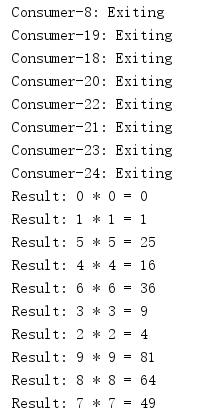
A more complex example shows how to manage multiple worker processes that consume data from a JoinableQueue and pass the results back to the parent process.Poison technology is used here to stop the process.After a specific task is established, the main program adds a "stop" value to each worker process in the job queue.When a worker process encounters this specific value, it exits its processing cycle.The main process uses the join() method of the task queue to wait for all tasks to complete before it begins processing the results.
import multiprocessing import time class Consumer(multiprocessing.Process): def __init__(self, task_queue, result_queue): multiprocessing.Process.__init__(self) self.task_queue = task_queue self.result_queue = result_queue def run(self): proc_name = self.name while True: next_task = self.task_queue.get() if next_task is None: # Poison pill means shutdown print('{}: Exiting'.format(proc_name)) self.task_queue.task_done() break print('{}: {}'.format(proc_name, next_task)) answer = next_task() self.task_queue.task_done() self.result_queue.put(answer) class Task: def __init__(self, a, b): self.a = a self.b = b def __call__(self): time.sleep(0.1) # pretend to take time to do the work return '{self.a} * {self.b} = {product}'.format( self=self, product=self.a * self.b) def __str__(self): return '{self.a} * {self.b}'.format(self=self) if __name__ == '__main__': # Establish communication queues tasks = multiprocessing.JoinableQueue() results = multiprocessing.Queue() # Start consumers num_consumers = multiprocessing.cpu_count() * 2 print('Creating {} consumers'.format(num_consumers)) consumers = [ Consumer(tasks, results) for i in range(num_consumers) ] for w in consumers: w.start() # Enqueue jobs num_jobs = 10 for i in range(num_jobs): tasks.put(Task(i, i)) # Add a poison pill for each consumer for i in range(num_consumers): tasks.put(None) # Wait for all of the tasks to finish tasks.join() # Start printing results while num_jobs: result = results.get() print('Result:', result) num_jobs -= 1
Although jobs are queued sequentially, their execution is parallel, so the order in which they are completed cannot be guaranteed.

1.11 Interprocess Signal Transfer
Event classes provide a simple way to transfer state information between processes.Events can switch between set and unset states.By using an optional timeout value, the user of the event object can wait for its state to never change from set to set.
import multiprocessing import time def wait_for_event(e): """Wait for the event to be set before doing anything""" print('wait_for_event: starting') e.wait() print('wait_for_event: e.is_set()->', e.is_set()) def wait_for_event_timeout(e, t): """Wait t seconds and then timeout""" print('wait_for_event_timeout: starting') e.wait(t) print('wait_for_event_timeout: e.is_set()->', e.is_set()) if __name__ == '__main__': e = multiprocessing.Event() w1 = multiprocessing.Process( name='block', target=wait_for_event, args=(e,), ) w1.start() w2 = multiprocessing.Process( name='nonblock', target=wait_for_event_timeout, args=(e, 2), ) w2.start() print('main: waiting before calling Event.set()') time.sleep(3) e.set() print('main: event is set')
wait() returns when the time is up and there are no errors.The caller is responsible for checking the state of the event using is_set().

1.12 Control Resource Access
If you need to share a resource among multiple processes, you can use a Lock to avoid access conflicts in this case.
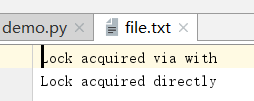
import multiprocessing def worker_with(lock, f): with lock: fs = open(f, "a+") fs.write('Lock acquired via with\n') fs.close() def worker_no_with(lock, f): lock.acquire() try: fs = open(f, "a+") fs.write('Lock acquired directly\n') fs.close() finally: lock.release() if __name__ == "__main__": f = "file.txt" lock = multiprocessing.Lock() w = multiprocessing.Process(target=worker_with, args=(lock, f)) nw = multiprocessing.Process(target=worker_no_with, args=(lock, f)) w.start() nw.start() w.join() nw.join()
In this example, if the two processes do not synchronize their output stream access with locks, messages printed to the console may become tangled.
1.13 Synchronization Operation
Condition objects can be used to synchronize parts of a workflow so that some parts run in parallel and others run in sequence, even if they are in different processes.
import multiprocessing import time def stage_1(cond): """perform first stage of work, then notify stage_2 to continue """ name = multiprocessing.current_process().name print('Starting', name) with cond: print('{} done and ready for stage 2'.format(name)) cond.notify_all() def stage_2(cond): """wait for the condition telling us stage_1 is done""" name = multiprocessing.current_process().name print('Starting', name) with cond: cond.wait() print('{} running'.format(name)) if __name__ == '__main__': condition = multiprocessing.Condition() s1 = multiprocessing.Process(name='s1', target=stage_1, args=(condition,)) s2_clients = [ multiprocessing.Process( name='stage_2[{}]'.format(i), target=stage_2, args=(condition,), ) for i in range(1, 3) ] for c in s2_clients: c.start() time.sleep(1) s1.start() s1.join() for c in s2_clients: c.join()
In this example, two processes run the second phase of a job in parallel, but only if the first phase is complete.

1.14 Controlling concurrent access to resources
Sometimes it may be necessary to allow multiple worker processes to access a resource at the same time, but limit the total number.At this point we can use Semaphore to manage.
import multiprocessing import time def worker(s, i): s.acquire() print(multiprocessing.current_process().name + " acquire") time.sleep(i) print(multiprocessing.current_process().name + " release") s.release() if __name__ == "__main__": s = multiprocessing.Semaphore(2) for i in range(5): p = multiprocessing.Process(target=worker, args=(s, i * 2)) p.start()

1.15 Manage Sharing Status
Manager is responsible for coordinating the status of information shared among all its users.
import multiprocessing def worker(d, key, value): d[key] = value if __name__ == '__main__': mgr = multiprocessing.Manager() d = mgr.dict() jobs = [ multiprocessing.Process( target=worker, args=(d, i, i * 2), ) for i in range(10) ] for j in jobs: j.start() for j in jobs: j.join() print('Results:', d)
Because this list was created by the manager, it will be shared by all processes, and all processes will see updates to this list.In addition to lists, the manager supports dictionaries.
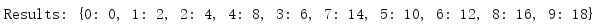
1.16 Shared Namespace
In addition to dictionaries and lists, Manager can create a shared Namespace.
import multiprocessing def producer(ns, event): ns.value = 'This is the value' event.set() def consumer(ns, event): try: print('Before event: {}'.format(ns.value)) except Exception as err: print('Before event, error:', str(err)) event.wait() print('After event:', ns.value) if __name__ == '__main__': mgr = multiprocessing.Manager() namespace = mgr.Namespace() event = multiprocessing.Event() p = multiprocessing.Process( target=producer, args=(namespace, event), ) c = multiprocessing.Process( target=consumer, args=(namespace, event), ) c.start() p.start() c.join() p.join()
All named values added to Namespace are visible to all clients receiving Namespace instances.
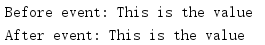
Updates to variable-value content in the namespace do not propagate automatically.
import multiprocessing def producer(ns, event): # DOES NOT UPDATE GLOBAL VALUE! ns.my_list.append('This is the value') event.set() def consumer(ns, event): print('Before event:', ns.my_list) event.wait() print('After event :', ns.my_list) if __name__ == '__main__': mgr = multiprocessing.Manager() namespace = mgr.Namespace() namespace.my_list = [] event = multiprocessing.Event() p = multiprocessing.Process( target=producer, args=(namespace, event), ) c = multiprocessing.Process( target=consumer, args=(namespace, event), ) c.start() p.start() c.join() p.join()
To update this list, you need to associate it with a namespace object again.

1.17 Process Pool
In some cases, the work to be done can be broken down and distributed independently across multiple worker processes, and in this simple case, a Pool class can be used to manage a fixed number of worker processes.The returns from each job are collected and returned as a list.The pool parameters include the number of processes and the function to run when the task process is started (called once per subprocess).
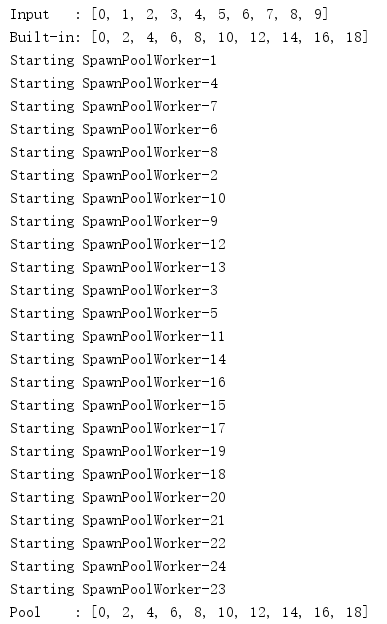
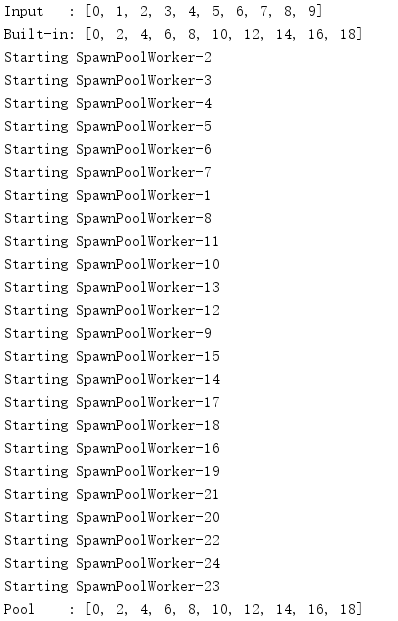
import multiprocessing def do_calculation(data): return data * 2 def start_process(): print('Starting', multiprocessing.current_process().name) if __name__ == '__main__': inputs = list(range(10)) print('Input :', inputs) builtin_outputs = list(map(do_calculation, inputs)) print('Built-in:', builtin_outputs) pool_size = multiprocessing.cpu_count() * 2 pool = multiprocessing.Pool( processes=pool_size, initializer=start_process, ) pool_outputs = pool.map(do_calculation, inputs) pool.close() # no more tasks pool.join() # wrap up current tasks print('Pool :', pool_outputs)
The result of the map() method is functionally equivalent to that of the built-in map(), except that the tasks run in parallel.Since the process pool processes inputs in parallel, close() and join() can be used to synchronize the task process with the main process to ensure proper cleanup is completed.
By default, Pool creates a fixed number of worker processes and passes jobs to them until there are no more jobs.Setting the maxtasksperchild parameter tells the pool to restart a worker process after completing some tasks to avoid long-running worker processes consuming more system resources.
import multiprocessing def do_calculation(data): return data * 2 def start_process(): print('Starting', multiprocessing.current_process().name) if __name__ == '__main__': inputs = list(range(10)) print('Input :', inputs) builtin_outputs = list(map(do_calculation, inputs)) print('Built-in:', builtin_outputs) pool_size = multiprocessing.cpu_count() * 2 pool = multiprocessing.Pool( processes=pool_size, initializer=start_process, maxtasksperchild=2, ) pool_outputs = pool.map(do_calculation, inputs) pool.close() # no more tasks pool.join() # wrap up current tasks print('Pool :', pool_outputs)
When the pool finishes its assigned tasks, the worker process is restarted even if there is no more work to do.From the output below, you can see that although there are only 10 tasks and each worker process can complete two tasks at a time, there are eight worker processes created here.