1. Manage concurrent operations in threading processes
The threading module provides an API to manage the execution of multiple threads, allowing programs to run multiple operations concurrently in the same process space.
1.1 Thread object
The easiest way to use Thread is to instantiate a Thread object with a target function and call start() to get it working.
import threading def worker(): """thread worker function""" print('Worker') threads = [] for i in range(5): t = threading.Thread(target=worker) threads.append(t) t.start()
The output has five lines, each of which is a "Worker".

This is useful if you can create a thread and pass parameters to it to tell it what to do.Any type of object can be passed to the thread as a parameter.The following example passes a number that the thread will print out.
import threading def worker(num): """thread worker function""" print('Worker: %s' % num) threads = [] for i in range(5): t = threading.Thread(target=worker, args=(i,)) threads.append(t) t.start()
Now this integer parameter is included in the messages printed by each thread.

1.2 Determine the current thread
Using parameters to identify or name threads is cumbersome and unnecessary.Each Thread instance has a name with a default value that can be changed when a thread is created.Naming threads is useful in server processes where multiple service threads handle different operations.
import threading import time def worker(): print(threading.current_thread().getName(), 'Starting') time.sleep(0.2) print(threading.current_thread().getName(), 'Exiting') def my_service(): print(threading.current_thread().getName(), 'Starting') time.sleep(0.3) print(threading.current_thread().getName(), 'Exiting') t = threading.Thread(name='my_service', target=my_service) w = threading.Thread(name='worker', target=worker) w2 = threading.Thread(target=worker) # use default name w.start() w2.start() t.start()
Each line of debug output contains the name of the current thread."Thread-1" row in the thread name column corresponds to unnamed thread w2.

Most programs do not use print for debugging.The logging module supports embedding thread names into individual log messages using formatting codes (threadName) s.By including the thread name in the log messages, you can track the source of these messages.
import logging import threading import time def worker(): logging.debug('Starting') time.sleep(0.2) logging.debug('Exiting') def my_service(): logging.debug('Starting') time.sleep(0.3) logging.debug('Exiting') logging.basicConfig( level=logging.DEBUG, format='[%(levelname)s] (%(threadName)-10s) %(message)s', ) t = threading.Thread(name='my_service', target=my_service) w = threading.Thread(name='worker', target=worker) w2 = threading.Thread(target=worker) # use default name w.start() w2.start() t.start()
And logging s are thread-safe, so messages from different threads are distinguished in the output.

1.3 Daemon and non-daemon threads
So far, the sample program has implicitly waited for all threads to finish their work before exiting.However, there are
A thread is created as a daemon that can run all the time without blocking the main program from exiting.
If a service cannot easily interrupt a thread, or even if the thread is stopped in half, it will not cause data
Loss or destruction (for example, generating a "heartbeat" thread for a service monitoring tool), then for these services, use
Daemon threads are useful.To mark a thread as a daemon thread, pass in daemon=True or when a thread is constructed
The user calls its setDaemon() method and provides the parameter True.Threads are not daemon threads by default.
import threading import time import logging def daemon(): logging.debug('Starting') time.sleep(0.2) logging.debug('Exiting') def non_daemon(): logging.debug('Starting') logging.debug('Exiting') logging.basicConfig( level=logging.DEBUG, format='(%(threadName)-10s) %(message)s', ) d = threading.Thread(name='daemon', target=daemon, daemon=True) t = threading.Thread(name='non-daemon', target=non_daemon) d.start() t.start()
The output of this code does not contain the "Exiting" message for the daemon thread because it wakes up from a sleep() call
All non-daemon threads (including the main thread) have exited before the daemon thread.

To wait for a daemon thread to complete its work, you need to use the join() method.
import threading import time import logging def daemon(): logging.debug('Starting') time.sleep(0.2) logging.debug('Exiting') def non_daemon(): logging.debug('Starting') logging.debug('Exiting') logging.basicConfig( level=logging.DEBUG, format='(%(threadName)-10s) %(message)s', ) d = threading.Thread(name='daemon', target=daemon, daemon=True) t = threading.Thread(name='non-daemon', target=non_daemon) d.start() t.start() d.join() t.join()
Waiting for the daemon thread to exit using join() means it has the opportunity to generate its "Exiting" message.

By default, join() is blocked indefinitely.Alternatively, you can pass in a floating-point value indicating how long the waiting thread is
Time (seconds) becomes inactive.join() returns even if the thread has not completed within this time period.
import threading import time import logging def daemon(): logging.debug('Starting') time.sleep(0.2) logging.debug('Exiting') def non_daemon(): logging.debug('Starting') logging.debug('Exiting') logging.basicConfig( level=logging.DEBUG, format='(%(threadName)-10s) %(message)s', ) d = threading.Thread(name='daemon', target=daemon, daemon=True) t = threading.Thread(name='non-daemon', target=non_daemon) d.start() t.start() d.join(0.1) print('d.isAlive()', d.isAlive()) t.join()
Since the heir timeout is less than the daemon thread sleeps, the thread remains "alive" after join() returns.

1.4 Enumerate all threads
There is no need to maintain a display handle for all daemon threads to ensure that they are finished before exiting the main process.
enumerate() returns a list of active Thread instances.This list also includes the current thread because
Waiting for the current thread to terminate (join) introduces a deadlock condition and must be skipped.
import random import threading import time import logging def worker(): """thread worker function""" pause = random.randint(1, 5) / 10 logging.debug('sleeping %0.2f', pause) time.sleep(pause) logging.debug('ending') logging.basicConfig( level=logging.DEBUG, format='(%(threadName)-10s) %(message)s', ) for i in range(3): t = threading.Thread(target=worker, daemon=True) t.start() main_thread = threading.main_thread() for t in threading.enumerate(): if t is main_thread: continue logging.debug('joining %s', t.getName()) t.join()
Since the amount of time a worker thread sleeps is random, the output of this program may change.

1.5 Derived Threads
At first, Thread completes some basic initialization, then calls its run() method, which calls the target function passed to the constructor.To create a subclass of Thread, you need to override run() to do the work you need.
import threading import logging class MyThread(threading.Thread): def run(self): logging.debug('running') logging.basicConfig( level=logging.DEBUG, format='(%(threadName)-10s) %(message)s', ) for i in range(5): t = MyThread() t.start()
The return value of run() will be ignored.

Since the args and kwargs values passed to the Thread constructor are stored in private variables (these variable names are prefixed), they cannot be easily accessed from subclasses.To pass parameters to a custom thread type, you need to redefine the constructor and save the values in an instance property visible to the subclass.
import threading import logging class MyThreadWithArgs(threading.Thread): def __init__(self, group=None, target=None, name=None, args=(), kwargs=None, *, daemon=None): super().__init__(group=group, target=target, name=name, daemon=daemon) self.args = args self.kwargs = kwargs def run(self): logging.debug('running with %s and %s', self.args, self.kwargs) logging.basicConfig( level=logging.DEBUG, format='(%(threadName)-10s) %(message)s', ) for i in range(5): t = MyThreadWithArgs(args=(i,), kwargs={'a': 'A', 'b': 'B'}) t.start()
MyThreadwithArgs uses the same API as Thread, but like other custom classes, this class can easily modify the constructor method to get more parameters or different parameters that are more directly related to the purpose of the thread.

1.6 Timer Threads
Sometimes for some reason you need to derive Thread, Timer is an example, and Timer is included in threading.Timer starts working after a delay and can be cancelled at any time during that delay.
import threading import time import logging def delayed(): logging.debug('worker running') logging.basicConfig( level=logging.DEBUG, format='(%(threadName)-10s) %(message)s', ) t1 = threading.Timer(0.3, delayed) t1.setName('t1') t2 = threading.Timer(0.3, delayed) t2.setName('t2') logging.debug('starting timers') t1.start() t2.start() logging.debug('waiting before canceling %s', t2.getName()) time.sleep(0.2) logging.debug('canceling %s', t2.getName()) t2.cancel() logging.debug('done')
In this example, the second timer will never run, and it looks like the first timer will run after the rest of the main program is finished.Since this is not a daemon thread, it exits implicitly when the main thread finishes.

1.7 Signaling Between Threads
Although the goal of using multithreading is to run separate operations concurrently, it is sometimes necessary to synchronize operations in two or more threads.Event objects are a simple way to achieve secure communication between threads.Event manages an internal flag that callers can control using set () and clear () methods.Other threads can use wait () to pause until this flag is set, effectively blocking processes until they are allowed to continue.
import logging import threading import time def wait_for_event(e): """Wait for the event to be set before doing anything""" logging.debug('wait_for_event starting') event_is_set = e.wait() logging.debug('event set: %s', event_is_set) def wait_for_event_timeout(e, t): """Wait t seconds and then timeout""" while not e.is_set(): logging.debug('wait_for_event_timeout starting') event_is_set = e.wait(t) logging.debug('event set: %s', event_is_set) if event_is_set: logging.debug('processing event') else: logging.debug('doing other work') logging.basicConfig( level=logging.DEBUG, format='(%(threadName)-10s) %(message)s', ) e = threading.Event() t1 = threading.Thread( name='block', target=wait_for_event, args=(e,), ) t1.start() t2 = threading.Thread( name='nonblock', target=wait_for_event_timeout, args=(e, 2), ) t2.start() logging.debug('Waiting before calling Event.set()') time.sleep(0.3) e.set() logging.debug('Event is set')
The wait() method takes a parameter that represents the time (in seconds) to wait for an event before it times out.it
A Boolean value is returned indicating whether the event has been set so that the caller knows why wait() returns.Yes
Parts use the is_set() method alone without worrying about blocking.
In this example, wait_for_event_timeout() checks the state of the event without infinite blocking.wait_for_event() is blocked at the location of the wait() call and will not return until the state of the event changes.

1.8 Control Resource Access
In addition to synchronizing thread operations, it is important to be able to control access to shared resources so as to avoid damaging or losing data.Python's built-in data structures (lists, dictionaries, and so on) are thread-safe, which is a side effect of Python using atomic byte codes to manage these data structures (the global interpreter lock GIL (Global Interpreter Lock) that protects Python's internal data structures is not released during updates).Other data structures implemented in Python or simpler types, such as integers and floating-point numbers, do not have this protection.To ensure secure access to an object at the same time, you can use a Lock object.
import logging import random import threading import time class Counter: def __init__(self, start=0): self.lock = threading.Lock() self.value = start def increment(self): logging.debug('Waiting for lock') self.lock.acquire() try: logging.debug('Acquired lock') self.value = self.value + 1 finally: self.lock.release() def worker(c): for i in range(2): pause = random.random() logging.debug('Sleeping %0.02f', pause) time.sleep(pause) c.increment() logging.debug('Done') logging.basicConfig( level=logging.DEBUG, format='(%(threadName)-10s) %(message)s', ) counter = Counter() for i in range(2): t = threading.Thread(target=worker, args=(counter,)) t.start() logging.debug('Waiting for worker threads') main_thread = threading.main_thread() for t in threading.enumerate(): if t is not main_thread: t.join() logging.debug('Counter: %d', counter.value)
In this example, the worker() function increments a Counter instance, which manages a Lock to avoid two threads changing their internal state at the same time.If you do not use Lock, you may lose one modification to the value property.

To determine if another thread is requesting the lock without affecting the current thread, pass False to the blocking parameter of acquire().In the next example, worker() wants to get three locks, respectively, and counts the number of attempts to get the locks.At the same time, lock_holder() loops between holding and releasing locks, and each state pauses briefly to simulate load conditions.
import logging import threading import time def lock_holder(lock): logging.debug('Starting') while True: lock.acquire() try: logging.debug('Holding') time.sleep(0.5) finally: logging.debug('Not holding') lock.release() time.sleep(0.5) def worker(lock): logging.debug('Starting') num_tries = 0 num_acquires = 0 while num_acquires < 3: time.sleep(0.5) logging.debug('Trying to acquire') have_it = lock.acquire(0) try: num_tries += 1 if have_it: logging.debug('Iteration %d: Acquired', num_tries) num_acquires += 1 else: logging.debug('Iteration %d: Not acquired', num_tries) finally: if have_it: lock.release() logging.debug('Done after %d iterations', num_tries) logging.basicConfig( level=logging.DEBUG, format='(%(threadName)-10s) %(message)s', ) lock = threading.Lock() holder = threading.Thread( target=lock_holder, args=(lock,), name='LockHolder', daemon=True, ) holder.start() worker = threading.Thread( target=worker, args=(lock,), name='Worker', ) worker.start()
worker() needs more than three iterations to get three locks.

1.8.1 Re-lock
Normal Lock objects cannot be requested multiple times, even by the same thread.If more than one function in the same call chain accesses a lock, there may be unwanted side effects.
import threading lock = threading.Lock() print('First try :', lock.acquire()) print('Second try:', lock.acquire(0))
Here, a given timeout value of 0 is given for the second acquire() call to avoid blocking because the lock has already been acquired by the first call.

If different code from the same thread needs to "reacquire" the lock, then RLock is used in this case.
import threading lock = threading.RLock() print('First try :', lock.acquire()) print('Second try:', lock.acquire(0))
Compared with the previous example, the only modification to the code is to replace Lock with RLock.

1.8.2 Lock as Context Manager
Locks implement the context manager API and are compatible with the with statement.With with, you no longer need to explicitly acquire and release locks.
import threading import logging def worker_with(lock): with lock: logging.debug('Lock acquired via with') def worker_no_with(lock): lock.acquire() try: logging.debug('Lock acquired directly') finally: lock.release() logging.basicConfig( level=logging.DEBUG, format='(%(threadName)-10s) %(message)s', ) lock = threading.Lock() w = threading.Thread(target=worker_with, args=(lock,)) nw = threading.Thread(target=worker_no_with, args=(lock,)) w.start() nw.start()
The functions worker_with() and worker_no_with() manage locks in an equivalent manner.

1.9 Synchronization Threads
In addition to using Event s, you can synchronize threads by using a Condition object.Since Condition uses a Lock, it can be bound to a shared resource, allowing multiple threads to wait for resource updates.In the next example, the consumer() thread waits for Conditions to be set before continuing.The producer() thread is responsible for setting conditions and notifying other threads to continue.
import logging import threading import time def consumer(cond): """wait for the condition and use the resource""" logging.debug('Starting consumer thread') with cond: cond.wait() logging.debug('Resource is available to consumer') def producer(cond): """set up the resource to be used by the consumer""" logging.debug('Starting producer thread') with cond: logging.debug('Making resource available') cond.notifyAll() logging.basicConfig( level=logging.DEBUG, format='%(asctime)s (%(threadName)-2s) %(message)s', ) condition = threading.Condition() c1 = threading.Thread(name='c1', target=consumer, args=(condition,)) c2 = threading.Thread(name='c2', target=consumer, args=(condition,)) p = threading.Thread(name='p', target=producer, args=(condition,)) c1.start() time.sleep(0.2) c2.start() time.sleep(0.2) p.start()
These threads use with to acquire locks associated with Condition s.The acquire() and release() methods can also be used explicitly.

Barriers are another thread synchronization mechanism.Barrier will set up a control point where all participating threads will block until all these participating "parties" have reached this point.In this way, threads can start and pause independently until all threads are ready to continue.
import threading import time def worker(barrier): print(threading.current_thread().name, 'waiting for barrier with {} others'.format( barrier.n_waiting)) worker_id = barrier.wait() print(threading.current_thread().name, 'after barrier', worker_id) NUM_THREADS = 3 barrier = threading.Barrier(NUM_THREADS) threads = [ threading.Thread( name='worker-%s' % i, target=worker, args=(barrier,), ) for i in range(NUM_THREADS) ] for t in threads: print(t.name, 'starting') t.start() time.sleep(0.1) for t in threads: t.join()
In this example, Barrier is configured to block threads until three threads are waiting.When this condition is met, all threads are released simultaneously to cross this control point.The return value of wait() indicates the number of participating threads released and can be used to limit some threads to actions such as cleaning up resources.

Barrier's abort() method causes all waiting threads to receive a BrokenBarrierError.If the thread is blocked on wait() and stops processing, this allows the thread to complete the cleanup.
import threading import time def worker(barrier): print(threading.current_thread().name, 'waiting for barrier with {} others'.format( barrier.n_waiting)) try: worker_id = barrier.wait() except threading.BrokenBarrierError: print(threading.current_thread().name, 'aborting') else: print(threading.current_thread().name, 'after barrier', worker_id) NUM_THREADS = 3 barrier = threading.Barrier(NUM_THREADS + 1) threads = [ threading.Thread( name='worker-%s' % i, target=worker, args=(barrier,), ) for i in range(NUM_THREADS) ] for t in threads: print(t.name, 'starting') t.start() time.sleep(0.1) barrier.abort() for t in threads: t.join()
This example configures Barrier to have one more thread, that is, one more participating thread than the one actually started, so processing in all threads will be blocked.The abort() call produces an exception on each blocked thread.

1.10 Restrict concurrent access to resources
Sometimes you may need to allow multiple worker threads to access a resource at the same time, but limit the total number.For example, a connection pool may support simultaneous connections, but the number may be fixed, or a network application may support a fixed number of concurrent downloads.These connections can be managed using Semaphore.
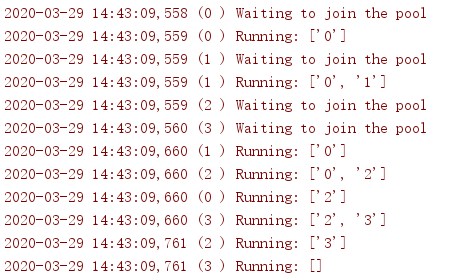
import logging import threading import time class ActivePool: def __init__(self): super(ActivePool, self).__init__() self.active = [] self.lock = threading.Lock() def makeActive(self, name): with self.lock: self.active.append(name) logging.debug('Running: %s', self.active) def makeInactive(self, name): with self.lock: self.active.remove(name) logging.debug('Running: %s', self.active) def worker(s, pool): logging.debug('Waiting to join the pool') with s: name = threading.current_thread().getName() pool.makeActive(name) time.sleep(0.1) pool.makeInactive(name) logging.basicConfig( level=logging.DEBUG, format='%(asctime)s (%(threadName)-2s) %(message)s', ) pool = ActivePool() s = threading.Semaphore(2) for i in range(4): t = threading.Thread( target=worker, name=str(i), args=(s, pool), ) t.start()
In this example, the ActivePool class is used only as a convenient way to track which threads are running at a given time.A true resource pool assigns a connection or another value to a new active thread and recycles the value when the thread finishes its work.Here, the resource pool is simply used to hold the name of the active thread to show that at least two threads are running concurrently.
1.11 Thread-specific data
Some resources need to be locked for use by multiple threads, while others need to be protected so that they are hidden from threads that are not "owners" of these resources.The local() function creates an object that hides values so that they cannot be seen in different threads.
import random import threading import logging def show_value(data): try: val = data.value except AttributeError: logging.debug('No value yet') else: logging.debug('value=%s', val) def worker(data): show_value(data) data.value = random.randint(1, 100) show_value(data) logging.basicConfig( level=logging.DEBUG, format='(%(threadName)-10s) %(message)s', ) local_data = threading.local() show_value(local_data) local_data.value = 1000 show_value(local_data) for i in range(2): t = threading.Thread(target=worker, args=(local_data,)) t.start()
The property local_data.value is not visible to all threads until it is set in a thread.

To initialize the settings so that all threads start with the same value, you can use a subclass and set these properties in _init_().
import random import threading import logging def show_value(data): try: val = data.value except AttributeError: logging.debug('No value yet') else: logging.debug('value=%s', val) def worker(data): show_value(data) data.value = random.randint(1, 100) show_value(data) class MyLocal(threading.local): def __init__(self, value): super().__init__() logging.debug('Initializing %r', self) self.value = value logging.basicConfig( level=logging.DEBUG, format='(%(threadName)-10s) %(message)s', ) local_data = MyLocal(1000) show_value(local_data) for i in range(2): t = threading.Thread(target=worker, args=(local_data,)) t.start()
This calls _init_() (note the id() value) on the same object, once per thread to set the default value.
