1. Codcs string encoding and decoding
The codecs module provides both stream and file interfaces to convert different representations of text data.Usually used to process Unicode text, but additional encoding is provided for other purposes.
1.1 Getting started with Unicode
CPython 3.x distinguishes between text and byte strings.The bytes instance uses an 8-bit sequence of byte values.In contrast, str strings are managed internally as a Unicode point sequence.Code point values are expressed as 2 or 4 bytes, depending on the options specified when compiling Python.(
When str values are output, they are encoded using a standard mechanism that can be later reconstructed to the same text string.The bytes of the coded values are not necessarily identical to the code point values, and encoding is only one way to define the conversion between two sets of values.You also need to know the encoding when reading Unicode data so that the bytes received can be converted to the internal representation used by the Unicode class.
The most commonly used codes in Western languages are UTF-8 and UTF-16, which use a sequence of single-byte and two-byte values to represent each code point.For other languages, since most characters are represented by code points of more than two bytes, it may be more efficient to store them using other encodings.
The best way to understand encoding is to code the same string differently and see the different byte sequences that are generated.The following example formats the byte string using the following functions to make it easier to read.
import binascii def to_hex(t, nbytes): """Format text t as a sequence of nbyte long values separated by spaces. """ chars_per_item = nbytes * 2 hex_version = binascii.hexlify(t) return b' '.join( hex_version[start:start + chars_per_item] for start in range(0, len(hex_version), chars_per_item) ) if __name__ == '__main__': print(to_hex(b'abcdef', 1)) print(to_hex(b'abcdef', 2))
This function uses binascii to get the hexadecimal representation of the input byte string and inserts a space every nbytes before returning this value.

The first encoding example uses the original representation of the Unicode class to print the text'francais', followed by the names of individual characters in the Unicode database.The next two lines encode the string as UTF-8 and UTF-16, respectively, and display the encoded hexadecimal values.
import unicodedata import binascii def to_hex(t, nbytes): """Format text t as a sequence of nbyte long values separated by spaces. """ chars_per_item = nbytes * 2 hex_version = binascii.hexlify(t) return b' '.join( hex_version[start:start + chars_per_item] for start in range(0, len(hex_version), chars_per_item) ) text = 'français' print('Raw : {!r}'.format(text)) for c in text: print(' {!r}: {}'.format(c, unicodedata.name(c, c))) print('UTF-8 : {!r}'.format(to_hex(text.encode('utf-8'), 1))) print('UTF-16: {!r}'.format(to_hex(text.encode('utf-16'), 2)))
The result of encoding a str is a bytes object.

Given a sequence of encoded bytes (as a bytes instance), the decode() method converts it to a code point and returns the sequence as a str instance.(
import binascii def to_hex(t, nbytes): """Format text t as a sequence of nbyte long values separated by spaces. """ chars_per_item = nbytes * 2 hex_version = binascii.hexlify(t) return b' '.join( hex_version[start:start + chars_per_item] for start in range(0, len(hex_version), chars_per_item) ) text = 'français' encoded = text.encode('utf-8') decoded = encoded.decode('utf-8') print('Original :', repr(text)) print('Encoded :', to_hex(encoded, 1), type(encoded)) print('Decoded :', repr(decoded), type(decoded))
Choosing which encoding to use does not change the output type.

1.2 Processing Files
Encoding and decoding strings are particularly important when working with I/O operations.Whether written to a file, socket, or other stream, the data must be properly encoded.Generally speaking, all text data needs to be decoded by its byte representation when it is read and encoded from its internal value when it is written.Programs can explicitly encode and decode data, but depending on the encoding used, it may not be easy to determine if enough bytes have been read to adequately decode the data.Codcs provides classes to manage data encoding and decoding, so applications no longer need to do this.
The simplest interface provided by codecs can replace the built-in open() function.This new version of the function does much the same as the built-in function, but adds two parameters to specify the encoding and error handling required.(
import binascii import codecs def to_hex(t, nbytes): """Format text t as a sequence of nbyte long values separated by spaces. """ chars_per_item = nbytes * 2 hex_version = binascii.hexlify(t) return b' '.join( hex_version[start:start + chars_per_item] for start in range(0, len(hex_version), chars_per_item) ) encodings = ['utf-8','utf-16','utf-32'] for encoding in encodings: filename = encoding + '.txt' print('Writing to', filename) with codecs.open(filename, mode='w', encoding=encoding) as f: f.write('français') # Determine the byte grouping to use for to_hex() nbytes = { 'utf-8': 1, 'utf-16': 2, 'utf-32': 4, }.get(encoding, 1) # Show the raw bytes in the file print('File contents:') with open(filename, mode='rb') as f: print(to_hex(f.read(), nbytes))
This example first deals with a unicode string that contains23

Reading data with open() is easy, but one thing to note is that you must know the encoding in advance to properly build the decoder.Although some data formats, such as XML, specify encoding in the file, they are usually managed by the application.Codcs takes only one encoding parameter and assumes that the encoding is correct.
import binascii import codecs def to_hex(t, nbytes): """Format text t as a sequence of nbyte long values separated by spaces. """ chars_per_item = nbytes * 2 hex_version = binascii.hexlify(t) return b' '.join( hex_version[start:start + chars_per_item] for start in range(0, len(hex_version), chars_per_item) ) encodings = ['utf-8','utf-16','utf-32'] for encoding in encodings: filename = encoding + '.txt' print('Reading from', filename) with codecs.open(filename, mode='r', encoding=encoding) as f: print(repr(f.read()))
This example reads a file created by the previous program and prints the representation of the resulting unicode object to the console.

1.3 Byte Order
Multibyte encoding, such as UTF-16 and UTF-32, can present a problem when transferring data between different computer systems, possibly directly copying a file or using network communication to complete the transfer.High and low bytes are used in different systems in different order.This feature of the data is called endianness, depending on factors such as hardware architecture and the choice made by the operating system and application developers.There is usually no way to know in advance which byte order to use for a given set of data, so multibyte encoding also contains a Byte-Order Marker (BOM), which appears in the first few bytes of the encoded output.For example, UTF-16 defines 0xFFFE and 0xFEFF as not legal characters and can be used to indicate byte order.Codcs define the corresponding constants for the byte order flags used in UTF-16 and UTF-32.
import codecs import binascii def to_hex(t, nbytes): """Format text t as a sequence of nbyte long values separated by spaces. """ chars_per_item = nbytes * 2 hex_version = binascii.hexlify(t) return b' '.join( hex_version[start:start + chars_per_item] for start in range(0, len(hex_version), chars_per_item) ) BOM_TYPES = [ 'BOM', 'BOM_BE', 'BOM_LE', 'BOM_UTF8', 'BOM_UTF16', 'BOM_UTF16_BE', 'BOM_UTF16_LE', 'BOM_UTF32', 'BOM_UTF32_BE', 'BOM_UTF32_LE', ] for name in BOM_TYPES: print('{:12} : {}'.format( name, to_hex(getattr(codecs, name), 2)))
Depending on the native byte order of the current system, BOM, BOM_UTF16, and BOM_UTF32 are automatically set to appropriate large-endian or small-endian values.

The byte order can be automatically detected and processed by the decoder in codecs, or it can be explicitly specified when encoding.(
import codecs import binascii def to_hex(t, nbytes): """Format text t as a sequence of nbyte long values separated by spaces. """ chars_per_item = nbytes * 2 hex_version = binascii.hexlify(t) return b' '.join( hex_version[start:start + chars_per_item] for start in range(0, len(hex_version), chars_per_item) ) # Pick the nonnative version of UTF-16 encoding if codecs.BOM_UTF16 == codecs.BOM_UTF16_BE: bom = codecs.BOM_UTF16_LE encoding = 'utf_16_le' else: bom = codecs.BOM_UTF16_BE encoding = 'utf_16_be' print('Native order :', to_hex(codecs.BOM_UTF16, 2)) print('Selected order:', to_hex(bom, 2)) # Encode the text. encoded_text = 'français'.encode(encoding) print('{:14}: {}'.format(encoding, to_hex(encoded_text, 2))) with open('nonnative-encoded.txt', mode='wb') as f: # Write the selected byte-order marker. It is not included # in the encoded text because the byte order was given # explicitly when selecting the encoding. f.write(bom) # Write the byte string for the encoded text. f.write(encoded_text)
The native byte order is derived first, and then an explicit alternative is used so that the next example can automatically detect the byte order when displaying a read.

The program does not specify the byte order when it opens the file, so the decoder uses the BOM values in the first two bytes of the file to determine the byte order.(
import codecs import binascii def to_hex(t, nbytes): """Format text t as a sequence of nbyte long values separated by spaces. """ chars_per_item = nbytes * 2 hex_version = binascii.hexlify(t) return b' '.join( hex_version[start:start + chars_per_item] for start in range(0, len(hex_version), chars_per_item) ) # Look at the raw data with open('nonnative-encoded.txt', mode='rb') as f: raw_bytes = f.read() print('Raw :', to_hex(raw_bytes, 2)) # Re-open the file and let codecs detect the BOM with codecs.open('nonnative-encoded.txt', mode='r', encoding='utf-16', ) as f: decoded_text = f.read() print('Decoded:', repr(decoded_text))
Since the first two bytes of the file are used for byte order detection, they are not included in the data returned by read().
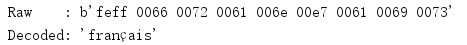
1.4 Error Handling
The previous sections pointed out that you need to know the encoding used when reading and writing Unicode files.It is important to set the encoding correctly for two reasons: First, if you do not configure the encoding correctly when reading the file, you will not be able to interpret the data correctly, and the data may be corrupted or decoded, resulting in an error and data loss.(
Like str's encode() method and bytes'decode() method, codecs uses the same five error handling options.
| Error mode | describe |
|---|---|
| strict | An exception is thrown if the data cannot be converted. |
| replace | Replace special marker characters with data that cannot be encoded. |
| ignore | Skip data. |
| xmlcharrefreplace | XML characters (encoding only) |
| backslashreplace | Escape Sequence (Coding Only) |
1.4.1 Encoding Error
The most common error is receiving a UnicodeEncodeError when writing Unicode data to an ASCII output stream, such as a regular file or sys.stdout.
import codecs error_handlings = ['strict','replace','ignore','xmlcharrefreplace','backslashreplace'] text = 'français' for error_handling in error_handlings: try: # Save the data, encoded as ASCII, using the error # handling mode specified on the command line. with codecs.open('encode_error.txt', 'w', encoding='ascii', errors=error_handling) as f: f.write(text) except UnicodeEncodeError as err: print('ERROR:', err) else: # If there was no error writing to the file, # show what it contains. with open('encode_error.txt', 'rb') as f: print('File contents: {!r}'.format(f.read()))
First, to ensure that the correct encoding is explicitly set for all I/O operations, strict mode is the safest option, but it can cause the program to crash when an exception is raised.
The second option, replace, ensures that no errors occur at the expense of losing some data that cannot be converted to the required encoding.Unicode characters for PI (pi) are still not ASCII-encoded, but when this error-handling mode is used, it does not produce an exception, but instead replaces the character with?In the output.
Third, data that cannot be encoded is discarded.
The fourth option replaces the character with a candidate representation defined in the standard that is different from the encoding.xmlcharrefreplace uses an XML character reference as an alternative.
The fifth option, like the fourth option, replaces the character with a candidate representation defined in the standard that is different from the encoding.It produces an output format similar to the value returned when printing repr() of a Unicode object.Unicode characters are replaced with \u and the hexadecimal value of the code point.

1.4.2 Encoding Error
Errors may also be encountered when encoding data, especially if incorrect encoding is used.
import codecs import binascii def to_hex(t, nbytes): """Format text t as a sequence of nbyte long values separated by spaces. """ chars_per_item = nbytes * 2 hex_version = binascii.hexlify(t) return b' '.join( hex_version[start:start + chars_per_item] for start in range(0, len(hex_version), chars_per_item) ) error_handlings = ['strict','ignore','replace'] text = 'français' for error_handling in error_handlings: print('Original :', repr(text)) # Save the data with one encoding with codecs.open('decode_error.txt', 'w', encoding='utf-16') as f: f.write(text) # Dump the bytes from the file with open('decode_error.txt', 'rb') as f: print('File contents:', to_hex(f.read(), 1)) # Try to read the data with the wrong encoding with codecs.open('decode_error.txt', 'r', encoding='utf-8', errors=error_handling) as f: try: data = f.read() except UnicodeDecodeError as err: print('ERROR:', err) else: print('Read :', repr(data))
As with encoding, strict error handling mode produces an exception if the byte stream cannot be properly throttled.Here, the UnicodeDecodeError is generated because of an attempt to convert the UTF-16BOM portion to a single character using a UTF-8 decoder.
Switching to ignore causes the decoder to skip illegal bytes.However, the result is still not what was originally expected, because it includes embedded null bytes.
In replace mode, illegal bytes are replaced with \uFFFD, the official Unicode replacement character that looks like a diamond with a black background and contains a white question mark.

1.5 Encoding Conversion
Although most applications process str data internally, decoding or encoding the data as part of an I/O operation, it may be useful in some cases to change the encoding of the file instead of continuing to adhere to this intermediate data format.EncodedFile() takes a file handle that is opened with some encoding, wraps it in a class, and converts the data to another encoding when I/O operations occur.(
import binascii import codecs import io def to_hex(t, nbytes): """Format text t as a sequence of nbyte long values separated by spaces. """ chars_per_item = nbytes * 2 hex_version = binascii.hexlify(t) return b' '.join( hex_version[start:start + chars_per_item] for start in range(0, len(hex_version), chars_per_item) ) # Raw version of the original data. data = 'français' # Manually encode it as UTF-8. utf8 = data.encode('utf-8') print('Start as UTF-8 :', to_hex(utf8, 1)) # Set up an output buffer, then wrap it as an EncodedFile. output = io.BytesIO() encoded_file = codecs.EncodedFile(output, data_encoding='utf-8', file_encoding='utf-16') encoded_file.write(utf8) # Fetch the buffer contents as a UTF-16 encoded byte string utf16 = output.getvalue() print('Encoded to UTF-16:', to_hex(utf16, 2)) # Set up another buffer with the UTF-16 data for reading, # and wrap it with another EncodedFile. buffer = io.BytesIO(utf16) encoded_file = codecs.EncodedFile(buffer, data_encoding='utf-8', file_encoding='utf-16') # Read the UTF-8 encoded version of the data. recoded = encoded_file.read() print('Back to UTF-8 :', to_hex(recoded, 1))
This example shows how to read and write different handles returned by EncodedFile().Whether the handle is used for reading or writing, file_encoding always indicates the encoding used to open the file handle (passed in as the first parameter), and the data_encoding value indicates the encoding used to pass data through read() and write() calls.

1.6 Non-Unicode Encoding
Although most of the previous examples used Unicode encoding, codecs can actually be used for many other data transformations.For example, Python contains codecs that handle base-64, bzip2, ROT-13, ZIP, and other data formats.(
import codecs import io buffer = io.StringIO() stream = codecs.getwriter('rot_13')(buffer) text = 'abcdefghijklmnopqrstuvwxyz' stream.write(text) stream.flush() print('Original:', text) print('ROT-13 :', buffer.getvalue())
If a transformation can be expressed as a function with a single input parameter and returns a byte or Unicode string, then such a transformation can be registered as a codec.For'rot_13'codec, the input should be a Unicode string; the output should also be a Unicode string.
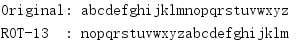
Wrapping a data stream with codecs provides a simpler interface than using zlib directly.(
import codecs import io buffer = io.BytesIO() stream = codecs.getwriter('zlib')(buffer) text = b'abcdefghijklmnopqrstuvwxyz\n' * 50 stream.write(text) stream.flush() print('Original length :', len(text)) compressed_data = buffer.getvalue() print('ZIP compressed :', len(compressed_data)) buffer = io.BytesIO(compressed_data) stream = codecs.getreader('zlib')(buffer) first_line = stream.readline() print('Read first line :', repr(first_line)) uncompressed_data = first_line + stream.read() print('Uncompressed :', len(uncompressed_data)) print('Same :', text == uncompressed_data)
Not all compression or encoding systems support reading a portion of the data through a stream interface using readline() or read(), as this requires finding the end of the compression segment to complete decompression.If a program cannot save the entire decompressed dataset in memory, you can use the incremental access feature of the compressed library instead of codecs.

1.7 incremental encoding
Some of the codes currently provided, especially bz2 and zlib, may significantly change the length of the data stream when it is processed.For large datasets, these codes can be better processed incrementally by processing only a small block of data at a time.The IncrementalEncoder/IncreamentalDecoder API is designed for this purpose.(
import codecs import sys text = b'abcdefghijklmnopqrstuvwxyz\n' repetitions = 50 print('Text length :', len(text)) print('Repetitions :', repetitions) print('Expected len:', len(text) * repetitions) # Encode the text several times to build up a # large amount of data encoder = codecs.getincrementalencoder('bz2')() encoded = [] print() print('Encoding:', end=' ') last = repetitions - 1 for i in range(repetitions): en_c = encoder.encode(text, final=(i == last)) if en_c: print('\nEncoded : {} bytes'.format(len(en_c))) encoded.append(en_c) else: sys.stdout.write('.') all_encoded = b''.join(encoded) print() print('Total encoded length:', len(all_encoded)) print() # Decode the byte string one byte at a time decoder = codecs.getincrementaldecoder('bz2')() decoded = [] print('Decoding:', end=' ') for i, b in enumerate(all_encoded): final = (i + 1) == len(text) c = decoder.decode(bytes([b]), final) if c: print('\nDecoded : {} characters'.format(len(c))) print('Decoding:', end=' ') decoded.append(c) else: sys.stdout.write('.') print() restored = b''.join(decoded) print() print('Total uncompressed length:', len(restored))
Each time data is passed to an encoder or decoder, its internal state is updated.When the state is consistent (as defined by codec), the data is returned and the state is reset.Prior to this, encode() or decode() calls did not return any data.When the last bit of data is passed in, the final parameter should be set to True so that the codec knows it needs to refresh all the remaining buffered data in the output.

1.8 Define custom encoding
Since Python already provides a large number of standard codecs, applications are unlikely to need to define custom codecs or decoders.However, if necessary, many base classes in codecs can help you define custom codes more easily.
The first step is to understand the conversion nature of the encoding description.The examples in this section use an invertcaps encoding that converts uppercase letters to lowercase and lowercase letters to uppercase.The following is a simple definition of an encoding function that performs this conversion on the input string.
import string def invertcaps(text): """Return new string with the case of all letters switched. """ return ''.join( c.upper() if c in string.ascii_lowercase else c.lower() if c in string.ascii_uppercase else c for c in text ) if __name__ == '__main__': print(invertcaps('ABCdef')) print(invertcaps('abcDEF'))
Here, both the encoder and decoder are the same function (similar to ROT-13).

Although easy to understand, this implementation is inefficient, especially for very large text strings.Fortunately, codecs contain auxiliary functions to create character map-based codecs, such as invertcaps.Character mapping encoding consists of two dictionaries.An encoding map converts the character value of an input string to a byte value in the output, whereas a decoding map converts to the opposite.First create a decoding map, then use make_encoding_map() to convert it to an encoding map.The C functions charmap_encode() and charmap_decode() can use these mappings to transform input data efficiently.(
import codecs import string # Map every character to itself decoding_map = codecs.make_identity_dict(range(256)) # Make a list of pairs of ordinal values for the lower # and uppercase letters pairs = list(zip( [ord(c) for c in string.ascii_lowercase], [ord(c) for c in string.ascii_uppercase], )) # Modify the mapping to convert upper to lower and # lower to upper. decoding_map.update({ upper: lower for (lower, upper) in pairs }) decoding_map.update({ lower: upper for (lower, upper) in pairs }) # Create a separate encoding map. encoding_map = codecs.make_encoding_map(decoding_map) if __name__ == '__main__': print(codecs.charmap_encode('abcDEF', 'strict', encoding_map)) print(codecs.charmap_decode(b'abcDEF', 'strict', decoding_map)) print(encoding_map == decoding_map)
Although invertcaps have the same encoding and decoding mappings, this is not always the case.Sometimes each input character is encoded as the same output byte, and make_encoding_map() detects these situations and replaces the encoded value with None, encoding the flag as undefined.

Character map encoders and decoders support all the standard error handling described earlier, so no additional work is required to support this part of the API.(
import codecs import string # Map every character to itself decoding_map = codecs.make_identity_dict(range(256)) # Make a list of pairs of ordinal values for the lower # and uppercase letters pairs = list(zip( [ord(c) for c in string.ascii_lowercase], [ord(c) for c in string.ascii_uppercase], )) # Modify the mapping to convert upper to lower and # lower to upper. decoding_map.update({ upper: lower for (lower, upper) in pairs }) decoding_map.update({ lower: upper for (lower, upper) in pairs }) # Create a separate encoding map. encoding_map = codecs.make_encoding_map(decoding_map) text = 'pi: \u03c0' for error in ['ignore', 'replace', 'strict']: try: encoded = codecs.charmap_encode( text, error, encoding_map) except UnicodeEncodeError as err: encoded = str(err) print('{:7}: {}'.format(error, encoded))
Since the Unicode point of PI is no longer in the coding map, using strict error handling will result in an exception.

After defining the encoding and decoding mappings, you need to establish additional classes and register the encoding.register() adds a search function to the registry so that codecs can find it when the user wants to use it.The search function must have a string parameter that contains the encoding name and, if it knows the encoding, returns a CodecInfo object or None.
import codecs def search1(encoding): print('search1: Searching for:', encoding) return None def search2(encoding): print('search2: Searching for:', encoding) return None codecs.register(search1) codecs.register(search2) utf8 = codecs.lookup('utf-8') print('UTF-8:', utf8) try: unknown = codecs.lookup('no-such-encoding') except LookupError as err: print('ERROR:', err)
Multiple search functions can be registered, and each search function will be called in turn until a search function returns a CodecInfo or all search functions have been called.Internal search functions registered with codecs know how to install standard codecs, such as UTF-8 for encodings, so these codenames are not passed to custom search functions.

The CodecInfo instance returned by the search function tells codecs how to use a variety of different mechanisms that are supported to complete encoding and decoding, including stateless encoding, incremental encoding, and stream encoding.Codcs include base classes to help establish character mapping encoding.The following example integrates everything, registers a search function, and returns a CodecInfo instance configured for invertcaps codec.(
import codecs import string # Map every character to itself decoding_map = codecs.make_identity_dict(range(256)) # Make a list of pairs of ordinal values for the lower # and uppercase letters pairs = list(zip( [ord(c) for c in string.ascii_lowercase], [ord(c) for c in string.ascii_uppercase], )) # Modify the mapping to convert upper to lower and # lower to upper. decoding_map.update({ upper: lower for (lower, upper) in pairs }) decoding_map.update({ lower: upper for (lower, upper) in pairs }) # Create a separate encoding map. encoding_map = codecs.make_encoding_map(decoding_map) class InvertCapsCodec(codecs.Codec): "Stateless encoder/decoder" def encode(self, input, errors='strict'): return codecs.charmap_encode(input, errors, encoding_map) def decode(self, input, errors='strict'): return codecs.charmap_decode(input, errors, decoding_map) class InvertCapsIncrementalEncoder(codecs.IncrementalEncoder): def encode(self, input, final=False): data, nbytes = codecs.charmap_encode(input, self.errors, encoding_map) return data class InvertCapsIncrementalDecoder(codecs.IncrementalDecoder): def decode(self, input, final=False): data, nbytes = codecs.charmap_decode(input, self.errors, decoding_map) return data class InvertCapsStreamReader(InvertCapsCodec, codecs.StreamReader): pass class InvertCapsStreamWriter(InvertCapsCodec, codecs.StreamWriter): pass def find_invertcaps(encoding): """Return the codec for 'invertcaps'. """ if encoding == 'invertcaps': return codecs.CodecInfo( name='invertcaps', encode=InvertCapsCodec().encode, decode=InvertCapsCodec().decode, incrementalencoder=InvertCapsIncrementalEncoder, incrementaldecoder=InvertCapsIncrementalDecoder, streamreader=InvertCapsStreamReader, streamwriter=InvertCapsStreamWriter, ) return None codecs.register(find_invertcaps) if __name__ == '__main__': # Stateless encoder/decoder encoder = codecs.getencoder('invertcaps') text = 'abcDEF' encoded_text, consumed = encoder(text) print('Encoded "{}" to "{}", consuming {} characters'.format( text, encoded_text, consumed)) # Stream writer import io buffer = io.BytesIO() writer = codecs.getwriter('invertcaps')(buffer) print('StreamWriter for io buffer: ') print(' writing "abcDEF"') writer.write('abcDEF') print(' buffer contents: ', buffer.getvalue()) # Incremental decoder decoder_factory = codecs.getincrementaldecoder('invertcaps') decoder = decoder_factory() decoded_text_parts = [] for c in encoded_text: decoded_text_parts.append( decoder.decode(bytes([c]), final=False) ) decoded_text_parts.append(decoder.decode(b'', final=True)) decoded_text = ''.join(decoded_text_parts) print('IncrementalDecoder converted {!r} to {!r}'.format( encoded_text, decoded_text))
The base class of stateless encoder/decoder is Codec, which overrides encode() and decode() with a new implementation (where charmap_encode() and charmap_decode() are called, respectively).These methods must return a tuple containing the converted data and the number of input bytes or characters consumed.This message has already been returned by charmap_encode() and charmap_decode(), so it is convenient.
Incremental Encoder and incrementalDecoder can be used as base classes for incremental encoding interfaces.Incremental encode() and decode() methods are defined to return only the true transformation data.Buffered messages are maintained as internal states.invertcaps encoding does not require buffering data (it uses a one-to-one mapping).Buffered IncrementalEncoder and BufferedIncrementalDecoder are more appropriate base classes for encoding that generates a different number of outputs based on the data being processed, such as compression algorithms, because they manage the unprocessed portions of the input.
StreamReader and StamWriter also require encode() and decode() methods, and since they often return the same value as the corresponding method in Codc, multiple inheritance can be used when implementing.
