Python web crawler practice (2)
1, Demand analysis
Crawling a novel from a novel website
Two, steps
- target data
- website
- page
- Analysis data loading process
- Analyze the url corresponding to the target data
- Download data
- Cleaning, processing data
- Data persistence
Key point: analyze the url corresponding to the target data
The novel website of this paper takes the wonderful novel website as an example, and the novels selected are tomb robbing notes.
Through the Chrome developer mode, find the novel name, directory, directory content location.
The name of the novel: 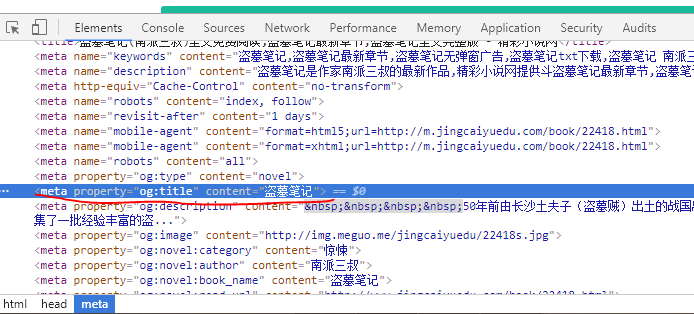
Catalog: 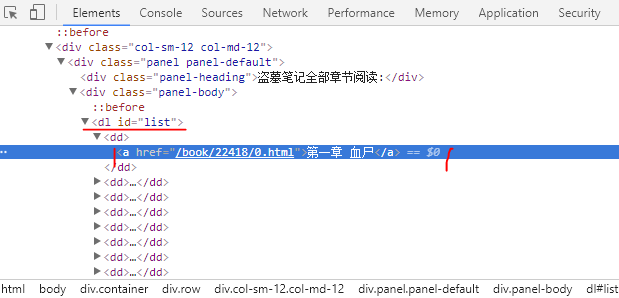
Contents: 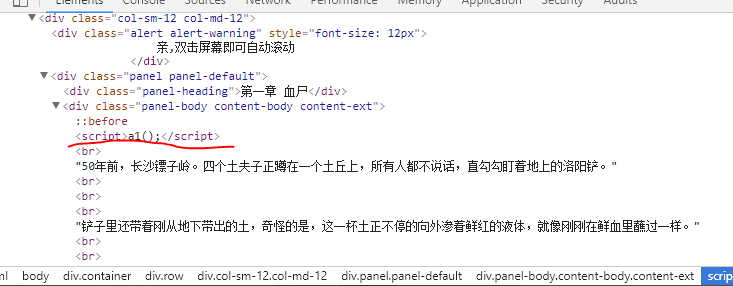
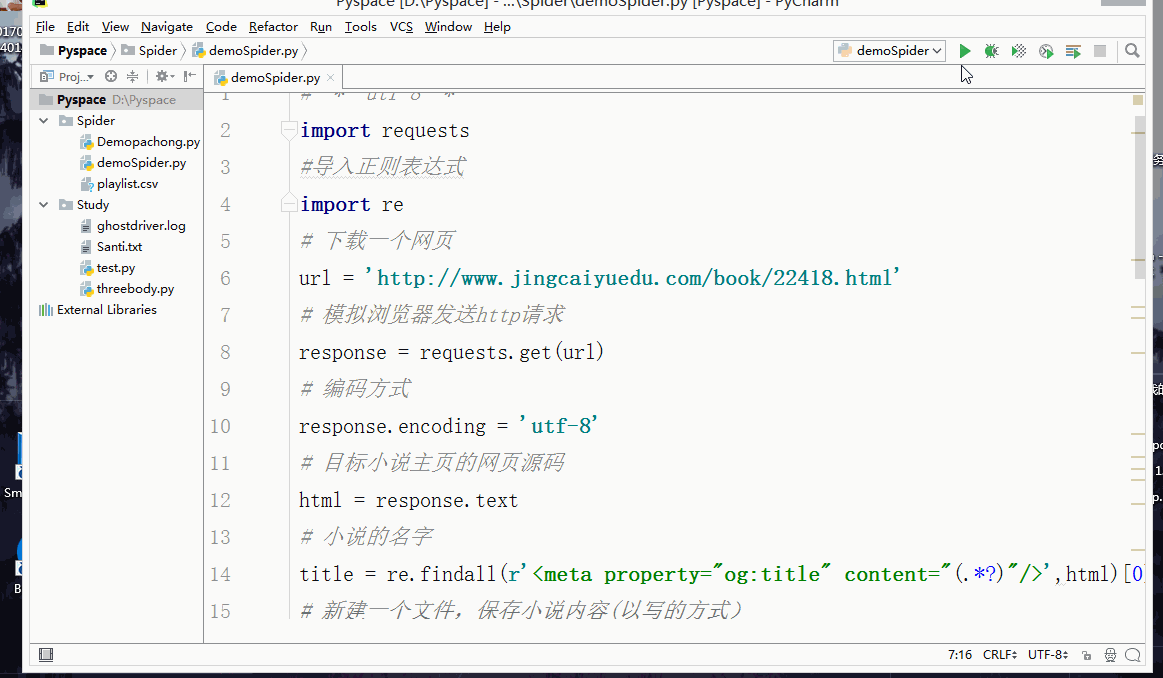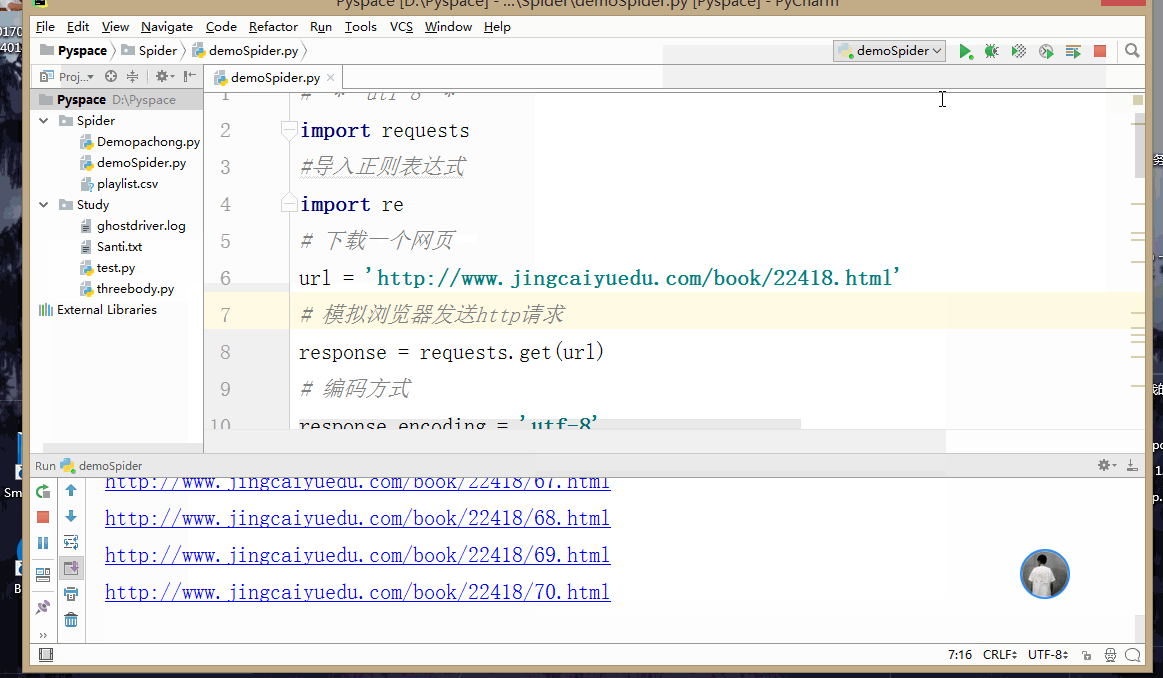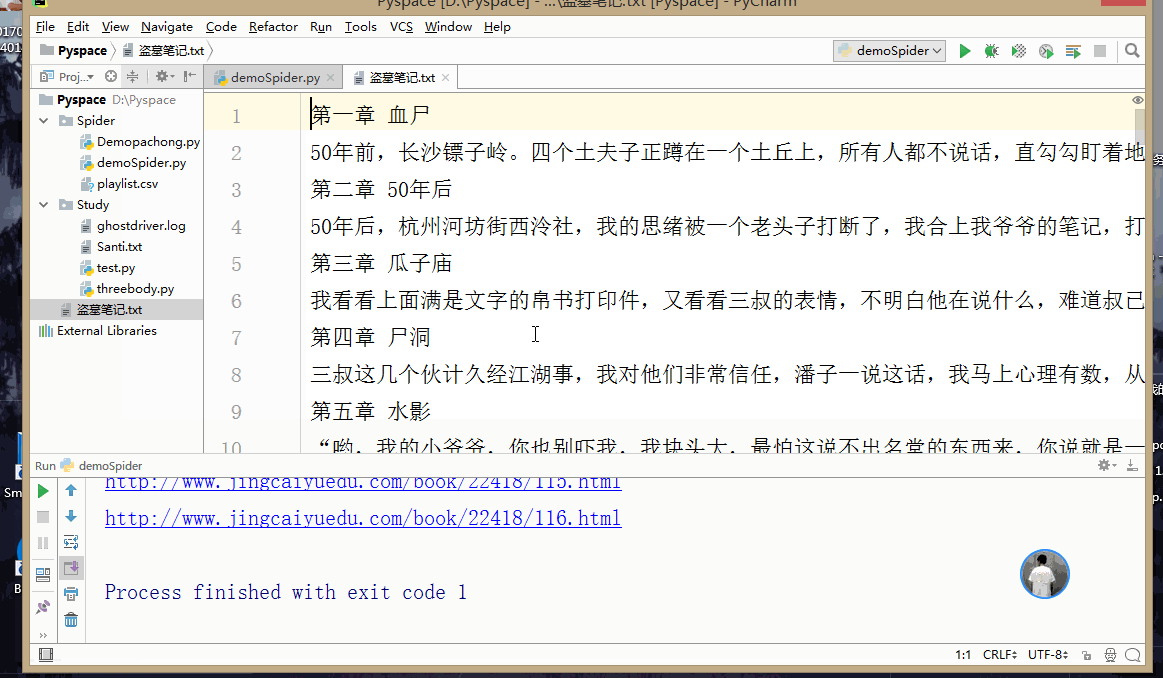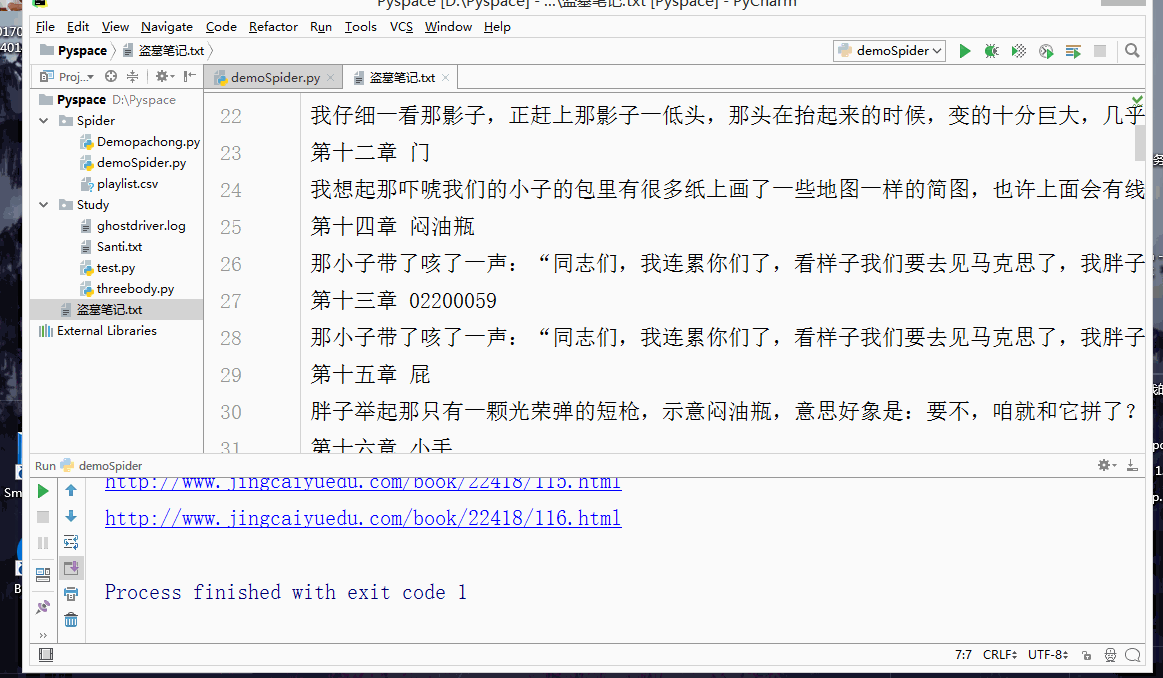
3, Code implementation
python:
import requests
#Import regular expression
import re
# Download a web page
url = 'http://www.jingcaiyuedu.com/book/22418.html'
# Impersonate browser to send http request
response = requests.get(url)
# Encoding mode
response.encoding = 'utf-8'
# Source code of target novel Homepage
html = response.text
# The name of the novel
title = re.findall(r'<meta property="og:title" content="(.*?)"/>',html)[0]
# Create a new file to save the content of the novel
fb = open('%s.txt' % title, 'w', encoding='utf-8')
# Get information about each chapter (chapter, url)
dl = re.findall(r'<dl id="list">.*?</dl>',html,re.S)[0]
chapter_info_list = re.findall(r'href="(.*?)">(.*?)<',dl)
# Cycle through each chapter and download them separately
for chapter_info in chapter_info_list:
chapter_url,chapter_title = chapter_info
chapter_url = "http://www.jingcaiyuedu.com%s" % chapter_url
# Download the contents of the chapter
chapter_response = requests.get(chapter_url)
chapter_response.encoding = 'utf-8'
chapter_html = chapter_response.text
# Extract chapter content
chapter_content = re.findall(r'<script>a1\(\);</script>(.*?)<script>a2\(\);</script>',chapter_html, re.S)[0]
# Clean data, replace space, line break
chapter_content = chapter_content.replace(' ','')
chapter_content = chapter_content.replace(' ','')
chapter_content = chapter_content.replace('<br/>','')
chapter_content = chapter_content.replace('<br>', '')
#Persistent, write title, content and line feed
fb.write(chapter_title)
fb.write(chapter_content)
fb.write('\n')
print(chapter_url)4, Operation results
Click Run to generate the txt file of the novel (as a demonstration, I only crawled a part of the chapters):