(1) Description
Based on the previous one, we use lxml to extract the body content of blog garden essay and save it in Word document.
The following modules are used to operate Word documents:
pip install python-docx
Modified code (mainly added the following paragraph in the while loop of link_crawler())
1 tree = lxml.html.fromstring(html) #analysis HTML For a unified format 2 title = tree.xpath('//a[@id="cb_post_title_url"]') #Get title 3 the_file = tree.xpath('//div[@id="cnblogs_post_body"]/p') #Get body content 4 pre = tree.xpath('//pre') #Get the code part of the essay (inserted with the code insertion function of the blog Park) 5 img = tree.xpath('//div[@id="cnblogs_post_body"]/p/img/@src') #Get pictures 6 #Modify working directory 7 os.chdir('F:\Python\worm\Blog Garden files') 8 #Create a blank new Word File 9 doc = docx.Document() 10 #Add title 11 doc.add_heading(title[0].text_content(), 0) 12 for i in the_file: 13 #Add the contents of each paragraph to Word Documents ( p Content of label) 14 doc.add_paragraph(i.text_content()) 15 # Add code section to document 16 for p in pre: 17 doc.add_paragraph(p.text_content()) 18 #Add picture to Word In document 19 for i in img: 20 ure.urlretrieve(i, '0.jpg') 21 doc.add_picture('0.jpg') 22 #Intercept the first 8 digits of the title as Word file name 23 filename = title[0].text_content()[:8] + '.docx' 24 #Preservation Word Document think 25 #If the filename already exists, set the filename to title[0].text_content()[:8]+ str(x).docx,Otherwise, set the filename to filename 26 if str(filename) in os.listdir('F:\Python\worm\Blog Garden files'): 27 doc.save(title[0].text_content()[:8] + str(x) + '.docx') 28 x += 1 29 else: 30 doc.save(filename)
(2) Complete code (the code of delayed.py will not be pasted out, as in the previous article)
It's better to set the speed limit a little higher. The following sentence, in seconds.
waitFor = WaitFor(2)
1 import urllib.request as ure 2 import re 3 import urllib.parse 4 from delayed import WaitFor 5 import lxml.html 6 import os 7 import docx 8 #Download Web page and return to HTML(Part of the dynamic load cannot be downloaded) 9 def download(url,user_agent='FireDrich',num=2): 10 print('download:'+url) 11 #Set up user agent 12 headers = {'user_agent':user_agent} 13 request = ure.Request(url,headers=headers) 14 try: 15 #Download webpage 16 html = ure.urlopen(request).read() 17 except ure.URLError as e: 18 print('Download failed'+e.reason) 19 html=None 20 if num>0: 21 #Encounter 5 XX In case of an error, recursively call itself to retry the download, and repeat at most twice 22 if hasattr(e,'code') and 500<=e.code<600: 23 return download(url,num-1) 24 return html 25 #seed_url Introduction of one url,for example https://www.cnblogs.com/ 26 #link_regex Pass in a regular expression 27 #Function functions: extracting and link_regex All matching page links and Downloads 28 def link_crawler(seed_url, link_regex): 29 html = download(seed_url) 30 crawl_queue = [] 31 #iteration get_links()Returns a list that matches the regular expression link_regex Links to add to the list 32 for link in get_links(html): 33 if re.match(link_regex, link): 34 #Splicing https://www.cnblogs.com/ and / cat / 35 link = urllib.parse.urljoin(seed_url, link) 36 #Do not add in list 37 if link not in crawl_queue: 38 crawl_queue.append(link) 39 x = 0 40 #call WaitFor Of wait()Function, download speed limit, wait if the interval is less than 2 seconds,Continue downloading until the interval is equal to 2 seconds (continue downloading directly if it is greater than 5 seconds) 41 waitFor = WaitFor(2) 42 #download crawl_queue All pages in 43 while crawl_queue: 44 #Delete data at the end of the list 45 url = crawl_queue.pop() 46 waitFor.wait(url) 47 html = download(url) 48 tree = lxml.html.fromstring(html) #analysis HTML For a unified format 49 title = tree.xpath('//a[@id="cb_post_title_url"]') #Get title 50 the_file = tree.xpath('//div[@id="cnblogs_post_body"]/p') #Get body content 51 pre = tree.xpath('//pre') #Get the code part of the essay (inserted with the code insertion function of the blog Park) 52 img = tree.xpath('//div[@id="cnblogs_post_body"]/p/img/@src') #Get pictures 53 #Modify working directory 54 os.chdir('F:\Python\worm\Blog Garden files') 55 #Create a blank new Word File 56 doc = docx.Document() 57 #Add title 58 doc.add_heading(title[0].text_content(), 0) 59 for i in the_file: 60 #Add the contents of each paragraph to Word Documents ( p Content of label) 61 doc.add_paragraph(i.text_content()) 62 # Add code section to document 63 for p in pre: 64 doc.add_paragraph(p.text_content()) 65 #Add picture to Word In document 66 for i in img: 67 ure.urlretrieve(i, '0.jpg') 68 doc.add_picture('0.jpg') 69 #Intercept the first 8 digits of the title as Word file name 70 filename = title[0].text_content()[:8] + '.docx' 71 #Preservation Word File 72 #If the filename already exists, set the filename to title[0].text_content()[:8]+ str(x).docx,Otherwise, set the filename to filename 73 if str(filename) in os.listdir('F:\Python\worm\Blog Garden files'): 74 doc.save(title[0].text_content()[:8] + str(x) + '.docx') 75 x += 1 76 else: 77 doc.save(filename) 78 #afferent html Object to return all links as a list 79 def get_links(html): 80 #Using regular expression extraction html All page links in 81 webpage_regex = re.compile('<a[^>]+href=["\'](.*?)["\']',re.IGNORECASE) 82 html = html.decode('utf-8') 83 # Return all web links as a list 84 return webpage_regex.findall(html) 85 86 link_crawler('https://www.cnblogs.com/cate/python/','.*/www.cnblogs.com/.*?\.html$')
(3) Results
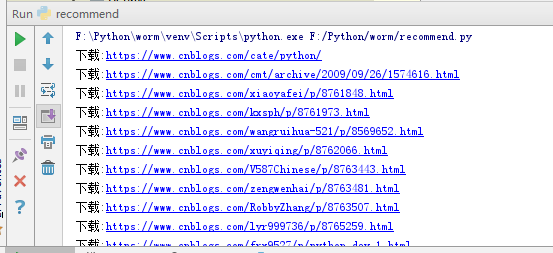

(4) Existing problems
(1) the code part is added after the body content. (if you have used the function of inserting code in blog Garden, the typesetting will be inconsistent.)
(2) The image is inserted directly after the code section. (if there is a picture inserted in the essay, the typesetting will be inconsistent)