1, Introduction to basic structure of crawling program
The first is the library that the program needs to call:
import requests import bs4 import os
Then write a function to parse the HTML of the web page:
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36 Edg/94.0.992.31'}
def getUrl(url):
r = requests.get(url, headers=headers)
r.encoding = r.apparent_encoding
r.raise_for_status()
return r.textThen comes the main part of the program:
Open Douban and enter the Top 250 page of Douban movie. When you slide down to the end, you can find that 25 movies are arranged on each page at most, and the rest can be seen only by turning the page. When you click the page number to turn the page, you can notice that the URL of the web page changes regularly with the conversion of each page, for example:
first page: https://movie.douban.com/top250
Page 5: https://movie.douban.com/top250?start=100&filter=
It is found that each page URL is composed of "? Start = n & filter" after the first page link. Therefore, there are two methods to obtain all page URLs:
1. Directly construct URL links according to laws.
2. Parse the HTML structure of the web page and crawl the URL suffix.
This article takes the second method to get the URL link to start each page.
def homepage():
URL = 'https://movie.douban.com/top250'
html = getUrl(URL)
bf = bs4.BeautifulSoup(html, 'html.parser')
temp = bf.find('div', attrs = {'class': 'paginator'})
tempList = temp.find_all('a')
# print(tempList)
linkList = ['https://movie.douban.com/top250']
for list in tempList:
link=list.get('href')
# print(link)
url = 'https://movie.douban.com/top250'+link
linkList.append(url)
return linkList#Get links to pages 1-10After obtaining the URL of each page, we solved the page turning function of the program. Then we entered each page, crawled the URL of each movie plot introduction respectively, and saved them. The structure of this part of the program is roughly similar to that of the previous part.
def partpage(parturl):
html = getUrl(parturl)
bf = bs4.BeautifulSoup(html, 'html.parser')
temp = bf.find_all('div', attrs = {'class': 'hd'})
linkList = []
for list in temp:
tempList=list.find('a', attrs = {'class': ''})
link = tempList.get('href')
# print(link)
linkList.append(link)
return linkListSo far, the program has realized the function of entering the plot profile of each film, and then we can start crawling the plot profile information of each film.
def movie(movieurl):
bf = bs4.BeautifulSoup(movieurl, 'html.parser')
#Get title
temp1=bf.find_all('div', id='content')
title=''
for TITLE in temp1:
Title1=TITLE.find('h1').find('span',property='v:itemreviewed')
title+=Title1.text
Title2=TITLE.find('h1').find('span',class_='year')
title+=Title2.text
# print(title)
temp2=bf.find_all('div', class_='related-info')
synopsis_title=''
synopsis=''
for Synopsis in temp2:
#XX plot introduction
tp=Synopsis.find('i',class_='')
synopsis_title+=tp.text
#Plot introduction
tn = Synopsis.find('div', class_='indent')
synopsis+=tn.text.replace(' ','')
return title,synopsis_title+synopsisThrough the above steps, we successfully saved the title and synopsis of each film. Next, we need to store them to form txt text.
#Store it in the filename.txt text named path under the address path where the program is located
def saveFile(content,path,filename):
if not os.path.exists(path):
os.makedirs(path)
with open(path+filename, 'w', encoding='utf-8') as f:
f.write(content)After the storage method is written, you can crawl and store the movie introduction:
def download():
HomePageUrl = homepage()
for HomePage in HomePageUrl:
AttachedPageUrl = partpage(HomePage)
for AttachedPage in AttachedPageUrl:
html = getUrl(AttachedPage)
title,content = movie(html)
content='\n'+content
path = 'TOP250/'
fileName = title + '.txt'
# Save file
saveFile(title+content, path,fileName)Finally, run:
if __name__ == '__main__':
download()The program is over.
2, Crawling results
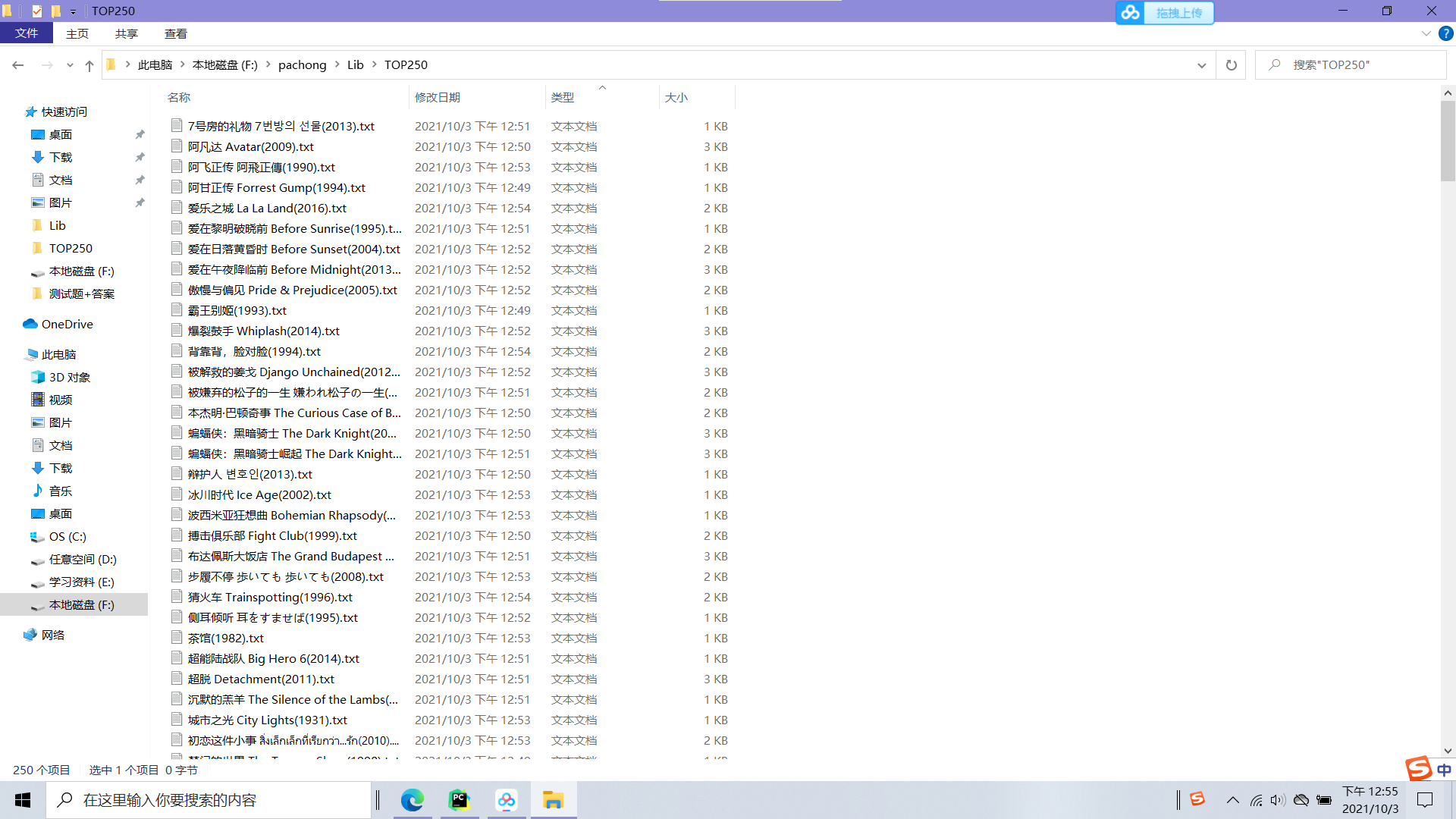
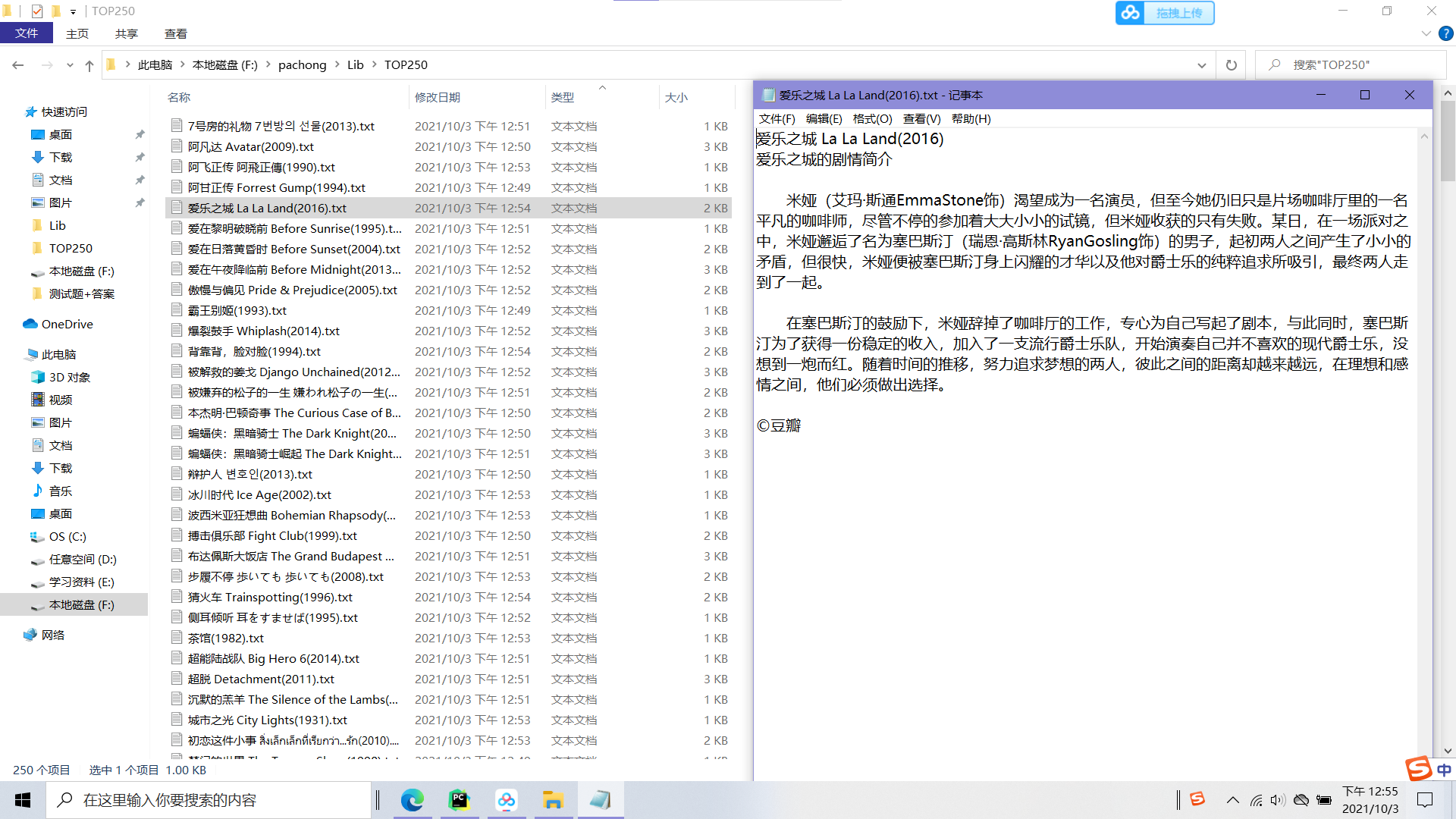
3, Summary
1. Some plot profiles need to click "expand all" to see the complete content. Therefore, in the tag of plot profile corresponding to HTML text, some movies contain incomplete plot profiles, which are not processed here. Therefore, in the crawled out text, some movie profiles will have incomplete and complete contents.
2. The page number link suffix and the label of the complete plot introduction that need to be found in the program are in the later part of the HTML of each web page. You need to be careful when searching.