Inverse Document Frequency (IDF for short)
If a certain word is less, but it appears many times in this article, it may reflect the characteristics of this article, which is the key words we need
Word frequency (TF) = the number of times a word appears in an article / the number of times a word appears most in the article
Inverse document frequency (IDF) = log (total number of documents in corpus / number of documents containing the word + 1)
TF-IDF: keyword extraction
TF-IDF = word frequency (TF) X inverse document frequency (IDF)

Data source: http://www.sogou.com/labs/resource/ca.php
import pandas as pd
import jieba
df_news=pd.read_table('data/val.txt',names=['category','theme','URL','content'],encoding='utf-8')
df_news=df_news.dropna()
print(df_news.head()) 
Word segmentation: using a stammer
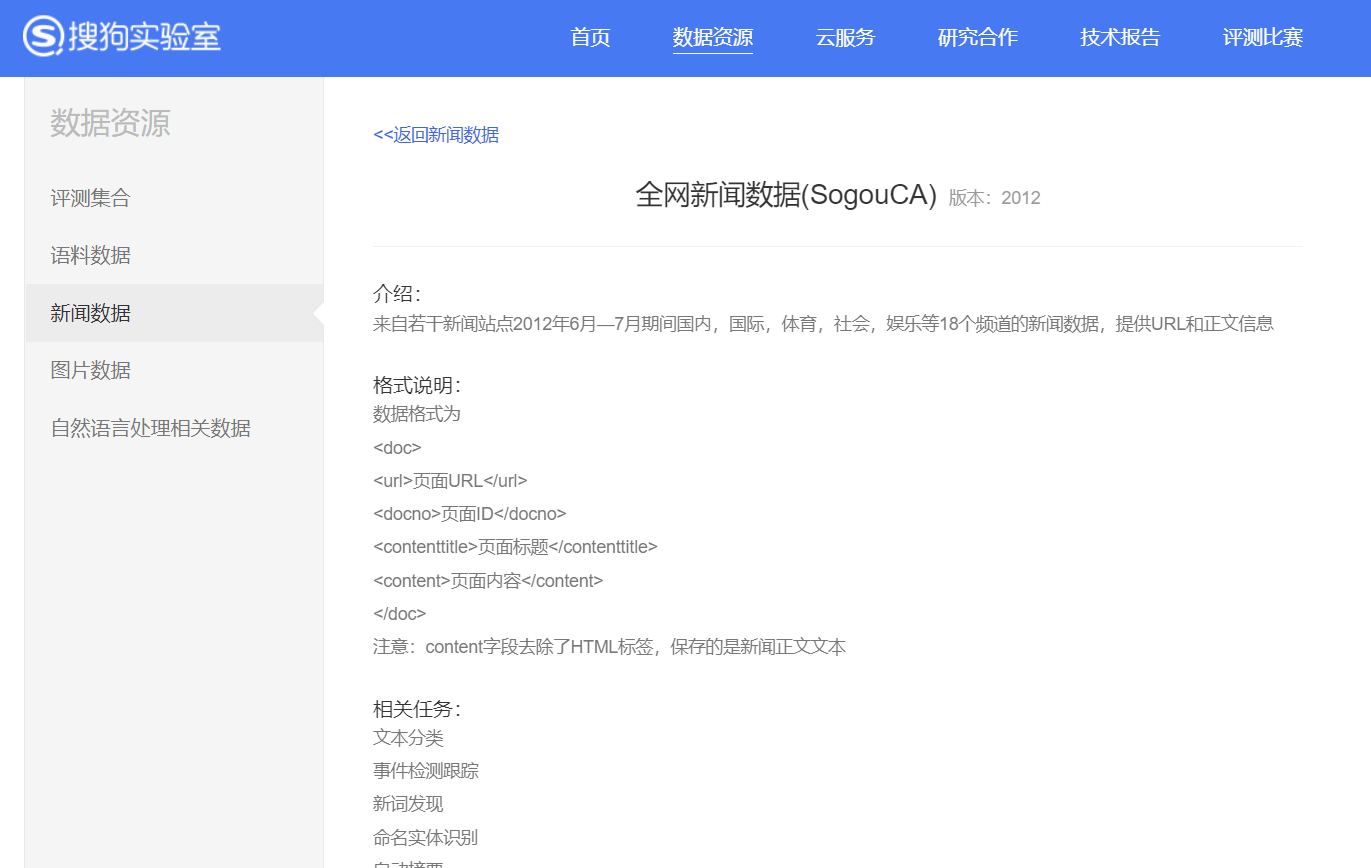
content=df_news.content.values.tolist() print(content[1000])

content_S=[]
for line in content:
current_segment=jieba.lcut(line)
if len(current_segment)>1 and current_segment !='r\n':
content_S.append(current_segment)
print(content_S[1000])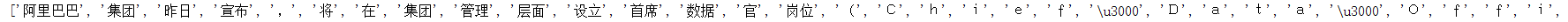
df_content=pd.DataFrame({'content_S':content_S})
print(df_content.head())
stopwords=pd.read_csv("stopwords.txt",index_col=False,sep='\t',quoting=3,names=['stopword'],encoding='utf-8')
print(stopwords.head())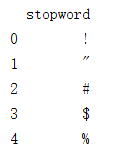
def drop_stopwords(contents,stopwords):
contents_clean=[]
all_words=[]
for line in contents:
line_clean=[]
for word in line:
if word in stopwords:
continue
line_clean.append(word)
all_words.append(str(word))
contents_clean.append(line_clean)
return contents_clean,all_words
contents=df_content.content_S.values.tolist()
stopwords=stopwords.stopword.values.tolist()
contents_clean,all_words=drop_stopwords(contents,stopwords)
df_content=pd.DataFrame({'contents_clean':contents_clean})
print(df_content.head())
df_all_words=pd.DataFrame({'all_words':all_words})
print(df_all_words.head()) 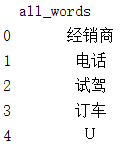
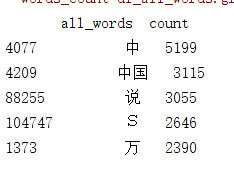
words_count=df_all_words.groupby(by=['all_words'])['all_words'].agg({'count':numpy.size})
words_count=words_count.reset_index().sort_values(by=["count"],ascending=False)
print(words_count.head())
Draw a cloud of words
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['figure.figsize']=(10.0,5.0)
wordcloud=WordCloud(font_path="./data/simhei.ttf",background_color='white',max_font_size=80)
word_frequence={x[0]:x[1] for x in words_count.head(100).values}
wordcloud=wordcloud.fit_words(word_frequence)
plt.imshow(wordcloud)
plt.show()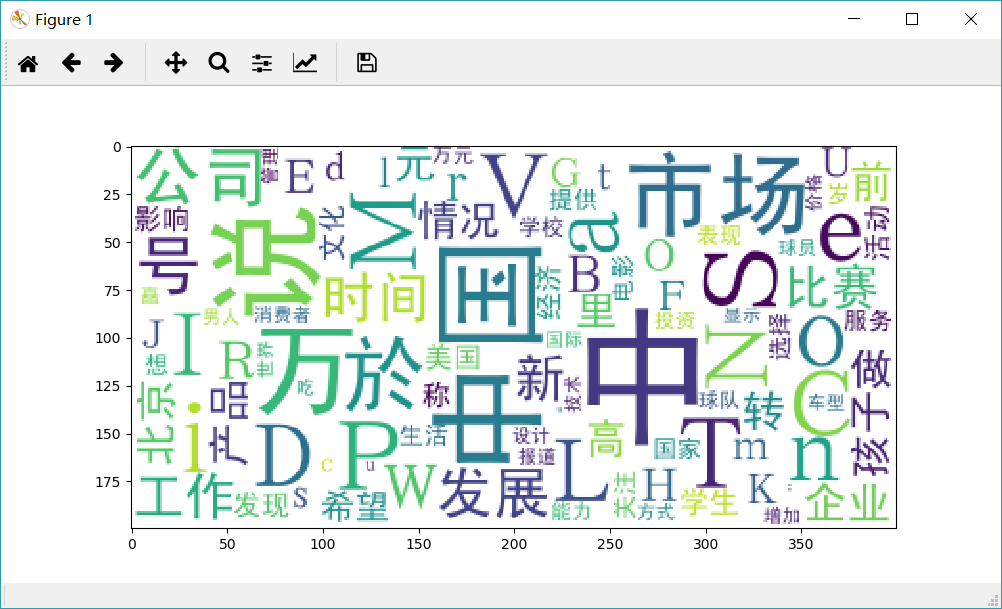
#TF-IDF extraction keywords
import jieba.analyse
index=1000
print(df_news['content'[index]])
content_S_str="".join(content_S[index])
print(" ".join(jieba.analyse.extract_tags(content_S_str,topK=5,withWeight=False)))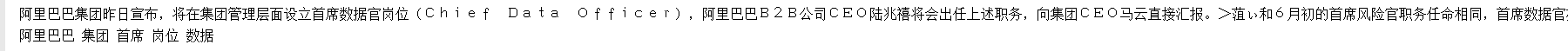
#LDA: theme model from gensim import corpora,models,similarities import gensim #Mapping is equivalent to reading dictionary=corpora.Dictionary(contents_clean) corpus=[dictionary.doc2bow(sentence) for sentence in contents_clean] lda=gensim.models.ldamodel.LdaModel(corpus=corpus,id2word=dictionary,num_topics=200) #Classification result No.1 print(lda.print_topic(1,topn=5))
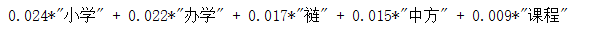
df_train=pd.DataFrame({'contents_clean':contents_clean,'label':df_news['category']})
print(df_train.head())
#['car', 'Finance', 'technology', 'health', 'Sports',' education ',' culture ',' military ',' entertainment 'fashion']
print(df_train.label.unique())

test
#Test test from sklearn.feature_extraction.text import CountVectorizer texts=["dog cat fish","dog cat cat","fish bird","bird"] cv=CountVectorizer() cv_fit=cv.fit_transform(texts) print(cv.get_feature_names()) print(cv_fit.toarray()) print(cv_fit.toarray().sum(axis=0))

Code:
import pandas as pd
import jieba
import numpy
df_news=pd.read_table('data/val.txt',names=['category','theme','URL','content'],encoding='utf-8')
df_news=df_news.dropna()
# print(df_news.head())
# print(df_news.shape)
#Word segmentation: using a stammer
content=df_news.content.values.tolist()
#print(content[1000])
content_S=[]
for line in content:
current_segment=jieba.lcut(line)
if len(current_segment)>1 and current_segment !='r\n':
content_S.append(current_segment)
#print(content_S[1000])
df_content=pd.DataFrame({'content_S':content_S})
#print(df_content.head())
stopwords=pd.read_csv("stopwords.txt",index_col=False,sep='\t',quoting=3,names=['stopword'],encoding='utf-8')
# print(stopwords.head())
def drop_stopwords(contents,stopwords):
contents_clean=[]
all_words=[]
for line in contents:
line_clean=[]
for word in line:
if word in stopwords:
continue
line_clean.append(word)
all_words.append(str(word))
contents_clean.append(line_clean)
return contents_clean,all_words
contents=df_content.content_S.values.tolist()
stopwords=stopwords.stopword.values.tolist()
contents_clean,all_words=drop_stopwords(contents,stopwords)
df_content=pd.DataFrame({'contents_clean':contents_clean})
# print(df_content.head())
df_all_words=pd.DataFrame({'all_words':all_words})
# print(df_all_words.head())
words_count=df_all_words.groupby(by=['all_words'])['all_words'].agg({'count':numpy.size})
words_count=words_count.reset_index().sort_values(by=["count"],ascending=False)
# print(words_count.head())
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['figure.figsize']=(10.0,5.0)
wordcloud=WordCloud(font_path="./data/simhei.ttf",background_color='white',max_font_size=80)
word_frequence={x[0]:x[1] for x in words_count.head(100).values}
wordcloud=wordcloud.fit_words(word_frequence)
plt.imshow(wordcloud)
plt.show()
#TF-IDF extraction keywords
import jieba.analyse
index=1000
print(df_news['content'][index])
content_S_str="".join(content_S[index])
# print(" ".join(jieba.analyse.extract_tags(content_S_str,topK=5,withWeight=False)))
#LDA: theme model
from gensim import corpora,models,similarities
import gensim
#Mapping is equivalent to reading
dictionary=corpora.Dictionary(contents_clean)
corpus=[dictionary.doc2bow(sentence) for sentence in contents_clean]
lda=gensim.models.ldamodel.LdaModel(corpus=corpus,id2word=dictionary,num_topics=200)
#Classification result No.1
print(lda.print_topic(1,topn=5))
for topic in lda.print_topics(num_topics=20,num_words=5):
print(topic[1])
df_train=pd.DataFrame({'contents_clean':contents_clean,'label':df_news['category']})
print(df_train.head())
#['car', 'Finance', 'technology', 'health', 'Sports',' education ',' culture ',' military ',' entertainment 'fashion']
print(df_train.label.unique())
label_mapping={"automobile":1,"Finance":2,"science and technology":3,"Healthy":4,"Sports":5,"education":6,
"Culture":7,"Military":8,"entertainment":9,"fashion":10}
df_train['label']=df_train['label'].map(label_mapping)
print(df_train.head())
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(df_train['contents_clean'].values,df_train['label'].values)
print(x_train[0][1])
words=[]
for line_index in range(len(x_train)):
try:
words.append(' '.join(x_train[line_index]))
except:
print(line_index)
print(words[0])
from sklearn.feature_extraction.text import CountVectorizer
vec=CountVectorizer(analyzer='word',max_features=4000,lowercase=False)
vec.fit(words)
from sklearn.naive_bayes import MultinomialNB
classifier=MultinomialNB()
classifier.fit(vec.transform(words),y_train)
test_words=[]
for line_index in range(len(x_test)):
try:
test_words.append(' '.join(x_test[line_index]))
except:
print(line_index)
print(test_words[0])
print(classifier.score(vec.transform(test_words),y_test))
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer=TfidfVectorizer(analyzer='word',max_features=4000,lowercase=False)
vectorizer.fit(words)
from sklearn.naive_bayes import MultinomialNB
classifier=MultinomialNB()
classifier.fit(vectorizer.transform(words),y_train)
print(classifier.score(vectorizer.transform(test_words),y_test))

