Case story: Testlink is a common use case management tool used by many companies,
Testlink supports the development of test plans, the simultaneous management and maintenance / execution of test cases by multiple people online, and the automatic generation of test reports.
I personally do not recommend Excel offline management test cases,
However, the official version of Testlink does not support Excel import, only Xml import.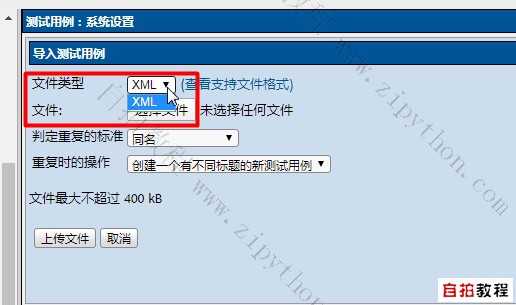
Without this Excel import function, it's a pity,
But Python is a panacea. It's not hard to transfer Excel to Xml.
Preparation stage
- To operate Excel module, openpyxl has always been preferred. Directly pip install openpyxl is enough
- To operate Xml module, I suggest that ElementTree is preferred, but its source code needs to be modified for the following reasons: 3, 4 steps.
- according to Official documents of Testlink , if a single use case, its xml is as follows, look dizzy, don't advise, just do it!
<?xml version='1.0' encoding='utf-8'?>
<testcases>
<testcase internalid="1" name="VTS Testing—— arm64-v8a VtsFastbootVerification">
<externalid />
<version>
<![CDATA[1]]>
</version>
<summary>
<![CDATA[VTS Testing—— arm64-v8a VtsFastbootVerification]]>
</summary>
<preconditions>
<![CDATA[Android Device passed USB Connect to Ubuntu system]]>
</preconditions>
<execution_type>
<![CDATA[2]]>
</execution_type>
<importance>
<![CDATA[1]]>
</importance>
<status>
<![CDATA[7]]>
</status>
<steps>
<step>
<step_number>
<![CDATA[1]]>
</step_number>
<actions>
<![CDATA[Step1: Function vts-tradefed Get into vts Console]]>
</actions>
<expectedresults>
<![CDATA[Result1: Successful entry vts Console]]>
</expectedresults>
<execution_type>
<![CDATA[2]]>
</execution_type>
</step>
<step>
<step_number>
<![CDATA[2]]>
</step_number>
<actions>
<![CDATA[Step2: implement run vts -m VtsFastbootVerification]]>
</actions>
<expectedresults>
<![CDATA[Result2: Operation results Pass,vts Pass the test]]>
</expectedresults>
<execution_type>
<![CDATA[2]]>
</execution_type>
</step>
</steps>
<keywords>
<keyword name="Android 9">
<notes>
<![CDATA[]]>
</notes>
</keyword>
</keywords>
</testcase>
</testcases>
4. As you can see from the above Xml, there is a very strange! [CDATA [*]],
The content contained by this tag will be represented as plain text and should not be parsed by an XML parser,
But this tag, the ElementTree of Python, cannot be generated normally,
So after many studies, I modified the source code of ElementTree and added 901902 lines,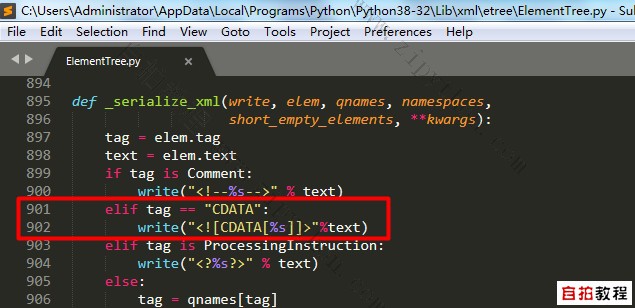
You can download the etree folder from this material case,
The etree of import in this case can be understood as a third-party module, an unofficial ElementTree module.
5. We need to set the test case Excel template as follows:
6. We need to consider to realize batch conversion of multiple Excel. The input is Excel input,
After running excel 2xml.py, the output is XML_Output, and its file directory is as follows: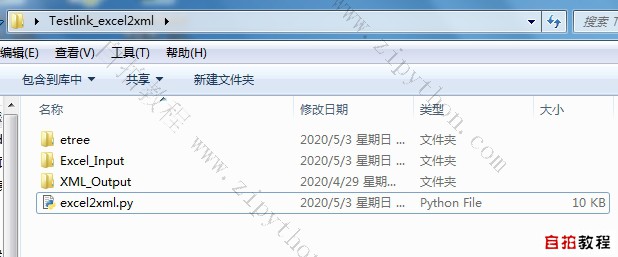
Python object oriented class form
Because the code involved in this case is somewhat difficult and relatively long,
Directly in the form of object-oriented classes to model and program design.
Modeling: first imagine a blank world and what kinds of things (nouns) the world needs.
We need two classes. One is the ExcelReader class, which is used to read Excel to get case data,
One is the XMLWriter class, which is used to write the Excel data obtained above into the Xml file.
# coding=utf-8
import os
import re
import shutil
from openpyxl import load_workbook
from etree.ElementTree import ElementTree, Element, SubElement
SUMMARY_COL = 1 # Use case title
PRECONDITION_COL = 2 # Preset conditions
EXECUTETYPE_COL = 3 # Execution mode of use case, manual and automatic
IMPORTANCE_COL = 4 # Priority of use cases
STEPS_COL = 5 # Execution steps of use cases
EXCEPTED_RESULT_COL = 6 # Expected results of use cases
KEYWORD_COL = 7 # Project to which the use case belongs
class ExcelReader(object):
"""Read Excel file and get all cases contents"""
def __init__(self, excel_file):
self.excel_file = excel_file
def __parse_steps(self, steps_str):
"""Analytical cutting required Step1:XXXXStep2:XXXXStep3:XXXXX And get the execution steps Step Specific text of"""
steps_str = steps_str + " "
new_steps_list = []
number_list = []
steps_count = 1
for i in range(1, 20):
if ("Step%s" % i in steps_str):
steps_count = i
else:
break
for x in range(1, steps_count + 1):
number_list.append(int(steps_str.find("Step%s" % x)))
number_list.append(-1)
for j in range(0, len(number_list) - 1):
new_steps_list.append(steps_str[number_list[j]:number_list[j + 1]])
return new_steps_list
def __parse_results(self, result_str):
"""Analytical cutting required Result1:XXXXResult2:XXXXResult3:XXXXX And get the expected results Result Specific text of"""
result_str = result_str + " "
new_result_list = []
number_list = []
steps_count = 1
for i in range(1, 20):
if ("Result%s" % i in result_str):
steps_count = i
else:
break
for x in range(1, steps_count + 1):
number_list.append(int(result_str.find("Result%s" % x)))
number_list.append(-1)
for j in range(0, len(number_list) - 1):
new_result_list.append(result_str[number_list[j]:number_list[j + 1]])
return new_result_list
def get_all_cases(self):
"""Read to Excel All test cases are written and stored in a list """
all_case_list = []
excel = load_workbook(self.excel_file)
_, excel_name = os.path.split(self.excel_file)
sheet = excel.active
max_rows = sheet.max_row
for row_num in range(2, max_rows):
print("Processing%s No%s That's ok" % (excel_name, row_num))
casedict = {}
summary = sheet.cell(row=row_num, column=SUMMARY_COL).value
# print(summary)
if summary:
precondition = sheet.cell(row=row_num, column=PRECONDITION_COL).value
execution_type = sheet.cell(row=row_num, column=EXECUTETYPE_COL).value
importance = sheet.cell(row=row_num, column=IMPORTANCE_COL).value
steps = sheet.cell(row=row_num, column=STEPS_COL).value
excepted_results = sheet.cell(row=row_num, column=EXCEPTED_RESULT_COL).value
keyword = sheet.cell(row=row_num, column=KEYWORD_COL).value
if keyword == None:
keyword = ""
casedict["internalid"] = "1"
casedict["summary"] = summary
casedict["status"] = "7"
casedict["preconditions"] = precondition
casedict["keyword"] = keyword
if (importance == "" or importance == None):
print(u"Format error, The first%s That's ok, \"priority\"column, Cannot be empty!" % row_num)
return None
else:
importance = importance.strip()
importance = importance.capitalize() # title case
if (importance == "Medium" or importance == "M"):
casedict["importance"] = "2"
elif (importance == "High" or importance == "H"):
casedict["importance"] = "3"
elif (importance == "Low" or importance == "L"):
casedict["importance"] = "1"
else:
print(u"priority error , The first%s That's ok, \"priority\"column, Must be High, Medium, Low perhaps H, M, L!" % row_num)
return None
if (execution_type != 'Manual' and execution_type != "automatic" and execution_type != "manual"):
print(u"Format error, The first%s That's ok, \"Execution mode\"column, Must be\"Manual\"or\"automatic\"!" % row_num)
return None
else:
if (execution_type == u"Manual"):
casedict["execution_type"] = "1"
else:
casedict["execution_type"] = "2"
if ("Step1" not in steps):
print(u"Format error, The first%s That's ok, \"testing procedure\"column,Must use Step1:, Step2:, Step3:...Format, etc!" % row_num)
return None
else:
steps_list = self.__parse_steps(steps)
for i in range(1, len(steps_list) + 1):
casedict["step" + str(i)] = steps_list[i - 1]
if not (re.match(r".*Result.*", excepted_results)):
print(u"Format error, The first%s That's ok, \"Expected results\"column,Must use Result1:, Result2:, Result3:...Format, etc!" % row_num)
return None
else:
result_list = self.__parse_results(excepted_results)
for i in range(1, len(result_list) + 1):
casedict["result" + str(i)] = result_list[i - 1]
all_case_list.append(casedict)
else:
break
# print(allcase_list)
return all_case_list
class XmlWriter():
'''Write to XML'''
def __init__(self, all_cases_list, save_path):
self.all_cases_list = all_cases_list
self.save_path = save_path
def write_xml(self):
xml_file = ElementTree()
testcases_node = Element("testcases")
xml_file._setroot(testcases_node)
for eachcase in self.all_cases_list:
testcase_node = Element("testcase", {"internalid": eachcase["internalid"], "name": eachcase["summary"]})
try:
SubElement(testcase_node, "externalid").append(CDATA(eachcase["externalid"]))
except:
pass
try:
SubElement(testcase_node, "version").append(CDATA(eachcase["version"]))
except:
pass
SubElement(testcase_node, "summary").append(CDATA(eachcase["summary"]))
SubElement(testcase_node, "preconditions").append(CDATA(eachcase["preconditions"]))
SubElement(testcase_node, "execution_type").append(CDATA(eachcase["execution_type"]))
SubElement(testcase_node, "importance").append(CDATA(eachcase["importance"]))
SubElement(testcase_node, "status").append(CDATA(eachcase["status"]))
stepsnode = SubElement(testcase_node, "steps")
for i in range(1, 20):
try:
step = eachcase["step" + str(i)]
result = eachcase["result" + str(i)]
stepnode = SubElement(stepsnode, "step")
SubElement(stepnode, "step_number").append(CDATA(str(i)))
SubElement(stepnode, "actions").append(CDATA(self.__remove_step_num(step)))
SubElement(stepnode, "expectedresults").append(CDATA(self.__remove_result_num(result)))
SubElement(stepnode, "execution_type").append(CDATA(eachcase["execution_type"]))
except:
break
try:
keywords_node = SubElement(testcase_node, "keywords")
keyword_node = SubElement(keywords_node, "keyword", {"name": eachcase["keyword"]})
SubElement(keyword_node, "notes").append(CDATA(""))
except:
pass
testcases_node.append(testcase_node)
self.__indent(testcases_node)
xml_file.write(self.save_path, encoding="utf-8", xml_declaration=True)
return xml_file
def __remove_step_num(self, text=None):
"""# Exclude Step: character ''“
step_text = re.sub(r"Step\s+:", "", text)
return step_text
def __remove_result_num(self, text=None):
"""# Exclude Result: character ''“
result_text = re.sub(r"Result\s+:", "", text)
return result_text
def __indent(self, elem, level=0):
i = "\n" + level * " "
if len(elem):
if not elem.text or not str(elem.text).strip():
elem.text = i + " "
for e in elem:
# print e
self.__indent(e, level + 1)
if not e.tail or not e.tail.strip():
e.tail = i
if level and (not elem.tail or not elem.tail.strip()):
elem.tail = i
return elem
def CDATA(text=None): # In order to match the CDATA format in the display xml, this part is all in uppercase.
"""generate CDATA Label related xml data"""
element = Element("CDATA")
element.text = text
return element
if __name__ == '__main__':
curpath = os.getcwd()
excel_folder = os.path.join(curpath, "Excel_Input")
excel_list = os.listdir(excel_folder)
xml_folder = os.path.join(curpath, "XML_Output")
# Delete the old XML output folder first
try:
shutil.rmtree(xml_folder)
except:
pass
if not os.path.exists(xml_folder):
os.mkdir(xml_folder)
# Batch by batch analysis of Excel
for each_excel in excel_list:
print("*" * 60)
print("Processing%s" % each_excel)
print("*" * 60)
e_obj = ExcelReader("%s%s%s" % (excel_folder, os.sep, each_excel))
all_cases_list = e_obj.get_all_cases()
excel_name, posfix = os.path.splitext(each_excel)
x_obj = XmlWriter(all_cases_list, "%s%s%s.xml" % (xml_folder, os.sep, excel_name))
x_obj.write_xml()
print("\nExcel to XML All processed! XML Build to XML_Output folder!")
os.system("pause")
Download the case materials
Including: test case template, etree package (including ElementTree), Python script
Jump to download the selfie tutorial on the official website
Wusanren products, please feel free to download!
Testlink import effect
Go to the official website to view Excel to XML and import the video of Testlink.
For more and better original articles, please visit the official website: www.zipython.com
Selfie course (Python course of automatic test, compiled by Wu Sanren)
Original link: https://www.zipython.com/#/detail?id=d5a9c3981b4b4d8ab560a09c428c39c1
You can also follow the wechat subscription number of "wusanren" and accept the article push at any time.