python practices every Monday
Every Friday, python requirements are released, all of which come from real businesses. Reference answers will be released next Friday.
2018-06-25 realizes factorial in a recursive way
Return n! = 123...n
2018-06-22 String and Regular Expressions Exercise
Question 1:
Which of the following string definitions is incorrect?
A,r'C:\Program Files\foo\bar'
B,r'C:\Program Files\foo\bar'
C, r'C:\Program Files\foo\bar\'
D,r'C:\Program Files\foo\bar\\'
Reference Answer: B
Question 2:
There are strings like'python 3 Quick Start Tutorial 2 Number and Sequence 3 List'. The character rules are as follows:
1. There are English or numeral combinations at the beginning of the line, Chinese in the middle, and English or numeral combinations at the end.
2. Require regular expressions to extract the first Chinese field, such as the Quick Start Tutorial above.
Reference answer
#!python In [1]: import re In [2]: t = 'python3 Quick Start Tutorial 2 Number and Sequence 3 List' In [3]: re.findall('^\w+(..*?)\w+',t, re.ASCII) Out[3]: ['Quick Start Tutorial']
Analysis of Open and Closed Eye Data in 2018-06-15
The following data are available
#!python $ head data.csv # Left Eye Open and Close Eye Score Left Eye Effective Score Right Eye Eye Effective Score Image Name 0.123603 9.835913 9.470212 9.889045,/home/andrew/code/data/common/Eyestate/ocular_base/close/1.jpg 0.179463 9.816979 2.074970 9.901421,/home/andrew/code/data/common/Eyestate/ocular_base/close/10.jpg 0.673736 9.925372 0.001438 9.968187,/home/andrew/code/data/common/Eyestate/ocular_base/close/11.jpg 0.593570 9.905622 0.001385 9.986063,/home/andrew/code/data/common/Eyestate/ocular_base/close/12.jpg 0.222101 9.974337 0.005272 9.985535,/home/andrew/code/data/common/Eyestate/ocular_base/close/13.jpg 1.105360 9.978926 0.007232 9.986403,/home/andrew/code/data/common/Eyestate/ocular_base/close/14.jpg 5.622934 9.955227 5.909572 9.969641,/home/andrew/code/data/common/Eyestate/ocular_base/close/15.jpg 0.010507 9.965939 0.005150 9.990325,/home/andrew/code/data/common/Eyestate/ocular_base/close/16.jpg 0.043546 9.986520 0.014031 9.982257,/home/andrew/code/data/common/Eyestate/ocular_base/close/17.jpg 6.176013 9.848222 4.293341 9.929223,/home/andrew/code/data/common/Eyestate/ocular_base/close/18.jpg
Requirement:
- Screen out the data of unrecognized faces (left eye opening and closing score is -1)
- Screen out the wrong format data (left eye opening and closing score is -2)
- Screen out the data identified as open eyes (picture name contains close, but open eyes have a greater than 9.5)
- Screen out the data identified as closed eyes (picture name contains open, but open and closed eyes are less than 9.5)
- Screen out data that is invalid and recognized as valid (image name contains invalid, but valid score is greater than 9.5)
- Screen out valid data that is identified as invalid (picture names contain valid, but valid scores are less than 9.5)
Code and reference code address
Creating Tricolor Pictures on June 14, 2018
Create the following three-color image with 600*400 pixels

python image processing reference library
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # Author: xurongzhong#126.com wechat:pythontesting qq:37391319 # Technical support nail group: 21745728 (can be added nail pythontesting invitation to join) # qq group: 144081101 591302926 567351477 # CreateDate: 2018-6-12 # dutchflag.py from PIL import Image def dutchflag(width, height): """Return new image of Dutch flag.""" img = Image.new("RGB", (width, height)) for j in range(height): for i in range(width): if j < height/3: img.putpixel((i, j), (255, 0, 0)) elif j < 2*height/3: img.putpixel((i, j), (0, 255, 0)) else: img.putpixel((i, j), (0, 0, 255)) return img def main(): img = dutchflag(600, 400) img.save("dutchflag.jpg") main()
Data Analysis for 2018-06-12: Screen Columns B Containing Column A
Questions from Group python Data Analysis Artificial Intelligence 521070358
There is a large amount of data similar to the following structure
#!python {'A':['Ford', 'Toyota', 'Ford','Audi'], 'B':['Ford F-Series pickup', 'Camry', 'Ford Taurus/Taurus X', 'Audi test']}
Now I want to:
1. Output column B contains records of column A content
2. Output column A is a record of Ford or Toyota
Reference code:
#!python #!/usr/bin/python3 # -*- coding: utf-8 -*- # Author: xurongzhong#126.com wechat:pythontesting qq:37391319 # Technical support nail group: 21745728 (can be added nail pythontesting invitation to join) # qq group: 144081101 591302926 567351477 # CreateDate: 2018-6-012 import pandas as pd def test(x): if x['A'] in x['B']: return True else: return False df = pd.DataFrame( {'A':['Ford', 'Toyota', 'Ford','Audi'], 'B':['Ford F-Series pickup', 'Camry', 'Ford Taurus/Taurus X', 'Audi test']} ) print(df) # Output column B contains records of column A content print(df[df.apply(test, axis=1)]) # lambda mode print(df[df.apply(lambda x: x['A'] in x['B'], axis=1)]) # Output column A is a record of Ford or Toyota print(df[df['A'].str.match('Ford|Toyota')])
Implementation results:
#!python A B 0 Ford Ford F-Series pickup 1 Toyota Camry 2 Ford Ford Taurus/Taurus X 3 Audi Audi test A B 0 Ford Ford F-Series pickup 2 Ford Ford Taurus/Taurus X 3 Audi Audi test A B 0 Ford Ford F-Series pickup 2 Ford Ford Taurus/Taurus X 3 Audi Audi test A B 0 Ford Ford F-Series pickup 1 Toyota Camry 2 Ford Ford Taurus/Taurus X
2018-06-11 Basic Interview Questions for Python Data Agencies
generate
#!python [-0.1, 0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1. , 1.1]
Reference resources:
#!python import numpy as np [x / 10.0 for x in range(-1, 11)] np.arange(-0.1, 1.1, 0.1)
2018-06-08 Draw a 10-pixel square with turtle (Primary)
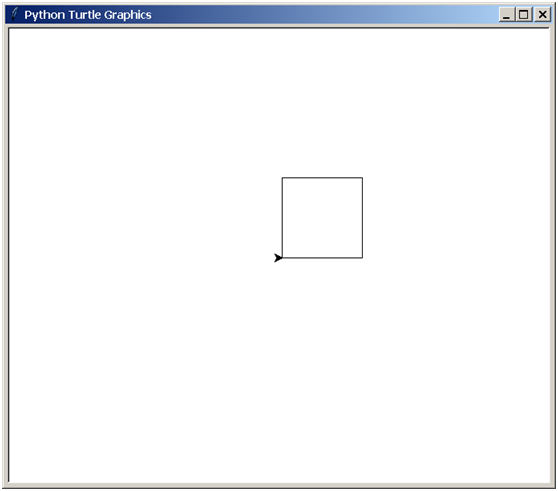
Reference code:
#!python #!/usr/bin/python3 # -*- coding: utf-8 -*- # Author: xurongzhong#126.com wechat:pythontesting qq:37391319 # Technical support nail group: 21745728 (can be added nail pythontesting invitation to join) # qq group: 144081101 591302926 567351477 # CreateDate: 2018-6-07 from turtle import * forward(100) left(90) forward(100) left(90) forward(100) left(90) forward(100) left(90) exitonclick()
Note that using Python 3.6.0 or later, command line execution is better.
Extended learning
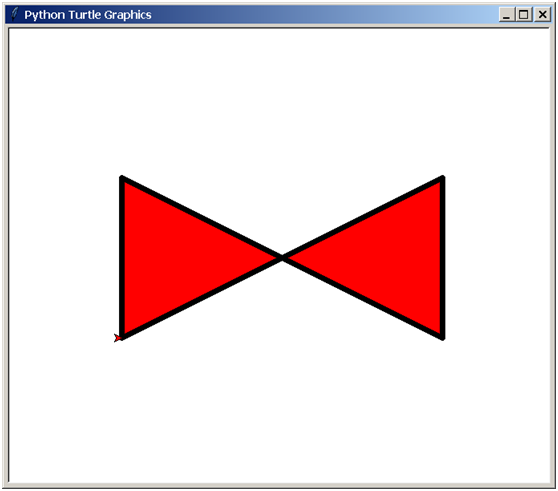
Reference code:
#!python #!/usr/bin/python3 # -*- coding: utf-8 -*- # Author: xurongzhong#126.com wechat:pythontesting qq:37391319 # Technical support nail group: 21745728 (can be added nail pythontesting invitation to join) # qq group: 144081101 591302926 567351477 # CreateDate: 2018-6-07 from turtle import * pensize(7) penup() goto(-200, -100) pendown() fillcolor("red") begin_fill() goto(-200, 100) goto(200, -100) goto(200, 100) goto(-200, -100) end_fill() exitonclick()
Computing the coincidence area of different versions of face recognition frames in 2018-06-07
For an existing picture, the coordinates identified by version 1 are: (60, 188, 260, 387) and those identified by version 2 are (106, 291, 340, 530). The format is left, top, right, buttom.
Please calculate the total number of common pixels, the total number of pixels in Version 1, the total number of pixels in Version 2, the ratio of coincidence area in Version 1 and the ratio of coincidence area in Version 2.
Reference code:
#!python #!/usr/bin/python3 # -*- coding: utf-8 -*- # Author: xurongzhong#126.com wechat:pythontesting qq:37391319 # Technical support nail group: 21745728 (can be added nail pythontesting invitation to join) # qq group: 144081101 591302926 567351477 # CreateDate: 2018-6-07 def get_area(pos): left, top, right, buttom = pos left = max(0, left) top = max(0, top) width = right - left height = buttom - top return (width*height, left, top, right, buttom) def overlap(pos1, pos2): area1, left1, top1, right1, buttom1 = get_area(pos1) area2, left2, top2, right2, buttom2 = get_area(pos2) left = max(left1, left2) top = max(top1, top2) left = max(0, left) top = max(0, top) right = min(right1, right2) buttom = min(buttom1, buttom2) if right <= left or buttom <= top: area = 0 else: area = (right - left)*(buttom - top) return (area, area1, area2, float(area)/area1, float(area)/area2) print(overlap((60, 188, 260, 387), (106, 291, 340, 530)))
implement
#!python $ python3 overlap.py (14784, 39800, 55926, 0.3714572864321608, 0.2643493187426242)
2018-06-06 json format conversion
There are a lot of data in face tagging, some of which are referred to as: data
Require output:
1,files.txt
#!python image_1515229323784.ir image_1515235832391.ir image_1515208991161.ir image_1515207265358.ir image_1521802748625.ir image_1515387191011.ir ...
2, coordinate information poses.txt
File name, left, top, right, buttom, width, height
#!python image_1515229323784.ir,4,227,234,497,230,270 image_1515235832391.ir,154,89,302,240,148,151 image_1515208991161.ir,76,369,309,576,233,207 image_1515207265358.ir,44,261,340,546,296,285 ...
3. Comparing documents:
First of all: \ followed by a serial number, incrementing from 1
3 640 4801 and the latter three rows were temporarily considered fixed. There are four coordinates left, top, right, buttom behind the last line 1.
#!python # 1 image_1515229323784.ir 3 640 480 1 0 1 1 4 227 234 497 # 2 image_1515235832391.ir 3 640 480 1 0 1 1 154 89 302 240 # 3 ...
Reference code:
#!python #!/usr/bin/env python3 # -*- coding: utf-8 -*- import shutil import os import glob import json import pprint import json import data_common directory = 'data' files = data_common.find_files_by_type(directory,'json') i = 1 file_list = [] results = [] poses = [] for filename in files: d = json.load(open(filename)) name = d['image']['rawFilename'].strip('.jpg') pos = d['objects']['face'][0]['position'] num = len(d['objects']['face']) if num > 1: print(filename) print(name) pprint.pprint(d['objects']['face']) out = "# {}\n{}\n3 640 480 1\n0\n{}\n".format(i, name, num) for face in d['objects']['face']: pos = face['position'] top = round(pos['top']) bottom = round(pos['bottom']) left = round(pos['left']) right = round(pos['right']) out = out + "1 {} {} {} {}\n".format(left, top, right, bottom) poses.append("{},{},{},{},{},{},{}".format(name, left, top, right, bottom, right - left, bottom -top)) i = i + 1 #print(out) file_list.append(name) results.append(out.rstrip('\n')) data_common.output_file("files.txt",file_list) data_common.output_file("results.txt",results) data_common.output_file("poses.txt",poses)
2018-06-01 Regular Expressions and Pinyin Sorting
A section of a group. Chat record
Now the qq name of the output sort is required, and the result is similar to the following:
#!python
[...,'Hermit of Materia Medica','jerryyu','Poor Cherry Tree','Good Wind and Cloud','Ouyang-Shenzhen Baimang',...]
Source of demand: There is an active user who wants to invite some qq groups to his group in batches. And I don't want to see chat records all over the place.
Reference material: python text processing library
Reference code:
#!python #!/usr/bin/python3 # -*- coding: utf-8 -*- # Author: xurongzhong@126.com wechat:pythontesting qq:37391319 # Technical support nail group: 21745728 (can be added nail pythontesting invitation to join) # qq group: 144081101 591302926 567351477 # CreateDate: 2018-6-1 import re from pypinyin import lazy_pinyin name = r'test.txt' text = open(name,encoding='utf-8').read() #print(text) results = re.findall(r'(:\d+)\s(.*?)\(\d+', text) names = set() for item in results: names.add(item[1]) keys = list(names) keys = sorted(keys) def compare(char): try: result = lazy_pinyin(char)[0][0] except Exception as e: result = char return result keys.sort(key=compare) print(keys)
Execute an example:
1. Export the chat record of qq group to TXT format and rename it test.txt
2, implementation:
#!python $ python3 qq.py ['Sally', '^^O^^', 'aa Lactation Division', 'bling', 'Hermit Hermit', 'Pure Chinese medicine for impotence and premature ejaculation', 'Long night without famine', 'east~Air China', 'Dry golden grass', 'Guangdong-Chao Qing Zheng', 'Red plum* Chongqing', 'jerryyu', 'Poor cherry tree', 'Lucky wind and cloud', 'Ouyang-Shenzhen white Mang', 'Sheng Xi Tang~Yuan Heng', 'Shu Zhong~Cowpea.', 'Shaanxi Weinan Yiqing Pavilion*Inaction', 'Wu Ning... let', 'System message', 'Yu Li Wei', 'Leaning on the window', 'Haze and mist', 'Swallow', 'Zhang Qiang', 'Taste', '✾Buy a can for Western food', '[Great Chivalrous', '[Chivalrous] facing the sea~Treatment of scald with pure Chinese medicine', '[Master Wu Ning... let', '[Red plum* Chongqing', '[Shao Xia) Burning Qin and Cooking Crane', '[Young Chivalrous] Stupid', '[Xipu☞Mountain family']
2018-05-25 Rotating Pictures
Rotate the jpg image of / home/andrew/code/tmp_photos2 270 degrees and place it in / home/andrew/code/tmp_photos3
Reference material: python image processing library
The required command line interface is as follows:
#!sh $ python3 rotate.py -h usage: rotate.py [-h] [-t TYPE] [-a ANGLE] [--version] src dst Function: Rotating Pictures Example: $python 3 rotate.py/home/andrew/code/tmp_photos2/home/andrew/code/tmp_photos3-a 270 Rotate the jpg image of / home/andrew/code/tmp_photos2 270 degrees and place it in / home/andrew/code/tmp_photos3 positional arguments: src source directory dst destination directory optional arguments: -h, --help show this help message and exit - t TYPE file extension, default to jpg -a ANGLE rotation angle, default is 90 degrees, the direction is counterclockwise. --version show program's version number and exit
Before rotation:

After rotation

Source of demand: Users may not take pictures of the face above, chin below, but the face recognition effect is better, for this reason.
Reference code:
#!python import glob import os import argparse from PIL import Image import photos import data_common description = ''' //Function: Rotating Pictures //Example: $python 3 rotate.py/home/andrew/code/tmp_photos2/home/andrew/code/tmp_photos3-a 270 ''' parser = argparse.ArgumentParser(description=description, formatter_class=argparse.RawTextHelpFormatter) parser.add_argument('src', action="store", help=u'Source directory') parser.add_argument('dst', action="store", help=u'Destination directory') parser.add_argument('-t', action="store", dest="type", default="jpg", help=u'File extension, Default is jpg') parser.add_argument('-a', action="store", dest="angle", default=90, type=int, help=u'Rotation angle, default is 90 degrees, direction is counterclockwise.') parser.add_argument('--version', action='version', version='%(prog)s 1.0 Rongzhong xu 2018 04 26') options = parser.parse_args() data_common.check_directory(options.dst) files = data_common.find_files_by_type(options.src, filetype=options.type) photos.rotate(files, options.dst, options.angle)
Reference material
- Discuss qq q group 144081101 591302926 567351477 nail free group 21745728
- Address of the latest version of this article
- python test development library Thank you for your compliment.
- Massive downloads of books related to this article