Spider
1. Python Basics
1.Python environment installation
1.1 download Python
Official website: https://www.python.org/
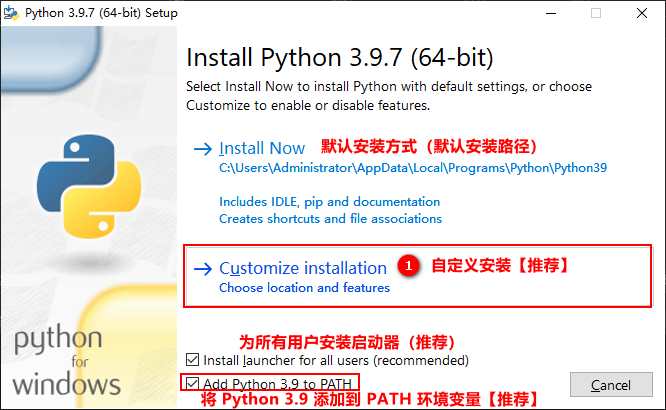
1.2 installing Python
One way fool installation
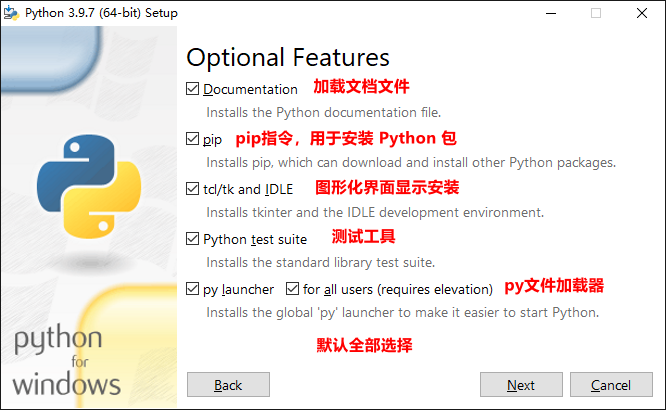
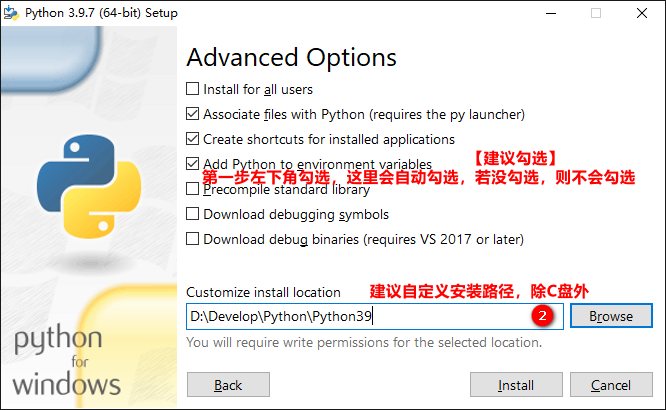
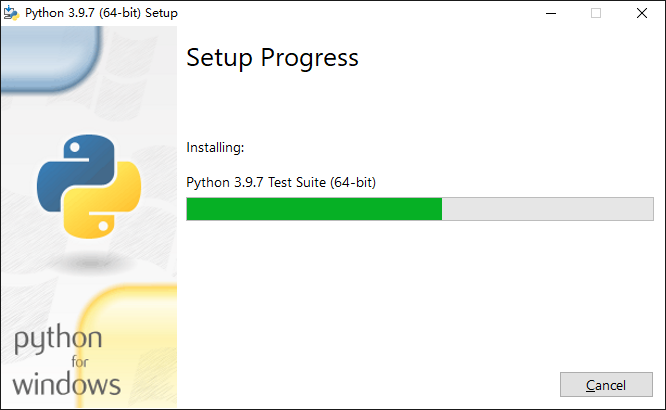
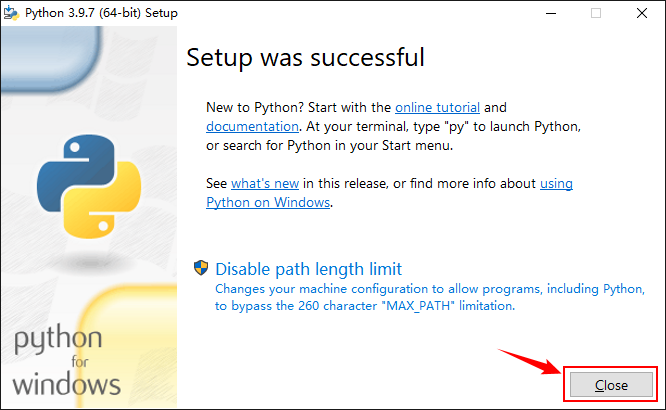
1.3 test whether the installation is successful
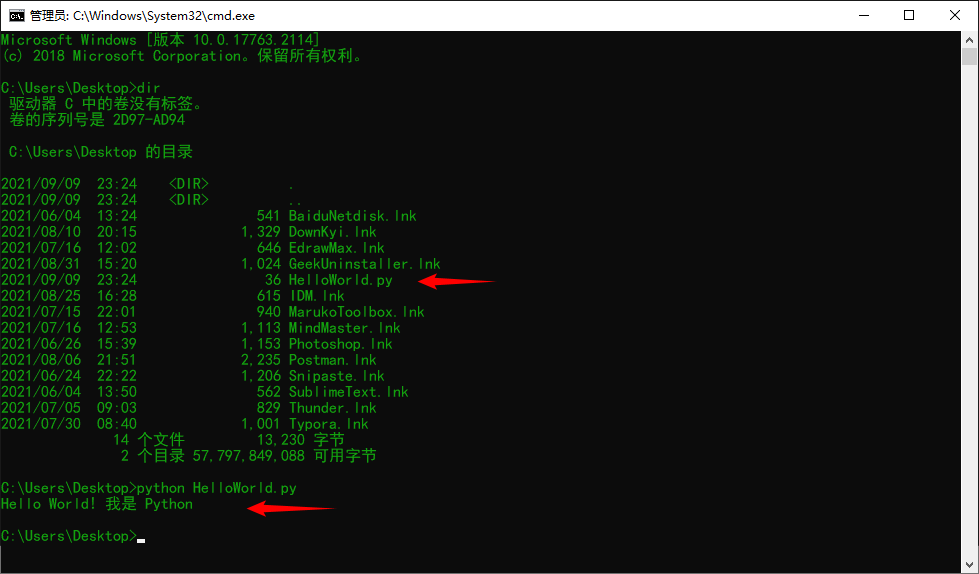
Win + R, enter cmd, enter
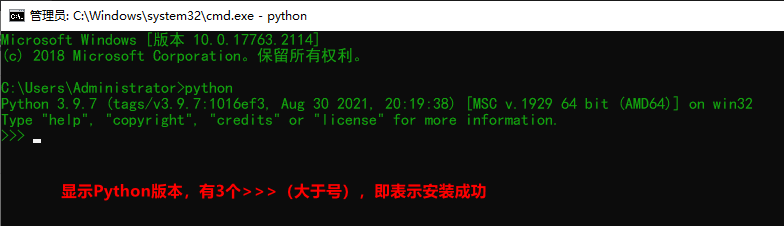
If an error occurs: 'python', it is not an internal or external command, nor is it a runnable program or batch file.
Cause: the problem of environment variables may be because the Add Python 3.x to PATH option is not checked during Python installation. At this time, python needs to be configured manually.
1.4 configuring Python environment variables
Note: if the Add Python 3.x to PATH option has been checked during the installation process, and in the cmd command mode, enter the python instruction to display version information without error, there is no need to manually configure python. (skip the step of manually configuring environment variables)
Right click this computer, select properties,
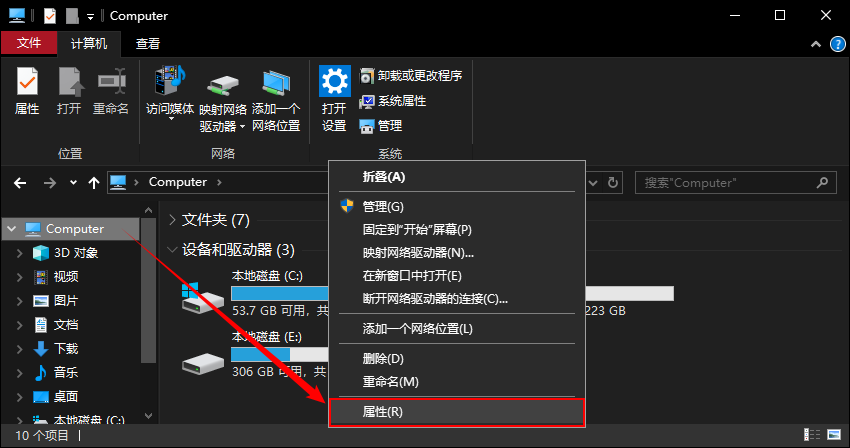
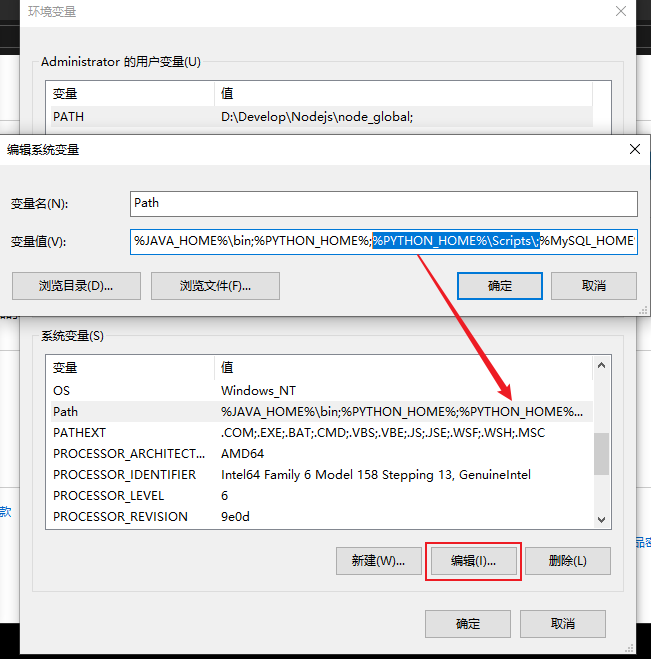
Select advanced system settings -- > environment variables -- > find and double-click Path
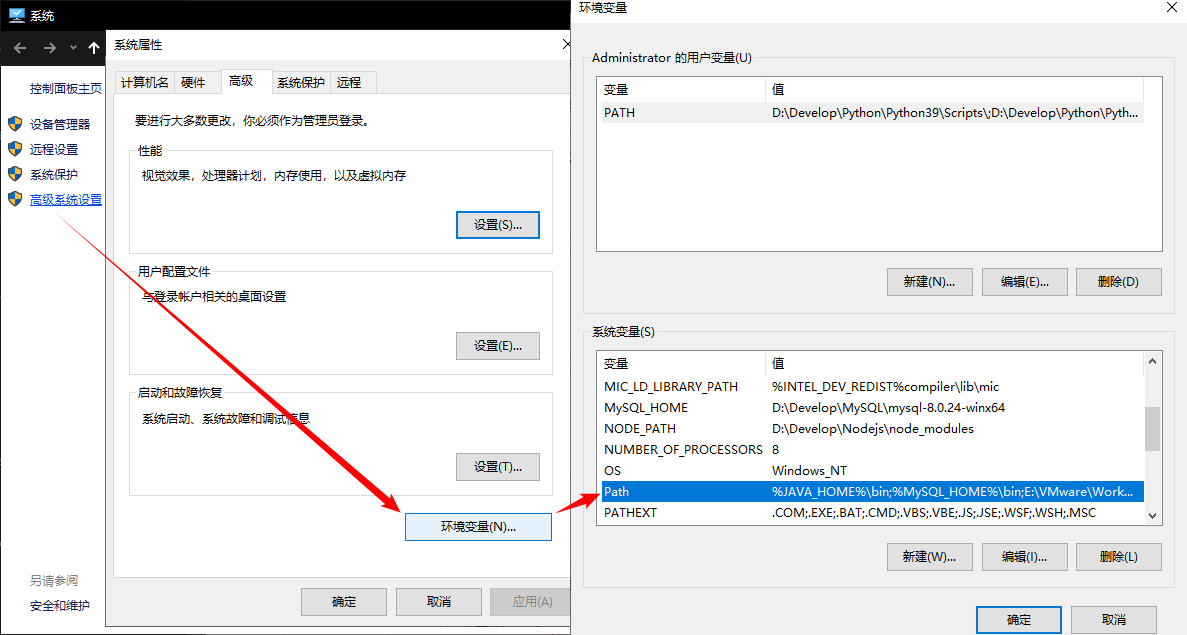
Double click Path, click New in the pop-up box, add the python installation directory, add the Path, then edit the environment variable in Path, and use%% to read the python installation Path
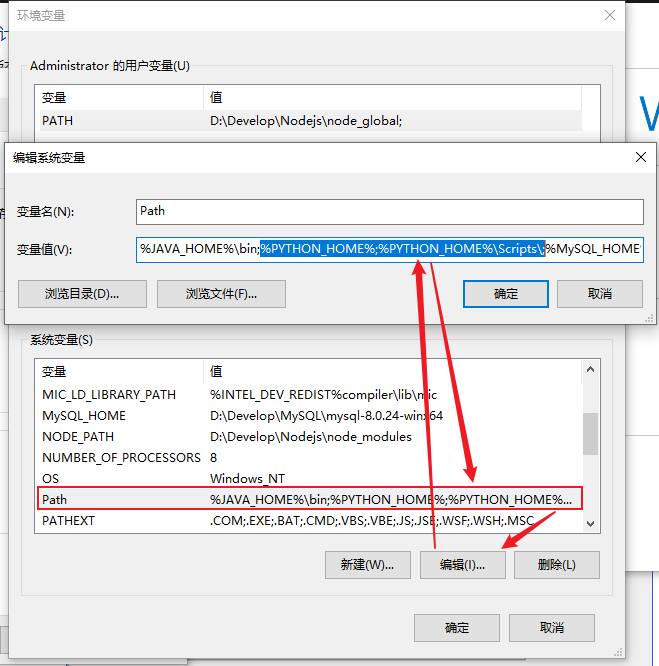
2. Use of Pip
pip is a modern, general-purpose Python package management tool. It provides the functions of finding, downloading, installing and uninstalling Python packages, which is convenient for us to manage Python resource packages.
2.1 installation
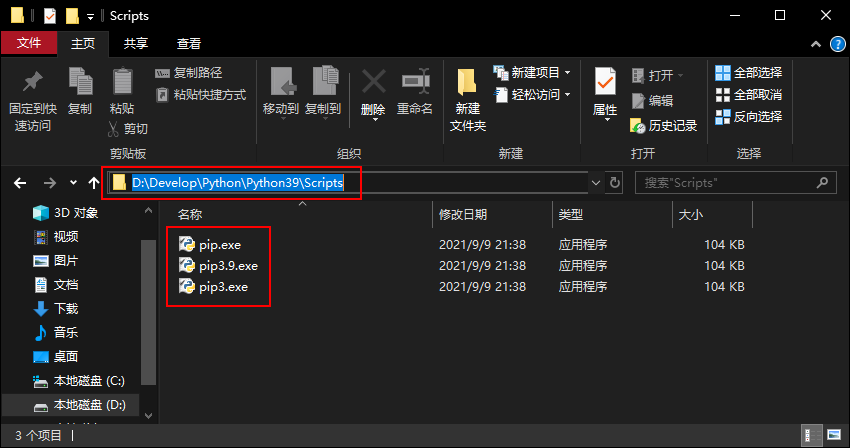
When Python is installed, pip.exe is automatically downloaded and installed
2.2 configuration
On the windows command line, enter pip -V to view the version of pip.
# View pip Version (capital V) pip -V
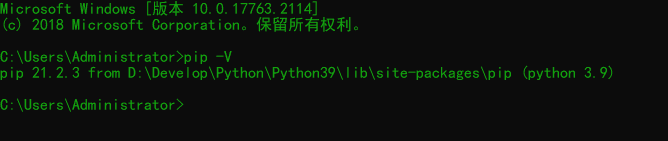
If you run pip -V on the command line, the following prompt appears: 'pip', which is not an internal or external command, nor a runnable program or batch file.
Cause: the problem of environment variables may be because the Add Python 3.x to PATH option is not checked during Python installation. At this time, python needs to be configured manually.
Right click the computer -- > environment variable -- > find and double-click path -- > click Edit in the pop-up window – > find the installation directory of pip (that is, the path of Scripts in the python installation directory) and add the path.
Configure environment variables (if configured, please skip. There are many ways, you can configure them anyway)
2.3 using pip to manage Python packages
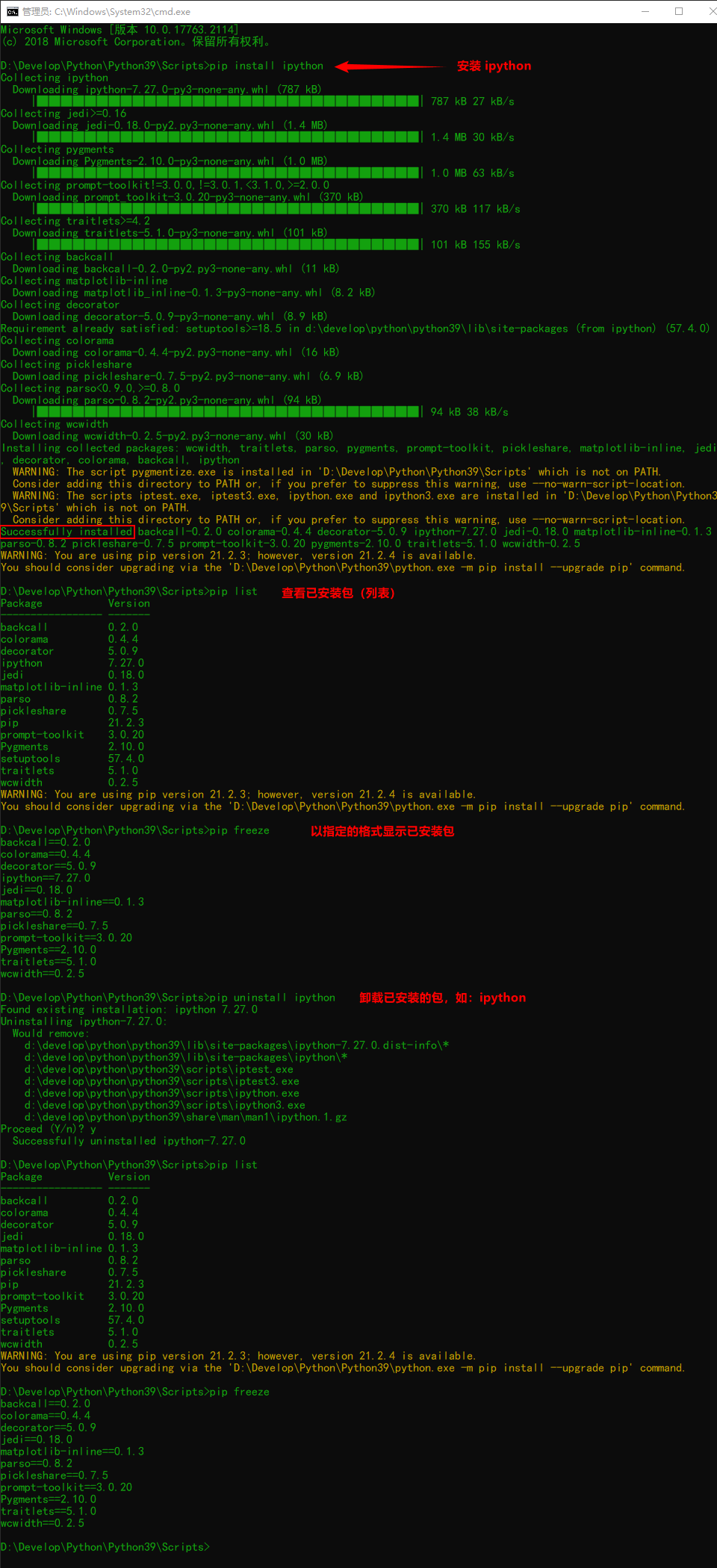
pip install <Package name> # Install the specified package pip uninstall <Package name> # Delete the specified package pip list # Displays installed packages pip freeze # Displays the installed packages in the specified format
2.4 modify pip download source
- Running the pip install command will download the specified python package from the website. The default is from the https://files.pythonhosted.org/ Download from the website. This is a foreign website. In case of bad network conditions, the download may fail. We can modify the source of pip software through commands.
- Format: pip install package name-i address
- Example: pip install ipython -i https://pypi.mirrors.ustc.edu.cn/simple/ Is to download requests (a third-party web Framework Based on python) from the server of USTC
List of commonly used pip download sources in China:
- Alibaba cloud: http://mirrors.aliyun.com/pypi/simple/
- University of science and technology of China: https://pypi.mirrors.ustc.edu.cn/simple/
- Douban: http://pypi.douban.com/simple/
- Tsinghua University: https://pypi.tuna.tsinghua.edu.cn/simple/
- University of science and technology of China:[ http://pypi.mirrors.ustc.edu.cn/simple/ ](
2.4.1 temporary modification
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/
2.4.2 permanent modification
Under Linux, modify ~ /. pip/pip.conf (or create one), and modify the index URL variable to the source address to be replaced:
[global] index-url = https://mirrors.aliyun.com/pypi/simple/ [install] trusted-host = mirrors.ustc.edu.cn
Under windows, create a PIP directory in the user directory, such as C:\Users\xxx\pip, and create a new file pip.ini, as follows:
3. Run Python program
3.1 terminal operation
-
Write code directly in the python interpreter
# Exit python environment exit() Ctrl+Z,Enter
-
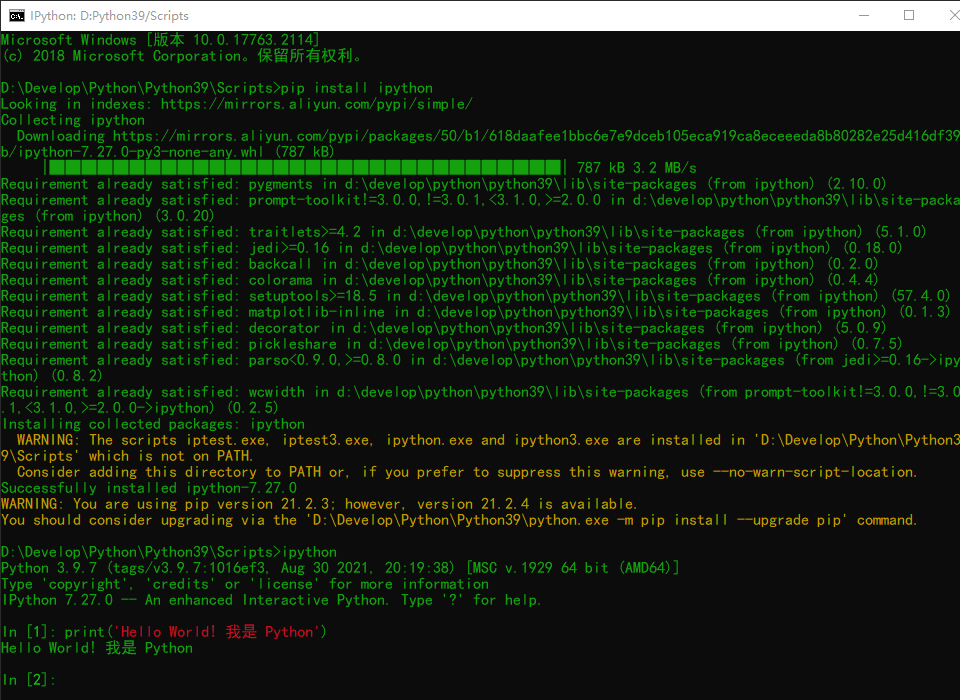
Write code using the ipython interpreter
Using the pip command, you can quickly install IPython
# Install ipython pip install ipython
3.2 running Python files
Use the python directive to run a python file with the suffix. py
python File path\xxx.py
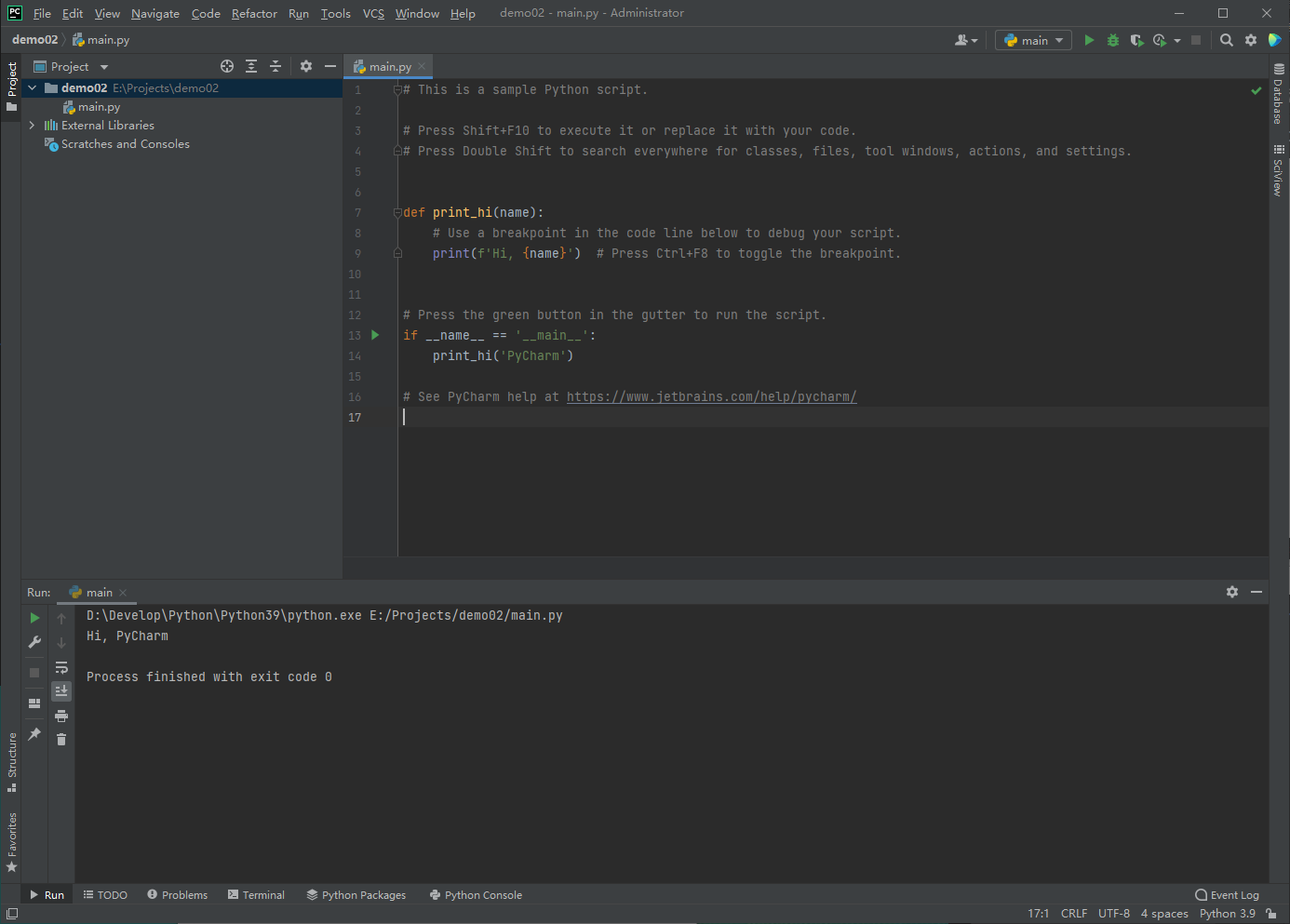
3.3 pychar (IDE integrated development environment)
Concept of IDE
IDE(Integrated Development Environment) is also called integrated development environment. To put it bluntly, it has a graphical interface software, which integrates the functions of editing code, compiling code, analyzing code, executing code and debugging code. In Python development, the commonly used IDE is pychart
pycharm is an IDE developed by JetBrains, a Czech company. It provides code analysis, graphical debugger, integrated tester, integrated version control system, etc. it is mainly used to write Python code.
3.3.1 download pychar
Official website download address: http://www.jetbrains.com/pycharm/download

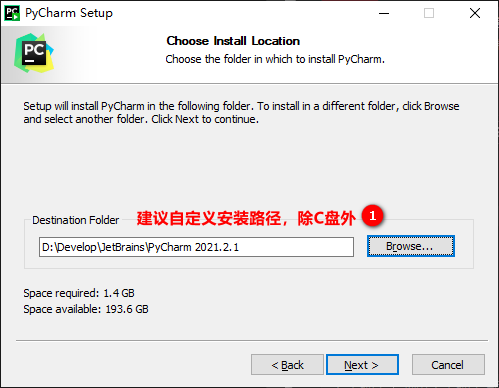
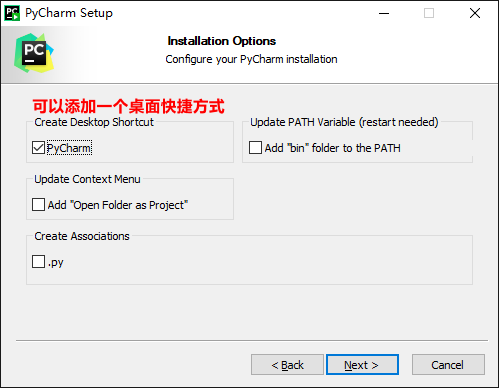
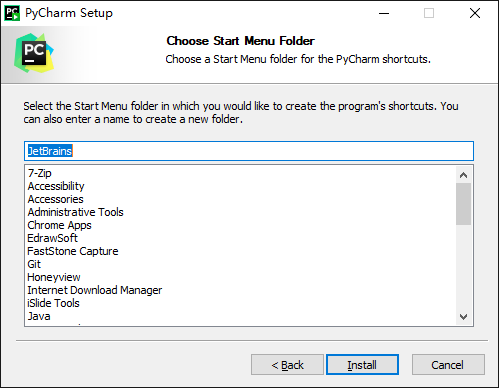
3.3.2 installation of pychar
One way fool installation
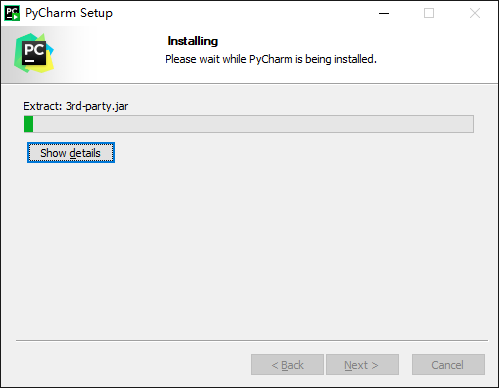
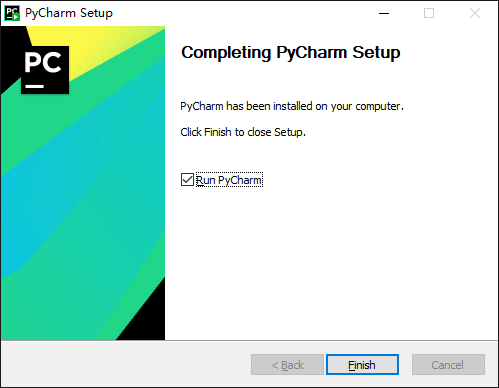

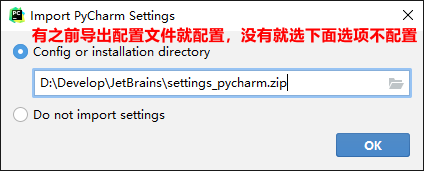
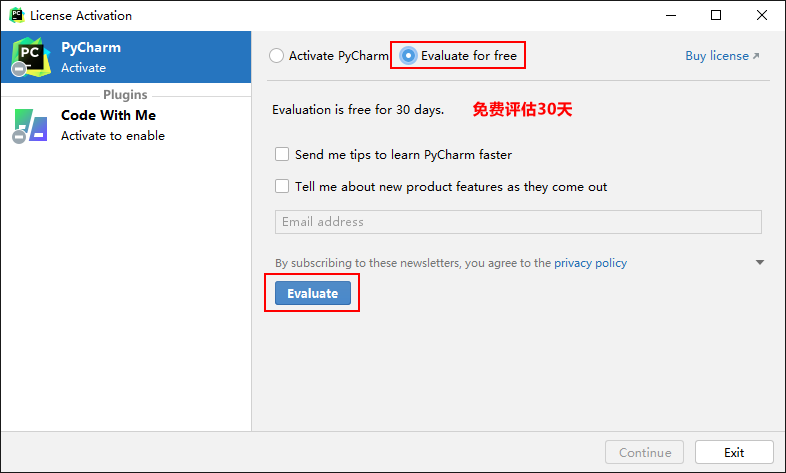
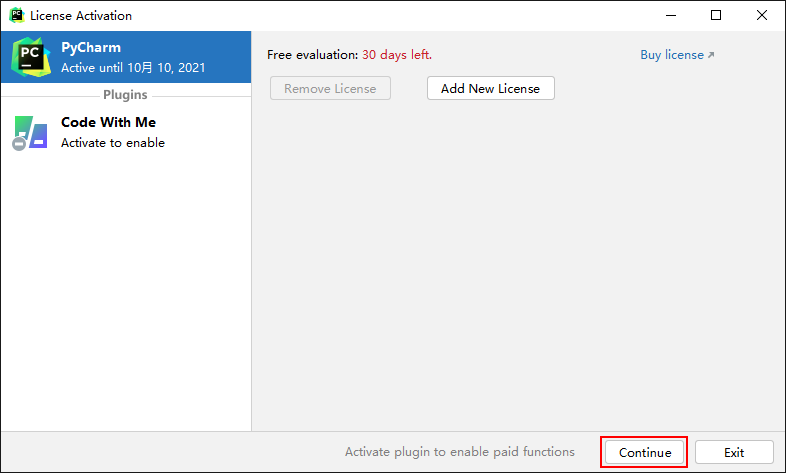
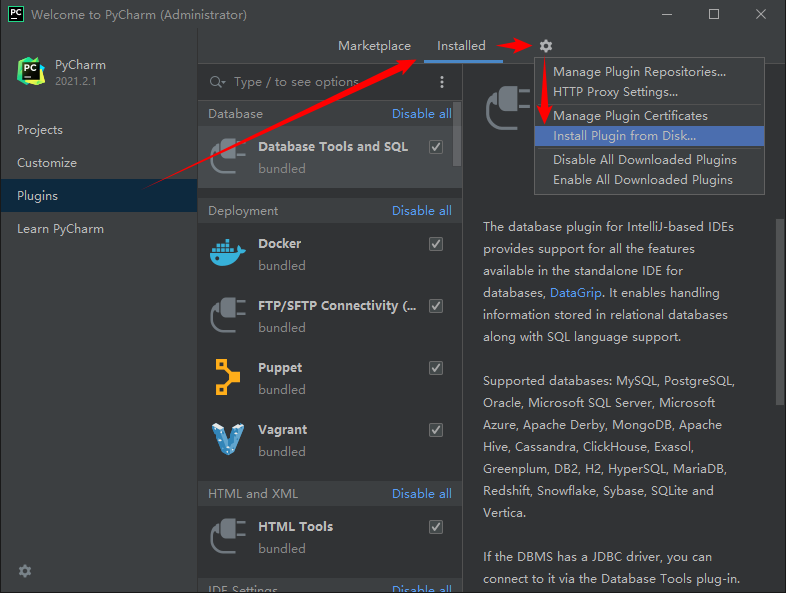
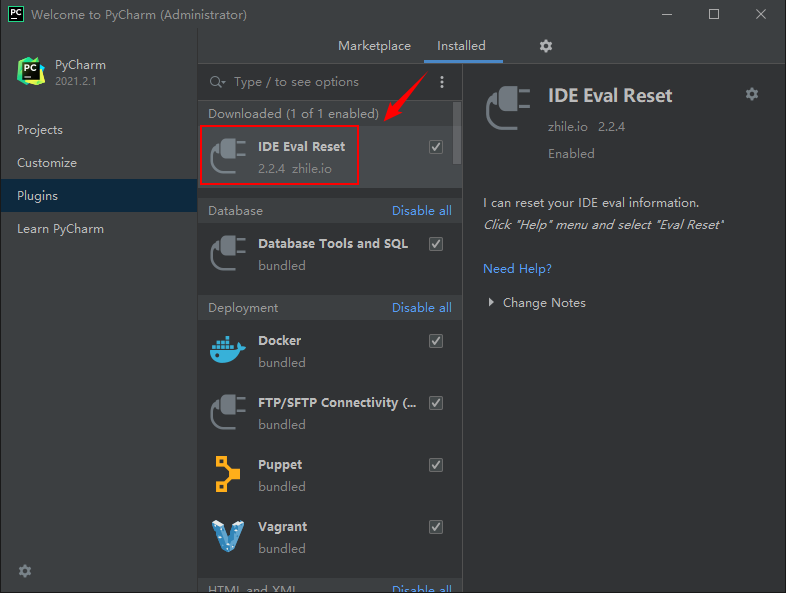
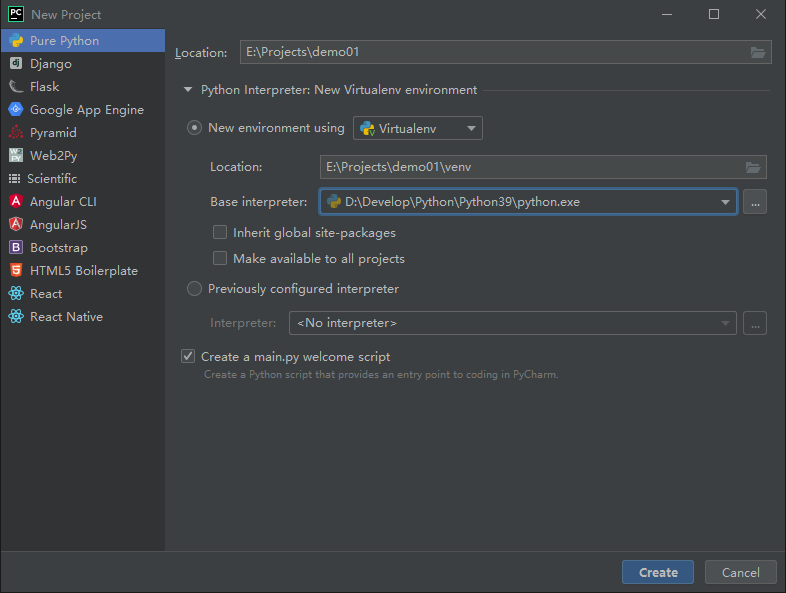
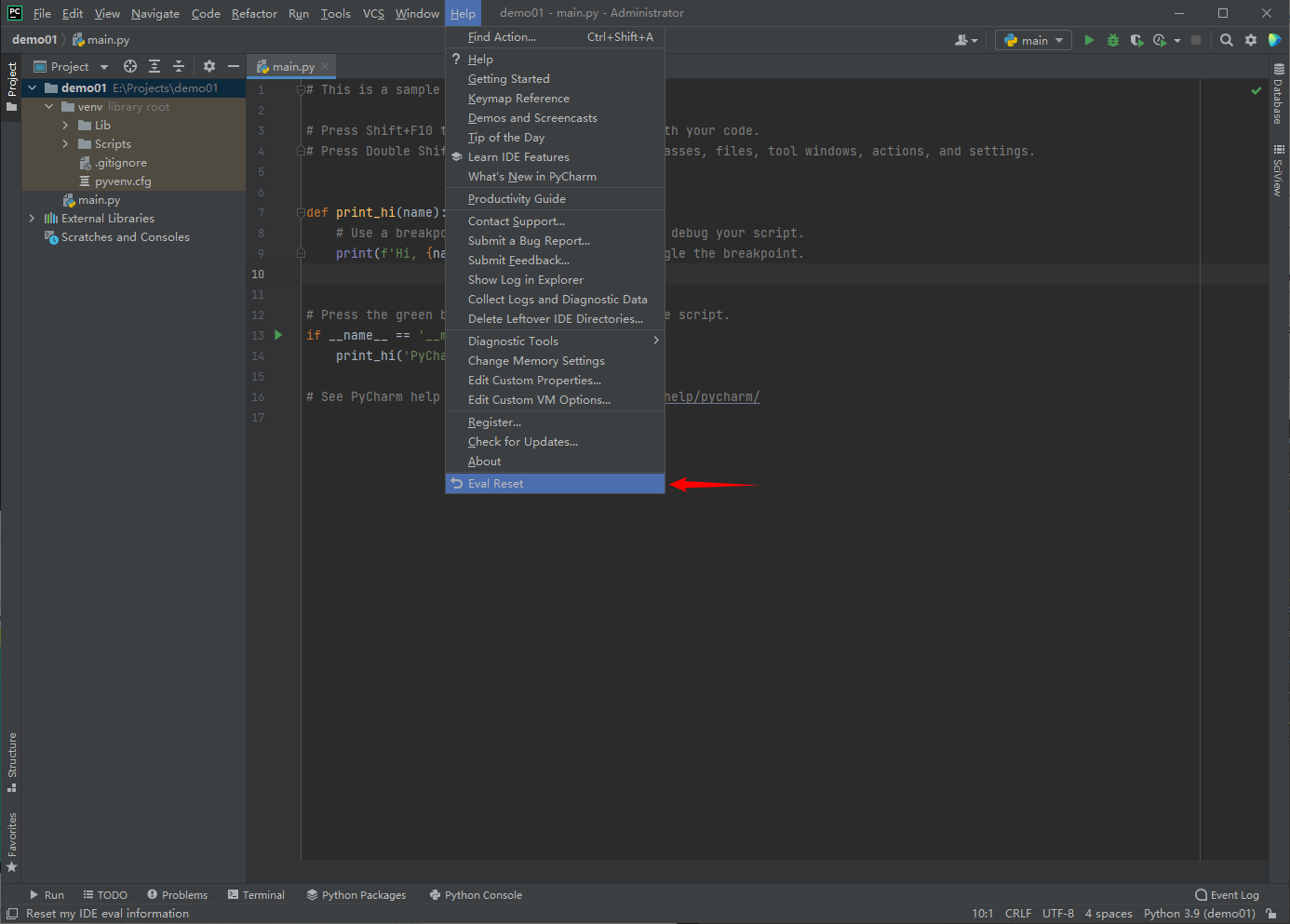
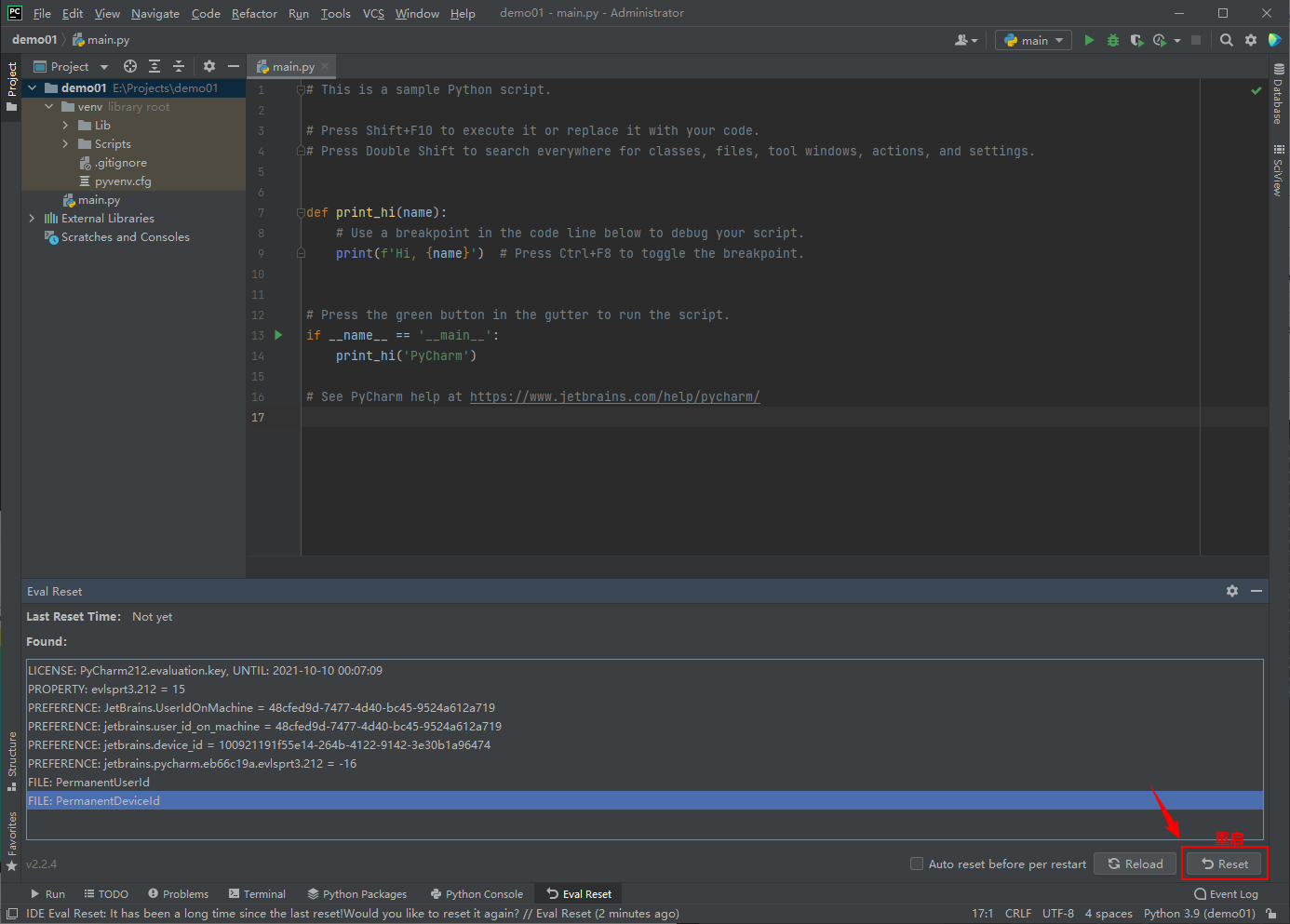

At present, it has been updated to 2021.2.2, which can be downloaded to Download from the official website Used, updated on the official website: September 15, 2021
3.3.3 use pychar
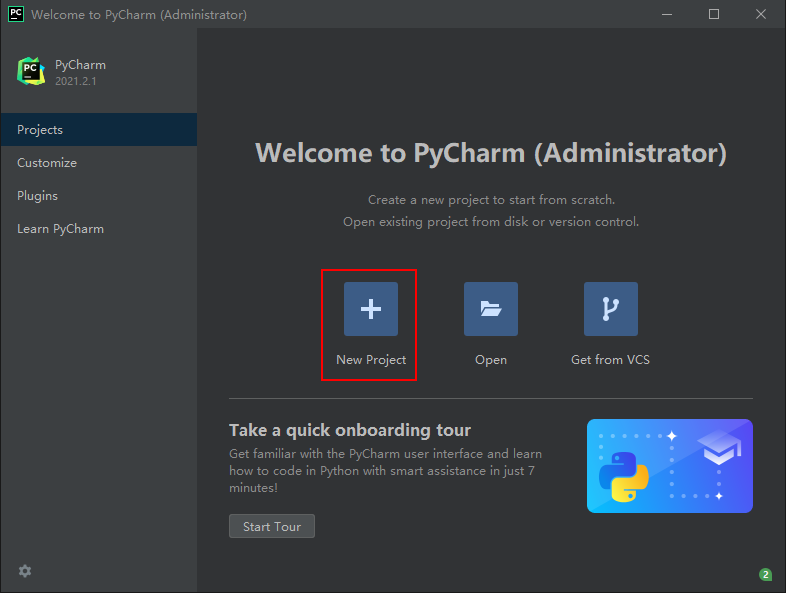
Create a new project
You can select an existing interpreter
Run test
4. Notes
Comments are for programmers. In order to make it easy for programmers to read the code, the interpreter will ignore comments. It is a good coding habit to annotate and explain the code appropriately in their familiar language.
4.1 classification of notes
Single line comments and multi line comments are supported in Python.
Single-Line Comments
Start with #.
multiline comment
Start with '' and end with '', multiline comment.
5. Variables and data types
5.1 definition of variables
Data that is reused and often needs to be modified can be defined as variables to improve programming efficiency.
Variables are variables that can be changed and can be modified at any time.
Programs are used to process data, and variables are used to store data.
5.2 variable syntax
Variable name = variable value. (the = function here is assignment.)
5.3 access to variables
After defining a variable, you can use the variable name to access the variable value.
5.4 data types of variables
In Python, in order to meet different business needs, data is also divided into different types.
Variable has no type, data has type
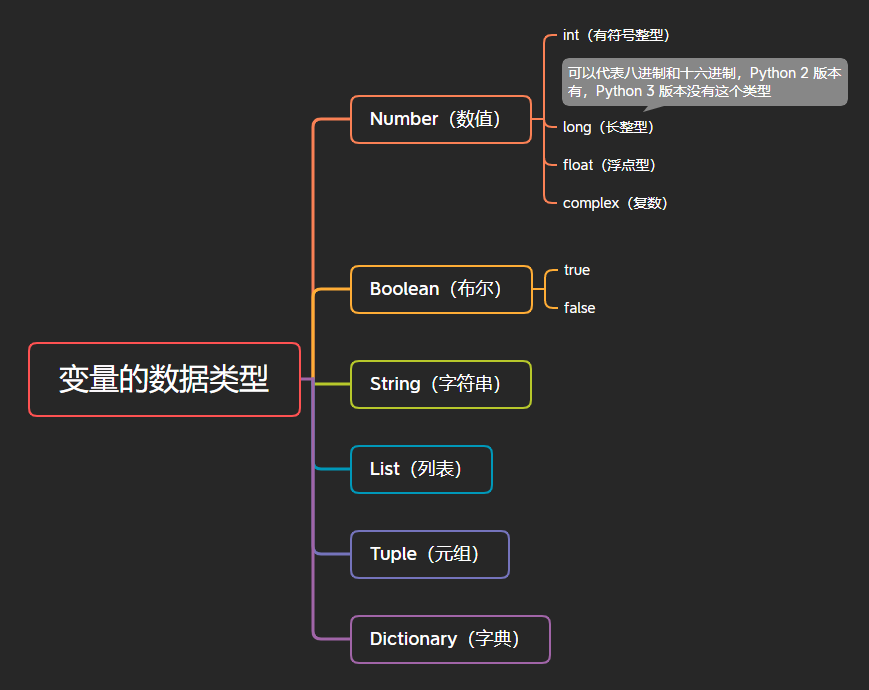
5.5 viewing data types
In python, as long as a variable is defined and it has data, its type has been determined. It does not need the developer to actively explain its type, and the system will automatically identify it. That is to say, "when a variable has no type, data has type".
To view the data type stored by a variable, you can use type (variable name) to view the data type stored by the variable.
# Data type of variable
# numerical value
money = 100000
print(type(money)) # <class 'int'>
# Boolean
gender = True
sex = False
print(type(gender)) # <class 'bool'>
# character string
s = 'character string'
s1 = "String 1"
s2 = '"Cross nesting of single and double quotation marks"'
s3 = "'Cross nesting of single and double quotation marks'"
print(s2)
print(type(s)) # <class 'str'>
# list
name_list = ['Tomcat', 'Java']
print(type(name_list)) # <class 'list'>
# Tuple tuple
age_tuple = (16, 17, 18)
print(type(age_tuple)) # <class 'tuple'>
# dictionary variable name = {key:value,key:value,...}
person = {'name': 'admin', 'age': 18}
print(type(person)) # <class 'dict'>
6. Identifier and keyword
In computer programming language, identifier is the name used by users in programming. It is used to name variables, constants, functions, statement blocks, etc., so as to establish the relationship between name and use.
- An identifier consists of letters, underscores, and numbers, and cannot begin with a number.
- Strictly case sensitive.
- Keywords cannot be used.
6.1 naming conventions
Identifier naming shall be as the name implies (see the meaning of name).
Follow certain naming conventions.
-
Hump nomenclature is divided into large hump nomenclature and small hump nomenclature.
- lower camel case: the first word starts with a lowercase letter; The first letter of the second word is capitalized, for example: myName, aDog
- upper camel case: the first letter of each word is capitalized, such as FirstName and LastName
-
Another naming method is to use the underscore "" to connect all words, such as send_buf. Python's command rules follow the PEP8 standard
6.2 keywords
Keywords: some identifiers with special functions.
Keyword has been officially used by python, so developers are not allowed to define identifiers with the same name as keywords.
| False | None | True | and | as | assert | break | class | continue | def | del |
|---|---|---|---|---|---|---|---|---|---|---|
| elif | else | except | finally | for | from | global | if | import | in | is |
| lambda | nonlocal | not | or | pass | raise | return | try | while | with | yield |
7. Type conversion
| function | explain |
|---|---|
| int(x) | Convert x to an integer |
| float(x) | Convert x to a floating point number |
| str(x) | Convert object x to string |
| bool(x) | Convert object x to Boolean |
Convert to integer
print(int("10")) # 10 convert string to integer
print(int(10.98)) # 10 convert floating point numbers to integers
print(int(True)) # The Boolean value True is converted to an integer of 1
print(int(False)) # The Boolean value False of 0 is converted to an integer of 0
# The conversion will fail in the following two cases
'''
123.456 And 12 ab Strings contain illegal characters and cannot be converted into integers. An error will be reported
print(int("123.456"))
print(int("12ab"))
'''
Convert to floating point number
f1 = float("12.34")
print(f1) # 12.34
print(type(f1)) # float converts the string "12.34" to a floating point number 12.34
f2 = float(23)
print(f2) # 23.0
print(type(f2)) # float converts an integer to a floating point number
Convert to string
str1 = str(45) str2 = str(34.56) str3 = str(True) print(type(str1),type(str2),type(str3))
Convert to Boolean
print(bool('')) # False
print(bool("")) # False
print(bool(0)) # False
print(bool({})) # False
print(bool([])) # False
print(bool(())) # False
8. Operator
8.1 arithmetic operators
| Arithmetic operator | describe | Example (a = 10, B = 20) |
|---|---|---|
| + | plus | Adding two objects a + b outputs the result 30 |
| - | reduce | Get a negative number or subtract one number from another a - b output - 10 |
| * | ride | Multiply two numbers or return a string a * b repeated several times, and output the result 200 |
| / | except | b / a output result 2 |
| // | to be divisible by | Return the integer part of quotient 9 / / 2 output result 4, 9.0 / / 2.0 output result 4.0 |
| % | Surplus | Return the remainder of Division B% a output result 0 |
| ** | index | a**b is the 20th power of 10 |
| () | parentheses | Increase the operation priority, such as: (1 + 2) * 3 |
# Note: during mixed operation, the priority order is: * * higher than * /% / / higher than + -. In order to avoid ambiguity, it is recommended to use () to handle the operator priority. Moreover, when different types of numbers are mixed, integers will be converted into floating-point numbers for operation. >>> 10 + 5.5 * 2 21.0 >>> (10 + 5.5) * 2 31.0 # If two strings are added, the two strings will be directly spliced into a string. In [1]: str1 ='hello' In [2]: str2 = ' world' In [3]: str1+str2 Out[3]: 'hello world' # If you add numbers and strings, an error will be reported directly. In [1]: str1 = 'hello' In [2]: a = 2 In [3]: a+str1 --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-3-993727a2aa69> in <module> ----> 1 a+str1 TypeError: unsupported operand type(s) for +: 'int' and 'str' # If you multiply a number and a string, the string will be repeated multiple times. In [4]: str1 = 'hello' In [5]: str1*10 Out[5]: 'hellohellohellohellohellohellohellohellohellohello'
8.2 assignment operators
| Assignment Operators | describe | Example |
|---|---|---|
| = | Assignment Operators | Assign the result on the right of the = sign to the variable on the left, such as num = 1 + 2 * 3, and the value of the result num is 7 |
| compound assignment operators | describe | Example |
|---|---|---|
| += | Additive assignment operator | c += a is equivalent to c = c + a |
| -= | Subtraction assignment operator | c -= a is equivalent to c = c - a |
| *= | Multiplication assignment operator | c *= a is equivalent to c = c * a |
| /= | Division assignment operator | c /= a is equivalent to c = c / a |
| //= | Integer division assignment operator | c //= a is equivalent to c = c // a |
| %= | Modulo assignment operator | C% = a is equivalent to C = C% a |
| **= | Power assignment operator | c **= a is equivalent to c = c ** a |
# Single variable assignment >>> num = 10 >>> num 10 # Assign values to multiple variables at the same time (connect with equal sign) >>> a = b = 4 >>> a 4 >>> b 4 >>> # Multiple variable assignments (separated by commas) >>> num1, f1, str1 = 100, 3.14, "hello" >>> num1 100 >>> f1 3.14 >>> str1 "hello" # Example:+= >>> a = 100 >>> a += 1 # Equivalent to performing a = a + 1 >>> a 101 # Example:*= >>> a = 100 >>> a *= 2 # Equivalent to performing a = a * 2 >>> a 200 # Example: * =, during operation, the expression on the right side of the symbol calculates the result first, and then operates with the value of the variable on the left >>> a = 100 >>> a *= 1 + 2 # Equivalent to executing a = a * (1+2) >>> a 300
8.3 comparison operators
<>: Python version 3.x does not support <>, use != Instead, python version 2 supports < >, python version 3 no longer supports < >, use= Replace.
For all comparison operators, 1 means True and 0 means False, which are equivalent to the special variables True and False respectively.
| Comparison operator | describe | Example (a=10,b=20) |
|---|---|---|
| == | Equal: whether the comparison objects are equal | (a == b) returns False |
| != | Not equal: compares whether two objects are not equal | (a! = b) returns True |
| > | Greater than: Returns whether x is greater than y | (a > b) returns False |
| >= | Greater than or equal to: Returns whether x is greater than or equal to y | (a > = b) returns False |
| < | Less than: Returns whether x is less than y | (a < b) returns True |
| <= | Less than or equal to: Returns whether x is less than or equal to y | (a < = b) return True |
8.4 logical operators
| Logical operator | expression | describe | Example |
|---|---|---|---|
| and | x and y | As long as one operand is False, the result is False; The result is True only if all operands are True If the front is False, it will not be executed later (short circuit and) | True and False – > the result is False True and True and True – > the result is true |
| or | x or y | As long as one operand is True, the result is True; The result is False only if all operands are False If the front is True, the back is not executed (short circuit or) | False or False or True – > the result is True False or False or False – > the result is false |
| not | not x | Boolean not - Returns False if x is True. If x is False, it returns True. | not True --> False |
9. Input and output
9.1 output
Normal output:
print('xxx')
Format output:
# %s: Representative string% d: representative value
age = 18
name = "admin"
print("My name is%s, Age is%d" % (name, age))
9.2 input
In Python, the method to get the data entered by the keyboard is to use the input function
- In the parentheses of input(), the prompt information is used to give a simple prompt to the user before obtaining the data
- After obtaining data from the keyboard, input() will be stored in the variable to the right of the equal sign
- input() treats any value entered by the user as a string
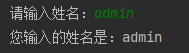
name = input("Please enter your name:")
print('The name you entered is:%s' % name)
10. Process control statement
10.1 if conditional judgment statement
# ① Single if statement
if Judgment conditions:
When the condition holds, execute the statement
# For example:
age = 16
if age >= 18:
print("Grow up")
# ② If else statement
if Judgment conditions:
If the condition holds, execute the statement
else:
If the condition does not hold, execute the statement
# For example:
height = input('Please enter your height(cm): \n')
if int(height) <= 150:
print('Free tickets for Science Park')
else:
print('I need to buy a ticket')
# ③ elif statement
if Judgment condition 1:
If condition 1 is true, execute the statement
elif Judgment condition 2:
If condition 2 is true, execute the statement
elif Judgment condition 3:
If condition 3 is true, execute the statement
elif Judgment conditions n:
condition n Yes, execute the statement
# For example:
score = 77
if score>=140:
print('The result is A')
elif score>=130:
print('The result is B')
elif score>=120:
print('The result is C')
elif score>=100:
print('The result is D')
elif score<90:
print('The result is E')
10.2 for cycle
# for loop
for Temporary variable in Iteratable objects such as lists, strings, etc:
Circulatory body
# For example:
name = 'admin'
for i in name:
print(i)
# range(x): [0,x)
for i in range(3):
print(i) # 0 1 2
# range(a,b): [a,b)
for i in range(2, 5):
print(i) # 2 3 4
# Range of range(a,b,c): [a, b], C is the step size, and within this range, it is increased according to the step value
for i in range(2, 10, 3):
print(i) # 2 5 8
11. Data type
11.1 string
Common methods / functions in strings
| Method / function | describe |
|---|---|
| len() | Gets the length of the string |
| find() | Finds whether the specified content exists in the string. If it exists, it returns the start position index value of the content for the first time in the string. If it does not exist, it returns - 1 |
| startswith()/endswith | Judge whether the string starts / ends with who |
| count() | Returns the number of occurrences of subStr in objectStr between start and end |
| replace() | Replace the content specified in the string. If count is specified, the replacement will not exceed count |
| split() | Cut the string by the content of the parameter |
| upper()/lower() | Convert case |
| strip() | Remove spaces around the string |
| join() | String splicing |
str1 = ' Administrators '
print(len(str1)) # 18
print(str1.find('d')) # 3
print(str1.startswith('a')) # False
print(str1.endswith('s')) # False
print(str1.count('s')) # 2
print(str1.replace('s', '', 1)) # Adminitrators
print(str1.split('n')) # [' Admi', 'istrators ']
print(str1.upper()) # ADMINISTRATORS
print(str1.lower()) # administrators
print(str1.strip()) # Administrators
print(str1.join('admin')) # a Administrators d Administrators m Administrators i Administrators n
11.2 list
Addition, deletion, modification and query of list
| Add element | describe |
|---|---|
| append() | Append a new element to the end of the list |
| insert() | Inserts a new element at the specified index location |
| extend() | Append all elements of a new list to the end of the list |
# Add element
name_list = ['zhang', 'cheng', 'wang', 'li', 'liu']
print(name_list) # ['zhang', 'cheng', 'wang', 'li', 'liu']
name_list.append('tang')
print(name_list) # ['zhang', 'cheng', 'wang', 'li', 'liu', 'tang']
name_list.insert(2, 'su')
print(name_list) # ['zhang', 'cheng', 'su', 'wang', 'li', 'liu', 'tang']
subName = ['lin', 'qing', 'xue']
name_list.extend(subName)
print(name_list) # ['zhang', 'cheng', 'su', 'wang', 'li', 'liu', 'tang', 'lin', 'qing', 'xue']'xue']
| Modify element | describe |
|---|---|
| list[index] = modifyValue | Modify a list element by specifying a subscript assignment |
# Modify element name_list[0] = 'zhao' print(name_list) # ['zhao', 'cheng', 'su', 'wang', 'li', 'liu', 'tang', 'lin', 'qing', 'xue']
| Find element | describe |
|---|---|
| in | Judge whether it exists. If it exists, the result is true; otherwise, it is false |
| not in | Judge whether it does not exist. If it does not exist, the result is true; otherwise, it is false |
# Find element
findName = 'li'
# In the list ['zhao ',' Cheng ',' Su ',' Wang ',' li ',' Liu ',' Tang ',' Lin ',' Qing ',' Xue '], the last name is found: li
if findName in nameList:
print('In list %s Last name found in:%s' % (nameList, findName))
else:
print('In list %s Last name is not found in:%s' % (nameList, findName))
findName1 = 'qian'
# In the list ['zhao ',' Cheng ',' Su ',' Wang ',' Li ',' Liu ',' Tang ',' Lin ',' Qing ',' Xue '], the last name is not found: qian
if findName1 not in nameList:
print('In list %s Last name is not found in:%s' % (nameList, findName1))
else:
print('In list %s Last name found in:%s' % (nameList, findName1))
| Delete element | describe |
|---|---|
| del | Delete by subscript |
| pop() | The last element is deleted by default |
| remove | Delete according to the value of the element |
# Delete element
print(nameList) # ['zhao', 'cheng', 'su', 'wang', 'li', 'liu', 'tang', 'lin', 'qing', 'xue']
# del nameList[1] # Deletes the element of the specified index
# print(nameList) # ['zhao', 'su', 'wang', 'li', 'liu', 'tang', 'lin', 'qing', 'xue']
# nameList.pop() # Default output last element
# print(nameList) # ['zhao', 'cheng', 'su', 'wang', 'li', 'liu', 'tang', 'lin', 'qing']
# nameList.pop(3) # Deletes the element of the specified index
# print(nameList) # ['zhao', 'cheng', 'su', 'li', 'liu', 'tang', 'lin', 'qing', 'xue']
nameList.remove('zhao') # Deletes the element with the specified element value
print(nameList) # ['cheng', 'su', 'wang', 'li', 'liu', 'tang', 'lin', 'qing', 'xue']
11.3 tuples
Python tuples are similar to lists, except that the element data of tuples cannot be modified, while the element data of lists can be modified. Tuples use parentheses and lists use brackets.
# tuple
nameTuple = ('zhang', 'cheng', 'wang', 'li', 'liu')
print(nameTuple) # ('zhang', 'cheng', 'wang', 'li', 'liu')
# nameTuple[3] = 'su' # Tuples cannot modify the value of elements inside
# print(nameTuple) # TypeError: 'tuple' object does not support item assignment
ageInt = (16) # If you do not write a comma, it is of type int
print(ageInt, type(ageInt)) # 16 <class 'int'>
ageTuple = (17,) # To define a tuple with only one element, you need to write a comma after the unique element
print(ageTuple, type(ageTuple)) # (17,) <class 'tuple'>
11.4 slicing
Slicing refers to the operation of intercepting part of the operated object. String, list and tuple all support slicing.
Slicing syntax
# The interval of slice (start index, end index), and the step size represents the slice interval. Slice is no different from interception. Note that it is a left closed and right open interval [Start index:End index:step] # Intercept the index from the start index to the end index in a specified step [Start index:End index] # The default step size is 1, which can simplify not writing
# section str_slice = 'Hello World!' # The slice follows the left closed right open interval, cutting the left without cutting the right print(str_slice[2:]) # llo World! print(str_slice[0:5]) # Hello print(str_slice[2:9:2]) # loWr print(str_slice[:8]) # Hello Wo
11.5 dictionary
Addition, deletion and modification of dictionary
Use key to find data and get() to get data
| View element | describe |
|---|---|
| dictionaryName['key'] | Specify the key to find the corresponding value value, access the nonexistent key, and an error is reported |
| dictionaryName.get('key') | Use its get('key ') method to obtain the value value corresponding to the key, access the nonexistent key and return None |
# View element
personDictionary = {'name': 'King', 'age': 16}
print(personDictionary) # {'name': 'King', 'age': 16}
print(personDictionary['name'], personDictionary['age']) # King 16
# print(personDictionary['noExistKey']) # KeyError: 'noExistKey', the key is specified in square brackets. If you access a nonexistent key, an error will be reported
print(personDictionary.get('name')) # King
print(personDictionary.get('noExistKey')) # None, access the nonexistent key in the form of get(), and return none without error
| Modify element | describe |
|---|---|
| dictionaryName['key'] = modifiedValue | Assign the new value to the value of the key to be modified |
# Modify element
petDictionary = {'name': 'glory', 'age': 17}
print(petDictionary) # {'name': 'Glory', 'age': 17}
petDictionary['age'] = 18
print(petDictionary) # {'name': 'Glory', 'age': 18}
| Add element | describe |
|---|---|
| dictionaryName['key'] = newValue | When using variable name ['key'] = data, this "key" does not exist in the dictionary, so this element is added |
# Add element
musicDictionary = {'name': 'Netease', 'age': 19}
print(musicDictionary) # {'name': 'Netease', 'age': 19}
# musicDictionary['music'] = 'xxx' # When the key does not exist, add an element
# print(musicDictionary) # {'name': 'Netease', 'age': 19, 'music': 'xxx'}
musicDictionary['age'] = '20' # Overwrite element when key exists
print(musicDictionary) # {'name': 'Netease', 'age': '20'}
| Delete element | describe |
|---|---|
| del | Deletes a specified element or the entire dictionary |
| clear() | Empty the dictionary and keep the dictionary object |
# Delete element
carDictionary = {'name': 'bmw', 'age': 20}
print(carDictionary) # {'name': 'BMW', 'age': 20}
# del carDictionary['age'] # Delete the element of the specified key
# print(carDictionary) # {'name': 'BMW'}
# del carDictionary # Delete entire dictionary
# print(carDictionary) # NameError: name 'xxx' is not defined. The dictionary has been deleted, so it will report undefined
carDictionary.clear() # Empty dictionary
print(carDictionary) # {}
| Traversal element | describe |
|---|---|
| for key in dict.keys(): print(key) | key to traverse the dictionary |
| for value in dict.values(): print(value) | Traverse the value of the dictionary |
| for key,value in dict.items(): print(key,value) | Traverse the key value (key value pair) of the dictionary |
| for item in dict.items(): print(item) | Traverse the element/item of the dictionary |
# Traversal element
airDictionary = {'name': 'aviation', 'age': 21}
# key traversing dictionary
# for key in airDictionary.keys():
# print(key) # name age
# Traverse the value of the dictionary
# for value in airDictionary.values():
# print(value) # Aviation 21
# Traverse the key value of the dictionary
# for key, value in airDictionary.items():
# print(key, value) # name aviation 21
# Traverse the item/element of the dictionary
for item in airDictionary.items():
print(item) # ('name ',' aviation ') ('age', 21)
12. Function
12.1 defining functions
format
# Define a function. After defining a function, the function will not be executed automatically. You need to call it
def Function name():
Method body
code
# Define function
def f1():
print('After the function is defined, the function will not be executed automatically. You need to call it')
12.2 calling functions
format
# Call function Function name()
code
# Call function f1()
12.3 function parameters
Formal parameter: defines the parameters in parentheses of the function, which are used to receive the parameters of the calling function.
Argument: the parameter in parentheses of the calling function, which is used to pass to the parameter defining the function.
12.3.1 position transfer (sequential transfer)
Transfer parameters according to the one-to-one correspondence of parameter position order
format
# Define functions with parameters
def Function name(arg1,arg2,...):
Method body
# Calling a function with parameters
Function name(arg1,arg2,...)
code
# Define functions with parameters
def sum_number(a, b):
c = a + b
print(c)
# Calling a function with parameters
sum_number(10, 6)
12.3.2 keyword parameter transfer (non sequential parameter transfer)
Pass the parameters in the specified parameter order
format
# Define functions with parameters
def Function name(arg1,arg2,...):
Method body
# Calling a function with parameters
Function name(arg2=xxx,arg1=xxx,...)
code
# Define functions with parameters
def sum_number(a, b):
c = a + b
print(c)
# Calling a function with parameters
sum_number(b=6, a=10)
12.4 function return value
Return value: the result returned to the caller after the function in the program completes one thing
format
# Define a function with a return value
def Function name():
return Return value
# Receive function with return value
recipient = Function name()
# Use results
print(recipient)
code
# Define a function with a return value
def pay_salary(salary, bonus):
return salary + bonus * 16
# Receive function with return value
receive_salary = pay_salary(1000000, 100000)
print(receive_salary)
13. Local and global variables
13.1 local variables
Local variable: a variable defined inside a function and on a function parameter.
Scope of local variable: used inside the function (not outside the function).
# local variable
def partial_variable(var1, var2):
var3 = var1 + var2
var4 = 15
return var3 + var4
local_variable = partial_variable(12, 13)
print(local_variable)
13.2 global variables
Global variables: variables defined outside the function.
Scope of global variables: both internal and external functions can be used
# global variable
globalVariable = 100
def global_variable(var1, var2):
return var1 + var2 + globalVariable
global_var = global_variable(10, 20)
print(global_var, globalVariable)
14. Documentation
14.1 opening and closing of documents
Open / create file: in python, you can use the open() function to open an existing file or create a new file open (file path, access mode)
Close file: close() function
Absolute path: absolute position, which completely describes the location of the target, and all directory hierarchical relationships are clear at a glance.
Relative path: relative position, the path starting from the folder (directory) where the current file is located.
Access mode: r, w, a
| Access mode | describe |
|---|---|
| r | Open the file as read-only. The pointer to the file is placed at the beginning of the file. If the file does not exist, an error is reported. This is the default mode. |
| w | Open a file for writing only. If the file already exists, overwrite it. If the file does not exist, create a new file. |
| a | Open a file for append. If the file already exists, the file pointer will be placed at the end of the file. That is, the new content will be written after the existing content. If the file does not exist, create a new file for writing. |
| r+ | Open a file for reading and writing. The file pointer will be placed at the beginning of the file. |
| w+ | Open a file for reading and writing. If the file already exists, overwrite it. If the file does not exist, create a new file. |
| a+ | Open a file for reading and writing. If the file already exists, the file pointer will be placed at the end of the file. The file is opened in append mode. If the file does not exist, create a new file for reading and writing. |
| rb | Open a file in binary format for read-only. The file pointer will be placed at the beginning of the file. |
| wb | Open a file in binary format for writing only. If the file already exists, overwrite it. If the file does not exist, create a new file. |
| ab | Open a file in binary format for append. If the file already exists, the file pointer will be placed at the end of the file. That is, the new content will be written after the existing content. If the file does not exist, create a new file for writing. |
| rb+ | Open a file in binary format for reading and writing. The file pointer will be placed at the beginning of the file. |
| wb+ | Open a file in binary format for reading and writing. If the file already exists, overwrite it. If the file does not exist, create a new file. |
| ab+ | Open a file in binary format for reading and writing. If the file already exists, the file pointer will be placed at the end of the file. If the file does not exist, create a new file for reading and writing. |
# Create a file open (file path, access mode)
testFile = open('file/test.txt', 'w', encoding='utf-8')
testFile.write('Write file contents')
# Close the document [suggestion]
testFile.close()
14.2 reading and writing of documents
14.2.1 write data
Write data: write() can write data to a file. If the file does not exist, create it; If it exists, empty the file first and then write data
# Write data
writeFile = open('file/write.txt', 'w', encoding='utf-8')
writeFile.write('Write file data\n' * 5)
writeFile.close()
14.2.2 data reading
Read data: read(num) can read data from the file. Num indicates the length of the data to be read from the file (in bytes). If num is not passed in, it means to read all the data in the file
# Read data
readFile = open('file/write.txt', 'r', encoding='utf-8')
# readFileCount = readFile.read() # By default, read one byte by one, and read all data of the file
# readFileCount1 = readFile.readline() # Read line by line, only one line of data of the file can be read
readFileCount2 = readFile.readlines() # Read by line, read all data of the file, and return all data in the form of a list. The elements of the list are data line by line
print(readFileCount2)
readFile.close()
14.3 file serialization and deserialization
Through file operation, we can write strings to a local file. However, if it is an object (such as list, dictionary, tuple, etc.), it cannot be written directly to a file. The object needs to be serialized before it can be written to the file.
Serialization: convert data (objects) in memory into byte sequences, so as to save them to files or network transmission. (object – > byte sequence)
Deserialization: restore the byte sequence to memory and rebuild the object. (byte sequence – > object)
The core of serialization and deserialization: the preservation and reconstruction of object state.
Python provides JSON modules to serialize and deserialize data.
JSON module
JSON (JavaScript object notation) is a lightweight data exchange standard. JSON is essentially a string.
Serialization using JSON
JSON provides dumps and dump methods to serialize an object.
Deserialization using JSON
Using the loads and load methods, you can deserialize a JSON string into a Python object.
14.3.1 serialization
dumps(): converts an object into a string. It does not have the function of writing data to a file.
import json
# Serialization ① dumps()
serializationFile = open('file/serialization1.txt', 'w', encoding='utf-8')
name_list = ['admin', 'administrator', 'administrators']
names = json.dumps(name_list)
serializationFile.write(names)
serializationFile.close()
dump(): specify a file object while converting the object into a string, and write the converted String to this file.
import json
# Serialization ② dump()
serializationFile = open('file/serialization2.txt', 'w', encoding='utf-8')
name_list = ['admin', 'administrator', 'administrators']
json.dump(name_list, serializationFile) # This is equivalent to the two steps of dumps() and write() combined
serializationFile.close()
14.3.2 deserialization
loads(): a string parameter is required to load a string into a Python object.
import json
# Deserialization ① loads()
serializationFile = open('file/serialization1.txt', 'r', encoding='utf-8')
serializationFileContent = serializationFile.read()
deserialization = json.loads(serializationFileContent)
print(deserialization, type(serializationFileContent), type(deserialization))
serializationFile.close()
load(): you can pass in a file object to load the data in a file object into a Python object.
import json
# Deserialization ② load()
serializationFile = open('file/serialization2.txt', 'r', encoding='utf-8')
deserialization = json.load(serializationFile) # It is equivalent to two steps of combined loads() and read()
print(deserialization, type(deserialization))
serializationFile.close()
15. Abnormal
During the running process of the program, our program cannot continue to run due to non-standard coding or other objective reasons. At this time, the program will be abnormal. If we do not handle exceptions, the program may be interrupted directly due to exceptions. In order to ensure the robustness of the program, the concept of exception handling is proposed in the program design.
15.1 try... except statement
The try... except statement can handle exceptions that may occur during code running.
Syntax structure:
try: A block of code where an exception may occur except Type of exception: Processing statement after exception
# Example:
try:
fileNotFound = open('file/fileNotFound.txt', 'r', encoding='utf-8')
fileNotFound.read()
except FileNotFoundError:
print('The system is being upgraded. Please try again later...')
2,Urllib
1. Internet crawler
1.1 introduction to reptiles
If the Internet is compared to a large spider network, the data on a computer is a prey on the spider network, and the crawler program is a small spider that grabs the data you want along the spider network.
Explanation 1: through a program, according to Url (e.g.: http://www.taobao.com )Crawl the web page to get useful information.
Explanation 2: use the program to simulate the browser to send a request to the server and obtain the response information

1.2 reptile core
- Crawl web page: crawl the entire web page, including all the contents in the web page
- Analyze data: analyze the data you get in the web page
- Difficulty: game between reptile and anti reptile
1.3 use of reptiles
-
Data analysis / manual data set
-
Social software cold start
-
Public opinion monitoring
-
Competitor monitoring, etc
-
List item
1.4 classification of reptiles
1.4.1 universal crawler
Example: Baidu, 360, google, sougou and other search engines - Bole Online
Functions: accessing web pages - > fetching data - > data storage - > Data Processing - > providing retrieval services
Robots protocol: a conventional protocol. Add robots.txt file to specify what content of this website can not be captured and can not play a restrictive role. Crawlers written by themselves do not need to abide by it.
Website ranking (SEO):
- Rank according to pagerank algorithm value (refer to website traffic, click through rate and other indicators)
- Competitive ranking (whoever gives more money will rank first)
Disadvantages:
- Most of the captured data is useless
- Unable to accurately obtain data according to the needs of users
1.4.2 focused reptiles
Function: implement the crawler program and grab the required data according to the requirements
Design idea:
- Determine the Url to crawl (how to get the Url)
- Simulate the browser accessing the url through http protocol to obtain the html code returned by the server (how to access it)
- Parse html string (extract the required data according to certain rules) (how to parse)
1.5 anti climbing means
1.5.1 User-Agent
The Chinese name of User Agent is User Agent, or UA for short. It is a special string header that enables the server to identify the operating system and version, CPU type, browser and version, browser rendering engine, browser language, browser plug-in, etc.
1.5.2 proxy IP
-
Xici agency
-
Fast agent
Anonymity, high anonymity, transparent proxy and the differences between them
-
Using a transparent proxy, the other server can know that you have used the proxy and your real IP.
-
Using anonymous proxy, the other server can know that you have used the proxy, but does not know your real IP.
-
Using high anonymous proxy, the other server does not know that you use the proxy, let alone your real IP.
1.5.3 verification code access
- Coding platform
- Cloud coding platform
- super 🦅
1.5.4 dynamically loading web pages
The website returns other js data, not the real data of the web page
selenium drives real browsers to send requests
1.5.5 data encryption
Analyze js code
2. Use of urllib Library
urllib.request.urlopen(): simulate the browser to send a request to the server
1 type and 6 methods
- Response: the data returned by the server. The data type of response is HttpResponse
- decode: byte – > string
- Encoding: string – > bytes
- read(): read binary in byte form, red (Num): return the first num bytes
- readline(): read one line
- readlines(): read line by line until the end
- getcode(): get the status code
- geturl(): get url
- getheaders(): get headers
import urllib.request url = "http://www.baidu.com" response = urllib.request.urlopen(url) # 1 type and 6 methods # ① The data type of response is HttpResponse # print(type(response)) # <class 'http.client.HTTPResponse'> # ① read(): read byte by byte # content = response.read() # Low efficiency # content = response.read(10) # Returns the first 10 bytes # print(content) # ② readline(): read one line # content = response.readline() # Read one line # print(content) # ③ readlines(): read line by line until the end # content = response.readlines() # Read line by line until the end # print(content) # ④ getcode(): get the status code # statusCode = response.getcode() # Return to 200, that is OK! # print(statusCode) # ⑤ geturl(): returns the url address of the access # urlAddress = response.geturl() # print(urlAddress) # ⑥ getheaders(): get request headers getHeaders = response.getheaders() print(getHeaders)
urllib.request.urlretrieve(): copy (download) the network object represented by the URL to the local file
- Request web page
- Request picture
- Request video
import urllib.request url_page = 'http://www.baidu.com' # url: download path, filename: file name # Request web page # urllib.request.urlretrieve(url_page, 'image.baidu.html') # Download pictures # url_img = 'https://img2.baidu.com/it/u=3331290673,4293610403&fm=26&fmt=auto&gp=0.jpg' # urllib.request.urlretrieve(url_img, '0.jpg') # Download Video url_video = 'https://vd4.bdstatic.com/mda-kev64a3rn81zh6nu/hd/mda-kev64a3rn81zh6nu.mp4?v_from_s=hkapp-haokan-hna&auth_key=1631450481-0-0-e86278b3dbe23f6324c929891a9d47cc&bcevod_channel=searchbox_feed&pd=1&pt=3&abtest=3000185_2' urllib.request.urlretrieve(url_video, 'Frozen.mp4')
3. Customization of request object
Purpose: in order to solve the first method of anti crawling, if the crawling request information is incomplete, the customization of the request object is used
Introduction to UA: the Chinese name of User Agent is User Agent, or UA for short. It is a special string header that enables the server to identify the operating system and version, CPU type, browser and version used by the customer. Browser kernel, browser rendering engine, browser language, browser plug-in, etc.
Syntax: request = urllib.request.Request()
import urllib.request
url = 'https://www.baidu.com'
# Composition of url
# For example: https://www.baidu.com/s?ie=utf -8&f=8&rsv_ BP = 1 & TN = Baidu & WD = rat Laibao & RSV_ pq=a1dbf18f0000558d&rsv_ t=076ebVS%2BfOJbuqzKTEC4L%2FtOXZ5BxqzbgdFwHDGl8vEpGmeM5%2BKSr6Owpjk&rqlang=cn&rsv_ enter=1&rsv_ dl=tb&rsv_ sug3=13&rsv_ sug1=11&rsv_ sug7=100&rsv_ sug2=0&rsv_ btype=t&inputT=3568&rsv_ sug4=3568
# Protocol: http/https (https is more secure with SSL)
# Host (domain name): www.baidu.com
# Port number (default): http (80), https (443), mysql (3306), oracle (1521), redis (6379), mongodb (27017)
# Path: s
# Parameters: ie=utf-8, f=8, wd = rat Laibao
# Anchor point:#
# Problem: the requested information is incomplete -- UA anti crawl
# Solution -- disguise the complete request header information
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'}
# Because the dictionary cannot be stored in urlopen(), headers cannot be passed in
# Customization of request object
# Check the Request() source code: because of the order of the parameters passed, you can't write the url and headers directly. There is a data parameter in the middle, so you need to pass the parameters by keyword
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
Evolution of coding set
Because the computer was invented by Americans, only 127 characters were encoded into the computer at first, that is, upper and lower case English letters, numbers and some symbols. This coding table is called ASCII coding. For example, the coding of capital letter A is 65 and the coding of lower case letter z is 122. However, it is obvious that one byte is not enough to deal with Chinese, at least two bytes are required, and it can not conflict with ASCII coding. Therefore, China has formulated GB2312 coding to encode Chinese.
Imagine that there are hundreds of languages all over the world. Japan compiles Japanese into English_ In JIS, South Korea compiles Korean into EUC Kr. If countries have national standards, there will inevitably be conflicts. As a result, there will be garbled codes in multilingual mixed texts.
Therefore, Unicode came into being. Unicode unifies all languages into one set of codes, so that there will be no more random code problems. The Unicode standard is also evolving, but the most commonly used is to represent a character with two bytes (four bytes are required if very remote characters are used). Modern operating systems and most programming languages support Unicode directly.
4. Encoding and decoding
4.1 get request method
4.1.1 urllib.parse.quote()
import urllib.request
# url to visit
url = 'https://www.baidu.com/s?ie=UTF-8&wd='
# The customization of request object is the first method to solve anti crawling
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'}
# Parsing Chinese characters into unicode encoding format depends on urllib.parse
words = urllib.parse.quote('Frozen')
# The url should be spliced
url = url + words
# Customization of request object
request = urllib.request.Request(url=url, headers=headers)
# Impersonate the browser to send a request to the server
response = urllib.request.urlopen(request)
# Get the content of the response
content = response.read().decode('utf-8')
# print data
print(content)
4.1.2 urllib.parse.urlencode()
import urllib.parse
import urllib.request
# urlencode() application scenario: when the url has multiple parameters
# url source code: https://www.baidu.com/s?ie=UTF -8&wd=%E5%86%B0%E9%9B%AA%E5%A5%87%E7%BC%98&type=%E7%94%B5%E5%BD%B1
# url decoding: https://www.baidu.com/s?ie=UTF -8 & WD = snow and Ice & type = movie
base_url = 'https://www.baidu.com/s?ie=UTF-8&'
data = {'wd': 'Frozen', 'type': 'film'}
urlEncode = urllib.parse.urlencode(data)
url = base_url + urlEncode
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
4.2 post request mode
1.post request Baidu translation
import json
import urllib.parse
import urllib.request
# post request Baidu translation
# Browser general -- > request URL:
# url = 'https://translate.google.cn/_/TranslateWebserverUi/data/batchexecute?rpcids=MkEWBc&f.sid=2416072318234288891&bl=boq_translate-webserver_20210908.10_p0&hl=zh-CN&soc-app=1&soc-platform=1&soc-device=1&_reqid=981856&rt=c'
url = 'https://fanyi.baidu.com/v2transapi?from=en&to=zh'
# Browser request headers -- > User Agent:
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'}
# Browser From Data (data in the form of key value. Note: if there are characters such as: \ in the browser data, you need to escape when copying to pychar, and remember to add one more \)
# Example: browser From Data: f.req: [[["mkewbc", [[\ "spider \", \ "auto \", \ "zh cn \", true], [null]], null, "generic"]]]
# data = {'f.req': '[[["MkEWBc","[[\\"Spider\\",\\"auto\\",\\"zh-CN\\",true],[null]]",null,"generic"]]]'}
data = {'query': 'Spider'}
# The parameters of the post request must be decoded. data = urllib.parse.urlencode(data)
# After encoding, you must call the encode() method data = urllib.parse.urlencode(data).encode('utf-8 ')
data = urllib.parse.urlencode(data).encode('utf-8')
# The parameter is placed in the method customized by the request object. request = urllib.request.Request(url=url, data=data, headers=headers)
request = urllib.request.Request(url=url, data=data, headers=headers)
# Impersonate the browser to send a request to the server
response = urllib.request.urlopen(request)
# Get response data
content = response.read().decode('utf-8')
# # print data
print(content)
# String -- > JSON object
jsonObjContent = json.loads(content)
print(jsonObjContent)
Summary:
Difference between post and get
- The parameters of the get request method must be encoded. The parameters are spliced behind the url. After encoding, you do not need to call the encode method
- The parameters of the post request method must be encoded. The parameters are placed in the method customized by the request object. After encoding, you need to call the encode method
2.post requests Baidu to translate in detail and anti crawl – > cookie (plays a decisive role) to solve
import json
import urllib.parse
import urllib.request
# post request Baidu translation's anti crawling Cookie (plays a decisive role)
# Browser general -- > request URL:
# url = 'https://translate.google.cn/_/TranslateWebserverUi/data/batchexecute?rpcids=MkEWBc&f.sid=2416072318234288891&bl=boq_translate-webserver_20210908.10_p0&hl=zh-CN&soc-app=1&soc-platform=1&soc-device=1&_reqid=981856&rt=c'
url = 'https://fanyi.baidu.com/v2transapi?from=en&to=zh'
# Browser request headers -- > User Agent:
# headers = {
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'
# }
headers = {
# 'Accept': '*/*',
# 'Accept-Encoding': 'gzip, deflate, br', # Be sure to annotate this sentence
# 'Accept-Language': 'en-GB,en-US;q=0.9,en;q=0.8,zh-CN;q=0.7,zh;q=0.6',
# 'Connection': 'keep-alive',
# 'Content-Length': '137',
# 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie': 'BIDUPSID=7881F5C444234A44A8A135144C7277E2; PSTM=1631452046; BAIDUID=7881F5C444234A44B6D4E05D781C0A89:FG=1; H_PS_PSSID=34442_34144_34552_33848_34524_34584_34092_34576_26350_34427_34557; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; delPer=0; PSINO=6; BAIDUID_BFESS=7881F5C444234A44B6D4E05D781C0A89:FG=1; BA_HECTOR=0k0h2h8g040l8hag8k1gjs8h50q; BCLID=7244537998497862517; BDSFRCVID=XrFOJexroG0YyvRHhm4AMZOfDuweG7bTDYLEOwXPsp3LGJLVJeC6EG0Pts1-dEu-EHtdogKK3gOTH4DF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF=tR3aQ5rtKRTffjrnhPF3KJ0fXP6-hnjy3bRkX4nvWnnVMhjEWxntQbLWbttf5q3RymJJ2-39LPO2hpRjyxv4y4Ldj4oxJpOJ-bCL0p5aHl51fbbvbURvDP-g3-AJ0U5dtjTO2bc_5KnlfMQ_bf--QfbQ0hOhqP-jBRIEoCvt-5rDHJTg5DTjhPrMWh5lWMT-MTryKKJwM4QCObnzjMQYWx4EQhofKx-fKHnRhlRNB-3iV-OxDUvnyxAZyxomtfQxtNRJQKDE5p5hKq5S5-OobUPUDUJ9LUkJ3gcdot5yBbc8eIna5hjkbfJBQttjQn3hfIkj2CKLK-oj-D8RDjA23e; BCLID_BFESS=7244537998497862517; BDSFRCVID_BFESS=XrFOJexroG0YyvRHhm4AMZOfDuweG7bTDYLEOwXPsp3LGJLVJeC6EG0Pts1-dEu-EHtdogKK3gOTH4DF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF_BFESS=tR3aQ5rtKRTffjrnhPF3KJ0fXP6-hnjy3bRkX4nvWnnVMhjEWxntQbLWbttf5q3RymJJ2-39LPO2hpRjyxv4y4Ldj4oxJpOJ-bCL0p5aHl51fbbvbURvDP-g3-AJ0U5dtjTO2bc_5KnlfMQ_bf--QfbQ0hOhqP-jBRIEoCvt-5rDHJTg5DTjhPrMWh5lWMT-MTryKKJwM4QCObnzjMQYWx4EQhofKx-fKHnRhlRNB-3iV-OxDUvnyxAZyxomtfQxtNRJQKDE5p5hKq5S5-OobUPUDUJ9LUkJ3gcdot5yBbc8eIna5hjkbfJBQttjQn3hfIkj2CKLK-oj-D8RDjA23e; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1631461937; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1631461937; __yjs_duid=1_9333541ca3b081bff2fb5ea3b217edc41631461934213; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; ab_sr=1.0.1_MTZhNGI2ZDNjYmUzYTFjZjMxMmI4YWM3OGU1MTM1Nzc4M2JiN2M0OTE3ZDcyNmEwMzY0MTA3MzI2NzZjMDBjNzczMzExMmQyZGMyOGQ5MjIyYjAyYWIzNjMxMmYzMGVmNWNmNTFkODc5ZTVmZTQzZWFhOGM5YjdmNGVhMzE2OGI3ZDFkMjhjNzAwMDgxMWVjMmYzMmE5ZjAzOTA0NWI4Nw==; __yjs_st=2_ZTZkODNlNThkYTFhZDgwNGQxYjE1Y2VmZTFkMzYxYzIyMzQ3Mjk4ZGM0NWViM2Y0ZDRkMjFiODkxNjQxZDhmMWNjMDA0OTQ0N2I2N2U4ZDdkZDdjNzAxZTZhYWNkYjI5NWIwMWVkMWZlYTMxNzA2ZjI0NjU3MDhjNjU5NDgzYjNjNDRiMDA1ODQ4YTg4NTg0MGJmY2VmNTE0YmEzN2FiMGVkZjUxZDMzY2U3YjIzM2RmNTQ4YThjMzU4NzMxOTBkZmJiMDgzZTIxYjdlMzIxY2M3MjhiNTQ4MGI2ZTI0ODRhMDI4NWI3ZDhhOGFkN2RhNjk2NjI3YzdkN2M5ZmQyN183XzI5ODZkODEz',
# 'Host': 'fanyi.baidu.com',
# 'Origin': 'https://fanyi.baidu.com',
# 'Referer': 'https://fanyi.baidu.com/translate?aldtype=16047&query=Spider&keyfrom=baidu&smartresult=dict&lang=auto2zh',
# 'sec-ch-ua': '"Google Chrome";v="93", " Not;A Brand";v="99", "Chromium";v="93"',
# 'sec-ch-ua-mobile': '?0',
# 'sec-ch-ua-platform': '"Windows"',
# 'Sec-Fetch-Dest': 'empty',
# 'Sec-Fetch-Mode': 'cors',
# 'Sec-Fetch-Site': 'same-origin',
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36',
# 'X-Requested-With': 'XMLHttpRequest',
}
# Browser From Data (data in the form of key value. Note: if there are characters such as: \ in the browser data, you need to escape when copying to pychar, and remember to add one more \)
# Example: browser From Data: f.req: [[["mkewbc", [[\ "spider \", \ "auto \", \ "zh cn \", true], [null]], null, "generic"]]]
# data = {'f.req': '[[["MkEWBc","[[\\"Spider\\",\\"auto\\",\\"zh-CN\\",true],[null]]",null,"generic"]]]'}
data = {'from': 'en', 'to': 'zh', 'query': 'Spider', 'transtype': 'realtime', 'simple_means_flag': '3',
'sign': '579526.799991', 'token': 'e2d3a39e217e299caa519ed2b4c7fcd8', 'domain': 'common'}
# The parameters of the post request must be decoded. data = urllib.parse.urlencode(data)
# After encoding, you must call the encode() method data = urllib.parse.urlencode(data).encode('utf-8 ')
data = urllib.parse.urlencode(data).encode('utf-8')
# The parameter is placed in the method customized by the request object. request = urllib.request.Request(url=url, data=data, headers=headers)
request = urllib.request.Request(url=url, data=data, headers=headers)
# Impersonate the browser to send a request to the server
response = urllib.request.urlopen(request)
# Get response data
content = response.read().decode('utf-8')
# # print data
print(content)
# String -- > JSON object
jsonObjContent = json.loads(content)
print(jsonObjContent)
5. get request of Ajax
Example: Douban movie
Climb the data on the first page of Douban film - ranking list - Costume - and save it
# Climb the data on the first page of Douban film - ranking list - Costume - and save it
# This is a get request
import urllib.request
url = 'https://movie.douban.com/j/chart/top_list?type=30&interval_id=100%3A90&action=&start=0&limit=20'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'
}
# Customization of request object
request = urllib.request.Request(url=url, headers=headers)
# Get response data
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
# Download data locally
# Open() uses gbk encoding by default. If you need to save Chinese, you want to specify UTF-8 encoding format encoding='utf-8 'in open()
# downloadFile = open('file/douban.json', 'w', encoding='utf-8')
# downloadFile.write(content)
# This kind of writing has the same effect
with open('file/douban1.json', 'w', encoding='utf-8') as downloadFile:
downloadFile.write(content)
Climb the data of the first 10 pages of Douban movie - ranking list - Costume - and save it (the costume data is not so much, about 4 pages, not behind, and the data is empty when you climb down)
import urllib.parse
import urllib.request
# Climb the data of the first 10 pages of Douban film - ranking list - Costume - and save it
# This is a get request
# Find regular top_ list?type=30&interval_ id=100%3A90&action=&start=40&limit=20
# Page 1: https://movie.douban.com/j/chart/top_ list?type=30&interval_ id=100%3A90&action=&start=0&limit=20
# Page 2: https://movie.douban.com/j/chart/top_ list?type=30&interval_ id=100%3A90&action=&start=20&limit=20
# Page 3: https://movie.douban.com/j/chart/top_ list?type=30&interval_ id=100%3A90&action=&start=40&limit=20
# Page n: start=(n - 1) * 20
def create_request(page):
base_url = 'https://movie.douban.com/j/chart/top_list?type=30&interval_id=100%3A90&action=&'
data = {
'start': (page - 1) * 20,
'limit': 20
}
data = urllib.parse.urlencode(data)
url = base_url + data
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'
}
request = urllib.request.Request(url=url, headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def download(content, page):
# downloadFile = open('file/douban.json', 'w', encoding='utf-8')
# downloadFile.write(content)
# This kind of writing has the same effect
with open('file/douban_ancient costume_' + str(page) + '.json', 'w', encoding='utf-8') as downloadFile:
downloadFile.write(content)
if __name__ == '__main__':
start_page = int(input('Please enter the starting page number: '))
end_page = int(input('Please enter the ending page number: '))
for page in range(start_page, end_page + 1):
# Each page has customization of its own request object
request = create_request(page)
# Get response data
content = get_content(request)
# download
download(content, page)
6.ajax post request
Example: KFC official website, climb KFC official website - Restaurant query - City: Beijing - the first 10 pages of data and save them
import urllib.parse
import urllib.request
# Climb KFC's official website - Restaurant query - City: Beijing - the first 10 pages of data and save it
# This is a post request
# Find GetStoreList.ashx?op=cname
# Request address: http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# Form Data
# Page 1
# cname: Beijing
# pid:
# pageIndex: 1
# pageSize: 10
# Page 2
# cname: Beijing
# pid:
# pageIndex: 2
# pageSize: 10
# Page n
# cname: Beijing
# pid:
# pageIndex: n
# pageSize: 10
def create_request(page):
base_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data = {
'cname': 'Beijing',
'pid': '',
'pageIndex': page,
'pageSize': 10,
}
data = urllib.parse.urlencode(data).encode('utf-8')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'
}
request = urllib.request.Request(url=base_url, data=data, headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def download(content, page):
# downloadFile = open('file/douban.json', 'w', encoding='utf-8')
# downloadFile.write(content)
# This kind of writing has the same effect
with open('file/KFC_city_beijing_' + str(page) + '.json', 'w', encoding='utf-8') as downloadFile:
downloadFile.write(content)
if __name__ == '__main__':
start_page = int(input('Please enter the starting page number: '))
end_page = int(input('Please enter the ending page number: '))
for page in range(start_page, end_page + 1):
# Each page has customization of its own request object
request = create_request(page)
# Get response data
content = get_content(request)
# download
download(content, page)
7.URLError/HTTPError
brief introduction
- The HTTPError class is a subclass of the URLError class
- Imported package urlib.error.httperror, urlib.error.urlerror
- HTTP error: http error is an error prompt added when the browser cannot connect to the server. Guide and tell the viewer what went wrong with the page.
- When sending a request through urllib, it may fail. At this time, if you want to make your code more robust, you can catch exceptions through try exception. There are two types of exceptions: URLError\HTTPError
import urllib.request
import urllib.error
# url = 'https://blog.csdn.net/sjp11/article/details/120236636'
url = 'https://If the url is misspelled, the url will report an error '
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'
}
try:
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
except urllib.error.HTTPError:
print('The system is being upgraded,Please try again later...')
except urllib.error.URLError:
print('As I said, the system is being upgraded,Please try again later...')
8.cookie login
Example: weibo login
Assignment: qq space crawling
(temporarily missing code)
9.Handler processor
Reasons for learning the handler processor:
urllib.request.urlopen(url): request headers cannot be customized
urllib.request.Request(url,headers,data): request headers can be customized
Handler: Customize more advanced request headers. With the complexity of business logic, the customization of request object can not meet our needs (dynamic cookie s and agents can not use the customization of request object).
import urllib.request
# Use handler to visit Baidu and get the web page source code
url = 'http://www.baidu.com'
# headers = {
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'
# }
headers = {
'User - Agent': 'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 74.0.3729.169Safari / 537.36'
}
request = urllib.request.Request(url=url, headers=headers)
# handler,build_opener,open
# Get handler object
handler = urllib.request.HTTPHandler()
# Get opener object
opener = urllib.request.build_opener(handler)
# Call the open method
response = opener.open(request)
content = response.read().decode('utf-8')
print(content)
10. Proxy server
-
Common functions of agent
-
Break through their own IP access restrictions and visit foreign sites.
-
Access internal resources of some units or groups
For example, FTP of a University (provided that the proxy address is within the allowable access range of the resource) can be used for various FTP download and upload, as well as various data query and sharing services open to the education network by using the free proxy server in the address section of the education network.
-
Improve access speed
For example, the proxy server usually sets a large hard disk buffer. When external information passes through, it is also saved in the buffer. When other users access the same information again, the information is directly taken out from the buffer and transmitted to users to improve the access speed.
-
Hide real IP
For example, Internet users can also hide their IP in this way to avoid attacks.
-
-
Code configuration agent
- Create a Reuqest object
- Create ProxyHandler object
- Creating an opener object with a handler object
- Send the request using the opener.open function
agent
Fast agent - free agent: https://www.kuaidaili.com/free/
You can also purchase proxy ip: generate API connection - return high hidden ip and port, but if you access it frequently, it will still be blocked. Therefore, the need for proxy pool means that there are a pile of high hidden ip in the proxy pool, which will not expose your real ip.
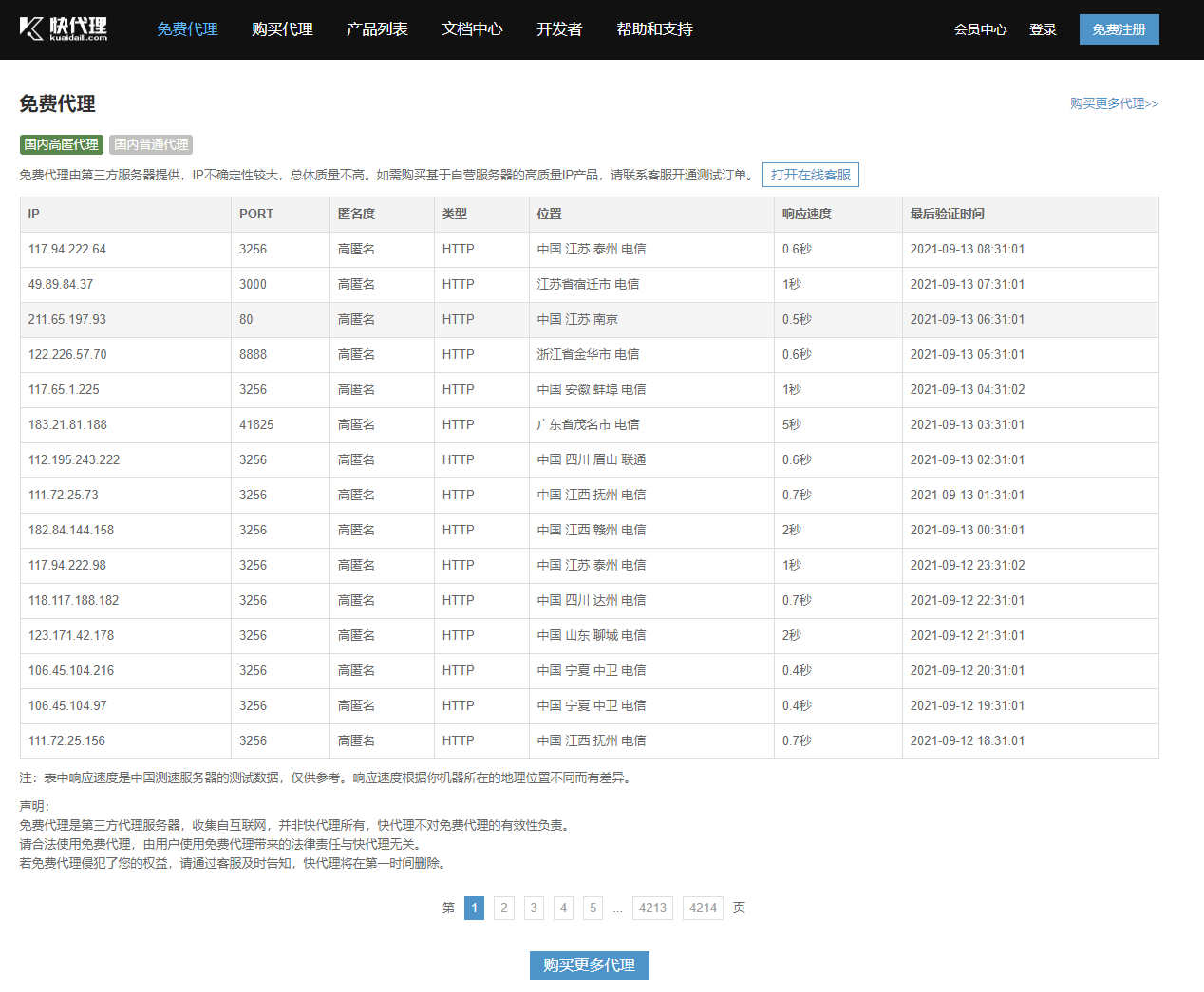
Single agent
import urllib.request
url = 'http://www.baidu.com/s?ie=UTF-8&wd=ip'
headers = {
'User - Agent': 'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 74.0.3729.169Safari / 537.36'
}
# Request object customization
request = urllib.request.Request(url=url, headers=headers)
# The proxy ip address can be found on this website: https://www.kuaidaili.com/free/
proxies = {'http': '211.65.197.93:80'}
handler = urllib.request.ProxyHandler(proxies=proxies)
opener = urllib.request.build_opener(handler)
# Impersonate browser access server
response = opener.open(request)
# Get response information
content = response.read().decode('utf-8')
# Save to local
with open('file/proxy.html', 'w', encoding='utf-8') as downloadFile:
downloadFile.write(content)
Agent pool
import random
import urllib.request
url = 'http://www.baidu.com/s?ie=UTF-8&wd=ip'
headers = {
'User - Agent': 'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 74.0.3729.169Safari / 537.36'
}
# https://www.kuaidaili.com/free/
proxies_pool = [
{'http': '118.24.219.151:16817'},
{'http': '118.24.219.151:16817'},
{'http': '117.94.222.64:3256'},
{'http': '49.89.84.37:3000'},
{'http': '211.65.197.93:80'},
{'http': '122.226.57.70:8888'},
{'http': '117.65.1.225:3256'},
{'http': '183.21.81.188:41825'},
{'http': '112.195.243.222:3256'},
{'http': '111.72.25.73:3256'},
{'http': '182.84.144.158:3256'},
{'http': '117.94.222.98:3256'},
{'http': '118.117.188.182:3256'},
{'http': '123.171.42.178:3256'},
{'http': '106.45.104.216:3256'},
{'http': '106.45.104.97:3256'},
{'http': '111.72.25.156:3256'},
{'http': '111.72.25.156:3256'},
{'http': '163.125.29.37:8118'},
{'http': '163.125.29.202:8118'},
{'http': '175.7.199.119:3256'},
{'http': '211.65.197.93:80'},
{'http': '113.254.178.224:8197'},
{'http': '117.94.222.106:3256'},
{'http': '117.94.222.52:3256'},
{'http': '121.232.194.229:9000'},
{'http': '121.232.148.113:3256'},
{'http': '113.254.178.224:8380'},
{'http': '163.125.29.202:8118'},
{'http': '113.254.178.224:8383'},
{'http': '123.171.42.178:3256'},
{'http': '113.254.178.224:8382'},
]
# Request object customization
request = urllib.request.Request(url=url, headers=headers)
proxies = random.choice(proxies_pool)
handler = urllib.request.ProxyHandler(proxies=proxies)
opener = urllib.request.build_opener(handler)
# Impersonate browser access server
response = opener.open(request)
# Get response information
content = response.read().decode('utf-8')
# Save to local
with open('file/proxies_poor.html', 'w', encoding='utf-8') as downloadFile:
downloadFile.write(content)
3. Analysis
1.xpath
1.1 use of XPath
Installing the xpath plug-in
Open the Chrome browser -- > click the dot in the upper right corner -- > more tools -- > extensions -- > drag the xpath plug-in into the extensions -- > if the crx file fails, you need to modify the suffix of the. crx file to. zip or. rar compressed file -- > drag again -- > close the browser, reopen -- > open a web page, and press Ctrl + Shift + X -- > to display a small black box, Description the xpath plug-in is in effect
Install lxml Library
Note: the installation path is consistent with the library path (Scripts directory path) of python, such as D: \ develop \ Python \ Python 39 \ Scripts
# 1. Install lxml Library
pip install lxml -i https://pypi.douban.com/simple
# 2. Import lxml.etree
from lxml import etree
# 3.etree.parse() parse local files
html_tree = etree.parse('XX.html')
# 4.etree.HTML() server response file
html_tree = etree.HTML(response.read().decode('utf-8')
# 4.html_tree.xpath(xpath path)
Basic xpath syntax
# Basic xpath syntax
# 1. Path query
//: find all descendant nodes regardless of hierarchy
/ : Find direct child node
# 2. Predicate query
//div[@id]
//div[@id="maincontent"]
# 3. Attribute query
//@class
# 4. Fuzzy query
//div[contains(@id, "he")]
//div[starts‐with(@id, "he")]
# 5. Content query
//div/h1/text()
# 6. Logical operation
//div[@id="head" and @class="s_down"]
//title | //price
Local HTML file: 1905.html
<!DOCTYPE html>
<html lang="zh-cmn-Hans">
<head>
<meta charset="utf-8"/>
<title>Movie Network_1905.com</title>
<meta property="og:image" content="https://static.m1905.cn/144x144.png"/>
<link rel="dns-prefetch" href="//image14.m1905.cn"/>
<style>
.index-carousel .index-carousel-screenshot {
background: none;
}
</style>
</head>
<body>
<!-- Movie number -->
<div class="layout-wrapper depth-report moive-number">
<div class="layerout1200">
<h3>
<span class="fl">Movie number</span>
<a href="https://www.1905.com/dianyinghao/" class="fr" target="_ Blank "> more</a>
</h3>
<ul class="clearfix">
<li id="1">
<a href="https://www.1905.com/news/20210908/1539457.shtml">
<img src="//static.m1905.cn/images/home/pixel.gif"/></a>
<a href="https://www.1905.com/dianyinghao/detail/lst/95/">
<img src="//static.m1905.cn/images/home/pixel.gif"/>
<em>Mirror Entertainment</em>
</a>
</li>
<li id="2">
<a href="https://www.1905.com/news/20210910/1540134.shtml">
<img src="//static.m1905.cn/images/home/pixel.gif"/></a>
<a href="https://www.1905.com/dianyinghao/detail/lst/75/">
<img src="//static.m1905.cn/images/home/pixel.gif"/>
<em>Entertainment Capital</em>
</a>
</li>
<li id="3">
<a href="https://www.1905.com/news/20210908/1539808.shtml">
<img src="//static.m1905.cn/images/home/pixel.gif"/>
</a>
<a href="https://www.1905.com/dianyinghao/detail/lst/59/">
<img src="//static.m1905.cn/images/home/pixel.gif"/>
<em>Rhinoceros Entertainment</em>
</a>
</li>
</ul>
</div>
</div>
<!-- Links -->
<div class="layout-wrapper">
<div class="layerout1200">
<section class="frLink">
<div>Links</div>
<p>
<a href="http://Www.people.com.cn "target =" _blank "> people.com</a>
<a href="http://www.xinhuanet.com/" target="_ Blank "> Xinhua</a>
<a href="http://Www.china. Com. CN / "target =" _blank "> china.com</a>
<a href="http://www.cnr.cn" target="_ Blank "> CNR</a>
<a href="http://Www.legaldaily. Com. CN / "target =" _blank "> Legal Network</a>
<a href="http://www.most.gov.cn/" target="_ Blank "> Ministry of science and technology</a>
<a href="http://Www.gmw.cn "target =" _blank "> guangming.com</a>
<a href="http://news.sohu.com" target="_ Blank "> Sohu News</a>
<a href="https://News.163.com "target =" _blank "> Netease News</a>
<a href="https://www.1958xy.com/" target="_ blank" style="margin-right:0; "> xiying.com</a>
</p>
</section>
</div>
</div>
<!-- footer -->
<footer class="footer" style="min-width: 1380px;">
<div class="footer-inner">
<h3 class="homeico footer-inner-logo"></h3>
<p class="footer-inner-links">
<a href="https://Www.1905. COM / about / aboutus / "target =" _blank "> about us < / a > < span >|</span>
<a href="https://www.1905.com/sitemap.html" target="_ Blank "> website map < / a > < span >|</span>
<a href="https://Www.1905. COM / jobs / "target =" _blank "> looking for talents < / a > < span >|</span>
<a href="https://www.1905.com/about/copyright/" target="_ Blank "> copyright notice < / a > < span >|</span>
<a href="https://Www.1905. COM / about / contactus / "target =" _blank "> contact us < / a > < span >|</span>
<a href="https://www.1905.com/error_ report/error_ report-p-pid-125-cid-126-tid-128.html" target="_ Blank "> help and feedback < / a > < span >|</span>
<a href="https://Www.1905. COM / link / "target =" _blank "> link < / a > < span >|</span>
<a href="https://www.1905.com/cctv6/advertise/" target="_ Blank "> CCTV6 advertising investment < / a > <! -- < span >|</span>
<a href="javascript:void(0)">Associated Media</a>-->
</p>
<div class="footer-inner-bottom">
<a href="https://Www.1905. COM / about / license / "target =" _blank "> network audio visual license No. 0107199</a>
<a href="https://www.1905.com/about/cbwjyxkz/" target="_ Blank "> publication business license</a>
<a href="https://Www.1905. COM / about / dyfxjyxkz / "target =" _blank "> film distribution license</a>
<a href="https://www.1905.com/about/jyxyc/" target="_ Blank "> business performance license</a>
<a href="https://Www.1905. COM / about / gbdsjm / "target =" _blank "> Radio and television program production and operation license</a>
<br/>
<a href="https://www.1905.com/about/beian/" target="_ Blank "> business license of enterprise legal person</a>
<a href="https://Www.1905. COM / about / zzdxyw / "target =" _blank "> value added telecom business license</a>
<a href="http://beian.miit.gov.cn/" target="_ Blank "> Jing ICP Bei 12022675-3</a>
<a href="http://Www.beian. Gov.cn / portal / registersysteminfo? Recordcode = 11010202000300 "target =" _blank "> jinggong.com.anbei No. 11010202000300</a>
</div>
</div>
</footer>
<!-- copyright -->
<div class="copy-right" style="min-width: 1380px;">
<div class="copy-right-conts clearfix">
<div class="right-conts-left fl">
<span>CopyRight © 2017</span>
<em>Official website of film channel program center</em><em class="conts-left-margin">|</em>
<em>
<a href="https://www.1905.com/about/icp/" target="_ Blank "> Beijing ICP certificate 100935</a>
</em>
</div>
</div>
</div>
<!-- Back to top -->
<div class="return-top index-xicon"></div>
<script src="//static.m1905.cn/homepage2020/PC/js/main20201016.min.js?t=20201102"></script>
<!--Statistical code-->
<script type="text/javascript" src="//js.static.m1905.cn/pingd.js?v=1"></script>
</body>
</html>
xpath parses local html (e.g. 1905.html)
from lxml import etree
# xpath parsing
# ① Local file -- > etree.parse
# ② Data of server response response response. Read(). Decode ('utf-8 ') -- > etree. HTML ()
# xpath parsing local files
tree = etree.parse('1905.html')
# print(tree)
# tree.xpath('xpath path ')
# Find li under ul
li_list = tree.xpath('//body//ul/li')
# print(li_list)
# len(): get the length of the list
# print(len(li_list))
# View all div tags with class attribute
div_list = tree.xpath('//body/div[@class]')
# print(div_list)
# print(len(div_list))
# text(): get the content in the tag
div_content_list = tree.xpath('//body//span[@class]/text()')
# print(div_content_list)
# print(len(div_content_list))
# Find the contents of the em tag under the li tag with id 1
li_1_list = tree.xpath('//ul/li[@id="1"]//em/text()')
# print(li_1_list)
# print(len(li_1_list))
# Find the href attribute value of the a tag under the li tag with id 1
a_href_list = tree.xpath('//ul/li[@id="1"]//a/@href')
# print(a_href_list)
# print(len(a_href_list))
# Find the contents of the em tag under the a tag of www.1905.com in the href attribute
em_content_list = tree.xpath('//ul/li/a[contains(@href,"www.1905.com")]//em/text()')
# print(em_content_list)
# print(len(em_content_list))
# Look in the href attribute to https://www.1905.com Contents of em tag under a tag at the beginning
a_em_content_list = tree.xpath('//ul/li/a[starts-with(@href,"https://www.1905.com")]//em/text()')
# print(a_em_content_list)
# print(len(a_em_content_list))
# Find the href attribute as https://www.1905.com/about/aboutus/ And the contents of a tag with target _blank
a1_content_list = tree.xpath('//a[@href="https://www.1905.com/about/aboutus/" and @target="_blank"]/text()')
# print(a1_content_list)
# print(len(a1_content_list))
# Find the content of a tag whose href attribute contains http and target is _blank
all_a_content_list = tree.xpath('//a[contains(@href,"http") and @target="_blank"]/text()')
# print(all_a_content_list)
# print(len(all_a_content_list))
# Find the content of a tag whose href attribute contains http or whose href attribute contains https
ah_a_content_list = tree.xpath('//footer//a[contains(@href,"http")]/text() | //footer//a[contains(@href,"https")]/text()')
print(ah_a_content_list)
print(len(ah_a_content_list))
Ctrl+Shift+X, open the Xpath Helper plug-in (it needs to be installed in advance)
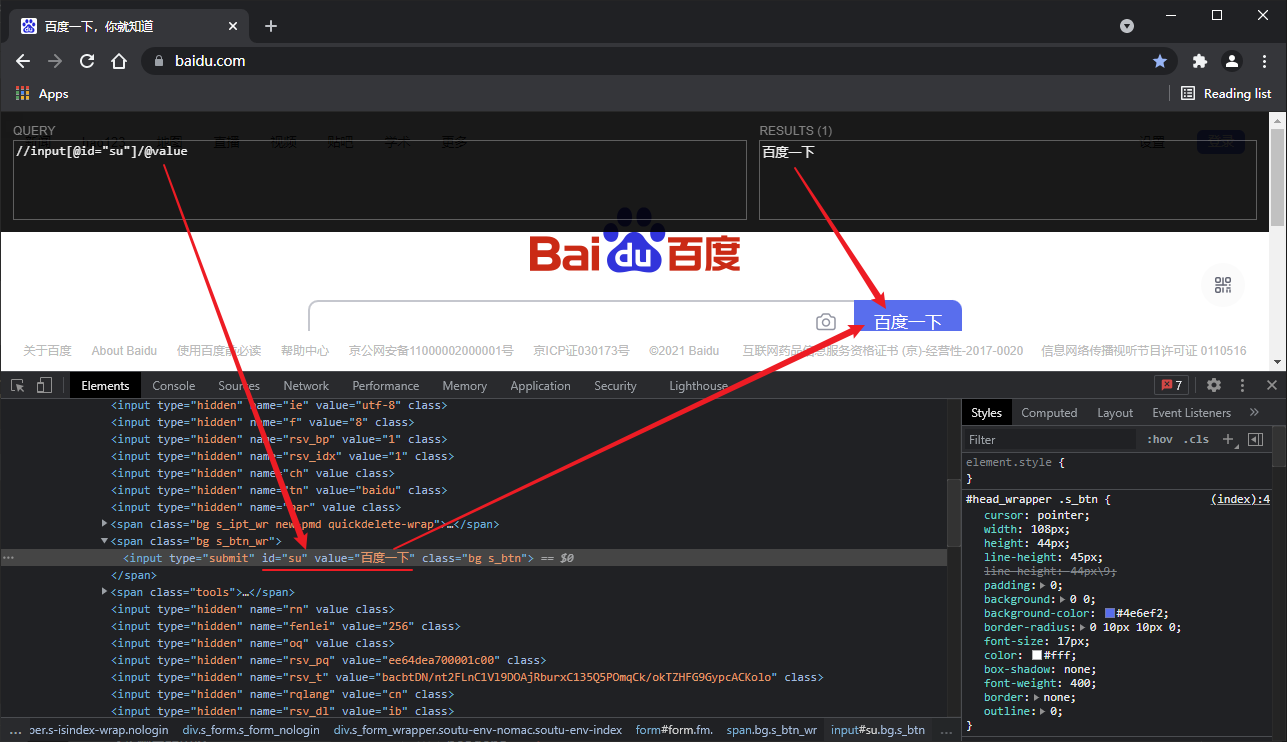
xpath parses the server response html file, such as Baidu
import urllib.request
from lxml import etree
# Get web source code
# Parse the server response file etree.HTML()
# Print
# Demand: analyze Baidu
url = 'http://www.baidu.com/'
headers = {
'User - Agent': 'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 74.0.3729.169Safari / 537.36'
}
# Customization of request object
request = urllib.request.Request(url=url, headers=headers)
# Impersonate browser access server
response = urllib.request.urlopen(request)
# Get web source code
content = response.read().decode('utf-8')
# Parse the server response file (parse the web page source code and get the desired data)
tree = etree.HTML(content)
# Get the desired data. xpath returns a list type of data
# result = tree.xpath('//input[@id="su"]/@value ') # [' Baidu once ']
result = tree.xpath('//input[@id="su"]/@value')[0] # Baidu Click
print(result)
The xpath parsing server responds to html files, such as: parsing webmaster material - HD pictures - beauty pictures, and obtaining the pictures on the first 10 pages
Get picture path: src
//div[@id="container"]//a/img/@src
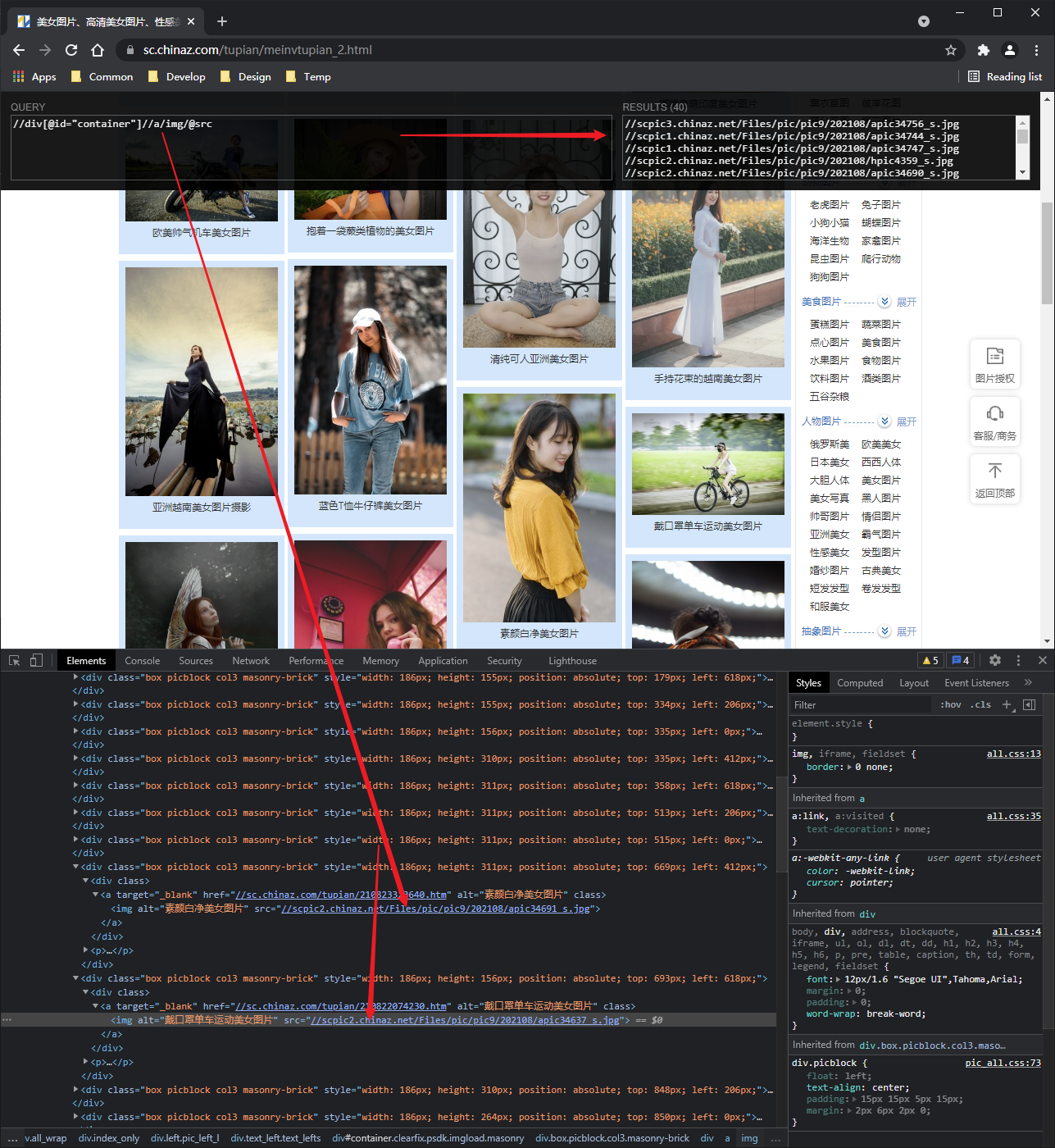
Get picture name: alt
//div[@id="container"]//a/img/@alt
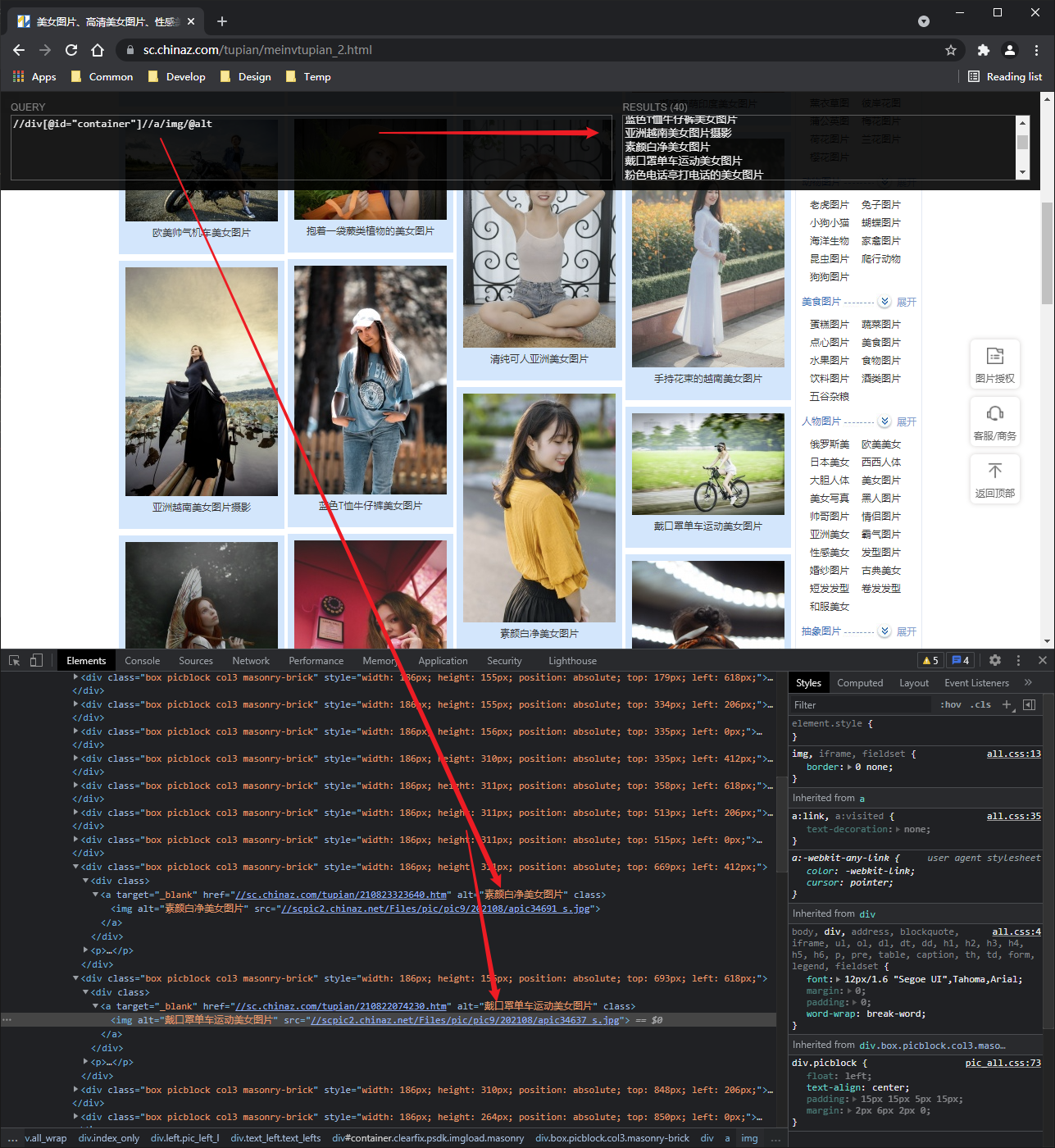
code
import urllib.request
from lxml import etree
# Demand: Download webmaster material - HD pictures - beauty pictures, pictures on the first 10 pages
# Get web source code
# Parse the server response file etree.HTML()
# download
# Law finding:
# Page 1: https://sc.chinaz.com/tupian/meinvtupian.html
# Page 2: https://sc.chinaz.com/tupian/meinvtupian_2.html
# Page 3: https://sc.chinaz.com/tupian/meinvtupian_3.html
# Page n: https://sc.chinaz.com/tupian/meinvtupian_n.html
def create_request(page):
if page == 1:
url = 'http://sc.chinaz.com/tupian/meinvtupian.html'
else:
url = 'http://sc.chinaz.com/tupian/meinvtupian_' + str(page) + '.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36'
}
request = urllib.request.Request(url=url, headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def download_photo(content):
# Download picture urllib.request.urlretrieve('picture address', 'picture name')
tree = etree.HTML(content)
# Generally, pictures are loaded lazily
# photo_path_list = tree.xpath('//div[@id="container"]//a/img/@src ') # after lazy loading
photo_src_list = tree.xpath('//div[@id="container"]//a/img/@src2 ') # before lazy loading
photo_name_list = tree.xpath('//div[@id="container"]//a/img/@alt')
for i in range(len(photo_name_list)):
photo_name = photo_name_list[i]
photo_src = photo_src_list[i]
photo_full_name = photo_name + '.jpg'
photo_path = 'https:' + photo_src
urllib.request.urlretrieve(url=photo_path, filename='img/chinaz/' + photo_full_name)
if __name__ == '__main__':
start_page = int(input('Please enter the starting page number: '))
end_page = int(input('Please enter the end page number: '))
for page in range(start_page, end_page + 1):
# Customization of request object
request = create_request(page)
# Get web source code
content = get_content(request)
# download
download_photo(content)
2.JsonPath
2.1 installation and usage of jsonpath
pip installation
Note: the installation path is consistent with the library path (Scripts directory path) of python, such as D: \ develop \ Python \ Python 39 \ Scripts
pip install jsonpath
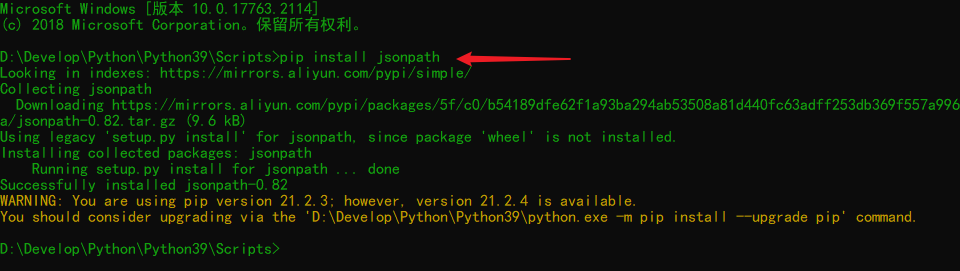
Use of jsonpath
jsonpath can only parse local files, not server response files
import json
import jsonpath
obj = json.load(open('json file', 'r', encoding='utf-8'))
ret = jsonpath.jsonpath(obj, 'jsonpath grammar')
| XPath | JSONPath | Description |
|---|---|---|
| / | $ | Represents the root element |
| . | @ | Current element |
| / | . or [] | Child element |
| .. | n/a | Parent element |
| // | .. | Recursive descent, JSONPath is borrowed from E4X. |
| * | * | Wildcard, representing all elements |
| @ | n/a | Property access character |
| [] | [] | Child element operator |
| | | [,] | The join operator merges other node sets in the XPath result. JSONP allows name or array indexes. |
| n/a | [start :end:step] | The array segmentation operation is borrowed from ES4. |
| [] | ?() | Apply filter expression |
| n/a | () | Script expressions are used under the script engine. |
| () | n/a | Xpath grouping |
JSONPath getting started article link:( http://blog.csdn.net/luxideyao/article/details/77802389)
jsonpath_store.json
{
"store": {
"book": [
{
"category": "Xiuzhen",
"author": "Liudao",
"title": "How do bad guys practice",
"price": 8.95
},
{
"category": "Xiuzhen",
"author": "Silkworm potato",
"title": "Break through the sky",
"price": 12.99
},
{
"category": "Xiuzhen",
"author": "Tang family San Shao",
"title": "Douluo continent",
"isbn": "0-553-21311-3",
"price": 8.99
},
{
"category": "Xiuzhen",
"author": "Third uncle of Southern Sect",
"title": "Star change",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "black",
"price": 19.95,
"category": "urban",
"author": "Tang family Sishao",
"title": "Douluo Xiaolu",
"isbn": "0-553-21311-4",
"price": 9.99
}
}
}
parse_jsonpath.py
import json
import jsonpath
obj = json.load(open('jsonpath_store.json', 'r', encoding='utf-8'))
# The author of all the books in the bookstore
# author_list = jsonpath.jsonpath(obj, '$.store.book[*].author')
# print(author_list)
# All authors
# all_author_list = jsonpath.jsonpath(obj, '$..author')
# print(all_author_list)
# All elements of store. All books and bicycle s
# all_element_list = jsonpath.jsonpath(obj, '$.store.*')
# print(all_element_list)
# price of everything in the store
# all_price_list = jsonpath.jsonpath(obj, '$.store..price')
# print(all_price_list)
# The third book
# three_book_list = jsonpath.jsonpath(obj, '$..book[2]')
# print(three_book_list)
# The last book
# last_book_list = jsonpath.jsonpath(obj, '$..book[(@.length-1)]')
# print(last_book_list)
# The first two books
# front_two_book_list = jsonpath.jsonpath(obj, '$..book[0,1]')
# front_two_book_list = jsonpath.jsonpath(obj, '$..book[:2]')
# print(front_two_book_list)
# Filter out all books containing isbn
# front_two_book_list = jsonpath.jsonpath(obj, '$..book[?(@.isbn)]')
# print(front_two_book_list)
# Filter out books with prices below 10
# price_lessthan10_book_list = jsonpath.jsonpath(obj, '$..book[?(@.price<10)]')
# print(price_lessthan10_book_list)
# All elements
all_element_list = jsonpath.jsonpath(obj, '$..*')
print(all_element_list)
Case: ticket panning (use jsonpath to analyze ticket panning)
Get request URLs and Request Headers for all cities
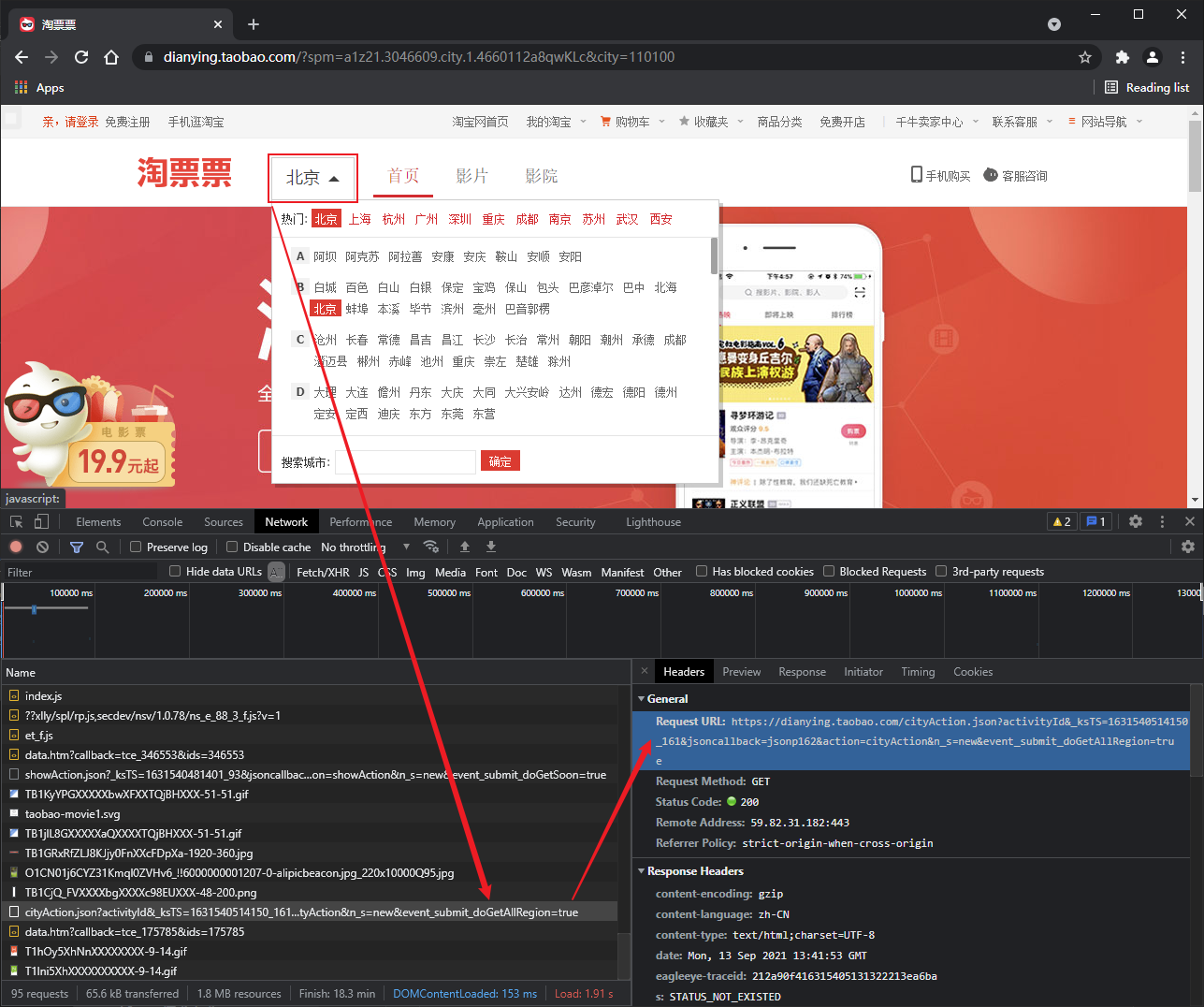
All crawling cities (json format, crawling files are displayed only once, and later crawling files are no longer displayed because there are too many): jsonpath parses tickets. json
{
"returnCode": "0",
"returnValue": {
"A": [
{
"id": 3643,
"parentId": 0,
"regionName": "ABA",
"cityCode": 513200,
"pinYin": "ABA"
},
{
"id": 3090,
"parentId": 0,
"regionName": "Aksu",
"cityCode": 652900,
"pinYin": "AKESU"
},
{
"id": 3632,
"parentId": 0,
"regionName": "Alashan",
"cityCode": 152900,
"pinYin": "ALASHAN"
},
{
"id": 899,
"parentId": 0,
"regionName": "Ankang",
"cityCode": 610900,
"pinYin": "ANKANG"
},
{
"id": 196,
"parentId": 0,
"regionName": "Anqing",
"cityCode": 340800,
"pinYin": "ANQING"
},
{
"id": 758,
"parentId": 0,
"regionName": "Anshan",
"cityCode": 210300,
"pinYin": "ANSHAN"
},
{
"id": 388,
"parentId": 0,
"regionName": "Anshun",
"cityCode": 520400,
"pinYin": "ANSHUN"
},
{
"id": 454,
"parentId": 0,
"regionName": "Anyang",
"cityCode": 410500,
"pinYin": "ANYANG"
}
],
"B": [
{
"id": 3633,
"parentId": 0,
"regionName": "Baicheng",
"cityCode": 220800,
"pinYin": "BAICHENG"
},
{
"id": 356,
"parentId": 0,
"regionName": "Baise",
"cityCode": 451000,
"pinYin": "BAISE"
},
{
"id": 634,
"parentId": 0,
"regionName": "mount bai",
"cityCode": 220600,
"pinYin": "BAISHAN"
},
{
"id": 275,
"parentId": 0,
"regionName": "silver",
"cityCode": 620400,
"pinYin": "BAIYIN"
},
{
"id": 426,
"parentId": 0,
"regionName": "Baoding",
"cityCode": 130600,
"pinYin": "BAODING"
},
{
"id": 188,
"parentId": 0,
"regionName": "Baoji",
"cityCode": 610300,
"pinYin": "BAOJI"
},
{
"id": 994,
"parentId": 0,
"regionName": "Baoshan",
"cityCode": 530500,
"pinYin": "BAOSHAN"
},
{
"id": 1181,
"parentId": 0,
"regionName": "Baotou",
"cityCode": 150200,
"pinYin": "BAOTOU"
},
{
"id": 789,
"parentId": 0,
"regionName": "Bayannur",
"cityCode": 150800,
"pinYin": "BAYANNAOER"
},
{
"id": 925,
"parentId": 0,
"regionName": "Bazhong",
"cityCode": 511900,
"pinYin": "BAZHONG"
},
{
"id": 358,
"parentId": 0,
"regionName": "the north sea",
"cityCode": 450500,
"pinYin": "BEIHAI"
},
{
"id": 3,
"parentId": 0,
"regionName": "Beijing",
"cityCode": 110100,
"pinYin": "BEIJING"
},
{
"id": 200,
"parentId": 0,
"regionName": "Bengbu",
"cityCode": 340300,
"pinYin": "BENGBU"
},
{
"id": 760,
"parentId": 0,
"regionName": "Benxi",
"cityCode": 210500,
"pinYin": "BENXI"
},
{
"id": 390,
"parentId": 0,
"regionName": "Bijie",
"cityCode": 522401,
"pinYin": "BIJIE"
},
{
"id": 824,
"parentId": 0,
"regionName": "Binzhou",
"cityCode": 371600,
"pinYin": "BINZHOU"
},
{
"id": 1126,
"parentId": 0,
"regionName": "Bozhou",
"cityCode": 341600,
"pinYin": "BOZHOU"
},
{
"id": 5860,
"parentId": 0,
"regionName": "Bayingolin",
"cityCode": 652800,
"pinYin": "BYGL"
}
],
"C": [
{
"id": 430,
"parentId": 0,
"regionName": "Cangzhou",
"cityCode": 130900,
"pinYin": "CANGZHOU"
},
{
"id": 623,
"parentId": 0,
"regionName": "Changchun",
"cityCode": 220100,
"pinYin": "CHANGCHUN"
},
{
"id": 573,
"parentId": 0,
"regionName": "Changde",
"cityCode": 430700,
"pinYin": "CHANGDE"
},
{
"id": 983,
"parentId": 0,
"regionName": "Changji",
"cityCode": 652300,
"pinYin": "CHANGJI"
},
{
"id": 5781,
"parentId": 0,
"regionName": "Changjiang",
"cityCode": 469026,
"pinYin": "CHANGJIANG"
},
{
"id": 576,
"parentId": 0,
"regionName": "Changsha",
"cityCode": 430100,
"pinYin": "CHANGSHA"
},
{
"id": 883,
"parentId": 0,
"regionName": "CiH ",
"cityCode": 140400,
"pinYin": "CHANGZHI"
},
{
"id": 651,
"parentId": 0,
"regionName": "Changzhou",
"cityCode": 320400,
"pinYin": "CHANGZHOU"
},
{
"id": 3244,
"parentId": 0,
"regionName": "Sunrise",
"cityCode": 211300,
"pinYin": "CHAOYANG"
},
{
"id": 1138,
"parentId": 0,
"regionName": "Chaozhou",
"cityCode": 445100,
"pinYin": "CHAOZHOU"
},
{
"id": 433,
"parentId": 0,
"regionName": "Chengde",
"cityCode": 130800,
"pinYin": "CHENGDE"
},
{
"id": 70,
"parentId": 0,
"regionName": "Chengdu",
"cityCode": 510100,
"pinYin": "CHENGDU"
},
{
"id": 5859,
"parentId": 0,
"regionName": "Chengmai County",
"cityCode": 469023,
"pinYin": "CHENGMAI"
},
{
"id": 585,
"parentId": 0,
"regionName": "Chenzhou",
"cityCode": 431000,
"pinYin": "CHENZHOU"
},
{
"id": 791,
"parentId": 0,
"regionName": "Chifeng",
"cityCode": 150400,
"pinYin": "CHIFENG"
},
{
"id": 205,
"parentId": 0,
"regionName": "Chizhou",
"cityCode": 341700,
"pinYin": "CHIZHOU"
},
{
"id": 40,
"parentId": 0,
"regionName": "Chongqing",
"cityCode": 500100,
"pinYin": "CHONGQING"
},
{
"id": 3640,
"parentId": 0,
"regionName": "Chongzuo",
"cityCode": 451400,
"pinYin": "CHONGZUO"
},
{
"id": 996,
"parentId": 0,
"regionName": "Chu Xiong",
"cityCode": 532300,
"pinYin": "CHUXIONG"
},
{
"id": 207,
"parentId": 0,
"regionName": "Chuzhou",
"cityCode": 341100,
"pinYin": "CHUZHOU"
}
],
"D": [
{
"id": 998,
"parentId": 0,
"regionName": "Dali",
"cityCode": 532900,
"pinYin": "DALI"
},
{
"id": 763,
"parentId": 0,
"regionName": "Dalian",
"cityCode": 210200,
"pinYin": "DALIAN"
},
{
"id": 3071,
"parentId": 0,
"regionName": "Danzhou",
"cityCode": 460400,
"pinYin": "DAN"
},
{
"id": 753,
"parentId": 0,
"regionName": "Dandong",
"cityCode": 210600,
"pinYin": "DANDONG"
},
{
"id": 514,
"parentId": 0,
"regionName": "Daqing",
"cityCode": 230600,
"pinYin": "DAQING"
},
{
"id": 885,
"parentId": 0,
"regionName": "da tong",
"cityCode": 140200,
"pinYin": "DATONG"
},
{
"id": 3638,
"parentId": 0,
"regionName": "Greater Khingan Range",
"cityCode": 232700,
"pinYin": "DAXINGANLING"
},
{
"id": 935,
"parentId": 0,
"regionName": "Dazhou",
"cityCode": 511700,
"pinYin": "DAZHOU"
},
{
"id": 3650,
"parentId": 0,
"regionName": "Dehong",
"cityCode": 533100,
"pinYin": "DEHONG"
},
{
"id": 937,
"parentId": 0,
"regionName": "Deyang",
"cityCode": 510600,
"pinYin": "DEYANG"
},
{
"id": 827,
"parentId": 0,
"regionName": "Texas",
"cityCode": 371400,
"pinYin": "DEZHOU"
},
{
"id": 5884,
"parentId": 0,
"regionName": "Ding'an",
"cityCode": 469021,
"pinYin": "DINGANXIAN"
},
{
"id": 1135,
"parentId": 0,
"regionName": "Dingxi",
"cityCode": 621100,
"pinYin": "DINGXI"
},
{
"id": 1000,
"parentId": 0,
"regionName": "Diqing",
"cityCode": 533400,
"pinYin": "DIQINGZANGZU"
},
{
"id": 5742,
"parentId": 0,
"regionName": "east",
"cityCode": 469007,
"pinYin": "DONGFANG"
},
{
"id": 109,
"parentId": 0,
"regionName": "Dongguan",
"cityCode": 441900,
"pinYin": "DONGGUAN"
},
{
"id": 829,
"parentId": 0,
"regionName": "doy ",
"cityCode": 370500,
"pinYin": "DONGYING"
}
],
"E": [
{
"id": 793,
"parentId": 0,
"regionName": "erdos",
"cityCode": 150600,
"pinYin": "EERDUOSI"
},
{
"id": 541,
"parentId": 0,
"regionName": "Enshi",
"cityCode": 422800,
"pinYin": "ENSHI"
},
{
"id": 543,
"parentId": 0,
"regionName": "Ezhou",
"cityCode": 420700,
"pinYin": "EZHOU"
}
],
"F": [
{
"id": 360,
"parentId": 0,
"regionName": "port of fangcheng",
"cityCode": 450600,
"pinYin": "FANGCHENGGANG"
},
{
"id": 61,
"parentId": 0,
"regionName": "Foshan",
"cityCode": 440600,
"pinYin": "FOSHAN"
},
{
"id": 770,
"parentId": 0,
"regionName": "Fushun",
"cityCode": 210400,
"pinYin": "FUSHUN"
},
{
"id": 1176,
"parentId": 0,
"regionName": "Fuxin",
"cityCode": 210900,
"pinYin": "FUXIN"
},
{
"id": 1125,
"parentId": 0,
"regionName": "Fuyang",
"cityCode": 341200,
"pinYin": "FUYANG"
},
{
"id": 745,
"parentId": 0,
"regionName": "Fuzhou",
"cityCode": 361000,
"pinYin": "FUZHOU"
},
{
"id": 98,
"parentId": 0,
"regionName": "Fuzhou",
"cityCode": 350100,
"pinYin": "FUZHOU"
}
],
"G": [
{
"id": 3658,
"parentId": 0,
"regionName": "Gannan",
"cityCode": 623000,
"pinYin": "GANNAN"
},
{
"id": 718,
"parentId": 0,
"regionName": "Ganzhou",
"cityCode": 360700,
"pinYin": "GANZHOU"
},
{
"id": 3644,
"parentId": 0,
"regionName": "Ganzi",
"cityCode": 513300,
"pinYin": "GANZI"
},
{
"id": 2166,
"parentId": 43,
"regionName": "Gongyi ",
"cityCode": 410181,
"pinYin": "GONGYI",
"selected": 1
},
{
"id": 3642,
"parentId": 0,
"regionName": "Guang'an",
"cityCode": 511600,
"pinYin": "GUANGAN"
},
{
"id": 3453,
"parentId": 0,
"regionName": "Guangyuan",
"cityCode": 510800,
"pinYin": "GUANGYUAN"
},
{
"id": 8,
"parentId": 0,
"regionName": "Guangzhou",
"cityCode": 440100,
"pinYin": "GUANGZHOU"
},
{
"id": 362,
"parentId": 0,
"regionName": "Guigang",
"cityCode": 450800,
"pinYin": "GUIGANG"
},
{
"id": 364,
"parentId": 0,
"regionName": "Guilin",
"cityCode": 450300,
"pinYin": "GUILIN"
},
{
"id": 394,
"parentId": 0,
"regionName": "Guiyang",
"cityCode": 520100,
"pinYin": "GUIYANG"
},
{
"id": 1183,
"parentId": 0,
"regionName": "Guyuan",
"cityCode": 640400,
"pinYin": "GUYUAN"
}
],
"H": [
{
"id": 508,
"parentId": 0,
"regionName": "Harbin",
"cityCode": 230100,
"pinYin": "HAERBIN"
},
{
"id": 3659,
"parentId": 0,
"regionName": "Haidong",
"cityCode": 630200,
"pinYin": "HAIDONG"
},
{
"id": 414,
"parentId": 0,
"regionName": "Haikou",
"cityCode": 460100,
"pinYin": "HAIKOU"
},
{
"id": 5788,
"parentId": 0,
"regionName": "Hainan State",
"cityCode": 632500,
"pinYin": "HAINANZHOU"
},
{
"id": 3665,
"parentId": 0,
"regionName": "Haixi",
"cityCode": 632800,
"pinYin": "HAIXI"
},
{
"id": 3669,
"parentId": 0,
"regionName": "Hami",
"cityCode": 652200,
"pinYin": "HAMI"
},
{
"id": 435,
"parentId": 0,
"regionName": "Handan",
"cityCode": 130400,
"pinYin": "HANDAN"
},
{
"id": 16,
"parentId": 0,
"regionName": "Hangzhou",
"cityCode": 330100,
"pinYin": "HANGZHOU",
"selected": 0
},
{
"id": 902,
"parentId": 0,
"regionName": "Hanzhong",
"cityCode": 610700,
"pinYin": "HANZHONG"
},
{
"id": 460,
"parentId": 0,
"regionName": "Hebi",
"cityCode": 410600,
"pinYin": "HEBI"
},
{
"id": 1144,
"parentId": 0,
"regionName": "Hechi",
"cityCode": 451200,
"pinYin": "HECHI"
},
{
"id": 210,
"parentId": 0,
"regionName": "Hefei",
"cityCode": 340100,
"pinYin": "HEFEI"
},
{
"id": 1154,
"parentId": 0,
"regionName": "Hegang",
"cityCode": 230400,
"pinYin": "HEGANG"
},
{
"id": 3637,
"parentId": 0,
"regionName": "Heihe River",
"cityCode": 231100,
"pinYin": "HEIHE"
},
{
"id": 1148,
"parentId": 0,
"regionName": "Hengshui",
"cityCode": 131100,
"pinYin": "HENGSHUI"
},
{
"id": 587,
"parentId": 0,
"regionName": "city in Hunan",
"cityCode": 430400,
"pinYin": "HENGYANG"
},
{
"id": 3673,
"parentId": 0,
"regionName": "Hotan",
"cityCode": 653200,
"pinYin": "HETIAN"
},
{
"id": 319,
"parentId": 0,
"regionName": "Heyuan",
"cityCode": 441600,
"pinYin": "HEYUAN"
},
{
"id": 832,
"parentId": 0,
"regionName": "Heze",
"cityCode": 371700,
"pinYin": "HEZE"
},
{
"id": 370,
"parentId": 0,
"regionName": "Hezhou",
"cityCode": 451100,
"pinYin": "HEZHOU"
},
{
"id": 1002,
"parentId": 0,
"regionName": "Red River",
"cityCode": 532500,
"pinYin": "HONGHE"
},
{
"id": 666,
"parentId": 0,
"regionName": "Huai'an",
"cityCode": 320800,
"pinYin": "HUAIAN"
},
{
"id": 1127,
"parentId": 0,
"regionName": "Huaibei",
"cityCode": 340600,
"pinYin": "HUAIBEI"
},
{
"id": 590,
"parentId": 0,
"regionName": "Huaihua",
"cityCode": 431200,
"pinYin": "HUAIHUA"
},
{
"id": 215,
"parentId": 0,
"regionName": "Huainan",
"cityCode": 340400,
"pinYin": "HUAINAN"
},
{
"id": 547,
"parentId": 0,
"regionName": "Huanggang",
"cityCode": 421100,
"pinYin": "HUANGGANG"
},
{
"id": 3661,
"parentId": 0,
"regionName": "Huang Nan",
"cityCode": 632300,
"pinYin": "HUANGNAN"
},
{
"id": 217,
"parentId": 0,
"regionName": "Mount Huangshan",
"cityCode": 341000,
"pinYin": "HUANGSHAN"
},
{
"id": 550,
"parentId": 0,
"regionName": "Yellowstone",
"cityCode": 420200,
"pinYin": "HUANGSHI"
},
{
"id": 796,
"parentId": 0,
"regionName": "Hohhot",
"cityCode": 150100,
"pinYin": "HUHEHAOTE"
},
{
"id": 163,
"parentId": 0,
"regionName": "Huizhou",
"cityCode": 441300,
"pinYin": "HUIZHOU"
},
{
"id": 776,
"parentId": 0,
"regionName": "Huludao",
"cityCode": 211400,
"pinYin": "HULUDAO"
},
{
"id": 801,
"parentId": 0,
"regionName": "Hulun Buir",
"cityCode": 150700,
"pinYin": "HULUNBEIER"
},
{
"id": 173,
"parentId": 0,
"regionName": "Huzhou",
"cityCode": 330500,
"pinYin": "HUZHOU"
}
],
"J": [
{
"id": 523,
"parentId": 0,
"regionName": "Jiamusi",
"cityCode": 230800,
"pinYin": "JIAMUSI"
},
{
"id": 747,
"parentId": 0,
"regionName": "Ji'an",
"cityCode": 360800,
"pinYin": "JIAN"
},
{
"id": 317,
"parentId": 0,
"regionName": "Jiangmen",
"cityCode": 440700,
"pinYin": "JIANGMEN"
},
{
"id": 462,
"parentId": 0,
"regionName": "Jiaozuo",
"cityCode": 410800,
"pinYin": "JIAOZUO"
},
{
"id": 156,
"parentId": 0,
"regionName": "Jiaxing",
"cityCode": 330400,
"pinYin": "JIAXING"
},
{
"id": 1136,
"parentId": 0,
"regionName": "Jiayuguan",
"cityCode": 620200,
"pinYin": "JIAYUGUAN"
},
{
"id": 327,
"parentId": 0,
"regionName": "Jieyang",
"cityCode": 445200,
"pinYin": "JIEYANG"
},
{
"id": 628,
"parentId": 0,
"regionName": "Jilin",
"cityCode": 220200,
"pinYin": "JILIN"
},
{
"id": 837,
"parentId": 0,
"regionName": "Jinan",
"cityCode": 370100,
"pinYin": "JINAN"
},
{
"id": 3556,
"parentId": 0,
"regionName": "Jinchang",
"cityCode": 620300,
"pinYin": "JINCHANG"
},
{
"id": 892,
"parentId": 0,
"regionName": "Jincheng",
"cityCode": 140500,
"pinYin": "JINCHENG"
},
{
"id": 724,
"parentId": 0,
"regionName": "Jingdezhen",
"cityCode": 360200,
"pinYin": "JINGDEZHEN"
},
{
"id": 536,
"parentId": 0,
"regionName": "Jingmen",
"cityCode": 420800,
"pinYin": "JINGMEN"
},
{
"id": 545,
"parentId": 0,
"regionName": "Jingzhou",
"cityCode": 421000,
"pinYin": "JINGZHOU"
},
{
"id": 142,
"parentId": 0,
"regionName": "Jinhua",
"cityCode": 330700,
"pinYin": "JINHUA"
},
{
"id": 842,
"parentId": 0,
"regionName": "Jining",
"cityCode": 370800,
"pinYin": "JINING"
},
{
"id": 894,
"parentId": 0,
"regionName": "Jinzhong",
"cityCode": 140700,
"pinYin": "JINZHONG"
},
{
"id": 779,
"parentId": 0,
"regionName": "Jinzhou",
"cityCode": 210700,
"pinYin": "JINZHOU"
},
{
"id": 726,
"parentId": 0,
"regionName": "Jiujiang",
"cityCode": 360400,
"pinYin": "JIUJIANG"
},
{
"id": 277,
"parentId": 0,
"regionName": "Jiuquan",
"cityCode": 620900,
"pinYin": "JIUQUAN"
},
{
"id": 521,
"parentId": 0,
"regionName": "Jixi",
"cityCode": 230300,
"pinYin": "JIXI"
},
{
"id": 1102,
"parentId": 0,
"regionName": "Jiyuan",
"cityCode": 410881,
"pinYin": "JIYUAN"
}
],
"K": [
{
"id": 466,
"parentId": 0,
"regionName": "Kaifeng",
"cityCode": 410200,
"pinYin": "KAIFENG"
},
{
"id": 985,
"parentId": 0,
"regionName": "Kashgar",
"cityCode": 653100,
"pinYin": "KASHEN"
},
{
"id": 3667,
"parentId": 0,
"regionName": "Karamay",
"cityCode": 650200,
"pinYin": "KELAMAYI"
},
{
"id": 3672,
"parentId": 0,
"regionName": "Kizilsu Kirgiz",
"cityCode": 653000,
"pinYin": "KEZILESUKEERKEZI"
},
{
"id": 18,
"parentId": 0,
"regionName": "Kunming",
"cityCode": 530100,
"pinYin": "KUNMING"
}
],
"L": [
{
"id": 3639,
"parentId": 0,
"regionName": "guest",
"cityCode": 451300,
"pinYin": "LAIBIN"
},
{
"id": 419,
"parentId": 0,
"regionName": "Langfang",
"cityCode": 131000,
"pinYin": "LANGFANG"
},
{
"id": 279,
"parentId": 0,
"regionName": "Lanzhou",
"cityCode": 620100,
"pinYin": "LANZHOU"
},
{
"id": 979,
"parentId": 0,
"regionName": "Lhasa",
"cityCode": 540100,
"pinYin": "LASA"
},
{
"id": 940,
"parentId": 0,
"regionName": "Leshan",
"cityCode": 511100,
"pinYin": "LESHAN"
},
{
"id": 3645,
"parentId": 0,
"regionName": "Liangshan",
"cityCode": 513400,
"pinYin": "LIANGSHAN"
},
{
"id": 677,
"parentId": 0,
"regionName": "Lianyungang",
"cityCode": 320700,
"pinYin": "LIANYUNGANG"
},
{
"id": 847,
"parentId": 0,
"regionName": "Liaocheng",
"cityCode": 371500,
"pinYin": "LIAOCHENG"
},
{
"id": 1178,
"parentId": 0,
"regionName": "Liaoyang",
"cityCode": 211000,
"pinYin": "LIAOYANG"
},
{
"id": 630,
"parentId": 0,
"regionName": "Liaoyuan",
"cityCode": 220400,
"pinYin": "LIAOYUAN"
},
{
"id": 992,
"parentId": 0,
"regionName": "Lijiang",
"cityCode": 530700,
"pinYin": "LIJIANG"
},
{
"id": 1008,
"parentId": 0,
"regionName": "Lincang",
"cityCode": 530900,
"pinYin": "LINCANG"
},
{
"id": 890,
"parentId": 0,
"regionName": "Linfen",
"cityCode": 141000,
"pinYin": "LINFEN"
},
{
"id": 5590,
"parentId": 0,
"regionName": "ascend a height",
"cityCode": 469024,
"pinYin": "LINGAO"
},
{
"id": 3498,
"parentId": 0,
"regionName": "Linxia",
"cityCode": 622900,
"pinYin": "LINXIA"
},
{
"id": 849,
"parentId": 0,
"regionName": "Linyi",
"cityCode": 371300,
"pinYin": "LINYI"
},
{
"id": 3657,
"parentId": 0,
"regionName": "Nyingchi",
"cityCode": 542600,
"pinYin": "LINZHI"
},
{
"id": 1039,
"parentId": 0,
"regionName": "Lishui",
"cityCode": 331100,
"pinYin": "LISHUI"
},
{
"id": 227,
"parentId": 0,
"regionName": "Lu'an",
"cityCode": 341500,
"pinYin": "LIUAN"
},
{
"id": 406,
"parentId": 0,
"regionName": "Liupanshui",
"cityCode": 520200,
"pinYin": "LIUPANSHUI"
},
{
"id": 380,
"parentId": 0,
"regionName": "city in Guangxi",
"cityCode": 450200,
"pinYin": "LIUZHOU"
},
{
"id": 288,
"parentId": 0,
"regionName": "Longnan",
"cityCode": 621200,
"pinYin": "LONGNAN"
},
{
"id": 263,
"parentId": 0,
"regionName": "Longyan",
"cityCode": 350800,
"pinYin": "LONGYAN"
},
{
"id": 595,
"parentId": 0,
"regionName": "Loudi",
"cityCode": 431300,
"pinYin": "LOUDI"
},
{
"id": 5863,
"parentId": 0,
"regionName": "Lingshui",
"cityCode": 469028,
"pinYin": "LS"
},
{
"id": 1194,
"parentId": 0,
"regionName": "Lv Liang",
"cityCode": 141100,
"pinYin": "LULIANG"
},
{
"id": 495,
"parentId": 0,
"regionName": "Luohe",
"cityCode": 411100,
"pinYin": "LUOHE"
},
{
"id": 486,
"parentId": 0,
"regionName": "Luoyang",
"cityCode": 410300,
"pinYin": "LUOYANG"
},
{
"id": 959,
"parentId": 0,
"regionName": "Luzhou",
"cityCode": 510500,
"pinYin": "LUZHOU"
}
],
"M": [
{
"id": 170,
"parentId": 0,
"regionName": "Ma On Shan",
"cityCode": 340500,
"pinYin": "MAANSHAN"
},
{
"id": 348,
"parentId": 0,
"regionName": "Maoming",
"cityCode": 440900,
"pinYin": "MAOMING"
},
{
"id": 961,
"parentId": 0,
"regionName": "Meishan",
"cityCode": 511400,
"pinYin": "MEISHAN"
},
{
"id": 350,
"parentId": 0,
"regionName": "Meizhou",
"cityCode": 441400,
"pinYin": "MEIZHOU"
},
{
"id": 944,
"parentId": 0,
"regionName": "Mianyang",
"cityCode": 510700,
"pinYin": "MIANYANG"
},
{
"id": 528,
"parentId": 0,
"regionName": "Mudanjiang",
"cityCode": 231000,
"pinYin": "MUDANJIANG"
}
],
"N": [
{
"id": 738,
"parentId": 0,
"regionName": "Nanchang",
"cityCode": 360100,
"pinYin": "NANCHANG"
},
{
"id": 968,
"parentId": 0,
"regionName": "Nao ",
"cityCode": 511300,
"pinYin": "NANCHONG"
},
{
"id": 63,
"parentId": 0,
"regionName": "Nanjing",
"cityCode": 320100,
"pinYin": "NANJING"
},
{
"id": 372,
"parentId": 0,
"regionName": "Nanning",
"cityCode": 450100,
"pinYin": "NANNING"
},
{
"id": 254,
"parentId": 0,
"regionName": "Nanping",
"cityCode": 350700,
"pinYin": "NANPING"
},
{
"id": 132,
"parentId": 0,
"regionName": "Nantong",
"cityCode": 320600,
"pinYin": "NANTONG"
},
{
"id": 499,
"parentId": 0,
"regionName": "Nanyang",
"cityCode": 411300,
"pinYin": "NANYANG"
},
{
"id": 970,
"parentId": 0,
"regionName": "Neijiang",
"cityCode": 511000,
"pinYin": "NEIJIANG"
},
{
"id": 147,
"parentId": 0,
"regionName": "Ningbo",
"cityCode": 330200,
"pinYin": "NINGBO"
},
{
"id": 268,
"parentId": 0,
"regionName": "Ningde",
"cityCode": 350900,
"pinYin": "NINGDE"
},
{
"id": 3651,
"parentId": 0,
"regionName": "Nujiang River",
"cityCode": 533300,
"pinYin": "NUJIANG"
}
],
"P": [
{
"id": 784,
"parentId": 0,
"regionName": "Panjin",
"cityCode": 211100,
"pinYin": "PANJIN"
},
{
"id": 951,
"parentId": 0,
"regionName": "Panzhihua",
"cityCode": 510400,
"pinYin": "PANZHIHUA"
},
{
"id": 502,
"parentId": 0,
"regionName": "Pingdingshan",
"cityCode": 410400,
"pinYin": "PINGDINGSHAN"
},
{
"id": 1137,
"parentId": 0,
"regionName": "Pingliang",
"cityCode": 620800,
"pinYin": "PINGLIANG"
},
{
"id": 711,
"parentId": 0,
"regionName": "Pingxiang",
"cityCode": 360300,
"pinYin": "PINGXIANG"
},
{
"id": 3198,
"parentId": 0,
"regionName": "Pu 'er Tea",
"cityCode": 530800,
"pinYin": "PUER"
},
{
"id": 271,
"parentId": 0,
"regionName": "Putian",
"cityCode": 350300,
"pinYin": "PUTIAN"
},
{
"id": 458,
"parentId": 0,
"regionName": "Puyang",
"cityCode": 410900,
"pinYin": "PUYANG"
}
],
"Q": [
{
"id": 3647,
"parentId": 0,
"regionName": "Southeast Guizhou",
"cityCode": 522600,
"pinYin": "QIANDONGNAN"
},
{
"id": 1158,
"parentId": 0,
"regionName": "Qianjiang",
"cityCode": 429005,
"pinYin": "QIANJIANG"
},
{
"id": 3648,
"parentId": 0,
"regionName": "Qiannan",
"cityCode": 522700,
"pinYin": "QIANNAN"
},
{
"id": 3646,
"parentId": 0,
"regionName": "Southwest Guizhou",
"cityCode": 522300,
"pinYin": "QIANXINAN"
},
{
"id": 51,
"parentId": 0,
"regionName": "Qingdao",
"cityCode": 370200,
"pinYin": "QINGDAO"
},
{
"id": 3318,
"parentId": 0,
"regionName": "Qingyang",
"cityCode": 621000,
"pinYin": "QINGYANG"
},
{
"id": 102,
"parentId": 0,
"regionName": "Qingyuan",
"cityCode": 441800,
"pinYin": "QINGYUAN"
},
{
"id": 446,
"parentId": 0,
"regionName": "qinghuangdao",
"cityCode": 130300,
"pinYin": "QINHUANGDAO"
},
{
"id": 1145,
"parentId": 0,
"regionName": "Qinzhou",
"cityCode": 450700,
"pinYin": "QINZHOU"
},
{
"id": 1124,
"parentId": 0,
"regionName": "Qionghai",
"cityCode": 469002,
"pinYin": "QIONGHAI"
},
{
"id": 5851,
"parentId": 0,
"regionName": "Qiongzhong",
"cityCode": 469030,
"pinYin": "QIONGZHONG"
},
{
"id": 530,
"parentId": 0,
"regionName": "Qiqihar",
"cityCode": 230200,
"pinYin": "QIQIHAER"
},
{
"id": 3636,
"parentId": 0,
"regionName": "Qitaihe",
"cityCode": 230900,
"pinYin": "QITAIHE"
},
{
"id": 245,
"parentId": 0,
"regionName": "Quanzhou",
"cityCode": 350500,
"pinYin": "QUANZHOU"
},
{
"id": 1016,
"parentId": 0,
"regionName": "Qu Jing",
"cityCode": 530300,
"pinYin": "QUJING"
},
{
"id": 145,
"parentId": 0,
"regionName": "Quzhou",
"cityCode": 330800,
"pinYin": "QUZHOU"
}
],
"R": [
{
"id": 3654,
"parentId": 0,
"regionName": "Shigatse",
"cityCode": 540200,
"pinYin": "RIKEZE"
},
{
"id": 877,
"parentId": 0,
"regionName": "sunshine",
"cityCode": 371100,
"pinYin": "RIZHAO"
}
],
"S": [
{
"id": 449,
"parentId": 0,
"regionName": "Sanmenxia",
"cityCode": 411200,
"pinYin": "SANMENXIA"
},
{
"id": 239,
"parentId": 0,
"regionName": "Sanming",
"cityCode": 350400,
"pinYin": "SANMING"
},
{
"id": 410,
"parentId": 0,
"regionName": "Sanya",
"cityCode": 460200,
"pinYin": "SANYA"
},
{
"id": 1,
"parentId": 0,
"regionName": "Shanghai",
"cityCode": 310100,
"pinYin": "SHANGHAI"
},
{
"id": 897,
"parentId": 0,
"regionName": "Shangluo",
"cityCode": 611000,
"pinYin": "SHANGLUO"
},
{
"id": 452,
"parentId": 0,
"regionName": "Shangqiu",
"cityCode": 411400,
"pinYin": "SHANGQIU"
},
{
"id": 713,
"parentId": 0,
"regionName": "Shangrao",
"cityCode": 361100,
"pinYin": "SHANGRAO"
},
{
"id": 3653,
"parentId": 0,
"regionName": "Shannan",
"cityCode": 540500,
"pinYin": "SHANNANSHI"
},
{
"id": 290,
"parentId": 0,
"regionName": "Shantou",
"cityCode": 440500,
"pinYin": "SHANTOU"
},
{
"id": 294,
"parentId": 0,
"regionName": "Shanwei",
"cityCode": 441500,
"pinYin": "SHANWEI"
},
{
"id": 296,
"parentId": 0,
"regionName": "Shaoguan",
"cityCode": 440200,
"pinYin": "SHAOGUAN"
},
{
"id": 66,
"parentId": 0,
"regionName": "Shaoxing",
"cityCode": 330600,
"pinYin": "SHAOXING"
},
{
"id": 571,
"parentId": 0,
"regionName": "Shaoyang",
"cityCode": 430500,
"pinYin": "SHAOYANG"
},
{
"id": 75,
"parentId": 0,
"regionName": "Shenyang",
"cityCode": 210100,
"pinYin": "SHENYANG"
},
{
"id": 28,
"parentId": 0,
"regionName": "Shenzhen",
"cityCode": 440300,
"pinYin": "SHENZHEN"
},
{
"id": 1200,
"parentId": 0,
"regionName": "Shihezi",
"cityCode": 659001,
"pinYin": "SHIHEZI"
},
{
"id": 59,
"parentId": 0,
"regionName": "Shijiazhuang",
"cityCode": 130100,
"pinYin": "SHIJIAZHUANG"
},
{
"id": 68,
"parentId": 0,
"regionName": "Shiyan",
"cityCode": 420300,
"pinYin": "SHIYAN"
},
{
"id": 807,
"parentId": 0,
"regionName": "Shizuishan",
"cityCode": 640200,
"pinYin": "SHIZUISHAN"
},
{
"id": 3635,
"parentId": 0,
"regionName": "Shuangyashan",
"cityCode": 230500,
"pinYin": "SHUANGYASHAN"
},
{
"id": 3629,
"parentId": 0,
"regionName": "Shuozhou",
"cityCode": 140600,
"pinYin": "SHUOZHOU"
},
{
"id": 621,
"parentId": 0,
"regionName": "Siping",
"cityCode": 220300,
"pinYin": "SIPING"
},
{
"id": 1174,
"parentId": 0,
"regionName": "Songyuan",
"cityCode": 220700,
"pinYin": "SONGYUAN"
},
{
"id": 511,
"parentId": 0,
"regionName": "Suihua",
"cityCode": 231200,
"pinYin": "SUIHUA"
},
{
"id": 922,
"parentId": 0,
"regionName": "Suining",
"cityCode": 510900,
"pinYin": "SUINING"
},
{
"id": 534,
"parentId": 0,
"regionName": "Suizhou",
"cityCode": 421300,
"pinYin": "SUIZHOU"
},
{
"id": 644,
"parentId": 0,
"regionName": "Suqian",
"cityCode": 321300,
"pinYin": "SUQIAN"
},
{
"id": 193,
"parentId": 0,
"regionName": "Suzhou",
"cityCode": 341300,
"pinYin": "SUZHOU"
},
{
"id": 107,
"parentId": 0,
"regionName": "Suzhou",
"cityCode": 320500,
"pinYin": "SUZHOU"
}
],
"T": [
{
"id": 3674,
"parentId": 0,
"regionName": "Tuscaloosa ",
"cityCode": 654200,
"pinYin": "TACHENG"
},
{
"id": 817,
"parentId": 0,
"regionName": "Taian",
"cityCode": 370900,
"pinYin": "TAIAN"
},
{
"id": 81,
"parentId": 0,
"regionName": "Taiyuan",
"cityCode": 140100,
"pinYin": "TAIYUAN"
},
{
"id": 181,
"parentId": 0,
"regionName": "Taizhou",
"cityCode": 331000,
"pinYin": "TAIZHOU"
},
{
"id": 640,
"parentId": 0,
"regionName": "Taizhou",
"cityCode": 321200,
"pinYin": "TAIZHOU"
},
{
"id": 83,
"parentId": 0,
"regionName": "Tangshan",
"cityCode": 130200,
"pinYin": "TANGSHAN"
},
{
"id": 22,
"parentId": 0,
"regionName": "Tianjin",
"cityCode": 120100,
"pinYin": "TIANJIN"
},
{
"id": 1159,
"parentId": 0,
"regionName": "Tianmen",
"cityCode": 429006,
"pinYin": "TIANMEN"
},
{
"id": 1119,
"parentId": 0,
"regionName": "Tianshui",
"cityCode": 620500,
"pinYin": "TIANSHUI"
},
{
"id": 1179,
"parentId": 0,
"regionName": "Tieling",
"cityCode": 211200,
"pinYin": "TIELING"
},
{
"id": 1187,
"parentId": 0,
"regionName": "Tongchuan",
"cityCode": 610200,
"pinYin": "TONGCHUAN"
},
{
"id": 619,
"parentId": 0,
"regionName": "make well-connected",
"cityCode": 220500,
"pinYin": "TONGHUA"
},
{
"id": 787,
"parentId": 0,
"regionName": "Tongliao",
"cityCode": 150500,
"pinYin": "TONGLIAO"
},
{
"id": 191,
"parentId": 0,
"regionName": "Tongling",
"cityCode": 340700,
"pinYin": "TONGLING"
},
{
"id": 386,
"parentId": 0,
"regionName": "Tongren",
"cityCode": 522201,
"pinYin": "TONGREN"
}
],
"W": [
{
"id": 5534,
"parentId": 0,
"regionName": "Wanning",
"cityCode": 469006,
"pinYin": "WANNING"
},
{
"id": 821,
"parentId": 0,
"regionName": "Weifang",
"cityCode": 370700,
"pinYin": "WEIFANG"
},
{
"id": 853,
"parentId": 0,
"regionName": "Weihai",
"cityCode": 371000,
"pinYin": "WEIHAI"
},
{
"id": 905,
"parentId": 0,
"regionName": "Weinan",
"cityCode": 610500,
"pinYin": "WEINAN"
},
{
"id": 5773,
"parentId": 0,
"regionName": "God of Literature",
"cityCode": 469005,
"pinYin": "WENCHANG"
},
{
"id": 3269,
"parentId": 0,
"regionName": "Wenshan",
"cityCode": 532600,
"pinYin": "WENSHAN"
},
{
"id": 1047,
"parentId": 0,
"regionName": "Wenzhou",
"cityCode": 330300,
"pinYin": "WENZHOU"
},
{
"id": 803,
"parentId": 0,
"regionName": "Wuhai",
"cityCode": 150300,
"pinYin": "WUHAI"
},
{
"id": 10,
"parentId": 0,
"regionName": "Wuhan",
"cityCode": 420100,
"pinYin": "WUHAN"
},
{
"id": 219,
"parentId": 0,
"regionName": "Wuhu",
"cityCode": 340200,
"pinYin": "WUHU"
},
{
"id": 5754,
"parentId": 0,
"regionName": "Wujiaqu",
"cityCode": 659004,
"pinYin": "WUJIAQU"
},
{
"id": 3630,
"parentId": 0,
"regionName": "Ulanqab",
"cityCode": 150900,
"pinYin": "WULANCHABU"
},
{
"id": 987,
"parentId": 0,
"regionName": "Urumqi",
"cityCode": 650100,
"pinYin": "WULUMUQI"
},
{
"id": 284,
"parentId": 0,
"regionName": "Wuwei",
"cityCode": 620600,
"pinYin": "WUWEI"
},
{
"id": 151,
"parentId": 0,
"regionName": "Wuxi",
"cityCode": 320200,
"pinYin": "WUXI"
},
{
"id": 3666,
"parentId": 0,
"regionName": "Wu Zhong",
"cityCode": 640300,
"pinYin": "WUZHONG"
},
{
"id": 374,
"parentId": 0,
"regionName": "Wuzhou",
"cityCode": 450400,
"pinYin": "WUZHOU"
}
],
"X": [
{
"id": 89,
"parentId": 0,
"regionName": "Xiamen",
"cityCode": 350200,
"pinYin": "XIAMEN"
},
{
"id": 46,
"parentId": 0,
"regionName": "Xi'an",
"cityCode": 610100,
"pinYin": "XIAN"
},
{
"id": 599,
"parentId": 0,
"regionName": "Xiangtan",
"cityCode": 430300,
"pinYin": "XIANGTAN"
},
{
"id": 602,
"parentId": 0,
"regionName": "Xiangxi",
"cityCode": 433100,
"pinYin": "XIANGXI"
},
{
"id": 731,
"parentId": 0,
"regionName": "Xiangyang",
"cityCode": 420600,
"pinYin": "XIANGYANG"
},
{
"id": 538,
"parentId": 0,
"regionName": "Xianning",
"cityCode": 421200,
"pinYin": "XIANNING"
},
{
"id": 569,
"parentId": 0,
"regionName": "peach of immortality",
"cityCode": 429004,
"pinYin": "XIANTAO"
},
{
"id": 918,
"parentId": 0,
"regionName": "Xianyang",
"cityCode": 610400,
"pinYin": "XIANYANG"
},
{
"id": 1160,
"parentId": 0,
"regionName": "Filial piety",
"cityCode": 420900,
"pinYin": "XIAOGAN"
},
{
"id": 3303,
"parentId": 0,
"regionName": "Xilin Gol",
"cityCode": 152500,
"pinYin": "XILINGUOLE"
},
{
"id": 3631,
"parentId": 0,
"regionName": "Xing'an League",
"cityCode": 152200,
"pinYin": "XINGAN"
},
{
"id": 441,
"parentId": 0,
"regionName": "Xingtai",
"cityCode": 130500,
"pinYin": "XINGTAI"
},
{
"id": 3679,
"parentId": 3646,
"regionName": "Xingyi ",
"cityCode": 522301,
"pinYin": "XINGYI",
"selected": 1
},
{
"id": 814,
"parentId": 0,
"regionName": "Xining",
"cityCode": 630100,
"pinYin": "XINING"
},
{
"id": 472,
"parentId": 0,
"regionName": "Xinxiang",
"cityCode": 410700,
"pinYin": "XINXIANG"
},
{
"id": 470,
"parentId": 0,
"regionName": "Xinyang",
"cityCode": 411500,
"pinYin": "XINYANG"
},
{
"id": 733,
"parentId": 0,
"regionName": "Xinyu",
"cityCode": 360500,
"pinYin": "XINYU"
},
{
"id": 3432,
"parentId": 0,
"regionName": "Xinzhou",
"cityCode": 140900,
"pinYin": "XINZHOU"
},
{
"id": 1010,
"parentId": 0,
"regionName": "Xishuangbanna",
"cityCode": 532800,
"pinYin": "XISHUANGBANNA"
},
{
"id": 224,
"parentId": 0,
"regionName": "Xuancheng",
"cityCode": 341800,
"pinYin": "XUANCHENG"
},
{
"id": 477,
"parentId": 0,
"regionName": "Xu Chang",
"cityCode": 411000,
"pinYin": "XUCHANG"
},
{
"id": 95,
"parentId": 0,
"regionName": "Xuzhou",
"cityCode": 320300,
"pinYin": "XUZHOU"
}
],
"Y": [
{
"id": 3438,
"parentId": 0,
"regionName": "Ya'an",
"cityCode": 511800,
"pinYin": "YAAN"
},
{
"id": 912,
"parentId": 0,
"regionName": "Yan'an",
"cityCode": 610600,
"pinYin": "YANAN"
},
{
"id": 3634,
"parentId": 0,
"regionName": "Yanbian",
"cityCode": 222400,
"pinYin": "YANBIAN"
},
{
"id": 642,
"parentId": 0,
"regionName": "ynz ",
"cityCode": 320900,
"pinYin": "YANCHENG"
},
{
"id": 329,
"parentId": 0,
"regionName": "Yangjiang",
"cityCode": 441700,
"pinYin": "YANGJIANG"
},
{
"id": 5750,
"parentId": 0,
"regionName": "Yangpu",
"cityCode": 469000,
"pinYin": "YANGPU"
},
{
"id": 1195,
"parentId": 0,
"regionName": "Yangquan",
"cityCode": 140300,
"pinYin": "YANGQUAN"
},
{
"id": 660,
"parentId": 0,
"regionName": "Yangzhou",
"cityCode": 321000,
"pinYin": "YANGZHOU"
},
{
"id": 105,
"parentId": 0,
"regionName": "Yantai",
"cityCode": 370600,
"pinYin": "YANTAI"
},
{
"id": 949,
"parentId": 0,
"regionName": "Yibin",
"cityCode": 511500,
"pinYin": "YIBIN"
},
{
"id": 565,
"parentId": 0,
"regionName": "Yichang",
"cityCode": 420500,
"pinYin": "YICHANG"
},
{
"id": 3463,
"parentId": 0,
"regionName": "Yichun",
"cityCode": 230700,
"pinYin": "YICHUN"
},
{
"id": 716,
"parentId": 0,
"regionName": "Yichun",
"cityCode": 360900,
"pinYin": "YICHUN"
},
{
"id": 1104,
"parentId": 0,
"regionName": "Ili ",
"cityCode": 654000,
"pinYin": "YILI"
},
{
"id": 810,
"parentId": 0,
"regionName": "Yinchuan",
"cityCode": 640100,
"pinYin": "YINCHUAN"
},
{
"id": 774,
"parentId": 0,
"regionName": "Yingkou",
"cityCode": 210800,
"pinYin": "YINGKOU"
},
{
"id": 1170,
"parentId": 0,
"regionName": "Yingtan",
"cityCode": 360600,
"pinYin": "YINGTAN"
},
{
"id": 4636,
"parentId": 151,
"regionName": "Yixing City",
"cityCode": 320282,
"pinYin": "YIXINGSHI",
"selected": 1
},
{
"id": 605,
"parentId": 0,
"regionName": "Yiyang",
"cityCode": 430900,
"pinYin": "YIYANG"
},
{
"id": 1164,
"parentId": 0,
"regionName": "Yongzhou",
"cityCode": 431100,
"pinYin": "YONGZHOU"
},
{
"id": 607,
"parentId": 0,
"regionName": "Yueyang",
"cityCode": 430600,
"pinYin": "YUEYANG"
},
{
"id": 378,
"parentId": 0,
"regionName": "Yulin",
"cityCode": 450900,
"pinYin": "YULIN"
},
{
"id": 914,
"parentId": 0,
"regionName": "Yulin",
"cityCode": 610800,
"pinYin": "YULIN"
},
{
"id": 888,
"parentId": 0,
"regionName": "Yuncheng",
"cityCode": 140800,
"pinYin": "YUNCHENG"
},
{
"id": 332,
"parentId": 0,
"regionName": "Yunfu",
"cityCode": 445300,
"pinYin": "YUNFU"
},
{
"id": 3664,
"parentId": 0,
"regionName": "Yushu",
"cityCode": 632700,
"pinYin": "YUSHU"
},
{
"id": 1012,
"parentId": 0,
"regionName": "Yuxi",
"cityCode": 530400,
"pinYin": "YUXI"
}
],
"Z": [
{
"id": 857,
"parentId": 0,
"regionName": "Zaozhuang",
"cityCode": 370400,
"pinYin": "ZAOZHUANG"
},
{
"id": 1236,
"parentId": 0,
"regionName": "Zhangjiajie",
"cityCode": 430800,
"pinYin": "ZHANGGUJIE"
},
{
"id": 443,
"parentId": 0,
"regionName": "Zhangjiakou",
"cityCode": 130700,
"pinYin": "ZHANGJIAKOU"
},
{
"id": 286,
"parentId": 0,
"regionName": "Zhangye",
"cityCode": 620700,
"pinYin": "ZHANGYE"
},
{
"id": 243,
"parentId": 0,
"regionName": "Zhangzhou",
"cityCode": 350600,
"pinYin": "ZHANGZHOU"
},
{
"id": 334,
"parentId": 0,
"regionName": "Zhanjiang",
"cityCode": 440800,
"pinYin": "ZHANJIANG"
},
{
"id": 337,
"parentId": 0,
"regionName": "Zhaoqing",
"cityCode": 441200,
"pinYin": "ZHAOQING"
},
{
"id": 3649,
"parentId": 0,
"regionName": "Zhaotong",
"cityCode": 530600,
"pinYin": "ZHAOTONG"
},
{
"id": 43,
"parentId": 0,
"regionName": "Zhengzhou",
"cityCode": 410100,
"pinYin": "ZHENGZHOU"
},
{
"id": 657,
"parentId": 0,
"regionName": "Zhenjiang",
"cityCode": 321100,
"pinYin": "ZHENJIANG"
},
{
"id": 339,
"parentId": 0,
"regionName": "Zhongshan",
"cityCode": 442000,
"pinYin": "ZHONGSHAN"
},
{
"id": 1184,
"parentId": 0,
"regionName": "Centre back",
"cityCode": 640500,
"pinYin": "ZHONGWEI"
},
{
"id": 93,
"parentId": 0,
"regionName": "Zhoukou",
"cityCode": 411600,
"pinYin": "ZHOUKOU"
},
{
"id": 1055,
"parentId": 0,
"regionName": "Zhoushan",
"cityCode": 330900,
"pinYin": "ZHOUSHAN"
},
{
"id": 346,
"parentId": 0,
"regionName": "Zhuhai",
"cityCode": 440400,
"pinYin": "ZHUHAI"
},
{
"id": 484,
"parentId": 0,
"regionName": "Zhumadian",
"cityCode": 411700,
"pinYin": "ZHUMADIAN"
},
{
"id": 597,
"parentId": 0,
"regionName": "Zhuzhou",
"cityCode": 430200,
"pinYin": "ZHUZHOU"
},
{
"id": 860,
"parentId": 0,
"regionName": "Zibo",
"cityCode": 370300,
"pinYin": "ZIBO"
},
{
"id": 955,
"parentId": 0,
"regionName": "Zigong",
"cityCode": 510300,
"pinYin": "ZIGONG"
},
{
"id": 957,
"parentId": 0,
"regionName": "Ziyang",
"cityCode": 512000,
"pinYin": "ZIYANG"
},
{
"id": 403,
"parentId": 0,
"regionName": "Zunyi",
"cityCode": 520300,
"pinYin": "ZUNYI"
}
]
}
}
jsonpath parsing
import json
import urllib.request
import jsonpath
url = 'https://dianying.taobao.com/cityAction.json?activityId&_ksTS=1631540514150_161&jsoncallback=jsonp162&action=cityAction&n_s=new&event_submit_doGetAllRegion=true'
headers = {
# The request header with colon in front of key cannot be used, otherwise an error will be reported
# ':authority': 'dianying.taobao.com',
# ':method': 'GET',
# ':path': '/cityAction.json?activityId&_ksTS=1631540514150_161&jsoncallback=jsonp162&action=cityAction&n_s=new&event_submit_doGetAllRegion=true',
# ':scheme': 'https',
'accept': 'text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01',
# 'accept-encoding': 'gzip, deflate, br', # This should be commented out when crawling
'accept-language': 'en-GB,en-US;q=0.9,en;q=0.8,zh-CN;q=0.7,zh;q=0.6',
'cookie': 't=ecfbe37814c28d684d543bc8a9cf89f9; cookie2=1d725fe9f811152c0ff023c5109e28e1; v=0; _tb_token_=e37316037eb4e; cna=YSfGGUtwOmcCAXFC+2y7V2PJ; xlly_s=1; tb_city=110100; tb_cityName="sbG+qQ=="; tfstk=c0KABPmINbcDgg6JLE3o1BAF2fkhaLkAa-6YXx0MywtQIbEgbsDpxHKJTq14MgHR.; l=eBPLFCPegb7ITPVABOfwhurza77O9IRAguPzaNbMiOCPOafH5n7PW633bMYMCnGNhswDR35NsM4TBeYBqSvjjqj4axom4ADmn; isg=BHl5FuwqPFeSCODDMj1A6FF_iOVThm04oHsdm5uuyKAfIpm049c1CKv0pC7UmgVw',
'referer': 'https://dianying.taobao.com/?spm=a1z21.3046609.city.1.4660112a8qwKLc&city=110100',
'sec-ch-ua': '"Google Chrome";v="93", " Not;A Brand";v="99", "Chromium";v="93"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36',
'x-requested-with': 'XMLHttpRequest',
}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
# Use split() to cut off the start jsonp162 (and end jsonp162);
content = content.split('(')[1].split(')')[0]
# Save to local
with open('file/jsonpath Analysis of ticket panning.json', 'w', encoding='utf-8') as downloadFile:
downloadFile.write(content)
obj = json.load(open('file/jsonpath Analysis of ticket panning.json', 'r', encoding='utf-8'))
city_list = jsonpath.jsonpath(obj, '$..regionName')
print(city_list)
Exercise: (code omitted)
-
Stock information extraction( http://quote.stockstar.com/ )
-
boos direct employment
-
Chinese talents
-
Car home
3.BeautifulSoup
3.1 introduction
Beautiful soup is abbreviated as bs4. Like lxml, beautiful soup is an html parser. Its main function is to parse and extract data
Advantages and disadvantages
- Advantages: the interface design is humanized and easy to use
- Disadvantages: not as efficient as lxml
3.2 installation and creation
Note: the installation path is consistent with the library path (Scripts directory path) of python, such as D: \ develop \ Python \ Python 39 \ Scripts
# install
pip install bs4
# Import
from bs4 import BeautifulSoup
# create object
# Local files generate objects. Note: by default, the encoding format of open files is gbk, so you need to specify the opening encoding format
soup = BeautifulSoup(open('xxx.html', encoding='utf-8'), 'lxml')
# File generation object for server response
soup = BeautifulSoup(response.read().decode(), 'lxml')
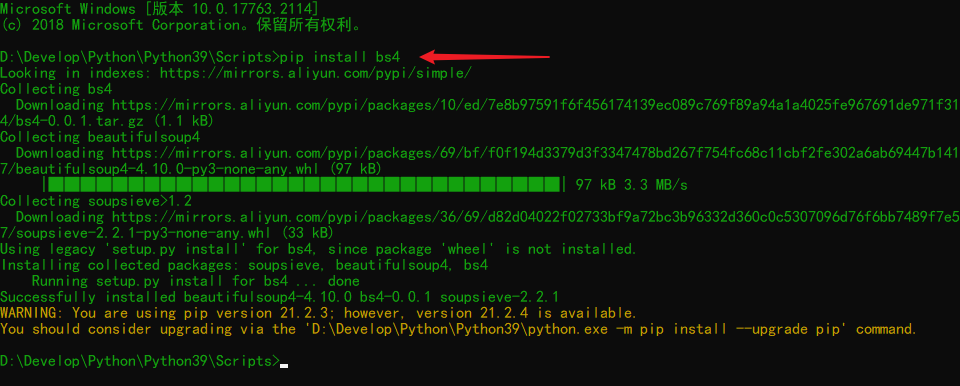
Example local file: 1905.html
<!DOCTYPE html>
<html lang="zh-cmn-Hans">
<head>
<meta charset="utf-8"/>
<title>Movie Network_1905.com</title>
<meta property="og:image" content="https://static.m1905.cn/144x144.png"/>
<link rel="dns-prefetch" href="//image14.m1905.cn"/>
<style>
.index-carousel .index-carousel-screenshot {
background: none;
}
</style>
</head>
<body>
<!-- Movie number -->
<div class="layout-wrapper depth-report moive-number">
<div class="layerout1200">
<h3>
<span class="fl">Movie number</span>
<a href="https://Www.1905. COM / dianyinghao / "class =" fr "target =" _blank "> more</a>
</h3>
<ul class="clearfix">
<li id="1">
<a href="https://www.1905.com/news/20210908/1539457.shtml">
<img src="//static.m1905.cn/images/home/pixel.gif"/></a>
<a href="https://www.1905.com/dianyinghao/detail/lst/95/">
<img src="//static.m1905.cn/images/home/pixel.gif"/>
<em>Mirror Entertainment</em>
</a>
</li>
<li id="2">
<a href="https://www.1905.com/news/20210910/1540134.shtml">
<img src="//static.m1905.cn/images/home/pixel.gif"/></a>
<a href="https://www.1905.com/dianyinghao/detail/lst/75/">
<img src="//static.m1905.cn/images/home/pixel.gif"/>
<em>Entertainment Capital</em>
</a>
</li>
<li id="3">
<a href="https://www.1905.com/news/20210908/1539808.shtml">
<img src="//static.m1905.cn/images/home/pixel.gif"/>
</a>
<a href="https://www.1905.com/dianyinghao/detail/lst/59/">
<img src="//static.m1905.cn/images/home/pixel.gif"/>
<em>Rhinoceros Entertainment</em>
</a>
</li>
</ul>
</div>
</div>
<!-- Links -->
<div class="layout-wrapper">
<div class="layerout1200">
<section class="frLink">
<div>Links</div>
<p>
<a href="http://Www.people.com.cn "target =" _blank "> people.com</a>
<a href="http://Www.xinhuanet.com/ "target =" _blank "> xinhuanet.com</a>
<a href="http://Www.china. Com. CN / "target =" _blank "> china.com</a>
<a href="http://Www.cnr.cn "target =" _blank "> cnr.com</a>
<a href="http://Www.legaldaily. Com. CN / "target =" _blank "> Legal Network</a>
<a href="http://Www.most. Gov.cn / "target =" _blank "> Ministry of science and technology</a>
<a href="http://Www.gmw.cn "target =" _blank "> guangming.com</a>
<a href="http://News.sohu.com "target =" _blank "> Sohu News</a>
<a href="https://News.163.com "target =" _blank "> Netease News</a>
<a href="https://Www.1958xy. COM / "target =" _blank "style =" margin right: 0; "> xiying.com</a>
</p>
</section>
</div>
</div>
<!-- footer -->
<footer class="footer" style="min-width: 1380px;">
<div class="footer-inner">
<h3 class="homeico footer-inner-logo"></h3>
<p class="footer-inner-links">
<a href="https://Www.1905. COM / about / aboutus / "target =" _blank "> about us < / a > < span >|</span>
<a href="https://Www.1905.com/sitemap.html "target =" _blank "> website map < / a > < span >|</span>
<a href="https://Www.1905. COM / jobs / "target =" _blank "> looking for talents < / a > < span >|</span>
<a href="https://Www.1905. COM / about / copyright / "target =" _blank "> copyright notice < / a > < span >|</span>
<a href="https://Www.1905. COM / about / contactus / "target =" _blank "> contact us < / a > < span >|</span>
<a href="https://Www.1905. COM / error_report / error_report-p-pid-125-cid-126-tid-128. HTML "target =" _blank "> help and feedback < / a > < span >|</span>
<a href="https://Www.1905. COM / link / "target =" _blank "> link < / a > < span >|</span>
<a href="https://Www.1905. COM / CCTV 6 / advertisement / "target =" _blank "> CCTV 6 advertising < / a > <! -- < span >|</span>
<a href="javascript:void(0)">Associated Media</a>-->
</p>
<div class="footer-inner-bottom">
<a href="https://Www.1905. COM / about / license / "target =" _blank "> network audio visual license No. 0107199</a>
<a href="https://www.1905.com/about/cbwjyxkz/" target="_ Blank "> publication business license</a>
<a href="https://Www.1905. COM / about / dyfxjyxkz / "target =" _blank "> film distribution license</a>
<a href="https://www.1905.com/about/jyxyc/" target="_ Blank "> business performance license</a>
<a href="https://Www.1905. COM / about / gbdsjm / "target =" _blank "> Radio and television program production and operation license</a>
<br/>
<a href="https://www.1905.com/about/beian/" target="_ Blank "> business license of enterprise legal person</a>
<a href="https://Www.1905. COM / about / zzdxyw / "target =" _blank "> value added telecom business license</a>
<a href="http://beian.miit.gov.cn/" target="_ Blank "> Jing ICP Bei 12022675-3</a>
<a href="http://Www.beian. Gov.cn / portal / registersysteminfo? Recordcode = 11010202000300 "target =" _blank "> jinggong.com.anbei No. 11010202000300</a>
</div>
</div>
</footer>
<!-- copyright -->
<div class="copy-right" style="min-width: 1380px;">
<div class="copy-right-conts clearfix">
<div class="right-conts-left fl">
<span>CopyRight © 2017</span>
<em>Official website of film channel program center</em><em class="conts-left-margin">|</em>
<em>
<a href="https://www.1905.com/about/icp/" target="_ Blank "> Beijing ICP certificate 100935</a>
</em>
</div>
</div>
</div>
<!-- Back to top -->
<div class="return-top index-xicon"></div>
<script src="//static.m1905.cn/homepage2020/PC/js/main20201016.min.js?t=20201102"></script>
<!--Statistical code-->
<script type="text/javascript" src="//js.static.m1905.cn/pingd.js?v=1"></script>
</body>
</html>
Example: parsing a local file, 1905.html
from bs4 import BeautifulSoup
# Parsing local files
soup = BeautifulSoup(open('1905.html', encoding='utf-8'), 'lxml')
print(soup)
3.3 node positioning
from bs4 import BeautifulSoup
# Parsing local files
soup = BeautifulSoup(open('1905.html', encoding='utf-8'), 'lxml')
# 1. Find nodes by tag name
soup.a # View the first a label
soup.a.name # View the tag name of the first a tag
soup.a.attrs # View the attributes and attribute values of the first a tag
print(soup.a) # Find the first a label
print(soup.a.name) # Find the tag name of the first a tag
print(soup.a.attrs) # Find the attribute and attribute value of the first a tag
# 2. Function
# (1) find(): returns the first qualified data and the returned object
find('a') # Find the first a label
find('a', target="Attribute value") # Find the a tag whose first attribute target is the attribute value
find('a', class_='Attribute value') # Find the a tag with the first attribute class fr. class_ is to distinguish the keyword class used by python
print(soup.find('a')) # Find the first a label
print(soup.find('a', target="_blank")) # Find the a tag with the first attribute target _blank
print(soup.find('a', class_='fr')) # Find the a tag with the first attribute class fr. class_ is to distinguish the keyword class used by python
# (2) find_all(): returns all data that meets the criteria, and a list is returned
find_all('a') # Find all a
find_all(['a', 'span']) # Returns all a and span
find_all('a', limit=2) # Only find the a label with the number of previous constraints
print(soup.find_all('a')) # Find all a Tags
print(soup.find_all(['a', 'span'])) # Find all a and span Tags
print(soup.find_all('a', limit=2)) # Find only the first 2 a Tags
# (3) select(): returns the node object according to the selector, and a list is returned [recommended]
# ① element eg: p
# ② . class (class selector) eg:. firstname
# ③ #id(id (selector) eg: #firstname
# ④ [attribute] (attribute selector) eg: li = soup.select('li[class] ')
# [attribute=value] eg: li = soup.select('li[class="hengheng1"]')
# ⑤ (level selector) eg: soup = soup.select('a,span ')
# Element (descendant selector) eg: div p
# Element > element eg: div > p
# element , element eg: div,p
print(soup.select('a')) # Returns all a tags
print(soup.select('.frLink')) # Returns all labels and sub labels with. frLink in the class selector
print(soup.select('#list2')) # Returns all tags and sub tags with list2 in the id selector
print(soup.select('li[id]')) # Returns all tags and sub tags with id in the attribute selector
print(soup.select('li[id=list3]')) # Returns all tags and sub tags with id=list3 in the attribute selector
print(soup.select('div li')) # Returns all li tags and sub tags of div in the descendant level selector
print(soup.select('div > ul')) # Returns all ul tags and child tags of div in the descendant level selector, and the first level child tag under the parent tag
print(soup.select('div , ul')) # Returns all div tags and ul tags and sub tags
3.4 node information
from bs4 import BeautifulSoup
# Parsing local files
soup = BeautifulSoup(open('1905.html', encoding='utf-8'), 'lxml')
obj = soup.select('#list2')[0]
# (1) Get node content: applicable to the structure of nested labels in labels
obj.string
obj.get_text() # [recommended]
# If there is only content in the tag object, both string and get_text() can be used
# If the tag object contains not only content but also tags, the string cannot get the data, but get_text() can get the data. Generally, it is recommended to use get_text()
print(obj.string) # Get node content
print(obj.get_text()) # Get node content [recommended]
# (2) Properties of nodes
tag.name # Get tag name
tag.attrs # Returns the property value as a dictionary
print(obj.name) # Get node name
print(obj.attrs) # Get the node attribute value and return a dictionary
# (3) Get node properties
obj.attrs.get('title') # [common]
obj.get('title')
obj['title']
print(obj.attrs.get('class')) # Get node properties
print(obj.get('class')) # Get node properties
print(obj['class']) # Get node properties
Application example:
1. Stock information extraction( http://quote.stockstar.com/)
2. China Talent Network - old version
3. Capture the recruitment needs of Tencent( https://hr.tencent.com/index.php)
4,Selenium
1.Selenium
1.1 introduction to selenium
Selenium is a tool for testing Web applications.
Selenium tests run directly in the browser, just like real users.
It supports driving real browsers to complete testing through various drivers (FirfoxDriver, IternetExplorerDriver, opera driver, ChromeDriver).
selenium also supports browser operation without interface.
1.2 reasons for using selenium
Simulate the browser function, automatically execute the js code in the web page, and realize dynamic loading
1.3 download and install selenium
Operating Google browser driver download address: http://chromedriver.storage.googleapis.com/index.html
Mapping table between Google driver and Google browser version: http://blog.csdn.net/huilan_same/article/details/51896672 [it's too old and out of date. It's useless. It's already 9x old, so it's meaningless. There's no need to read it]
View Google browser version: top right corner of Google browser -- > help -- > about
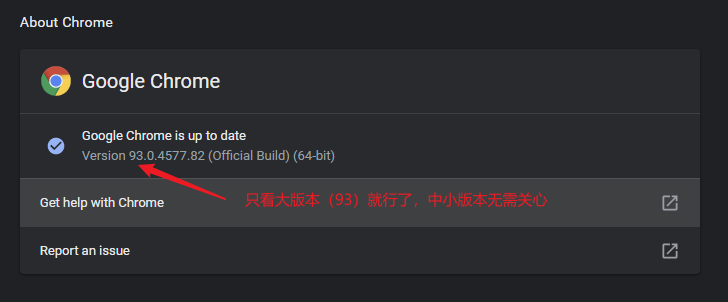
Download driver: http://chromedriver.storage.googleapis.com/index.html
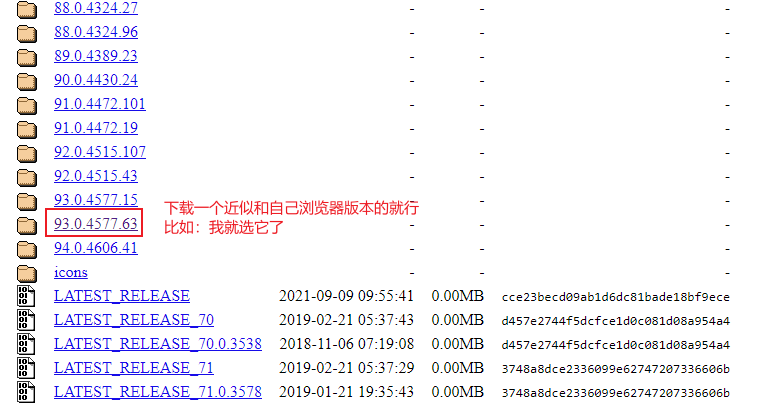
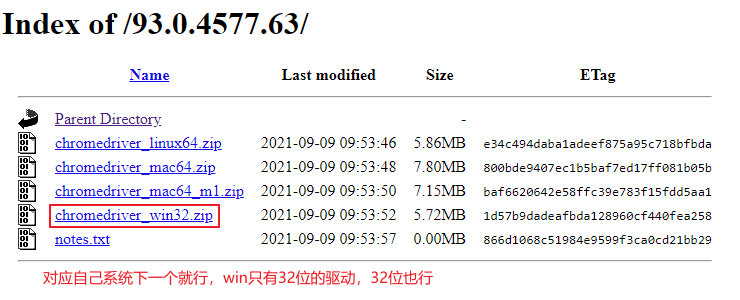
Unzip the copy and paste it into the project
You can also paste it into a custom directory
To install selenium:
Note: the installation path is consistent with the library path (Scripts directory path) of python, such as D: \ develop \ Python \ Python 39 \ Scripts
pip install selenium
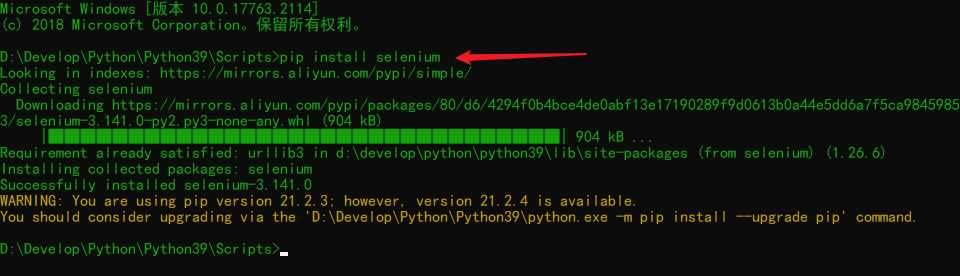
1.4 use of selenium
# (1) Import from selenium import webdriver # (2) Create a Google browser action object path = 'Google browser driver file path' browser = webdriver.Chrome(path) # (3) Visit website url = Web address to visit browser.get(url)
Before the use of selenium: (the response data is incomplete, some data is missing, and the simulated browser)
# Climb Jingdong second kill
# https://www.jd.com/
import urllib.request
url = 'https://www.jd.com/'
response = urllib.request.urlopen(url)
content = response.read().decode('utf-8')
print(content)
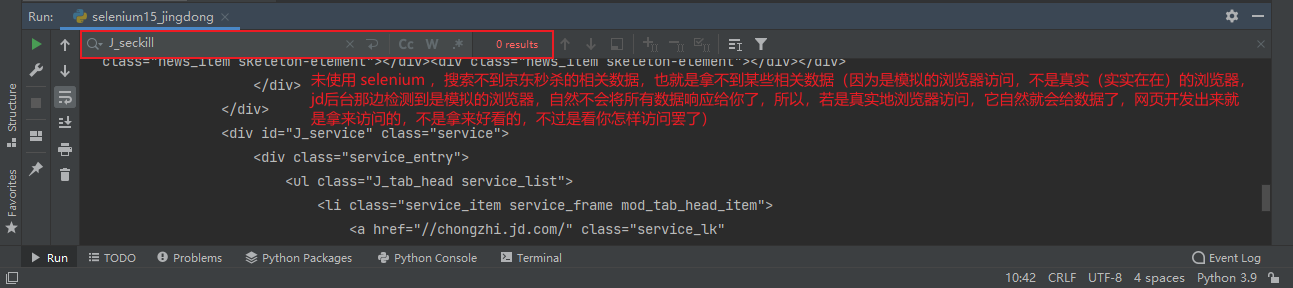
After the use of selenium: (complete response data, real browser)
from selenium import webdriver # Create browser action object path = 'chromedriver.exe' browser = webdriver.Chrome(path) # Visit website # url = 'https://www.baidu.com/' url = 'https://www.jd.com/' browser.get(url) # page_source: get the web page source code content = browser.page_source print(content)
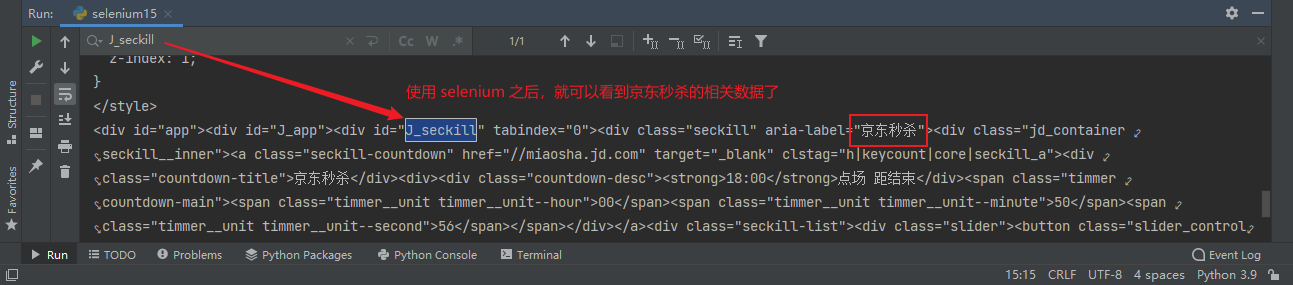
1.4.1 element positioning of selenium
Element positioning: what automation needs to do is to simulate the operation of mouse and keyboard to operate these elements, click, input, etc. before operating these elements, we must first find them. WebDriver provides many methods to locate elements
from selenium import webdriver
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
url = 'https://www.baidu.com/'
browser.get(url)
# Element positioning (a method without s is a single, and a method with s is multiple)
# find_element_by_id(): find an object by ID [common]
button = browser.find_element_by_id('su')
print(button)
# find_element_by_name(): get the object according to the attribute value of the tag attribute
button = browser.find_element_by_name('wd')
print(button)
# find_elements_by_xpath(): get objects according to XPath statements [common]
button = browser.find_elements_by_xpath('//input[@id="su"]')
print(button)
# find_element_by_tag_name(): get the object according to the name of the tag
button = browser.find_element_by_tag_name('input')
print(button)
# find_element_by_css_selector(): bs4 syntax is used to obtain the object [common]
button = browser.find_element_by_css_selector('#su')
print(button)
# find_element_by_link_text(): get the object according to the connection text
button = browser.find_element_by_link_text('live broadcast')
print(button)
1.4.2 accessing element information
# Get element properties
get_attribute('class')
# Get element text
text
# Get tag name
tag_name
from selenium import webdriver
# Access element information
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
url = 'https://www.baidu.com/'
browser.get(url)
input = browser.find_element_by_id('su')
print(input.get_attribute('class')) # Get element properties
print(input.tag_name) # Get element text
a = browser.find_element_by_link_text('Journalism')
print(a.text) # Get tag name
1.4.3 interaction
Simulate the operation of mouse and keyboard.
# click click() # input send_keys() # back off browser.back() # forward browser.forword() # Simulate JS scrolling js='document.documentElement.scrollTop=100000' browser.execute_script(js) # Execute js code # Get web source code page_source # sign out browser.quit()
Example: open Baidu web page - search keyword snow and ice - sleep for 2 seconds - slide to the bottom - sleep for 2 seconds - next page - sleep for 2 seconds - return to the previous page - sleep for 2 seconds - move forward - sleep for 3 seconds - exit
import time
from selenium import webdriver
# interactive
# Create browser objects
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
# url
url = 'https://www.baidu.com/'
browser.get(url)
# Sleep for 2 seconds
time.sleep(2)
# Get text box object
input = browser.find_element_by_id('kw')
# Enter the keyword you want to search in the text box
input.send_keys('Frozen')
# Sleep for another two seconds
time.sleep(2)
# Get Baidu's button
button = browser.find_element_by_id('su')
# Click the button
button.click()
time.sleep(2)
# Slide down to the bottom
js_bottom = 'document.documentElement.scrollTop=100000'
browser.execute_script(js_bottom) # Execute js code
# Get button for next page
next_page = browser.find_element_by_xpath('//a[@class="n"]')
# Click next
next_page.click()
time.sleep(2)
# Return to previous page
browser.back()
time.sleep(2)
# Move on
browser.forward()
time.sleep(3)
# Last exit
browser.quit()
2. Phantom JS [stop watch, replaced by headless]
2.1 introduction to phantomjs
- Is a browser without interface
- Support page element search, js execution, etc
- Without css and gui rendering, it runs much faster than a real browser
2.2 download and installation of phantomjs
The download and installation method is the same as selenium
Download from the official website: https://phantomjs.org/download.html
GitHub source code: https://github.com/ariya/phantomjs/ [obviously, the update has also been stopped]
Download from the official website
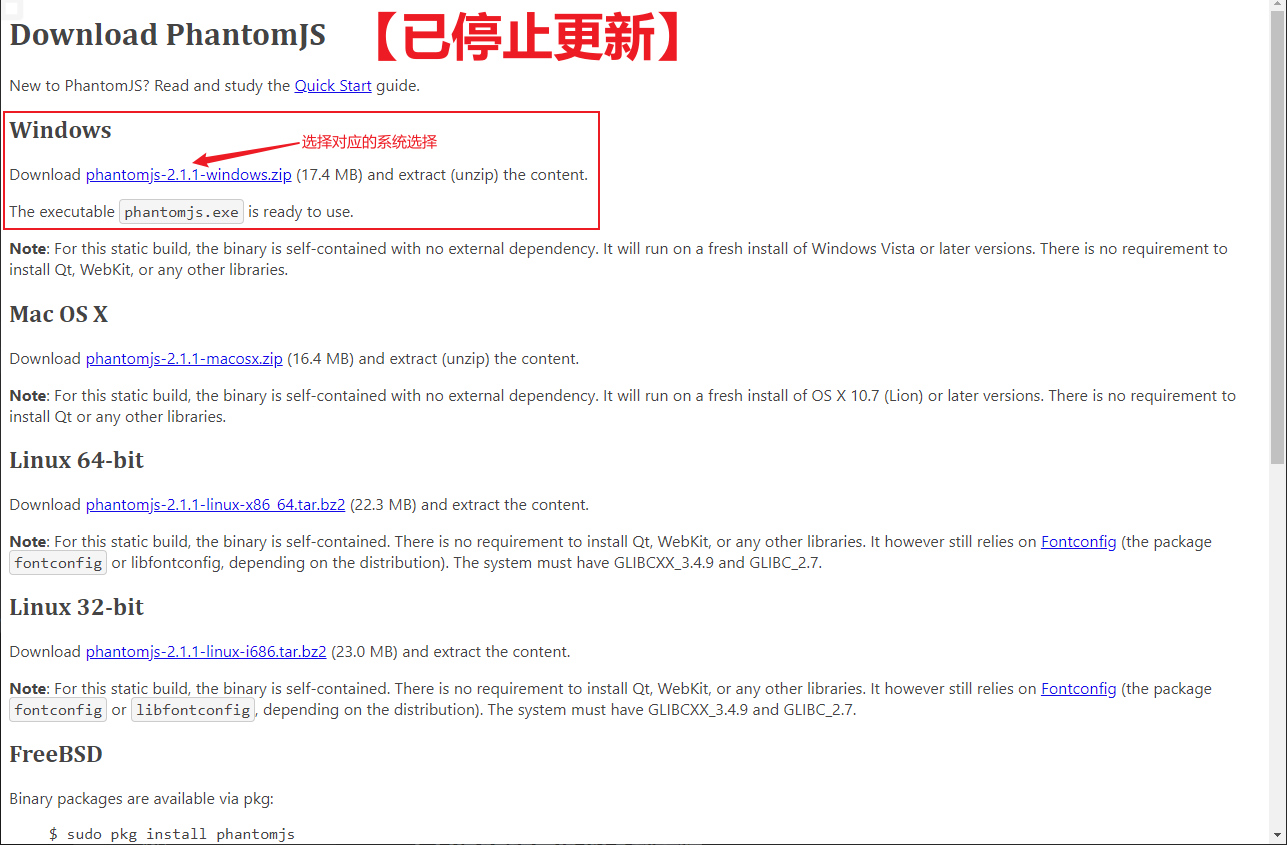
Or GitHub Download
Unzip the copy and paste it into the project
Put it in the current project path or in the user-defined directory
2.3 use of phantomjs
# Get the path of PhantomJS.exe file path
path = 'xxx/phantomjs.exe.exe'
browser = webdriver.PhantomJS(path)
browser.get(url)
# Note: save screenshot
browser.save_screenshot('baidu.png')
After use, you can see the prompt of stopping and updating:
import time
from selenium import webdriver
# Get the path of PhantomJS.exe file path
path = 'phantomjs.exe'
browser = webdriver.PhantomJS(path)
url = 'https://www.baidu.com'
browser.get(url)
# Note: save screenshot
browser.save_screenshot('screenshot/baidu.png')
time.sleep(2)
input_text = browser.find_element_by_id('kw')
input_text.send_keys('Phantomjs Official website')
time.sleep(3)
browser.save_screenshot('screenshot/phantomjs.png')
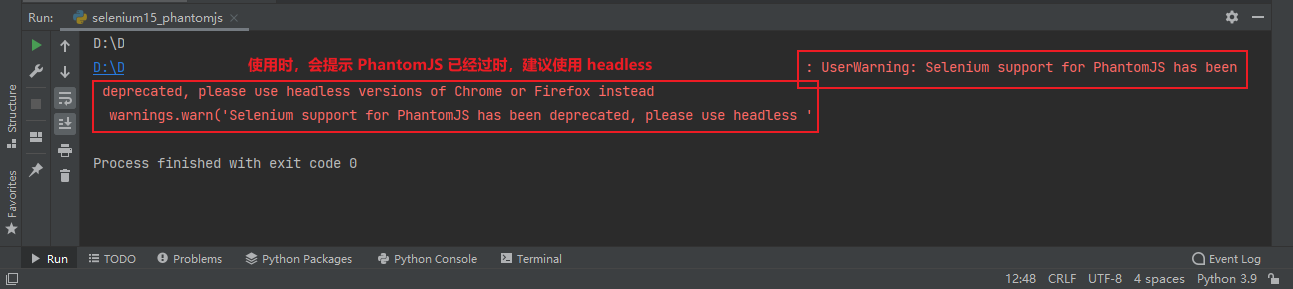
3.headless chrome
Chrome headless mode, a new mode added by Google for Chrome browser version 59, allows you to use Chrome browser without opening the UI interface, so the operation effect is perfectly consistent with chrome, and the performance is higher than that of opening the interface.
3.1 system requirements
Chrome
- Unix\Linux system: requires chrome > = 59
- Windows system: requires chrome > = 60
Python >= 3.6
Selenium >= 3.4.x
ChromeDriver >= 2.31
3.2 use of headless Chrome
3.2.1 configuration
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# headless not encapsulated
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# Path: is the file path of the Chrome browser chrome.exe you installed (usually located in C:\Program Files\Google\Chrome\Application)
path = r'C:\Program Files\Google\Chrome\Application\chrome.exe'
chrome_options.binary_location = path
# browser = webdriver.Chrome(chrome_options=chrome_options)
browser = webdriver.Chrome(options=chrome_options)
url = 'https://www.baidu.com/'
browser.get(url)
browser.save_screenshot('screenshot/baidu1.png')
3.2.2 configuration encapsulated in method
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# Encapsulate headless into methods
def share_browser():
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# Path: is the file path of the Chrome browser chrome.exe you installed (usually located in C:\Program Files\Google\Chrome\Application)
path = r'C:\Program Files\Google\Chrome\Application\chrome.exe'
chrome_options.binary_location = path
# browser = webdriver.Chrome(chrome_options=chrome_options)
browser = webdriver.Chrome(options=chrome_options)
return browser
# Call method
browser = share_browser()
url = 'https://www.baidu.com/'
browser.get(url)
browser.save_screenshot('screenshot/baidu2.png')
Obsolete warning
DeprecationWarning: use options instead of chrome_options browser = webdriver.Chrome(chrome_options=chrome_options)
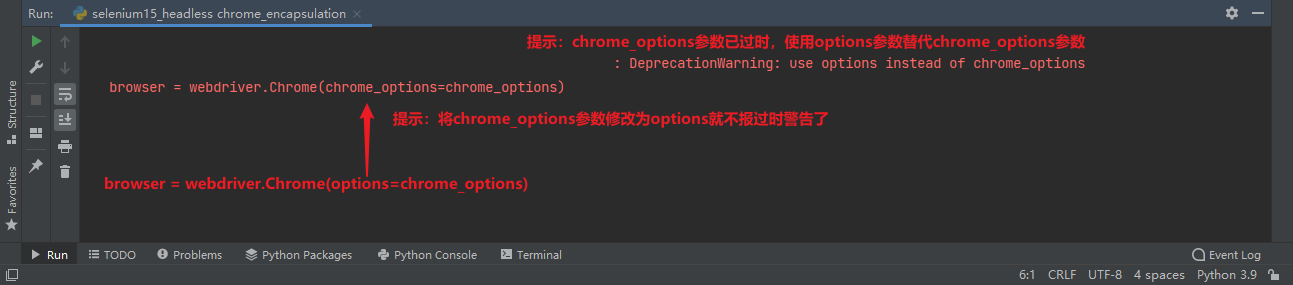
View source code description
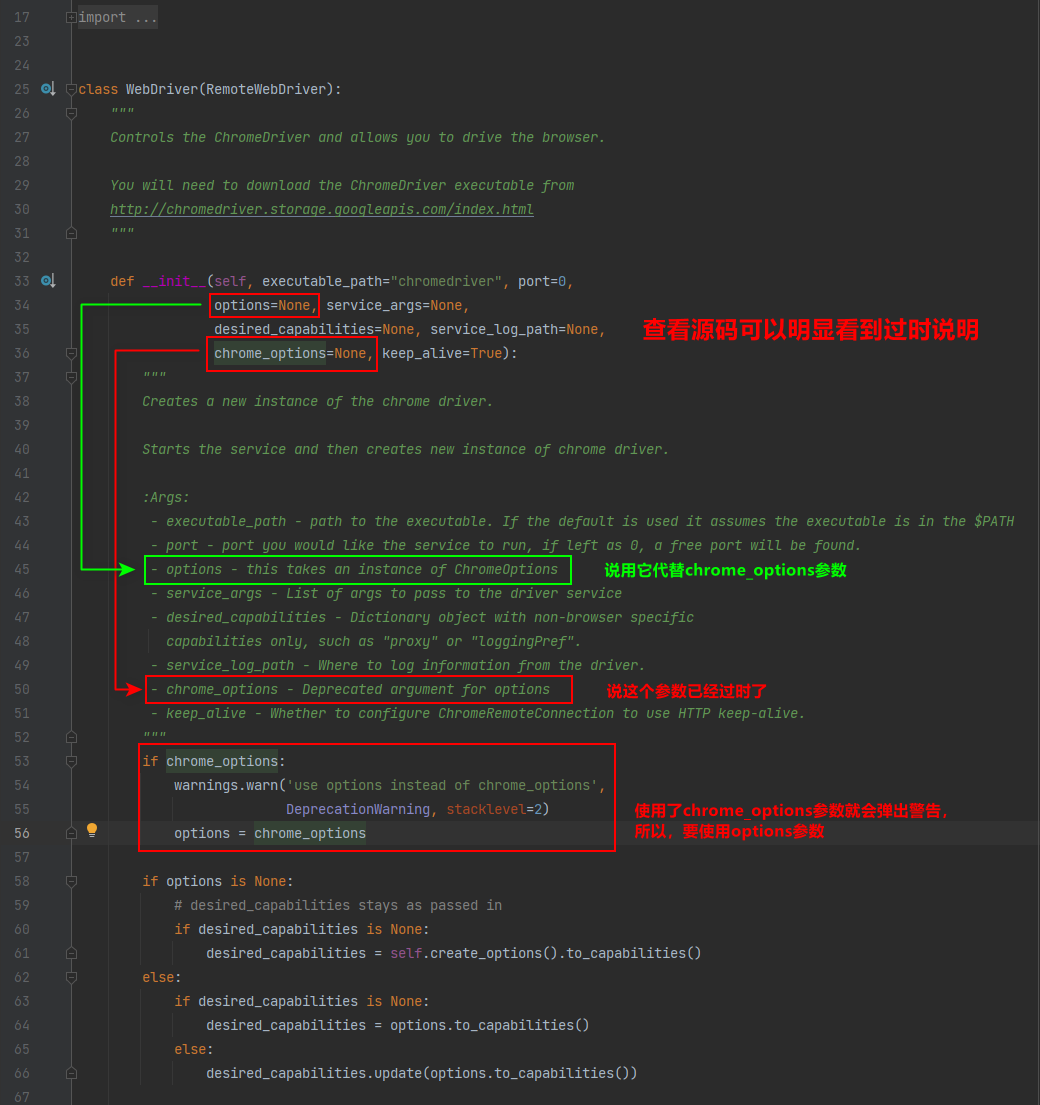
resolvent
# Replace the parameter options with chrome_options. After replacement, the obsolete warning will not be reported # browser = webdriver.Chrome(chrome_options=chrome_options) browser = webdriver.Chrome(options=chrome_options)
5,Requests
# urllib and requests # urllib # 1.1 types and 6 methods # 2.get request # 3.post request Baidu translation # 4. get request of Ajax # 5. post request for Ajax # 6. Log in to microblog with cookie # 7. Agency # requests # 1.1 types and 6 attributes # 2.get request # 3.post request # 4. Agency # 5.cookie login verification code
1. Official documents
Official documents: http://cn.python-requests.org/zh_CN/latest/
Quick start: http://cn.python-requests.org/zh_CN/latest/user/quickstart.html
2. Installation
Note: the installation path is consistent with the library path (Scripts directory path) of python, such as D: \ develop \ Python \ Python 39 \ Scripts
pip install requests
3.1 types and 6 attributes
models.Response # type response.text # Get the website source code response.encoding # Access or customize encoding response.url # Get the url of the request response.content # Byte type of response response.status_code # Response status code response.headers # Response header information
import requests url = 'https://www.baidu.com' response = requests.get(url=url) # 1 type and 6 attributes # response type print(type(response)) # <class 'requests.models.Response'> # Set the encoding format of the response response.encoding = 'utf-8' # Return the website source code in the form of string (without setting the code, Chinese will be garbled) print(response.text) # Get web source code # Returns the url of the request print(response.url) # Returns binary data print(response.content) # Returns the status code of the response print(response.status_code) # Return response header information print(response.headers)
4.get request
Custom parameters
- Parameters are passed using params
- Parameters do not require urlencode encoding
- No customization of the request object is required
- Request resource path? You can add it or not
import requests
# https://www.baidu.com/s?ie=UTF-8&wd=%E5%8C%97%E4%BA%AC
# url = 'https://www.baidu.com/?https://www.baidu.com/s?ie=UTF-8&'
url = 'https://www.baidu.com/?'
headers = {
'User‐Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'
}
data = {
'wd': 'Beijing'
}
# url: request resource path
# params: parameters
# kwargs: Dictionary
# In python 3.9, specifying headers here will report an error, and not specifying headers here will not report an error
# response = requests.get(url, params=data, headers=headers)
response = requests.get(url, params=data)
response.encoding = 'utf-8'
content = response.text
print(content)
5.post request
The difference between get and post requests
- The parameter name of the get request is params, and the parameter name of the post request is data
- The request resource path can be left blank?
- Manual encoding and decoding is not required
- There is no need to customize the request object
import json
import requests
# Baidu Translate
post_url = 'https://fanyi.baidu.com/sug'
headers = {
'User‐Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
data = {
'kw': 'snow'
}
# In python 3.9, specifying headers here will report an error, and not specifying headers here will not report an error
# response = requests.post(url=post_url, data=data, headers=headers)
response = requests.post(url=post_url, data=data)
# response.encoding = 'utf-8'
content = response.text
# In python 3.9, if encoding is specified here, an error will be reported. If it is not specified, no error will be reported
# obj = json.loads(content, encoding='utf-8')
obj = json.loads(content)
print(obj)
6. Agency
proxy customization
Set the proxies parameter in the request. The parameter type is a dictionary type
Express agent: https://www.kuaidaili.com/free/ [free is generally difficult to use. You can buy it - generate API links]
import json
import requests
url = 'http://www.baidu.com/s?'
headers = {
'User‐Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
data = {
'wd': 'ip'
}
proxy = {
'https://': '211.65.197.93:80'
}
# In python 3.9, specifying headers here will report an error, and not specifying headers here will not report an error
# response = requests.get(url, params=data, headers=headers)
response = requests.get(url, params=data, proxies=proxy)
response.encoding = 'utf-8'
content = response.text
with open('file/proxy_requests.html', 'w', encoding='utf-8') as download:
download.write(content)
7.cookie customization
cookie customization
Application case:
- (1) Ancient poetry network (to be verified)
- (2) Cloud coding platform (super) 🦅: https://www.chaojiying.com/)
practice:
National Bureau of Statistics( http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2017/ )Total 680000
National Bureau of Statistics( http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2018/)
National Bureau of Statistics( http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/)
National Bureau of Statistics( http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2020/)
Ancient poetry network code
import urllib.request
import requests
from bs4 import BeautifulSoup
# Log in to the main page
# It is found through the login interface that many parameters are required during login
# _VIEWSTATE: WgkBYQCmEeLuyAPdsCmmvjx7mj9WC2t2IjRor1QxMqig8FFcVx++XIZ9JfNvLFpGXUZ6jzElZyvlCKGybrnuwJ8RvkpVdHk2DKrQ/yqnyF7hIXmu73P8R+VpImg=
# __VIEWSTATEGENERATOR: C93BE1AE
# from: http://so.gushiwen.cn/user/collect.aspx
# email: 595165358@qq.com
# pwd: action
# code: i2sd
# denglu: Login
# It is found that: _VIEWSTATE, _viewstategeneratorand code are the amount of change
# Difficulties: (① hidden domain problem, ② verification code problem)
# ① _VIEWSTATE,__VIEWSTATEGENERATOR # Generally, the invisible data is in the source code of the page. Therefore, you need to obtain the page source code and analyze it
# ② Verification code
# Address of the login page
# https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
headers = {
'User‐Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
# Get the source code of the page
# In python 3.9, specifying headers here will report an error, and not specifying headers here will not report an error
# response = requests.get(url, params=data, headers=headers)
response = requests.get(url)
response.encoding = 'utf-8'
content = response.text
# Analyze the page source code, and then obtain _VIEWSTATE and _VIEWSTATEGENERATOR
soup = BeautifulSoup(content, 'lxml')
# Get _VIEWSTATE
viewstate = soup.select('#__VIEWSTATE')[0].attrs.get('value')
# Get VIEWSTATEGENERATOR
viewstategenerator = soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value')
# Get verification code picture
# //*[@id="imgCode"]
code = soup.select('#imgCode')[0].attrs.get('src')
code_url = 'https://so.gushiwen.cn' + code
# Get the picture of the verification code, download it locally, then observe the verification code, enter the verification code on the console, and then you can pass the value of the verification code to the code parameter, so as to realize the login function
# Download verification code image to local
# urllib.request.urlretrieve(url=url, filename='file/code/code.jpg') # Here, a verification code is requested, and the following requests.post() requests another verification code. The verification codes of the two requests are obviously inconsistent
# session() method in requests: the request can be turned into an object through the return value of session
session = requests.session()
# url content of verification code
response_code = session.get(code_url)
# Note that binary data (content download) should be used at this time. text download cannot be used because pictures need to be downloaded
content_code = response_code.content
# wb: write binary data to file
with open('file/code/code.jpg', 'wb') as down:
down.write(content_code)
code_value = input('Please enter the value of the verification code: ')
# Click login
url_post = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
data_post = {
'__VIEWSTATE': viewstate,
'__VIEWSTATEGENERATOR': viewstategenerator,
'from': 'http://so.gushiwen.cn/user/collect.aspx',
'email': '595165358@qq.com',
'pwd': 'action',
'code': code_value,
'denglu': 'Sign in',
}
# response_post = requests.post(url=url, headers=headers, data=data_post)
response_post = session.post(url=url, data=data_post) # Change the request into the same request and use session. Here, you still can't pass the headers. If you pass it, an error will still be reported
content_post = response_post.text
with open('file/gushiwen.html', 'w', encoding='utf-8') as download:
download.write(content_post)
Cloud coding platform - Super Eagle
Official website homepage: https://www.chaojiying.com/ -->Development documentation

Click download
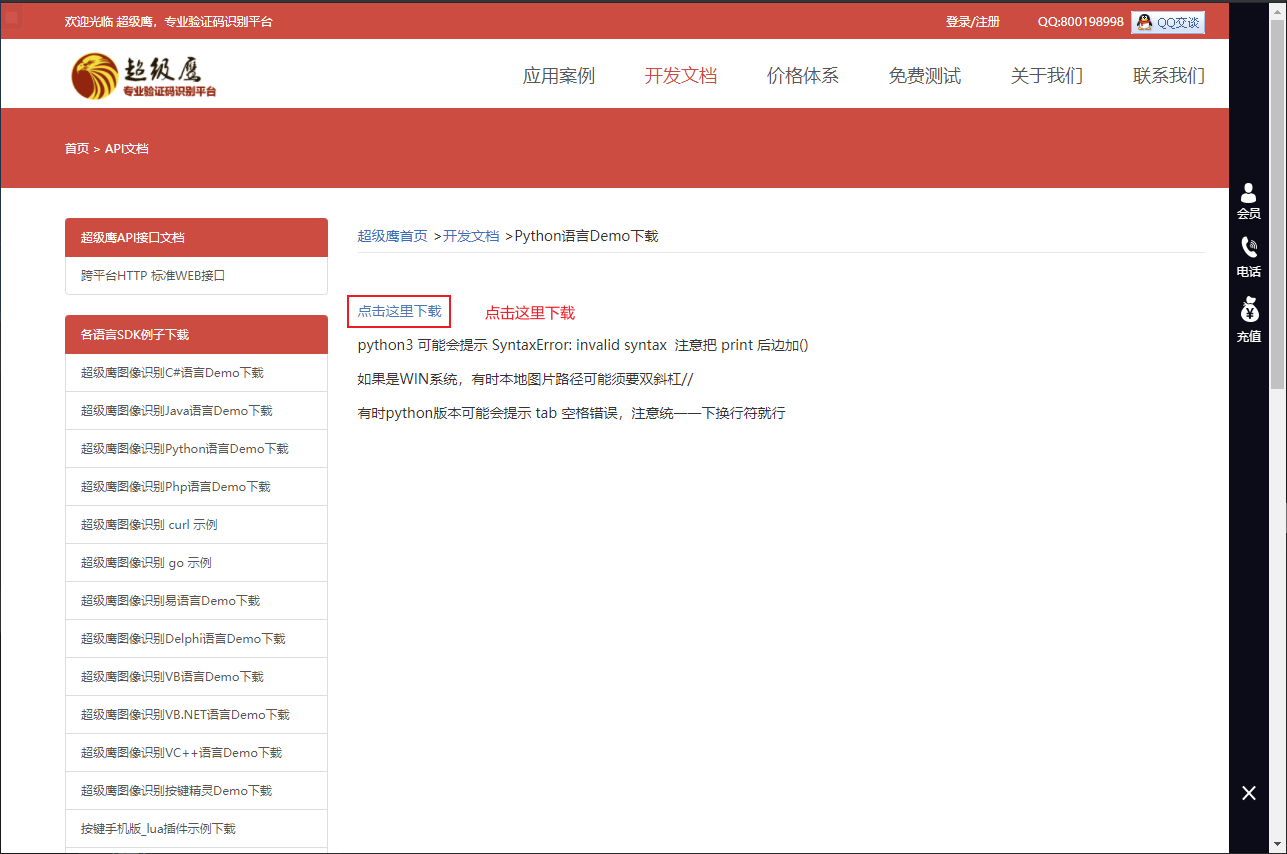
Unzip, copy and paste a.jpg image and python file chaojiying.py into the project (you can customize the specified directory)
code
#!/usr/bin/env python
# coding:utf-8
import requests
from hashlib import md5
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: Picture byte
codetype: Topic type reference http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:Pictures of wrong topics ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
if __name__ == '__main__':
# The user center > > software ID generates a replacement 96001
# chaojiying = Chaojiying_Client('Super Eagle user name ',' password of super Eagle user name ',' 96001 ')
chaojiying = Chaojiying_Client('action', 'action', '921720') # Change to your own user name, password and generated software ID
# Local image file path to replace a.jpg. Sometimes WIN system needs to//
im = open('a.jpg', 'rb').read()
# 1902 verification code type official website > > price system version 3.4 + print should be added ()
# print chaojiying.PostPic(im, 1902)
# print(chaojiying.PostPic(im, 1902))
print(chaojiying.PostPic(im, 1902).get('pic_str'))
6. Sketch framework
1. Introduction to scratch
Scrapy is an application framework written for crawling website data and extracting structural data. It can be applied to a series of programs, including data mining, information processing or storing historical data.
Official website: https://scrapy.org/
2. Scene installation
Note: the installation path is consistent with the library path (Scripts directory path) of python, such as D: \ develop \ Python \ Python 39 \ Scripts
# Install the script pip install scrapy # During installation, ① if an error is reported (the twisted library is missing) building 'twisted.test.raiser' extension error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-tools # Solution # Download (twisted, the download website is as follows) http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted # Download the whl file of the corresponding version of twisted (for example, I downloaded Twisted-20.3.0-cp39-cp39-win_amd64.whl), followed by the python version, AMD64 represents 64 bits, and run the command (add the absolute path of the twisted library, for example, I put it on the desktop: C:\Users\Administrator\Desktop, and remember to change this path to the path where I put the twisted Library): pip install C:\Users\Administrator\Desktop\Twisted-20.3.0-cp39-cp39-win_amd64.whl # Where install is followed by the full path name of the downloaded whl file. After installation, run the following installation command again pip install scrapy # ② If an error is reported again, you will be prompted to upgrade the pip instruction python -m pip install --upgrade pip # ③ If an error is reported, the win32 error is reported pip install pypiwin32 # ④ If you still report an error, you can use Anaconda (the following is the download address of the official website, which can be installed all the way) https://www.anaconda.com/products/individual-d#Downloads
Installation succeeded
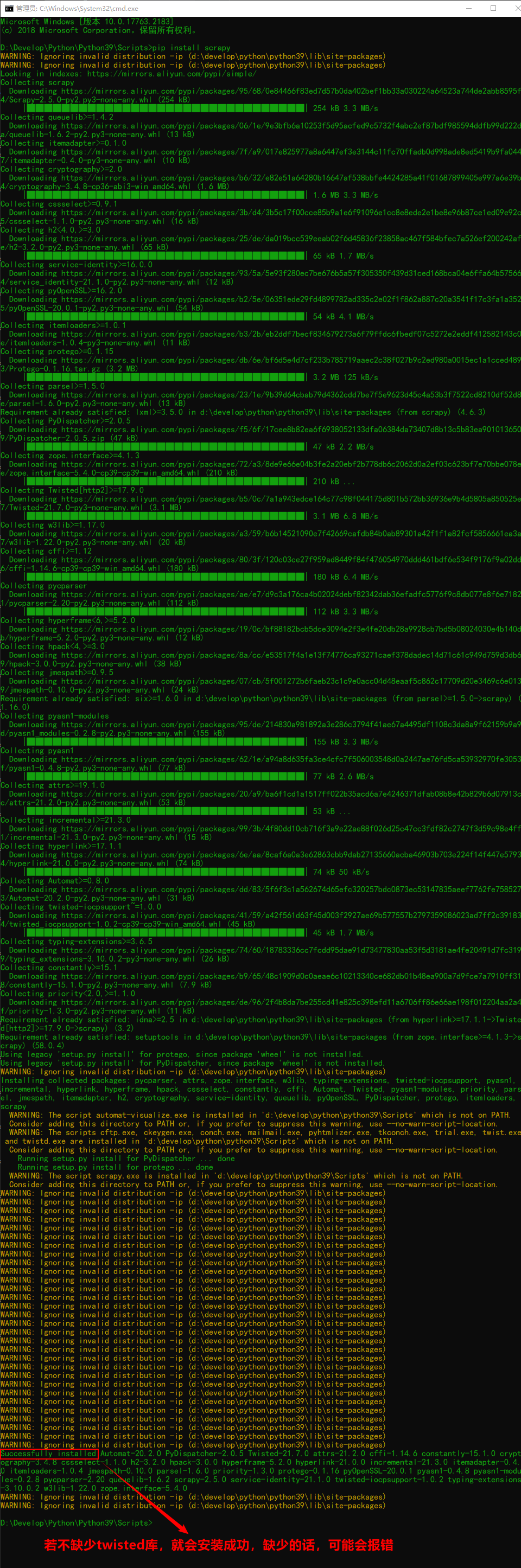
If an error is reported, the twisted library is missing (skip here after successful installation)
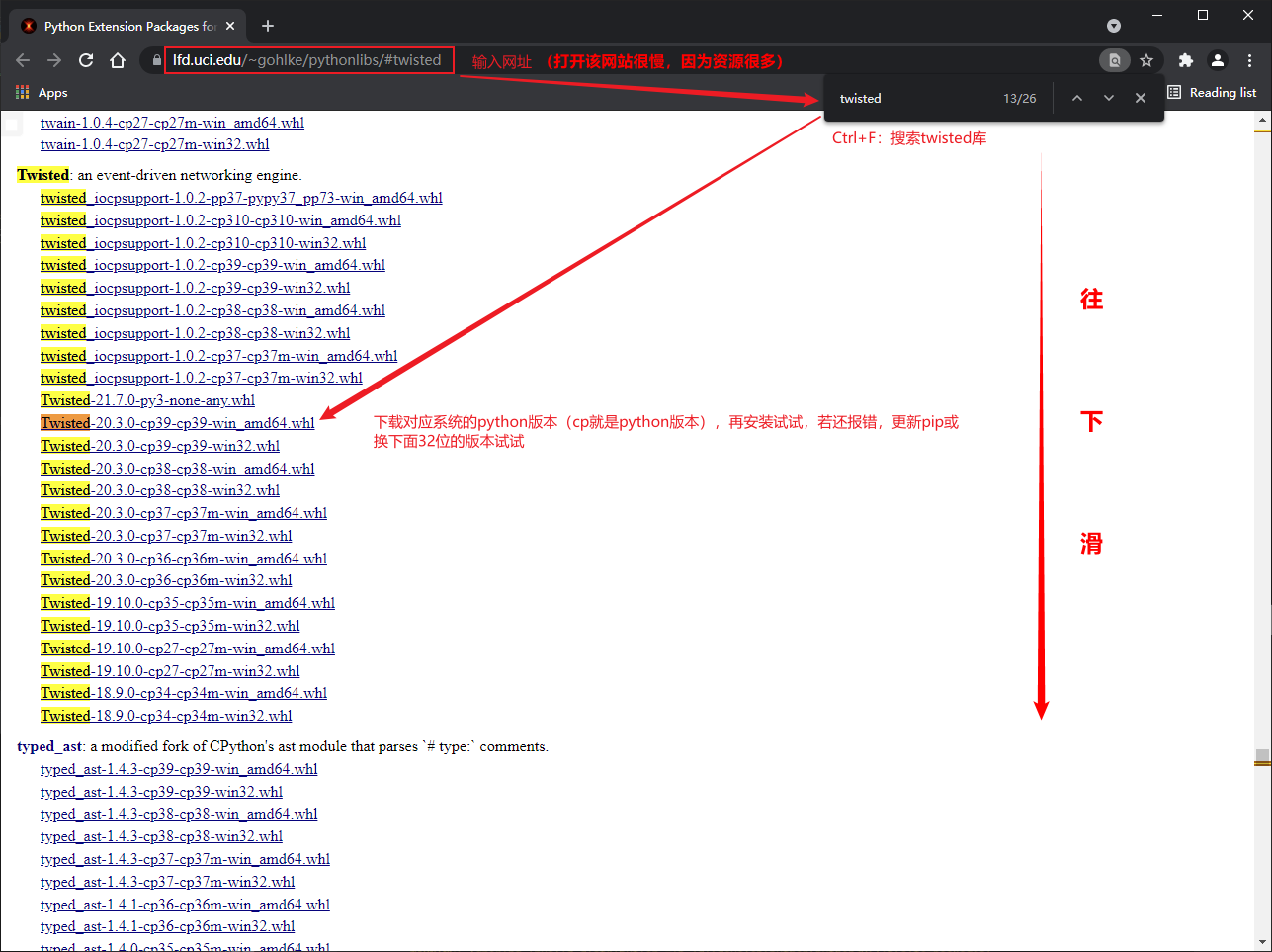
3. Create project and run [CMD / terminal]
3.1 creating a scene project
# When creating a project, the project name cannot start with a number or contain Chinese scrapy startproject entry name # For example: scrapy startproject scrapy17_baidu
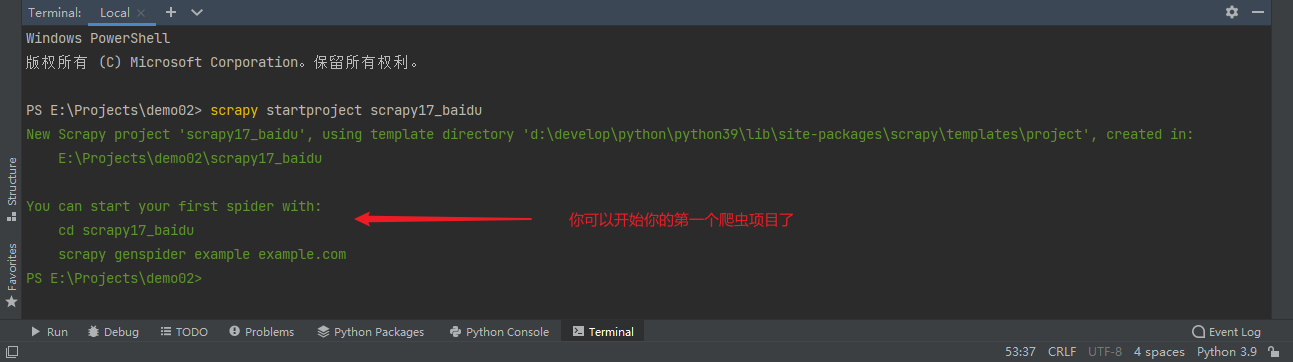
3.2 creating crawler files
# ① You need to switch to the spider directory to create the crawler file cd xxx entry name\xxx entry name\spiders # For example: cd .\scrapy17_baidu\scrapy17_baidu\spiders\ # ② Create a crawler file (the crawler URL is usually written directly to the domain name, and the HTTP protocol is generally omitted. If http: / /, you need to manually delete the redundant http: / /, so you can write the domain name directly) scrapy genspider The name of the crawler and the web address of the crawler # For example: # scrapy genspider baidu http://www.baidu.com scrapy genspider baidu www.baidu.com
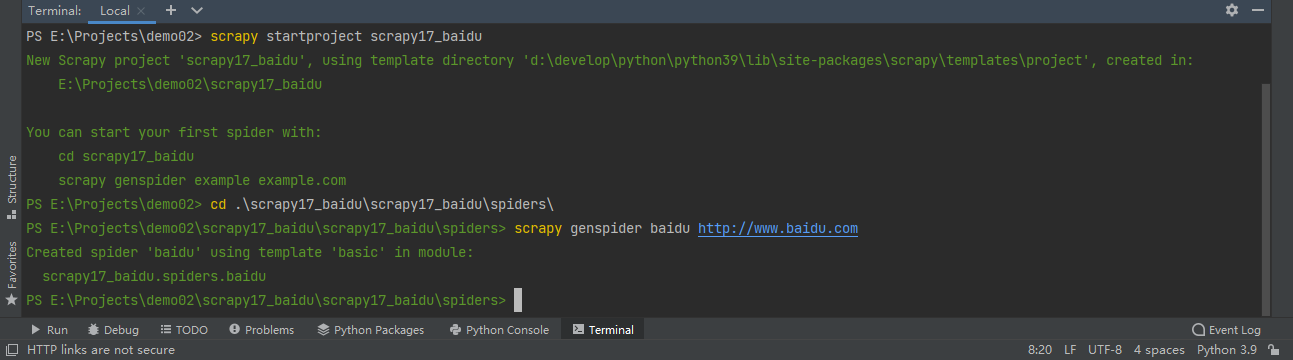
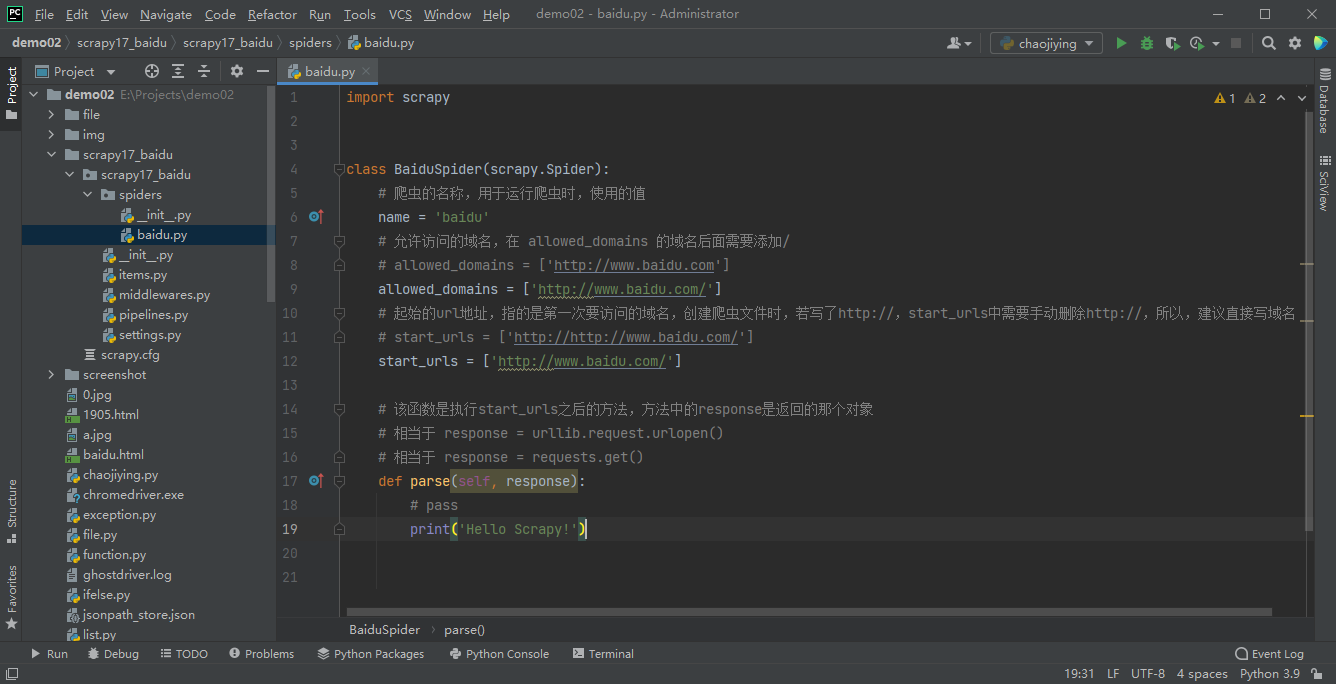
Crawler file code
import scrapy
class BaiduSpider(scrapy.Spider):
# The name of the crawler and the value used when running the crawler
name = 'baidu'
# Allow access to the domain name in allowed_domains needs to be added after the domain name/
# allowed_domains = ['http://www.baidu.com']
allowed_domains = ['http://www.baidu.com/']
# The starting url address refers to the domain name accessed for the first time. If http: / /, start is written when creating the crawler file_ Http: / / needs to be deleted manually in URLs, so it is recommended to write the domain name directly
# start_urls = ['http://http://www.baidu.com/']
start_urls = ['http://www.baidu.com/']
# This function executes start_ After URLs, the response in the method is the object returned
# Equivalent to response = urllib.request.urlopen()
# Equivalent to response = requests.get()
def parse(self, response):
# pass
print('Hello Scrapy!')
3.3 running crawler files
# Run crawler file scrapy crawl The name of the reptile # For example: scrapy crawl baidu # Robots.txt (decided by the gentleman, anti climbing is set, and the major manufacturers agree: don't climb me, I won't climb you, but, is it possible): robots protocol -- > you can add robots.txt to the back of the domain name to see which can be crawled # settings.py file # Obey robots.txt rules # Observe the robots.txt protocol, which is a gentleman's agreement. Generally, it does not need to be observed # ROBOTSTXT_OBEY = True # The default value is True. It enables compliance with the robots.txt protocol. If you can comment it out, you will not comply
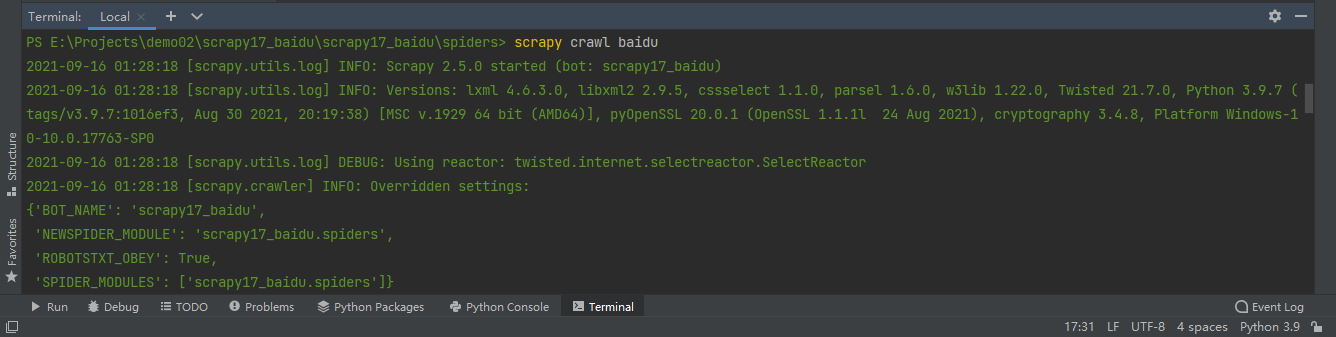
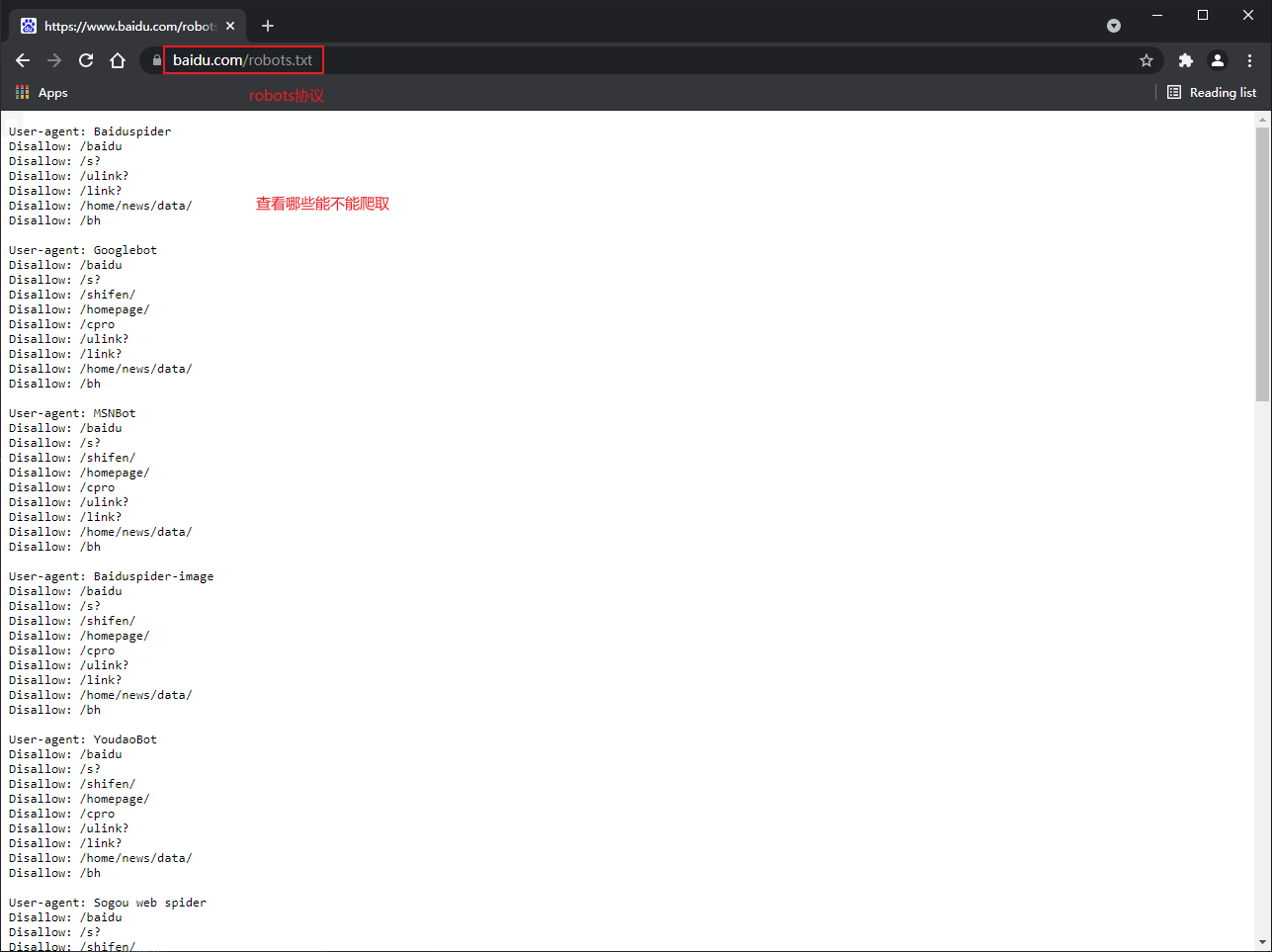
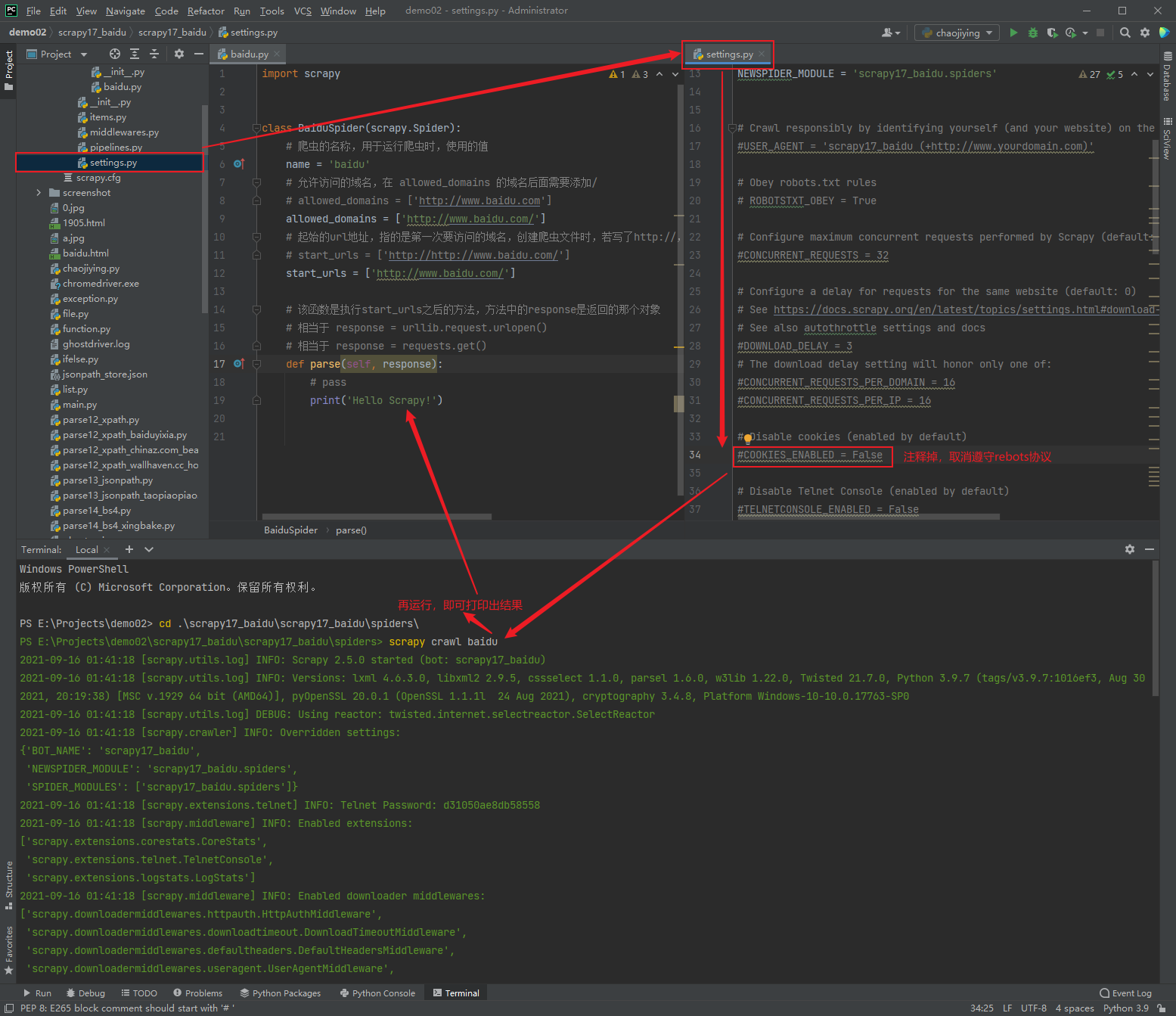
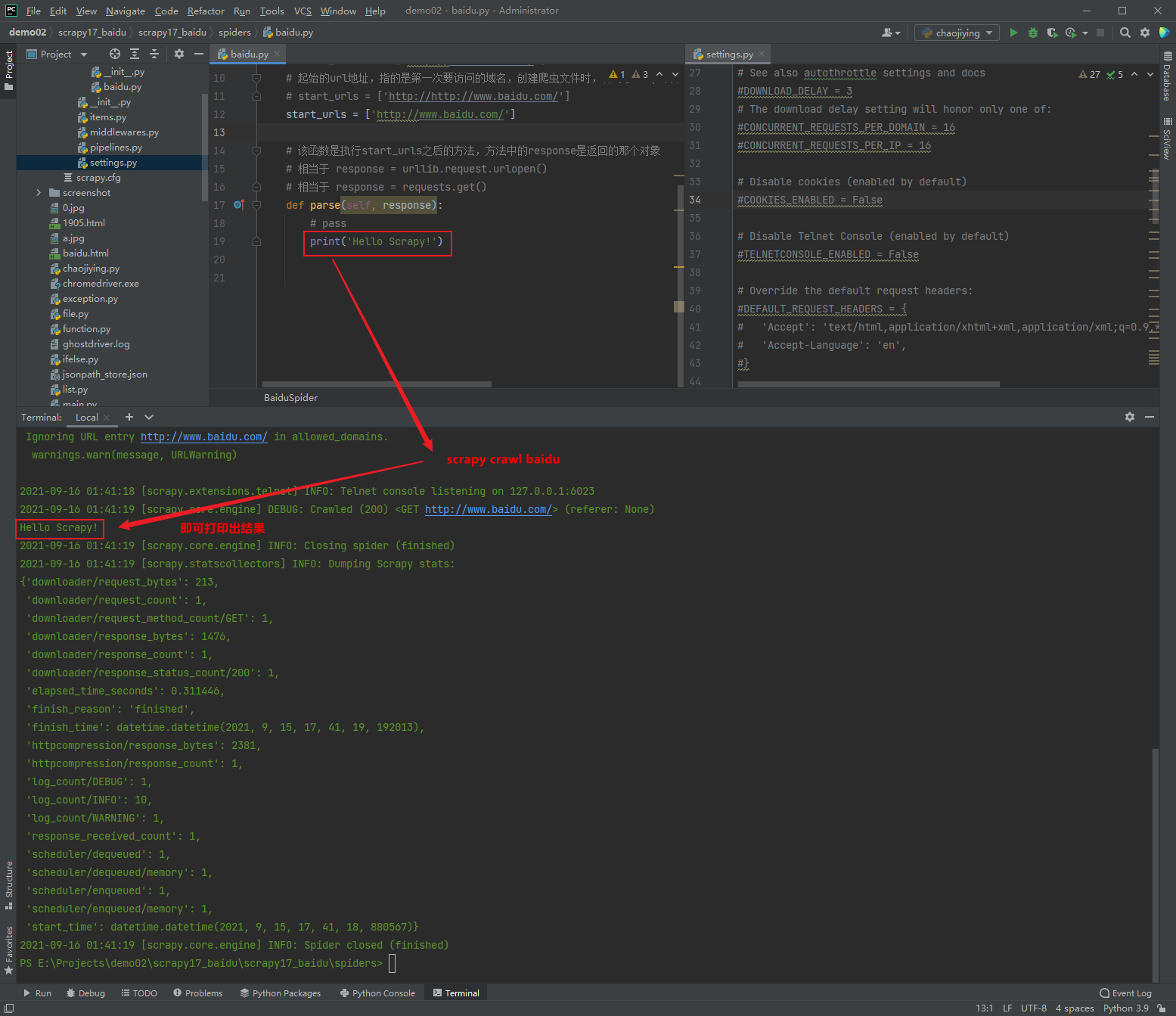
4. Attributes and methods of the structure and response of the scratch project
By crawling 58 cities, we study the attributes and methods of the structure and response of the story project
Home page: https://gz.58.com/ -->Search front end development
Terminal
# Create project https://gz.58.com/sou/?key=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91&classpolicy=jianzhi_ B scrapy startproject scrapy17_58tc # Switch to spiders directory cd .\scrapy17_58tc\scrapy17_58tc\spiders\ # Create crawler file scrapy genspider tc gz.58.com/sou/?key=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91&classpolicy=jianzhi_B # Note: the parameter & symbol in pychart terminal needs to be wrapped with double quotation marks "&", otherwise an error will be reported. It is required to use "&" to replace &, and cmd will not report an error & symbol. If cmd reports an error, some parameters are not internal and external commands, it can be ignored. Just create a crawler file scrapy genspider tc gz.58.com/sou/?key=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91"&"classpolicy=jianzhi_B # Note: if the following link suffix is. html, the result will not be printed. To print the result, you need to start the generated file_ / at the end of URLs link is removed, and / is not required. Therefore, it is generally recommended not to add // # For example: https://pro.jd.com/mall/active/3fNa4gg4udob1juiWbWWBp9z9PBs/index.html scrapy genspider tc pro.jd.com/mall/active/3fNa4gg4udob1juiWbWWBp9z9PBs/index.html # Comment out the robots protocol in settings.py # Obey robots.txt rules # ROBOTSTXT_OBEY = True # It is on by default. In line 20 of the code, comment it out # Run the crawler file. If the tobots protocol is not commented out, the results will not be printed scrapy crawl tc
4.1 project structure
spiders # Crawler directory __init__.py # When creating a crawler directory, initialize the crawler files created Custom crawler files # Created by yourself, it is a file to realize the core functions of the crawler __init__.py # When creating a crawler directory, initialize the crawler files created itmes.py # The place where the data structure is defined is a class inherited from the scene.item (that is, what the crawled data contains) middlewares.py # Middleware, proxy mechanism pipelines.py # There is only one class in the pipeline file, which is used for subsequent processing of downloaded data. The default is 300 priority. The smaller the value, the higher the priority (1-1000) settings.py # Configuration files, such as compliance with robots protocol and user agent definition, are all in it
4.2 basic composition of crawler files
Composition of crawler files
# Inherit the script.spider class name = 'baidu' # The name used when running the crawler file allowed_domains # The domain name allowed by the crawler will be filtered out if it is not the url under the domain name start_urls # Declare the starting url address of the crawler. You can write multiple URLs, usually one parse(self, response) # Callback function for parsing data response.text # Gets the string of the response response.body # Gets the binary of the response response.xpath() # You can directly use xpath() to parse the content in the response, and the return value type is the selector list response.extract() # Extract the data attribute value of the selector object response.extract_first() # The first data in the extracted selector list
Crawler file
Baidu
import scrapy
class BaiduSpider(scrapy.Spider):
# The name of the crawler and the value used when running the crawler
name = 'baidu'
# Allow access to the domain name in allowed_domains needs to be added after the domain name/
# allowed_domains = ['http://www.baidu.com']
allowed_domains = ['http://www.baidu.com/']
# The starting url address refers to the domain name accessed for the first time. If http: / /, start is written when creating the crawler file_ Http: / / needs to be deleted manually in URLs, so it is recommended to write the domain name directly
# start_urls = ['http://http://www.baidu.com/']
start_urls = ['http://www.baidu.com/']
# This function executes start_ After URLs, the response in the method is the object returned
# Equivalent to response = urllib.request.urlopen()
# Equivalent to response = requests.get()
def parse(self, response):
# pass
print('Hello Scrapy!')
58 same city
import scrapy
class TcSpider(scrapy.Spider):
name = 'tc'
allowed_domains = ['gz.58.com/sou/?key=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91&classpolicy=jianzhi_B']
start_urls = ['http://gz.58.com/sou/?key=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91&classpolicy=jianzhi_B/']
def parse(self, response):
# pass
print("Test climb 58 city, basic test method")
content = response.text # Gets the string of the response
print(content)
content = response.bosy # Get the binary data of the response
print(content)
# span = response.xpath('//div[@id="filter"]/div[@class="tabs"]/a/span ') # gets the binary data of the response
span = response.xpath('//div[@id="filter"]/div[@class="tabs"]/a/span')[0] # gets the binary data of the response
print(span, span.extract())
5. Composition of sketch architecture
# ① Engine: it runs automatically without attention. It will automatically organize all request objects and distribute them to downloaders # ② Downloader: requests data after obtaining the request object from the engine # ③ spiders: the Spider class defines how to crawl a certain (or some) web address, including the crawling action (such as whether to follow up the link) and how to extract structured data (crawl item) from the content of the web page. (that is, Spider is the place where you define crawling actions and analyze certain / some web pages) # ④ Scheduler: it has its own scheduling rules and needs no attention # ⑤ Item pipeline: finally, an effective pipeline will be processed, and an interface will be reserved for us to process data. When an item is in the Spider, it will be passed to the item pipeline, and some components will process the item in a certain order. Each item pipeline component (sometimes referred to as "item pipeline") is a Python class that implements a simple method. They receive an item and perform some behavior through it. At the same time, they also determine whether the item continues to pass through the pipeline or is discarded and no longer processed. # The following are some typical applications of item pipeline: # 1. Clean up HTML data # 2. Verify the crawled data (check that the item contains some fields) # 3. Duplicate check (and discard) # 4. Save the crawling results to the database
6. Working principle of scratch
- The engine asks spiders for a url
- The engine sends the url that needs to be crawled to the scheduler
- The scheduler will generate a request object from the url, put the request object into the specified queue, and then queue a request from the queue
- The engine passes the request to the downloader for processing
- Downloader sends request Internet data
- Download device to get internet data
- The downloader returns the data to the engine
- The engine sends the data to spiders, which parses the data through xpath to get the data or url
- spiders return the data or url to the engine
- The engine determines whether the data is data or url. If it is data, it will be handed over to the item pipeline for processing. If it is url, it will be handed over to the scheduler for processing
Preview of official website architecture: https://docs.scrapy.org/en/latest/topics/architecture.html
6.1 architecture diagram
6.1.1 previous architecture
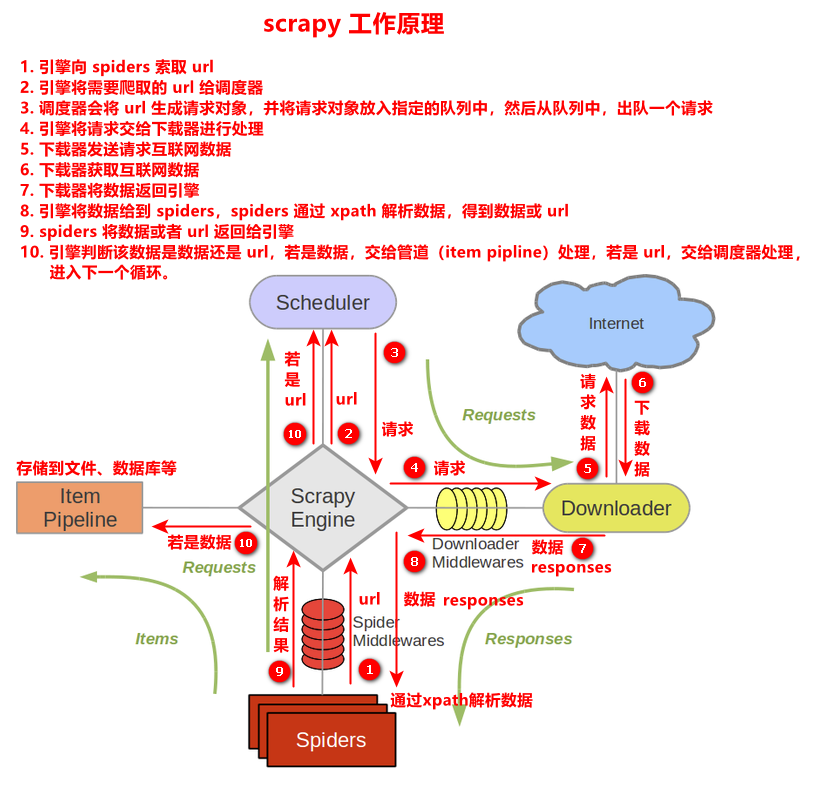
6.1.2 current architecture
summary
The following figure shows an overview of the Scrapy architecture and its components, as well as an overview of the data flows that occur within the system (shown by the red arrows). A brief description of the components and links to more detailed information about them are included below. The data flows are also described below.
Data flow
https://docs.scrapy.org/en/latest/topics/architecture.html
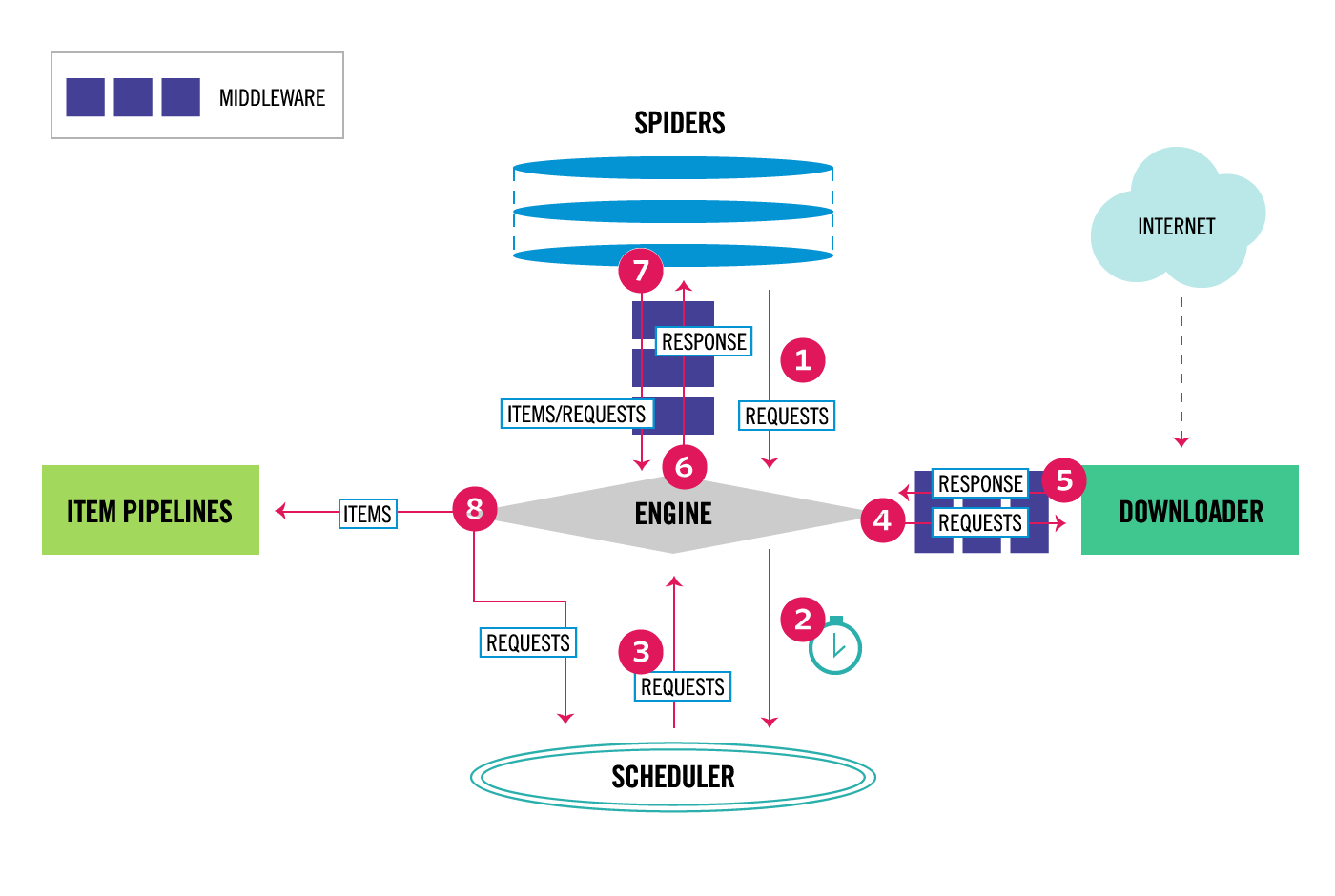
The data flow in scripy is controlled by the execution engine, as shown below:
- Should engine Get crawl from initial request Spiders.
- Should engine Schedule on request Scheduler And request the next request crawl.
- Should plan Returns the of the next request engine.
- Should engine Send request to Downloader , pass Downloader Middleware (see process_request()).
- After downloading the page, Downloader Generate a response (with the page) and send it to the engine through Downloader Middleware (see reference materialprocess_response()).
- Should engine Receive response from Downloader And send it to the Spiders Process by Spiders Middleware (see process_spider_input()).
- Should Spiders Process the response and return the scraped items and new requirements (follow) engine , pass Spiders Middleware (see process_spider_output()).
- Should engine Send processed items to Item Pipeline And then put the processed request dispatch And request that crawling may be requested in the future.
- The process is repeated (starting from step 1) until there are no more from Scheduler's Request.
Scratch engine
The engine is responsible for controlling the data flow between all components of the system and triggering events when certain actions occur. For more details, see above data stream part.
Scheduler
The scheduler receives requests from the engine and queues them when requested by the engine for later (also to the engine).
Downloader
The Downloader is responsible for obtaining web pages and providing them to the engine, and then the engine provides them to Spiders.
Spiders
Spiders is a custom class written by scripy users to parse responses and extract project Or other requests to follow. For more information, see Spiders.
Item Pipeline
Once an item is extracted (or crawled) by Spiders, the Item Pipeline is responsible for processing the item. Typical tasks include cleaning, validation, and persistence (such as storing the item in a database). For more information, see Item Pipeline.
Downloader Middleware
Downloader middleware is a specific hook between the engine and the downloader, and processes the request when the request is passed from the engine to the downloader, as well as the response passed from the downloader to the engine.
If you need to do one of the following, use the Downloader middleware:
- Process the request before sending the request to the downloader (i.e. before Scrapy sends the request to the website);
- Change the received response before passing it to Spiders;
- Send a new request instead of passing the received response to Spiders;
- Pass the response to Spiders without getting the web page;
- Silently give up some requests.
For more information, see Download program Middleware.
Spiders Middleware
Spider middleware is a specific hook between Engine and spider, which can handle spider input (response) and output (project and request).
If necessary, use Spider middleware
- Post processing output of Spiders callback - change / add / delete request or item;
- Post processing start_requests;
- Handle Spiders exceptions;
- Call errback instead of callback for some requests according to the response content.
For more information, see Spiders Middleware.
Event driven networking
Scrapy is used Twisted This is a popular Python event driven network framework. Therefore, it uses non blocking (also known as asynchronous) code to achieve concurrency.
6.2 cases
Car home: https://www.autohome.com.cn/beijing/ – search BMW – crawl to BMW series name and price
Terminal
# Create project https://sou.autohome.com.cn/zonghe?q=%B1%A6%C2%ED&mq=&pvareaid=3311667 scrapy startproject scrapy17_carhome # Switch to spiders directory cd .\scrapy17_carhome\scrapy17_carhome\spiders\ # Create crawler file scrapy genspider car sou.autohome.com.cn/zonghe?q=%B1%A6%C2%ED&mq=&pvareaid=3311667 # perhaps scrapy genspider car sou.autohome.com.cn/zonghe?q=%B1%A6%C2%ED"&"mq="&"pvareaid=3311667 # Comment out the robots protocol in settings.py # Obey robots.txt rules # ROBOTSTXT_OBEY = True # It is on by default. In line 20 of the code, comment it out # Run crawler file scrapy crawl tc
code
import scrapy
class CarSpider(scrapy.Spider):
name = 'car'
allowed_domains = ['sou.autohome.com.cn/zonghe?q=%B1%A6%C2%ED&mq=&pvareaid=3311667']
start_urls = ['http://sou.autohome.com.cn/zonghe?q=%B1%A6%C2%ED&mq=&pvareaid=3311667/']
def parse(self, response):
# pass
# print('car home ')
car_name_price_list = response.xpath('//div[@class="brand-rec-box"]/ul//li/p/a/text()')
# for car_name_price in car_name_price_list:
# print(car_name_price.extract())
for i in range(len(car_name_price_list)):
car_name_price = car_name_price_list[i].extract()
print(car_name_price)
6.3 scrapy shell
Scrapy shell is an interactive terminal that provides code to try and debug crawling without starting the spider. It is intended to test the code to extract data, but it can be used as a normal Python terminal to test any Python code on it.
The terminal is used to test xpath or css expressions, check their working mode and extract data from crawled web pages. When writing spiders, the terminal provides the function of interactivity test expression code, avoiding the trouble of running spiders after each modification. After getting familiar with the script terminal, you will find that it plays a great role in developing and debugging spiders.
6.3.1 installation of ipython
If ipython is installed, the script terminal will use ipython (instead of the standard python terminal). Compared with other terminals, ipython terminal is more powerful and provides intelligent automatic completion, highlight output and other features.
Note: the installation path is consistent with the library path (Scripts directory path) of python, such as D: \ develop \ Python \ Python 39 \ Scripts
# Install ipython pip install ipython # View ipython version ipython
6.3.2 application
# Enter the scan shell domain name in the terminal scrapy shell www.baidu.com scrapy shell http://www.baidu.com scrapy shell "http://www.baidu.com" scrapy shell "www.baidu.com"
6.3.3 syntax
# ① response object
response.body
response.text
response.url
response.status
# ② response parsing
# Use the xpath path to query a specific element and return a selector list object [common]
response.xpath()
# Using CSS_ The selector query element returns a selector list object
response.css()
# Get content
response.css('#su::text').extract_first()
# get attribute
response.css('#su::attr("value")').extract_first()
# ③ selector object (the list of selectors is returned through the xpath() call)
# Extract the value of the selector object. If the value cannot be extracted, an error will be reported. The object requested by xpath is a selector object. You need to further unpack it with extract() and convert it into a unicode string
extract()
# Note: each selector object can use xpath() or css() again
# Extract the first value in the selector list. If the value cannot be extracted, it will return a null value and the first parsed value. If the list is empty, this method will not report an error and will return a null value
extract_first()
xpath()
css()
7.yield
- The function with yield is no longer an ordinary function, but a generator, which can be used for iteration
- Yield is a keyword similar to return. When an iteration encounters yield, it returns the value after (on the right) yield. In the next iteration, the execution starts from the code (next line) after the yield encountered in the previous iteration.
- yield is a value returned by return. Remember the returned position. The next iteration starts after this position (the next line).
case
- Dangdang: ① yield, ② pipeline encapsulation, ③ multi pipeline download, ④ multi page data download
- Movie Paradise: ① an item contains multi-level page data
Dangdang network
Climb Dangdang - Books - Youth Literature - Love / emotion - the first 100 pages of book pictures, profiles and prices, and create a directory to receive downloaded files in the spiders directory, such as books, book.json, which is a file created in JSON format
Crawling results: 6000 pictures: 244MB; book.json: 1.26MB
Terminal
# Create project http://category.dangdang.com/cp01.01.02.00.00.00.html
scrapy startproject scrapy17_dangdang
# Switch to spiders directory
cd .\scrapy17_dangdang\scrapy17_dangdang\spiders\
# Create crawler file
scrapy genspider dang category.dangdang.com/cp01.01.02.00.00.00.html
# Remove start_urls at the end of the link/
# start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html / '] # this path is incorrect
# start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html '] # delete the at the end/
# Comment out the robots protocol in settings.py
# Obey robots.txt rules
# ROBOTSTXT_OBEY = True # It is on by default. In line 20 of the code, comment it out
# If you need to use the pipeline, you need to open the pipeline in settings. The code is 65 lines. Uncomment. 300 is the priority. The smaller the value, the higher the priority. The priority value is 1-1000
ITEM_PIPELINES = {
'scrapy17_dangdang.pipelines.Scrapy17DangdangPipeline': 300,
}
# Run crawler file
scrapy crawl dang
code
Project structure
dang.py
import scrapy
from scrapy17_dangdang.items import Scrapy17DangdangItem # Don't worry about errors in this import method
class DangSpider(scrapy.Spider):
name = 'dang'
# Single page download
# allowed_domains = ['category.dangdang.com/cp01.01.02.00.00.00.html']
# Multi page download, allowed needs to be modified_ Domains. Generally, only domain names are required
allowed_domains = ['category.dangdang.com']
start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html']
# Find rules
# Page 1: http://category.dangdang.com/cp01.01.02.00.00.00.html
# Page 2: http://category.dangdang.com/pg2-cp01.01.02.00.00.00.html
# Page 3: http://category.dangdang.com/pg3-cp01.01.02.00.00.00.html
# Page n: http://category.dangdang.com/pgn-cp01.01.02.00.00.00.html
base_url = 'http://category.dangdang.com/pg'
page = 1
def parse(self, response):
# Downloading data from pipelines
# items defines the data structure
# pass
# It is found that the first picture does not have data original, that is, the first picture does not use lazy loading mode. Except for the first picture, the following pictures are lazy loading mode
# src = //UL [@ id = "component_59"] / Li / / img / @ SRC # SRC is set after lazy loading. It needs to be set before data original lazy loading
# src = //UL [@ id = "component_59"] / Li / / img / @ data original # SRC is set after lazy loading. It needs to be set before data original lazy loading
# alt = //ul[@id="component_59"]/li//img/@alt
# price = //ul[@id="component_59"]/li//p[@class="price"]/span[1]/text()
# All selector objects can call xpath() again
li_list = response.xpath('//ul[@id="component_59"]/li')
for li in li_list:
# The properties of the first picture are different from those of other pictures. The former has no data original, and the latter has
# That is, the src of the first picture can be used. Its picture address is src and the addresses of other pictures are data original
src = li.xpath('.//img/@data-original').extract_first() # extract_first(): if you cannot get the data, you will return None
book_id = li.xpath('./@ddt-pit').extract_first()
page = self.page
num_list = len(li_list)
if src:
src = src
else:
src = li.xpath('.//img/@src').extract_first()
name = li.xpath('.//img/@alt').extract_first()
price = li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()
book = Scrapy17DangdangItem(book_id=book_id, page=page, num_list=num_list, src=src, name=name, price=price)
# Get a book and give the book to pipelines
yield book
# Multi page download: the business logic of each page crawling is the same. Therefore, you only need to call parse() again for the request to execute that page
if self.page < 100:
self.page += 1
url = self.base_url + str(self.page) + '-cp01.01.02.00.00.00.html'
# Call parse(): sweep. Request() is the get request of sweep
# url: request address
# callback: the function to be executed. The self.parse function does not need to be followed by (), and the function name can be written
yield scrapy.Request(url=url, callback=self.parse)
items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class Scrapy17DangdangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# pass
# Data structure: Generally speaking, what is the data to be downloaded
# Picture, name, price
book_id = scrapy.Field()
page = scrapy.Field()
num_list = scrapy.Field()
src = scrapy.Field()
name = scrapy.Field()
price = scrapy.Field()
pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
import urllib.request
from itemadapter import ItemAdapter
# If you need to use a pipe, you must turn on the pipe in settings
class Scrapy17DangdangPipeline:
# Execute before crawler files
def open_spider(self, spider):
self.fp = open('book.json', 'w', encoding='utf-8')
# item is the book object after yield
def process_item(self, item, spider):
# write() must write a string and cannot be any other object
# w mode: will overwrite the previous content a mode: append content
# This method is not recommended because the file is opened every time an object is passed, and the operation on the file is too frequent
# with open('book.json', 'a', encoding='utf-8') as down:
# down.write(str(item))
self.fp.write(str(item))
return item
# Execute after crawler file
def close_spider(self, spider):
self.fp.close()
# Multiple channels open download
# ① Define pipe classes
# ② Open the pipe 'dangdangdownloadpipeline. Pipelines. Dangdangdownloadpipeline' in settings: 301
class DangDangDownloadPipeline:
def process_item(self, item, spider):
url = 'http:' + item.get('src') # Picture address
page = item.get('page') # Page number
book_id = item.get('book_id') # The DDT pit attribute value of book is 1-60 (i.e. the number of books per page: 1-60)
num_list = item.get('num_list') # List length of books (i.e. number of books per page: 60)
num = int(page - 1) * int(num_list) + int(book_id) # Serial number, for convenience of viewing
filename = 'books/' + str(num) + '.' + item.get('name') + '.jpg'
urllib.request.urlretrieve(url=url, filename=filename)
return item
settings.py
# Scrapy settings for scrapy17_dangdang project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'scrapy17_dangdang'
SPIDER_MODULES = ['scrapy17_dangdang.spiders']
NEWSPIDER_MODULE = 'scrapy17_dangdang.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'scrapy17_dangdang (+http://www.yourdomain.com)'
# Obey robots.txt rules
# ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'scrapy17_dangdang.middlewares.Scrapy17DangdangSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'scrapy17_dangdang.middlewares.Scrapy17DangdangDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'scrapy17_dangdang.pipelines.Scrapy17DangdangPipeline': 300,
'scrapy17_dangdang.pipelines.DangDangDownloadPipeline': 301,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
Movie paradise
Climb to movie paradise - the latest movie - level 1 page movie name, level 2 page movie picture
Terminal
# Create project https://www.dytt8.net/html/gndy/dyzz/list_23_1.html
scrapy startproject scrapy17_movie
# Switch to spiders directory
cd .\scrapy17_movie\scrapy17_movie\spiders\
# Create crawler file
scrapy genspider movie www.dytt8.net/html/gndy/dyzz/list_23_1.html
# Remove start_urls at the end of the link/
# start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html / '] # this path is incorrect
# start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html '] # delete the at the end/
# Comment out the robots protocol in settings.py
# Obey robots.txt rules
# ROBOTSTXT_OBEY = True # It is on by default. In line 20 of the code, comment it out
# If you need to use the pipeline, you need to open the pipeline in settings. The code is 65 lines. Uncomment. 300 is the priority. The smaller the value, the higher the priority. The priority value is 1-1000
ITEM_PIPELINES = {
'scrapy17_dangdang.pipelines.Scrapy17DangdangPipeline': 300,
}
# Run crawler file
scrapy crawl movie
code
Project structure
code
movie.py
import scrapy
from scrapy17_movie.items import Scrapy17MovieItem
class MovieSpider(scrapy.Spider):
name = 'movie'
allowed_domains = ['www.dytt8.net']
start_urls = ['http://www.dytt8.net/html/gndy/dyzz/list_23_1.html']
def parse(self, response):
# Requirements: movie name on level 1 page, picture of movie on Level 2 page
# //div[@class="co_content8"]//td[2]/b/a/text()
movie_a_list = response.xpath('//div[@class="co_content8"]//td[2]/b/a')
for movie_a in movie_a_list:
# Get the movie name of level 1 page and the link to click on Level 2 page
movie_name = movie_a.xpath('./text()').extract_first()
movie_href = movie_a.xpath('./@href').extract_first()
# Level 2 page link address
url = 'https://www.dytt8.net' + movie_href
# Initiate access to the level 2 page of the movie name link jump, involving Level 2 / multi-level pages, which need to be saved using meta
yield scrapy.Request(url=url, callback=self.parse_second, meta={'name': movie_name})
def parse_second(self, response):
# The span tag is not recognized. If you cannot get the data, you must first check whether the xpath syntax is correct
# src = response.xpath('//div[@id="Zoom"]/span/img/@src').extract_first()
src = response.xpath('//div[@id="Zoom"]//img/@src').extract_first()
# Received value of request parameter meta
movie_name = response.meta['name']
movie = Scrapy17MovieItem(src=src, name=movie_name)
yield movie
items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class Scrapy17MovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
src = scrapy.Field()
pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class Scrapy17MoviePipeline:
def open_spider(self, spider):
self.fp = open('movie.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self, spider):
self.fp.close()
settings.py
# Scrapy settings for scrapy17_movie project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'scrapy17_movie'
SPIDER_MODULES = ['scrapy17_movie.spiders']
NEWSPIDER_MODULE = 'scrapy17_movie.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'scrapy17_movie (+http://www.yourdomain.com)'
# Obey robots.txt rules
# ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'scrapy17_movie.middlewares.Scrapy17MovieSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'scrapy17_movie.middlewares.Scrapy17MovieDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'scrapy17_movie.pipelines.Scrapy17MoviePipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
8.MySQL
- Download (8.0.x): https://dev.mysql.com/downloads/mysql/ 5.7.x: https://dev.mysql.com/downloads/mysql/5.7.html)
- Installation (8.0.x): https://www.cnblogs.com/fuhui-study-footprint/p/14953899.html)
9. Using pymysql
Note: the installation path is consistent with the library path (Scripts directory path) of python, such as D: \ develop \ Python \ Python 39 \ Scripts
# Install pymysql pip install pymysql # Connect to pymysql pymysql.connect(host,port,user,password,db,charset) conn.cursor() # Execute sql statement cursor.execute() # Submit conn.commit() # close resource cursor.close() conn.close()
10.CrawlSpider
After crawling, put the data into the database
10.1 introduction
Inherited from scene.spider
CrawlSpider can define rules. When parsing html content, you can extract the pointed links according to the link rules, and then send requests to these links. Therefore, it is suitable for the needs of following up links (that is, after crawling the web page, you need to extract the links and crawl again. It is very suitable to use CrawlSpider).
10.2 extract links
# Link extractor, where you can write rules to extract specified links
scrapy.linkextractors.LinkExtractor(
allow = (), # Regular expression to extract regular links
deny = (), # (no) regular expressions, do not extract regular links
allow_domains = (), # (no) allowed domain names
deny_domains = (), # (no) domain name not allowed
restrict_xpaths = (), # xpath to extract links that conform to xpath rules
restrict_css = () # Extract links that match selector rules
)
10.3 simulated use
# Regular usage links1 = LinkExtractor(allow=r'list_23_\d+\.html') # xpath usage links2 = LinkExtractor(restrict_xpaths=r'//div[@class="x"]') # css usage links3=LinkExtractor(restrict_css='.x')
10.4 extract links
link.extract_links(response)
10.5 precautions
- Callback can only be written in the function name string, callback = 'parse_item’
- In the basic spider, if the request is sent again, the callback there is written as callback=self.parse_item, follow=true whether to follow up is to extract the link all the time according to the extraction link rules
10.6 operating principle
follow parameter in Rule:
After sending the request, send the request to url1, url2, url3, url4, etc. in these link response contents, it is determined by the follow configuration parameter whether it is necessary to continue to extract the links that meet the rules according to. If follow=True, the link will continue to be extracted according to the rules. If follow=Talse, it will not. If the follow parameter is not configured, its default value will be determined according to whether there is a callback function to process follow. If there is a callback function to process follow, it will default to False, otherwise it will be True.
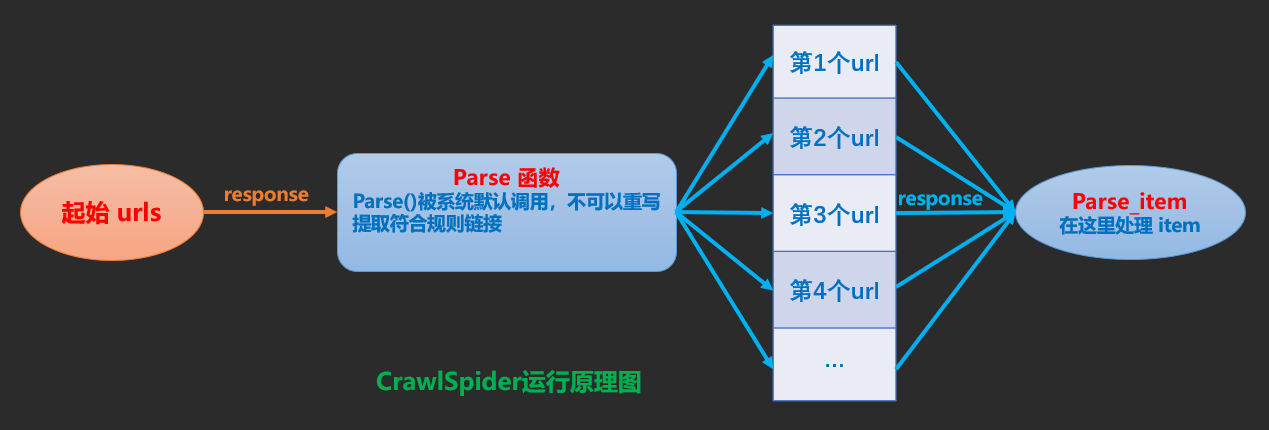
10.7 CrawlSpiser case
Requirements: reading King data warehousing, data saving to local and mysql database
Terminal
# Create project https://www.dushu.com/book/1107.html
scrapy startproject scrapy17_readbook
# Switch to spiders directory
cd .\scrapy17_readbook\scrapy17_readbook\spiders\
# Create a crawler file (Note: the - t crawl parameter is added here)
scrapy genspider -t crawl read www.dushu.com/book/1107.html
# Remove start_urls at the end of the link/
# start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html / '] # this path is incorrect
# start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html '] # delete the at the end/
# Comment out the robots protocol in settings.py
# Obey robots.txt rules
# ROBOTSTXT_OBEY = True # It is on by default. In line 20 of the code, comment it out
# If you need to use the pipeline, you need to open the pipeline in settings. The code is 65 lines. Uncomment. 300 is the priority. The smaller the value, the higher the priority. The priority value is 1-1000
ITEM_PIPELINES = {
'scrapy17_dangdang.pipelines.Scrapy17DangdangPipeline': 300,
}
# Run crawler file
scrapy crawl read
Crawl to the local and save it as a read.json file
Project structure
code
read.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy17_readbook.items import Scrapy17ReadbookItem
class ReadSpider(CrawlSpider):
name = 'read'
allowed_domains = ['www.dushu.com']
# In book.json, after formatting, a total of 1440 / 3 / 40 = 12 pages are crawled. If one page is missing, it is the home page. The home page does not match the rules, so it is not implemented
# start_urls = ['http://www.dushu.com/book/1107.html']
# If you use the allow parameter of the rules rule of crawlespider, remember to match page 1 to the rule (add _1before the. html suffix)
# Otherwise, like the link on page 1 above, it will not be matched in the rule of allow parameter. If it does not match the link in the rule, it will not be executed,
# So, remember to add_ 1 (of course, the home page link after adding _1should be accessible. If it is not accessible, we should find another way to solve it)
# In book.json, after formatting, a total of 1560 / 3 / 40 = 13 pages are crawled, no more, no less, just right
start_urls = ['http://www.dushu.com/book/1107_1.html '] # home page and other pages match the allowed rules written by yourself, not necessarily all of them_ 1. Flexible application
rules = (
# Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
# \d: Number \.: Escape.. to prevent this symbol from not taking effect sometimes
Rule(LinkExtractor(allow=r'/book/1107_\d+\.html'), callback='parse_item', follow=False),
)
def parse_item(self, response):
# item = {}
#item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
#item['name'] = response.xpath('//div[@id="name"]').get()
#item['description'] = response.xpath('//div[@id="description"]').get()
# return item
img_list = response.xpath('//div[@class="bookslist"]/ul/li//img')
for img in img_list:
name = img.xpath('./@alt').extract_first()
src = img.xpath('./@data-original').extract_first()
book = Scrapy17ReadbookItem(name=name,src=src)
yield book
items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class Scrapy17ReadbookItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# pass
name = scrapy.Field()
src = scrapy.Field()
pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class Scrapy17ReadbookPipeline:
def open_spider(self, spider):
self.fp = open('book.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self, spider):
self.fp.close()
settings.py
# Scrapy settings for scrapy17_readbook project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'scrapy17_readbook'
SPIDER_MODULES = ['scrapy17_readbook.spiders']
NEWSPIDER_MODULE = 'scrapy17_readbook.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'scrapy17_readbook (+http://www.yourdomain.com)'
# Obey robots.txt rules
# ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'scrapy17_readbook.middlewares.Scrapy17ReadbookSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'scrapy17_readbook.middlewares.Scrapy17ReadbookDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'scrapy17_readbook.pipelines.Scrapy17ReadbookPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
Next, the crawled data is stored in the database
11. Data warehousing
# mysql preparatory work
# Start mysql service
mysqlserver start
# Login to mysql
# mysql -h ip -u root -p
# mysql -h localhost -u root -p # Local login (default port: 3306, which can be omitted and not written. If you need to specify the port, bring the parameter uppercase - P, [password is lowercase - P]: - P)
# mysql -h 127.0.0.1 -u root -p # Local login
# mysql -u root -p # Local login
# mysql -uroot -p # Local login
# mysql -h 192.168.xxx.xxx -u root -p # Remote login of other hosts (e.g. 192.168.20.13)
mysql -u root -p
# Create database
create database spider01;
# Switch to database
use spider01
# Create table
create table book(
id int primary key auto_increment,
name varchar(128),
src varchar(128)
);
# View all data of the table (take the book table as an example)
select * form book;
# Check the host ip address (for example, my ip address is 192.168.0.9)
ifconfig # perhaps
ip addr
#================================================================================
# 1. In the crawler project settings file, configure some relevant parameters for connecting to the database. You can configure the following parameters anywhere. I'm used to adding them at the end
DB_HOST = '192.168.XXX.XXX'
DB_PORT = 3306
DB_USER = 'root'
DB_PASSWORD = 'XXXXXX'
DB_NAME = 'database'
DB_CHARSET = 'utf-8'
# Custom pipes, in the pipelines.py file
class MysqlPipeline:
def process_item(self, item, spider):
return item
# For pipe configuration, in the settings file, add a custom pipe in line 65 (priority 1-1000. The smaller the value, the higher the priority)
# Format: 'project name. pipelines. Custom pipeline name': priority,
ITEM_PIPELINES = {
'scrapy17_readbook.pipelines.Scrapy17ReadbookPipeline': 300,
'scrapy17_readbook.pipelines.MysqlPipeline': 301, # Custom pipe
}
# Load settings file
from scrapy.utils.project import get_project_settings
import pymysql
class MysqlPipeline(object):
# Follow pymysql (installed, please skip)
pip install pymysql
# Connect to pymysql
pymysql.connect(host,port,user,password,db,charset)
conn.cursor()
# Execute sql statement
cursor.execute()
# Submit
conn.commit()
# close
cursor.close()
conn.close()
# Run crawler file
scrapy crawl read
Terminal
# Run crawler file scrapy crawl read
Crawl to mysql database
Project structure
Database (4520 books in total, 12000 / 3 / 40 = 100 pages)
code
read.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy17_readbook.items import Scrapy17ReadbookItem
class ReadSpider(CrawlSpider):
name = 'read'
allowed_domains = ['www.dushu.com']
# In book.json, after formatting, a total of 1440 / 3 / 40 = 12 pages are crawled. If one page is missing, it is the home page. The home page does not match the rules, so it is not implemented
# start_urls = ['http://www.dushu.com/book/1107.html']
# If you use the allow parameter of the rules rule of crawlespider, remember to match page 1 to the rule (add _1before the. html suffix)
# Otherwise, like the link on page 1 above, it will not be matched in the rule of allow parameter. If it does not match the link in the rule, it will not be executed,
# So, remember to add_ 1 (of course, the home page link after adding _1should be accessible. If it is not accessible, we should find another way to solve it)
# In book.json, after formatting, a total of 1560 / 3 / 40 = 13 pages are crawled, no more, no less, just right
start_urls = ['http://www.dushu.com/book/1107_1.html '] # home page and other pages match the allowed rules written by yourself, not necessarily all of them_ 1. Flexible application
rules = (
# Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
# \d: Number \.: Escape.. to prevent this symbol from not taking effect sometimes
Rule(LinkExtractor(allow=r'/book/1107_\d+\.html'), callback='parse_item', follow=True),
)
def parse_item(self, response):
# item = {}
#item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
#item['name'] = response.xpath('//div[@id="name"]').get()
#item['description'] = response.xpath('//div[@id="description"]').get()
# return item
img_list = response.xpath('//div[@class="bookslist"]/ul/li//img')
for img in img_list:
name = img.xpath('./@alt').extract_first()
src = img.xpath('./@data-original').extract_first()
book = Scrapy17ReadbookItem(name=name,src=src)
yield book
items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class Scrapy17ReadbookItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# pass
name = scrapy.Field()
src = scrapy.Field()
pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
# Load settings file
from scrapy.utils.project import get_project_settings
import pymysql
class Scrapy17ReadbookPipeline:
def open_spider(self, spider):
self.fp = open('book.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self, spider):
self.fp.close()
class MysqlPipeline:
def open_spider(self, spider):
settings = get_project_settings()
# Connect to database
# DB_HOST = '192.168.0.9'
# DB_PORT = 3306
# DB_USER = 'root'
# DB_PASSWORD = 'root'
# DB_NAME = 'spider01'
# DB_CHARSET = 'utf8'
self.host = settings['DB_HOST']
self.port = settings['DB_PORT']
self.username = settings['DB_USER']
self.password = settings['DB_PASSWORD']
self.databasename = settings['DB_NAME']
self.charset = settings['DB_CHARSET']
self.connect()
def connect(self):
self.conn = pymysql.connect(host=self.host, port=self.port, user=self.username, password=self.password,
db=self.databasename, charset=self.charset)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
sql = 'insert into book(name, src) values ("{}", "{}")'.format(item['name'], item['src'])
# Execute sql statement
self.cursor.execute(sql)
# Submit
self.conn.commit()
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
settings.py
# Scrapy settings for scrapy17_readbook project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'scrapy17_readbook'
SPIDER_MODULES = ['scrapy17_readbook.spiders']
NEWSPIDER_MODULE = 'scrapy17_readbook.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'scrapy17_readbook (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'scrapy17_readbook.middlewares.Scrapy17ReadbookSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'scrapy17_readbook.middlewares.Scrapy17ReadbookDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'scrapy17_readbook.pipelines.Scrapy17ReadbookPipeline': 300,
'scrapy17_readbook.pipelines.MysqlPipeline': 301,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
# Connect to database
DB_HOST = '192.168.0.9'
DB_PORT = 3306
DB_USER = 'root'
DB_PASSWORD = 'root'
DB_NAME = 'spider01'
DB_CHARSET = 'utf8' # This is utf8, No-
12. Log information and log level
12.1 log level
- DEBUG: DEBUG information [highest level, default log level]
- INFO: general notification information
- WARNING: WARNING message
- ERROR: general ERROR
- CRITICAL: CRITICAL error [lowest level]
Default log level: DEBUG. If the log level is above CRITICAL, its own logs and logs below it will be printed.
12.2 settings.py file settings
Specify the log level in the settings.py file and append it anywhere
LOG_LEVEL: sets the level of log display, that is, what is displayed and what is not displayed
LOG_FILE: record all the information displayed on the screen into the xxx.log file. The screen will no longer display. Note that the file suffix must be. Log
# Specify the level of the log [general default, not modifiable] # LOG_LEVEL = 'WARNING' # Log file [must have] LOG_FILE = 'logdemo.log'
12.3 cases
Terminal
# Create project https://www.baidu.com/
scrapy startproject scrapy17_log
# Switch to spiders directory
cd .\scrapy17_log\scrapy17_log\spiders\
# Create a crawler file (here is just a demonstration of log level and log related information. There is no need to crawl. Take Baidu as an example)
scrapy genspider log www.baidu.com
# Remove start_urls at the end of the link/
# start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html / '] # this path is incorrect
# start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html '] # delete the at the end/
# Comment out the robots protocol in settings.py
# Obey robots.txt rules
# ROBOTSTXT_OBEY = True # It is on by default. In line 20 of the code, comment it out
# If you need to use the pipeline, you need to open the pipeline in settings. The code is 65 lines. Uncomment. 300 is the priority. The smaller the value, the higher the priority. The priority value is 1-1000
ITEM_PIPELINES = {
'scrapy17_dangdang.pipelines.Scrapy17DangdangPipeline': 300,
}
# Run crawler file
scrapy crawl log
Project structure
code
settings.py
# Scrapy settings for scrapy17_log project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'scrapy17_log'
SPIDER_MODULES = ['scrapy17_log.spiders']
NEWSPIDER_MODULE = 'scrapy17_log.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'scrapy17_log (+http://www.yourdomain.com)'
# Obey robots.txt rules
# ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'scrapy17_log.middlewares.Scrapy17LogSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'scrapy17_log.middlewares.Scrapy17LogDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# 'scrapy17_log.pipelines.Scrapy17LogPipeline': 300,
#}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
# Specify the level of the log [general default, not modifiable]
# LOG_LEVEL = 'WARNING'
# Log file [must have]
LOG_FILE = 'logdemo.log'
13. post request of the scratch
# 1. Rewrite start_requests() def start_requests(self) # 2.start_ Return value of requests # url: post address to send # headers: header information can be customized # Callback: callback function # formdata: the data carried by post. This is a dictionary scrapy.FormRequest(url=url, headers=headers,callback=self.parse_item,formdata=data)
14. Agency
# 1. In settings.py, open the option, code line 53, and cancel the comment
DOWNLOADER_MIDDLEWARES = {
'scrapy17_log.middlewares.Scrapy17LogDownloaderMiddleware': 543,
}
# 2. Write code in middlewares.py
def process_request(self, request, spider):
request.meta['proxy'] = 'https://36.43.62.12:6123'
return None
14.1 cases
Baidu translation
Terminal
# Create project https://fanyi.baidu.com/sug
scrapy startproject scrapy17_translatebaidu
# Switch to spiders directory
cd .\scrapy17_translatebaidu\scrapy17_translatebaidu\spiders\
# Create a crawler file (it is a post request)
scrapy genspider fanyi fanyi.baidu.com/sug
# Remove start_urls at the end of the link/
# start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html / '] # this path is incorrect
# start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html '] # delete the at the end/
# Comment out the robots protocol in settings.py
# Obey robots.txt rules
# ROBOTSTXT_OBEY = True # It is on by default. In line 20 of the code, comment it out
# If you need to use the pipeline, you need to open the pipeline in settings. The code is 65 lines. Uncomment. 300 is the priority. The smaller the value, the higher the priority. The priority value is 1-1000
ITEM_PIPELINES = {
'scrapy17_dangdang.pipelines.Scrapy17DangdangPipeline': 300,
}
# Run crawler file
scrapy crawl fanyi
Project structure
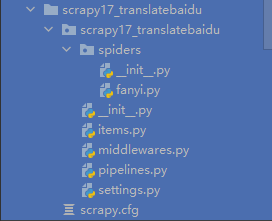
fanyi.py
import json
import scrapy
class FanyiSpider(scrapy.Spider):
name = 'fanyi'
allowed_domains = ['fanyi.baidu.com/sug']
# This is a post request. If the post request has no parameters, it has no meaning, so starts_urls is useless, resulting in the useless parse method
# post request and start_urls and parse have nothing to do with each other
# start_urls = ['http://fanyi.baidu.com/sug/']
# def parse(self, response):
# pass
def start_requests(self):
url = 'https://fanyi.baidu.com/sug'
data = {'kw': 'air'}
yield scrapy.FormRequest(url=url, formdata=data, callback=self.parse_second)
def parse_second(self, response):
content = response.text
# print(content)
# obj = json.loads(content, encoding='utf-8')
# python 3 does not need to bring the encoding parameter, but it will report an error
obj = json.loads(content)
print(obj)