I want to read a novel in my spare time. I plan to download it to the computer. After searching for a long time, I can't find a website to download. So I want to crawl the content of the novel and save it locally.
Chapter 1 The Faramita Flowers in the Desert-Chendong-6 Mao Novels Network http://www.6mao.com/html/40/40184/12601161.html
This is the web page to crawl.
Observation structure

Next chapter

Then start creating scrapy projects:
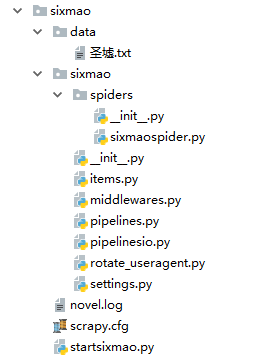
Among them, sixmaospider.py:
# -*- coding: utf-8 -*- import scrapy from ..items import SixmaoItem class SixmaospiderSpider(scrapy.Spider): name = 'sixmaospider' #allowed_domains = ['http://www.6mao.com'] start_urls = ['http://www.6mao.com/html/40/40184/12601161.html'] #Holy ruins def parse(self, response): novel_biaoti = response.xpath('//div[@id="content"]/h1/text()').extract() #print(novel_biaoti) novel_neirong=response.xpath('//div[@id="neirong"]/text()').extract() print(novel_neirong) #print(len(novel_neirong)) novelitem = SixmaoItem() novelitem['novel_biaoti'] = novel_biaoti[0] print(novelitem['novel_biaoti']) for i in range(0,len(novel_neirong),2): #print(novel_neirong[i]) novelitem['novel_neirong'] = novel_neirong[i] yield novelitem #Next chapter nextPageURL = response.xpath('//div[@class="s_page"]/a/@href').extract() # Take the address of the next page nexturl='http://www.6mao.com'+nextPageURL[2] print('Next chapter',nexturl) if nexturl: url = response.urljoin(nexturl) # Send the next page request and call it parse()Function Continuation Analysis yield scrapy.Request(url, self.parse, dont_filter=False) pass else: print("Sign out") pass
pipelinesio.py saves content to local files
import os print(os.getcwd()) class SixmaoPipeline(object): def process_item(self, item, spider): #print(item['novel']) with open('./data/Holy ruins.txt', 'a', encoding='utf-8') as fp: fp.write(item['novel_neirong']) fp.flush() fp.close() return item print('Write file successfully')
items.py
import scrapy class SixmaoItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() novel_biaoti=scrapy.Field() novel_neirong=scrapy.Field() pass
startsixmao.py, right-click the run directly, and the project will start running.
from scrapy.cmdline import execute execute(['scrapy', 'crawl', 'sixmaospider'])
settings.py
LOG_LEVEL='INFO' #This is a log. LOG_FILE='novel.log' DOWNLOADER_MIDDLEWARES = { 'sixmao.middlewares.SixmaoDownloaderMiddleware': 543, 'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware' : None, 'sixmao.rotate_useragent.RotateUserAgentMiddleware' :400 #This line uses the proxy } ITEM_PIPELINES = { #'sixmao.pipelines.SixmaoPipeline': 300, 'sixmao.pipelinesio.SixmaoPipeline': 300, } #stay pipelines The output pipe adds this SPIDER_MIDDLEWARES = { 'sixmao.middlewares.SixmaoSpiderMiddleware': 543, } #Opening the middleware should leave the rest unchanged
rotate_useragent.py Proxy the project to prevent it from being banned by the server
# Import random Modular import random # Import useragent User Agent Module UserAgentMiddleware class from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware # RotateUserAgentMiddleware Class, inheritance UserAgentMiddleware Parent class # Function: Create a dynamic proxy list, randomly select the header information of the user proxy in the list, and disguise the request. # Bind every request of the crawler program and send it to the web site. # Crawler technology: Because many websites have anti-crawler technology, crawler programs are prohibited from accessing webpages directly. # Therefore, we need to create a dynamic proxy, which disguises the crawler simulation as a browser for web page access. class RotateUserAgentMiddleware(UserAgentMiddleware): def __init__(self, user_agent=''): self.user_agent = user_agent def process_request(self, request, spider): #This sentence is used for random rotation. user-agent ua = random.choice(self.user_agent_list) if ua: # Output automatic rotation user-agent print(ua) request.headers.setdefault('User-Agent', ua) # the default user_agent_list composes chrome,I E,firefox,Mozilla,opera,netscape # for more user agent strings,you can find it in http://www.useragentstring.com/pages/useragentstring.php # Writing Header Request Agent List user_agent_list = [\ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"\ "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",\ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",\ "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",\ "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",\ "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",\ "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",\ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",\ "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",\ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",\ "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",\ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",\ "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",\ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",\ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",\ "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",\ "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",\ "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24" ]
The final operation results are as follows:
Naona, this is a small scrapy project.