We connect Linux to implement regular expressions
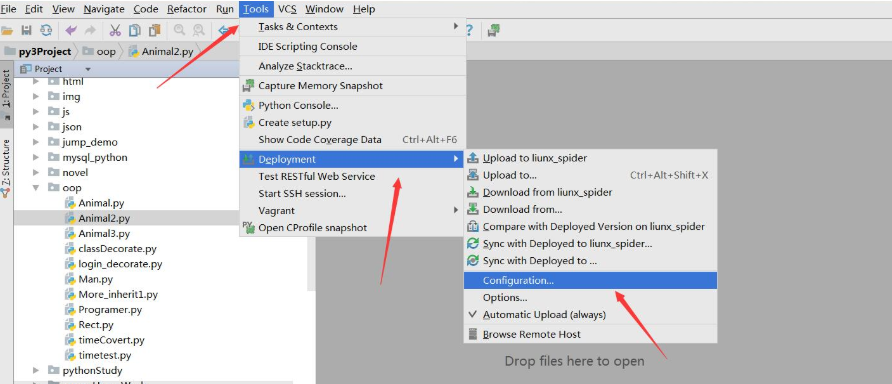
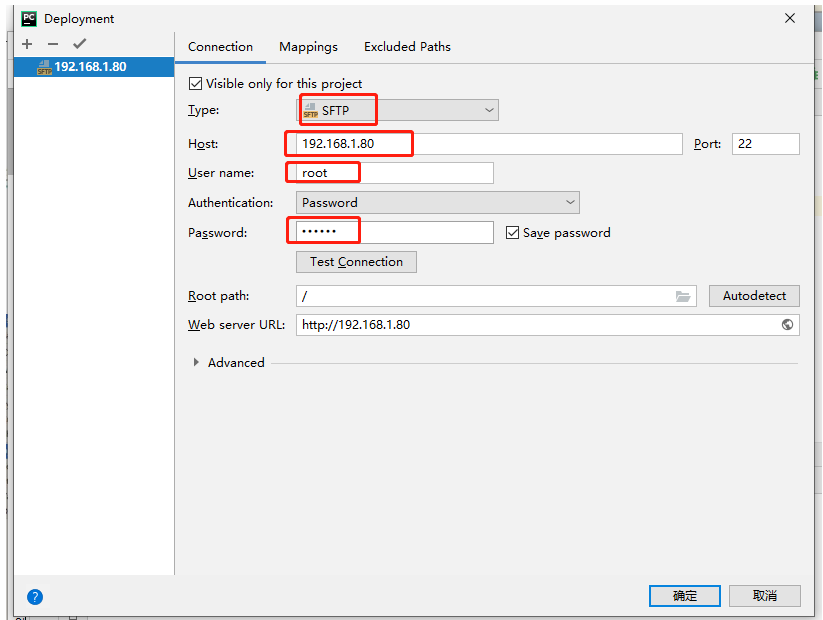
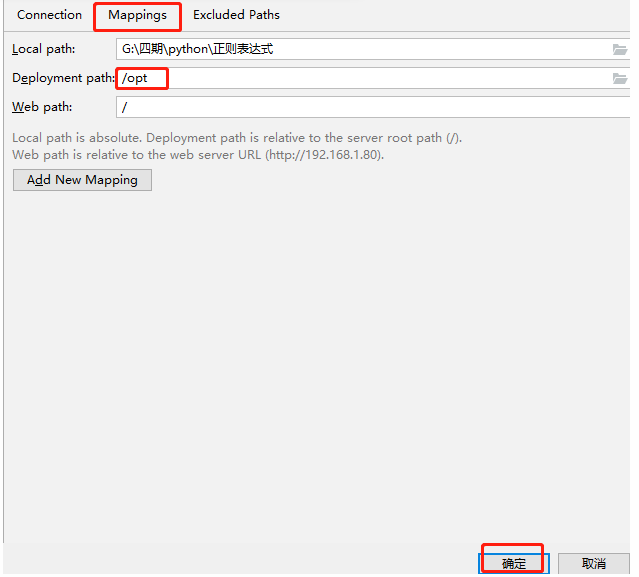
1. Python3 Regular Expressions
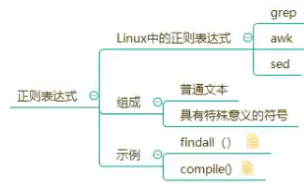
Regular expressions are a special sequence of characters that help you easily check if a string matches a pattern.
Python has added the re module since version 1.5 to provide Perl-style regular expression patterns.
The re module gives the Python language full regular expression functionality.
The compile function generates a regular expression object based on a pattern string and an optional flag parameter.The object has a series of methods for regular expression matching and substitution.
The re module also provides functions that are fully consistent with these methods and use a pattern string as their first parameter.
This chapter focuses on the regular expression processing functions commonly used in Python. If you don't know about regular expressions, you can see our Regular Expression-Tutorial.
1,re.split
The split method divides a string into matching substrings and returns a list as follows:
re.split(pattern, string[, maxsplit=0, flags=0])
Parameters:
| parameter | describe |
|---|---|
| pattern | Matching Regular Expressions |
| string | The string to match. |
| maxsplit | Number of delimitations, maxsplit=1 delimits once, defaulting to 0, unlimited number of times. |
| flags | Flag bits, used to control how regular expressions are matched, such as case-sensitive, multi-line matching, and so on.See: Regular Expression Modifier-Optional Flag |
Example
import re
# fLags=re.IGNORECASE: Ignore case
data = 'Last login: Tue Mar 31 17:56:11 2020 from 192.168.1.80'
new_data = re.split('[:.]\s*', data)
print(new_data)
print(data.split(': '))The output from the above example is as follows:
['Last login', 'Tue Mar 31 17', '56', '11 2020 from 192', '168', '1', '80'] ['Last login', 'Tue Mar 31 17:56:11 2020 from 192.168.1.80']
The following is the basic syntax for regular expressions:
| Pattern | describe |
|---|---|
| ^ | Beginning of match string |
| $ | Matches the end of the string. |
| . | Matches any character except line breaks. Any character including line breaks can be matched when the re.DOTALL tag is specified. |
| [...] | Used to represent a set of characters, listed separately: [a m k] matches'a','m'or'k' |
| [^...] | Characters not in []: [^a B c] matches characters other than a,b,c. |
| re* | Match 0 or more expressions. |
| re+ | Match one or more expressions. |
| re? | Match zero or one fragment defined by the previous regular expression, non-greedy |
| re{ n} | Matches n previous expressions.For example,'o{2}'cannot match'o' in'Bob', but it can match two'o'in'food'. |
| re{ n,} | Exact match n previous expressions.For example, "o{2,}" does not match "o" in "Bob", but matches all o in "foood"."o{1,}" is equivalent to "o+"."o{0,}" is equivalent to "o*". |
| re{ n, m} | Matches fragments n to m times defined by previous regular expressions, greedy |
2. Special Character Classes
| Example | describe |
|---|---|
| . | Matches any single character except'\n'.To match any character including'\n', use a pattern like'[. \n]'. |
| \d | Matches a numeric character.Equivalent to [0-9]. |
| \D | Matches a non-numeric character.Equivalent to [^0-9]. |
| \s | Match any white space characters, including spaces, tabs, page breaks, and so on.Equivalent to [\f\n\rt\v]. |
| \S | Matches any non-whitespace characters.Equivalent to [^ \f\nrt\v]. |
| \w | Match any word character that includes an underscore.Equivalent to'[A-Za-z0-9_]'. |
| \W | Match any non-word characters.Equivalent to'[^A-Za-z0-9_]'. |
# ?[a-zA-Z]+
# To match possible spaces before and after a word, [a-zA-Z] stands for one or more English letters
# Match an IP address 192.168.1.80
# [0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}3. findall function
Finds all the substrings matched by the regular expression in the string and returns a list, or an empty list if no match is found.
Note: match and search are matches that match all findall s at once.
The grammar format is:
re.findall(string[, pos[, endpos]])
Parameters:
- String The string to be matched.
- pos optional parameter that specifies the starting position of the string, defaulting to 0.
- The endpos optional parameter specifies the end position of the string, defaulting to the length of the string.
Find all the numbers in the string:
import re
pattern = re.compile(r'\d+') # Find Numbers
result1 = pattern.findall('runoob 123 google 456')
result2 = pattern.findall('run88oob123google456', 0, 10)
print(result1)
print(result2)The output from the above example is as follows:
['123', '456'] ['88', '12']
4. compile function
The compile function compiles a regular expression and generates a Pattern object for use by the match() and search() functions.
The grammar format is:
re.compile(pattern[, flags])
Parameters:
- pattern: A regular expression in the form of a string
- flags are optional and represent matching patterns, such as ignoring case and multiline patterns, with specific parameters:
-
-
re.I ignores case
- re.L denotes the special character set\w, \W, \b, \B, \s, \S depending on the current environment
- re.M Multiline Mode
- re.S is'. 'and any characters including line breaks ('.' excludes line breaks)
- re.U stands for the special character set\w, \W, \b, \B, \d, \D, \s, \S depending on the Unicode character attribute database
- re.X Ignores spaces and comments after '#' for readability
-
Example 1
>>>import re
>>> pattern = re.compile(r'\d+') # Used to match at least one number
>>> m = pattern.match('one12twothree34four') # Find header, no match
>>> print( m )
None
>>> m = pattern.match('one12twothree34four', 2, 10) # Match from'e'position, no match
>>> print( m )
None
>>> m = pattern.match('one12twothree34four', 3, 10) # Match from the position of'1', just match
>>> print( m ) # Return a Match object
<_sre.SRE_Match object at 0x10a42aac0>
>>> m.group(0) # Omit 0
'12'
>>> m.start(0) # Omit 0
3
>>> m.end(0) # Omit 0
5
>>> m.span(0) # Omit 0
(3, 5)Above, when the match succeeds, a Match object is returned, where:
- group([group1,...]) The method is used to obtain one or more grouped matching strings, and group() or group(0) can be used directly when the entire matching substring is to be obtained;
- The start([group]) method is used to get the starting position (index of the first character of the substring) of the grouping match throughout the string, and the default value of the parameter is 0.
- The end([group]) method is used to get the end position of the grouped matching substring in the entire string (index + 1 of the last character of the substring), with a default parameter of 0;
- The span([group]) method returns (start (group), end (group).
Example 2
import re
# flags=re. IGNORECASE: ignoring case
data = 'Linux System built-in Python 2.7.5,We installed Python 3.8.1. '
print(re.findall( 'python [0-9]\.[0-9]\.[0-9]', data, flags=re.IGNORECASE))
#
re_obj = re.compile('python [0-9]\.[0-9]\.[0-9]', flags=re.IGNORECASE)
print(re_obj.findall(data))The output from the above example is as follows:
['Python 2.7.5', 'Python 3.8.1'] ['Python 2.7.5', 'Python 3.8.1']
5. Test the reading speed of findall and compile
(1) Generating digital files on Linux
[root@python ~]# seq 10000 > data.txt
(2) pycharm creates files for findall and compile to read data.txt
findall
import re
def main():
pattern = "[0-9]+"
with open('~/data.txt') as f:
for line in f:
re.findall(pattern, line)
if __name__ == 'main':
main()compile
import re
def main() :
pattern = "[0-9]+"
re_obj = re.compile(pattern)
with open("~/data.txt") as f:
for line in f:
re_obj.findall(line)
if __name__ == "main":
main( )(3) Upload files to Linux

The following message appears at the bottom and uploaded successfully

(4) Linux test download speed
Enter uploaded directory/opt
[root@python ~]# cd /opt/ [root@python opt]# cd exercise [root@python Practice]# ls 001.py findall.py compile.py
test
[root@python Practice]# time python3 findall.py real 0m0.058s user 0m0.005s sys 0m0.029s [root@python Practice]# time python3 compile.py real 0m0.018s user 0m0.014s sys 0m0.004s
Tests show that compile s read faster
2. Common re functions
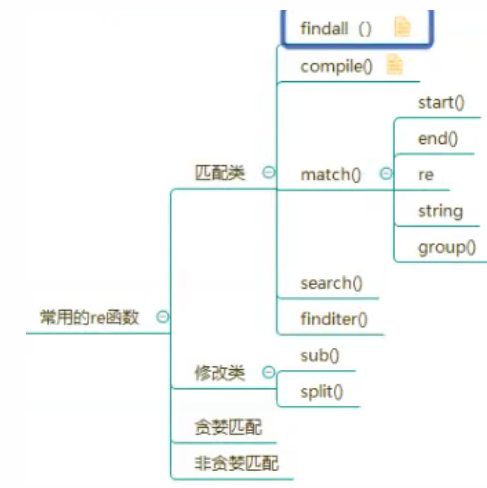
data = 'What is the difference between python 2.7.5 and Python 3.8.1 ?'
import re
print(re.findall('[0-9]\.[0-9]\.[0-9]',data))
print(re.findall('python [0-9]\.[0-9]\.[0-9]',data))
print(re.findall('Python [0-9]\.[0-9]\.[0-9]',data))
print(re.findall('ython [0-9]\.[0-9]\.[0-9]',data))
print(data.startswith('What'))
print(data.endswith('?'))
print(re.match('What',data))
word = "123 is one hender and twentyu-there"
print(re.match('\d+',word))
r = re.match('\d+',word)
print(r)
print(r.start())
print(r.end())
print(r.re)
print(r.group())
print(r.string)
rr = re.finditer('[0-9]\.[0-9]\.[0-9]',data)
print(rr)
# print([r for r in rr])
for it in rr:
print(it.group(0))The above example outputs the results:
# Output number of type'x.x.x'
['2.7.5', '3.8.1']
# Output number of type'python x.x.x'
['python 2.7.5']
# Output a number of type'Python x.x.x'
['Python 3.8.1']
# Output a number of type'ython x.x.x'
['ython 2.7.5', 'ython 3.8.1']
# Find out if'What'is in the data
True
# Find out if'J'is in the data
True
# Find out if'What'is in the data
<re.Match object; span=(0, 4), match='What'>
# Find if there are'numeric characters'in the data
<re.Match object; span=(0, 3), match='123'>
# Find if there are'numeric characters'in the data
<re.Match object; span=(0, 3), match='123'>
# The starting position of a matched substring in the entire string
0
# The end position of the matched substring in the entire string
3
# Gets the type of re function
re.compile('\\d+')
# Get one or more grouped matching strings
123
# Matched string
123 is one hender and twentyu-there
# Output rr
<callable_iterator object at 0x000001B92D1613D0>
# Output rr file type'x.x.x'number one line at a time
2.7.5
3.8.1
(1) Matching classes
1. re.match function
re.match attempts to match a pattern from the beginning of the string, and returns none if the match is not successful.
Functional syntax:
re.match(pattern, string, flags=0)
Function parameter description:
| parameter | describe |
|---|---|
| pattern | Matching Regular Expressions |
| string | The string to match. |
| flags | Flag bits, used to control how regular expressions are matched, such as case-sensitive, multi-line matching, and so on.See: Regular Expression Modifier-Optional Flag |
The match successful re.match method returns a matching object, otherwise returns None.
We can use the group(num) or groups() Match Object function to get a match expression.
| Match Object Method | describe |
|---|---|
| group(num=0) | A string of matching entire expressions in which group() can enter more than one group number at a time, in which case it will return a tuple containing the corresponding values for those groups. |
| groups() | Returns a tuple containing all the group strings, from 1 to the group number contained. |
import re
print(re.match('www', 'www.runoob.com').span()) # Match at start position
print(re.match('com', 'www.runoob.com')) # Not Matching at StartThe above example outputs the results:
(0, 3) None
import re
line = "Cats are smarter than dogs"
# *Indicates any matching of any single or multiple characters other than line breaks (\n, \r)
matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)
if matchObj:
print ("matchObj.group() : ", matchObj.group())
print ("matchObj.group(1) : ", matchObj.group(1))
print ("matchObj.group(2) : ", matchObj.group(2))
else:
print ("No match!!")The above example outputs the results:
matchObj.group() : Cats are smarter than dogs matchObj.group(1) : Cats matchObj.group(2) : smarter
2. compile function
The compile function compiles a regular expression and generates a Pattern object for use by the match() and search() functions.
The grammar format is:
re.compile(pattern[, flags])
Parameters:
- pattern: A regular expression in the form of a string
- flags are optional and represent matching patterns, such as ignoring case and multiline patterns, with specific parameters:
-
-
re.I ignores case
- re.L denotes the special character set\w, \W, \b, \B, \s, \S depending on the current environment
- re.M Multiline Mode
- re.S is'. 'and any characters including line breaks ('.' excludes line breaks)
- re.U stands for the special character set\w, \W, \b, \B, \d, \D, \s, \S depending on the Unicode character attribute database
- re.X Ignores spaces and comments after '#' for readability
-
Example
>>>import re
>>> pattern = re.compile(r'([a-z]+) ([a-z]+)', re.I) # re.I means ignoring case
>>> m = pattern.match('Hello World Wide Web')
>>> print( m ) # Match succeeded, returning a Match object
<_sre.SRE_Match object at 0x10bea83e8>
>>> m.group(0) # Returns the entire substring that matched successfully
'Hello World'
>>> m.span(0) # Returns the index of the entire substring that matched successfully
(0, 11)
>>> m.group(1) # Returns the first successful substring for grouping matching
'Hello'
>>> m.span(1) # Returns the index of the first group matching successful substring
(0, 5)
>>> m.group(2) # Returns the substring of the second group matching success
'World'
>>> m.span(2) # Returns the substring index of the second group that matched successfully
(6, 11)
>>> m.groups() # Equivalent to (m.group(1), m.group(2),...)
('Hello', 'World')
>>> m.group(3) # No third grouping exists
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: no such groupAbove, when the match succeeds, a Match object is returned, where:
- group([group1,...]) The method is used to obtain one or more grouped matching strings, and group() or group(0) can be used directly when the entire matching substring is to be obtained;
- The start([group]) method is used to get the starting position (index of the first character of the substring) of the grouping match throughout the string, and the default value of the parameter is 0.
- The end([group]) method is used to get the end position of the grouped matching substring in the entire string (index + 1 of the last character of the substring), with a default parameter of 0;
- The span([group]) method returns (start (group), end (group).
3. re.search method
re.search scans the entire string and returns the first successful match.
Functional syntax:
re.search(pattern, string, flags=0)
Function parameter description:
| parameter | describe |
|---|---|
| pattern | Matching Regular Expressions |
| string | The string to match. |
| flags | Flag bits, used to control how regular expressions are matched, such as case-sensitive, multi-line matching, and so on.See: Regular Expression Modifier-Optional Flag |
The matched successful re.search method returns a matching object, otherwise returns None.
We can use the group(num) or groups() Match Object function to get a match expression.
| Match Object Method | describe |
|---|---|
| group(num=0) | A string of matching entire expressions in which group() can enter more than one group number at a time, in which case it will return a tuple containing the corresponding values for those groups. |
| groups() | Returns a tuple containing all the group strings, from 1 to the group number contained. |
Example
import re
print(re.search('www', 'www.runoob.com').span()) # Match at start position
print(re.search('com', 'www.runoob.com').span()) # Not Matching at StartThe above example outputs the results:
(0, 3) (11, 14)
4. Differences between re.match and re.search
re.match matches only the beginning of the string. If the beginning of the string does not match the regular expression, the match fails, the function returns None, and re.search matches the entire string until a match is found.
import re
line = "Cats are smarter than dogs"
matchObj = re.match( r'dogs', line, re.M|re.I)
if matchObj:
print ("match --> matchObj.group() : ", matchObj.group())
else:
print ("No match!!")
matchObj = re.search( r'dogs', line, re.M|re.I)
if matchObj:
print ("search --> matchObj.group() : ", matchObj.group())
else:
print ("No match!!")The above example outputs the results:
No match!! search --> matchObj.group() : dogs
5. Parameters:
| parameter | describe |
|---|---|
| pattern | Matching Regular Expressions |
| string | The string to match. |
| flags | Flag bits, used to control how regular expressions are matched, such as case-sensitive, multi-line matching, and so on.See: Regular Expression Modifier-Optional Flag |
Example
import re
it = re.finditer(r"\d+","12a32bc43jf3")
for match in it:
print (match.group() )Output results:
12 32 43 3
(2) Modifying classes
1. Retrieval and Replacement
Python's re module provides re.sub s to replace matches in strings.
Grammar:
re.sub(pattern, repl, string, count=0, flags=0)
Parameters:
- Pattern: The pattern string in the regular.
- repl: Replaced string, or a function.
- String: The original string to be replaced by the search.
- count: Maximum number of replacements after pattern matching, default 0 means replacing all matches.
- flags: Compile-time matching pattern, in numeric form.
The first three parameters are required, and the last two are optional.
import re
phone = "2004-959-559 # This is a telephone number.
# Delete Note
num = re.sub(r'#.*$', "", phone)
print ("Phone number : ", num)
# Remove content other than numbers
num = re.sub(r'\D', "", phone)
print ("Phone number : ", num)Output results:
Phone number: 2004-959-559 Phone number: 2004959559
The repl parameter is a function
In the following example, the matching number in the string is multiplied by 2:
import re
# Multiply the matching number by 2
def double(matched):
value = int(matched.group('value'))
return str(value * 2)
s = 'A23G4HFD567'
print(re.sub('(?P<value>\d+)', double, s))Output results:
A46G8HFD1134
2,re.split
The split method divides a string into matching substrings and returns a list as follows:
re.split(pattern, string[, maxsplit=0, flags=0])
| parameter | describe |
|---|---|
| pattern | Matching Regular Expressions |
| string | The string to match. |
| maxsplit | Number of delimitations, maxsplit=1 delimits once, defaulting to 0, unlimited number of times. |
| flags | Flag bits, used to control how regular expressions are matched, such as case-sensitive, multi-line matching, and so on.See: Regular Expression Modifier-Optional Flag |
>>>import re
>>> re.split('\W+', 'runoob, runoob, runoob.')
['runoob', 'runoob', 'runoob', '']
>>> re.split('(\W+)', ' runoob, runoob, runoob.')
['', ' ', 'runoob', ', ', 'runoob', ', ', 'runoob', '.', '']
>>> re.split('\W+', ' runoob, runoob, runoob.', 1)
['', 'runoob, runoob, runoob.']
>>> re.split('a*', 'hello world') # Split does not split a string for which no match can be found
['hello world'](3) Greedy and non-greedy modes
1. Concepts
Let's start with an example:
example = "abbbbbbc"
pattern = re.compile("ab+")Greedy pattern: Regular expressions tend to match at the maximum length, also known as greedy matching.If the pattern pattern pattern is used above to match the string example, the result of the match is the entire string of "abbbb".
Non-greedy pattern: match as few as possible, provided the entire expression matches successfully.If the pattern pattern pattern pattern is used above to match the string example, the only result to match is the entire string of "ab".
2. Usage
In python, greedy mode is used by default, and in the case of non-greedy mode, just add a question mark directly after the quantifier?".
In the first article, there are five quantifiers in regular expressions:
3. Principle analysis
Greedy is the default in regular expressions. In the example above, the whole expression can be successfully matched when "ab" is already matched, but since greedy is used, matching needs to continue to occur later, and longer strings can be matched when checking.Until the last "b" is matched, there is no string that can be successfully matched. The match ends.Returns the matching result "abbbb".
So we can think of the greedy pattern as matching as much as possible, given that the entire expression matches successfully.
The non-greedy pattern is to change the regular expression "ab+" to "ab+?" in our example. When matched to "ab", the match succeeded, ending the match directly, and returning the matched string "ab" instead of trying backwards.
So we can think of a non-greedy pattern as matching as little as possible, given that the entire expression matches successfully
4. Instances
import re
text = 'Beautifulis better than ugly. Explicit is better than implicit.'
print(re.findall('Beautifulis.*\.',text))
print(re.findall('Beautifulis.*?\.',text))Output results:
['Beautifulis better than ugly. Explicit is better than implicit.'] ['Beautifulis better than ugly.']
5. Summary
1. Greedy and non-greedy from an application perspective
Greedy and non-greedy modes affect the matching behavior of quantifier-modified subexpressions. Greedy modes match as many as possible if the whole expression matches successfully, while non-greedy modes match as few as possible if the whole expression matches successfully.
2. Greedy and non-greedy from the point of view of matching principle
The greedy and non-greedy modes that can achieve the same matching result are usually more efficient to match.All non-greedy modes can be converted to greedy mode by modifying quantifier-modified subexpressions.Greedy mode can be combined with solid grouping to improve matching efficiency, but not greedy mode.
(4) Python3 replace() method
describe
The replace() method replaces old (old string) with new (new string) in the string and, if a third parameter, max, no more than max times.
grammar
replace() method syntax:
str.replace(old, new[, max])
parameter
- old -- The substring to be replaced.
- New -- A new string that replaces the old substring.
- Max -- Optional string, replaced no more than max times
Return value
Returns the new string generated by replacing old (old string) with new (new string) in a string, and no more than max times if a third parameter, max, is specified.
Example
The following examples show how to use the replace() function:
data = 'What is the difference between python 2.7.5 and Python 3.8.1 ?'
print(data)
import re
r_data = data.replace('2.7.5','x.x.x')
r_data2 = r_data.replace('3.8.1','x.x.x')
print(r_data2)
print(re.sub('[0-9]\.[0-9]\.[0-9]','x.x.x',data))
print(data.split())
print(re.split('[ .]+',data))Output results:
What is the difference between python 2.7.5 and Python 3.8.1 ? What is the difference between python x.x.x and Python x.x.x ? What is the difference between python x.x.x and Python x.x.x ? ['What', 'is', 'the', 'difference', 'between', 'python', '2.7.5', 'and', 'Python', '3.8.1', '?'] ['What', 'is', 'the', 'difference', 'between', 'python', '2', '7', '5', 'and', 'Python', '3', '8', '1', '?']
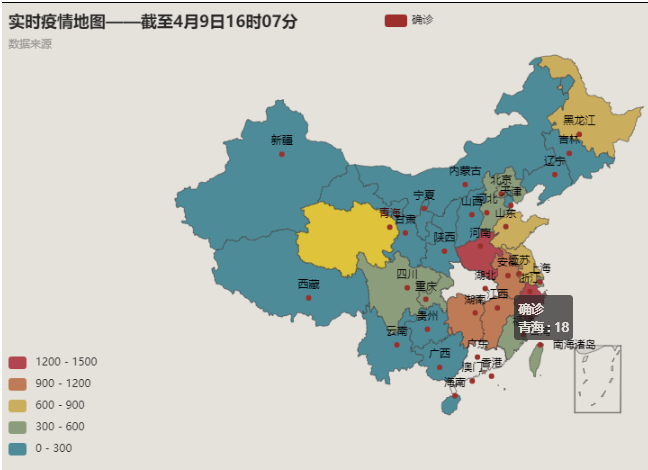
(5) Draw a simple epidemic map
from pyecharts.charts import Map
from pyecharts import options as opt
import requests
import json
#get data
data = requests.get( 'https://gwpre.sina.cn/interface/fymap2020_data.json').content
data = json.loads(data)
print(data)
#Filter data
sub_data = list()
for i in data['data']['list']:
sub_data.append((i['name'],i['value']))
print(sub_data)
#Mapping China
map_info = Map()
#Set up basic information for the map
map_info.set_global_opts(title_opts=opt.TitleOpts('Real-time epidemic map-'+data['data' ]['times']
,subtitle='data sources',
subtitle_link='https://news.sina.cn/zt_d/yiqing0121?vt=4&pos=222')
,visualmap_opts=opt.VisualMapOpts (max_=1500,is_piecewise=True))
map_info.add('Diagnosis', sub_data, maptype='china')
#Generate Web Page File
map_info.render( '20200403.html' )After the output, a web page information is generated, which can be seen by executing the web page:
(6) Using regular expressions to resolve all http or https links within a page
import re
import requests
r = requests.get('https://www.lagou.com/beijing')
# print(r)
result = re.findall('"(https?://.*?)"',r.content.decode('utf-8'))
print(result)Output results:
['https://www.lagou.com/beijing/', 'https://www.lagou.com/', 'https://www.lagou.com/about.html', 'http://www.beian.gov.cn/portal/registerSystemInfo?recordcode=11010802024043', 'https://www.lagou.com/upload/oss.js?v=1010'] -----