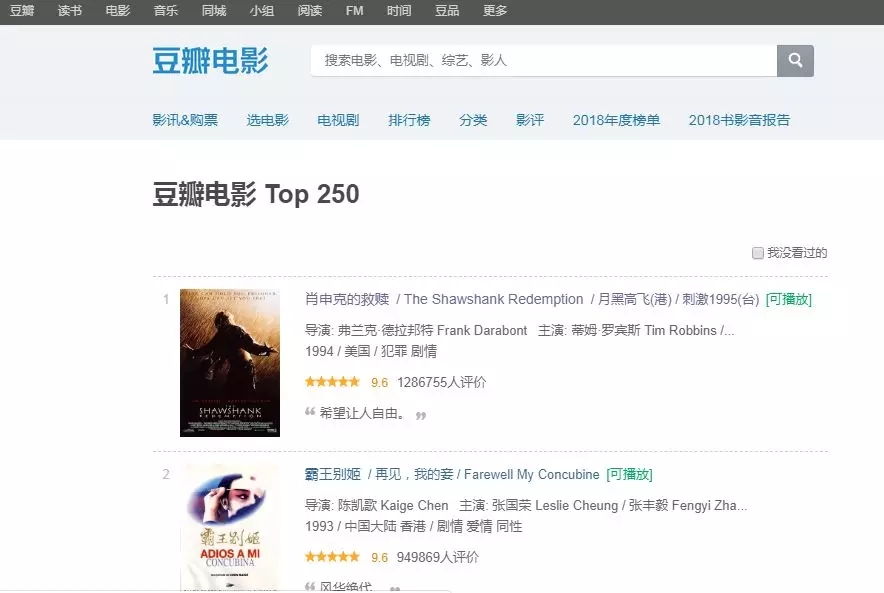
python Reptilian Real-time Project Climbing Bean Flap: 250 Most Popular Movies
The main idea is to request the link of Douban to get the source code of the web page.
Then use BeatifulSoup to get what we want
Finally, the data is stored in excel file
The main idea is to request the link of Douban to get the source code of the web page.
Then use BeatifulSoup to get what we want
Finally, the data is stored in excel file
Project Source Sharing
1 ''' 2 What I don't know in the process of learning can be added to me? 3 python Learning Exchange Button qun,934109170 4 There are good learning tutorials, development tools and e-books in the group. 5 Share with you python Enterprises'Current Demand for Talents and How to Learn Well from Zero Foundation python,And what to learn. 6 ''' 7 8 import requests 9 from bs4 import BeautifulSoup 10 import xlwt 11 12 13 def request_douban(url): 14 try: 15 response = requests.get(url) 16 if response.status_code == 200: 17 return response.text 18 except requests.RequestException: 19 return None 20 21 22 book = xlwt.Workbook(encoding='utf-8', style_compression=0) 23 24 sheet = book.add_sheet('Watercress movie Top250', cell_overwrite_ok=True) 25 sheet.write(0, 0, 'Name') 26 sheet.write(0, 1, 'picture') 27 sheet.write(0, 2, 'ranking') 28 sheet.write(0, 3, 'score') 29 sheet.write(0, 4, 'author') 30 sheet.write(0, 5, 'brief introduction') 31 32 n = 1 33 34 35 def save_to_excel(soup): 36 list = soup.find(class_='grid_view').find_all('li') 37 38 for item in list: 39 item_name = item.find(class_='title').string 40 item_img = item.find('a').find('img').get('src') 41 item_index = item.find(class_='').string 42 item_score = item.find(class_='rating_num').string 43 item_author = item.find('p').text 44 if (item.find(class_='inq') != None): 45 item_intr = item.find(class_='inq').string 46 47 # print('Climbing Movies:' + item_index + ' | ' + item_name +' | ' + item_img +' | ' + item_score +' | ' + item_author +' | ' + item_intr ) 48 print('Climbing Movies:' + item_index + ' | ' + item_name + ' | ' + item_score + ' | ' + item_intr) 49 50 global n 51 52 sheet.write(n, 0, item_name) 53 sheet.write(n, 1, item_img) 54 sheet.write(n, 2, item_index) 55 sheet.write(n, 3, item_score) 56 sheet.write(n, 4, item_author) 57 sheet.write(n, 5, item_intr) 58 59 n = n + 1 60 61 62 def main(page): 63 url = 'https://movie.douban.com/top250?start=' + str(page * 25) + '&filter=' 64 html = request_douban(url) 65 soup = BeautifulSoup(html, 'lxml') 66 save_to_excel(soup) 67 68 69 if __name__ == '__main__': 70 71 for i in range(0, 10): 72 main(i) 73 74 book.save(u'Douban's 250 Most Popular Movies.xlsx')
Code run screenshot
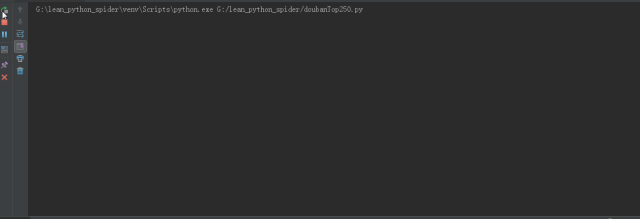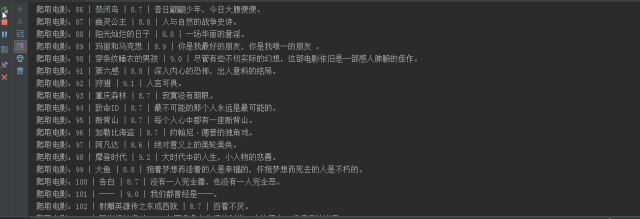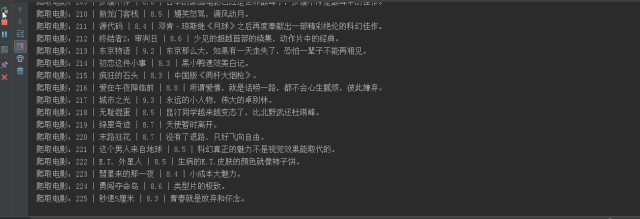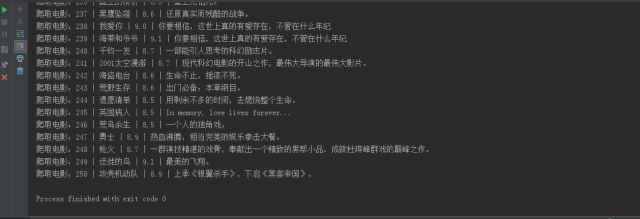
An excel file was generated
