Recently, I bought "Python Programming from Introduction to Practice", and I want to write two articles later, one is data visualization, the other is python web. Today, this article is the introduction of python.
I. Preliminary preparation:
IDE preparation: pycharm
Imported python libraries: requests for requests, Beautiful Soup for page parsing
II. Implementation steps
1. introduction of url
2. Parsing the returned data
3. screening
4. Traversing to extract data
3. Code Implementation
import requests # Import Web Page Request Library from bs4 import BeautifulSoup # Import Web Parsing Library # Incoming URL r = requests.get("https://movie.douban.com/top250") # Parse the returned data soup=BeautifulSoup(r.content,"html.parser") #Find the div in which the class attribute is item movie_list=soup.find_all("div",class_="item") #Traversing to extract data for movie in movie_list: title=movie.find("span",class_="title").text rating_num=movie.find("span",class_="rating_num").text inq=movie.find("span",class_="inq").text star = movie.find('div', class_='star') comment_num = star.find_all('span')[-1].text print(title, rating_num, '\n', comment_num, inq, '\n')
Taking Title Variable as an example, we find the div whose class attribute is item in Div. Then in this div, we filter out the span whose class name is title, get the text content, and print (comment_num is special, because it has no class attribute under star div, it is the last span in div, so we take out the last span in star level and turn it into text). Here is the output knot. Fruit.
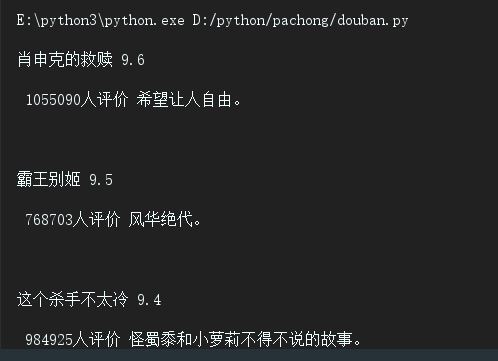
IV. Integration of the acquired data
1. Integrate into a list
2. Integrating into json files
3. Defined as a functional form
1. Integrate into a list
import requests # Import Web Page Request Library from bs4 import BeautifulSoup # Import Web Parsing Library import pprint # Plug-in libraries that specify display lists # Incoming URL r = requests.get("https://movie.douban.com/top250") # Parse the returned data soup=BeautifulSoup(r.content,"html.parser") #Find the div in which the class attribute is item movie_list=soup.find_all("div",class_="item") #Create an empty list of stored results result_list=[] #Traversing to extract data for movie in movie_list: #Create dictionary dict={} dict["title"]=movie.find("span",class_="title").text dict["dictrating_num"]=movie.find("span",class_="rating_num").text dict["inq"]=movie.find("span",class_="inq").text star = movie.find('div', class_='star') dict["comment_num"] = star.find_all('span')[-1].text result_list.append(dict) # Display result pp = pprint.PrettyPrinter(indent=4) pp.pprint(result_list)
The results displayed on the console are as follows:
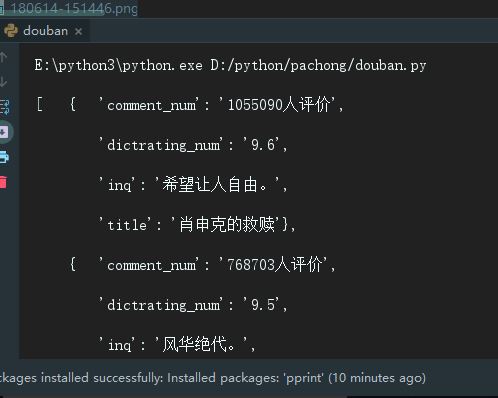
2. Integration into JSON files
import requests # Import Web Page Request Library import json# Used to convert list dictionary (json format) into the same form of string for file storage from bs4 import BeautifulSoup # Import Web Parsing Library # Incoming URL r = requests.get("https://movie.douban.com/top250") # Parse the returned data soup=BeautifulSoup(r.content,"html.parser") #Find the div in which the class attribute is item movie_list=soup.find_all("div",class_="item") #Create an empty list of stored results result_list=[] #Traversing to extract data for movie in movie_list: #Create dictionary dict={} dict["title"]=movie.find("span",class_="title").text dict["dictrating_num"]=movie.find("span",class_="rating_num").text dict["inq"]=movie.find("span",class_="inq").text star = movie.find('div', class_='star') dict["comment_num"] = star.find_all('span')[-1].text result_list.append(dict) # Display result # Convert the result_list json-formatted python object into a string s = json.dumps(result_list, indent = 4, ensure_ascii=False) # Write a string to a file with open('movies.json', 'w', encoding = 'utf-8') as f: f.write(s)
Result:
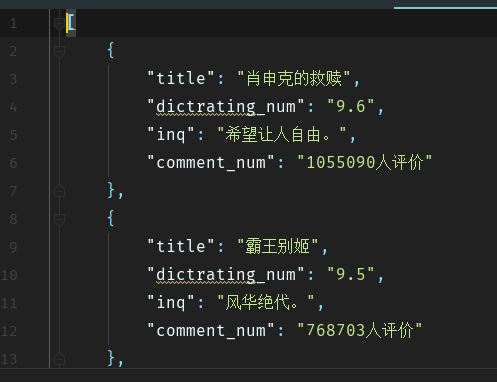
3. Definition as a function
import requests # Import Web Page Request Library import json# Used to convert list dictionary (json format) into the same form of string for file storage from bs4 import BeautifulSoup # Import Web Parsing Library # Used to send requests, get the source code of the web page for parsing def start_requests(url): r = requests.get(url) return r.content # Parse the returned data def parse(text): soup=BeautifulSoup(text,"html.parser") movie_list=soup.find_all("div",class_="item") result_list=[] for movie in movie_list: #Create dictionary dict={} dict["title"]=movie.find("span",class_="title").text dict["dictrating_num"]=movie.find("span",class_="rating_num").text dict["inq"]=movie.find("span",class_="inq").text star = movie.find('div', class_='star') dict["comment_num"] = star.find_all('span')[-1].text result_list.append(dict) return result_list #Write data to json file def write_json(result): s = json.dumps(result, indent = 4, ensure_ascii=False) with open('movies1.json', 'w', encoding = 'utf-8') as f: f.write(s) # Main run function, call other functions def main(): url = 'https://movie.douban.com/top250' text = start_requests(url) result = parse(text) write_json(result) if __name__ == '__main__': main()
Result:
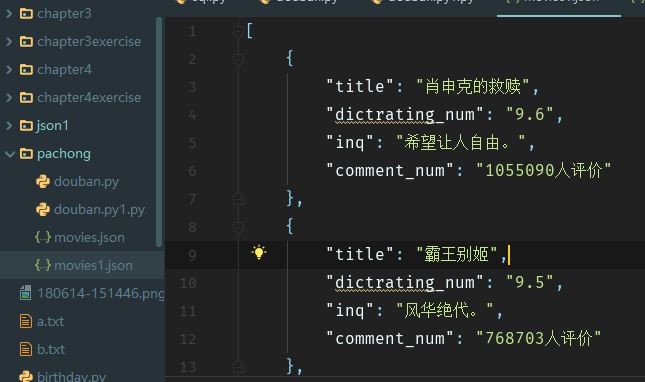
If it's useful, just give it a little bit 65