Goal: Climbing Articles Reading Network (Youth | Campus) to Read Novels
Attached website: http://xs.duwenzhang.com/list1/
The compiler used: pycharm
python3.0
Attach the code:
import os
import re
import urllib.request
from bs4 import BeautifulSoup
# Objective: To save all the youth campus novels on the novel website to local disk. (Store chapters of each chapter in the title of the novel as a catalogue)
def get_url_list(url):
rq = urllib.request.urlopen(url)
total_url = set() #
if rq.getcode() == 200:
total_url.add(url)
soup = BeautifulSoup(rq, 'html.parser', from_encoding='gbk')
url_list = soup.find_all('a', href=re.compile(r'/list1/[0-9]+.html'))
for url in url_list:
total_url.add(url['href'])
return total_url
else:
return 'Crawl failure'
def get_article_urlList(url_list):
for article_url in url_list:
rq = urllib.request.urlopen(article_url)
if rq.getcode() == 200:
soup = BeautifulSoup(rq, 'html.parser', from_encoding='gbk')
page_url = soup.find_all('a', href=re.compile(r'/1/[0-9]+/'))
page_url_list = set()
for url in page_url:
page_url_list.add('http://xs.duwenzhang.com' + url['href'])
return page_url_list
else:
return 'Crawl failure'
def get_page_chapter_url(url_list):
chaper_url = set()
for url in url_list:
rq = urllib.request.urlopen(url)
if rq.getcode() == 200:
soup = BeautifulSoup(rq, 'html.parser', from_encoding='gbk')
chaper_list = soup.find_all('a', href=re.compile(r'/[0-9]+.html'))
for chaper in chaper_list:
chaper_url.add(chaper['href'])
else:
print('Crawl failure')
return chaper_url
def get_chaper_page(url_list):
for url in url_list:
rq = urllib.request.urlopen(url)
soup = BeautifulSoup(rq, 'html.parser', from_encoding='gbk')
title = soup.find('a', href=re.compile('/1/[0-9]+/'))
chaper_titile = soup.find(name='dt') #
chaper_content = soup.find(name='dd') #
if not title:
print('page not present:%s' % url)
continue
else:
title = str(title.get_text())
chaper_titile = str(chaper_titile.get_text())
chaper_content = str(chaper_content.get_text())
dir_path = ('F:/Crawler file/Youth Campus Novels/' + str(title)).strip()
if not os.path.exists(dir_path):
os.mkdir(dir_path)
strinfo = re.compile(r'(\t| |)')
chaper_title = strinfo.sub('', chaper_titile)
file_path = dir_path + '/' + chaper_title + '.txt'
f = open(file_path, 'w+', encoding='utf-8')
f.write(str(chaper_content))
f.close()
return 'Climb to success'
if __name__ == '__main__':
root_url = 'http://xs.duwenzhang.com/list1/' root url, the front page of campus fiction
Url_List = get_url_list(root_url) # Entry function to get home url and other page URLs
Page_List = get_article_urlList(Url_List) # Get all the entry URLs for fiction on these pages
Chaper_url = get_page_chapter_url(Page_List) # Get the population url for all chapters
print(get_chaper_page(Chaper_url)) # Implementing the required functions
Attached are the pictures of the implementation of the function:
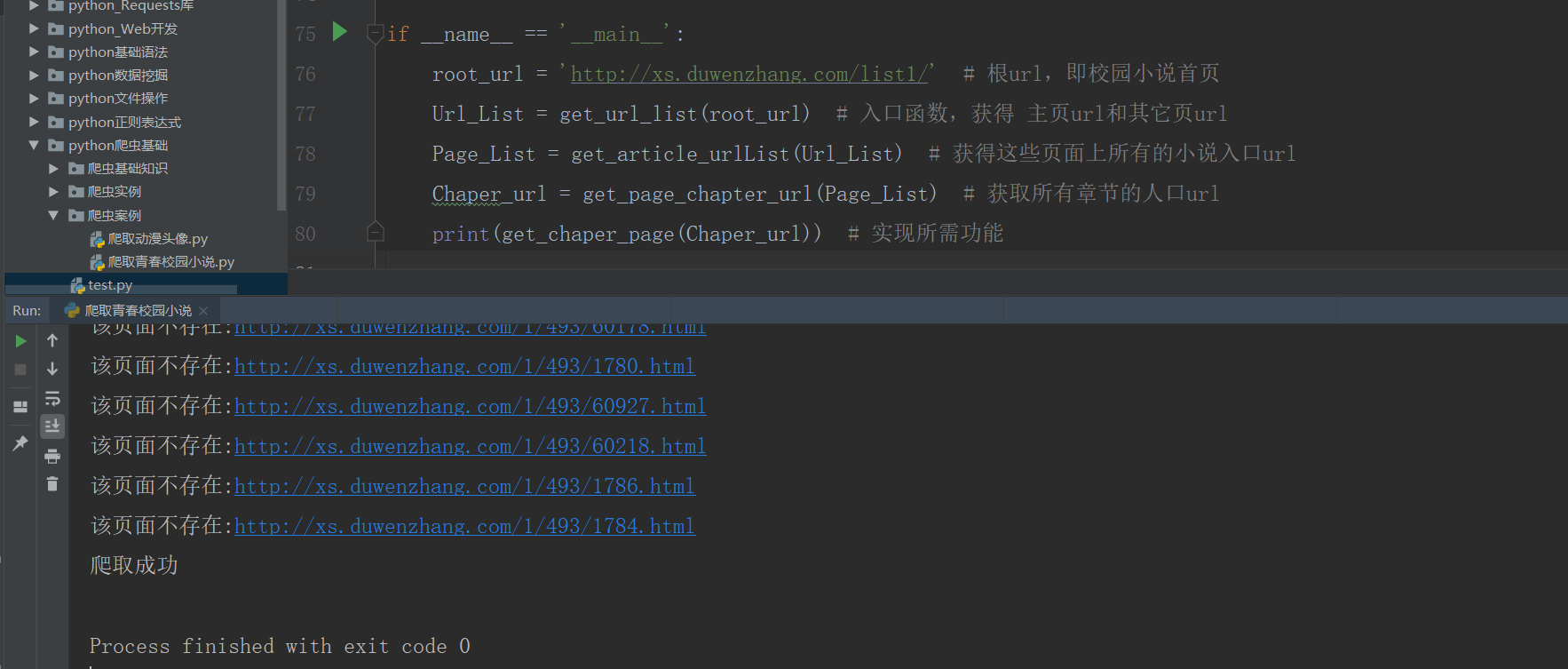
When crawling, some of the stories are empty (...... Maybe the content is blocked.)
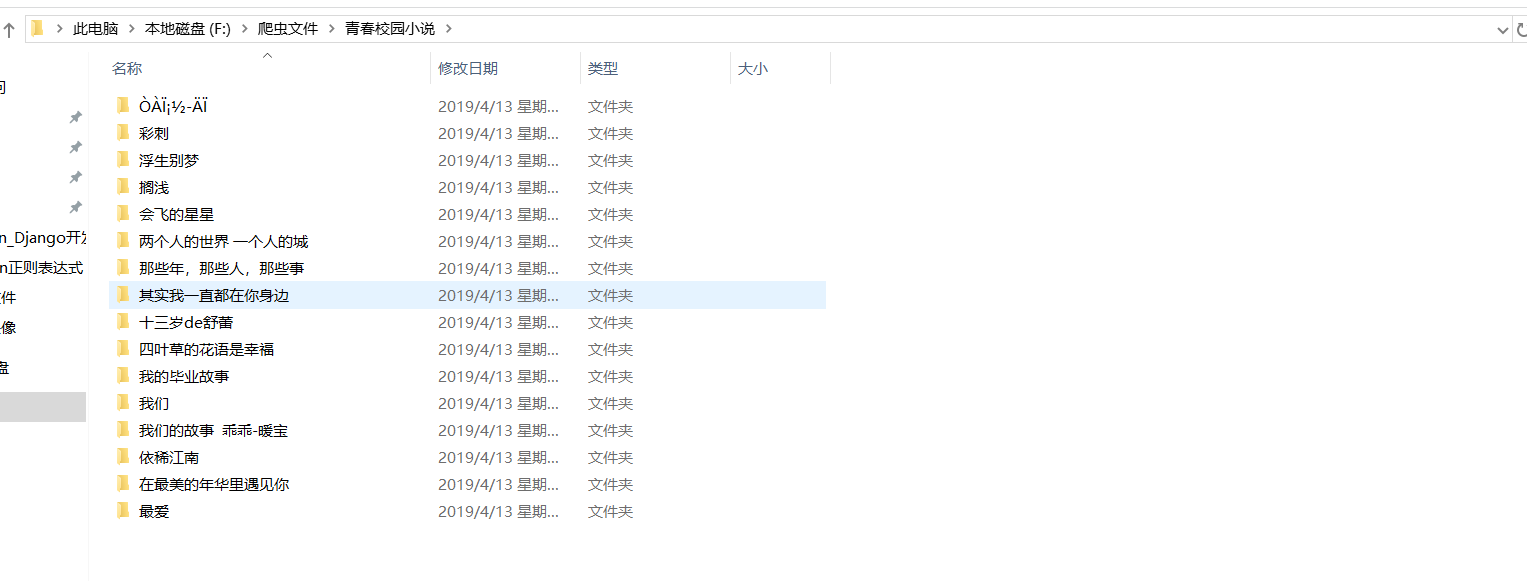
The first folder was scrambled... I don't know why... to be resolved...
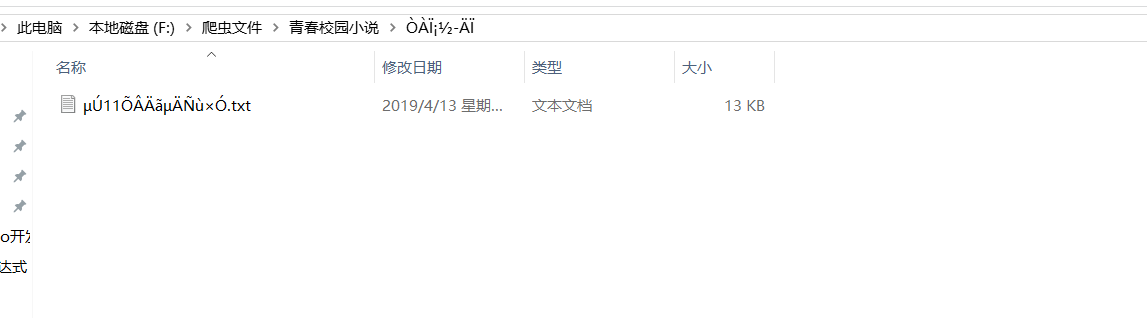 The files in the scrambled directory are also scrambled.
The files in the scrambled directory are also scrambled.
I guess it's because the coding of this novel is inconsistent with that of other novels....
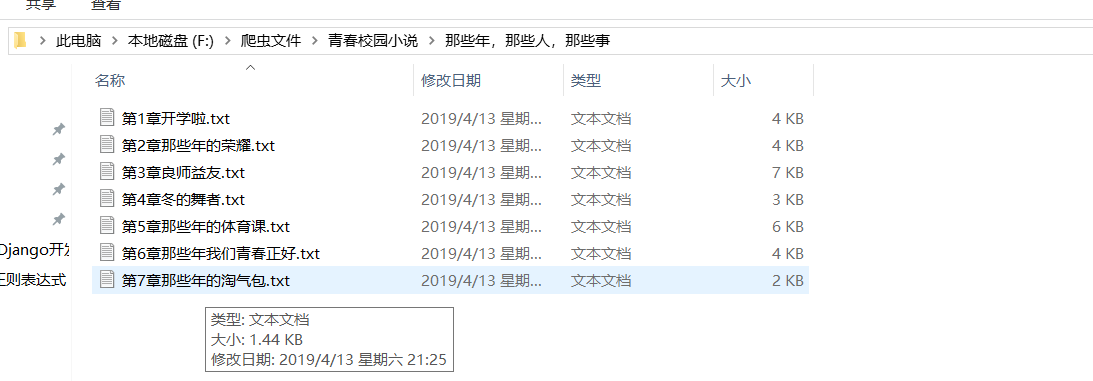
All other documents and texts are in order.
Cough and cough. The level still needs to be improved.