Python practice notes - 2. Crawl public information from the website
Zhang Banshu's Python practice notes, including notes and DeBug's experience.
In order to complete a troublesome internship task, I tried to do such a reptile project.
One of the task requirements is to search the government affairs disclosure of Anhui emergency management department and record all the enterprise names that have issued hazardous chemical safety licenses. However, after searching, you can see that the information of Anhui Province is published weekly. If you want to get all the enterprise names, you need to open 50 + web pages, which is more troublesome. Therefore, you want to design a crawler to solve it.
http://yjt.ah.gov.cn/public/column/9377745?type=4&action=list&nav=3&catId=49550951
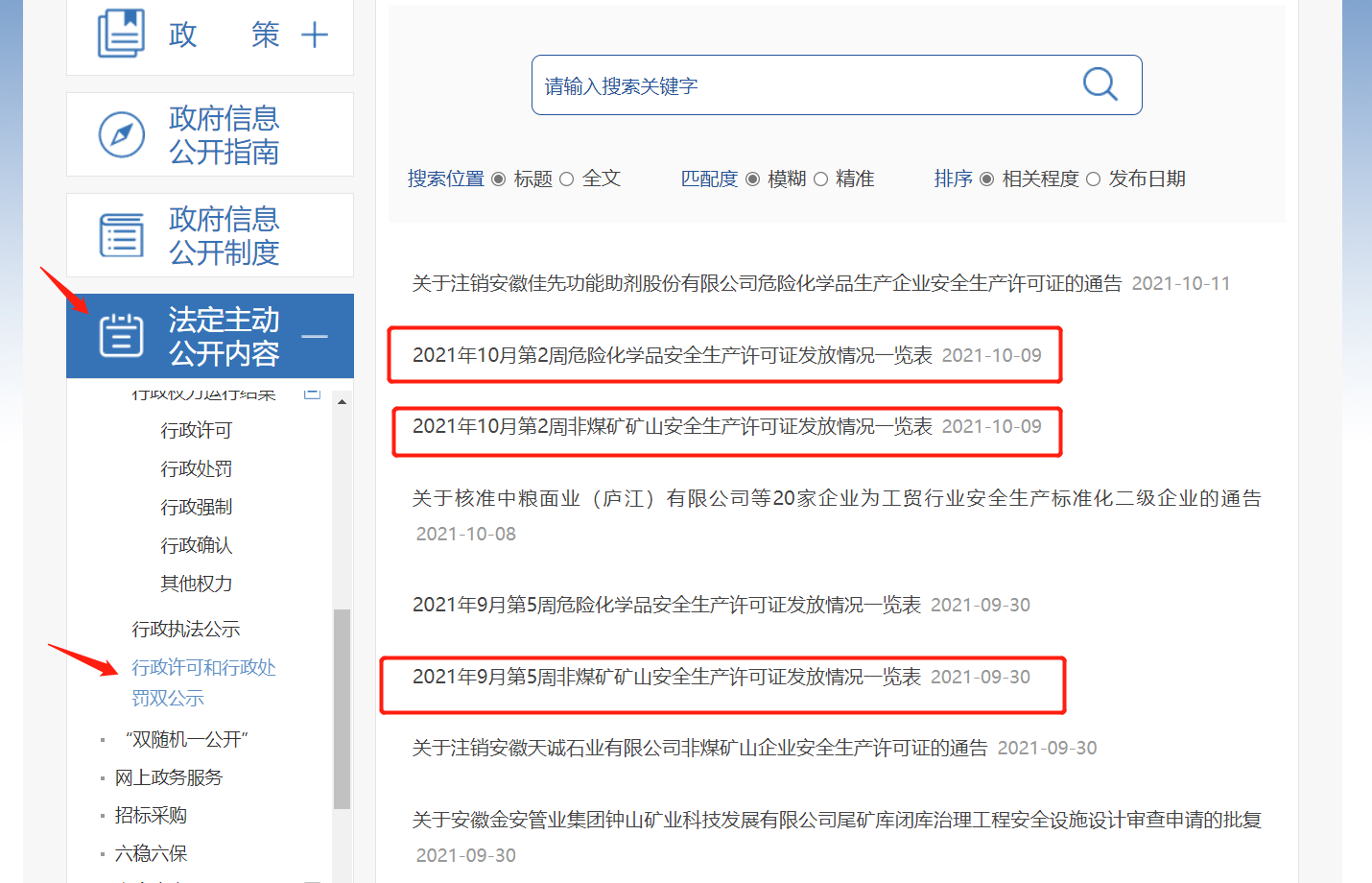
1, Information acquisition of a single web page
When we open several of these pages, we can see that the format is very regular, and the information is displayed in the form of a table:
http://yjt.ah.gov.cn/public/9377745/146123891.html
http://yjt.ah.gov.cn/public/9377745/146123631.html
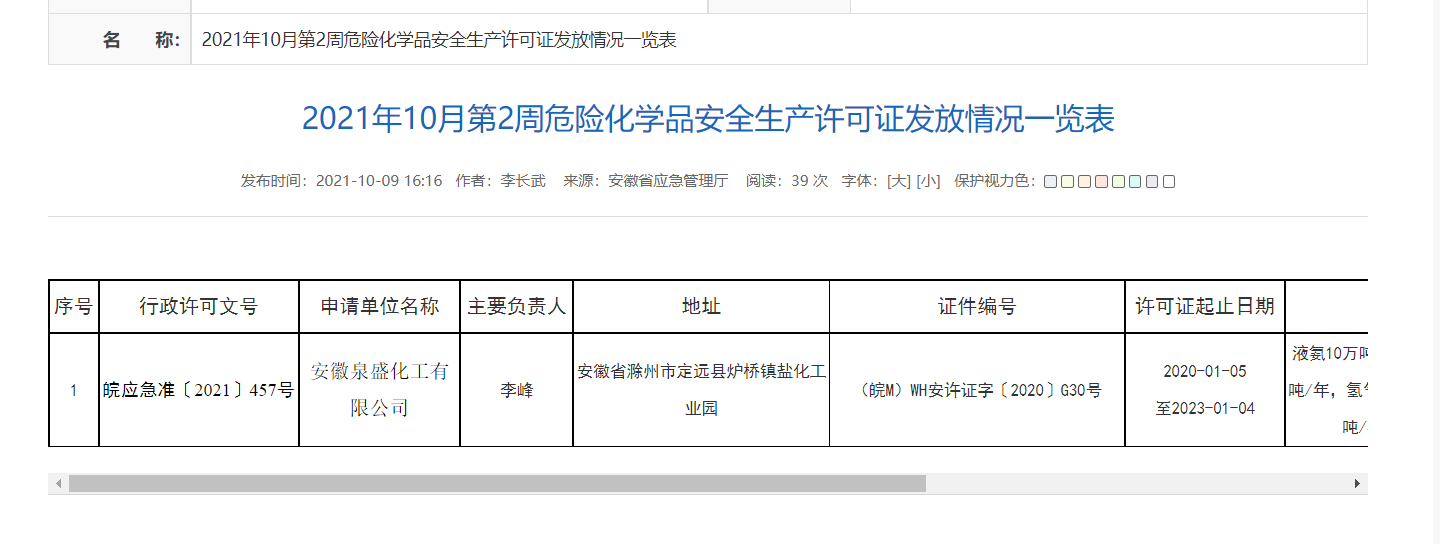
Get xpath to locate information
Developer tools using Google browser or Edge browser (F12 or Fn + F12)
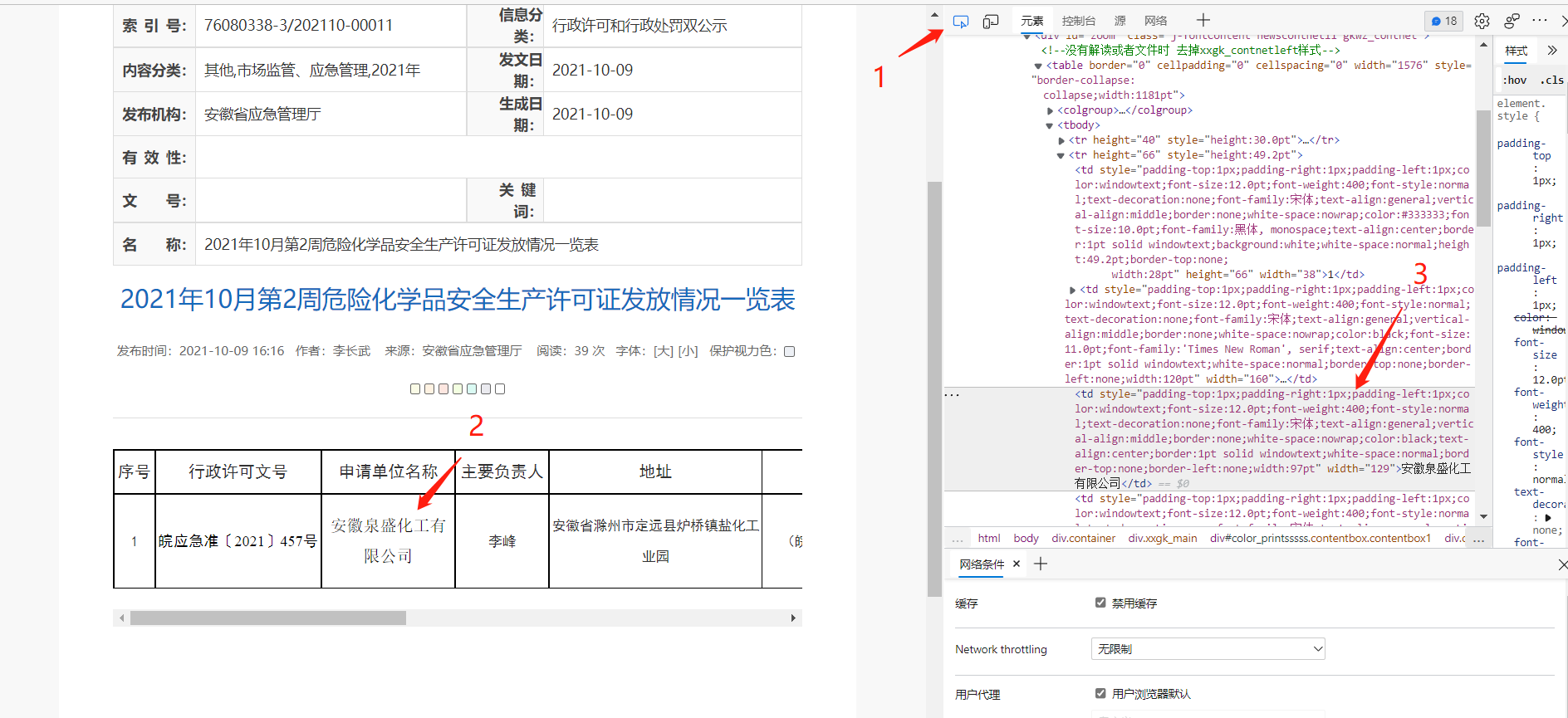
- 1. Select the element retrieval tool;
- 2. Place the cursor on the desired element;
- 3. The required elements are displayed on the right;
Find another file with more than one row of tables, and use the element retrieval tool to see the Xpath of each row in the table:
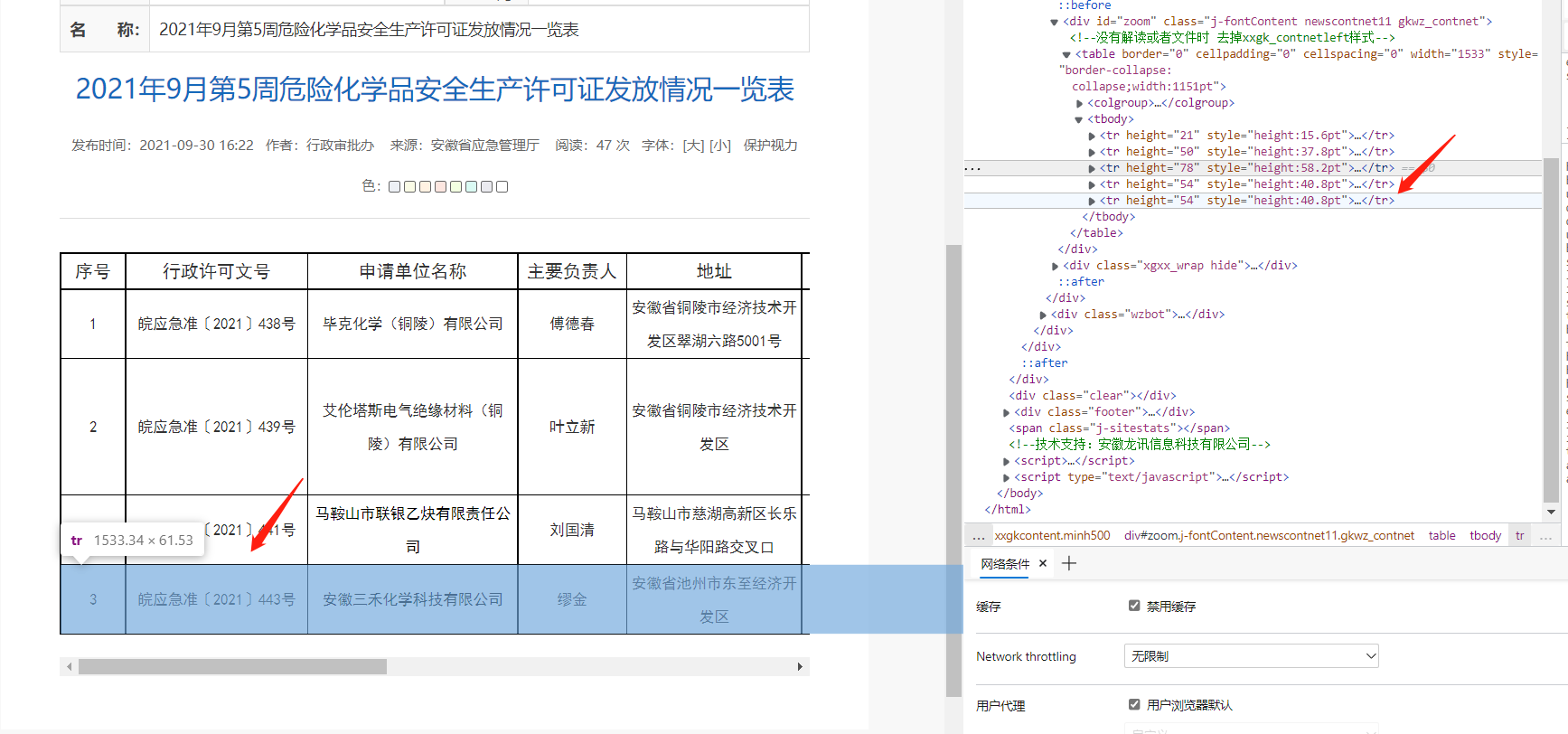
In this way, you can use a loop to traverse the information of each line in the program
- Right click - copy - copy xpath
Here, we copy the xpath at the upper level of the table, that is, the tbody item. The xpath is:
//*[@id="zoom"]/table/tbody
Create a function in python to crawl all company names in this interface:
import requests
import json
from lxml import etree
def paqu_AH(url): # Crawl the company name in the table according to the url
headers = {'referer':'http://yjt.hubei.gov.cn/fbjd/xxgkml/xkfw/xzxkgs/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}
html = requests.get(url, headers=headers).content
xml = etree.HTML(html)
factorys = []
xpath = '//*[@id="zoom"]/table/tbody'
content = xml.xpath(xpath) # Parsing the obtained web page information with xpath
for tbody in content[0][1:]: # The specific information can be printed out or checked with the element detection during vscode debug;
# At the same time, [1:] indicates that except the first row (because the first row is the header of the table)
factorys.append(tbody[2].text) # [2] Indicates the second column, mainly depending on the web page structure
return factorys
AH_0 = "http://yjt.ah.gov.cn/public/9377745/146080571.html"
print(paqu_AH(AH_0))
>>>['Anhui Xingxin New Material Co., Ltd', 'Tongling Huaxing Fine Chemical Co., Ltd', 'Huaibei Oasis New Material Co., Ltd', 'MAANSHAN Shenjian New Material Co., Ltd', 'Anhui Yutai Chemical Co., Ltd']
2, Get all URLs
1. Get information through post request
As mentioned above, it is very simple to simply crawl the web page of a form, but we need to crawl all the information, so we need to crawl the URLs of all such web pages
We observed this web page and found that the keywords on the web page of hazardous chemicals license have the same format:
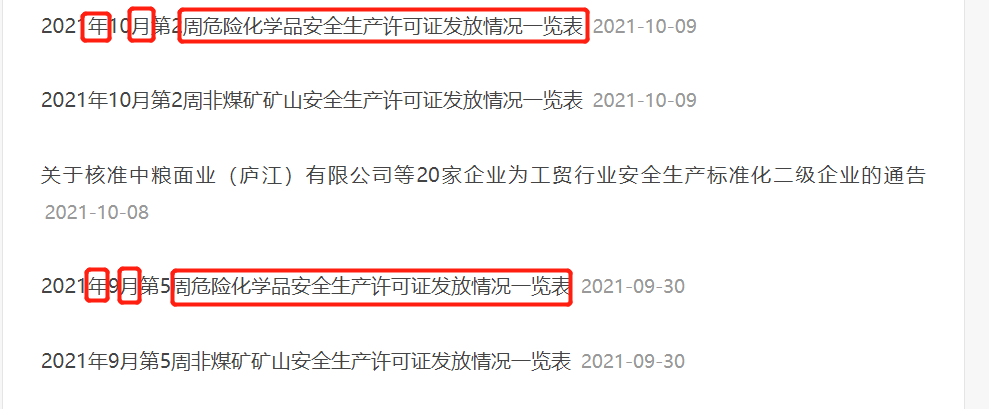
Therefore, we search these keywords in the search on this page:
List of issuance of safety production license for hazardous chemicals in the week of
We can see that it is in line with our guess:
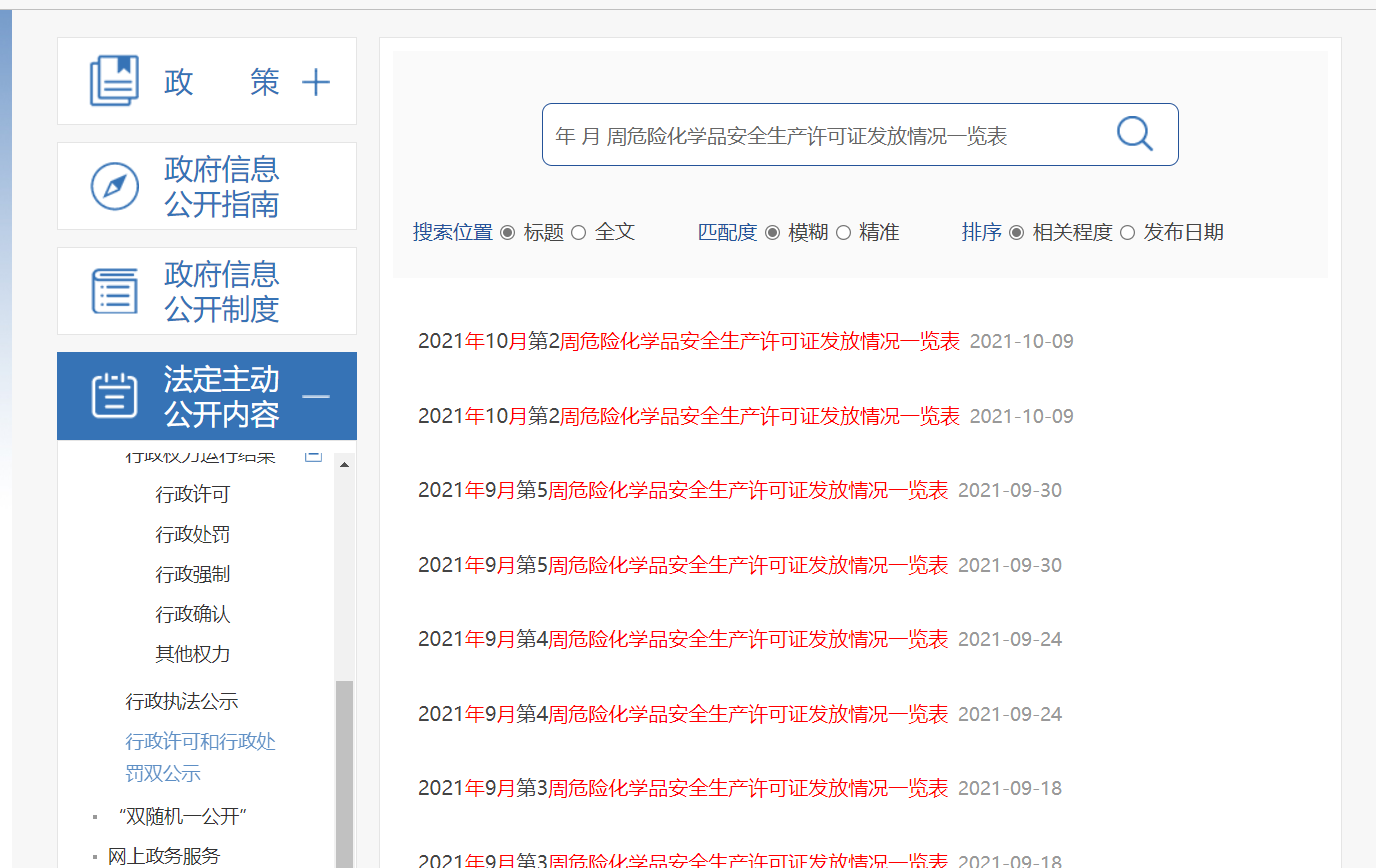
Also use the developer tool to get xpath, so you can use the program to crawl the content of the current page
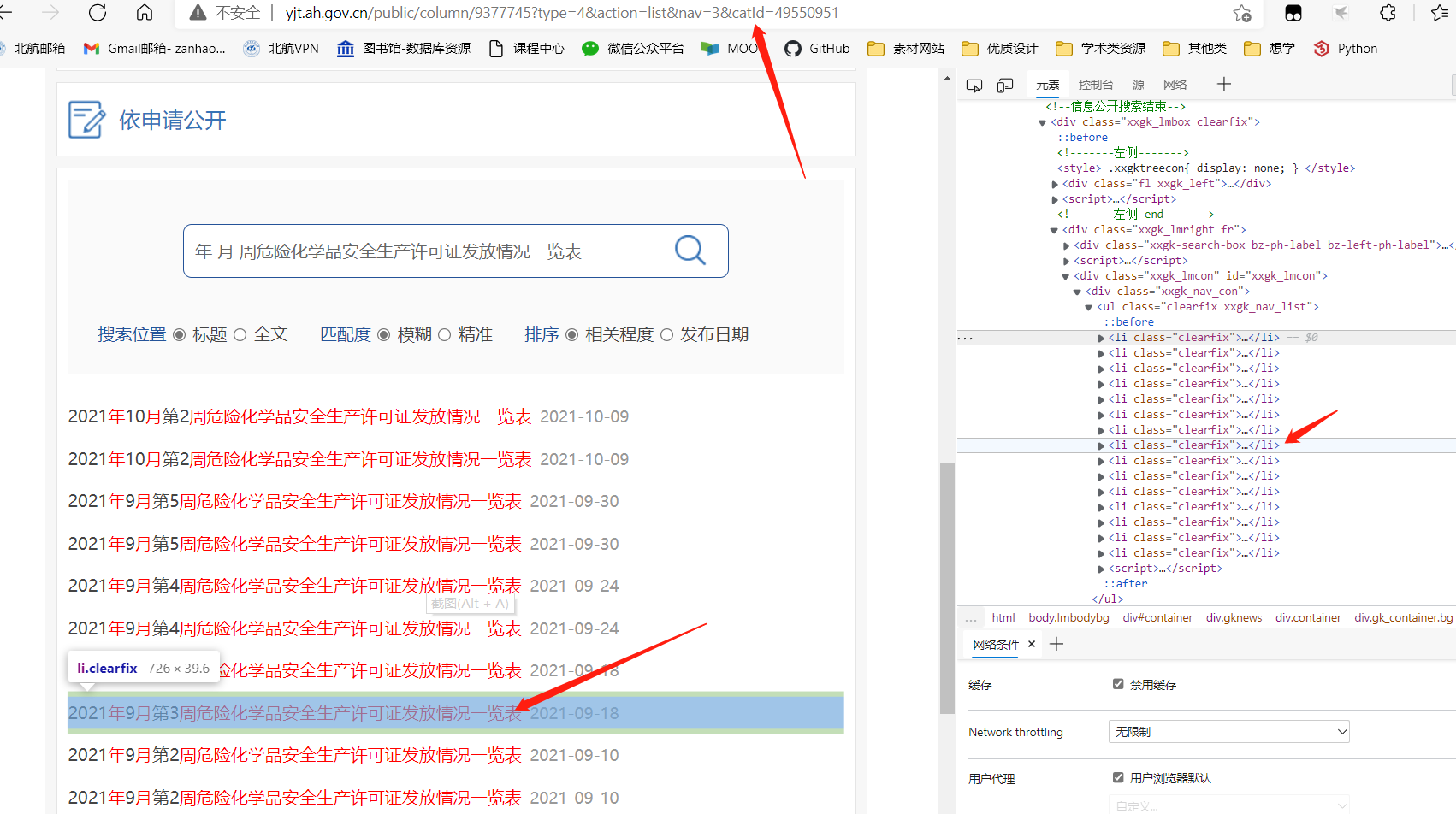
This time, because the crawling is not performed directly in this interface, the request is not get, but post request:
import requests
import json
from lxml import etree
def paqu_URL(url,data): # Sub function, crawling the application layer of url
URLS = []
num = 0
headers = {'referer':'http://yjt.hubei.gov.cn/fbjd/xxgkml/xkfw/xzxkgs/','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}
html = requests.post(url, headers=headers, data=data).content
xml = etree.HTML(html)
xpath = '//*[@id="xxgk_lmcon"]/div[1]/ul'
txt = xml.xpath(xpath)
for ul in txt:
for li in ul[:-1]:
content = li[0]
dic = content.attrib
URLS.append(dic['href'])
num += 1
print("-- {} -- ".format(num),dic['href'])
AH = "http://yjt.ah.gov.cn/public/column/9377745?type=4&action=list&nav=3&catId=49550951"
data = "List of issuance of safety production license for hazardous chemicals in the week of".encode("utf-8") # The coding method should be added here, otherwise an error will be reported
paqu_URL(AH,data)
>>>-- 1 -- http://yjt.ah.gov.cn/public/9377745/146126481.html
>>>-- 2 -- http://yjt.ah.gov.cn/public/9377745/146123891.html
>>>-- 3 -- http://yjt.ah.gov.cn/public/9377745/146123631.html
>>>-- 4 -- http://yjt.ah.gov.cn/public/9377745/146120821.html
>>>-- 5 -- http://yjt.ah.gov.cn/public/9377745/146115731.html
>>>-- 6 -- http://yjt.ah.gov.cn/public/9377745/146115701.html
>>>-- 7 -- http://yjt.ah.gov.cn/public/9377745/146115601.html
>>>-- 8 -- http://yjt.ah.gov.cn/public/9377745/146115461.html
>>>-- 9 -- http://yjt.ah.gov.cn/public/9377745/146101311.html
>>>-- 10 -- http://yjt.ah.gov.cn/public/9377745/146101251.html
>>>-- 11 -- http://yjt.ah.gov.cn/public/9377745/146101261.html
>>>-- 12 -- http://yjt.ah.gov.cn/public/9377745/146094421.html
>>>-- 13 -- http://yjt.ah.gov.cn/public/9377745/146094401.html
>>>-- 14 -- http://yjt.ah.gov.cn/public/9377745/146080931.html
>>>-- 15 -- http://yjt.ah.gov.cn/public/9377745/146080571.html
However, because the search content is not displayed in one page, and the url of this page is observed, it is found that the keyword "list of issuance of hazardous chemical safety production license in month, month and week" is not retrieved in the url, and it is not reflected in the url after turning the page, so it is impossible to change directly on the url to turn the page.
2. Crawler with page turning url unchanged
Use developer tools to monitor web page actions:
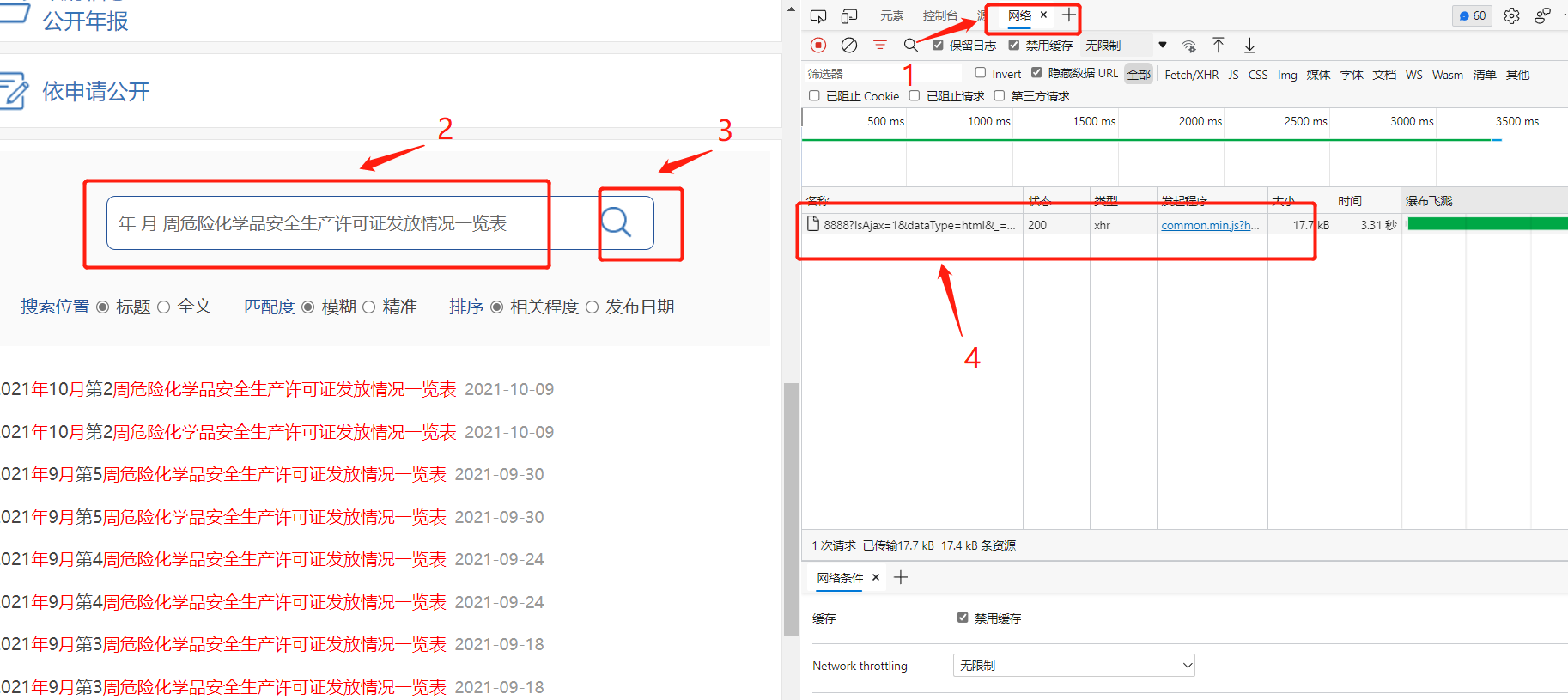
- 1. Open the network in the developer tool;
- 2. Enter the search content in the search box;
- 3. Click search;
- 4. It is found that the web page has sent information and relevant responses;
Click this response to see that the preview of its response content is indeed the search result:
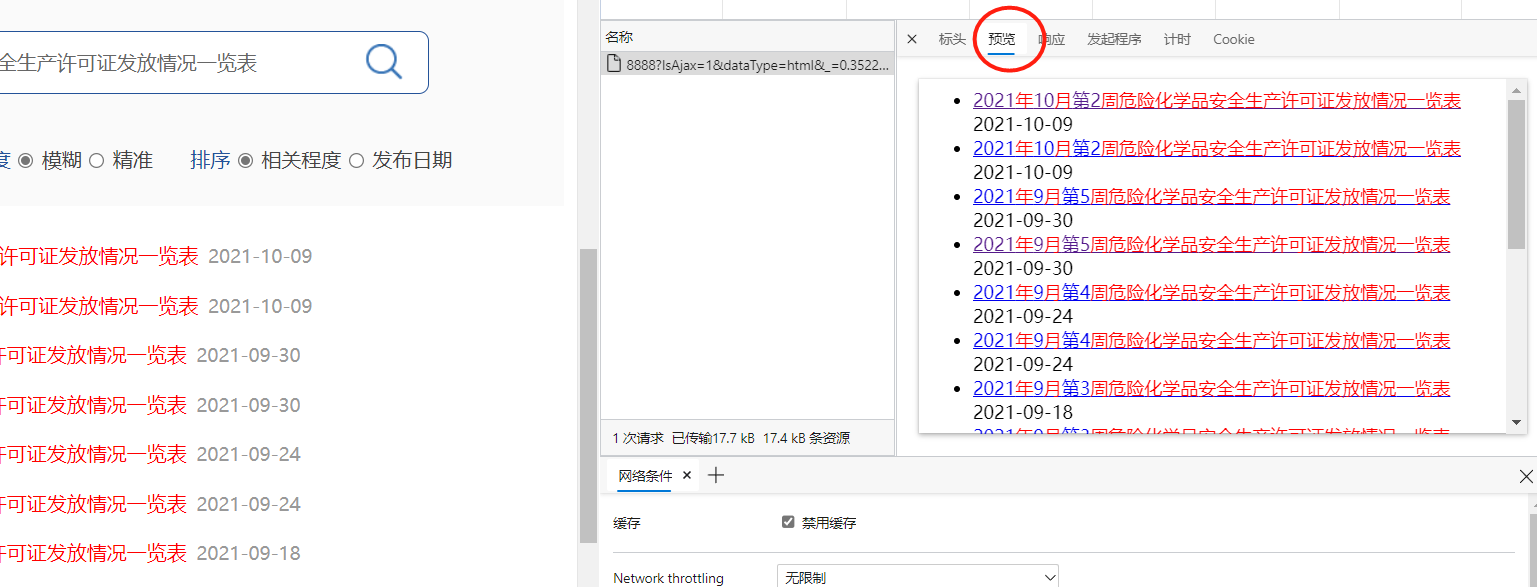
Click into the header, observe the sent information, and guess the meaning of the parameter according to the header name:
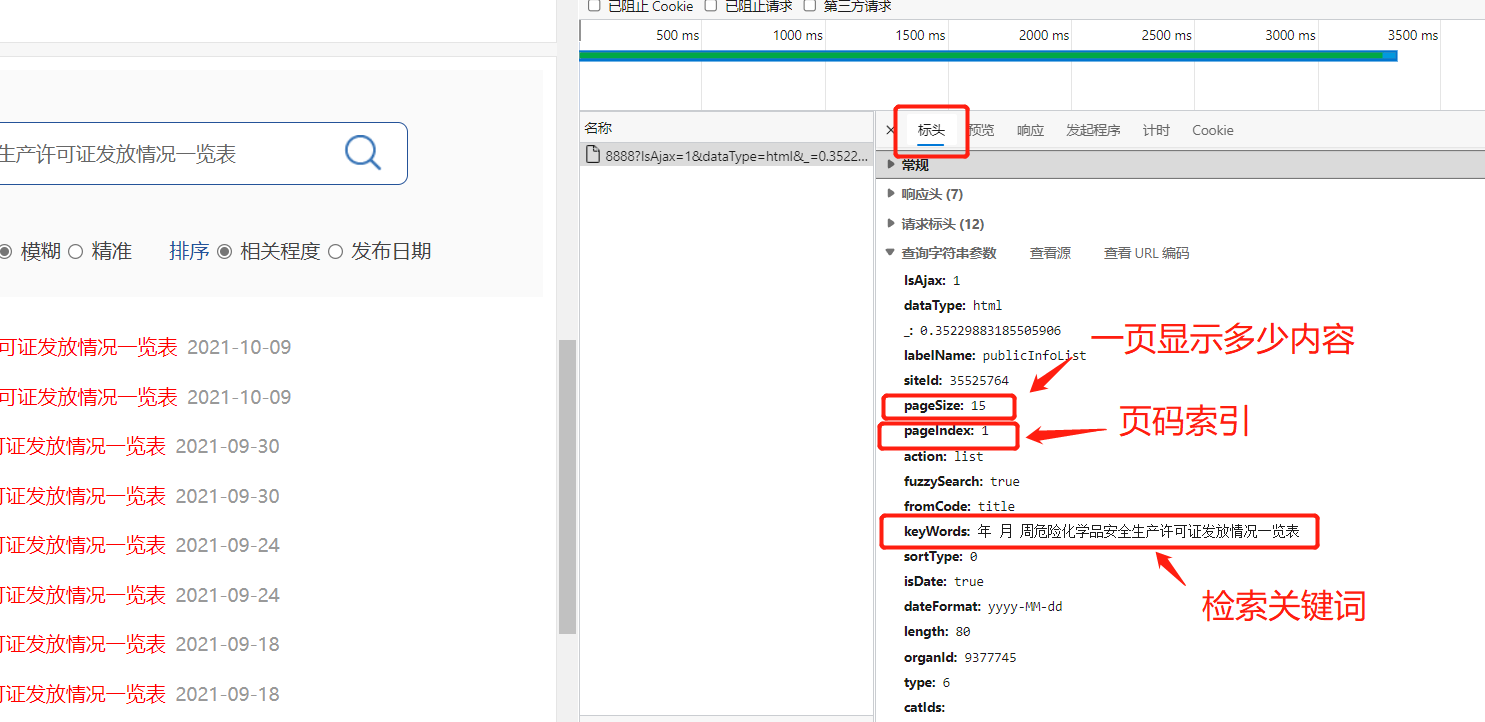
Analysis is available, but try the post request, and send the requested information to the header file here, and change the corresponding parameters to realize page turning or other functions:
import requests
import json
from lxml import etree
def get_all_url(num): # Crawl all formula URLs
i = 1
url_list = []
for i in range(num):
print("#####The first {} group###########################".format(i))
request_dic = {
'IsAjax': 1,
'dataType': 'html',
'_': '0.9035590852646269',
'labelName': 'publicInfoList',
'siteId': 35525764,
'pageSize': 15,
'pageIndex': i, # Every time you change the page index
'action': 'list',
'fuzzySearch': 'true',
'fromCode': 'title',
'keyWords': 'List of issuance of work safety license for hazardous chemicals in the week of',
'sortType': 0,
'isDate': 'true',
'dateFormat': 'yyyy-MM-dd',
'length': 80,
'organId': 9377745,
'type': 6,
'catIds': '',
'cId': '',
'result': 'No relevant information',
'file': '/xxgk/publicInfoList_newest2020',}
i += 1
urls,num = paqu_URL(AH,request_dic)
url_list += urls
# try:
# urls,num = paqu_URL(AH,request_dic)
# url_list += urls
# except:
# print("-#-#-#- Climb to the third {} An error occurred on the page -#-#-#-".format(i))
print("Crawling completed, total {} individual URL".format(len(url_list)))
return url_list
def paqu_URL(url,data): # The sending and reading mode of data is changed here
URLS = []
num = 0
headers = {'referer':'http://yjt.hubei.gov.cn/fbjd/xxgkml/xkfw/xzxkgs/','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}
# html = requests.get(url, headers=headers).content
html = requests.post(url, headers=headers, data = json.dumps(data)).content
xml = etree.HTML(html)
xpath = '//*[@id="xxgk_lmcon"]/div[1]/ul'
txt = xml.xpath(xpath)
for ul in txt:
for li in ul[:-1]:
content = li[0]
dic = content.attrib
URLS.append(dic['href'])
num += 1
# print("-- {} -- ".format(num),dic['href'])
return URLS, num
get_all_url(5) # Climb 50 pages
>>>#####Group 0###########################
>>>#####Group 1###########################
>>>#####Group 2###########################
>>>#####Group 3###########################
>>>#####Group 4###########################
Climbing completed, 75 in total URL
Finally, by combining these functions, you can completely crawl the names of these companies
def get_factorys(num):
factorys = []
urls = get_all_url(num)
for url in urls:
try:
for factory in paqu_AH(url):
if factory not in factorys:
factorys.append(factory)
except:
factorys = factorys
print(factorys)
print("-#-#- After crawling, a total of {} company -#-#-".format(len(factorys)))
return factorys
>>>Climbing completed, 75 in total URL
>>>['Anhui Quansheng Chemical Co., Ltd', 'Jinzhai China Resources Ecological Agriculture Development Co., Ltd', 'Anhui Tiancheng Stone Industry Co., Ltd', 'Anhui Magang Mining Resources Group Co., Ltd. Gushan Mining Co., Ltd. Heshan Iron Mine', 'Bike chemical (Tongling) Co., Ltd', 'Allantas electrical insulation material (Tongling) Co., Ltd', 'MAANSHAN Lianyin acetylene Co., Ltd', 'Anhui Sanhe Chemical Technology Co., Ltd', 'Zhangjiaxialou iron mine, Huoqiu County, Anhui Province', 'Shejiaao copper gold mine of Anhui Zongyang Hengyuan Mining Co., Ltd', 'Anhui Magang mining resources group Nanshan Mining Co., Ltd. and Shangqiao Iron Mine', 'Gaocun Iron Mine of Anhui Magang mining resources group Nanshan Mining Co., Ltd', 'Chengmentong tailings pond of Anhui Magang mining resources group Nanshan Mining Co., Ltd', 'Aoshan general tailings pond of Anhui Magang mining resources group Nanshan Mining Co., Ltd', 'Anhui Shucheng Xinjie Fluorite Mining Co., Ltd', 'Jinfeng mining (Anhui) Co., Ltd', 'Calcite mine in dameling mining area of Guangde Jingyu Mining Co., Ltd', 'Anhui jinrisheng Mining Co., Ltd', 'Jingxian yinshanling Mining Co., Ltd', 'Tongling Hushan magnetite Co., Ltd', 'Fanchang Qianshan Mining Co., Ltd', 'Chizhou TAIDING Mining Development Co., Ltd. jigtoushan marble mine, Tangxi Township, Guichi District', 'Tailings pond of Chizhou taopo Xinlong Mining Development Co., Ltd', 'Anhui Jiuhua Jinfeng Mining Co., Ltd. Chizhou LAILONGSHAN dolomite mine', 'Lingshan, Fengyang County-Section 15 of quartzite ore for glass in mulishan mining area', 'Lingshan quartzite mine of Anhui Sanli Mining Co., Ltd', 'Caiping granite mine, tanfan village, Guanzhuang Town, Qianshan Tianzhu Hongshi Industry Co., Ltd', 'Anhui Zhonghuai mining new building materials Co., Ltd', 'No. 1 limestone mine of Tongling maodi Mining Co., Ltd', 'Anhui Shuntai Tiancheng Blasting Engineering Co., Ltd', 'MAANSHAN Magang Linde Gas Co., Ltd', 'Guangde meitushi Chemical Co., Ltd', 'Guangde Laiwei paint Co., Ltd', 'Tongling chemical group Organic Chemical Co., Ltd', 'Anhui jiatiansen Pesticide Chemical Co., Ltd', 'Anhui Jiuyi Agriculture Co., Ltd', 'Chizhou Liuhe Huafeng Stone Co., Ltd', 'Anhui Xingxin New Material Co., Ltd', 'Tongling Huaxing Fine Chemical Co., Ltd', 'Huaibei Oasis New Material Co., Ltd', 'MAANSHAN Shenjian New Material Co., Ltd', 'Anhui Yutai Chemical Co., Ltd']
>>>-#-#- After crawling, 42 companies were obtained -#-#-
Finally, I confess that when I crawled, the search part of the government affairs publicity of Anhui emergency management department "collapsed" for a period of time due to the large number of visits per unit time. If you want to try, you should use other websites as much as possible, especially large factories and new websites. Their bandwidth is relatively large, otherwise you will cause trouble
ah ~ _ ~