We learned the simple use of XPath before. Refer to: https://www.cnblogs.com/minseo/p/15502584.html
Today, let's practice using XPath to analyze the Douban film ranking. This time, we practice obtaining the new film ranking information of the film ranking. The content obtained in the exercise is the url, film name and director name of the new film
In order to view the whole process of XPath analyzing html, we download the source code of the web page and open it with a text editor Notepad + +. The text editor can clearly view the corresponding relationship of tags.
First, let's find the url of 10 new films
Viewing the source code, it is found that the Douban new film list is contained in a label < div >, which has a unique id = "content"

Use XPath to find this tag
# Climb the new movie gang of Douban movie ranking list and use the synchronization method
# Import module
import requests
from lxml import etree
# Set the access client header information. If it is not set, it may not be accessible using requests
headers = {'User-Agent': 'M'}
movice_url = 'https://movie.douban.com/chart'
resp = requests.get(movice_url,headers=headers)
# Get all the source code information of the response
movice_resp_text = resp.text
# Use etree.HTML to convert to lxml. etree.HTML that can be parsed using xpath_ Element object
movice_etree_element = etree.HTML(movice_resp_text)
movice_url = movice_etree_element.xpath('//*[@id="content"]')
print(movice_url)
XPath code parsing
xpath('//*[@id="content"]')
// #Selects nodes in the document from the current node that matches the selection, regardless of their location
* # Wildcard matches all
[@id="content"] # Match the tag attribute. This time, the id attribute is unique, so you can match a unique tag
Note: if the matching code has multiple quotation marks, the internal and external quotation marks cannot be the same, that is, if the external quotation marks are single quotation marks, the internal quotation marks need to be double quotation marks, and vice versa
An object is found this time, and the output is as follows
[<Element div at 0x134e93395c8>]
If you are not sure whether this tag is found, you can print the key attributes of the tag to view it
Print the id attribute, and you can see that it is indeed the corresponding label
movice_url = movice_etree_element.xpath('//*[@id="content"]/@id')
print(movice_url)
# ['content']
Next, narrow the scope and continue to find < div > tags under the tags found in the previous step
movice_url = movice_etree_element.xpath('//*[@id="content"]/div')
print(movice_url)
# [<Element div at 0x1f2b3248688>]
Find the only one, print the class attribute of the label, and see which label you find
movice_url = movice_etree_element.xpath('//*[@id="content"]/div/@class')
print(movice_url)
# ['grid-16-8 clearfix']
You can see that the corresponding tag in the source code is found
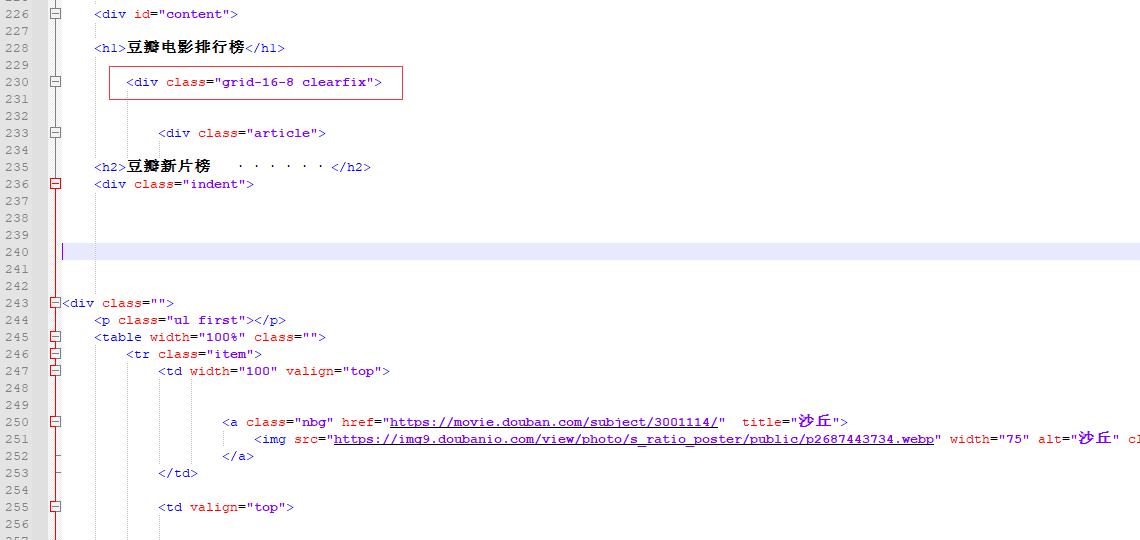
Obviously, the corresponding movie url has not been found
Now narrow down and continue to find
movice_url = movice_etree_element.xpath('//*[@id="content"]/div/div')
print(movice_url)
# [<Element div at 0x288c4f18508>, <Element div at 0x288c4f18548>, <Element div at 0x288c4f18488>]
Three < div > tags are found under the previous tag < div > found. Next, let's determine which of the three tags of the new film through attributes
movice_url = movice_etree_element.xpath('//*[@id="content"]/div/div')
print(movice_url[0].xpath('@class'),movice_url[1].xpath('@class'),movice_url[2].xpath('@class'))
# ['article'] ['aside'] ['extra']
The location of the three tags is determined by taking the elements of the list and using the xpath method to find the value of the attribute class
Key keyword find the location of these three tags in the source code
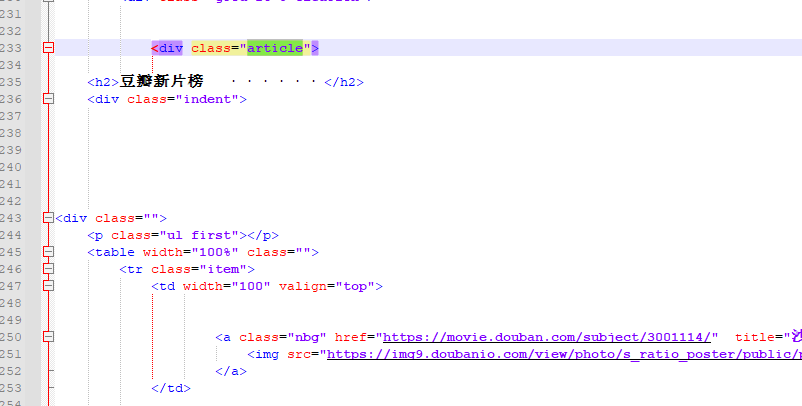
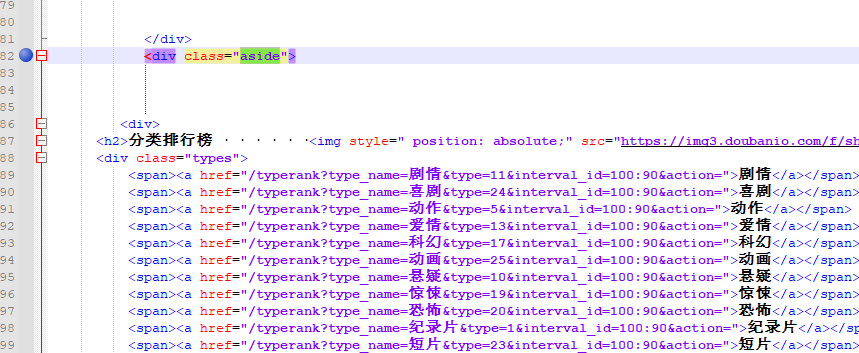

Obviously, the movie url we're looking for is in the first tag
Narrow down and continue to find the first label
movice_url = movice_etree_element.xpath('//*[@id="content"]/div/div[1]')
print(movice_url)
# print(movice_url)
[<Element div at 0x23daef97788>]
Note: the subscript of the first tag here is 1, not like other python objects, such as list. The first tag is 0
This time, another object is returned
Next, continue to find the next div label printing attribute class
movice_url = movice_etree_element.xpath('//*[@id="content"]/div/div[1]/div/@class')
print(movice_url)
# ['indent']
Find the only < div > tag in the source code as follows
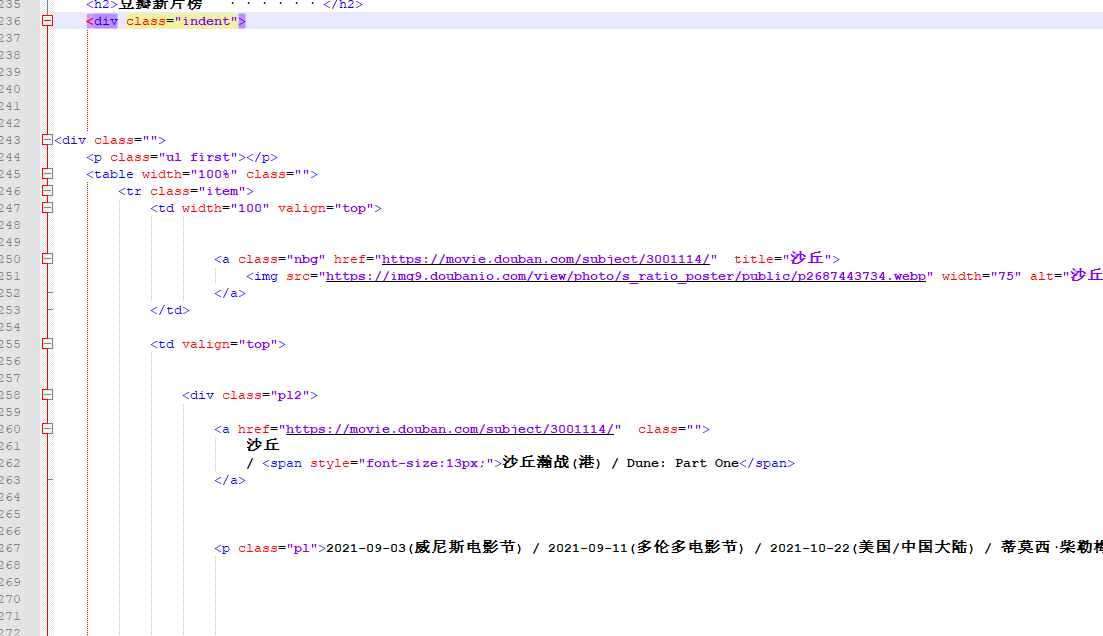
Narrow down and continue to find
movice_url = movice_etree_element.xpath('//*[@id="content"]/div/div[1]/div/div')
print(movice_url)
# [<Element div at 0x2d9b21186c8>]
There is only one, and the new film is still within the scope of this label
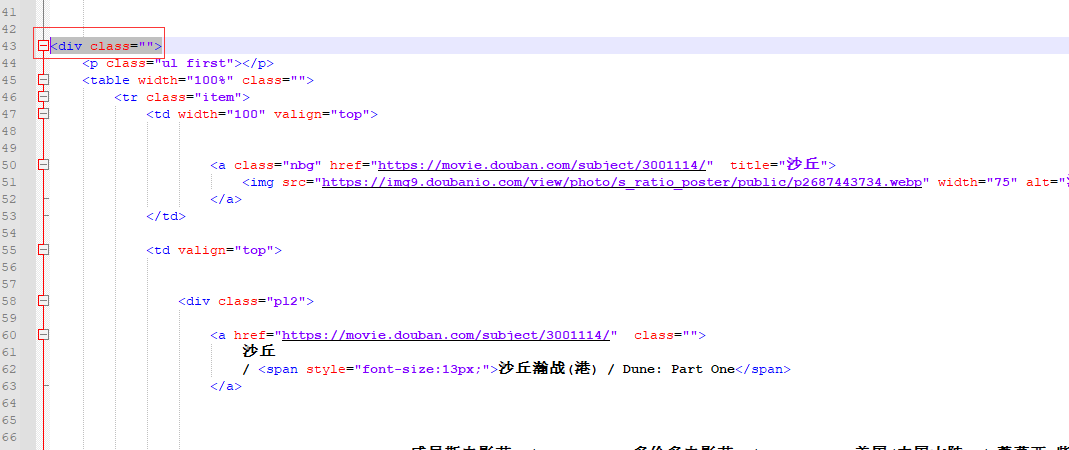
Narrow the scope and continue to check, because under this label is the table label. We use the table label to find it
movice_url = movice_etree_element.xpath('//*[@id="content"]/div/div[1]/div/div/table')
print(movice_url)
# [<Element table at 0x1bedccf8608>, <Element table at 0x1bedccf8588>, <Element table at 0x1bedccf85c8>, <Element table at 0x1bedccf8508>, <Element table at 0x1bedccf8188>, <Element table at 0x1bedccf8148>, <Element table at 0x1bedccf8108>, <Element table at 0x1bedccf8048>, <Element table at 0x1bedccf8088>, <Element table at 0x1bedccf8208>]
Under this < div > tag, there are 10 table tags. Obviously, the information of 10 new films is in these 10 tables
Narrow the scope and continue to find the url corresponding to these 10 movies. Find the tr tag below
movice_url = movice_etree_element.xpath('//*[@id="content"]/div/div[1]/div/div/table/tr')
print(movice_url)
# [<Element tr at 0x2135c038648>, <Element tr at 0x2135c0385c8>, <Element tr at 0x2135c038608>, <Element tr at 0x2135c038548>, <Element tr at 0x2135c0381c8>, <Element tr at 0x2135c038188>, <Element tr at 0x2135c038148>, <Element tr at 0x2135c038088>, <Element tr at 0x2135c0380c8>, <Element tr at 0x2135c038248>]
Or 10 objects, representing the contents of 10 films are all in these 10 lines
Narrow down and continue to find
movice_etree_element = etree.HTML(movice_resp_text)
movice_url = movice_etree_element.xpath('//*[@id="content"]/div/div[1]/div/div/table/tr/td')
print(movice_url)
This time, 20 objects are returned, that is, 20 td, that is, there are 2 columns in each row. We take the required column, that is, the first column
movice_url = movice_etree_element.xpath('//*[@id="content"]/div/div[1]/div/div/table/tr/td[1]')
print(movice_url)
Ten more column labels are returned. We need url information in these ten columns
Is the corresponding column of the following source code. There are 10 in total, and only one display is intercepted
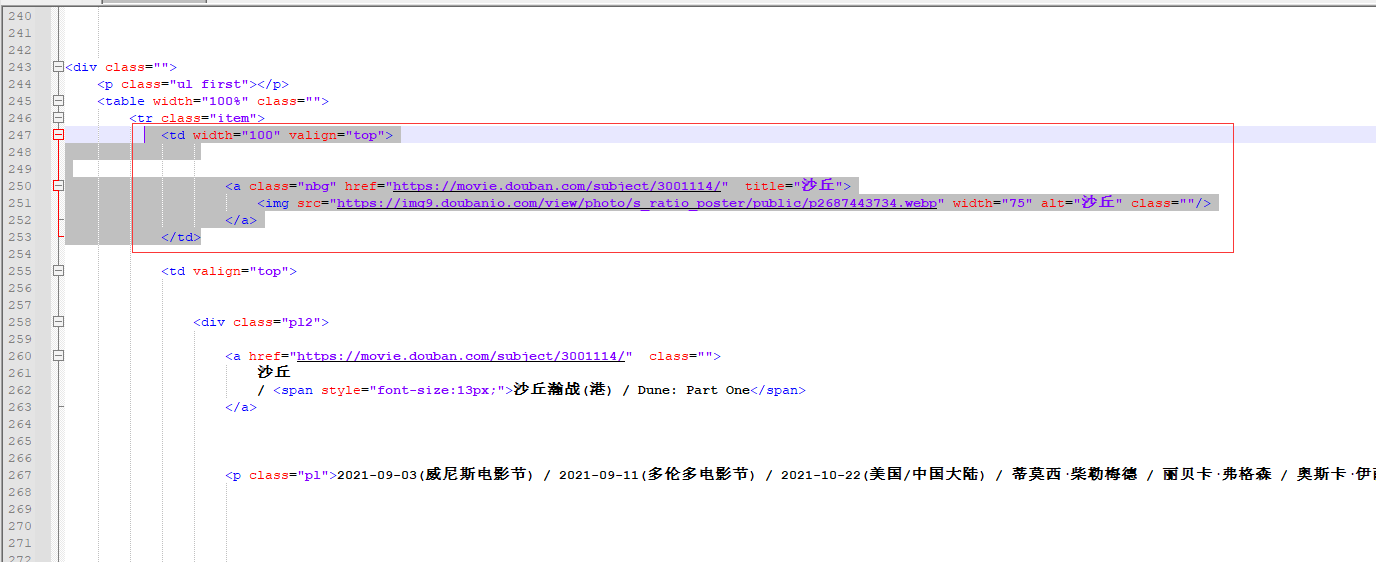
Narrow down and keep looking. This time we look for the < a > tag
movice_url = movice_etree_element.xpath('//*[@id="content"]/div/div[1]/div/div/table/tr/td[1]/a')
print(movice_url)
If there is no problem, return 10 corresponding < a > tags, that is, the tags corresponding to the source code
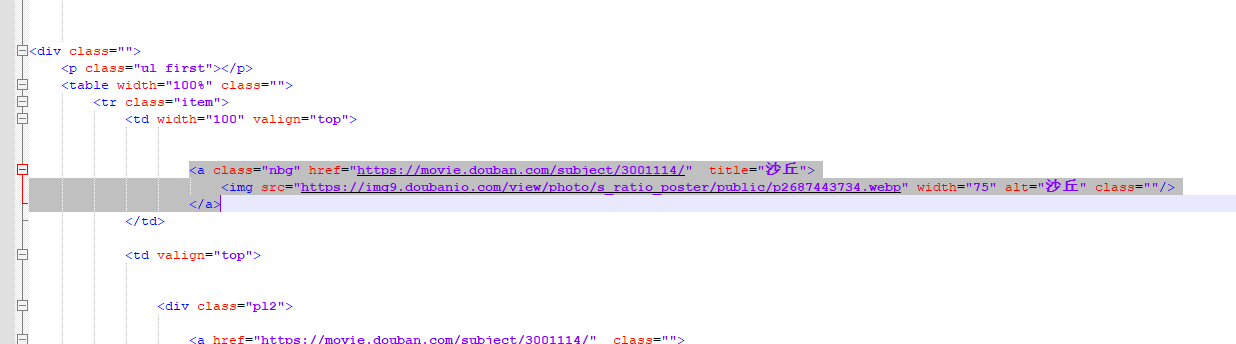
The following tag is the href attribute value, so you can get the url of 10 movies
movice_url = movice_etree_element.xpath('//*[@id="content"]/div/div[1]/div/div/table/tr/td[1]/a/@href')
print(movice_url)
# ['https://movie.douban.com/subject/3001114/', 'https://movie.douban.com/subject/33457594/', 'https://movie.douban.com/subject/34820925/', 'https://movie.douban.com/subject/35235502/', 'https://movie.douban.com/subject/1428581/', 'https://movie.douban.com/subject/34626280/', 'https://movie.douban.com/subject/35158124/', 'https://movie.douban.com/subject/34874432/', 'https://movie.douban.com/subject/35115642/', 'https://movie.douban.com/subject/32568661/']
According to the obtained url, take one of the URLs to analyze and obtain the film name and director name of the film
The principle is the same as the above. The key is to find the corresponding information from the source code
# Set the access client header information. If it is not set, it may not be accessible using requests
headers = {'User-Agent': 'M'}
movice_url = 'https://movie.douban.com/subject/3001114/'
resp = requests.get(movice_url,headers=headers)
# Get all the source code information of the response
movice_resp_text = resp.text
# Use etree.HTML to convert to lxml. etree.HTML that can be parsed using xpath_ Element object
movice_etree_element = etree.HTML(movice_resp_text)
movice_name = movice_etree_element.xpath('//*[@id="content"]/h1/span[1]/text()')
movice_author = movice_etree_element.xpath('//*[@id="info"]/span[1]/span[2]/a/text()')
print(movice_name,movice_author)
# ['Dune dune'] ['Dennis Villeneuve']
Next, modify the above code into a function, then obtain the information of 10 new films and check the execution time
D: / learn-python 3 / learning script / aiohttp/get_movice_use_sync.py
# Climb the new movie gang of Douban movie ranking list and use the synchronization method
# Import module
import requests
from lxml import etree
import time
def get_movice_url():
# Set the access client header information. If it is not set, it may not be accessible using requests
headers = {'User-Agent': 'M'}
movice_url = 'https://movie.douban.com/chart'
resp = requests.get(movice_url,headers=headers)
# Get all the source code information of the response
movice_resp_text = resp.text
# Use etree.HTML to convert to lxml. etree.HTML that can be parsed using xpath_ Element object
movice_etree_element = etree.HTML(movice_resp_text)
# Get the url of 10 movies and return a list element as the url of 10 movies
movice_url = movice_etree_element.xpath('//*[@id="content"]/div/div[1]/div/div/table/tr/td[1]/a/@href')
return movice_url
def get_movice_info():
movice_url = get_movice_url()
# print(movice_url)
# Set the access client header information. If it is not set, it may not be accessible using requests
headers = {'User-Agent': 'M'}
# Define an empty dictionary to receive movie information
movice_info = {}
# Traverse the obtained movie url to the movie name and director
for url in movice_url:
resp = requests.get(url,headers=headers)
# Get all the source code information of the response
movice_resp_text = resp.text
# Use etree.HTML to convert to lxml. etree.HTML that can be parsed using xpath_ Element object
movice_etree_element = etree.HTML(movice_resp_text)
# Get the name and director of the movie
movice_name = movice_etree_element.xpath('//*[@id="content"]/h1/span[1]/text()')
movice_author = movice_etree_element.xpath('//*[@id="info"]/span[1]/span[2]/a/text()')
# Assign the obtained movie name and director as a value to the dictionary, and the dictionary key is the movie url
movice_info[url] = {'name':movice_name,'author':movice_author}
return movice_info
if __name__ == '__main__':
start_time = time.time()
movice_info = get_movice_info()
print(movice_info)
end_time = time.time()
print(end_time-start_time)
The output is as follows. The returned dictionary contains the url, movie name and director name of the movie. The execution time is more than 8 seconds
{'https://Movie. Doublan. COM / subject / 3001114 / ': {name': ['dune Dune'], 'author': ['Dennis Villeneuve']}, ' https://movie.douban.com/subject/33457594/': {'name ': [' Mogadishu
sand 모가디슈'], 'author': ['Liu shengwan']}, 'https://Movie. Doublan. COM / subject / 34820925 / ': {name': ['titanium'], 'author': ['Julia dicuno']}, ' https://movie.douban.com/subject/35235502/': {'name ': [' drive my car ドゅイブマイカー], 'author': ['Hamaguchi']}, ' https://movie.douban.com/subject/1428581/': {'name ': [' Book of heaven '],' author ': [' Wang Shuchen ',' Qian Yunda ']} , ' https://movie.douban.com/subject/34626280/': {'name ': [' moonlight panic: killing Halloween Kills'], 'author': ['David Gordon Green']}, ' https://movie.douban.com/subject/35158124/': {'name ': [' midsummer future '],' author ': [' Chen Zhengdao ']},' https://movie.douban.com/subject/34874432/': {'name': ['bouquet like love bouquet みたいなをした
'], 'author': ['Nobuhiro Doi ']}, 'https://Movie. Doublan. COM / subject / 35115642 / ': {name': ['parallel forest'], 'author': ['Zheng Lei']}, ' https://movie.douban.com/subject/32568661/': {'name ': [' mother's magic boy ',' mother's magic boy '],' author ': [' Yin Zhiwen ']}}
8.593812465667725
The following uses asynchronous methods to perform the same operation in combination with AIO HTTP and asyncio
get_movice_use_async.py
# Climb the new movie gang of Douban movie ranking list and use asynchronous method
# Import module
import requests
from lxml import etree
import time
import asyncio
import aiohttp
async def get_movice_url():
# Set the access client header information. If it is not set, it may not be accessible using requests
headers = {'User-Agent': 'M'}
movice_url = 'https://movie.douban.com/chart'
async with aiohttp.ClientSession() as session:
async with session.get(movice_url,headers=headers) as resp:
# print(resp.status)
# Get all the source code information of the response
movice_resp_text = await resp.text()
# Use etree.HTML to convert to lxml. etree.HTML that can be parsed using xpath_ Element object
movice_etree_element = etree.HTML(movice_resp_text)
# Get the url of 10 movies and return a list element as the url of 10 movies
movice_url = movice_etree_element.xpath('//*[@id="content"]/div/div[1]/div/div/table/tr/td[1]/a/@href')
return movice_url
async def get_movice_info(url):
# Set the access client header information. If it is not set, it may not be accessible using requests
headers = {'User-Agent': 'M'}
# Traverse the obtained movie url to the movie name and director
async with aiohttp.ClientSession() as session:
async with session.get(url,headers=headers) as resp:
# Get all the source code information of the response
movice_resp_text = await resp.text()
# Use etree.HTML to convert to lxml. etree.HTML that can be parsed using xpath_ Element object
movice_etree_element = etree.HTML(movice_resp_text)
# Take the name and director of the film
movice_name = movice_etree_element.xpath('//*[@id="content"]/h1/span[1]/text()')
movice_author = movice_etree_element.xpath('//*[@id="info"]/span[1]/span[2]/a/text()')
# Assign the obtained movie name and director as a value to the dictionary, and the dictionary key is the movie url
return {url:{'name':movice_name,'author':movice_author}}
# Define main execution function main
async def main():
# First, call the coroutine function to obtain the movie url, and return a list element as the movie url
movice_url = await get_movice_url()
# Create tasks and pass the url of 10 movies as a parameter to the coroutine function get_movice_info to get the movie name and director information
tasks = [get_movice_info(url) for url in movice_url]
# Using the asyncio.gather method, 10 requests are run at the same time and the results are returned in order
movice_info = await asyncio.gather(*tasks)
print(movice_info)
# Execute and calculate execution time
if __name__ == '__main__':
start_time = time.time()
asyncio.run(main())
end_time = time.time()
print(end_time-start_time)
The output is as follows
[{'https://Movie. Doublan. COM / subject / 3001114 / ': {name': ['dune Dune'], 'author': ['Dennis Villeneuve']}}, {' https://movie.douban.com/subject/33457594/': {'name ': [' MOGA
Disha 모가디슈'], 'author': ['Liu shengwan']}}, {'https://Movie. Doublan. COM / subject / 34820925 / ': {name': ['titanium'], 'author': ['Julia dicuno']}}, {' https://movie.douban.com/subject/35235502/': {'name ': [' drive my car ドゅイブマイカー], 'author': ['Hamaguchi']}}, {' https://movie.douban.com/subject/1428581/': {'name ': [' Book of heaven '],' author ': [' Wang Shuchen ',' Qian Yunda ']}} , {' https://movie.douban.com/subject/34626280/ ': {name': ['moonlight panic: killing Halloween kills'],' author ': [' David Gordon Green ']}}, {' https://movie.douban.com/subject/35158124/': {'name ': [' midsummer future '],' author ': [' Chen Zhengdao ']}}, {' https://movie.douban.com/subject/34874432/': {'name ': [' bouquet like love bouquet み
たいなloveをした'], 'author': ['Nobuhiro Doi ']}}, {'https://Movie. Doublan. COM / subject / 35115642 / ': {name': ['parallel forest'], 'author': ['Zheng Lei']}}, {' https://movie.douban.com/subject/32568661/': {'name ': [' mother's magic boy ',' mother's magic boy '],' author ': [' Yin Zhiwen ']}}]
1.7407007217407227
You can see that asynchronous execution of the same task takes much less time than synchronous execution