Catalog
1. Word Memory
English is currently one of the most widely used languages in the world and is also a commonly used language in the world.As countries communicate more and more frequently, the position of English is increasing.In China, thousands of people have joined the English learning army. English is an indispensable skill for us, but the memory of English words is a big problem.Write a program to help learners remember English words quickly.Run a program to randomly output the Chinese meaning of English words and ask them to write or speak English.The results are shown in the following figure.
The sample code is as follows:
import random # Think: A Chinese word corresponds to an English word. What data type can I use to store it? # A: Dictionary key --> value (English) word_dict = {"Mobile phone": "mobile phone", "Beauty": "beauty", "Computer": "computer", "idiom": "idiom", "Price": "price", "Age": "age", "Shop": "shop"} word_list = list(word_dict) print("**************Baici Chopping**************") while True: terms = random.choice(word_list) # terms: print("Chinese:", terms) value = word_dict.get(terms).strip() # Get the corresponding English words in Chinese from the dictionary word = input("English: ").strip() # Prevent users from mistakenly entering blanks if word == value: print(f"\033[0;32m{chr(8730)}\033[0m You are so good!!!") else: print(f"\033[0;31m{chr(215)}\033[0m Wrong answer, correct answer: \033[0;31m{value}\033[0m") print("Go on!~")
Some of these grammars are described below:
2. Word Reminder
Add prompt function and exit function for Baici chopper.Run the program, the user enters a? Number (both Chinese and English greetings) to prompt the words, and the program randomly outputs the first two letters or the last two letters of the words to prompt.User input Q or Q, prompting to quit the program!!And exit the program.The results are shown in the following figure.
The sample code is as follows:
import random def equal(str_a, str_b): if str_a.strip() == str_b.strip(): # str_a: User-entered English word str_b: English word in dictionary print(f"\033[0;32m{chr(8730)}\033[0m You are so good!!!") else: print(f"\033[0;31m{chr(215)}\033[0m Wrong answer, correct answer: \033[0;31m{str_b}\033[0m") print("Go on!~") # Think: A Chinese word corresponds to an English word. What data type can I use to store it? # A: Dictionary key --> value (English) word_dict = {"Mobile phone": "mobile phone", "Beauty": "beauty", "Computer": "computer", "idiom": "idiom", "Price": "price", "Age": "age", "Shop": "shop"} word_list = list(word_dict) print("**************Baici Chopping**************") while True: terms = random.choice(word_list) # terms: print("Chinese:", terms) value = word_dict.get(terms).strip() # Get the corresponding English words in Chinese from the dictionary word = input("English: ").strip() # Prevent users from mistakenly entering blanks # There are three categories of judgements: 1. Enter q 2. Enter? 3. Enter normal words if word.lower() == "q": print("Exiting program!!!") break elif word in ["?", "?"]: tips_list = [value[:2], value[-2:]] # Store the first two letters and the last two letters of a word in a list tips = random.choice(tips_list) # Remove prompt letters randomly if tips_list.index(tips) == 0: print(f"\033[1;31m Tips:\033[0m The first two letters of a word are: {tips}") else: print(f"\033[1;31m Tips:\033[0m The last two letters of a word are: {tips}") word = input("English: ").strip() # Prevent users from mistakenly entering blanks equal(word, value) # Call function to compare user-entered words with words in dictionary else: equal(word, value) # Call function to compare user-entered words with words in dictionary
3. Memory function
Add a memory function for Baici chopping.User-answered words do not repeat.Words that are not answered correctly and words that do not appear continue to be output randomly.When all the words are answered, it's great to remind you that today's task is all over!!And exit the program.The result is shown in the diagram.
The sample code is as follows:
import random def equal(str_a, str_b): if str_a.strip() == str_b.strip(): # str_a: User-entered English word str_b: English word in dictionary print(f"\033[0;32m{chr(8730)}\033[0m You are so good!!!") word_dict.pop(terms) else: print(f"\033[0;31m{chr(215)}\033[0m Wrong answer, correct answer: \033[0;31m{str_b}\033[0m") print("Go on!~") # Think: A Chinese word corresponds to an English word. What data type can I use to store it? # A: Dictionary key --> value (English) word_dict = {"Mobile phone": "mobile phone", "Beauty": "beauty", "Age": "age", "Shop": "shop"} # To test for ease of deleting a part of a word print("**************Baici Chopping**************") while len(word_dict): terms = random.choice(list(word_dict)) # terms: print("Chinese:", terms) value = word_dict.get(terms).strip() # Get the corresponding English words in Chinese from the dictionary word = input("English: ").strip() # Prevent users from mistakenly entering blanks # There are three categories of judgements: 1. Enter q 2. Enter? 3. Enter normal words if word.lower() == "q": print("Exiting program!!!") break elif word in ["?", "?"]: tips_list = [value[:2], value[-2:]] # Store the first two letters and the last two letters of a word in a list tips = random.choice(tips_list) # Remove prompt letters randomly if tips_list.index(tips) == 0: print(f"\033[1;31m Tips:\033[0m The first two letters of a word are: {tips}") else: print(f"\033[1;31m Tips:\033[0m The last two letters of a word are: {tips}") word = input("English: ").strip() # Prevent users from mistakenly entering blanks equal(word, value) # Call function to compare user-entered words with words in dictionary else: equal(word, value) # Call function to compare user-entered words with words in dictionary else: print("You're awesome. You're all done today!!!")
Some of these grammars are described below:
4. Speech Reading
Add voice reading function for Bai Ci Chopping.Run the program, while outputting Chinese words, the voice broadcasts Chinese words, the answer is right, the voice broadcasts the answer is right, you are awesome!!The correct answer is to read the correct English words aloud. Go on!When you press the q key to exit the program, the voice announcement is exiting the program!!.It's awesome to have voice broadcasts at the end of the whole word memorization. You're all done today!!Note: To complete this task, you need to import third-party modules, import module commands, under Mac system:
pip install -i http://pypi.douban.com/simple --trusted-host pypi.douban.com pyttsx3 pip install -i http://pypi.douban.com/simple --trusted-host pypi.douban.com pyobjc
Under Windows:
pip install -i http://pypi.douban.com/simple --trusted-host pypi.douban.com pywin32
Demonstration of Program Running Results
On a Mac system, the sample code is:
import random import pyttsx3 def speak(sp_str): engine = pyttsx3.init() engine.say(sp_str) engine.runAndWait() def equal(str_a, str_b): if str_a.strip() == str_b.strip(): # str_a: User-entered English word str_b: English word in dictionary print(f"\033[0;32m{chr(8730)}\033[0m You are so good!!!") speak("Yes, you're great!!!") word_dict.pop(terms) else: print(f"\033[0;31m{chr(215)}\033[0m Wrong answer, correct answer: \033[0;31m{str_b}\033[0m") speak("Wrong answer, correct answer:" + str_b + "Go on!!!") print("Go on!~") # Think: A Chinese word corresponds to an English word. What data type can I use to store it? # A: Dictionary key --> value (English) word_dict = {"Mobile phone": "mobile phone", "Beauty": "beauty", "Age": "age", "Shop": "shop"} # To test for ease of deleting a part of a word print("**************Baici Chopping**************") while len(word_dict): terms = random.choice(list(word_dict)) # terms: print("Chinese:", terms) speak("Chinese:" + terms) value = word_dict.get(terms).strip() # Get the corresponding English words in Chinese from the dictionary word = input("English: ").strip() # Prevent users from mistakenly entering blanks # There are three categories of judgements: 1. Enter q 2. Enter? 3. Enter normal words if word.lower() == "q": print("Exiting program!!!") speak("Exiting program!!!") break elif word in ["?", "?"]: tips_list = [value[:2], value[-2:]] # Store the first two letters and the last two letters of a word in a list tips = random.choice(tips_list) # Remove prompt letters randomly if tips_list.index(tips) == 0: print(f"\033[1;31m Tips:\033[0m The first two letters of a word are: {tips}") else: print(f"\033[1;31m Tips:\033[0m The last two letters of a word are: {tips}") word = input("English: ").strip() # Prevent users from mistakenly entering blanks equal(word, value) # Call function to compare user-entered words with words in dictionary else: equal(word, value) # Call function to compare user-entered words with words in dictionary else: print("You're awesome. You're all done today!!!") speak("You're awesome. You're all done today!!!")
Under Windows, the sample code is:
import random import winsound from win32com.client import Dispatch def speak(sp_str): speak_out.speak(sp_str) winsound.PlaySound(sp_str, winsound.SND_ASYNC) def equal(str_a, str_b): if str_a.strip() == str_b.strip(): # str_a: User-entered English word str_b: English word in dictionary print(f"\033[0;32m{chr(8730)}\033[0m You are so good!!!") speak("Yes, you're great!!!") word_dict.pop(terms) else: print(f"\033[0;31m{chr(215)}\033[0m Wrong answer, correct answer: \033[0;31m{str_b}\033[0m") speak("Wrong answer, correct answer:" + str_b + "Go on!!!!") print("Go on!~") # Think: A Chinese word corresponds to an English word. What data type can I use to store it? # A: Dictionary key --> value (English) speak_out = Dispatch('sapi.spvoice') word_dict = {"Mobile phone": "mobile phone", "Beauty": "beauty", "Age": "age", "Shop": "shop"} # To test for ease of deleting a part of a word print("**************Baici Chopping**************") while len(word_dict): terms = random.choice(list(word_dict)) # terms: print("Chinese:", terms) speak("Chinese:" + terms) value = word_dict.get(terms).strip() # Get the corresponding English words in Chinese from the dictionary word = input("English: ").strip() # Prevent users from mistakenly entering blanks # There are three categories of judgements: 1. Enter q 2. Enter? 3. Enter normal words if word.lower() == "q": print("Exiting program!!!") speak("Exiting program!!!") break elif word in ["?", "?"]: tips_list = [value[:2], value[-2:]] # Store the first two letters and the last two letters of a word in a list tips = random.choice(tips_list) # Remove prompt letters randomly if tips_list.index(tips) == 0: print(f"\033[1;31m Tips:\033[0m The first two letters of a word are: {tips}") else: print(f"\033[1;31m Tips:\033[0m The last two letters of a word are: {tips}") word = input("English: ").strip() # Prevent users from mistakenly entering blanks equal(word, value) # Call function to compare user-entered words with words in dictionary else: equal(word, value) # Call function to compare user-entered words with words in dictionary else: print("You're awesome. You're all done today!!!") speak("You're awesome. You're all done today!!!")
5. Integral Evaluation
Add the function of memorizing integrals for Baici chopping.When you memorize a word, the word is answered correctly and the product is 3 points. You can use the prompt to answer incorrectly.After making a mistake, the subsequent answers are multiplied by one point.The highest score is 24 and the lowest is 8.Excellent scores are above 20, good 16-19, pass 12-15, and fail below 12.Broadcast the player's score and rating when the memorized word is complete.The effect is shown in the video.
Demonstration of Program Running Results
Considering that most people use the windows system, the author mainly gives the example code under the windows system here:
import random import winsound from win32com.client import Dispatch def speak(sp_str): speak_out.speak(sp_str) winsound.PlaySound(sp_str, winsound.SND_ASYNC) def equal(str_a, str_b): global score if str_a.strip() == str_b.strip(): # str_a: User-entered English word str_b: English word in dictionary print(f"\033[0;32m{chr(8730)}\033[0m You are so good!!!") speak("Yes, you're great!!!") word_dict.pop(terms) if terms in word_set: score += 1 else: score += 3 else: print(f"\033[0;31m{chr(215)}\033[0m Wrong answer, correct answer: \033[0;31m{str_b}\033[0m") speak("Wrong answer, correct answer:" + str_b + "Go on!!!!") print("Go on!~") word_set.add(terms) # Think: A Chinese word corresponds to an English word. What data type can I use to store it? # A: Dictionary key --> value (English) speak_out = Dispatch('sapi.spvoice') word_dict = {"Mobile phone": "mobile phone", "Beauty": "beauty", "Age": "age", "Shop": "shop", "We": "we", "Price": "price", "book": "book", "Computer": "computer"} score = 0 # Used for statistical scores word_set = set() # Words used to store first answer errors print("**************Baici Chopping**************") while len(word_dict): terms = random.choice(list(word_dict)) # terms: print("Chinese:", terms) speak("Chinese:" + terms) value = word_dict.get(terms).strip() # Get the corresponding English words in Chinese from the dictionary word = input("English: ").strip() # Prevent users from mistakenly entering blanks # There are three categories of judgements: 1. Enter q 2. Enter? 3. Enter normal words if word.lower() == "q": print("Exiting program!!!") speak("Exiting program!!!") break elif word in ["?", "?"]: tips_list = [value[:2], value[-2:]] # Store the first two letters and the last two letters of a word in a list tips = random.choice(tips_list) # Remove prompt letters randomly if tips_list.index(tips) == 0: print(f"\033[1;31m Tips:\033[0m The first two letters of a word are: {tips}") else: print(f"\033[1;31m Tips:\033[0m The last two letters of a word are: {tips}") word = input("English: ").strip() # Prevent users from mistakenly entering blanks equal(word, value) # Call function to compare user-entered words with words in dictionary else: equal(word, value) # Call function to compare user-entered words with words in dictionary else: if score >= 20: start = "excellent" elif score >= 16: start = "good" elif score >= 12: start = "pass" else: start = "Fail" print(f"Your score is{score}, achievement{start}") speak("Your score is: " + str(score) + "achievement" + start)
6. Silent Output
Add the function of silent output to Baici chopping.Computer-based word recitation works well, but if you can output words, it can reduce the visual acuity.Words can be printed on paper in a silent way, and users can easily recite and write exercises.Requires the program to print the number of silent spaces (1-6 silent spaces) for each word by typing it in, as shown in the diagram.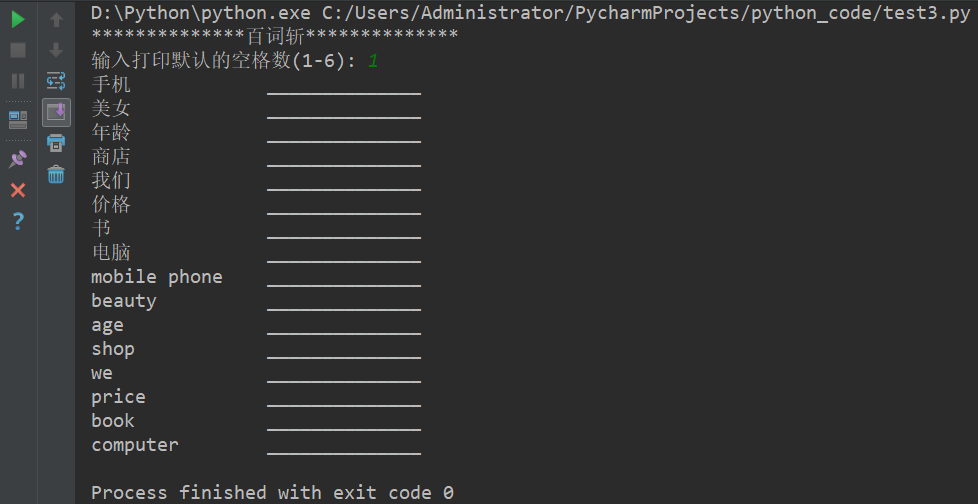
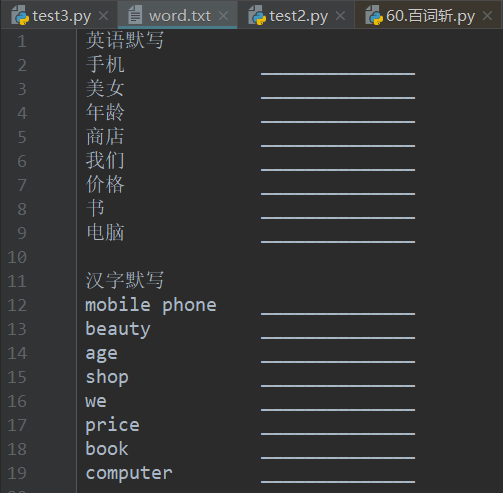
The sample code is as follows:
word_dict = {"Mobile phone": "mobile phone", "Beauty": "beauty", "Age": "age", "Shop": "shop", "We": "we", "Price": "price", "book": "book", "Computer": "computer"} print("**************Baici Chopping**************") blank_num = int(input("Enter the default number of blanks for printing(1-6): ").strip()) # Get all keys/values in the dictionary and save them in the list key_list = list(word_dict) value_list = list(word_dict.values()) max_len_key = max(list(map(len, key_list))) * 2 # Two letters in one Chinese max_len_value = max(list(map(len, value_list))) max_len = max_len_value if max_len_value > max_len_key else max_len_key # Maximum length for English and Chinese file = open("word.txt", "a", encoding="utf-8") file.write("English Silence\n") for key in word_dict.keys(): if len(key)*2 < max_len: key = key + " " * (max_len-len(key)*2) print(key + " \t"+ "______________ " * blank_num) # Generally speaking, English must be longer than Chinese content = key + " \t"+ "______________ " * blank_num + "\n" file.write(content) file.write("\n Chinese character silent writing\n") for value in word_dict.values(): if len(value) < max_len: value = value + " " * (max_len-len(value)) print(value + " \t"+ "______________ " * blank_num) content = value + " \t" + "______________ " * blank_num + "\n" file.write(content)
7. Vocabulary acquisition
This example provides a small number of English words for practice through the dictionary. If you want to apply them in practice, it is very convenient and practical to import words from a file.The following is a program that can import English words from a text file by unit, with spaces between English and Chinese in the text.During the import process, delete the.And, and spaces before the word.The text before importing and the effect of importing a dictionary are shown in the figure.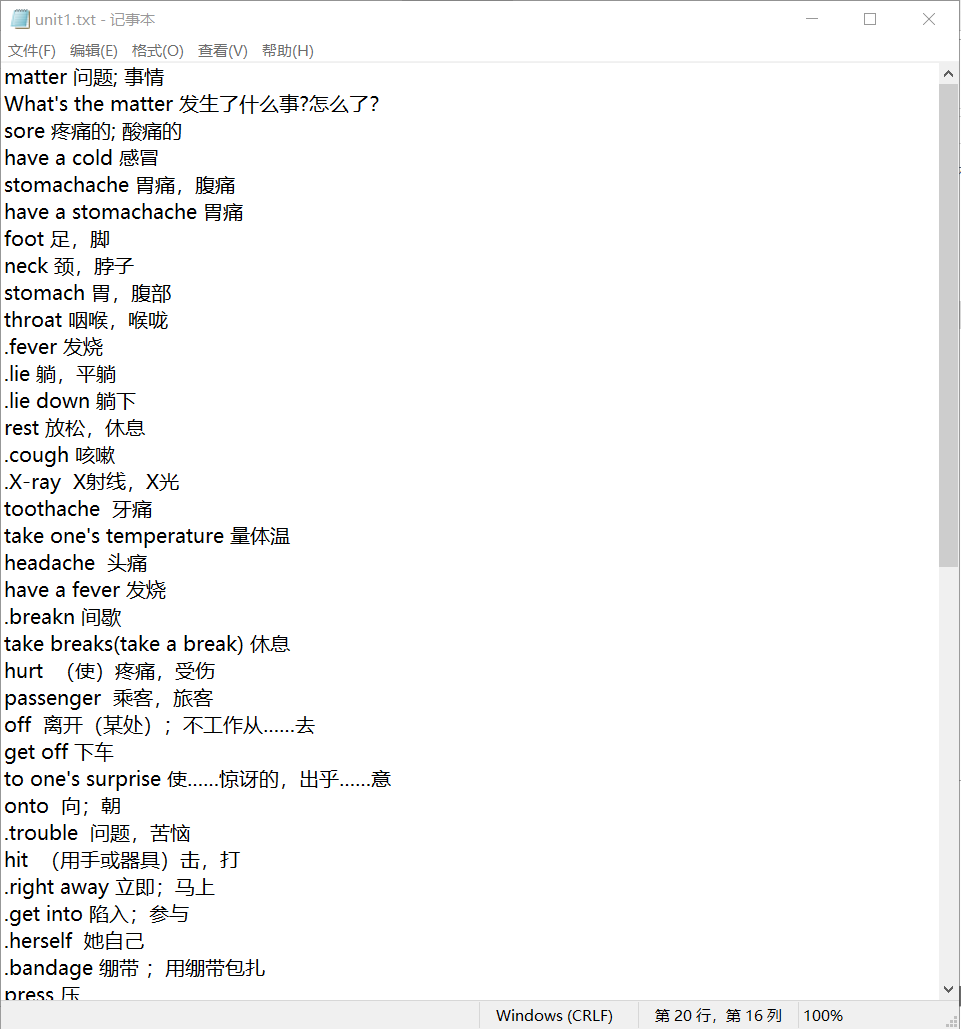

The sample code is as follows:
eng = {} with open('unit1.txt', 'r', encoding='UTF-8') as file: while True: line = file.readline() if line == '': break group = line.split() new = [i for i in group if i.strip() != ''] if len(new) == 2: word_eng = new[0].lstrip(".") eng[new[1]] = word_eng else: for i in range(len(new)): if ord(new[i][0]) > 255: word_eng = ' '.join(new[0:i]) word_eng = word_eng.lstrip(".") word_han = ' '.join(new[i:]) break eng[word_han] = word_eng print(eng)

