Python - pandas module - Series data structure
pandas
Numpy is more suitable for dealing with unified numerical array data
pandas is specially designed to handle tables and mixed data
panda has two data structures:
- Series
- DataFrame
Series
- The Series data type can store one-dimensional tag array of any type of data (integer, string, floating-point number, Python object, etc.), axis tags are collectively referred to as indexes, and each element has an index
- Series representation: the index is on the left and the value is on the right
- You can use the properties of Series:
Index -- get index column
values -- get data column
Think like this: each element can be similarly regarded as a dictionary, and the whole Series can be similarly regarded as a two-dimensional array
As shown in the figure:
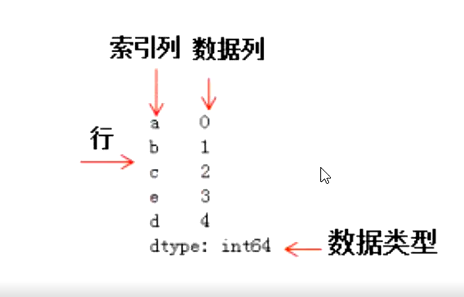
Create Series
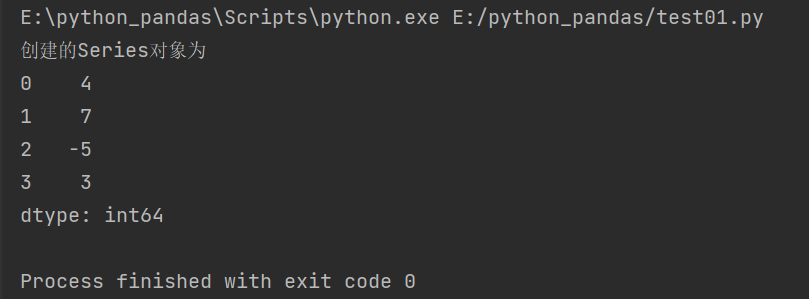
Automatically create an integer index of: 0~~(N-1)(N: array length) when no index column is specified
import pandas as pd
#Create with the Series function by passing in a list
obj = pd.Series([4,7,-5,3])
print('Created Series Object is')
print(obj)
Automatically add integer index 0 ~ ~ 4 (array length is 4)
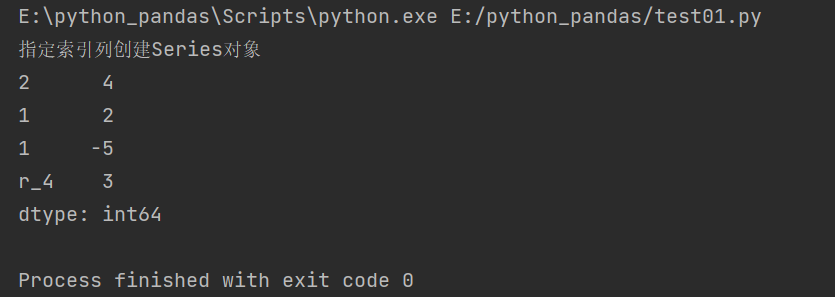
Specifying the index column index (number, string) is different from the array, and the element types in the array should be the same
#Create a Series object by specifying the index column
obj = pd.Series([4,2,-5,3],index=[2,1,1,'r_4'])
print('Specify index column creation Series object')
print(obj)
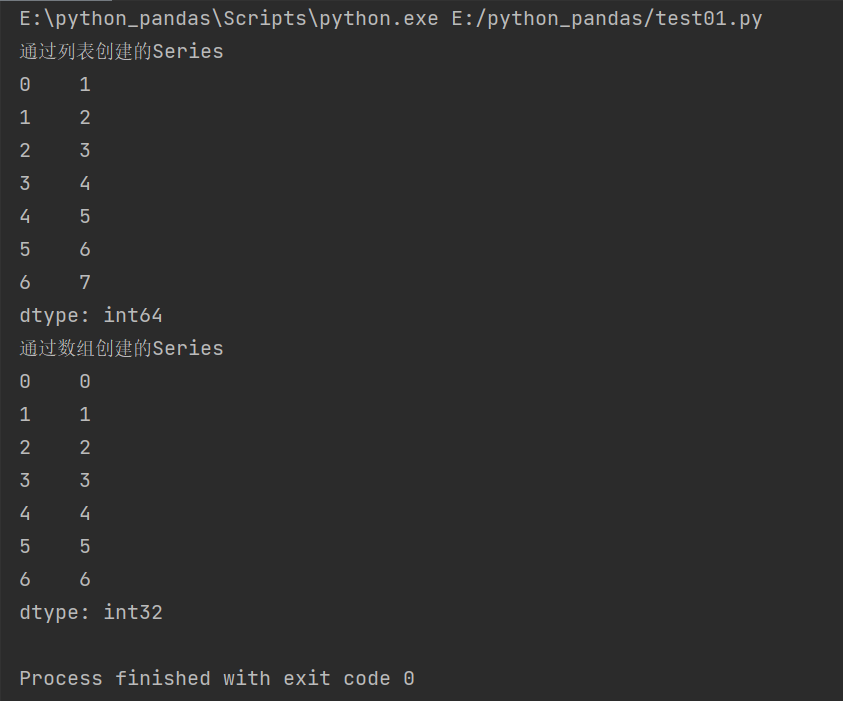
Build Series using lists and arrays
lis = [1,2,3,4,5,6,7]
array = np.arange(7)
Series_lis = pd.Series(lis)
Series_array = pd.Series(array)
print('Created from list Series')
print(Series_lis)
print('Created from an array Series')
print(Series_array)
Similarly, index columns are automatically added
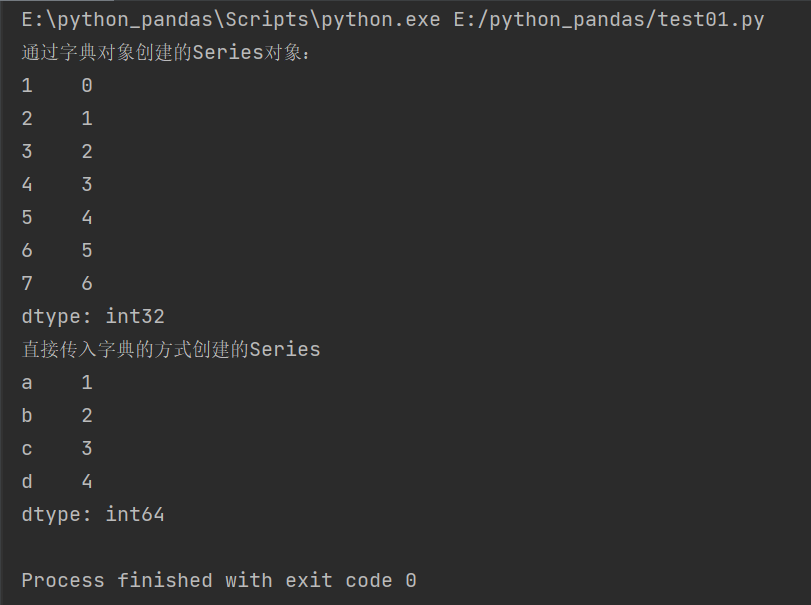
Create Series by dictionary / dictionary object
The difference is that the key in the dictionary cannot be repeated
But in Series, index can be repeated
#How to create a dictionary object
dic = dict(zip(lis,array))
#Zip package the zip(lis,array) operation to form a tuple list
Series_dict = pd.Series(dic)
print('Created from a dictionary object Series Object:')
print(Series_dict)
#Direct input dictionary mode
Series_dict2 = pd.Series({'a':1,'b':2,'c':3,'d':4})
print('Created by passing in the dictionary directly Series')
print(Series_dict2)
Visit Sreies
Let's take another example of dictionary building
dic = {'Ohio':35000,'Texas':71000,'Oregon':16000,'Utah':5000}
a = pd.Series(dic)
print(a)

Series.head() access
The first 5 elements are accessed by default
print(a.head(2))
Series.tail() accessed from behind
The last 5 elements are accessed by default
print(a.tail(2))
Sreies.index view index columns
print(a.index)
Sreies.values view data columns
print(a.values)

Series.dtype viewing data types
print(a.dtype)
Use of Series
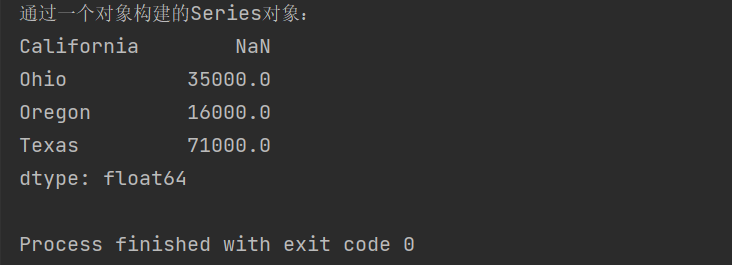
Using one Series to create another Series
Above, we created a Series object a
Next, we create another Series object with a
'''Dictionary construction Serise example'''
dic = {'Ohio':35000,'Texas':71000,'Oregon':16000,'Utah':5000}
a = pd.Series(dic)
b = pd.Series(a,index=['California','Ohio','Oregon','Texas'])
print('Built from an object Series Object:')
print(b)
When creating, the index of the new object is listed as the incoming index
The index of the template object directly takes its value
If the template object does not have an index, add it, and set the value value to the missing value NaN
Missing value detection
What is returned is an object whose data column is bool type
True: missing value
False: not a missing value
#Missing value detection
print('Missing value detection')
print(pd.isnull(b))

Non missing value detection
pd.notnull(Series)
practice
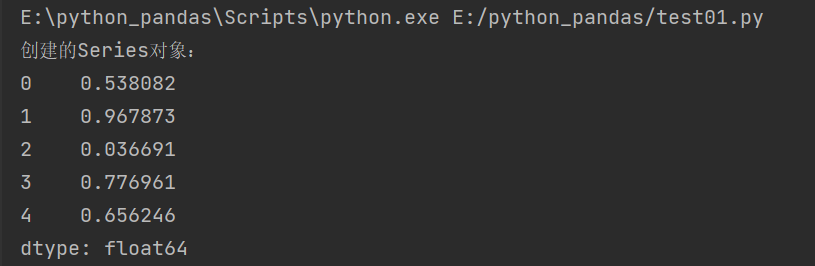
Generate a random number with the same length as sd
sd = pd.Series([1,2,3,4,5])
sd = pd.Series([1,2,4,1,2])
#Generate a random number sequence with the same length as sd
a = np.random.random(len(sd))
#Creating Series objects with arrays
s = pd.Series(a)
print('Created Series Object:')
print(s)
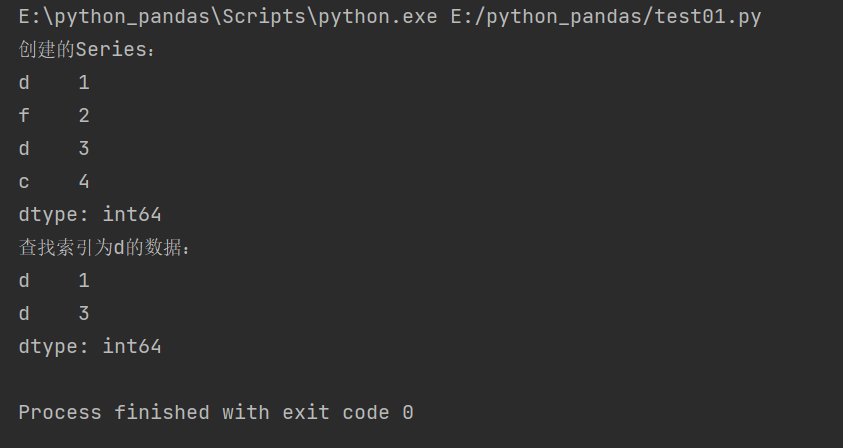
Find Series (index)
[index name]
When there is the same index name, multiple pieces of data are returned
It is verified again that the index name in the Series object is not unique and can be repeated
#Series [index name]
import pandas as pd
obj = pd.Series([1,2,3,4],index=['d','f','d','c'])
print('Created Series: ')
print(obj)
obj2 = obj['d']
print('Find index is d Data:')
print(obj2)
[index position subscript]
Value range of subscript: [o,len(Series.values)]
Can be:
Integer: positive, starting from 0
Negative number: inverted, starting from - 1
# [index position subscript]
import pandas as pd
obj = pd.Series([1,2,3,4],index=['d','f','d','c'])
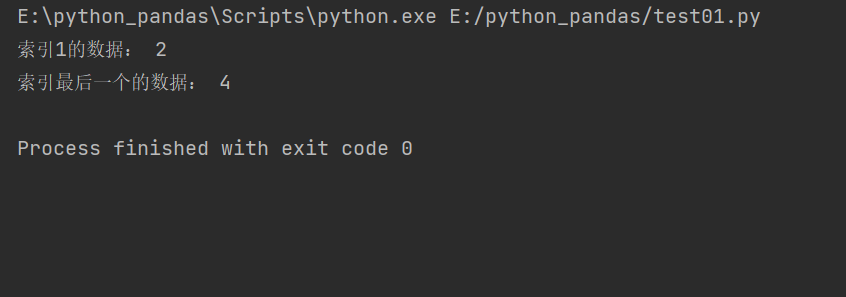
print('Data for index 1:',obj[1])
print('Index last data:',obj[-1])
Slicing operation
Similar to Numpy's ndarray slicing operation
The difference is that the data in the Series slice can be index values in addition to index numbers
be careful:
When slicing with index value, the index value in the index column should be unique, unless the starting value of the index is a unique index
Index position slice [index position: index position: step size]
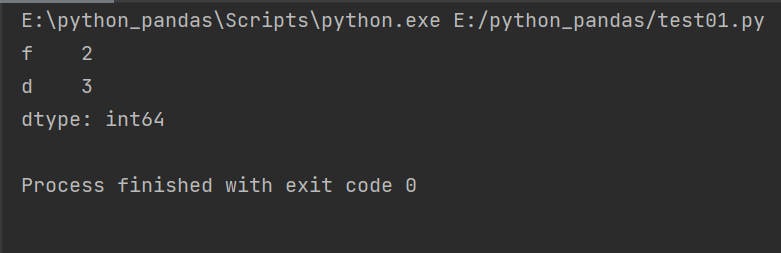
#Index position slice import pandas as pd obj = pd.Series([1,2,3,4],index=['d','f','d','c']) print(obj[1:3])
Index value slice [index value: index value]
When slicing with index value, the index value in the index column should be unique, unless the starting value of the index is a unique index
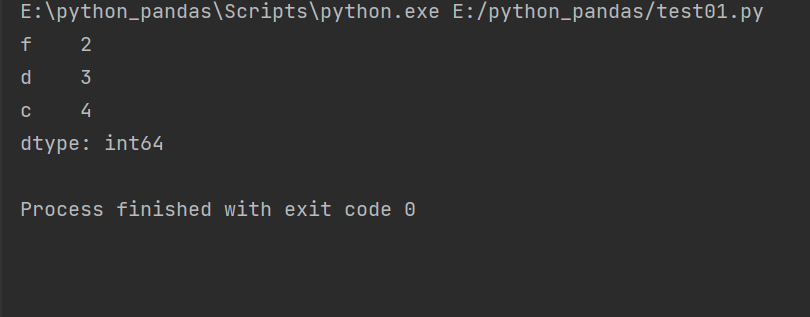
#Index position slice import pandas as pd obj = pd.Series([1,2,3,4],index=['d','f','d','c']) print(obj['f':'c']
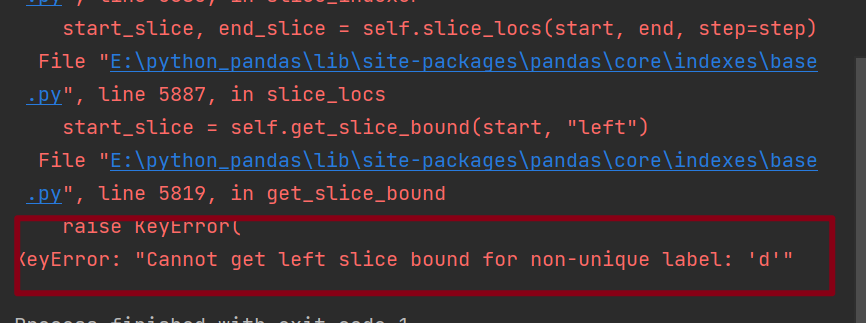
When the slice start index is not a unique index
import pandas as pd obj = pd.Series([1,2,3,4],index=['d','f','d','c']) print(obj['d':'c']
Index column reassignment
import pandas as pd obj = pd.Series([1,2,3,4],index=['d','f','d','c']) obj.index = ['one','two','three','four'] print(obj)
This method can only modify index, not values
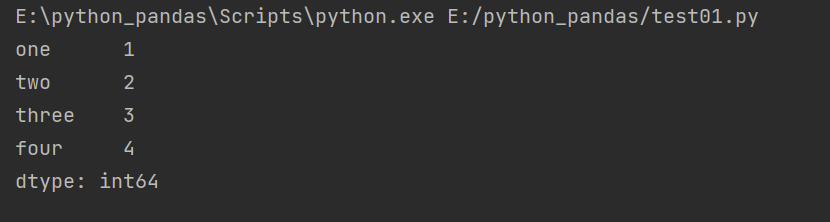
Series operation
Series retains the array operations in Numpy and can be used
When Series performs array operations, the mapping relationship between indexes and values will not change
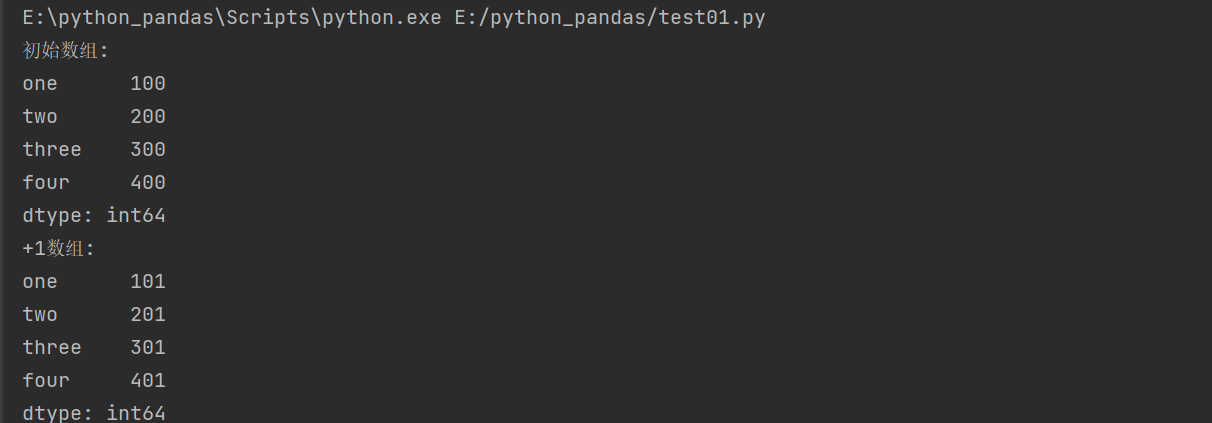
A Series operates on a number
# Series operation
import pandas as pd
obj = pd.Series([100,200,300,400],index = ['one','two','three','four'])
print('Initial array:')
print(obj)
print('+1 array:')
print(obj+1)
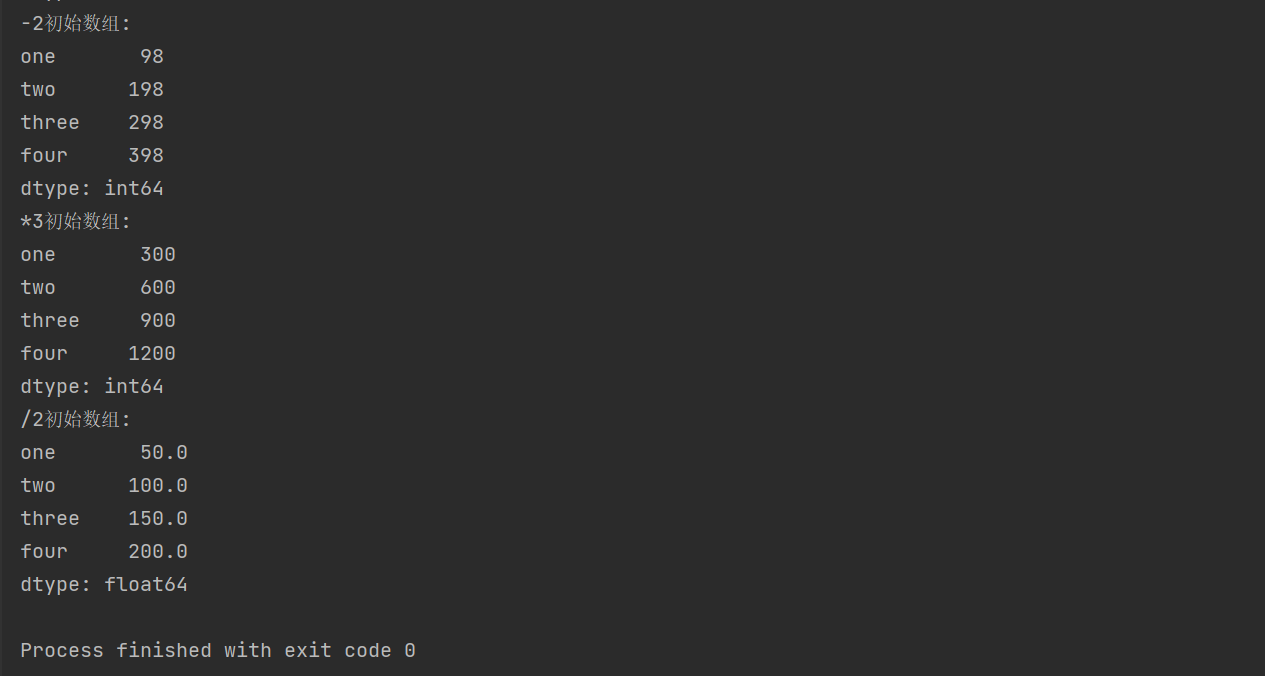
print('-2 Initial array:')
print(obj-2)
print('*3 Initial array:')
print(obj*3)
print('/2 Initial array:')
print(obj/2)
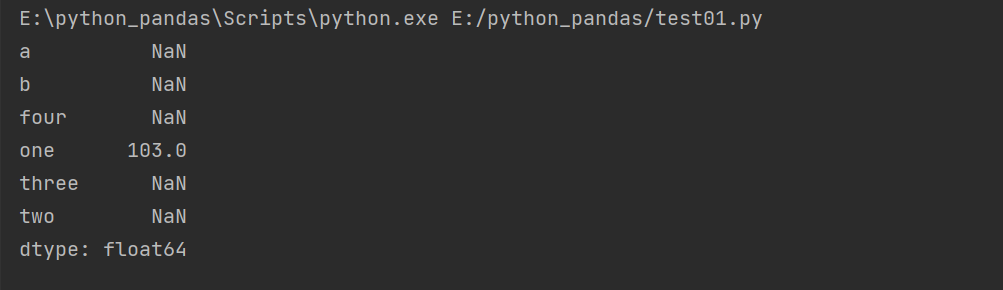
Two Series operations
Two corresponding elements are + - * /, and the other party does not return index, and value=NaN
import pandas as pd obj = pd.Series([100,200,300,400],index = ['one','two','three','four']) obj2 = pd.Series([1,2,3],index=['a','b','one']) print(obj+obj2)
When there are multiple duplicate indexes in two Series objects
To use the value corresponding to the index of Series1 and the value corresponding to the repeated index in Series2, respectively calculate and return
Summary:
When operating on a Series object, it can basically be regarded as operating on ndarray in Numpy
Most of the operations in ndarray can be used on Series