Crawling website: first PPT( http://www.1ppt.com/ )This website really has a conscience
As always, start with the last successful source code:
import requests
import urllib
import os
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
def getPPT(url):
f = requests.get(url,headers=headers) #Send out GET request
f.encoding = f.apparent_encoding #Set encoding method
soup1 = BeautifulSoup(f.text,'lxml')
classHtml = soup1.find('div',class_="col_nav i_nav clearfix").select('a') #stay html Search for categories in
for i in classHtml[:56]:
classUrl = i['href'].split('/')[2] #take ppt Template category keywords saved to classUrl
if not os.path.isdir(r'D:\PPT\\'+i['title']): #Determine whether there is this directory
os.mkdir(r'D:\PPT\\'+i['title']) #If not, create this directory.
else:
continue #If there is such a directory, you can directly exit the cycle, and it will be considered that this category has been downloaded
n = 0
for y in range(1,15): #Suppose each category has 14 pages ppt(The number of pages has been searched for a long time, but we can't find all the ways to get them. We can only take this measure.)
pagesUrl = url+i['href']+'/ppt_'+classUrl+'_'+str(y)+'.html'
a = requests.get(pagesUrl,headers=headers)
if a.status_code != 404: #Exclude pages with status code 404
soup2 = BeautifulSoup(a.text,'lxml')
for downppt in soup2.find('ul',class_='tplist').select('li > a'): #Get the URL
b = requests.get(url+downppt['href'],headers=headers)
b.encoding = b.apparent_encoding #Set encoding type
soup3 = BeautifulSoup(b.text,'lxml')
downList = soup3.find('ul',class_='downurllist').select('a') #Get Download PPT Of URL
pptName = soup3.select('h1') #ppt Template name
print('Downloading......')
try:
urllib.request.urlretrieve(downList[0]['href'],r'D:\PPT\\'+i['title']+'/'+pptName[0].get_text()+'.rar') #Start downloading template
print(i['title']+'type template download completed the '+str(n)+' few.'+pptName[0].get_text())
n += 1
except:
print(i['title']+'type download failed the '+str(n)+' few.')
n += 1
if __name__ == '__main__':
headers = {'user-agent':UserAgent().random} #Define request header
getPPT('http://www.1ppt.com')
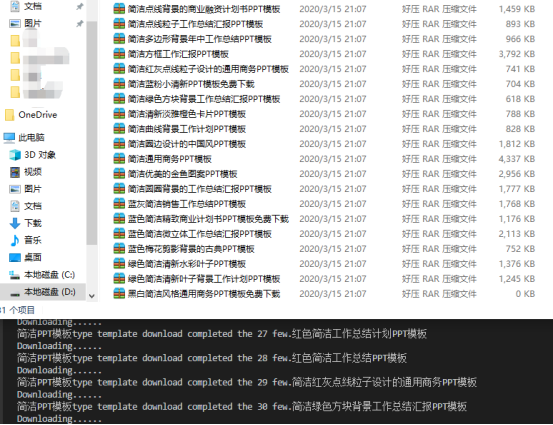
Design sketch:
In fact, the logic is quite simple, and the code is not complicated.
There are basically comments on the code. Let's go through the logic together first. The logic is clear. There's nothing wrong with the code.
1. First, the homepage of the website: F12 - > select a category (such as technology template), right click - > check - > view the html code on the right
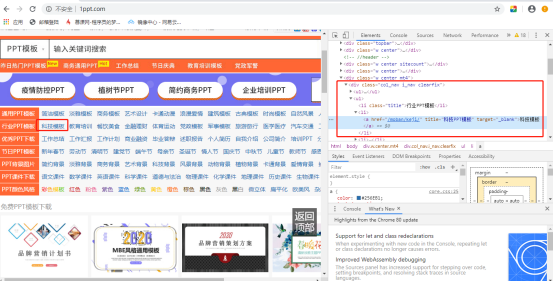
The URL of the discovery category is saved in the value of the href attribute of the < a > tag in the < li > tag under < div class = "col < NAV" I < NAV Clearfix >
So I thought of using the find() and select() methods of the beautifulsop library
2. Enter category interface
Similarly: F12 - > select a PPT (for example, the first one) right click - > check - > view the html code on the right
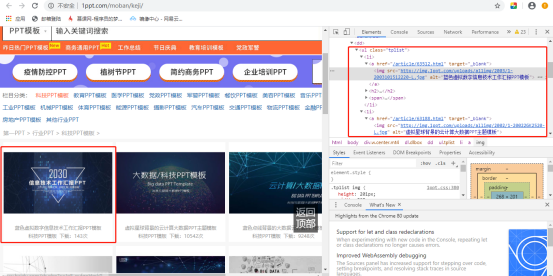
Continue to obtain the URL to enter the download interface according to the gourd ladle. The method is the same as above
However, on this page, please note that there are tabs below:
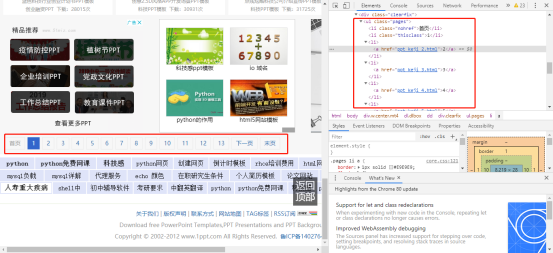
I have no idea how many pages there are in total, so I choose the range() function in this code to assume that each category has 14 pages, and then make a further judgment to see whether the returned http status code is 200.
3. Enter the download interface of specific PPT
Get the download URL of the final PPT as above
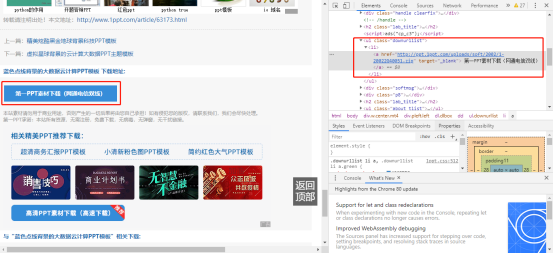
In this code, I choose to use urlib library to download, and finally put the corresponding category of PPT in the same folder.
I call the os library for folder operation. I'd better turn up the specific code.
The specific process is just a few steps, and the rest is recycling
Once the loop is written, it's done! Work together.