New year's Day is coming. Let's not talk about it. I'd like to give you a new year's Eve
Recently, the IOS students next to me asked for leave to stay at home. Hey, hey, I was left alone in the corner shivering. Although the air conditioner of the company was turned on to 28 ℃, it still couldn't melt my cold heart
Here you may ask, are there only two people in your company?
Ha ha ha ha, there are many people, but I can't get into the conversation about Chanel and Ferrari.
Idle, a lonely Internet to see the girls dancing. In a twinkling of an eye, an hour's long time has been like the sand in my hand. It has been quietly lost, but loneliness, like a maggot of tarsal bone, still lingers around me stubbornly.
What shall I do? It's impossible to be lonely. Only by writing BUG, ahhh, and code can you maintain your life like this.
Today, let's talk about Python downloading videos
Downloading video is nothing more than file I/O.
Three steps for python to download the video file: get the video url, request the link to get the video stream, write it to the local file for saving
Write a demo first:
import requests print("Start downloading") url = 'https://vdept.bdstatic.com/65796c493957364e51574e65504b757a/474c6d4464633277/37715aae880a70427da12d5d682d3a534b3947470869ecc29530cc310a944c1ac684c3ab83e07d18f65784748120987a.mp4?auth_key=1578908333-0-0-a70ed19862afa01935265e5a32906867' r = requests.get(url, stream=True) with open('test.mp4', "wb") as mp4: for chunk in r.iter_content(chunk_size=1024 * 1024): if chunk: mp4.write(chunk) print("Download end")
Click Run and wait for a while
Then click to open the saved mp4 file, you can enjoy watching the little sister dance.
(of course, this code also applies to most colored websites)
Oh, I'm a genius
Just as I was about to empty station B, I found that the video link of station B was either copied to 403, or different from ordinary people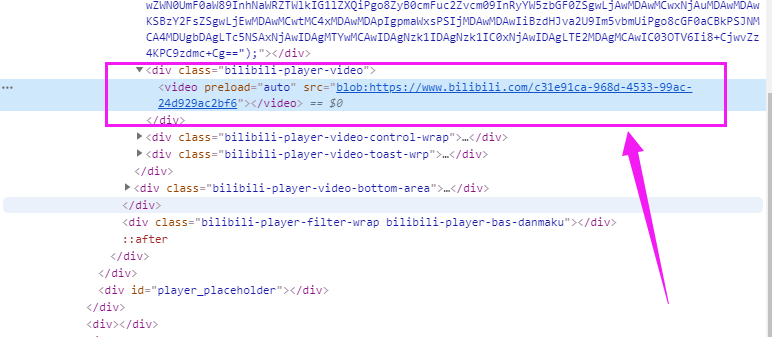
I'm surprised. Something must be wrong at this time.
Copy this link for a visit. Oh, it's not so easy
Why is this? Is station B involved in the spy? I quickly opened Tencent video, iqiyi looked at it, and found that this situation existed.
Finally, we found that the blob in front of the link appeared a little bit. google made a circle and concluded that the Blob URL / Object URL is a pseudo protocol, allowing blob and File objects to be used as URL sources for images, downloading binary data links, etc. In production scenarios, the blob format is often used to process the m3u8 address of sliced video. In fact, it is not for encryption, because the browser will still parse the blob and get the corresponding m3u8 address. The advantage of using blob uri is that it can interfere with the crawler at a certain level.
In short, F12 can't get the real address of the video directly

There are three steps for python to download the video file. The first step is stuck. At this time, I found that a thing called you get seems to be very popular among netizens. I checked its git address with the idea of "Hello everyone is really good". Oh, there are many star s
Read the document of you get with a try and find it's simple and appalling
Step 1: install you get, command: PIP3 install you get. Under normal circumstances, it is already installed. In case of special circumstances, please refer to the official document: https://github.com/soimort/you-get/wiki/%E4%B8%AD%E6%96%87%E8%AF%B4%E6%98%8E
It's also very simple to use. Take the dancing video of the little sister in station B as an example:
Link: https://www.bilibilili.com/video/av82238119? Spm_id_from = 333.5. B e63655f73746172.3
The page looks like this: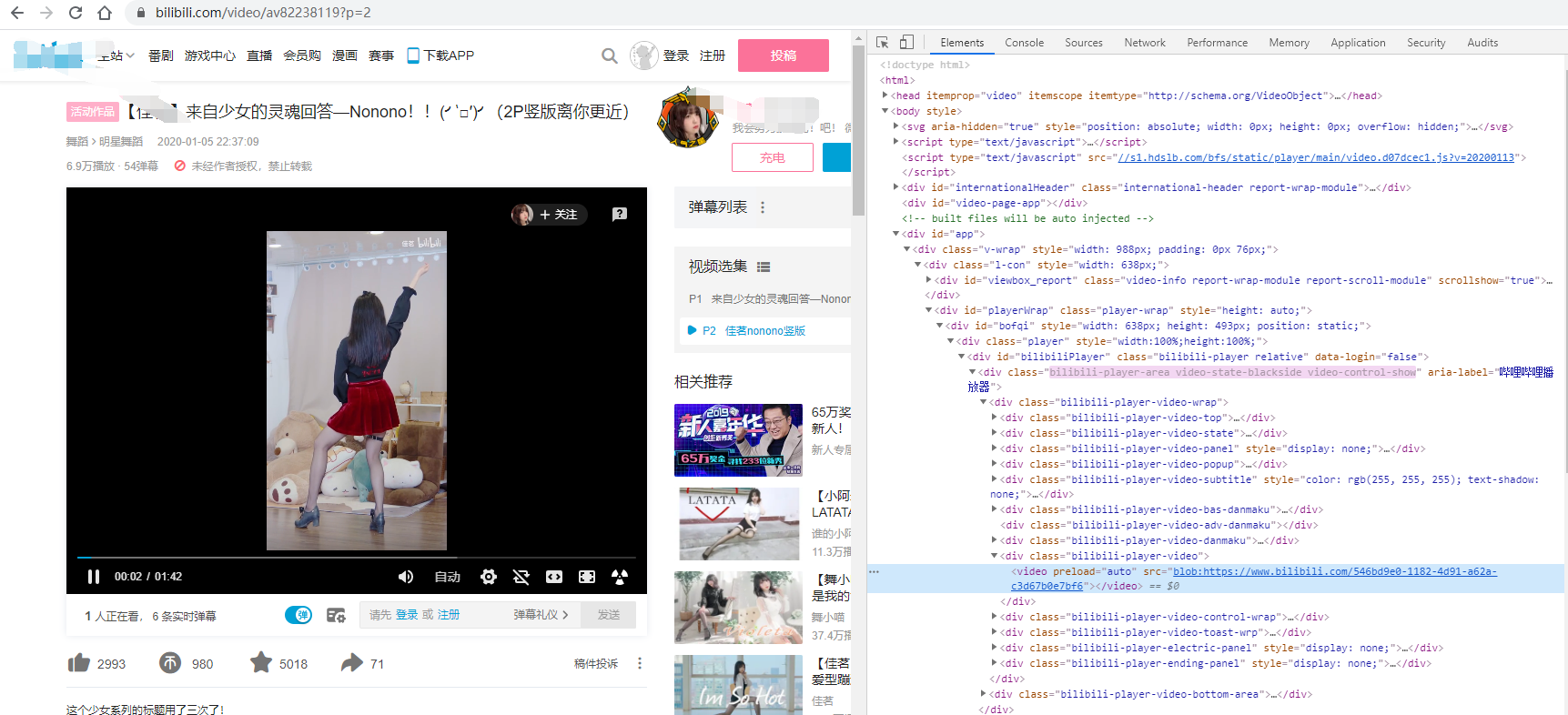
To save this dance video, just type the command from the python command line:
you-get -o D:\python\video https://www.bilibili.com/video/av82238119?spm_id_from=333.5.b_64616e63655f73746172.3
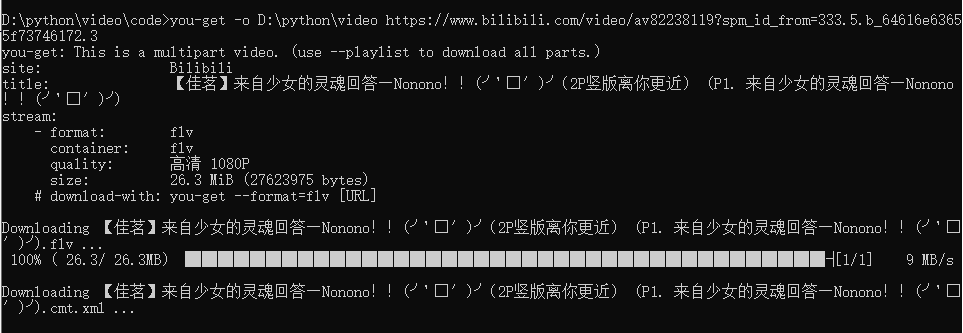
Wait for the progress bar to finish, and you can find your little sister in the directory D:\python\video, even the barrage has not been released (the xml file saves the video barrage, and the other is the video file)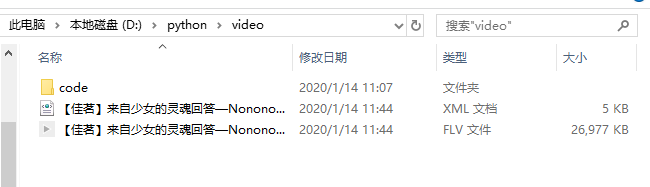
Of course, you can also save it in your hidden folder or learning materials directory
Of course, this semi-automatic way will not be able to meet my vigorous energy. In this way, what year and what month will I get if I empty station B.
Think about it. Write a python file. So the question is, how to call you get in Python file?
Example:
from you_get import common common.any_download(url='https://www.bilibili.com/video/av82238119?spm_id_from=333.5.b_64616e63655f73746172.3',info_only=False,output_dir=r'D:\python\video',merge=True)
Let's have a trial run. Hehehehehehe, it's actually running. The next thing will be easy to do. For example, I want the video of little sister dancing in station B. the example steps are as follows:
Step 1: find the dance part url of station B
Part 2: get the page and parse the url of each video page
Part 3: get video with you get
I can only see that I have finished the first edition in one go with the momentum of running the clouds and running the water, fishing for the moon and the moon
Run it. Oh, nothing
After some debugging, it is found that the video list of station B is loaded asynchronously through the interface. You can see it when you open F12, or copy the path of Xpath, but you can't get the data when you directly request the page. The interface is as follows. The return data format is json, and the arcurl is the url of the video playing page we need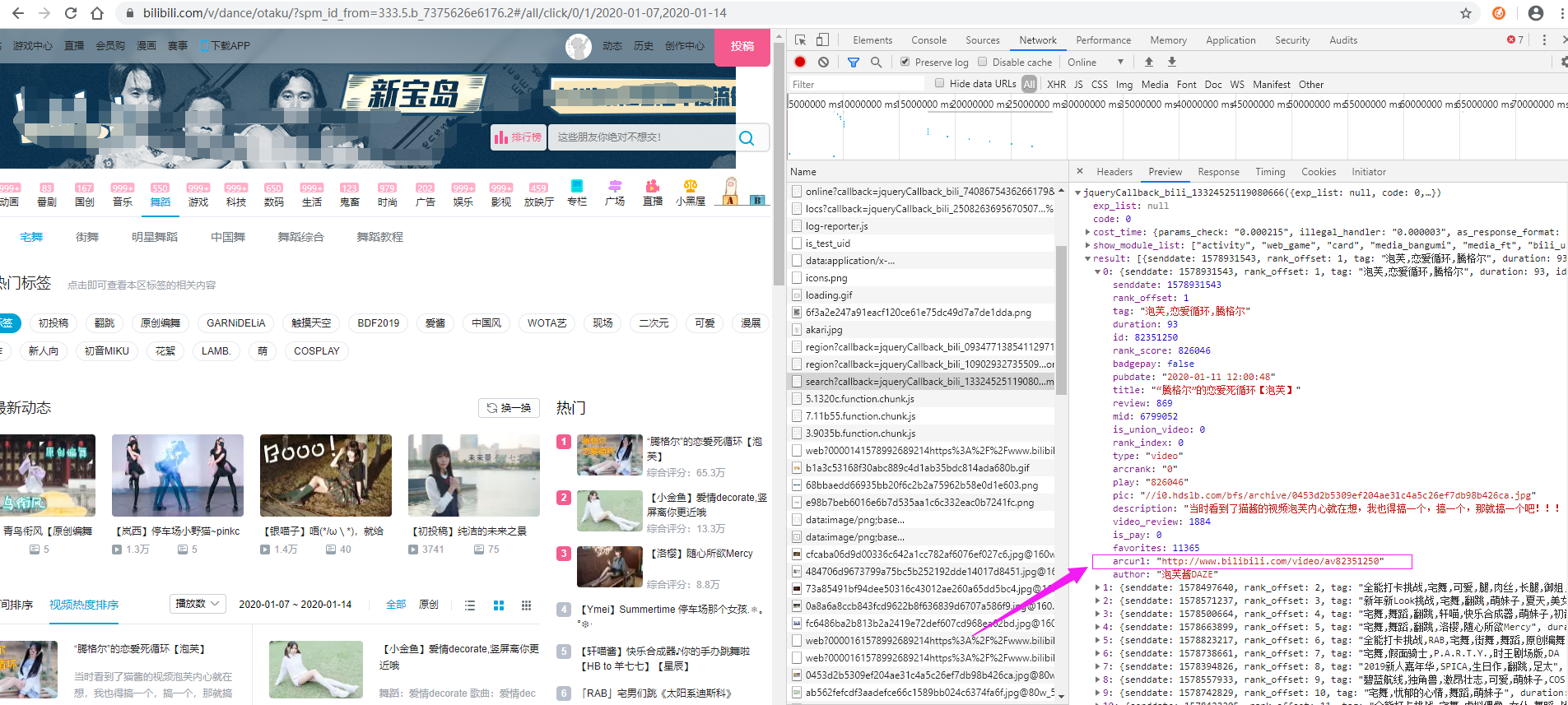
After understanding these, it's easy to do. First, try the house dance. Take down the dance on the first page of the video heat row and enjoy it. The code is as follows:
import requests import random import json from you_get import common #Common request agents header_list = [ {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"}, {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3676.400 QQBrowser/10.4.3469.400"}, {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36"}, {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362"} ] # Main function if __name__ == "__main__": base_url = 'https://s.search.bilibili.com/cate/search?main_ver=v3&search_type=video&view_type=hot_rank&order=click©_right=-1&cate_id=20&page=1&pagesize=20&jsonp=jsonp&time_from=20200107&time_to=20200114&_=1578992689153' headers = random.choice(header_list) # Get page information response = requests.get(url=base_url, headers=headers) # Get request status code code = response.status_code if code == 200: urls_json = json.loads(response.content) for i in urls_json['result']: print(i['arcurl']) common.any_download(url=i['arcurl'],info_only=False,output_dir=r'D:\python\video',merge=True) print('the end!')
Run the file and get the following results: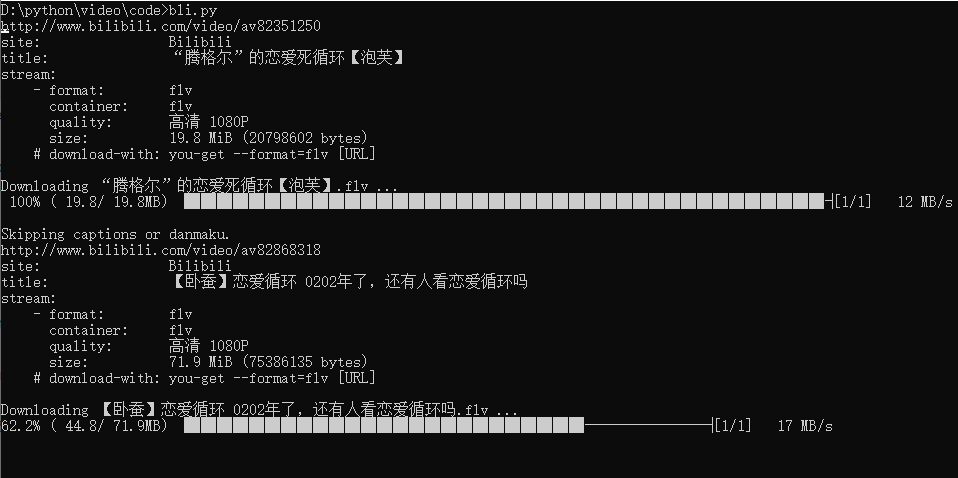
Open the save directory to see: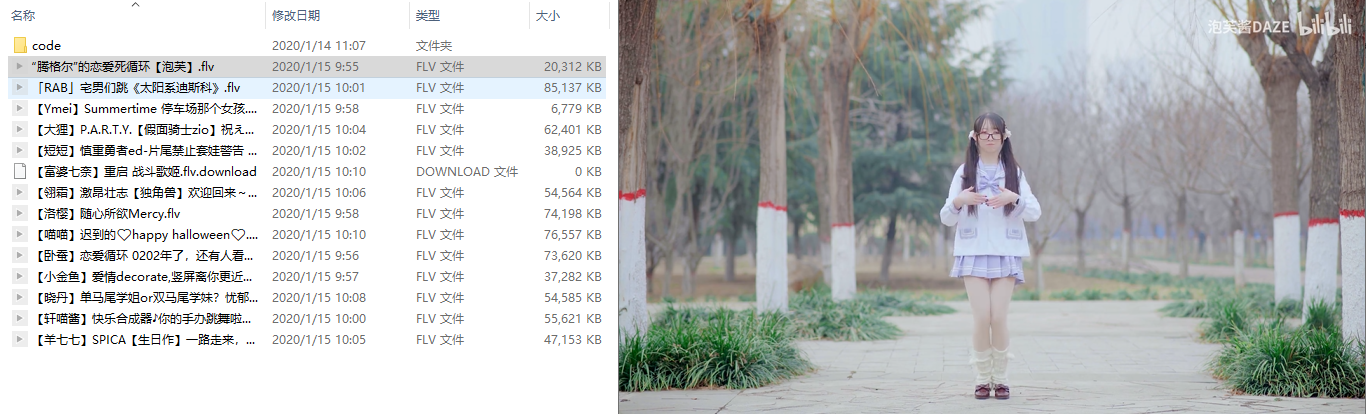
Yo, who can stand it
In line with the principle that one page of house dance can be done, it can be hollowed out. Analyze and analyze the interface rules, and simply package several methods:
import queue import requests import re import random import time import os import json from you_get import common #Common request agents header_list = [ {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"}, {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3676.400 QQBrowser/10.4.3469.400"}, {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36"}, {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362"} ] #Get video page url def get_urls(base_url,start_page_num,queue): while True: #Generate request agent information headers = random.choice(header_list) #Assembly interface url page_url = base_url + str(start_page_num) # Get page information response = requests.get(url=page_url, headers=headers) # Get request status code code = response.status_code if code == 200: urls_json = json.loads(response.content) if urls_json['result']: for i in urls_json['result']: queue.put(i['arcurl']) print(i['arcurl']) else: break start_page_num += 1 print('Get url done!') #Download and save the video def get_vedio(save_dir,queue): while not queue.empty(): #Take a break. I don't know what will happen too soon #time_num = 5 #time.sleep(time_num) # The get method of the Queue is used to extract elements from the Queue vedio_page_url = queue.get() queue.task_done() common.any_download(url=vedio_page_url,info_only=False,output_dir=save_dir,merge=True) # Main function if __name__ == "__main__": # Novel chapter base address base_url = 'https://s.search.bilibili.com/cate/search?main_ver=v3&search_type=video&view_type=hot_rank&order=click©_right=-1&cate_id=20&pagesize=20&jsonp=jsonp&time_from=20200107&time_to=20200114&_=1578992689153&page=' #Starting from page start_page_num = 1 #Please write the directory in quotation marks. The first r cannot be omitted save_dir = r'D:\python\video' # Using Queue to construct a FIFO Queue video_urls_queue = queue.Queue() #Get video page url get_urls(base_url,start_page_num,video_urls_queue) #Download and save the video get_vedio(save_dir,video_urls_queue) print('the end!')
Looking at his "learning file disk" is filled slowly, showing a dirty and handsome smile....
I thought to myself, it's just the same for the people in station B
Ha-ha
The end!
People's biggest rivals are often not others, but their own laziness.
Don't expect to be lucky. Luck can't always be on you. You need to be able to eat at any time.
You have to do your best to be qualified to say that you are unlucky.

