python multitasking process
1, First demo
- Process: after a program runs, the resource used by code + is called process, which is the basic unit of non allocated resources of the operating system. Multitasking completed by threads, processes can also
- Process in python uses process in multiprocessing module to define usage.
- give an example:
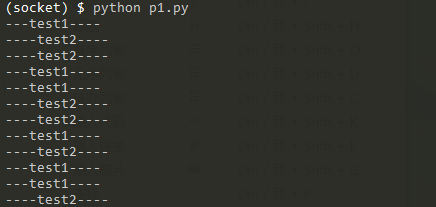
Operation result:"""Multitasking process""" import multiprocessing import time def test1(): while True: print('---test1----') time.sleep(1) def test2(): while True: print('----test2----') time.sleep(1) def main(): """process""" p1 = multiprocessing.Process(target=test1) p2 = multiprocessing.Process(target=test2) p1.start() p2.start() if __name__ == '__main__': main()
2, Queue
Process Queue: (decoupling low coupling) (complete data sharing)- Import: from multiprocessing import Queue
- Create and specify the maximum storage quantity: q = Queue(X) X: the maximum storage quantity
- Put data: q.put() get data: q.get() get() if it is empty, it will block put () if it is full
- Judge whether it is full: q.full() (true when it is full) judge whether it is empty: q.empty() (true when it is empty) return value is true: full / empty
- If there is no data, this q.get_nowait() throws an exception
- Any data type
Simulate downloading things on the Internet
"""Multitask --process --Queue Queue inter process data sharing""" import multiprocessing from multiprocessing import Queue def download_form_web(q): """Simulate downloading from a website""" data = [11, 22, 33, 44] # Write data to queue for temp in data: q.put(temp) # Output a successful write prompt print("----Downloader has finished downloading and data has been written to the queue----") def analysis_data(q): """Read data from queue""" waitting = list() # Read data from queue while True: data = q.get() waitting.append(data) # If it is empty, exit empty: true when it is empty if q.empty(): break print(waitting) def main(): """Queue Queue, interprocess communication""" # 1. Create a queue without writing parameters, and allocate space according to the hardware of the computer q = Queue() # 2. Create multiple processes to pass queues in as arguments p1 = multiprocessing.Process(target=download_form_web, args=(q, )) p2 = multiprocessing.Process(target=analysis_data, args=(q, )) # Start process p1.start() p2.start() if __name__ == "__main__": main()
3, Process Pool
-
When there are not many subprocesses to be created, you can directly use the Process in multiprocessing to dynamically generate multiple processes. If there are hundreds or even thousands of goals, the workload of manually creating a Process is huge, then you can use the Pool method provided by multiprocessing module.
-
When initializing the Pool, you can specify a maximum number of processes. When a new request is submitted to the Pool, if the process Pool is not full, a new process will be created to execute the request. If the process Pool is full, you need to wait until there are processes in the process Pool to finish, and then the previous process will be used to execute the new task.
-
Initialize process pool: Pool(x):x is the maximum number of processes
-
Create and call the target function: zpply_ Async (target function to be called, (parameter tuple passed to target,))
-
join(): wait for all processes in the process pool to execute (to be placed after close())
-
close(): close process pool – > process pool will not accept new requests
-
os.getpid(): view process number
-
example:
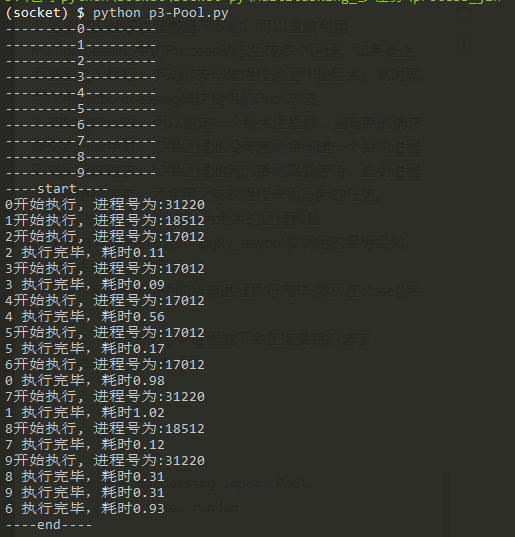
"""Process pool""" from multiprocessing import Pool import os, time, random def worker(msg): """Process pool work""" t_start = time.time() print("%s Start execution, The process number is:%d" % (msg, os.getpid())) # random.random() randomly generate floating-point numbers between 0-1 time.sleep(random.random()*2) t_stop = time.time() print(msg, "It takes time to execute%0.2f" % (t_stop - t_start)) def main(): po = Pool(3) # Define a process pool with a maximum of 3 processes for i in range(0,10): print(f"---------{i}---------") # Pool().apply_ Async (the target function to call, (the parameter tuple passed to the target,)) # Each cycle will call the target with the idle sub process po.apply_async(worker,(i, )) print("----start----") po.close() # Shut down the process pool. po will not accept new requests after shutting down po.join() # Wait for the execution of all subprocesses in po to complete, which must be placed after the close statement print("----end----") if __name__ == "__main__": main()
Implementation results:
4, Case: file copying
-
Use process pool to complete basic functions
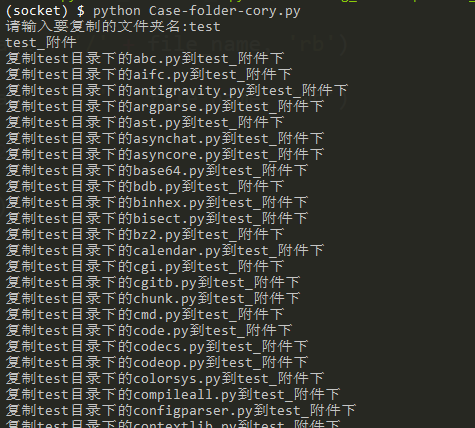
"""Multi process case -- Folder copy""" import os import multiprocessing def copy_folder(file_name, old_folder_name, new_folder_name): """Copy file""" print("copy%s Under the catalog%s reach%s lower" % (old_folder_name, file_name, new_folder_name)) # read file old_file = open(old_folder_name + '/' + file_name, 'rb') count = old_file.read() old_file.close() # Writing documents new_file = open(new_folder_name + '/' + file_name, 'wb') new_file.write(count) new_file.close() def main(): """Replication of multi process folder""" # Get the name of the folder to copy old_folder_name = input("Please enter the name of the folder to copy:") # New folder name + create new_folder_name = old_folder_name + "_enclosure" print(new_folder_name) try: # Exception if created os.mkdir(new_folder_name) except: pass # Get files in folder os.listdir() file_names = os.listdir(old_folder_name) # Copy file # Create process pool po = multiprocessing.Pool() for file_name in file_names: # Add task to process pool po.apply_async(copy_folder,args=(file_name, old_folder_name, new_folder_name)) po.close() po.join() if __name__ == "__main__": main()
Operation results:
-
Add progress bar using Queue queue communication
"""Multi process case -- Folder copy -- Queue Queue communication progress bar""" import os import multiprocessing def copy_folder(q, file_name, old_folder_name, new_folder_name): """Copy file""" # print("copy% s in% s directory to% s"% (old_folder_name, file_name, new_folder_name)) # read file old_file = open(old_folder_name + '/' + file_name, 'rb') # Write file new_file = open(new_folder_name + '/' + file_name, 'wb') while True: count = old_file.read(1024) if count: new_file.write(count) else: break old_file.close() new_file.close() # Write and send the message to the queue q.put(file_name) def main(): """Replication of multiprocess folders""" # Get the name of the folder to copy old_folder_name = input("Please enter the name of the folder to copy:") # New folder name + create new_folder_name = old_folder_name + "_enclosure" # print(new_folder_name) try: # If it has been created, an exception will occur os.mkdir(new_folder_name) except: pass # Get files in folder os.listdir() file_names = os.listdir(old_folder_name) # Copy file # Create queue q = multiprocessing.Manager().Queue() # Create process pool po = multiprocessing.Pool() for file_name in file_names: # Add tasks to the process pool po.apply_async(copy_folder,args=(q, file_name, old_folder_name, new_folder_name)) po.close() # po.join() # Total files file_num = len(file_names) file_num_ok = 0 # Show progress while True: file_name_ok = q.get() # Print (% s file has been copied)% file_name_ok) file_num_ok +=1 print("\r Progress of copy completion:%.2f %%" % (file_num_ok*100 / file_num), end="") if file_num_ok >= file_num: break if __name__ == "__main__": main()
Operation result:

5, Summary
The difference between process and thread: Different definitions:- Process is an independent unit of resource allocation and scheduling in the system
- Thread is an entity in the process and the basic unit of cpu scheduling and dispatching
- There must be a thread in a process
- A program has at least one process, and a process has at least one thread
- The dividing scale of threads is smaller than that of processes (less resources than processes), which makes the concurrent surname of multithreaded programs higher
- In the process of process execution, there are independent memory units, and multi threads share memory, which greatly improves the efficiency of the program
- Threads cannot run alone and must exist in the process