Chapter 7: Document Operation
- In order to save data for long-term reuse, modification and sharing, data must be stored in the form of files in external storage media (such as disk, U disk, CD or cloud disk, mesh disk, fast disk, etc.).
- Document manipulation plays an important role in the development and application of various application software.
Management information system uses database to store data, and the database is ultimately stored on disk or other storage media in the form of files.
Application configuration information is often stored in files. Graphics, images, audio, video, executable files and so on are also stored on disk in the form of files. - According to the organizational form of data in files, files are divided into binary files and text files.
Text files: Text files store regular strings, consisting of several text lines, usually ending with a newline character' n'. Conventional strings refer to strings that can be displayed, edited properly by Notepad or other text editors and can be read and understood directly by human beings, such as English letters, Chinese characters and digital strings. Text files can be edited by word processing software such as gedit and notepad.
_Binary file: Binary file stores object content as ** bytes ** and can not be edited directly by Notepad or other common word processing software. It can not be read and understood directly by human beings. It needs special software to read, display, modify or execute after decoding. Common image files, audio and video files, executable files, resource files, various database files, all kinds of Office documents are binary files. - File Content Operation Trilogy: Open, Read, Write, Close
open(file,mode = 'r',buffering = -1,encoding = None,errors = None,newline = None,closefd = True,opener = None)
The file name specifies the name of the file to be opened.
Open mode specifies how to handle files after they are opened.
_Buffers specify the cache mode for read-write, read-write, and write files. 0 denotes no cache, 1 denotes cache, and greater than 1 denotes the size of buffer. The default value is the cache mode.
Parameter encoding specifies the way to encode and decode text. It only applies to text mode. It can use any format supported by Python, such as GBK, utf8, CP936 and so on. - If the execution is normal, the open() function returns an iterative file object through which the file can be read and written. An exception is thrown if the specified file does not exist, access rights are insufficient, disk space is insufficient, or other reasons cause the creation of the file object to fail.
- The following code opens two files by reading and writing, and creates corresponding file objects.
f1 = open('file1.txt','r')
f2 = open('file2.txt','w') - When the file content operation is completed, the file object must be closed so as to ensure that any changes made are actually saved in the file.
f1.close() - It should be noted that even if you write the code to close the file, you can not guarantee that the file will be closed properly. For example, if an error occurs after opening the file and before closing the file, causing the program to crash, the file will not close properly. This problem can be effectively avoided by recommending the use of with keywords when managing file objects.
- When reading and writing the contents of a file, the use of the with statement is as follows:
with open(filename,mode,encoding) as fp:
# Write a statement here that reads and writes the contents of a file through the file object fp - In addition, the context management statement with supports the following usage, which further simplifies the coding.
with open('test.txt','r') as src,open('test_new.txt','w') as dst:
dst.write(src.read())
7.1 File Basic Operation
-
File Opening Mode

-
Common attributes of file objects

-
Common methods of file object
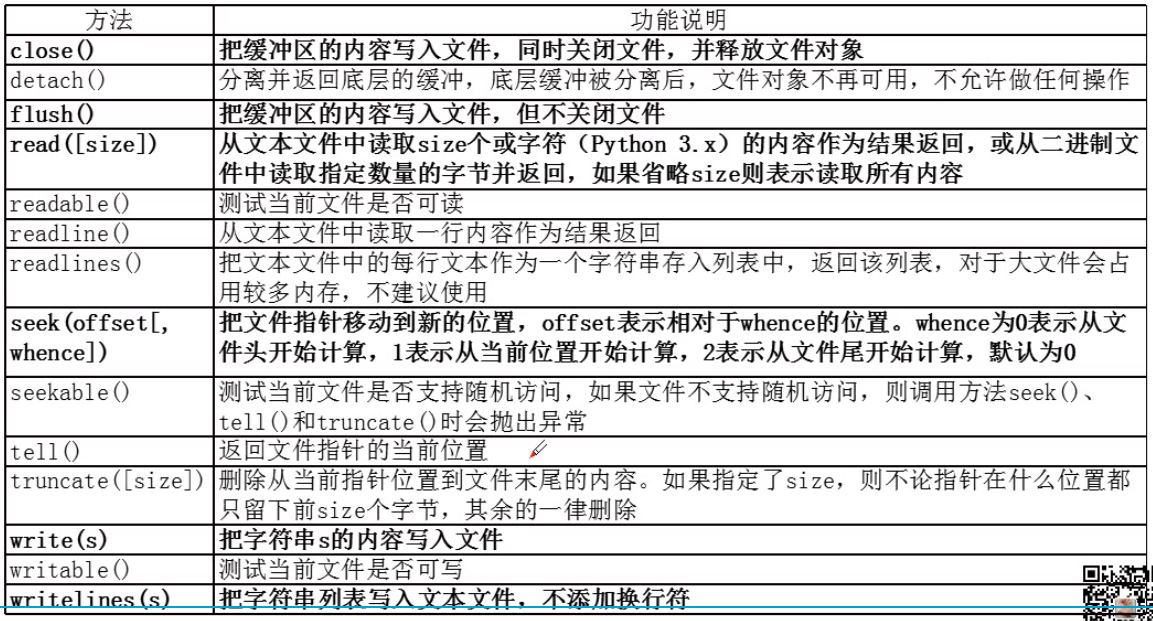
7.2 Selection of Text Document Operation Cases
Example 7-1 writes content to a text file and reads it out.
>>> s = 'Hello world\n Reading Method of Text File\n Writing Method of Text File\n'
>>> with open('sample.txt','w') as fp: #Default cp936 encoding
... fp.write(s)
...
32
>>> with open('sample.txt') as fp: #Default cp936 encoding
... print(fp.read())
...
Hello world
//Reading Method of Text File
//Writing Method of Text File
Example 7-4 Move the file pointer.
_Python 2.x and Python 3.x have the same understanding and processing of the seek() method, which locates the file pointer to the specified byte of the file. However, due to the different degree of support for Chinese, it may lead to different results in Python 2.x and Python 3.x. For example, the following code runs in Python 3. X and throws an exception when encountering characters that cannot be decoded.
>>> s = 'Yantai, Shandong Province, China SDIBT' >>> fp = open(r'D:\sample.txt','w') >>> fp.write(s) 11 >>> fp.close() >>> fp = open(r'D:\sample.txt','r') >>> print(fp.read(3)) //China Mountain >>> fp.seek(2) #Mobile pointer 2 >>> print(fp.read(1)) //country >>> fp.seek(13) 13 >>> print(fp.read(1)) D >>> fp.seek(3) 3 >>> print(fp.read(1)) Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeDecodeError: 'gbk' codec can't decode byte 0xfa in position 0: illegal multibyte sequence
# Python 2.x is in bytes, and Python 3.x is in characters.
Example 7.2 reads all integers in the text file data.txt (one integer per line in the file), sorts them in ascending order, and then writes them into the text file data_asc.txt.
with open('data.txt','r') as fp:
data = fp.readlines()
data = [int(line.strip()) for line in data]
data.sort()
data = [str(i) + '\n' for i in data]
with open('data_asc.txt','w') as fp:
fp.writelines(data)
Selection of 7.3 Binary File Operation Cases
- Database files, image files, executable files, audio and video files, Office documents and so on belong to binary files.
- Only by correctly understanding the structure and serialization rules of binary files can we accurately understand the content of binary files and design correct deserialization rules.
- The serialized form of the object should be able to restore to the original object accurately and correctly after the correct reverse sequence process.
- The common serialization modules in Python are struct, pickle, Marshal and shelve.
>>> import pickle
>>>
>>> i = 13000000
>>> a = 99.056
>>> s = 'Chinese people 123 abc'
>>> lst = [[1,2,3],[4,5,6],[7,8,9]]
>>> tu = (-5,10,8)
>>> coll = {4,5,6}
>>> dic = {'a':'apple','b':'banana','g':'grape','o':'orange'}
>>> data = [i,a,s,lst,tu,coll,dic]
>>>
>>> with open('sample_pickle.dat','wb') as f:
... try:
... pickle.dump(len(data),f) #Represents the number of data to be written later
... for item in data:
... pickle.dump(item,f)
... except:
... print('Write file exception!') #If the write file is abnormal, jump here to execute
Example 7.9 reads binary files.
>>> import pickle
>>>
>>> i = 13000000
>>> a = 99.056
"> s = 123abc of the Chinese people"
>>> lst = [[1,2,3],[4,5,6],[7,8,9]]
>>> tu = (-5,10,8)
>>> coll = {4,5,6}
>>> dic = {'a':'apple','b':'banana','g':'grape','o':'orange'}
>>> data = [i,a,s,lst,tu,coll,dic]
>>>
>>> with open('sample_pickle.dat','wb') as f:
... try:
... pickle.dump(len(data),f) indicates the number of data to be written later
... for item in data:
... pickle.dump(item,f)
... except:
print('Write file exception! ') # If the file is written abnormally, jump to execute it here. ___________
...
>>> import pickle
>>> with open('sample_pickle.dat','rb') as f:
... n = pickle.load(f) Number of data read out of files
... for i in range(n):
... x = pickle.load(f)
... print(x)
...
13000000
99.056
Chinese People 123abc
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
(-5, 10, 8)
{4, 5, 6}
{'a': 'apple', 'b': 'banana', 'g': 'grape', 'o': 'orange'}
Example 7-10 uses struct module to write binary files.
>>> n = 1300000000
>>> x = 96.45
>>> b = True
>>> s = 'a1@China'
>>> sn = struct.pack('if?',n,x,b) #serialize
>>> f = open('sample_struct.dat','wb')
>>> f.write(sn)
9
>>> f.write(s.encode()) #Strings are encoded directly into byte strings for writing
9
>>> f.close()
>>>>
>>> import struck
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ModuleNotFoundError: No module named 'struck'
>>> import struct
>>> f = open('sample_struct.dat','rb')
>>> sn = f.read(9)
>>> tu = struct.unpack('if?',sn)
>>> print(tu)
(1300000000, 96.44999694824219, True)
>>> n,x,bl = tu
>>> print('n = ',n)
n = 1300000000
>>> print('x = ',x)
x = 96.44999694824219
>>> print('bl = ',bl)
bl = True
>>> s = f.read(9).decode()
>>> f.close()
>>> print('s = ',s)
s = a1@China
7.3.3 Use shell serialization
>>> import shelve
>>> zhangsan = {'age':38,'Sex':'Male','address':'SXLF'}
>>> lisi = {'age':40,'sex':'Male','qq':'1234567','tel':'7654321'}
>>> with shelve.open('shelve_test.dat') as fp:
... fp['zhangsan'] = zhangsan #Write data into a file in the form of a dictionary
... fp['lisi'] = lisi
... for i in range(5):
... fp[str(i)] = str(i)
...
>>> with shelve.open('shelve_test.dat') as fp:
... print(fp['zhangsan'])
... print(fp['zhangsan']['age'])
... print(fp['lisi']['qq'])
... print(fp['3'])
...
{'age': 38, 'Sex': 'Male', 'address': 'SXLF'}
38
1234567
3
7.3.4 Using marshal serialization
Python standard library marshal can also serialize and deserialize objects.
>>> import marshal #Import module
>>> x1 = 30
>>> x2 = 5.0
>>> x3 = [1,2,3]
>>> x4 = (4,5,6)
>>> x5 = {'a':1,'b':2,'c':3}
>>> x6 = {7,8,9}
>>> x = [eval('x'+str(i)) for i in range(1,7)]
>>> x
[30, 5.0, [1, 2, 3], (4, 5, 6), {'a': 1, 'b': 2, 'c': 3}, {8, 9, 7}]
>>> with open('test.dat','wb') as fp:
... marshal.dump(len(x),fp) #Number of objects written first
... for item in x:
... marshal.dump(item,fp)
...
5
5
9
20
17
26
20
>>> with open('test.dat','rb') as fp: #Open the binary file
... n = marshal.load(fp) #Get the number of objects
... for i in range(n):
... print(marshal.load(fp)) #Deserialization, output results
...
30
5.0
[1, 2, 3]
(4, 5, 6)
{'a': 1, 'b': 2, 'c': 3}
{8, 9, 7}