Preface
The main function of index is to restrict and speed up the search. The ORM framework (sqlalchemy) uses classes and objects to operate the database.
Types of indexes
By category
1. General index: can speed up search
2. Primary key index: can speed up search, cannot be empty, cannot be duplicate
3. Unique index: accelerated search, can be empty, can't be duplicate
4. Joint index (multiple columns):
(1) union primary key index
(2) joint unique index
③ joint general index
Divide by data structure
1.hash index: hash index. Create an index table, convert the data (the 'name' used below) into hash values, put the hash values into the table, and add the storage address of the data. The order in the index table is not necessarily the same as the data in the data table, because the order in the index table is out of order. If you look for values in a range in the data table, the efficiency is not necessarily high, but if you only look for single values, it will find the results quickly.
2.btree index (commonly used): that is, binary tree index and binary tree index. It creates the btree index in the innodb engine. The efficiency of finding value in the range is high.
Accelerated search of index
Create a table first
create table dataset( id int not null auto_increment primary key, name varchar(32), data int, )engine = innodb default charset = utf8;
Create another stored procedure. When we execute the stored procedure, insert 10w data into the table.
delimiter // create procedure inserdatapro() begin declare i int default 1; -- Define a counter i declare t_name varchar(16); -- Temporary name variable declare t_data int; -- Temporary data variable while i <= 100000 do -- If i Less than 10 W Do the following set t_name = CONCAT('aaa',i); -- Give Way'aaa'and i Connect to string'aaa1','aaa2'...Form set t_data = CEIL(RAND()*100); -- Generate a 0-100 Random number insert into dataset(name,data) values(t_name,t_data); -- take t_name,t_data insert dataset within set i = i + 1; -- take i add one-tenth end while; -- End cycle end // delimiter ;
It will take a certain time to execute the stored procedure and insert data into the table. The performance of the computer also needs to be considered.
call inserdatapro();
Compare the execution speed of the two statements:
select * from dataset where name = 'aaa94021';
select * from dataset where id = 94021;
Result:
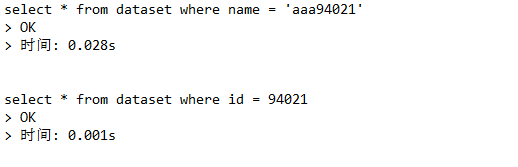
Through comparison, we can see that it is faster to use index (id) to search data. For example, the first query method has no index, so it has to search the results one by one, so we can create another index to search data.
create index nindex on dataset(name); -- create index of name
Then execute the first query statement:

It can be seen that the efficiency has been greatly improved.
Find by:
1. no index
Search from front to back
2. index
It creates a data structure or extra files, which are stored in a certain format. So its search method will query the location of the data in the table from the index file.
Query is fast, but insert is slower than delete
When we use index to find data, we need to hit the index, for example:
select * from dataset where name like 'aaa94021';
Index related operations:
1. General index
Create table
create table t( nid int not null auto_increment primary key, name varchar(32), data int, index index_name(name) )
② create index
create index index_name on t(name);
③ delete index
drop index index_name on t;
④ view index
show index from t;
2. Unique index
Create table
create table t2( id int not null auto_increment primary key, name varchar(32) not null, data int, unique index_name(name) )
② create a unique index
create unique index index_name on t2(name);
③ delete unique index
drop unique index index_name on t2;
3. Primary key index
Create table
-- Write a way create table t3( id int not null auto_increment primary key, name varchar(32) not null, int data, index index_name(name) ) -- Writing two craete table t4( id int not null auto_increment, name varchar(32) not null, int data, primary key(id), index index_name(name) )
② create primary key
alter table t3 add primary key(id);
③ delete primary key
alter table t3 modify id int,drop primary key; alter table t3 drop primary key;
4. Joint index
Create table
create table mtable( id int not null auto_increment, name varchar(32) not null, data int, primary key(id,name) )engine=innodb default charset=utf8;
② create union index
create index index_id_name on mtable(id,name);