Python Implementation of Naive Bayesian Classification (NBC)
Introduction to Bayesian Classification
Bayesian classification is based on Bayesian theorem, which was invented by Thomas Bayes, an early researcher of probability theory and decision theory in the 18th century. Therefore, it is named Bayesian theorem. Bayesian classification method based on Bayesian theory is a reasoning method with minimum error rate and minimum risk. Uncertainty is often expressed by Bayesian probability, which is a subjective probability.
Formula: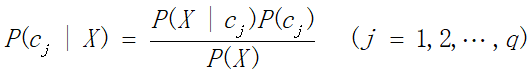
P(Cj|x): The probability of occurrence of event Cj under condition x;
P(x|Cj): The probability of being in condition x when an event Cj occurs;
P(Cj): The probability of occurrence of event Cj;
P(x): The probability of condition X.
naive bayesian classification
One of the most practical Bayesian learning methods is Naive Bayesian Classification.
Naive Bayesian classification is a very simple classification algorithm. Naive Bayesian classification is called Naive Bayesian classification because the idea of this method is really simple. Naive Bayesian thought is based on the following: for the given items to be classified, to solve the probability of each category appearing under this condition, which category is the largest, it is considered to belong to which category.
Naive Bayesian premise
Class conditional independence hypothesis: the attributes that make up the database must be independent of each other for the value of a given class, that is to say, the value of any attribute does not depend on other attributes.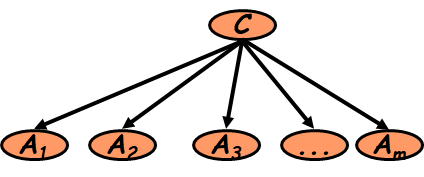
formula
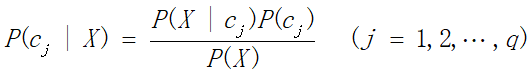
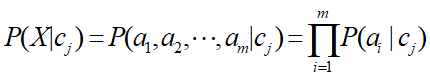
programming
Reading Data from Excel
'''
//Read Excel data
//Input: File name
//Output: Data List, Data Name
'''
def excel_table_byindex(file,colnameindex=0,by_index=0):
data = xlrd.open_workbook(file)#Getting Excel data
table = data.sheet_by_index(by_index)#Use sheet_by_name to get sheet object data with sheet page name called user table
colnames= table.row_values(colnameindex)#Get all the data values of the first row in the first row Excel, with the row number subscript 0
nrows = table.nrows #Get all the valid rows
list_table = []#The general idea is that data in Excel exists in the form of a dictionary in the string as a list element.
for rownum in range(1,nrows):
row =table.row_values(rownum)#Get the data values for each row of all rows
if row:
app= {}#Mainly with {name':'zhangsan','password': 12324.0}, as for the number of elements in the dictionary mainly depends on how many columns.
for i in range(0,len(colnames)):#In this Excel, the row in which the column is located has two data, so without looping a row, the two data are used as keys, and the value of the number of rows is the value of the key, which is stored in a dictionary.
app [colnames[i]] = row[i]
list_table.append(app)
return list_table,colnames
Calculating the probability of event Cj occurrence
'''
//Decomposing data
//Input: data list, data name, number of predicted variables
//Output: Conditional Variable Matrix, Decision Variable Matrix, Conditional Variable Name, Decision Variable Name, Data Matrix
'''
def sample_matrix(list_table,colnames,diction_num=1):#Number of diction_num decision variables
diction_name=colnames[-diction_num:len(colnames)]
condition_name=colnames[0:-diction_num]
list_decision=[]
for i in range(0,len(list_table)):
list_decision.append(list(list_table[i].values()))
matrix=np.array(list_decision)
matrix_decision=matrix[:,-diction_num:len(colnames)]
matrix_condition=matrix[:,0:-diction_num]
return matrix_condition,matrix_decision,condition_name,diction_name,matrix
'''
//Decomposing data
//Input: Data Matrix, Decision Variable Matrix, Decision Variable Name
//Output: Dictionary of Decision Variables, List of Decision Classifications
'''
def possible_weight(matrix,matrix_decision,diction_name):
M,N=np.shape(matrix_decision)
dic_decision={}
list_classify_dec=[]
for i in range(M):
a=''
for j in range(N):
if type(matrix_decision[i][j])==np.str_: #All capitals
matrix_decision[i][j]=matrix_decision[i][j].upper()
a=a+(diction_name[j])+'='+matrix_decision[i][j]+','
b=list(dic_decision)#Dictionaries
a_cla_new=list(matrix[i])
if a not in b:
dic_decision[a]=1
list_classify_dec.append([a_cla_new])
else:
c=b.index(a)
dic_decision[a]=dic_decision[a]+1
list_classify_dec[c].append(a_cla_new)
for i in dic_decision:
dic_decision[i]=dic_decision[i]/M
return dic_decision,list_classify_dec
Calculate the probability of each event under new conditions
'''
//Forecast
//Input: New data, list of decision classifications, name of conditional variables, Dictionary of decision variables
//Output: Probability
'''
def simple_predict(new,list_classify_dec,condition_name,dic_decision):
n=len(dic_decision)
p=np.ones([n,1])
dic=list(dic_decision.values())
for i in range(n):
for k in condition_name[1:]:
a=0
for j in range(len(list_classify_dec[i])):
if new[k] in list_classify_dec[i][j]:
a=a+1
a=a/len(list_classify_dec[i])
p[i]=p[i]*a
p[i]=p[i]*dic[i]%Multiplication
return p
Forecast
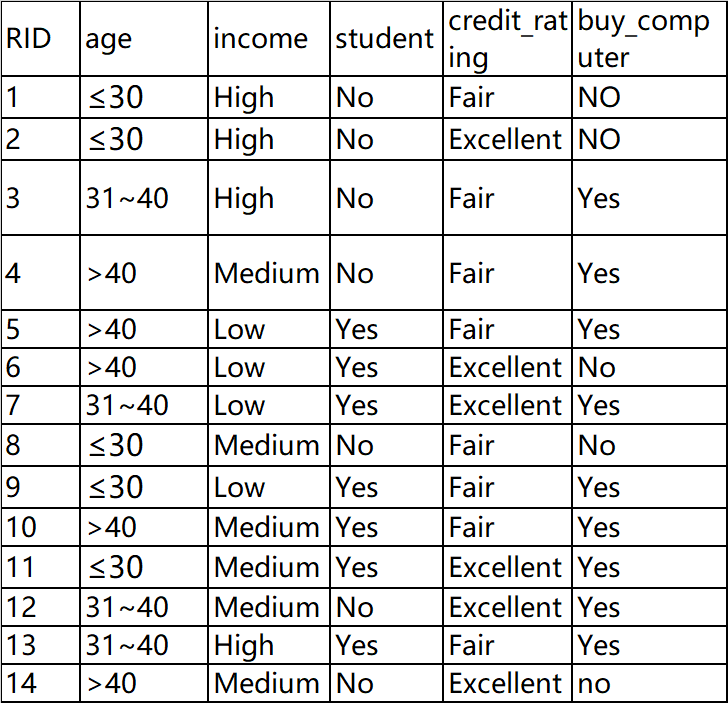
list_table,colnames=excel_table_byindex(r'D:\coures\Intelligent information\buyComputer_classify.xlsx')
matrix_condition,matrix_decision,condition_name,diction_name,matrix=sample_matrix(list_table,colnames)
dic_decision,list_classify_dec=possible_weight(matrix,matrix_decision,diction_name)
new={'age':'≤30','income':'Medium','student':'Yes','credit_rating':'Fair'}
p=simple_predict(new,list_classify_dec,condition_name,dic_decision)
p=p.tolist()
p_max=max(p)
p_index=p.index(p_max)
p_predict=list(dic_decision)[p_index]
print('Forecast results:'+p_predict+' Probability:'+str(p_max))
Operation result
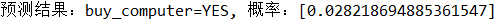
Data used
Master code
import xlrd import numpy as np ''' //Read Excel data //Input: File name //Output: Data List, Data Name ''' def excel_table_byindex(file,colnameindex=0,by_index=0): data = xlrd.open_workbook(file)#Getting Excel data table = data.sheet_by_index(by_index)#Use sheet_by_name to get sheet object data with sheet page name called user table colnames= table.row_values(colnameindex)#Get the number of rows subscripted to ___________0That's the first line. Excel All data values in the first row nrows = table.nrows #Get all the valid rows list_table = []#The general idea is that data in Excel exists in the form of a dictionary in the string as a list element. for rownum in range(1,nrows): row =table.row_values(rownum)#Get the data values for each row of all rows if row: app= {}#Mainly in{'name': 'zhangsan', 'password': 12324.0},How many elements are in a dictionary depends mainly on how many columns are there for i in range(0,len(colnames)):#In this Excel, the row in which the column is located has two data, so without looping a row, the two data are used as keys, and the value of the number of rows is the value of the key, which is stored in a dictionary. app [colnames[i]] = row[i] list_table.append(app) return list_table,colnames ''' //Decomposing data //Input: data list, data name, number of predicted variables //Output: Conditional Variable Matrix, Decision Variable Matrix, Conditional Variable Name, Decision Variable Name, Data Matrix ''' def sample_matrix(list_table,colnames,diction_num=1):#Number of diction_num decision variables diction_name=colnames[-diction_num:len(colnames)] condition_name=colnames[0:-diction_num] list_decision=[] for i in range(0,len(list_table)): list_decision.append(list(list_table[i].values())) matrix=np.array(list_decision) matrix_decision=matrix[:,-diction_num:len(colnames)] matrix_condition=matrix[:,0:-diction_num] return matrix_condition,matrix_decision,condition_name,diction_name,matrix ''' //Decomposing data //Input: Data Matrix, Decision Variable Matrix, Decision Variable Name //Output: Dictionary of Decision Variables, List of Decision Classifications ''' def possible_weight(matrix,matrix_decision,diction_name): M,N=np.shape(matrix_decision) dic_decision={} list_classify_dec=[] for i in range(M): a='' for j in range(N): if type(matrix_decision[i][j])==np.str_: #All capitals matrix_decision[i][j]=matrix_decision[i][j].upper() a=a+(diction_name[j])+'='+matrix_decision[i][j]+',' b=list(dic_decision)#Dictionaries a_cla_new=list(matrix[i]) if a not in b: dic_decision[a]=1 list_classify_dec.append([a_cla_new]) else: c=b.index(a) dic_decision[a]=dic_decision[a]+1 list_classify_dec[c].append(a_cla_new) for i in dic_decision: dic_decision[i]=dic_decision[i]/M return dic_decision,list_classify_dec ''' //Forecast //Input: New data, list of decision classifications, name of conditional variables, Dictionary of decision variables //Output: Probability ''' def simple_predict(new,list_classify_dec,condition_name,dic_decision): n=len(dic_decision) p=np.ones([n,1]) dic=list(dic_decision.values()) for i in range(n): for k in condition_name[1:]: #for k in range(1:m+1): a=0 for j in range(len(list_classify_dec[i])): if new[k] in list_classify_dec[i][j]: a=a+1 a=a/len(list_classify_dec[i]) p[i]=p[i]*a p[i]=p[i]*dic[i] return p list_table,colnames=excel_table_byindex(r'D:\coures\Intelligent information\buyComputer_classify.xlsx') matrix_condition,matrix_decision,condition_name,diction_name,matrix=sample_matrix(list_table,colnames) dic_decision,list_classify_dec=possible_weight(matrix,matrix_decision,diction_name) new={'age':'≤30','income':'Medium','student':'Yes','credit_rating':'Fair'} p=simple_predict(new,list_classify_dec,condition_name,dic_decision) p=p.tolist() p_max=max(p) p_index=p.index(p_max) p_predict=list(dic_decision)[p_index] print('Forecast results:'+p_predict+' Probability:'+str(p_max))