basic operation
File path
1: Splicing path
In windows and non Windows systems, the slash used for the path is different. Using os.path.join() can give the correct answer
import os
print(os.path.join('C', 'Program Files', 'Common Files'))
result:
C\Program Files\Common Files
There are three ways to the path:
(1) : use left slash [recommended, common to all platforms]
file = open('C:/Users/asuka/Desktop / new text document. txt ', encoding ='utf-8')
(2) : use escape characters
file = open('C:\Users\asuka\Desktop \ new text document. txt ', encoding ='utf-8')
(3) : use r to format characters
file = open(r'C:\Users\asuka\Desktop \ new text document. txt ', encoding ='utf-8')
2: Processing absolute and relative paths
- os.path.abspath() returns the absolute path of the parameter, which can be used to convert a relative path to an absolute path
- os.path.isabs(), return True if the path is absolute
- os.path.relpath(path,start) returns the relative path from start to path. If start is not written, the relative path from the current path to path is returned by default
import os
print(os.getcwd()) #View current working directory
print(os.path.abspath('.')) #Convert relative path to absolute path
print(os.path.isabs('.')) #Returns True if it is an absolute path
print(os.path.relpath('D:\\','D:\\pycharm\\02'))
result:
D:\pycharm\02
D:\pycharm\02
False
..\..
Separating pathnames and filenames
os.path.dirname(path) returns the contents before the last slash in the path parameter, that is, the directory name
os.path.basename(path) will return the content after the last slash in the path parameter, that is, the basic name

import os path = r'C:\Windows\System32\calc.exe' print(os.path.dirname(path)) #Get directory name print(os.path.basename(path)) #Get base name result: C:\Windows\System32 calc.exe
os.path.split() obtains the directory name and basic name of the path at the same time, and obtains a tuple composed of two strings
import os
path = r'C:\Windows\System32\calc.exe'
print(os.path.split(path))
result:
('C:\\Windows\\System32', 'calc.exe')
Separating file names and file suffixes
- OS. Path. Splittext() separates the file name from the extension
- os.path.split() returns the path and file name of the file
import os
path = r'C:\Users\asuka\Desktop\1.txt'
a = os.path.split(path) # Separating paths and files
print(a)
print(os.path.splitext(a[-1])) # Separate file names and suffixes
# result:
# ('C:\\Users\\asuka\\Desktop', '1.txt')
# ('1', '.txt')
A small example, change all png suffix files in a folder to jpg suffix
import os
path = r"C:\Users\asuka\Desktop\123"
os.chdir(path) # Modify work path
files = os.listdir(path)
print('Original file name:'+str(files)) # Print to see what files are in the above directory
# Use os.path.splittext to separate file names and suffixes
for filename in files:
fa = os.path.splitext(filename)
if fa[1] == ".png":
newname = fa[0] + ".jpg"
os.rename(filename, newname)
files = os.listdir(path)
print('Now file name:'+str(files)) # Print to see what files are in the above directory
Current working directory (os.getcwd, os.chdir)
If the working directory to be changed does not exist, python will report an error.
- print(os.getcwd()) # view the current working directory
- print(os.path.abspath('.') # view the current working directory
Details: the current working directory is a standard term. There is no current working folder
import os
print(os.getcwd()) #Get current working path
os.chdir('C:\\Program Files\\Common Files') #Change working directory
print(os.getcwd()) #Get current working path
result:
D:\pycharm\02
C:\Program Files\Common Files
Create a new folder (os.makedirs)
Create a folder using os.makedirs, and all necessary intermediate folders will be created to ensure that the full pathname exists.
import os print(os.path.exists(r'D:\Program Files\666')) #Prove that this path does not exist os.makedirs(r'D:\Program Files\666\777\888') print(os.path.exists(r'D:\Program Files\666')) #Prove that this path does not exist result: False True
View folder directory and file size (os.path.getsize, os.listdir)
- os.path.getsize(path) returns the number of bytes of the file in the path parameter.
- os.listdir(path) returns the contents of the folder in the path parameter
View file size
import os path = r'C:\Windows\System32\calc.exe' print(os.path.getsize(path)) #27648
View Folder Size
import os
totalSize = 0
for filename in os.listdir(r'D:\My documents'):
totalSize+=os.path.getsize(os.path.join(r'D:\My documents',filename))
print(totalSize) #144597950
View the contents of a folder
import os path = r'D:\iso' print(os.listdir(path)) result ['Cent7', 'kali-linux-2020.3-vmware-amd64', 'kali-linux-2020.3-vmware-amd64.zip', 'Metasploitable2-Linux', 'NGTOS-VM.7z', 'NG upgrade', 'ovf', 'vmware', 'win2008', 'win7', 'win7.zip', 'xp_sp3', 'history']
Path validity
- os.path.exists: returns True if the path exists (it can be a file or folder)
- os.path.isfile: returns True if the path exists and is a file
- os.path.isdir: returns True if the path exists and is a folder
import os print(os.path.exists(r'C:\Windows')) #Check if the path exists print(os.path.isfile(r'C:\Windows\System32\calc.exe')) #Check whether the file exists print(os.path.isdir(r'C:\Windows')) #Check if the folder exists result: True True True
Get desktop path
import os
desktop_path = os.path.join(os.path.expanduser("~"), 'Desktop')
print(desktop_path)
Of course, it will be more convenient to wrap the above code into a function GetDesktopPath() and call it when necessary
import os
def GetDesktopPath():
return os.path.join(os.path.expanduser("~"), 'Desktop')
File reading and writing
Plain text file: contains only basic text characters, not font, size and color information
Binary file: non plain text file, such as PDF, image, spreadsheet, executable program, etc
In python, there are three steps to read and write files:
- Call the open() function to return a File object (the File object represents a File in the computer, which is another type of value in python)
- Call the read() or write() method in the File object
- Call the close() method of the File object to close the File
read file
When python opens a file, the default is read mode. The following two codes are equivalent, but the latter indicates the use of read mode
open(r'C:\Users\asuka\Desktop\hello.txt ') and open(r'C:\Users\asuka\Desktop\hello.txt','r ')
Error: Unicode decodeerror: 'gbk' codec can't decode byte 0x8c in position 14: incomplete multibyte sequence
Most of the software we use usually uses utf8 encoding format when writing files, and it is ok to read files. However, the windows system uses gbk encoding format by default to read and write files, so there will be encoding problems when opening files using winodws system.
[if there is a problem with the prompt code, specify the code and modify the first line to
a =open(r'C:\Users\asuka\Desktop\hello.txt',encoding='utf-8')]
Use read() to return all text content
a = open(r'C:\Users\asuka\Desktop\hello.txt') print(a.read()) a.close() result: 68218 Oracle Data Integrator Denial of service attack variant 2 68219 Windows URI Handle named injection attack variant 2 68223 TCPDump print-bgp.c File remote integer underflow vulnerability 68224 Microsoft Windows IP Options Off-By-One 63528 Symantec Client Firewall SACK Attack 68223 Tcpdump BGP Dissector Integer Overflow
You can set the read length for read
file = open('C:/Users/asuka/Desktop/New text document.txt', encoding='utf-8')
print(file.read()) #Do you like me
file.close()
file = open('C:/Users/asuka/Desktop/New text document.txt', encoding='utf-8')
print(file.read(4)) #You like me?
file.close()
Use readline() to read by line
import os a = open(r'C:\Users\asuka\Desktop\hello.txt',encoding='utf-8') print(a.readline()) result: 68218 Oracle Data Integrator Denial of service attack variant 2
Use readlines() to add the contents of each line to the list
import os a = open(r'C:\Users\asuka\Desktop\hello.txt',encoding='utf-8') print(a.readlines()) # result; # ['68218 Oracle Data Integrator denial of service attack variant 2\n', '68219 Windows URI processing name injection attack variant 2 \ n', '68223 tcpdump print BGP. C file remote integer underflow vulnerability attack \ n', '68224 Microsoft Windows IP options off by one \ n', '63528 Symantec client firewall sack attack \ n', '68223 tcpdump BGP dissector integer overflow']
Use readlines() to read text files
with open(r'C:\Users\asuka\Desktop\1.txt', 'r', encoding='utf8') as file:
f = file.readlines()
for i in f:
i = i.replace('\n', '')
print(i)
result:
123
hello
nuclear energy
I
write file
Write files are divided into "write mode" and "add mode"
- "Write mode": overwrite the original content (empty the original content and write new content)
- "Add mode": add new content after the original content
If the filename passed to open() does not exist, the two modes create a new empty file. After reading and writing, the close() method is invoked before the file can be opened again.
When writing a file, you can only write string or binary data. Dictionaries, numbers, lists, etc. cannot be written directly to the file and need to be converted into string or binary data.
- Convert to string: repr/str, using json module
- Convert to binary: use pickle module
As follows: writing the list in this way will report an error
a = ['alice', 'bob', 'sinba'] file = open(r'C:\Users\asuka\Desktop\2.txt', 'w', encoding='utf8') file.write(a) file.close()
Write directly using write
"Write mode": first overwrite the content and close the file. Then read the content and close the file.
a = open(r'C:\Users\asuka\Desktop\hello.txt', 'w')
a.write('adale hello \n')
a.close()
b = open(r'C:\Users\asuka\Desktop\hello.txt')
print(b.read())
b.close()
result:
adale hello
"Add mode": first add content and close the file. Read the contents again and close the file.
a = open(r'C:\Users\asuka\Desktop\hello.txt', 'a')
a.write('adale someone like you')
a.close()
b = open(r'C:\Users\asuka\Desktop\hello.txt')
print(b.read())
b.close()
result:
adale hello
adale someone like you
Use writelines to write as a list
a = open(r'C:\Users\asuka\Desktop\hello.txt', 'w', encoding='utf-8') a.writelines(['123', 'abc', '***']) a.close()
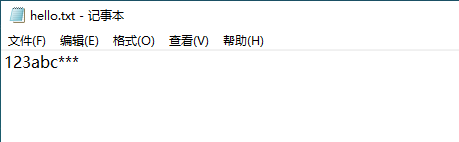
Use writelines to read a text file
import os
os.chdir(r'C:\Users\asuka\Desktop')
print(os.path.exists('noalert.txt'))
with open('noalert.txt', 'r', encoding='utf8') as f:
contents = f.readlines()
for i in contents:
i = i.replace('\n', '')
print(i)
other
# The following code is used to output the content in the terminal to a text
a = open(path_result, 'w', encoding='utf8')
for r in result:
a.write(r)
a.write('\n')
a.close()
perhaps
with open("data.txt",'a',newline='\n') as f:
f.write("Python is awsome")
open() method
The open() method is used to open a file and return the file object. This function is required during file processing. If the file cannot be opened, OSError will be thrown.
**Note: * * when using the open() method, you must ensure that the file object is closed, that is, call the close() method.
The common form of the open() function is to receive two parameters: file and mode.
open(file, mode='r')
The complete syntax format is:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
Parameter Description:
- File: required, file path (relative or absolute path).
- Mode: optional. The mode of file opening. The default is r, read-only mode
- Buffering: setting buffering
- Encoding: sets the encoding method used when opening a file. utf8 is generally used
- errors: error level
- newline: distinguish line breaks
- closefd: type of file parameter passed in
- Opener: set a custom opener. The return value of the opener must be an open file descriptor.
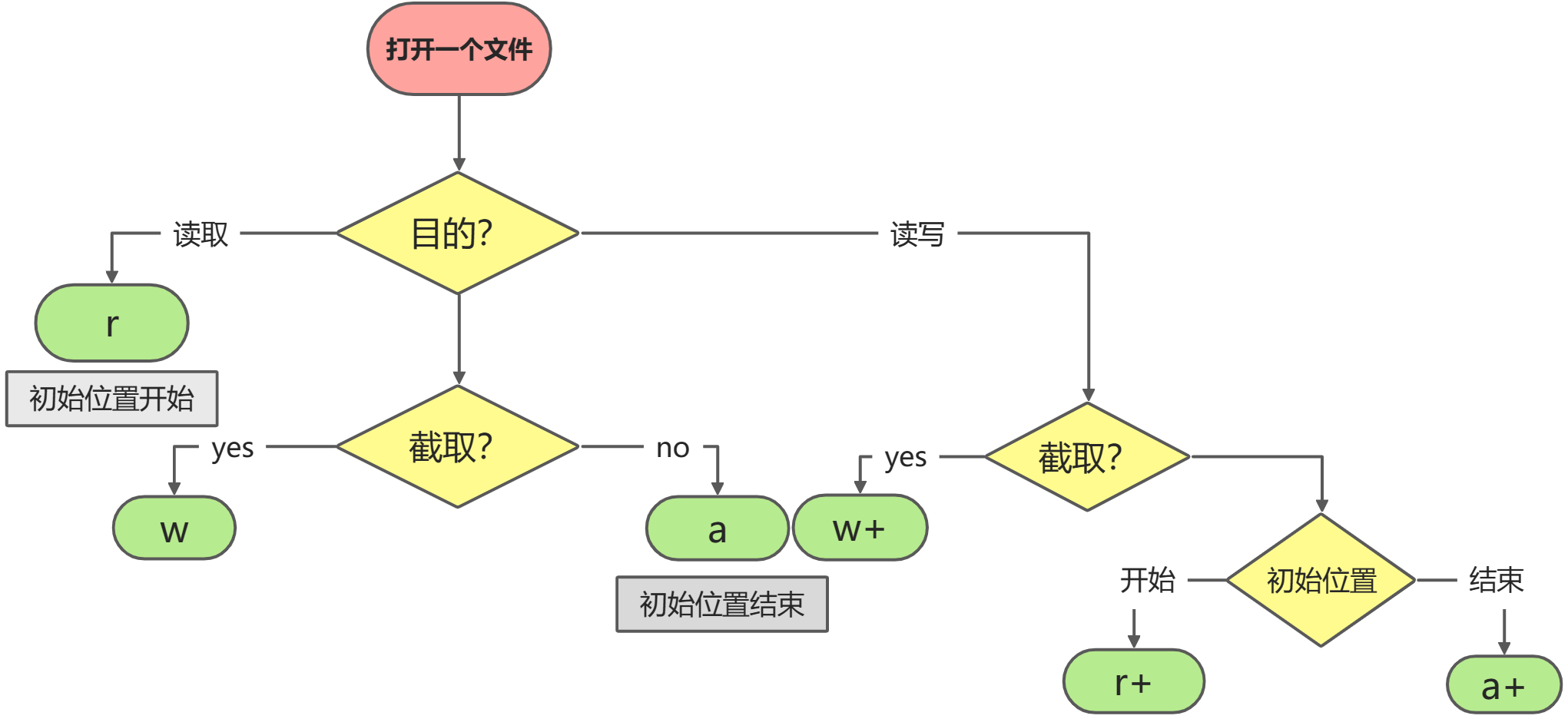
mode parameter
Common parameters [r, w, a is enough, other operations may cause pointer PROBLEMS]
- r: Read only, the file pointer will be placed at the beginning of the file
- w: Write only. If the file already exists, open the file and edit it from the beginning, that is, the original content will be deleted; If the file does not exist, create a new file
- a: Open a file for appending. If the file already exists, the file pointer will be placed at the end of the file; If the file does not exist, create a new file for writing
- rb: read only binary file, which is generally used for non text files, such as pictures
- wb: only binary files are written. It is generally used for non text files, such as pictures
- ab: open a file in binary format for appending
- w +: open a file for reading and writing
- r +: read / write (file is required)
- w +: read / write (file may not exist)
The mode parameters are:
| pattern | describe |
|---|---|
| t | Text mode (default). |
| x | In write mode, create a new file. If the file already exists, an error will be reported. |
| b | Binary mode. |
| + | Open a file for update (readable and writable). |
| U | General line feed mode (not supported by Python 3). |
| r | Open the file as read-only. The pointer to the file will be placed at the beginning of the file. This is the default mode. |
| rb | Open a file in binary format for read-only. The file pointer will be placed at the beginning of the file. This is the default mode. It is generally used for non text files, such as pictures. |
| r+ | Open a file for reading and writing. The file pointer will be placed at the beginning of the file. |
| rb+ | Open a file in binary format for reading and writing. The file pointer will be placed at the beginning of the file. It is generally used for non text files, such as pictures. |
| w | Open a file for writing only. If the file already exists, open the file and edit it from the beginning, that is, the original content will be deleted. If the file does not exist, create a new file. |
| wb | Open a file in binary format for writing only. If the file already exists, open the file and edit it from the beginning, that is, the original content will be deleted. If the file does not exist, create a new file. It is generally used for non text files, such as pictures. |
| w+ | Open a file for reading and writing. If the file already exists, open the file and edit it from the beginning, that is, the original content will be deleted. If the file does not exist, create a new file. |
| wb+ | Open a file in binary format for reading and writing. If the file already exists, open the file and edit it from the beginning, that is, the original content will be deleted. If the file does not exist, create a new file. It is generally used for non text files, such as pictures. |
| a | Open a file for append. If the file already exists, the file pointer will be placed at the end of the file. That is, the new content will be written after the existing content. If the file does not exist, create a new file for writing. |
| ab | Open a file in binary format for append. If the file already exists, the file pointer will be placed at the end of the file. That is, the new content will be written after the existing content. If the file does not exist, create a new file for writing. |
| a+ | Open a file for reading and writing. If the file already exists, the file pointer will be placed at the end of the file. The file is opened in append mode. If the file does not exist, create a new file for reading and writing. |
| ab+ | Open a file in binary format for append. If the file already exists, the file pointer will be placed at the end of the file. If the file does not exist, create a new file for reading and writing. |
The default is text mode. If you want to open it in binary mode, add b.
constitutive instrument
Using the shutil module
Copy files and folders
1: Copy the file shutil.copy
The file name of the source file is used by default. You can also specify a file name or even a suffix
>>> os.chdir('D:\\')
>>> shutil.copy(r'D:\picture\time.png',r'D:\iso') #Copy to a directory (the source file name is reserved by default)
'D:\\iso\\time.png'
>>> shutil.copy(r'D:\picture\time.png',r'D:\iso\time.png') #Copy to a directory and modify the file name of the new file
'D:\\iso\\time.png'
>>> shutil.copy(r'D:\picture\time.png',r'D:\iso\test.jpg') #Copy to a directory and modify the file name or even suffix of the new file
'D:\\iso\\test.jpg'
2: Copy the folder shutil.copytree
Copy all the picture folders and change the name of picture to picture_bak
>>> import shutil,os
>>> os.chdir('D:\\')
>>> shutil.copytree(r'D:\picture',r'D:\iso\picture_bak')
'D:\\iso\\picture_bak'
>>>
move files and folders
shutil.move(source,destination) moves all the files and folders at the path source to destination, and returns the string of the absolute path of the new location
1: Move files to destination folder
import shutil import os os.chdir(r'C:\Users\asuka\Desktop') shutil.copy(r'1\test.txt', r'2')
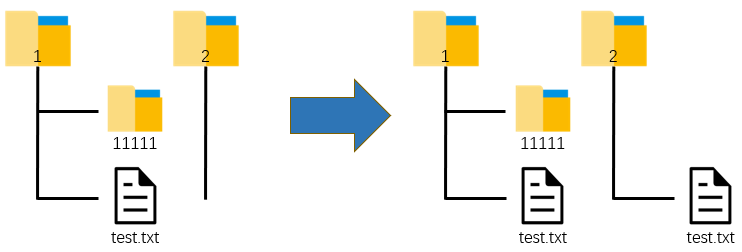
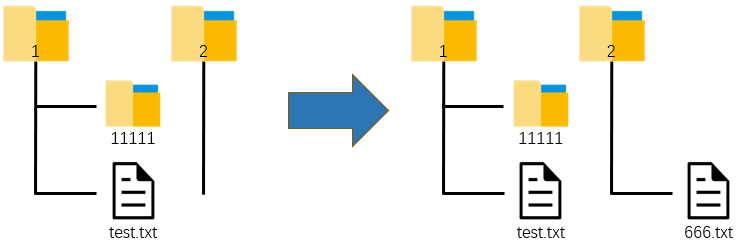
2: Move the file to the destination location and rename it.
import shutil import os os.chdir(r'C:\Users\asuka\Desktop') shutil.copy(r'1\test.txt', r'2\666.txt')
When you move a folder, the sub files and all the contents of the sub folder will be moved
import shutil
import os
os.chdir(r'C:\Users\asuka\Desktop')
shutil.copytree('1', '2\\666')
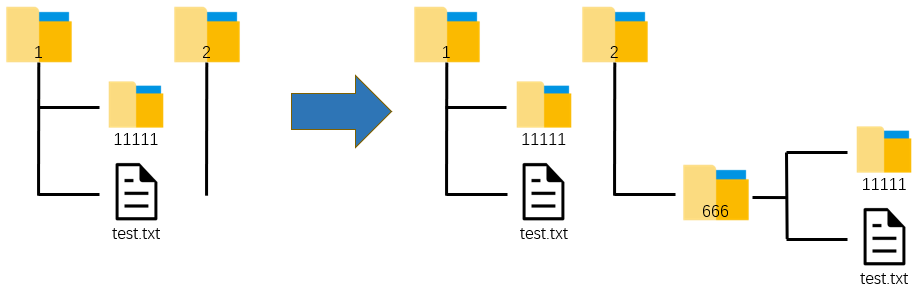
If there are files and folders with the same name in the target path, you need to modify the name in the moving folder, as follows, move 1.txt in D:\film to D:\demo, and rename it 2.txt. Otherwise, an error will be reported!
Note: in some python versions, if the names are duplicated, it seems that overwriting will occur when moving, so the move method should be used with caution
Delete files and folders
os module can delete a file or folder, but shutil can delete a folder and all its contents
Delete is to skip the recycle bin and remove it from the computer
- os.unlink(path): the file at path will be deleted
- os.rmdir(path): delete the folder at path. Folder must be empty
- shutil.rmtree(path): forcibly delete the folder at path and its attached contents
1: With the help of the for loop, delete a certain type of file under a file
(here, endswitch ('. txt') suggests to keep that. To prevent accidental deletion of files without suffix names.)
import os
os.chdir('D:\\film\\')
for filename in os.listdir('D:\\film\\'):
if filename.endswith('.txt'):
os.unlink(filename)
2: shutil.rmtree(path) is to delete the folder by root
import shutil
shutil.rmtree('D:\\demo')
Safe delete file (send2trash)
The tool is a third-party module and needs to manually download pip install send2trash.
Use send2trash(), which will throw the file into the trash can when deleting the file
import send2trash,os send2trash.send2trash(r'D:\photo')
Traversing the directory tree
The os.walk() parameter passes in the path of a folder. The directory tree is traversed by using os.walk() in the for loop. Traversal here refers to traversing all, not the outermost layer, as follows:
Split:
- Only the second for loop is reserved to print all folders in the current directory
- Only the third for loop is reserved to print all files in the current directory
import os
for current_folder, list_folders, files in os.walk(r'D:\iso\NG upgrade'):
print('Currently working in folder:' + current_folder)
for lf in list_folders:
print('Subfolders:'+current_folder+':'+lf)
for f in files:
print('File:'+current_folder+':'+f)
result:
Currently working in folder: D:\iso\NG upgrade
Subfolders: D:\iso\NG upgrade:history
File: D:\iso\NG upgrade:FeiQ.exe
File: D:\iso\NG upgrade:V3.2294.2027.1_ips_upt
Currently working in folder: D:\iso\NG upgrade\history
File: D:\iso\NG upgrade\history:V3.2294.2025.1_ips_B_upt
File: D:\iso\NG upgrade\history:V3.2294.2025.1_ips_upt
Rename folders, files
os.rename("file / folder", "new file name / new folder name")
import os
# Rename test1.xlsx to "my.xlsx"
os.rename("test1.xlsx","my.xlsx")
# Rename the "123" folder to the "abc" folder
os.rename("123","456")
Compressed file
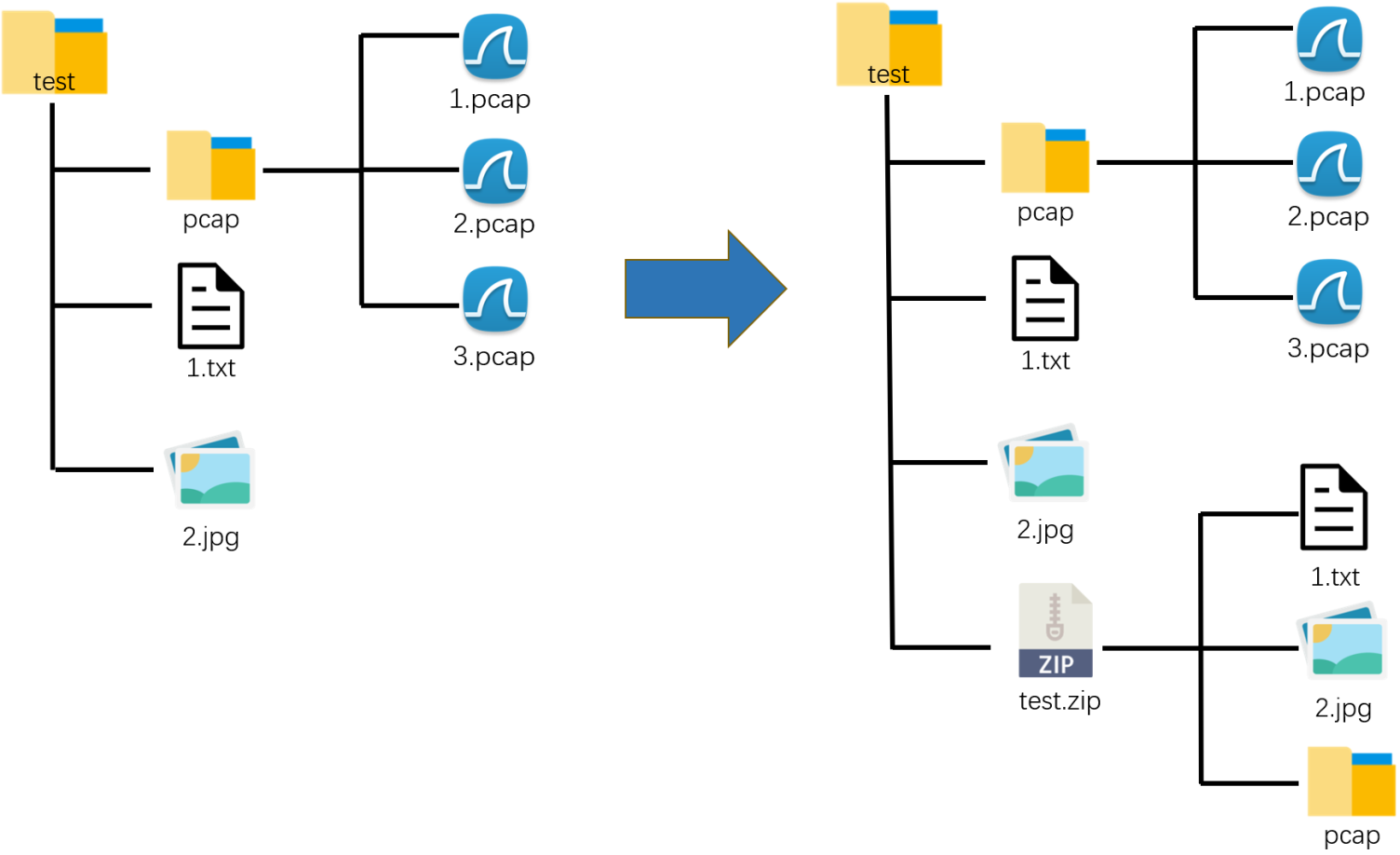
Use the following file directory

Read ZIP file
To read a zip file:
-
Call the zipfile.ZipFile() function to create a zipfile object [zipfile is the name of the python module, zipfile is the name of the function]
-
Use the namelist method to view all the files and folders in the zip file
-
The character information obtained in the previous step can be passed to the getinfo() method to return a ZipInfo object about a specific file.
This object has its own properties, such as file_ Size (indicates the size of the original file), compress_ Size (indicates the compressed size of the file)
ZipFile object represents the whole document, and ZipInfo object saves useful information of each file in the document file -
You can also calculate the compression ratio of files
import zipfile, os
os.chdir('D:\\') # Move to destination folder
testZip = zipfile.ZipFile('test.zip') # Call the zipfile.ZipFile() function to create a ZipFile object
print(testZip.namelist()) # View all files and folders in the zip file
info = testZip.getinfo('test/1.txt') #Get some information about this object
# Gets the size of the file before it is compressed
print(info.file_size)
# Gets the size of the compressed file
print(info.compress_size)
# Gets the compression ratio of the file
print('The compression ratio of the file is:{:.2f}%'.format((1 - (info.compress_size / info.file_size))*100))
# result
# ['test/', 'test/1.txt', 'test/2.jpg', 'test/pcap/', 'test/pcap/1.pcap', 'test/pcap/2.pcap', 'test/pcap/3.pcap']
# 26326980
# 169977
# The compression ratio of the file is 99.35%
Unzip file
Use the extractall() method to extract all the files from the ZIP file and put them into the current directory
- The following code will unzip test.zip to the folder named test in the current directory
- If a folder named test exists in the current directory, python will combine the extracted content with the content in test in one folder
- If there is no folder named test in the current directory, python will unzip it directly
- Only one layer can be decompressed, and the compressed package inside the compressed package cannot be decompressed
You can change the code in line 6 to testZip.extractall('123 '), that is, rename the folder from the decompression to avoid the problem of folder name duplication.
import zipfile, os
os.chdir('D:\\') # Move to destination folder
testZip = zipfile.ZipFile('test.zip') # Call the zipfile.ZipFile() function to create a ZipFile object
testZip.extractall()
testZip.close()
You can also use extract() to extract individual files
Create zip file
The file where it was created is located in D:\test\test.zip
[in the previous reading and decompression, I compressed test.zip manually, located in D:\test.zip. Don't worry about such details, just understand the operation]
Like writing a file, the write mode will erase the original contents of the ZIP file. If you want to add a new file to the original ZIP file, you need to open the ZIP file in the add mode and pass in the 'a' parameter
Write mode
- To create a zip file, you need to open the ZipFile object in write mode and pass in the 'w' parameter
- The first parameter of the write() method: the object to be compressed; The second parameter: compression algorithm
Compress a single file
import zipfile, os
os.chdir('D:\\test') # Move to destination folder
test = zipfile.ZipFile('test.zip','w') #Open the ZipFile object in write mode
test.write('1.txt',compress_type=zipfile.ZIP_DEFLATED)
test.close()
Drawing understanding:

Compress all files in the first tier of the folder
[only compress files, folders will not be compressed]
If you want to compress all the contents in the test folder, you need to use the for loop, as follows.
The pcap folder in test.zip is empty!!!
import zipfile, os
os.chdir('D:\\test') # Move to destination folder
current_folder = os.listdir() #Know all the outermost files and files in the current folder
test = zipfile.ZipFile('test.zip','w') #Open the ZipFile object in write mode
for cf in current_folder:
test.write(cf,compress_type=zipfile.ZIP_DEFLATED)
test.close()
Drawing understanding:
Add mode
Adding a pattern is to add 2.jpg after creating only 1.txt in test.zip
import zipfile, os
os.chdir('D:\\test') # Move to destination folder
test = zipfile.ZipFile('test.zip','w') #Open the ZipFile object in write mode
test.write('1.txt',compress_type=zipfile.ZIP_DEFLATED)
test.close()
os.chdir('D:\\test') # Move to destination folder
test = zipfile.ZipFile('test.zip','a') #Open the ZipFile object in add mode
test.write('2.jpg',compress_type=zipfile.ZIP_DEFLATED)
test.close()
Graphic understanding:

What if you add files in a folder? python creates an intermediate folder
import zipfile, os
os.chdir('D:\\test') # Move to destination folder
test = zipfile.ZipFile('test.zip','w') #Open the ZipFile object in write mode
test.write('1.txt',compress_type=zipfile.ZIP_DEFLATED)
test.close()
os.chdir('D:\\test') # Move to destination folder
test = zipfile.ZipFile('test.zip','a') #Open the ZipFile object in add mode
test.write('pcap\\1.pcap',compress_type=zipfile.ZIP_DEFLATED)
test.close()

Compress all files in the folder [a compression software was born]
In fact, it's OK to use the write mode, but I still think it's safer to add the mode
import zipfile, os
path = input(r'Please enter the compressed file path:') #Indicates the folder path to operate on
os.chdir(path) #Enter relevant path
for current_folder, list_folders, files in os.walk(path):
for f in files:
a = current_folder + '\\' + f
test = zipfile.ZipFile('test.zip', 'a') # Open the ZipFile object in add mode
test.write(a, compress_type=zipfile.ZIP_DEFLATED)
test.close()
print('Compression complete')

Crack the compressed package
See my previous article: python blasting ZIP file (support pure numbers, numbers + letters, and password book)