
preface
The text and pictures of this article are from the Internet, only for learning and communication, not for any commercial purpose. The copyright belongs to the original author. If you have any questions, please contact us in time for handling.
Project background
- Online PDF conversion tools are dazzling, difficult to choose, some even charge;
- The effect of opening PDF directly in other formats is generally poor;
- Some cute little people use copy and paste to operate, which wastes a lot of time.
So, is there any way to solve these problems in seconds? Yes, Python can. Don't talk too much, just practice.
Project operation
1, PDF to Text
First, install pdfplumber, the library for PDF operation. Pdfplumer can read PDF file content and extract tables in PDF well. This library does not belong to Python standard library and needs to be installed separately.
pip3 install pdfplumber
After installation, we import pdfplumber.
import pdfplumber
Open the PDF paper and extract the content of page 2 of the paper.
with pdfplumber.open("Industrial Development B Research on risk management of trust project.pdf") as p: page = p.pages[2] textdata = page.extract_text()
Print the textdata and extract the content on page 2 as follows:

At this point, you may be wondering, a master's thesis at least more than 50 pages. Yes, I downloaded 75 pages of this paper. I have to add a for loop to extract all the pages.
with pdfplumber.open("Industrial Development B Research on risk management of trust project.pdf") as p: for i in range(75): page = p.pages[i] textdata = page.extract_text() #print(textdata)
The content is extracted and then saved as text. "a" specifies that the write mode is append write. The complete code is as follows:
#PDF turn Text import pdfplumber with pdfplumber.open("Industrial Development B Research on risk management of trust project.pdf") as p: for i in range(75): page = p.pages[i] textdata = page.extract_text() #print(textdata) data = open("text.text", "a") data.write(textdata)
2, PDF to Word
You need to install Python docx, the library for Word operation.
pip3 install python-docx
Import the Document method.
from docx import Document
Open the PDF paper and extract the content of page 2 of the paper.
with pdfplumber.open("Industrial Development B Research on risk management of trust project.pdf") as p: page = p.pages[2] textdata = page.extract_text()
Create a new Word document and store the extracted content in it.
document = Document() #Create a new blank word file content = document.add_paragraph(textdata) #Add body paragraphs to the document, changing the textdata Lead in document.save("word.docx") #Save document docx,Named word
The complete code is as follows:
#PDF turn Word1import pdfplumber from docx import Document with pdfplumber.open("Industrial Development B Research on risk management of trust project.pdf") as p: page = p.pages[2] textdata = page.extract_text() #print(textdata) document = Document() #Create a new blank word file content = document.add_paragraph(textdata) #Add body paragraphs to the document, changing the textdata Lead in document.save("word.docx") #Save document docx,Named word
If you want to extract all, add a loop.
3, PDF to Excel
PDF to excel is not full-text to excel, but format conversion of some tables in the paper, which is convenient for data filtering, calculation and other operations in Excel.
Page 69-75 of the PDF paper of this case is the appendix part, which pastes the financial statement data and intercepts part of the content, as follows:
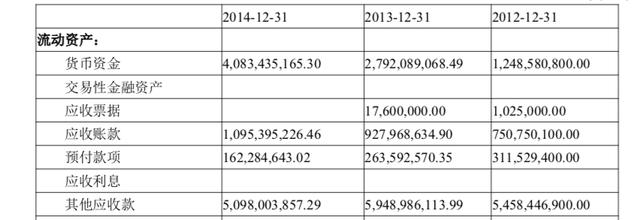
First, install and import openpyxl, a library for manipulating Excel tables.
pip3 install openpyxlfrom openpyxl import Workbook
Open the PDF paper, extract the table content on page 69-75 of the paper, and notice that the range is left open and right closed here.
with pdfplumber.open("Industrial Development B Research on risk management of trust project.pdf") as p: for i in range(68,75): #Traverse 69 pages-75 page page = p.pages[i] table = page.extract_table() #print(table)
Create a new blank Excel file, and write the table data content extracted from PDF by row. The complete code is as follows:
#PDF turn Excel import pdfplumber from openpyxl import Workbook with pdfplumber.open("Industrial Development B Research on risk management of trust project.pdf") as p: workbook = Workbook() #New blank Excel workbook sheet = workbook.active #activation sheet for i in range(68,75): #Traverse 69 pages-75 page page = p.pages[i] table = page.extract_table() #Extract table data #print(table) for row in table: #Traverse all rows #print(row) sheet.append(row) #Append write data by row workbook.save("Excel.xlsx") #Save file named Excel i += 1 print("The first%d page PDF Extraction complete"%i) #Prompt extraction progress
The final effect is as follows. It seems to be OK.
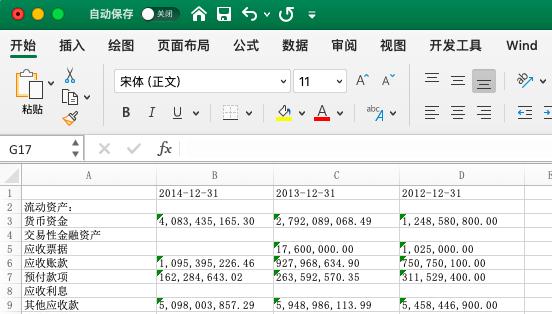
Conclusion
At this point, Python's simple operation on PDF paper is basically over. But there are still some problems worth exploring, such as what if there are 100 PDFs and the pages are not the same? Even if all the files are extracted, how to optimize the file format? How to merge multiple Excel tables extracted into one sheet? First of all, I'm sure to tell you that Python can solve all problems, and I will write related Python operations in the future.
Welcome to the top right corner to pay attention to the editor. In addition to sharing technical articles, there are many benefits. Private learning materials can be obtained, including but not limited to Python practice, PDF electronic documents, interview brochures, learning materials, etc.