Dictionaries
A dictionary is an unordered variable sequence of key value pairs. A key is any data that cannot be changed. A key cannot be repeated. Values are repeatable.
The definition of a typical Dictionary: {"name": "grace," age ": 18}
Dictionary creation:
- dict() and {}
Empty object: a = dict()
a = {}
b = dict(name="grace", age=18, job="student") print(b) c = dict([("name","grace"),("age",18)]) # There are two tuples in the list print(c)
- Create a dictionary object through dict(zip()) (zip can also be used to make the original list into a tuple in the list)
k = ["name", "age", "job"] v = ["grace", 18, "student"] a = dict(zip(k, v)) #Nature or two tuples in a list print(a)
- Create a dictionary with a null value through dict.fromkeys()
a = dict.fromkeys(["name", "age", "job"]) # Form of list required print(a)
Access to dictionary elements
- Get the value through the key, and throw an exception if the value does not exist
- Get "value" through get() method, recommended. Advantage: returns None when the specified key does not exist
- List all key value pairs a.items()
- List all keys, list all values a.keys() a.values()
- Number of len() key value pairs
- Check whether a key is in the dictionary
b = dict(name="grace", age=18, job="student") print(b["name"]) print(b.get("name")) print(b.get("gender")) print(b.get("gender", "Non-existent")) # Modify the default value of None to nonexistent print(b.items()) print(b.keys()) print(b.values()) print(len(b)) # b is in len() print("job" in b)
Dictionary element add modify delete
- Add key value pairs to the dictionary. If the key already exists, overwrite the old key. If the key does not exist, add a new key value pair.
a[""]=
a["address"] = "China" - Use update() to add all key value pairs in the new dictionary to the old dictionary object. If the key has duplicates, it will be overwritten directly
a = {}
b = {}
a.update(b) - For the deletion of elements in the dictionary, you can use del(a [""]), or a.clear() to delete all key value pairs, pop("") to delete the specified key value pairs, and return "value object" (b = a.pop(""))
- popitem() randomly deletes and returns the key value pair. The dictionary is an "unordered variable sequence", so there is no concept of the first and last element; popitem() pops up random items. If you want to remove and process items one by one, this method is very effective.
b = a.popitem()
b = dict(name="grace", age=18, job="student") b["address"] = "China" print(b) a = {"company":"sxt", "location":"Beijing", "job":"teacher"} b.update(a) # Update and overwrite b with the content of a, and modify b print(b) del(b["address"]) print(b) c = b.pop("company") print(c) # Return the key value sxt corresponding to company print(b) d = b.popitem() print(d) print(b) b.clear() print(b)
Sequence unpacking
Sequence unpacking can be used for tuples, lists, dictionaries. The unpacking sequence allows us to easily assign multiple quantities.
When sequence unpacking is used for dictionaries, the key is operated by default. If the key value is operated, the values() need to be used. If the key value pair is operated, the items() need to be used.
e = dict(name="grace", age=18, job="student") a, b, c = e print(a) f, g, h = e.values() print(g) s, t, u = e.items() print(u) d, f = (9, 10) print(d)
Exercise: (make a table in the form of a dictionary and a list)
a = dict(name="Grace", age=18, salary=1800, location="ON") b = dict(name="Lisa", age=19, salary=1700, location="QC") c = dict(name="Nancy", age=17, salary=1900, location="BC") tb = [a, b, c] # First line, second line, third line print(tb[1].get("salary")) #The first line takes the key value corresponding to salary for i in range(len(tb)): print(tb[i].get("salary")) for i in range(len(tb)): print(tb[i].get("name"), tb[i].get("age"), tb[i].get("salary"),tb[i].get("location"))
Dictionary core underlying principle
The core of a dictionary object is a hash table. Hash table is a sparse array. Each unit of the array is called bucket. A bucket has two parts: a key and a value.
Because each bucket has the same size and structure, we can read the specified bucket by offset.
Put a key value pair into the bottom process of the dictionary:
a = {} a["name"] = "grace" print(a) print(bin(hash("name"))) # 0b101001111010010100111100110001011010001111001101010010011001001
The first step is to calculate the hash value of the key "name", which can be calculated by using hash() in python
b = bin(hash("name")))
The array length is assumed to be 8. We can take the three rightmost digits of the calculated hash value as the offset, that is, "101", and the decimal digit is 5. We check the offset 5, if the corresponding bucket is empty, put the key value pair in, if it is not 0, take the three left digits in turn as the offset, and the decimal digit is 4. Until an empty bucket is found, put the key value pair in.
The process of finding key value pairs based on keys:
The first step is to calculate the hash value of the "name" object: bin(hash("name"))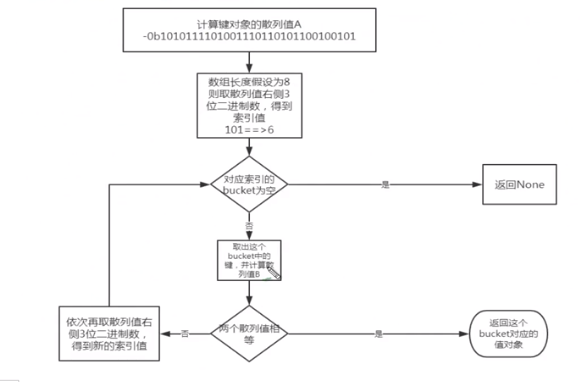
Usage Summary:
- Keys must be hashed: numbers, strings, tuples are hashable.
Custom objects need to meet the following three points:
- hash() function supported
- Support for eq uality detection through methods of
- If a == b, hash(a) == hash(b)
- Dictionary costs a lot in memory, typical space for time
- Fast key query
- Adding new content to the dictionary may result in expansion and change of key order in the hash table. Therefore, do not modify while traversing the dictionary
aggregate
The collection is unordered and variable, and the elements cannot be repeated. In fact, the bottom layer of the collection is implemented by a dictionary. All elements of the collection are key objects in the dictionary, so they cannot be repeated and unique.
Creation and deletion of collections
- Create an object with {} and add elements with a.add() (existing elements cannot be added)
- Use set() to convert list, tuple and other iteratable objects into a set. If there is duplicate data in the original data, only one is reserved. (b = set(a))
- Use a.remove() to delete the specified element, and a.clear() to clear the entire collection.
Collection related operations
Union (| or a.union()), intersection (& or a.intersection()), and difference set (- or a.difference()) is the part of a minus intersection
a = {1, 2, 3} b = (6, "sxt", 8) a.add("school") print(a) print(set(b)) print(a|set(b))
Control statement
Selection structure
The selection structure determines which branch to take by judging whether the condition is true or not.
There are many forms of selection structure: single branch, double branch and multi branch
Single branch selection structure
if condition expression:
(indent) statement block
a = input("Please enter a number:") if int(a)>10: #Convert a from string to integer print(a)
In the selection and loop structure, if the value of the conditional expression is false, it is as follows:
False, 0, null value None, null string, null sequence object, null range object, null iteration object
b = [] if b: print("Enter empty list as false") else: print("false")
The condition expression cannot have an assignor '='
Two branch selection structure
if condition expression:
(indent) statement block
else:
(indent) statement block
Ternary conditional operator
The format of the ternary conditional operator is as follows:
Value if (conditional expression) when condition is true value when else condition is false
a = input('Please enter a number:') print(a if int(a)<100 else "The number is too large.")
Multi branch selection structure
if condition expression 1:
Statement block 1
elif conditional expression 1:
Statement block 2
.
.
.
else:
Statement block n
score = input('Please enter a score:') grade = "" if int(score) < 60: grade = "Fail," elif int(score) < 80: grade = "pass" elif int(score) < 90: grade = "good" elif int(score) < 100 or int(score) == 100: grade = "excellent" else: print('Please re-enter the score') #The disadvantage is that when you enter a number greater than 100, it will also print a score print("The score is{0},Grade is{1}".format(score, grade))
Nesting of selection structures (implemented by indentation)
Insert a code slice here score = input('Please enter a score:') grade = "" if int(score) > 100 or int(score)<0: score = input("Input error, please input again") else: if int(score) < 60: grade = "Fail," elif int(score) < 80: grade = "pass" elif int(score) < 90: grade = "good" else: grade = "excellent" print("The score is{0},Grade is{1}".format(score, grade)) # print should also be indented so that it belongs to else
score = int(input('Please enter a score:')) grade = "ABCDE" num = 0 if score > 100 or score < 0: score = int(input("Input error, please input again")) else: num = score//10 if num<6: num = 5 elif num == 10: num = 9 # Consider the special case of 100 print("The score is{0},Grade is{1}".format(score, grade[9-num])) # print should also be indented so that it belongs to else
Cyclic structure
A loop structure is used to execute one or more statements repeatedly. Express such logic, if the condition is met, execute the statement of cyclic strength repeatedly.
while statement:
num = 0 while num<= 10: print(num, end="\t") num += 1
num = 0 sum_num = 0 while num <= 10: sum_num = num + sum_num num += 1 print(sum_num, end="\t")

