The theme of this time is to store data in CSV (or other) file format into MySQL database, and the table structure primary key should be established. Including the processing of date format. Although it's very simple, there are many details and a wide range of knowledge, so write it down.
Three tables, as follows
articles:
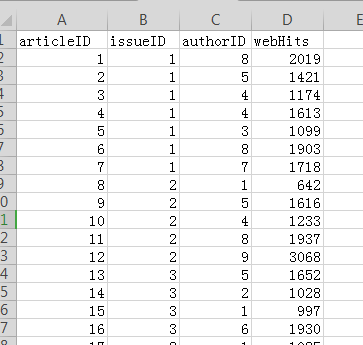
issues:
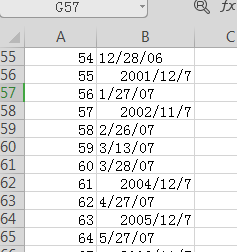
sales:
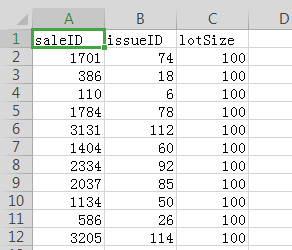
import numpy as np import pandas as pd # The module that interacts with the database works together with pandas. If it doesn't, it will pip itself. import sqlalchemy # This is the table, metadata, foreign keys, etc., which may be used later. from sqlalchemy import Table,MetaData,ForeignKey,Column,Integer,String,DateTime,Date,Float
# First read the data set, see the format of the data, null value, etc. do you want to deal with it? You can't just enter the database
# The first data is irregular and has redundant separators, so the first four columns are taken
data1 = pd.read_csv("../data/hfda_ch12_articles.csv",sep=",",usecols=[0,1,2,3])
data2 = pd.read_csv("../data/hfda_ch12_issues.csv")
data3 = pd.read_csv("../data/hfda_ch12_sales.csv")
The data format has been mapped before, and it will not be processed here. This is a set of data sources mentioned in the data analysis book. The analysis process will be posted when you have time.
# This is the sqlalchemy linked database engine. The format is fixed, and fill in your own database password at * * * * location
engine = sqlalchemy.create_engine("mysql+pymysql://root:****@localhost:3306/hjb")
"mysql+pymysql: / / user name: password @ localhost:3306 / database name"
The database name is not mysql. Don't fill in MySQL... Is the name of the database you want to use.....
No space in the middle!!!!!
Colons must be in English and Chinese. They are difficult to see and will be very annoying. Don't ask me why I know.
# Get metadata
metadata = MetaData()
# Column function: import ed earlier
# Table name, metadata,
# Column('mytable_id', Integer, primary_key=True),
# Column('value', String(50))
# Create a table, the name, type, and primary key constraint of each field
articles = Table(
"articles_fuben",metadata, # I added a copy after my name because I already have these three tables in my database
Column("articleID",Integer,primary_key=True),
Column("issueID",Integer),
Column("authorID",Integer),
Column("webHits",Integer)
)
issues = Table(
"issues_fuben",metadata,
Column("issueID",Integer,primary_key=True),
Column("PubDate",Date) # Note that the type is Date or Datetime
)
sales = Table(
"sales_fuben",metadata,
Column("saleID",Integer,primary_key=True),
Column("issueID",Integer),
Column("lotSize",Integer)
)
It is understandable to establish tables and table structures and put these tables into metadata. These tables are empty in the metadata.
# Create all tables with metadata metadata.create_all(bind=engine) # This establishment means that it is established in the MySQL database, so the engine should be bound. # At the end of this row, you can check whether there are three tables in the database # You can also use a single table to create a table without repeating # articles.create(bind=engine)
When the table is completed, there is only data to insert. What else is there in the middle?
Is the data in the CSV table the same as the type defined by our metadata? Can you insert it? This should be clear.
Check again. It cannot be stored in Integer in string format.
There is also a time pattern. We must turn the time in the dataframe. Otherwise, it will report an error. If you don't believe it, you can try it.
s = data2["PubDate"] data2["PubDate"] = pd.to_datetime(s) # Observe whether the time after turning is what you want. Whether the date is reversed, etc.
# From CSV to dataframe, there will be a default index and subscript starting from 0. There is no need to save when saving data. # if_exists defaults to fail, but we have created a table, so just append # It is better to run these three deposits separately, because there are no transactions here, and half of them may report an error. # Or use Navicat to view the data. pd.io.sql.to_sql(data1,"articles_fuben",engine,if_exists="append",index=False) pd.io.sql.to_sql(data2,"issues_fuben",engine,if_exists="append",index=False) pd.io.sql.to_sql(data3,"sales_fuben",engine,if_exists="append",index=False)
In addition, pandas can store data directly. If you don't create a table structure first, there are no data types and primary key constraints. It depends on yourself. If you don't need it, you can save it directly with pandas without metadata. I used to save directly when I studied.
# If you want to insert or delete changes and queries, you can use the following statement
engine.execute("insert into ........")
# The query will have a view of the return value
a = engine.execute("select ..........")
a.fetchone()
#You can also use pandas to read from the database
# You can also read pages and so on, just look at how your sentences are written
pd.read_sql("select * from articles",engine)