Preface
Preface
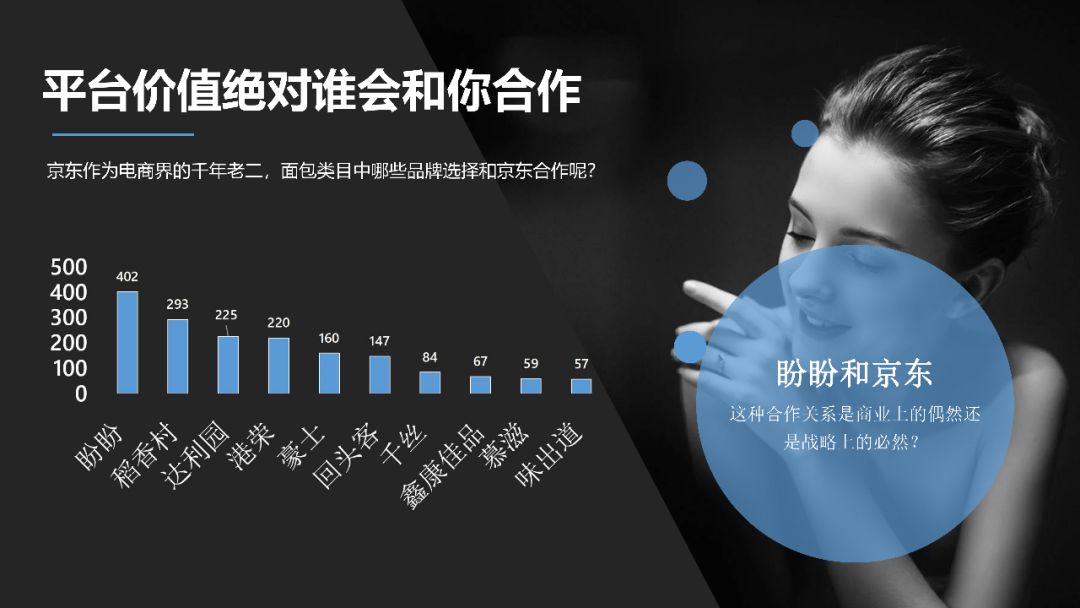
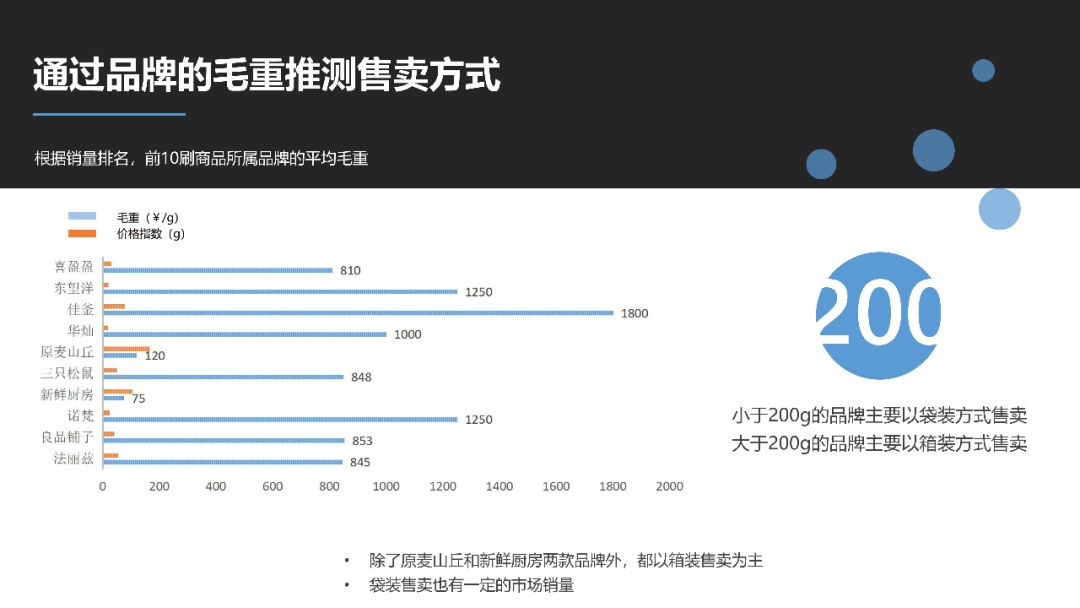
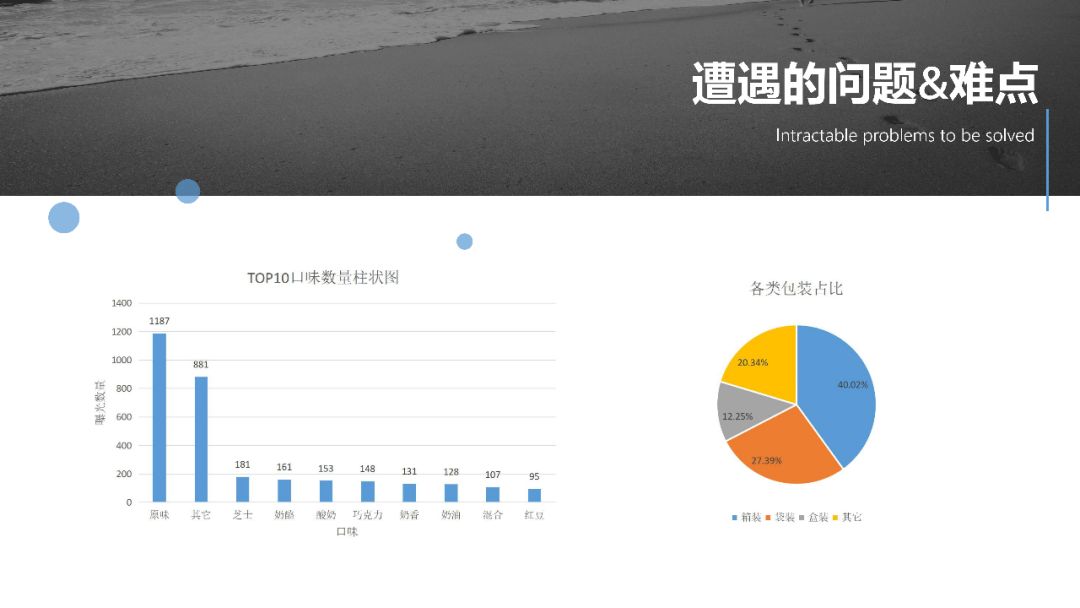
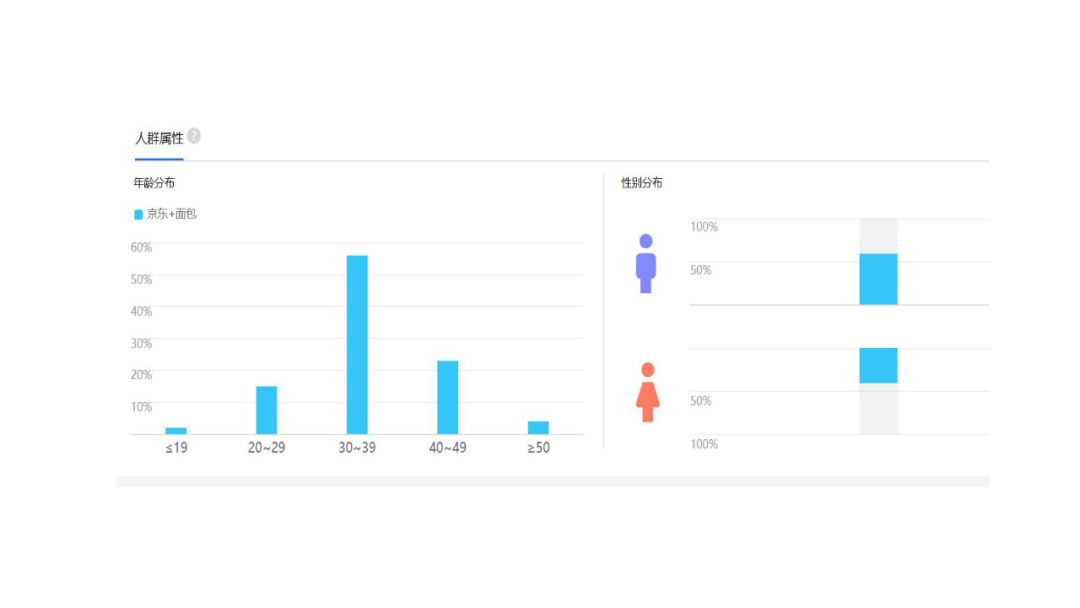
What's the best brand of bread to sell? What is the most popular taste? I believe that every friend who likes bread will care about these problems. By crawling the bread data of Jingdong, on the one hand, this paper answers all kinds of questions about bread before, on the other hand, it brings you a complete data report, which can be used for reference.
Data crawling (partial code)
Build agent for parsing detail page
def disguiser():
'''
//Build agent for parsing detail page
'''
try:
req = request.Request('http://www.agent.cn/xdaili-api//greatRecharge/getGreatIp?spiderId=8f75fb741de34cfb95adf347910db7a9&orderno=YZ20191169208Yi1jmu&returnType=2&count=1')
resp = request.urlopen(req)
jsonIP = resp.read().decode()
jsonIP = re.sub(' ','',jsonIP)
ipList = re.findall('"ip":"(.*?)"',jsonIP)
portList = re.findall('"port":"(.*?)"',jsonIP)
value = list(map(lambda x,y : x + ':' + y,ipList, portList))
key = ['http']
ipDict = {key[index] : value[index] for index in range(len(key))}
print(ipDict)
# 1. Use ProxyHandler and pass in agent to build a handler
handler = request.ProxyHandler(ipDict) # key: http/https val: ip:port
# 2. Use the handler created above to build an opener
opener = request.build_opener(handler)
print(opener)
except:
time.sleep(6)
req = request.Request('http://www.agent.cn/xdaili-api//greatRecharge/getGreatIp?spiderId=8f75fb741de34cfb95adf347910db7a9&orderno=YZ20191169208Yi1jmu&returnType=2&count=1')
resp = request.urlopen(req)
jsonIP = resp.read().decode()
jsonIP = re.sub(' ','',jsonIP)
ipList = re.findall('"ip":"(.*?)"',jsonIP)
portList = re.findall('"port":"(.*?)"',jsonIP)
value = list(map(lambda x,y : x + ':' + y,ipList, portList))
key = ['http']
ipDict = {key[index] : value[index] for index in range(len(key))}
print(ipDict)
# 1. Use ProxyHandler and pass in agent to build a handler
handler = request.ProxyHandler(ipDict) # key: http/https val: ip:port
# 2. Use the handler created above to build an opener
opener = request.build_opener(handler)
return opener
Analyze the contents of the details page
def parser(pageQueue, uaPool, priceRequestDoc, PRICEBASEURL, detailRequestDoc, open):
'''
//Analyze the contents of the details page
'''
detailUrl = pageQueue.get()[1]
print(detailUrl)
# Price
PRICEURL = PRICEBASEURL + re.search('\d+',detailUrl).group()
priceRequestDoc = re.sub(r' ','',priceRequestDoc)
headers_for_price = dict(re.findall('([-\w\d]*?):(.*)',priceRequestDoc))
headers_for_price.update(uaPool[random.randint(0,len(uaPool)-1)]) # Get headers information of commodity price information request
req = request.Request(PRICEURL, headers = headers_for_price)
resp = open(req) #First response
print(PRICEURL,'Commodity price page request response code:',resp.getcode())
if resp.getcode() == 200:
info = resp.read().decode()
elif SERVER_ERROR_MIN <= response.status_code < SERVER_ERROR_MAX:
for i in range(5):
time.sleep(i**i) #Can continue to optimize, the first 1 second, the second 10 seconds, the third 100 seconds
resp = open(req)
if resp.getcode() == 200:
break
elif SERVER_ERROR_MIN <= response.status_code < SERVER_ERROR_MAX:
if response.status_code == 404:
print('page not found')
elif response.status_code == 403:
print('have no right')
else:
pass
info = json.loads(info)
item_price = info[0]['p']
# Whether the name and brand contain sugar shelf life ingredients packaging goods origin
detailRequestDoc = re.sub(r' ','',detailRequestDoc)
headers_for_detail = dict(re.findall('([-\w\d:]*):(.*)',detailRequestDoc))
headers_for_detail.update(uaPool[random.randint(0,9)]) # Get headers information of commodity price information request
req = request.Request(detailUrl, headers = headers_for_detail)
resp = open(req) # Second response
print(detailUrl,'Detail page request response:',resp.getcode())
if resp.getcode() == 200:
pass
elif SERVER_ERROR_MIN <= response.status_code < SERVER_ERROR_MAX:
for i in range(5):
time.sleep(i**i) #Can continue to optimize, the first 1 second, the second 10 seconds, the third 100 seconds
resp = open(req)
if resp.getcode() == 200:
break
elif SERVER_ERROR_MIN <= response.status_code < SERVER_ERROR_MAX:
if response.status_code == 404:
print(detailUrl,'page not found')
elif response.status_code == 403:
print(detailUrl,'have no right')
else:
pass
parser = etree.HTMLParser(encoding = 'gbk')
html = etree.parse(resp, parser = parser)
print(html)
elements = html.xpath("//ul[@class='parameter2 p-parameter-list']//text() | //dl[@class='clearfix']//text()")
detailInfo = list(filter(lambda msg : len(msg.strip()) > 0 and msg, elements))
detailInfo = ('#').join(detailInfo)
try:
item_name = re.search('Commodity name:(.*?)#',detailInfo).group(1)
except AttributeError:
# print('item name information is not available for the product ')
item_name = 'n'
try:
item_id = re.search('\d+',detailUrl).group()
except AttributeError:
# print('item 'ID information is not available for the item')
item_id = 'n'
# Commodity name
elementTitle = html.xpath("//title//text()")[0]
elementTitle = elementTitle.strip()
item_fullName = re.search('([.*])*(.*)?[',elementTitle).group(2)
# brand
elementBrand = html.xpath("//*[@id='crumb-wrap']/div/div[1]/div[7]/div/div/div[1]/a/text()")
elementBrand = list(filter(lambda msg : len(msg.strip()) > 0 and msg, elementBrand))
try:
item_brand = elementBrand[0]
except IndexError:
item_brand = 'npl'
yield {
'item_id':item_id,
'item_fullName':item_fullName,
'item_name':item_name,
'item_price':item_price,
'item_brand':item_brand,
'gross_weight':gross_weight,
'item_origin':item_origin,
'item_certification':item_certification,
'processing_technology':processing_technology,
'packing_unit':packing_unit,
'is_suger':is_suger
}
Since the number of public addresses is limited, we cannot display all the code of this article. We have put the code into Baidu cloud disk. Reply "bread" in the background, you can get the code of this article.
Analysis text