Preface
The text and pictures of this article are from the Internet, only for learning and communication, not for any commercial purpose. The copyright belongs to the original author. If you have any questions, please contact us in time for handling.
Analysis background
With the popularity of artificial intelligence and big data in recent years, more and more people want to be engaged in or transfer to data analysts. The main reason why everyone loves this industry so much is that the salary is objective and there is a development prospect.
Based on my superficial work experience, let's talk about my opinion on data analysts. There has been a controversy in this industry. Whether it is tool or business level is important, that is, tool party and business party. First, I am business party (formerly tool party). Although I spend most of my time doing data processing, this ability is also necessary, whether it's simple EXCEL, SQL, PPT or complex R, Python, finebi, fineport and HIve, but there are too many analysis tools on the market, you can't master them all, and the business knowledge of each industry is basically the same. When a data analyst with business knowledge and experience sees a pile of data, he will clearly know from what perspective to analyze, how the data presents, whether the data is abnormal, and where the cause of the exception lies. The data can solve those problems, and the data is applicable to those scenarios. He will have a complete data analysis idea. So a qualified data analyst can find valuable information from a pile of data.
Back to the main topic, what is the "money" scenario of data analysis? This paper will analyze the data analyst positions recently recruited on the boas recruitment website, involving work city, work experience, salary level, skill requirements, etc.

Data analysis
The amount of post data obtained this time is 17485, and the amount of data only reserved for data analysis post is 5616. This time, the data tool is selenium, the analysis tool is panda, and the drawing tool is pyecharts. The final form of data presentation is

Considering the recruitment market demand of this year, this analysis of data analyst positions will be carried out from the following points
- City of position
- Education requirements
- Working life requirements
- Salary distribution
- Job skill requirements of Data Analyst
- Major recruitment industries
- Major recruitment companies
- Recruitment company benefits display
1. City of position
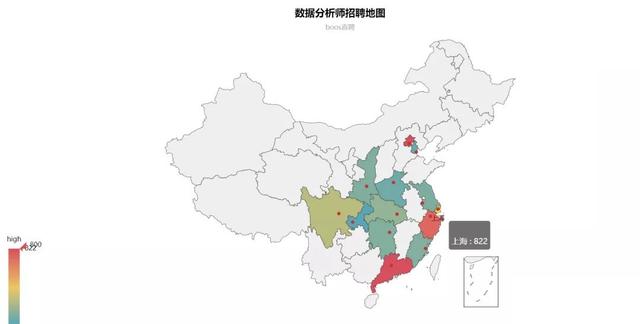
Due to the special position of data analyst, the analysis cities are mainly concentrated in the first tier and new first tier cities. It can be seen that the highest demand for recruitment is in the north, Shanghai, Guangzhou and Zhejiang. Other new first tier cities have little demand for this position. However, with the development of economy, most companies will have greater demand for data and more demand for corresponding positions
2. Education requirements
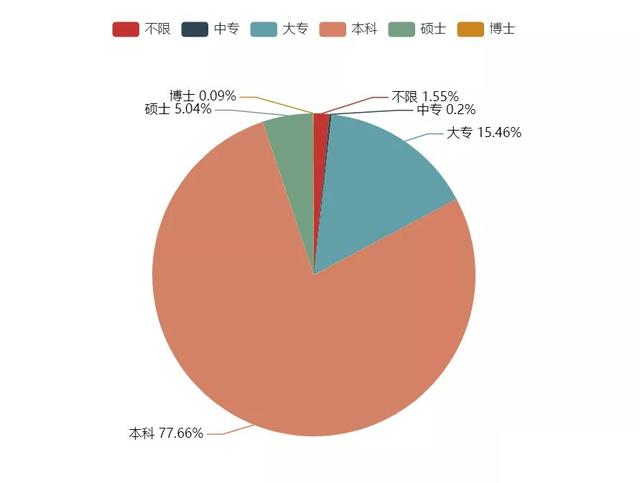
As can be seen from the education requirements, the proportion of undergraduate education for data analysts has reached 77.66%
3. Working life requirements
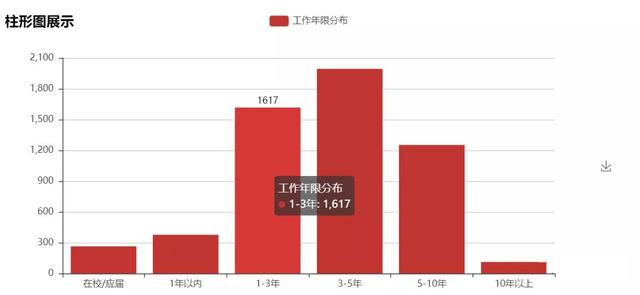
From the perspective of working years, the data analyst position is more popular for people who have been engaged in this work for 1-5 years, presenting a normal distribution as a whole.
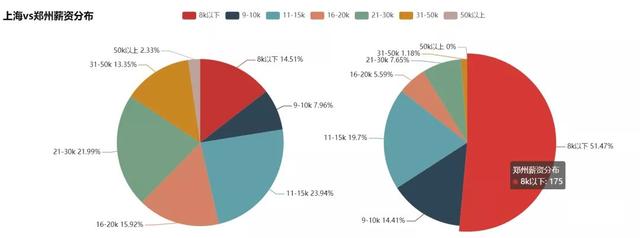
4. Salary distribution
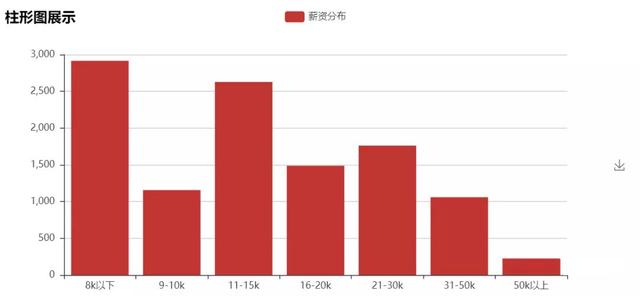
From the perspective of salary, this time's processing of salary is mainly to take the maximum and minimum two values from the salary space (for example, 8-15k, with values of 8k and 15K). The salary distribution is slightly higher. In order to avoid the new first tier cities being average by the first tier cities, we will compare the two cities of Shanghai and Zhengzhou, with the amount of......, as shown in the following figure
5. Job skill requirements of Data Analyst

For skill requirements, the most frequent words are data mining, data analysis, python, data warehouse, business analysis, HIVE, big data, etc. It can be seen that data analysts value data analysis tools and business level.
6. Major recruitment industries
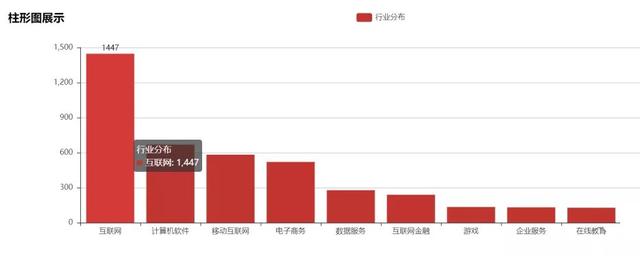
From the perspective of recruitment industry, Internet, e-commerce, data service, finance and other industries are in the greatest demand, mainly because these industries will generate a large number of data. The demographic dividend has passed and the sinking market has been tackled. Now they are all paying attention to the refined operation. Therefore, for the Internet industry, every user has become very important, and the digital user can operate better, so the demand for data analysts in these industries is very large, and will be greater in the future
7. Major recruitment companies
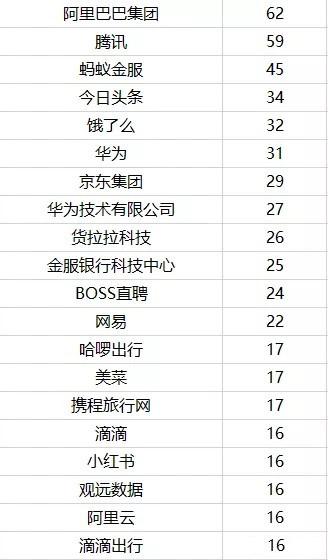
The largest recruitment demand is still from large companies
8. Recruitment company benefits display

Most of the company's benefits are five insurances and one fund, paid annual leave, holiday benefits, etc. However, 860 of the 5616 recruitment companies have no benefits. They also see that six holidays and one company benefit have become the company's benefits. 996 has become a blessing. It seems that for any industry, working is risky. It's impossible to work, so we have to find another way out

Data capture
The data source is the direct recruitment website of BOOS. The main anti crawling measures for the website are dynamic cookies. The main anti crawling measures are the encryption field of cookies, which is called "reverse decryption". I didn't finish it... It can only be crawled automatically by selenium. Anyway, the data is down. O(∩∩∩∩∩∩∩∩∩∩∩∩∩∩) O haha~
Code display:
from selenium import webdriver import time from urllib import parse import string from lxml import etree import csv def get_parse(driver): htmls=driver.page_source html=etree.HTML(htmls) items = html.xpath('//div[@class="job-list"]/ul/li') D=[] try: for item in items: zhiwei=item.xpath('.//div[@class="job-title"]/span[@class="job-name"]/a/text()')[0] diliweizhi = item.xpath('.//span[@class="job-area"]/text()')[0] xinzi = item.xpath('.//span[@class="red"]/text()')[0] gongzuonianxian = item.xpath('.//div[@class="job-limit clearfix"]/p/text()')[0] xueli = item.xpath('.//div[@class="job-limit clearfix"]/p/text()')[1] yaoqiu = item.xpath('.//div[@class="tags"]/span/text()')[0] yaoqiu1 = item.xpath('.//div[@class="tags"]/span/text()')[1] try: yaoqiu2 = item.xpath('.//div[@class="tags"]/span/text()')[2] except: yaoqiu2=' ' try: yaoqiu3 = item.xpath('.//div[@class="tags"]/span/text()')[3] except: yaoqiu3 = ' ' try: yaoqiu4 = item.xpath('.//div[@class="tags"]/span/text()')[4] except: yaoqiu4=' ' gongsi = item.xpath('.//div[@class="company-text"]/h3/a/text()')[0] try: hangye = item.xpath('.//div[@class="company-text"]/p/a/text()')[0] except: pass try: gongsidaxiao1 = item.xpath('.//div[@class="company-text"]/p/text()')[0] except: gongsidaxiao1=' ' try: gongsidaxiao2 = item.xpath('.//div[@class="company-text"]/p/text()')[1] except: gongsidaxiao2=' ' try: fuli = item.xpath('.//div[@class="info-desc"]/text()')[0] except: fuli=' ' print(zhiwei, diliweizhi, xinzi, gongzuonianxian, xueli, yaoqiu,yaoqiu1,yaoqiu2,yaoqiu3,yaoqiu4, gongsi, hangye, gongsidaxiao1,gongsidaxiao2,fuli) data=[zhiwei, diliweizhi, xinzi, gongzuonianxian, xueli, yaoqiu,yaoqiu1,yaoqiu2,yaoqiu3,yaoqiu4, gongsi, hangye, gongsidaxiao1,gongsidaxiao2,fuli] D.append(data) except: pass save(D) def save(data): with open('./boss2.csv','a',newline='',encoding='utf-8')as f: writer=csv.writer(f) writer.writerows(data) def main(): header=['position','region','salary','Working years','Education requirements','Skill Requirements1','Skill requirements 2','Skill requirements 3','Skill requirements 4','Skill requirements 5','corporate name','industry','Company status','Company size','welfare'] with open('./boss2.csv', 'a', newline='', encoding='utf-8')as f: writer = csv.writer(f) writer.writerow(header) chromedriver_path='C:/Users/10489/Desktop/chromedriver_win32/chromedriver.exe' # Use chrome Driver options = webdriver.ChromeOptions() # Set it to developer mode to prevent it from being recognized and used by major websites Selenium options.add_experimental_option('excludeSwitches', ['enable-automation']) driver = webdriver.Chrome(executable_path=chromedriver_path, options=options) a='Data Analyst' position=parse.quote(a, safe=string.printable) # Beijing, Shanghai, Guangzhou, Shenzhen, Hangzhou, Tianjin, Xi'an, Suzhou, Wuhan, Xiamen, Changsha, Chengdu, Zhengzhou, Chongqing city=['101010100','101020100','101280100','101280600','101210100','101030100','101110100','101190400','101200100','101230200','101250100','101270100','101180100','101040100'] for j in city: # Fresh students, within 1 year, 1-3 Year, 3-5 Year, 5-10 More than 10 years # https://www.zhipin.com/c101020100/e_103/?query={}&ka=sel-exp-102 # https://www.zhipin.com/c101020100/e_103/?query={}&ka=sel-exp-103 # https://www.zhipin.com/c101020100/e_103/?query={}&ka=sel-exp-104 # https://www.zhipin.com/c101020100/e_103/?query={}&ka=sel-exp-105 # https://www.zhipin.com/c101020100/e_103/?query={}&ka=sel-exp-106 # https://www.zhipin.com/c101020100/e_103/?query={}&ka=sel-exp-107 for i in range(2,8): driver.get('https://www.zhipin.com/c{}/e_10{}/?query={}&ka=sel-exp-10{}'.format(j,i,position,i)) # driver.get('https://www.zhipin.com/job_detail/?query={}&city=101020100&industry=&position='.format(position)) driver.maximize_window() time.sleep(10) get_parse(driver) try: while True: time.sleep(5) driver.execute_script("window.scrollTo(0,6000)") time.sleep(10) driver.find_element_by_xpath('//a[@class="next"]').click() get_parse(driver) except: pass if __name__ == '__main__': main()
No matter you are zero foundation or have foundation, you can get the corresponding study gift pack! It includes Python software tools and 2020's latest introduction to actual combat. Add 695185429 for free.