I. Summary of Basic Knowledge
1. Using pandas to read and write Excel files
2. Using pandas to read and write XML files
2. Begin to use your hands and brains
1. Using Python to Read and Write Excel
- Read, using the ExcelFile() method of the Pandas library.
- Write, use
Code
import pandas as pd
import os
'''
//The python learning materials prepared by Xiaobian, plus group: 821460695 can be obtained free of charge! ____________
'''
# Get the parent directory path of the current file
father_path = os.getcwd()
# Original Data File Path
rpath_excel = father_path+r'\data01\realEstate_trans.xlsx'
# Data save path
wpath_excel = father_path+r'\data01\temp_excel.xlsx
# Open excel file
excel_file = pd.ExcelFile(rpath_excel)
# Read file content
"""
ExcelFile Object parse()Method reads the contents of the specified worksheet
ExcelFile Object sheet_names Attributes can be obtained Excel All worksheets in the document
//Dictionary expressions are also used here to assign values to dictionaries (which look more elegant).
"""
excel_read = {sheetName : excel_file.parse(sheetName) for sheetName in excel_file.sheet_names}
# The first 10 rows of the price column of the output Sacramento table
print(excel_read['Sacramento'].head(10)['price'])
print(type(excel_read['Sacramento'].head(10)['price']))
# Error encountered: ModuleNotFoundError: No module named'xlrd'
# The top 10 rows of the price column written to the table
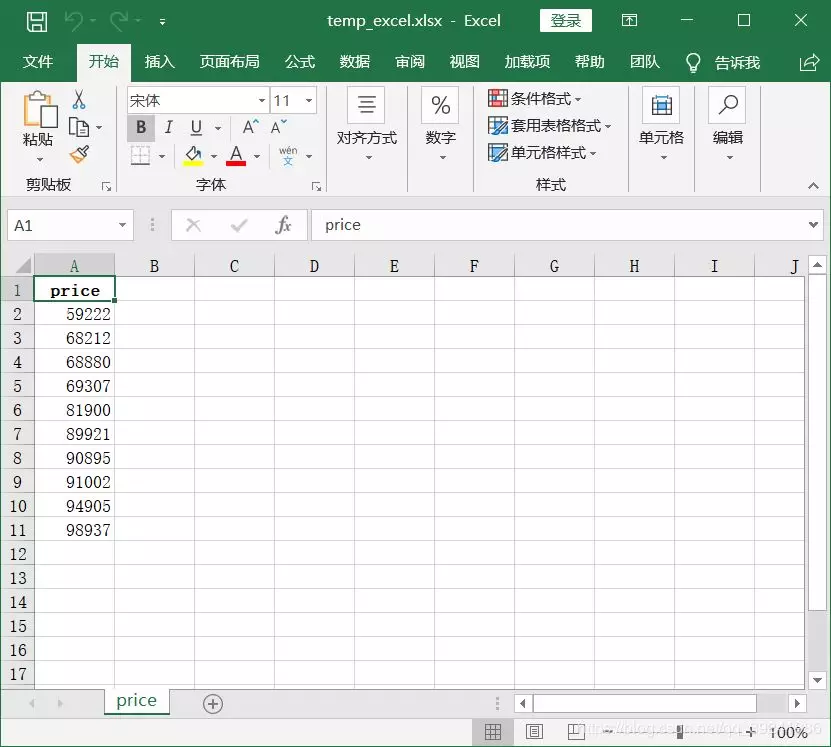
excel_read['Sacramento'].head(10)['price'].to_excel(wpath_excel, "price", index=False)
# Error encountered: ModuleNotFoundError: No module named'openpyxl'
Read results:
Write results:
Possible error:
Reading operation: ModuleNotFoundError: No module named 'xlrd' Write operations: ModuleNotFoundError: No module named 'openpyxl'
Solution:
# Install xlrd and openpyxl modules in the environment pip install xlrd pip install openpyxl
2. Using Python to Read and Write XML Files
Students who have studied java should not be unfamiliar with XML. The full name is eXtensible Markup Language (Extended Markup Language). Although it is not common, it supports XML encoding in Web API.
Read write code
import pandas as pd
# A Lightweight XML Parser
import xml.etree.ElementTree as ET
import os
'''
//The python learning materials prepared by Xiaobian, plus group: 821460695 can be obtained free of charge! ____________
'''
"""
//Read in XML data and return pa.DataFrame
"""
def read_xml(xml_FileName):
with open(xml_FileName, "r") as xml_file:
# Read data and store it in a tree structure
tree = ET.parse(xml_file)
# The Stem Node of Access Tree
root = tree.getroot()
# Return Data Frame Format Data
return pd.DataFrame(list(iter_records(root)))
"""
//Traversing the Recorded Generator
"""
def iter_records(records):
for record in records :
# Temporary dictionary for saving values
temp_dict = {}
# Traverse through all fields
for var in record:
temp_dict[
var.attrib["var_name"]
] = var.text
# Generating value
yield temp_dict
"""
//Save data in XML format
"""
def write_xml(xmlFileName, data):
with open(xmlFileName, "w") as xmlFile:
# Write head
xmlFile.write(
'<?xml version="1.0" encoding="UTF-8"?>'
)
xmlFile.write('<records>\n')
# Writing data
xmlFile.write(
'\n'.join(data.apply(xml_encode, axis=1))
)
# Write tail
xmlFile.write("\n</records>")
"""
//Encoding each line into XML in a specific nested format
"""
def xml_encode(row):
# Step 1 -- Output record node
xmlItem = [' <record>']
# Step 2 -- Add the XML format <field name= /> /</field> to each field in the row
for field in row.index:
xmlItem.append(
'<var var_name="{0}">{1}</var>'.format(field, row[field])
)
# The last step -- tagging the end tag of the record node
xmlItem.append(" </record>")
return '\n'.join(xmlItem)
# Get the parent directory path of the current file
father_path = os.getcwd()
# Original Data File Path
rpath_xml = father_path+r'\data01\realEstate_trans.xml'
# Data save path
wpath_xml = father_path+r'\data01\temp_xml.xml'
# Read data
xml_read = read_xml(rpath_xml)
# Output first 10 rows of records
print(xml_read.head(10))
# Write back the file in XML format
write_xml(wpath_xml, xml_read.head(10))
Operation result

Code parsing
(1)read_xml(xml_FileName) function
Function: Read in XML data and return pa.DataFrame
Here we use a lightweight XML parser: xml.etree.ElementTree. Input file name, first read the file content, then parse the XML using parse() function, create a tree structure and store it in the tree variable, call getroot() method on the tree object to get the root node, and finally call iter_records() function, pass in the root node, and then convert the returned information into a DataFrame.
(2)iter_records(records) function
Function: traversing the recorded generator
The iter'u records() method is a generator. From the keyword yield, you can see that if you don't know the generator, you can click here. Unlike return, the generator only returns one value to the main method until the end.
(3)write_xml(xmlFile, data) function
Function: Save data in XML format
Here we need to pay attention to the XML file format to save, what we need to do is three steps: save the header format, save the data according to the format, save the tail format. The application () method of the DataFrame object is used to save the data, traversing every row inside. The first parameter xml_encode specifies the method to be applied to every row record. axis=1 denotes row-by-row processing, and the default value is 0 denotes column-by-column processing.
(4)xml_encode(row) function
Function: Encoding each line into XML in a specific nested format
In the process of writing data, we will call this method to process each row of data and turn it into XML format.