Preface
The text and pictures of the article are from the Internet, only for learning and communication, and do not have any commercial use. The copyright belongs to the original author. If you have any questions, please contact us in time for handling.
Author: qingfengxiaozhu
PS: if you need Python learning materials, you can click the link below to get them by yourself
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
Zhihu is the largest Q & a community in China. Different from Weibo, post bar and other products, Zhihu's content is more about users sharing knowledge, experience and opinions on specific issues.
The connection of big V
First of all, I'll show you the diagram of the top 50 users who know the number of fans:
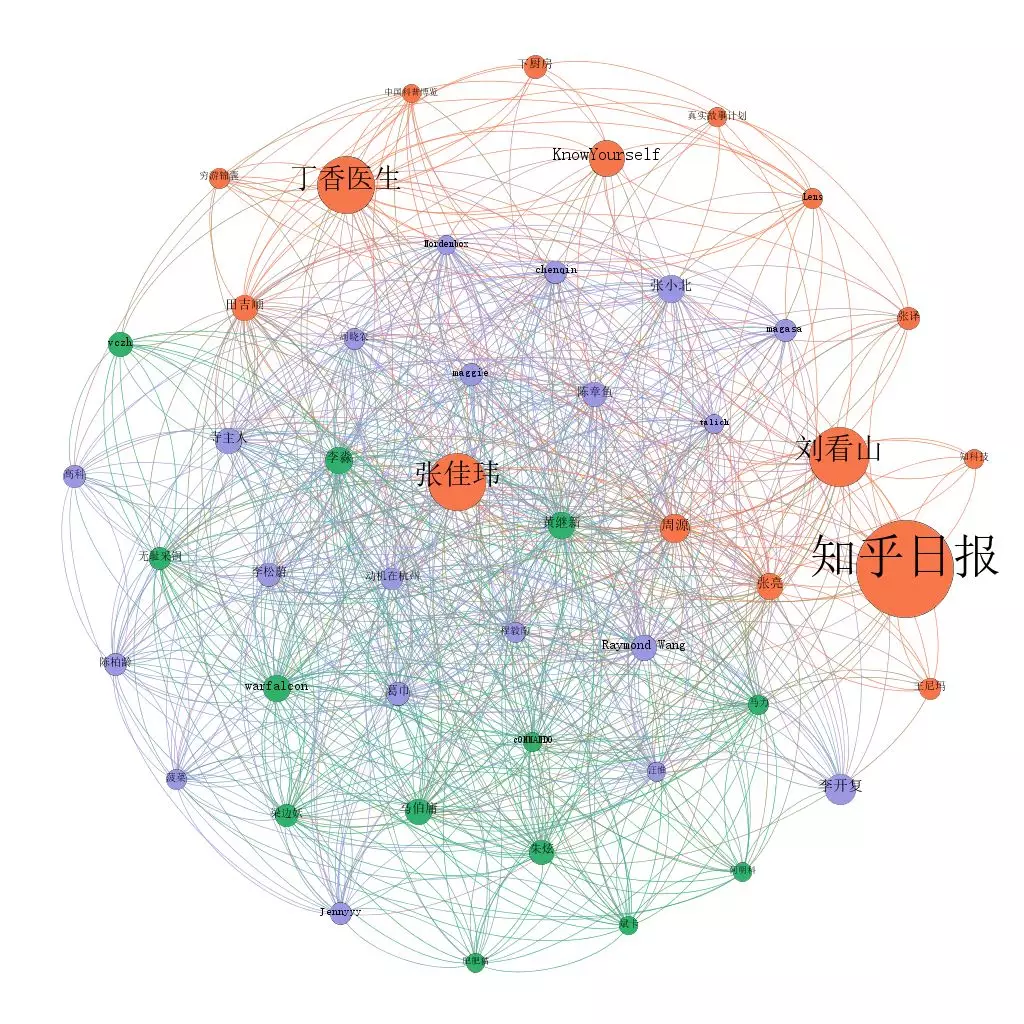
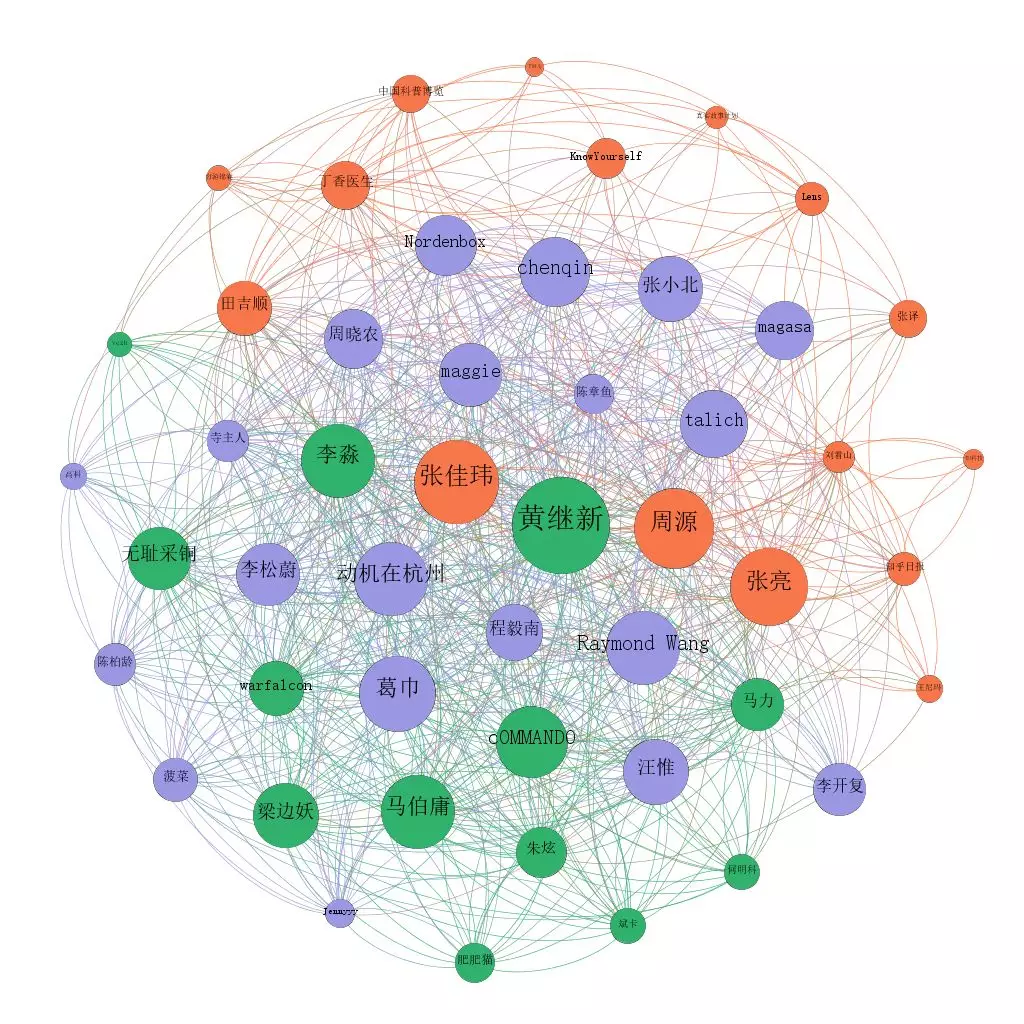
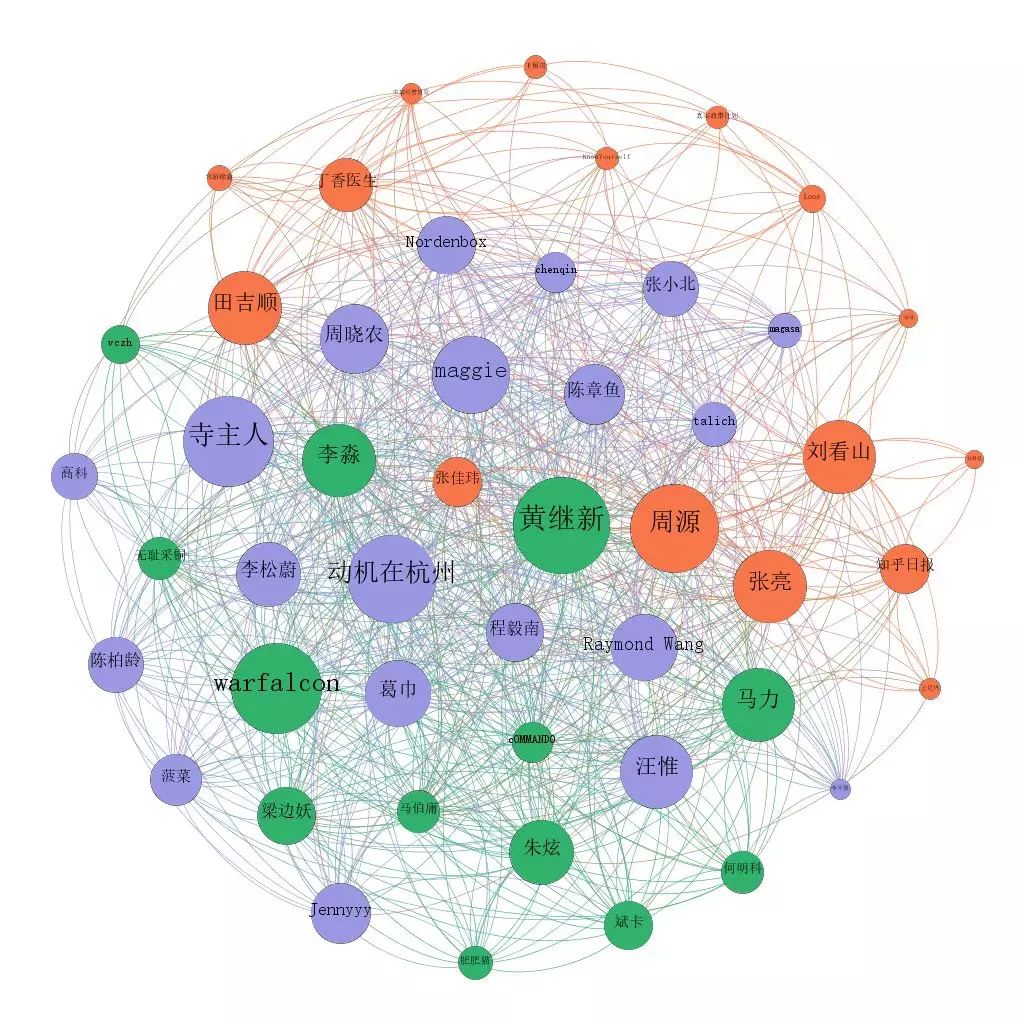
The lines in the diagram are the relationship of mutual concern between users. The difference of these three pictures is only in the size of the circle, which respectively represents: the number of fans, the degree of connection (the number of people who are concerned about in the picture), the degree of connection (the number of people who are concerned about in the picture)
Obviously, ordinary users such as Zhihu daily, Liu kanshan and Dingxiang doctor pay more attention to the "institution number", which is not highly concerned in the big V.
This picture is based on the data collected by Python through a software called Gephi. The color of the circle is the result of Gephi's automatic aggregation according to the association relationship.
Who is the big V?
Four indicators of Zhihu: attention, approval, thanks and collection. Let's take a look at the "head users" ranked by different indicators:
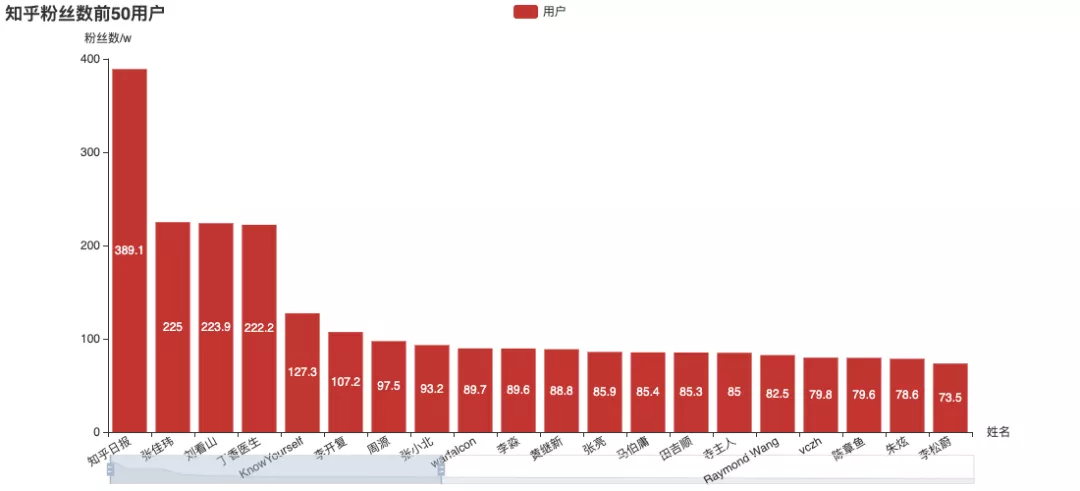
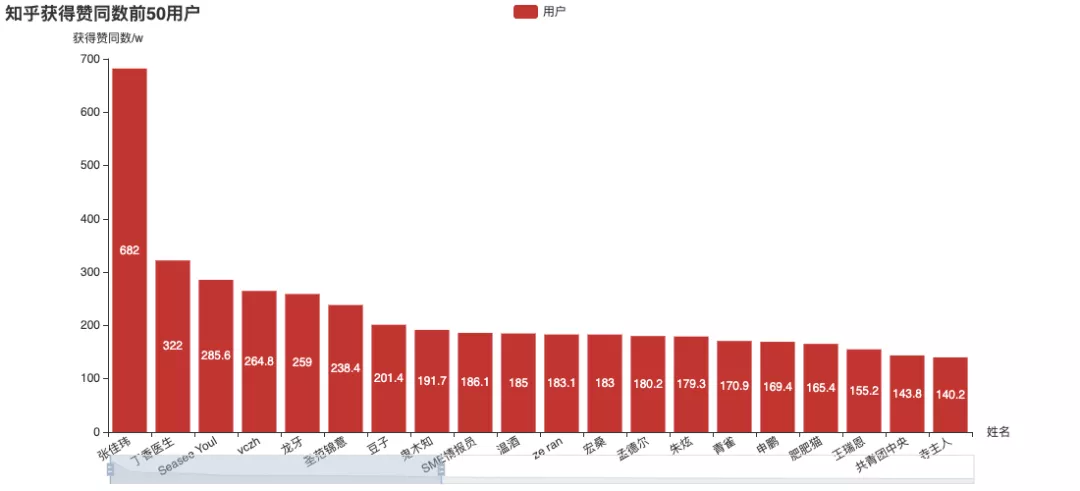
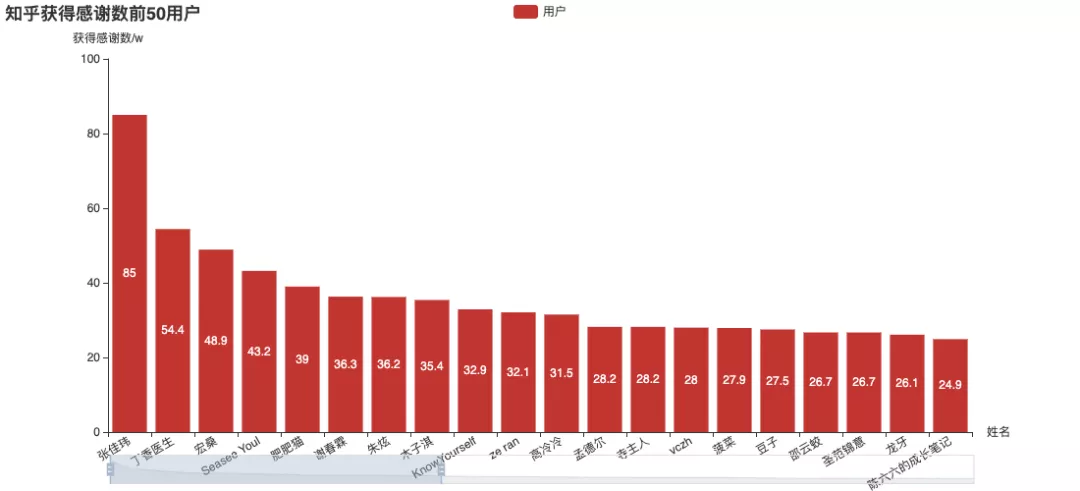
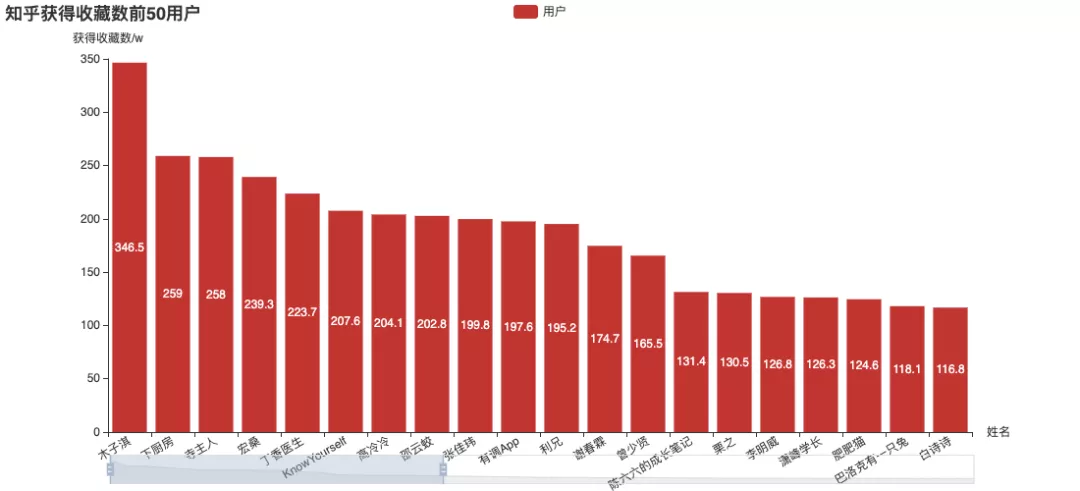
Among them, Zhang Jiawei is very outstanding. (the name is familiar Do you remember the analysis of tiger attack before
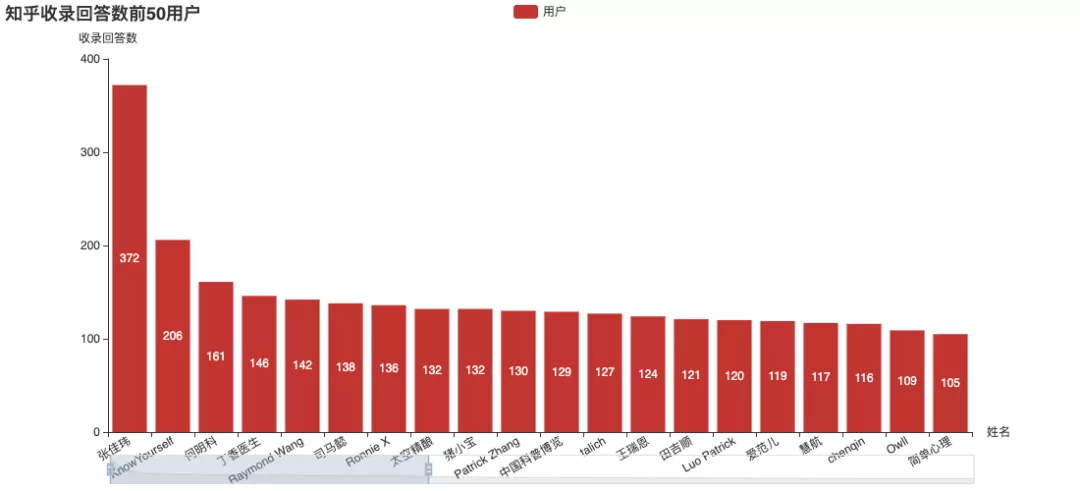
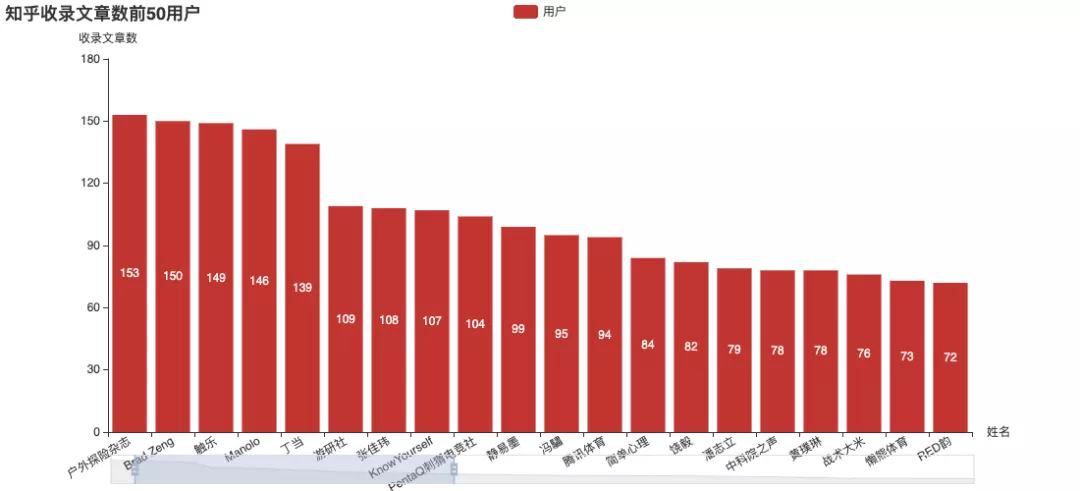
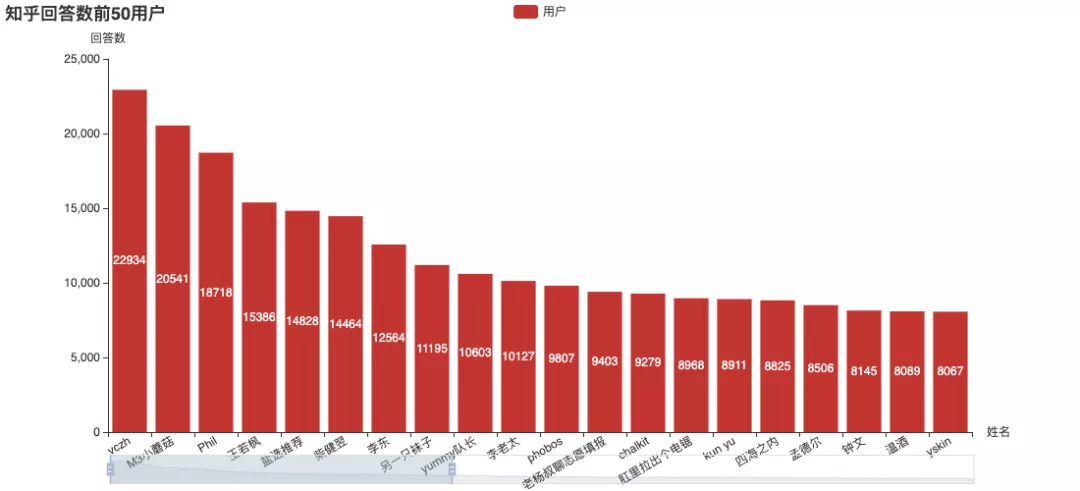
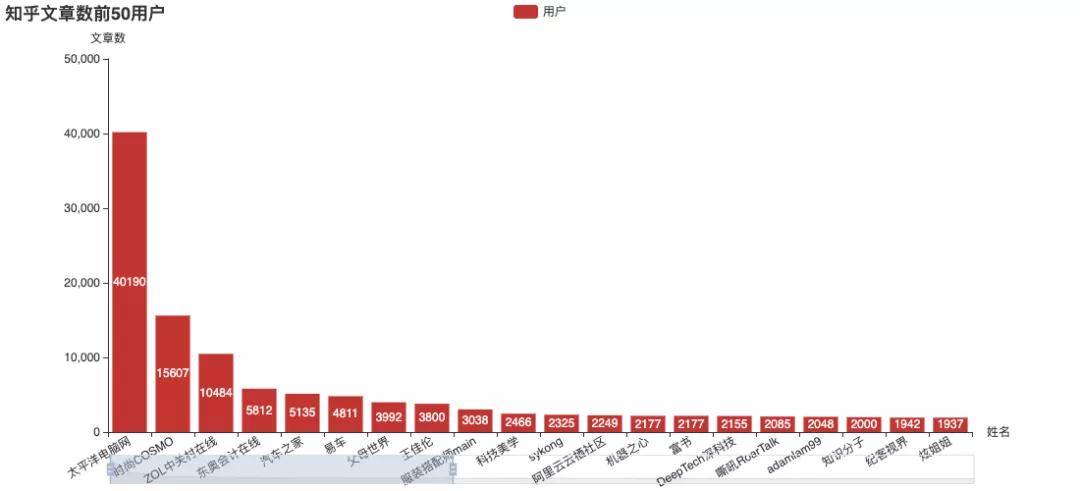
The official number of answers, Zhang Jiawei is still far ahead, including the number of articles on the list.
If we only look at quantity regardless of quality:
These data are combined into two three-dimensional scatter diagrams
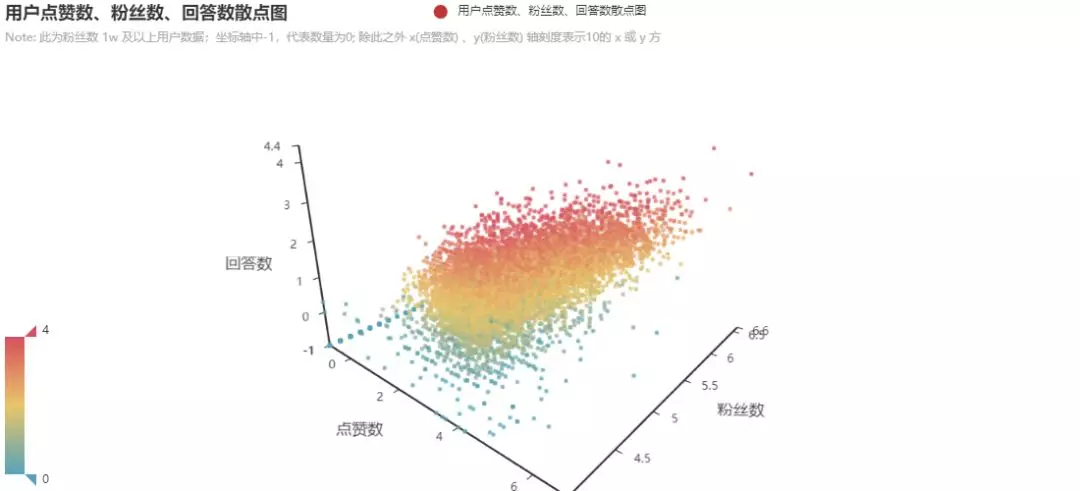
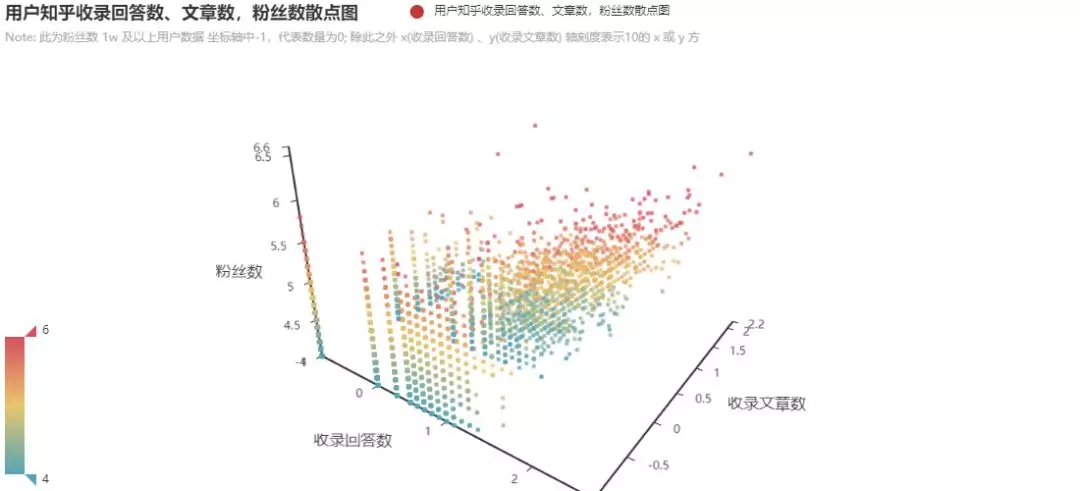
The data selected in the figure are users with more than 10000 concerns. There are interactive web versions in the project, which can be more intuitive to view the distribution map.
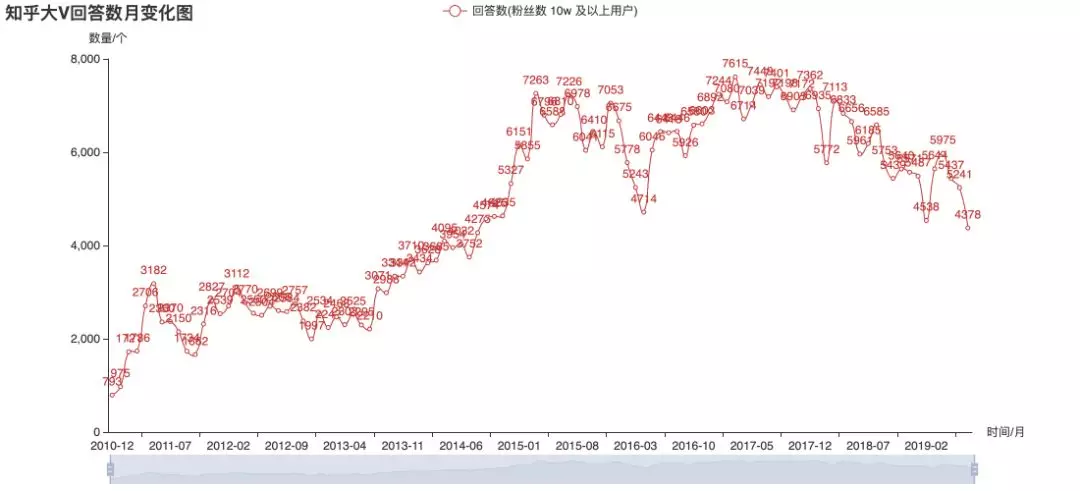
Big V's enthusiasm is fading?
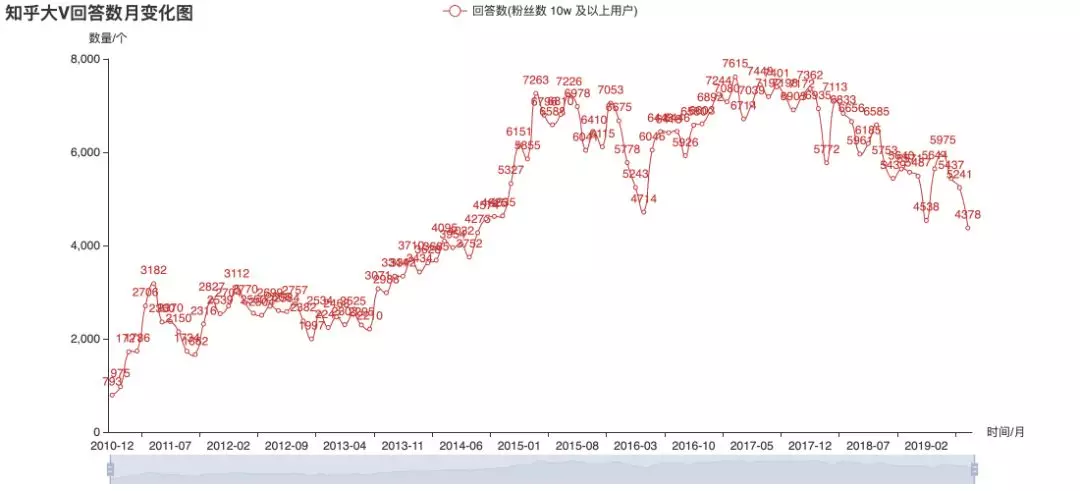
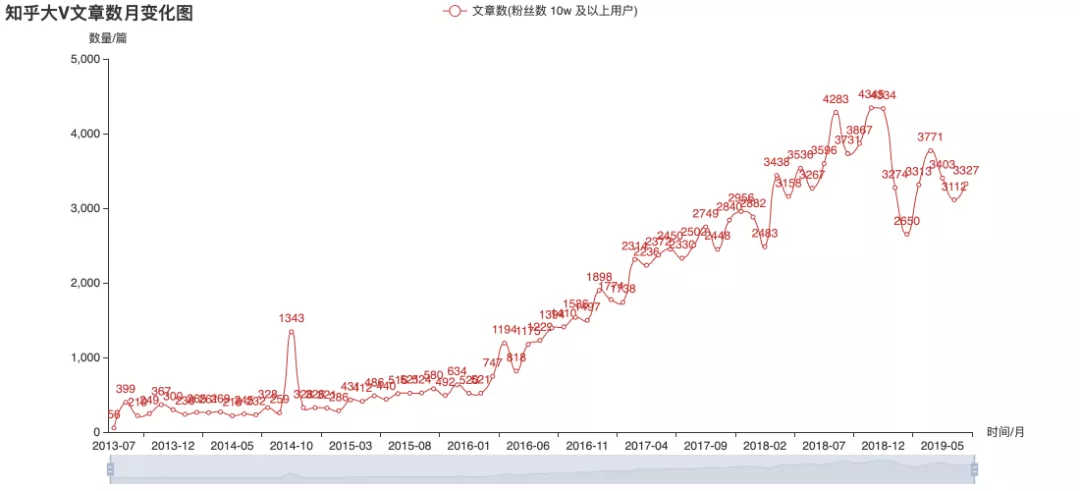
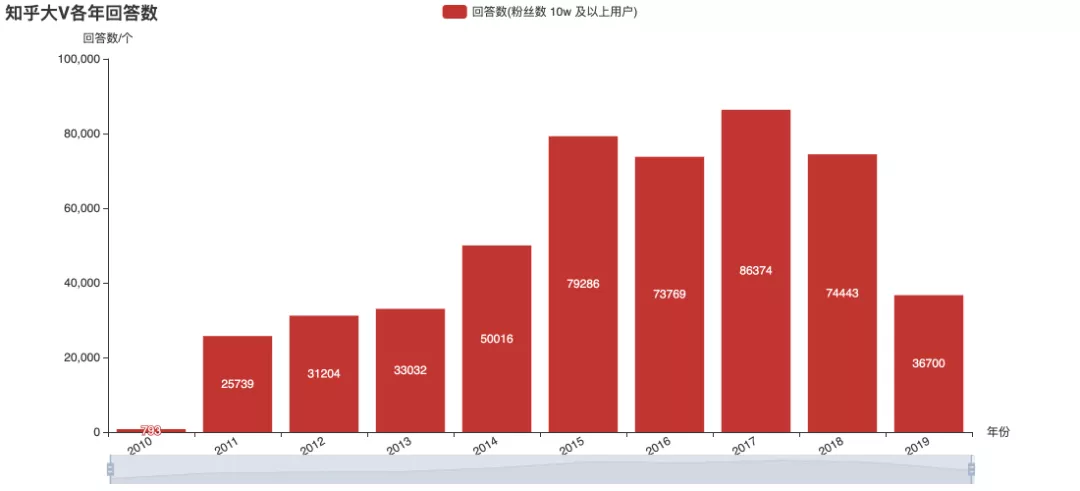
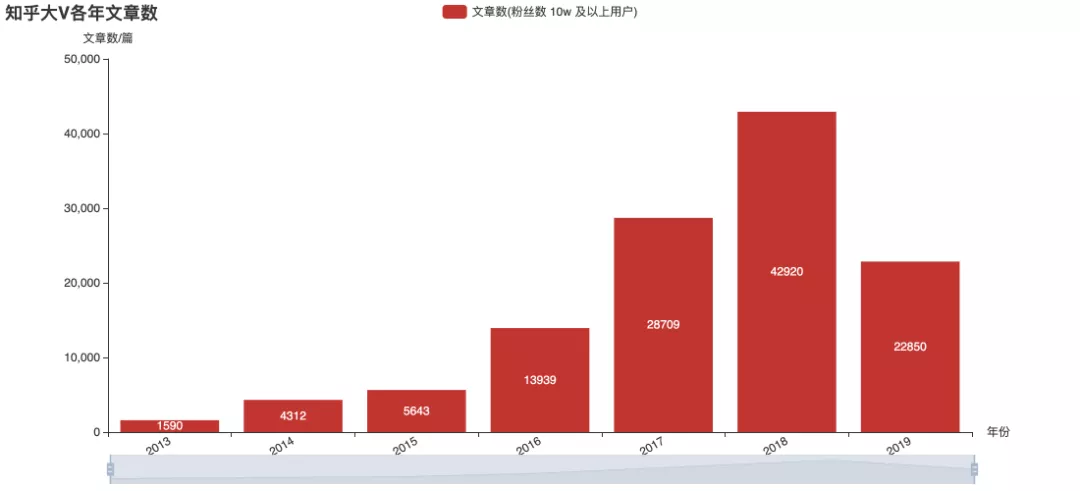
The above figures are statistics on the historical release data of over 100000 users currently concerned. From the picture, in 2015, the big V were more enthusiastic about answering, and later they mostly changed to write column articles. Judging from the trend, it seems that the frequency of big V's sending is no longer increasing. However, this can not directly infer the overall popularity of Zhihu, or the output of content may be more scattered among different users? This is the only way to have authoritative data.
What do users like to see?
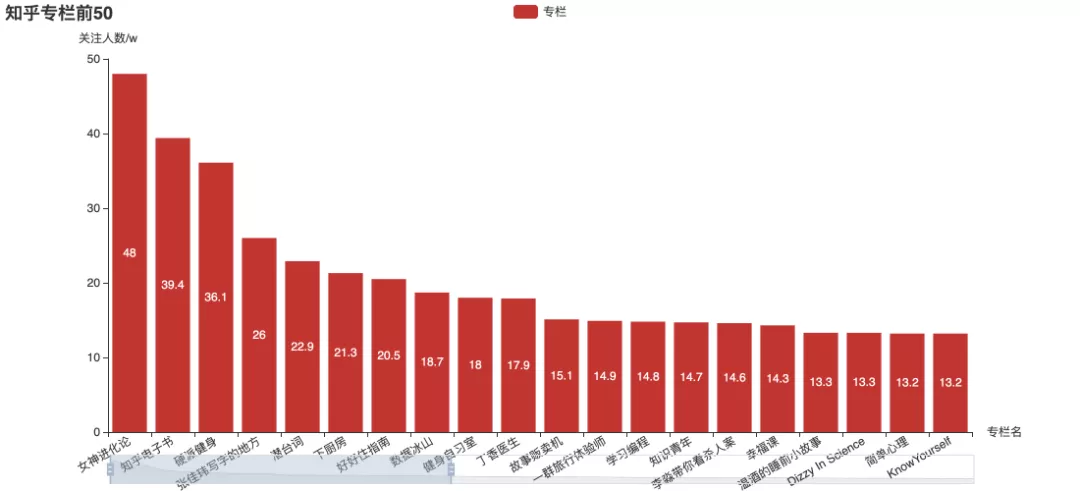
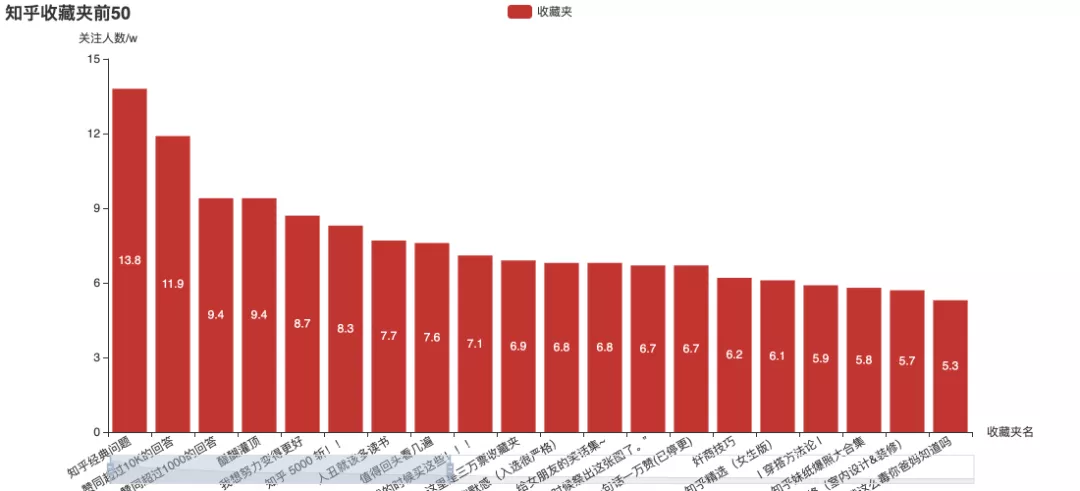
These columns and favorites with the highest attention, do you pay attention to them?
Finally, this is a word cloud created by focusing on personal profiles of more than 10000 users:

Code
1 # coding:utf8 2 # Number of fans grabbed is over 1 w user 3 import requests 4 import pymongo 5 import time 6 import pickle 7 8 def get_ready(ch='user_pd',dbname='test'): 9 '''Database call''' 10 global mycol, myclient,myhp 11 myclient = pymongo.MongoClient("mongodb://localhost:27017/") 12 mydb = myclient[dbname] 13 mycol = mydb[ch] 14 get_ready() 15 ss = mycol.find({}) 16 17 se = {1,} # De aggregation 18 se2 = ['GOUKI9999','zhang-jia-wei'] # Crawled list 19 # with open(r'C:\Users\yc\Desktop\used.txt', 'rb') as f: # read 20 # used = pickle.load(f) 21 used={1,} 22 sed = {} 23 for s in ss: 24 if s['follower_count']>=10000: # More than 10000 fans 25 sed[s['user_id']] = sed.get(s['user_id'],0) + 1 26 if sed[s['user_id']] == 1: 27 se.add(s['user_id']) 28 se2.append(s['user_id']) 29 leng = len(se2) 30 print(leng) 31 proxies = { 32 "http": "http://spiderbeg:pythonbe@106.52.85.210:8000", 33 "https": "http://spiderbeg:pythonbe@106.52.85.210:8000", 34 } 35 headers = { 36 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36', 37 'cookie':'your_cookie(User main page)' 38 } 39 for i,url_id in enumerate(se2): # Crawl 40 if i>=0: 41 print(i,' ', end='') # url Number 42 if url_id not in used: # Used or not 43 used.add(url_id) 44 nums = 500 45 off = 0 46 47 while True: 48 url2 = 'https://www.zhihu.com/api/v4/members/' + url_id + '/followees?include=data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset=' + str(off) + '&limit=' + str(nums) 49 r2 = requests.get(url2, headers=headers,proxies=proxies) 50 time.sleep(0.5) 51 c = 0 52 if 'error' in r2.json(): 53 if r2.json()['error']['code'] in {310000, 310001}: 54 break 55 else: 56 raise NameError('Page error') 57 used.add(url_id) # Determine whether to use 58 for d in r2.json()['data']: 59 z = {} 60 c+=1 61 z['user_id'] = d['url_token'] 62 z['name'] = d['name'] 63 z['headline'] = d['headline'] 64 z['follower_count'] = d['follower_count'] 65 z['answer_count'] = d['answer_count'] 66 z['articles_count'] = d['articles_count'] # if d['articles_count'] else 0 67 z['from'] = url_id # Whose list of concerns 68 if d['follower_count']>=10000 and d['url_token'] not in se and d['url_token'] not in used: # Fans greater than 1 w,Crawl 69 se.add(d['url_token']) 70 se2.append(d['url_token']) 71 mycol.insert_one(z) # insert data 72 if r2.json()["paging"]['is_end'] == False: 73 nums+=500 74 off+=500 75 elif r2.json()["paging"]['is_end'] == True: 76 break 77 else: 78 print(r2.json) 79 break