Recently there are crawler-related requirements, so I looked for a video (link in the end) on Station B and made a small program, which generally did not modify, but in the final storage, changed from txt to excel.
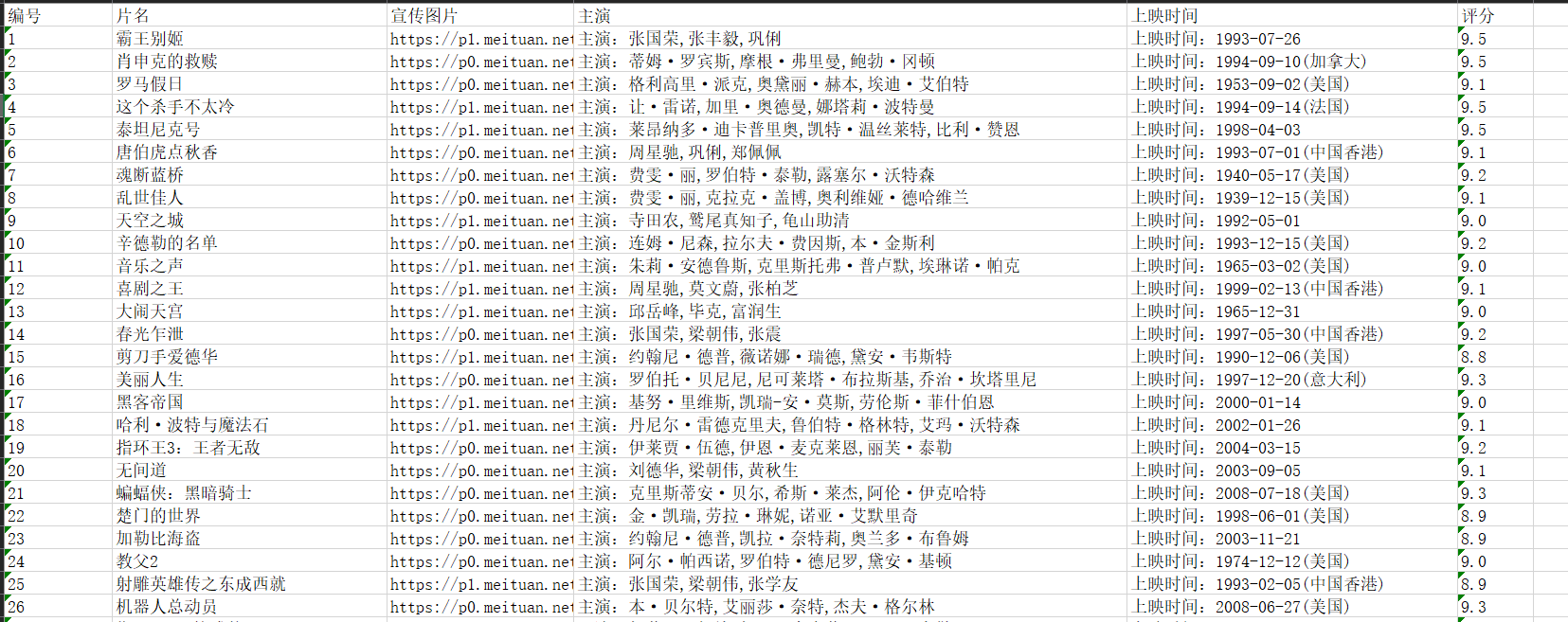
- Brief Requirements: Crawl Crawl Cat Eye Movie TOP100 List Data
- Use language: python
- Tools: PyCharm
- Involving libraries: requests, re, openpyxl (higher version excel operation library)
Implementation Code

1 # -*- coding: utf-8 -*- 2 # @Author : yocichen 3 # @Email : yocichen@126.com 4 # @File : MaoyanTop100.py 5 # @Software: PyCharm 6 # @Time : 2019/11/6 9:52 7 8 import requests 9 from requests import RequestException 10 import re 11 import openpyxl 12 13 # Get page's html by requests module 14 def get_one_page(url): 15 try: 16 headers = { 17 'user-agent':'Mozilla/5.0' 18 } 19 # use headers to avoid 403 Forbidden Error(reject spider) 20 response = requests.get(url, headers=headers) 21 if response.status_code == 200 : 22 return response.text 23 return None 24 except RequestException: 25 return None 26 27 # Get useful info from html of a page by re module 28 def parse_one_page(html): 29 pattern = re.compile('<dd>.*?board-index.*?>(\d+)<.*?<a.*?title="(.*?)"' 30 +'.*?data-src="(.*?)".*?</a>.*?star">[\\s]*(.*?)[\\n][\\s]*</p>.*?' 31 +'releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?' 32 +'fraction">(.*?)</i>.*?</dd>', re.S) 33 items = re.findall(pattern, html) 34 return items 35 36 # Main call function 37 def main(url): 38 page_html = get_one_page(url) 39 parse_res = parse_one_page(page_html) 40 return parse_res 41 42 # Write the useful info in excel(*.xlsx file) 43 def write_excel_xlsx(items): 44 wb = openpyxl.Workbook() 45 ws = wb.active 46 rows = len(items) 47 cols = len(items[0]) 48 # First, write col's title. 49 ws.cell(1, 1).value = 'number' 50 ws.cell(1, 2).value = 'title' 51 ws.cell(1, 3).value = 'Publicity Picture' 52 ws.cell(1, 4).value = 'To star' 53 ws.cell(1, 5).value = 'Show time' 54 ws.cell(1, 6).value = 'score' 55 # Write film's info 56 for i in range(0, rows): 57 for j in range(0, cols): 58 # print(items[i-1][j-1]) 59 if j != 5: 60 ws.cell(i+2, j+1).value = items[i][j] 61 else: 62 ws.cell(i+2, j+1).value = items[i][j]+items[i][j+1] 63 break 64 # Save the work book as *.xlsx 65 wb.save('maoyan_top100.xlsx') 66 67 if __name__ == '__main__': 68 res = [] 69 url = 'https://maoyan.com/board/4?' 70 for i in range(0, 10): 71 if i == 0: 72 res = main(url) 73 else: 74 newUrl = url+'offset='+str(i*10) 75 res.extend(main(newUrl)) 76 # test spider 77 # for item in res: 78 # print(item) 79 # test wirte to excel 80 # res = [ 81 # [1, 2, 3, 4, 9], 82 # [2, 3, 4, 5, 9], 83 # [4, 5, 6, 7, 9] 84 # ] 85 86 write_excel_xlsx(res)
Current results
Postnote
After getting started, you find that if you use regular expressions and requests libraries for data crawling, it is critical to analyze the structure of HTML pages and regular expressions, and all you have to do is replace the url.
Supplement an example of parsing HTML construction rules
Cat's Eye Classic Sci-fi by Rating
Review the elements and we will see that each item is in <dd>**</dd>format
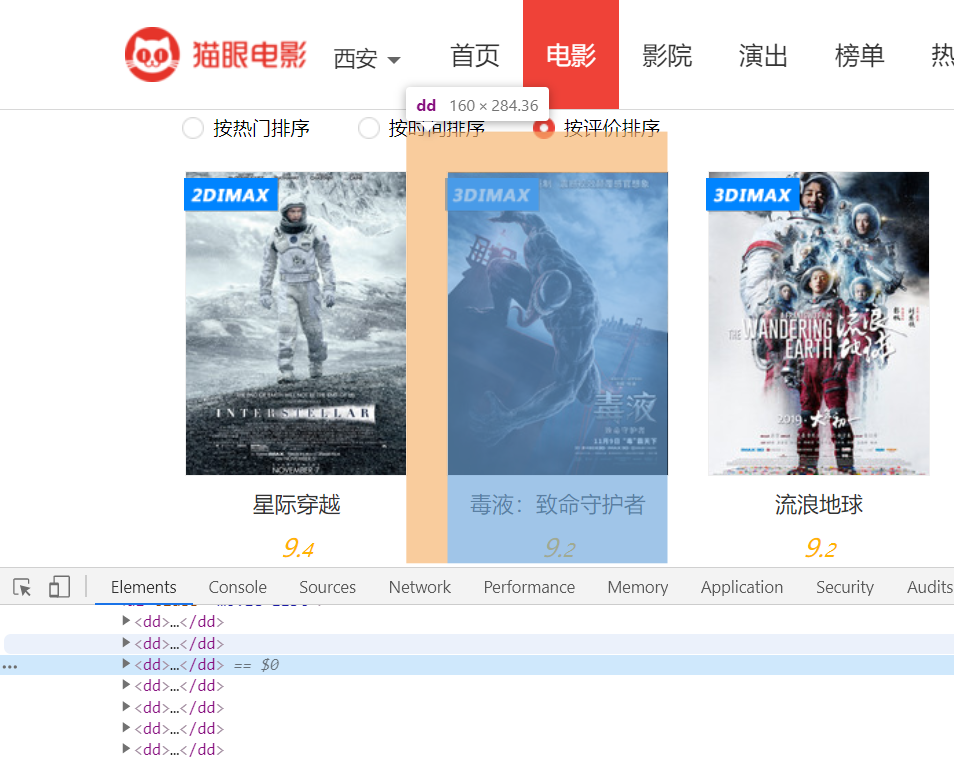
I want to get movie titles and ratings, first take out the HTML code and have a look

Try to construct a regular
'. *?<dd>. *? Movie-item-title. *? Title='(. *?)'>. *? Integer'>(. *?)<. *? Fraction'> (. *?)<. *?</dd>'(handwritten, unauthenticated)
Reference material
[Station B video 2018 latest Python 3.6 web crawler battle] https://www.bilibili.com/video/av19057145/?p=14
[Cat Eye Movie robots] https://maoyan.com/robots.txt (Better check it out before you climb, those that can't)