Preface
The text and pictures of the article are from the Internet, only for learning and communication, and do not have any commercial use. The copyright belongs to the original author. If you have any questions, please contact us in time for handling.
Author: Liu Quan @ CCIS Lab
PS: if you need Python learning materials, you can click the link below to get them by yourself
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
I. Analysis URL
1. Analyze Douban movie review URL
First of all, in Douban, find the movie "ice and snow 2" we want to climb

2. View Movie Reviews

II. Crawling comments
Analyze the source code of web page
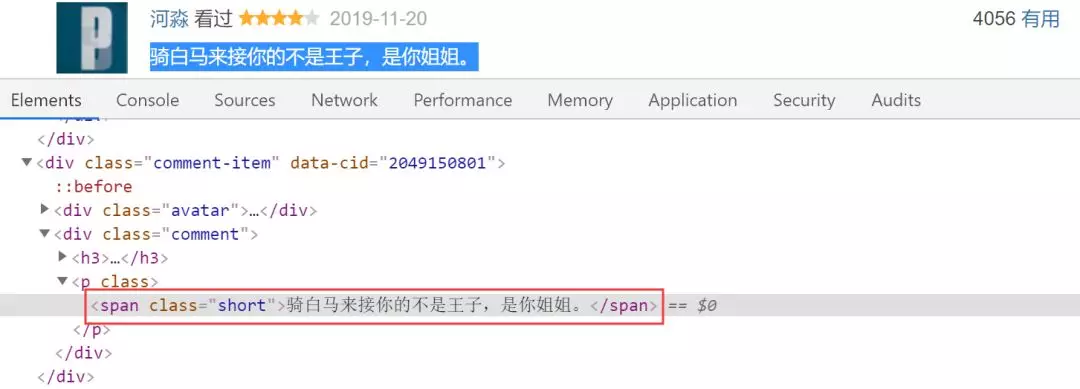
After analyzing the source code, you can see the comments in the < span class = "short" > tag, that is, the code is:
1 import urllib.request 2 from bs4 import BeautifulSoup 3 4 def getHtml(url): 5 """Obtain url page""" 6 headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'} 7 req = urllib.request.Request(url,headers=headers) 8 req = urllib.request.urlopen(req) 9 content = req.read().decode('utf-8') 10 return content 11 12 def getComment(url): 13 """analysis HTML page""" 14 html = getHtml(url) 15 soupComment = BeautifulSoup(html, 'html.parser') 16 comments = soupComment.findAll('span', 'short') 17 onePageComments = [] 18 for comment in comments: 19 onePageComments.append(comment.getText()+'\n') 20 return onePageComments 21 22 if __name__ == '__main__': 23 f = open('Ice and snow 2.txt', 'w', encoding='utf-8') 24 for page in range(10): # Douban crawling multi page comments need to be verified. 25 url = 'https://movie.douban.com/subject/25887288/comments?start=' + str(20*page) + '&limit=20&sort=new_score&status=P' 26 print('The first%s Page Reviews:' % (page+1)) 27 print(url + '\n') 28 for i in getComment(url): 29 f.write(i) 30 print(i) 31 print('\n')
Note here that users who are not logged in can only view the comments on the first ten pages. To crawl more comments, you need to simulate login first.
III. display of word cloud
After capturing the data, let's use word cloud to analyze the movie:
1. Use stammer participle
Because the movie reviews we download are paragraphs of text, and the word cloud we do is to count the number of words, so we need to segment first.
1 import matplotlib.pyplot as plt 2 from wordcloud import WordCloud 3 from scipy.misc import imread 4 import jieba 5 6 text = open("Ice and snow 2.txt","rb").read() 7 #Stuttering participle 8 wordlist = jieba.cut(text,cut_all=False) 9 wl = " ".join(wordlist)
2. Word cloud analysis
1 #Setting up word clouds 2 wc = WordCloud(background_color = "white", #Set background color 3 mask = imread('black_mask.png'), #Set background picture 4 max_words = 2000, #Set the maximum number of words to display 5 stopwords = ["Of", "such", "such", "still","Namely", "this", "No," , "One" , "What", "Film", "One part","First part", "Second parts"], #Set stop words 6 font_path = "C:\Windows\Fonts\simkai.ttf", # Set as regular script 7 #Set Chinese font so that word cloud can be displayed (default font of word cloud is“ DroidSansMono.ttf Font library ", does not support Chinese) 8 max_font_size = 60, #Set font maximum 9 random_state = 30, #Set how many randomly generated states are there, that is, how many color schemes are there 10 ) 11 myword = wc.generate(wl)#Generative word cloud 12 wc.to_file('result.png') 13 14 #Cloud map of exhibition words 15 plt.imshow(myword) 16 plt.axis("off") 17 plt.show()
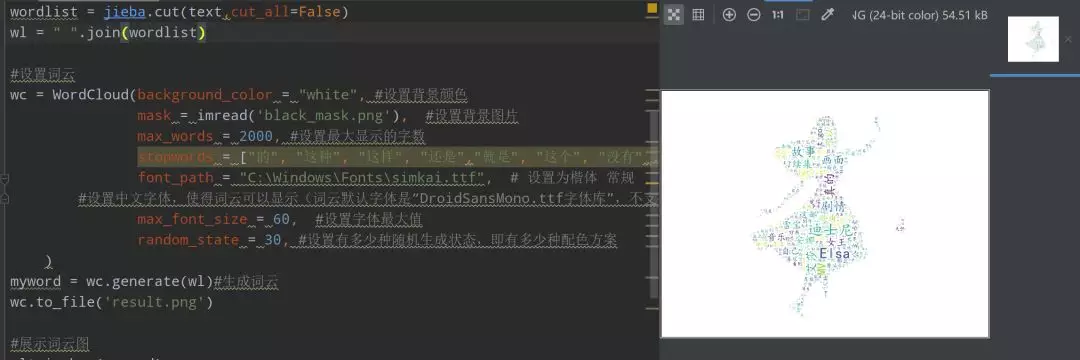 Final result:
Final result:  .
.