Python crawls the novel of the New Pen Fun Pavilion and saves it in the TXT file
This article I wrote is a program written by Python crawling fiction, which is the first program I wrote independently among Python crawlers. I also encountered some difficulties in the middle, but finally solved it. This program is very simple, the program is probably to first obtain the source code of the page, and then extract the url of each chapter in the source code of the page, after obtaining, through each url to get the content of the article, in the extraction of content, and then save to the local, a TXT file type to save.
Probably so.
1: Get the source code of the web page
2: Get URLs for each chapter
3: Get the content of each chapter
4: Download and save files
1. First of all, install the third-party library requests, which opens cmd and enters pip install requests to return to the train, waiting for installation. Then test
2. Then you can write a program. First, you can get the source code of the web page. You can also view and compare it in the browser.
s = requests.Session() url = 'https://www.xxbiquge.com/2_2634/' # Here you can change the url of the novel you want to crawl html = s.get(url) html.encoding = 'utf-8' print(html.text) #Get the source code of the web page
Display the source code of the web page after running
Press F12 to view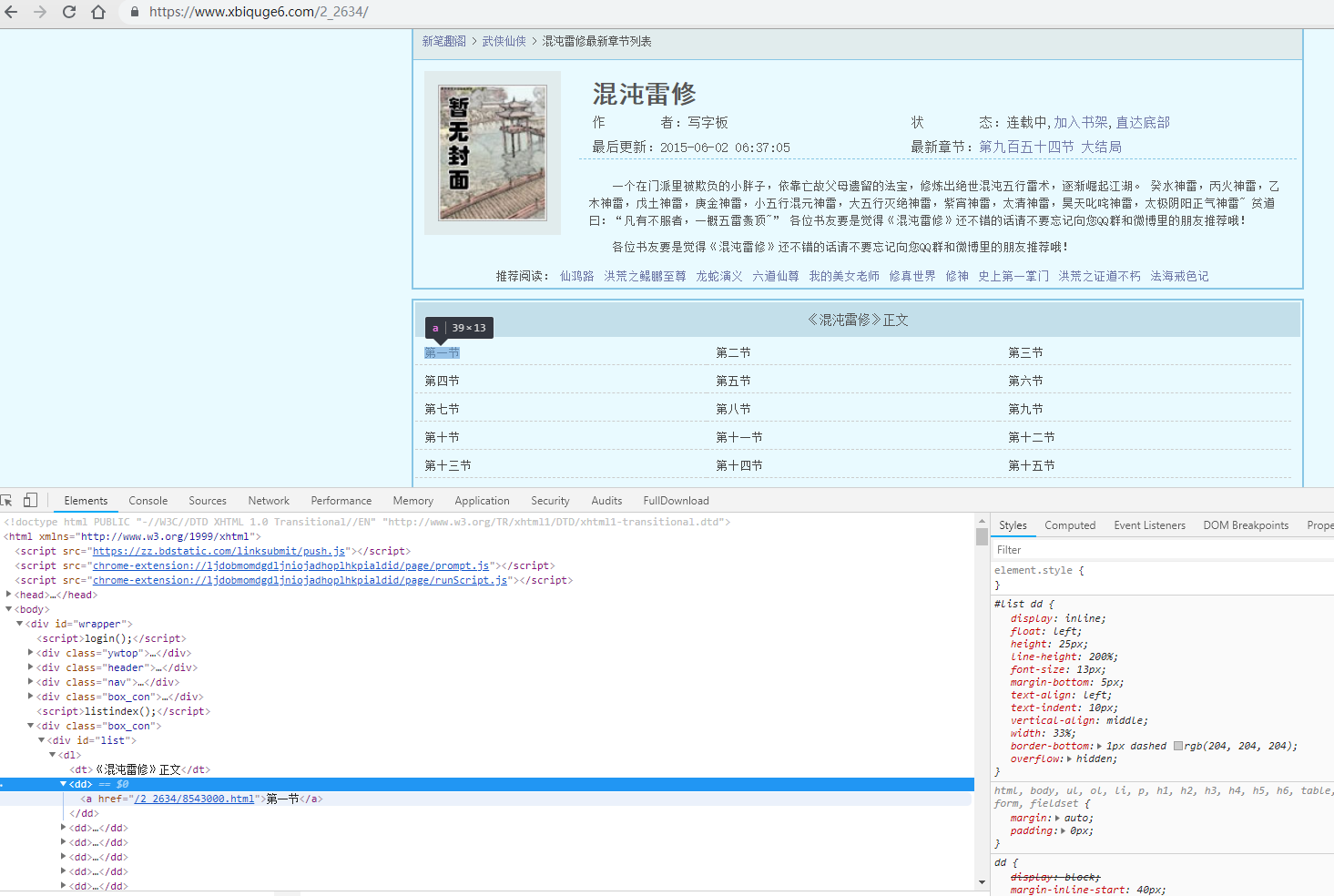
That's right.
3. Then extract the url of each chapter in the source code of the web page.
caption_title_1 = re.findall(r'<a href="(/2_2634/.*?\.html)">.*?</a>',html.text) print(caption_title_1)

Because there are too many, cut these, see these URLs, you may want to ask why they are not complete, because the page is not complete, need to be patched together to get a complete url.
for i in caption_title_1: caption_title_1 = 'https://www.xxbiquge.com'+i
That's done, and it's complete.
4. Here's how to get the title and content of the chapter
#Get chapter names
name = re.findall(r'<meta name="keywords" content="(.*?)" />',r1.text)[0] # Extract chapter names
print(name)
file_name.write(name)
file_name.write('\n')
# Getting Chapter Content
chapters = re.findall(r'<div id="content">(.*?)</div>',r1.text,re.S)[0] #Extracting Chapter Contents
chapters = chapters.replace(' ', '') # Then there's data cleaning.
chapters = chapters.replace('readx();', '')
chapters = chapters.replace('& lt;!--go - - & gt;', '')
chapters = chapters.replace('<!--go-->', '')
chapters = chapters.replace('()', '')
5. Converting strings and saving files
# Conversion string
s = str(chapters)
s_replace = s.replace('<br/>',"\n")
while True:
index_begin = s_replace.find("<")
index_end = s_replace.find(">",index_begin+1)
if index_begin == -1:
break
s_replace = s_replace.replace(s_replace[index_begin:index_end+1],"")
pattern = re.compile(r' ',re.I)
fiction = pattern.sub(' ',s_replace)
file_name.write(fiction)
file_name.write('\n')
6. Complete code
import requests import re s = requests.Session() url = 'https://www.xxbiquge.com/2_2634/' html = s.get(url) html.encoding = 'utf-8' # Get chapters caption_title_1 = re.findall(r'<a href="(/2_2634/.*?\.html)">.*?</a>',html.text) # Writing file path = r'C:\Users\Administrator\PycharmProjects\untitled\title.txt' # This is where I store it. You can change it. file_name = open(path,'a',encoding='utf-8') # Loop down each one for i in caption_title_1: caption_title_1 = 'https://www.xxbiquge.com'+i # Web source code s1 = requests.Session() r1 = s1.get(caption_title_1) r1.encoding = 'utf-8' # Get chapter names name = re.findall(r'<meta name="keywords" content="(.*?)" />',r1.text)[0] print(name) file_name.write(name) file_name.write('\n') # Getting Chapter Content chapters = re.findall(r'<div id="content">(.*?)</div>',r1.text,re.S)[0] chapters = chapters.replace(' ', '') chapters = chapters.replace('readx();', '') chapters = chapters.replace('& lt;!--go - - & gt;', '') chapters = chapters.replace('<!--go-->', '') chapters = chapters.replace('()', '') # Conversion string s = str(chapters) s_replace = s.replace('<br/>',"\n") while True: index_begin = s_replace.find("<") index_end = s_replace.find(">",index_begin+1) if index_begin == -1: break s_replace = s_replace.replace(s_replace[index_begin:index_end+1],"") pattern = re.compile(r' ',re.I) fiction = pattern.sub(' ',s_replace) file_name.write(fiction) file_name.write('\n') file_name.close()
7. Modify the url you want to crawl the novel and run it again. If there is an error, it may be the location of the file. You can save the file address and change it to the address you want to store, and then it's over.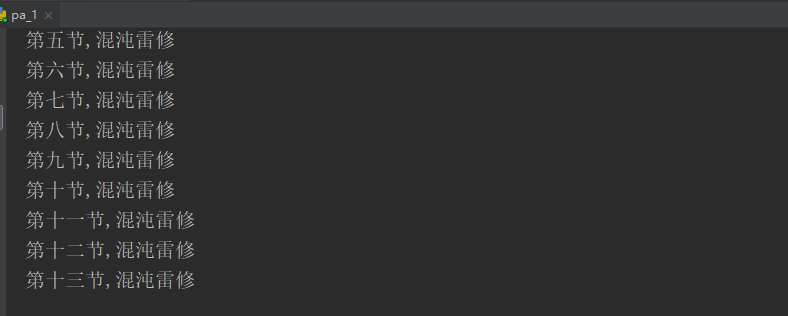

This is the complete novel crawling, is it simple, hope to help you?