Crawling Top 100 cat's eye movies After that, I will climb the book information of Douban (mainly the information, score and proportion of the book, but not the comments). Original, reprint please contact me.
Requirement: crawling all books under a certain type of label of Douban
Language: python
Support library:
- Regular, parse and search: re, requests, bs4, lxml (the latter three need to be installed)
- Random number: time, random
Step: three steps
- Visit the label page for links to all books under the label
- Visit the book links one by one to get the book information and scores
- Persistent storage of book information (excel is used here, database can be used)
I. visit the label page to get the links of all books under the label
As usual, let's take a look first Robots.txt of Douban , cannot crawl prohibited content.
The tag page we are going to crawl in this step, take the novel as an example https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4
Let's take a look at its HTML structure
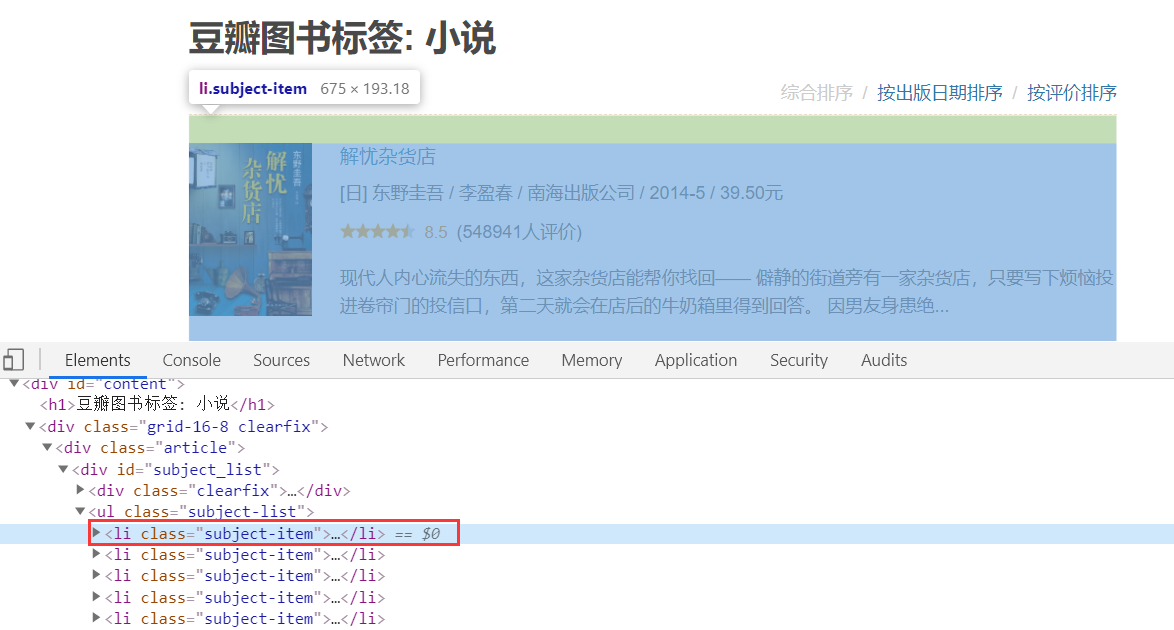
Find that every book is in a < li > tag, and all we need is a link to that picture (that is, a link to the book page)

In this way, you can write regular or use BS4 (beautiful soup) to get links to books.
As you can see, each page only displays 20 books, so you need to traverse all pages, and its page links are regular.
Second pages: https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4?start=20&type=T
Third pages: https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4?start=40&type=T
That is to say: start will increase by 20 every time.
Here's the code:
1 # -*- coding: utf-8 -*- 2 # @Author : yocichen 3 # @Email : yocichen@126.com 4 # @File : labelListBooks.py 5 # @Software: PyCharm 6 # @Time : 2019/11/11 20:10 7 8 import re 9 import openpyxl 10 import requests 11 from requests import RequestException 12 from bs4 import BeautifulSoup 13 import lxml 14 import time 15 import random 16 17 src_list = [] 18 19 def get_one_page(url): 20 ''' 21 Get the html of a page by requests module 22 :param url: page url 23 :return: html / None 24 ''' 25 try: 26 head = ['Mozilla/5.0', 'Chrome/78.0.3904.97', 'Safari/537.36'] 27 headers = { 28 'user-agent':head[random.randint(0, 2)] 29 } 30 response = requests.get(url, headers=headers, proxies={'http':'171.15.65.195:9999'}) # The proxy here can be set or not added. If it fails, it can be replaced or not added 31 if response.status_code == 200: 32 return response.text 33 return None 34 except RequestException: 35 return None 36 37 def get_page_src(html, selector): 38 ''' 39 Get book's src from label page 40 :param html: book 41 :param selector: src selector 42 :return: src(list) 43 ''' 44 # html = get_one_page(url) 45 if html is not None: 46 soup = BeautifulSoup(html, 'lxml') 47 res = soup.select(selector) 48 pattern = re.compile('href="(.*?)"', re.S) 49 src = re.findall(pattern, str(res)) 50 return src 51 else: 52 return [] 53 54 def write_excel_xlsx(items, file): 55 ''' 56 Write the useful info into excel(*.xlsx file) 57 :param items: book's info 58 :param file: memory excel file 59 :return: the num of successful item 60 ''' 61 wb = openpyxl.load_workbook(file) 62 ws = wb.worksheets[0] 63 sheet_row = ws.max_row 64 item_num = len(items) 65 # Write film's info 66 for i in range(0, item_num): 67 ws.cell(sheet_row+i+1, 1).value = items[i] 68 # Save the work book as *.xlsx 69 wb.save(file) 70 return item_num 71 72 if __name__ == '__main__': 73 total = 0 74 for page_index in range(0, 50): # Why 50 pages here? Douban seems to have many pages, but there is no data after it is accessed. Currently, there are only 50 pages to access. 75 # novel label src : https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4?start= 76 # program label src : https://book.douban.com/tag/%E7%BC%96%E7%A8%8B?start= 77 # computer label src : https://book.douban.com/tag/%E8%AE%A1%E7%AE%97%E6%9C%BA?start= 78 # masterpiece label src : https://book.douban.com/tag/%E5%90%8D%E8%91%97?start= 79 url = 'https://book.douban.com/tag/%E5%90%8D%E8%91%97?start='+str(page_index*20)+'&type=T' # All you have to do is replace the front part of the URL with the corresponding part of all the tags you climb, specifically the red bold text part. 80 one_loop_done = 0 81 # only get html page once 82 html = get_one_page(url) 83 for book_index in range(1, 21): 84 selector = '#subject_list > ul > li:nth-child('+str(book_index)+') > div.info > h2' 85 src = get_page_src(html, selector) 86 row = write_excel_xlsx(src, 'masterpiece_books_src.xlsx') # To store files, you need to create them first 87 one_loop_done += row 88 total += one_loop_done 89 print(one_loop_done, 'done') 90 print('Total', total, 'done')
The annotation is clear. First get the page HTML, regular or bs4 traverse to get the book links in each page, and save them in excel file.
Note: if you need to use my code directly, you only need to look at the link of that label page, and then replace the red bold part (Chinese label code), as well as create an excel file to store the crawled Book link.
2. Visit the book links one by one and crawl the book information and scores
In the previous step, we have climbed to the src of all books under the novel label. This step is to visit the src of books one by one, and then crawl the specific information of books.
First look at the HTML structure of the information to be crawled
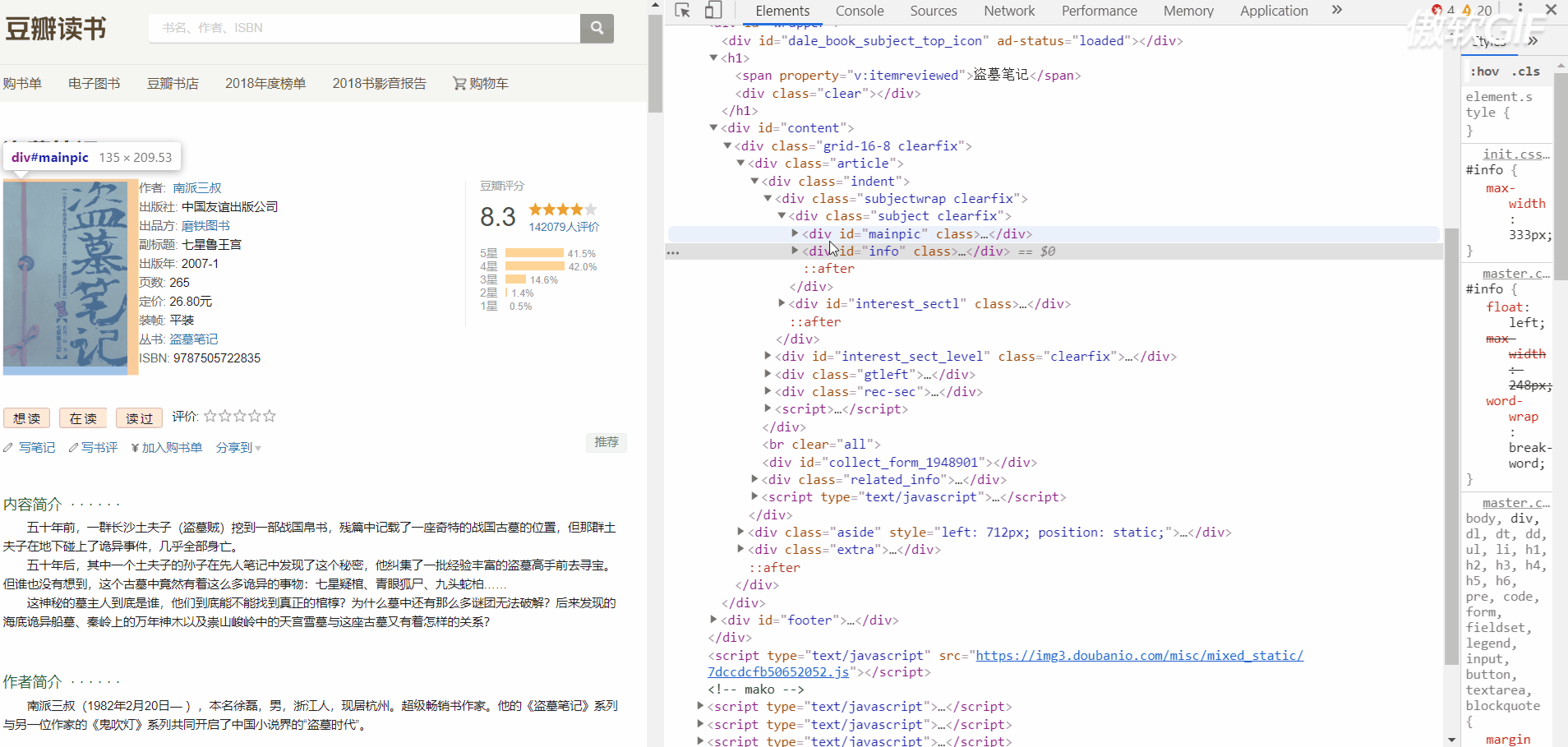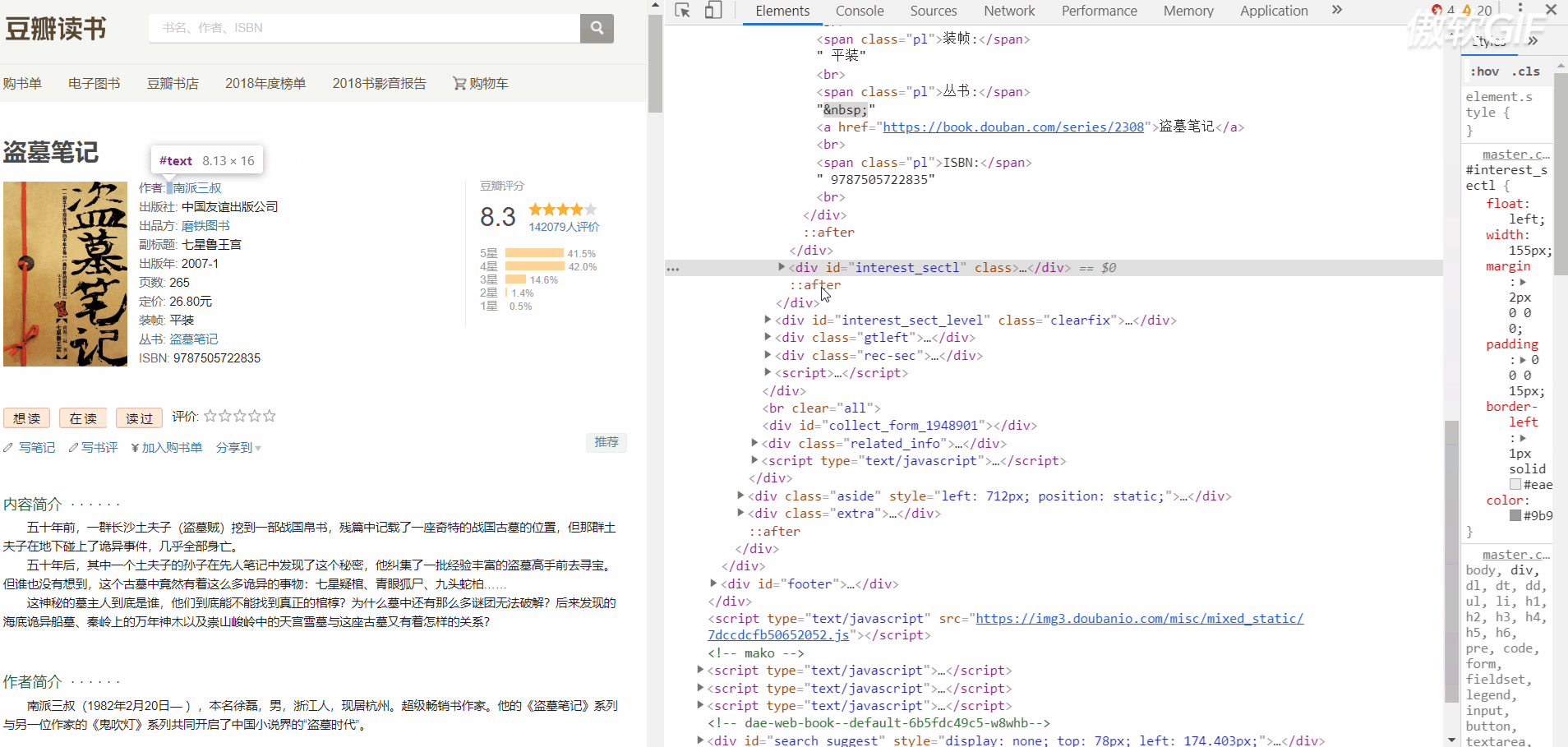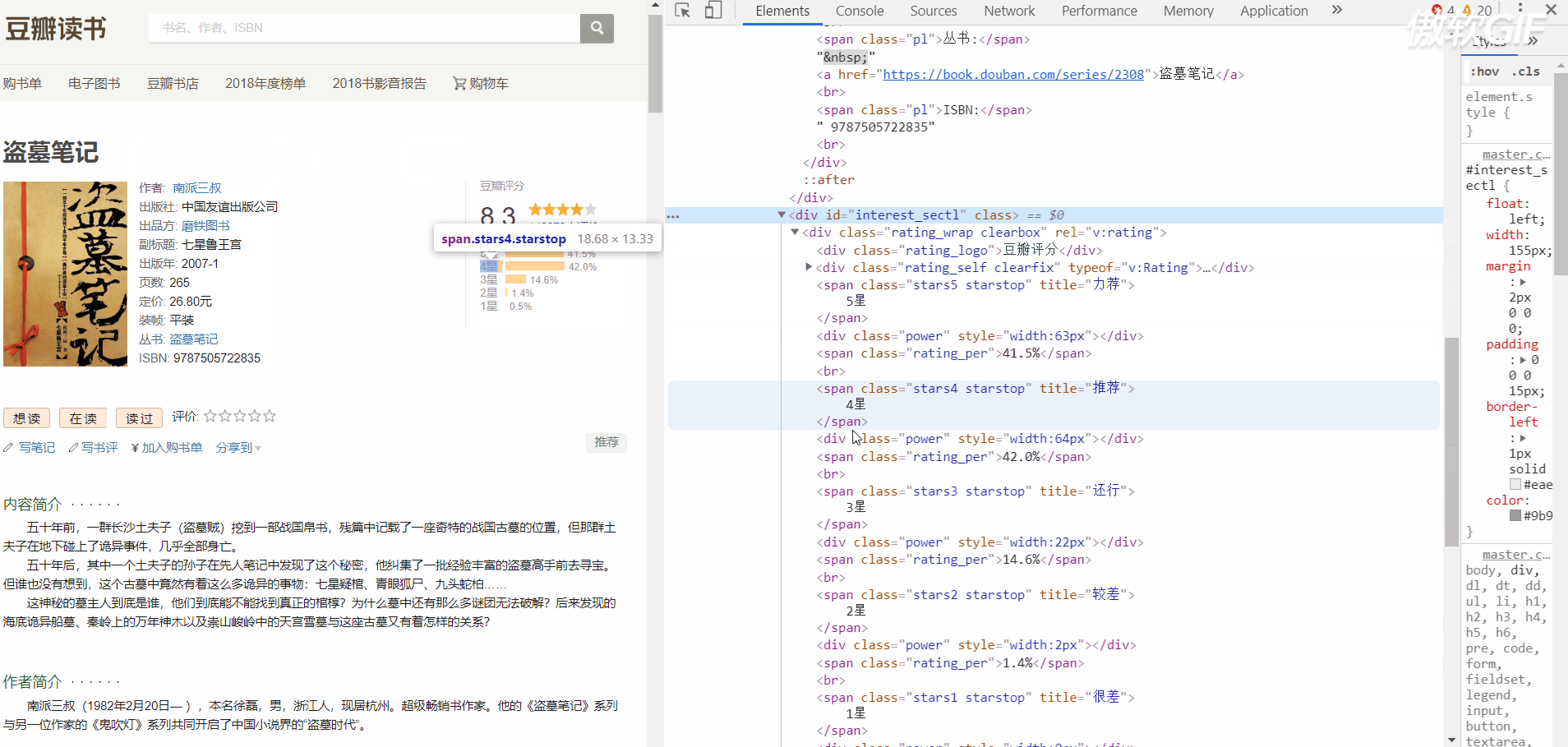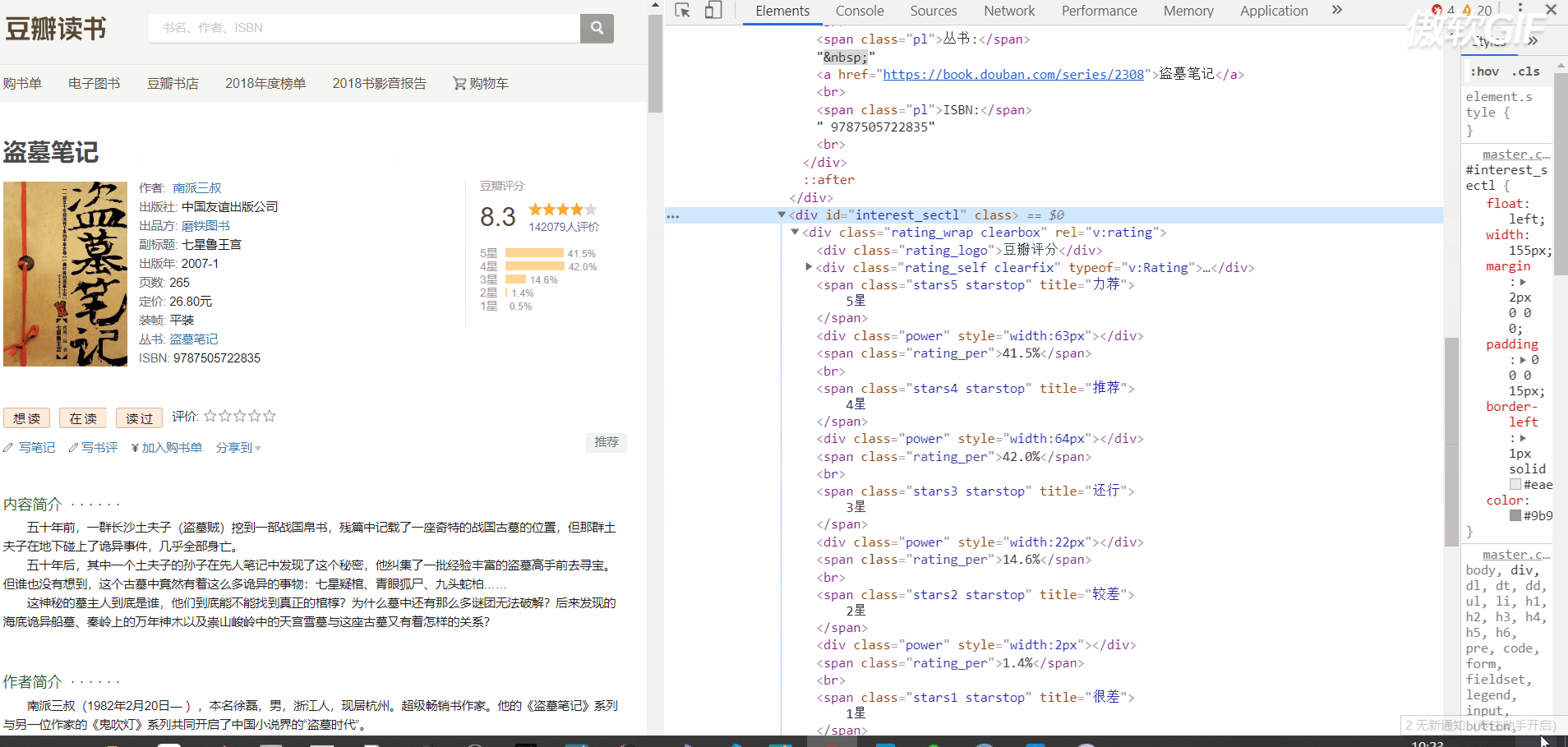
Here is the book information page structure
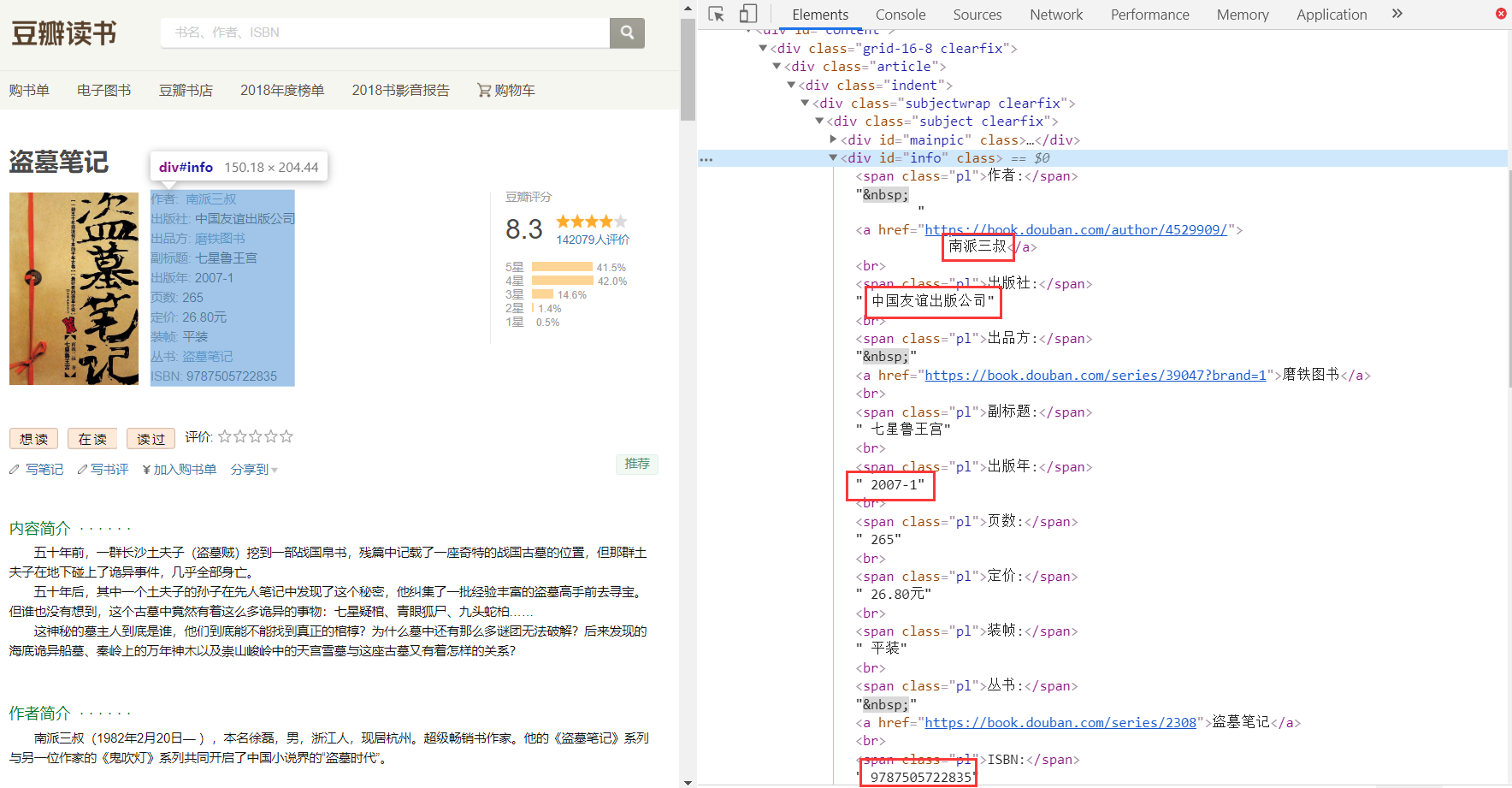
Score page structure
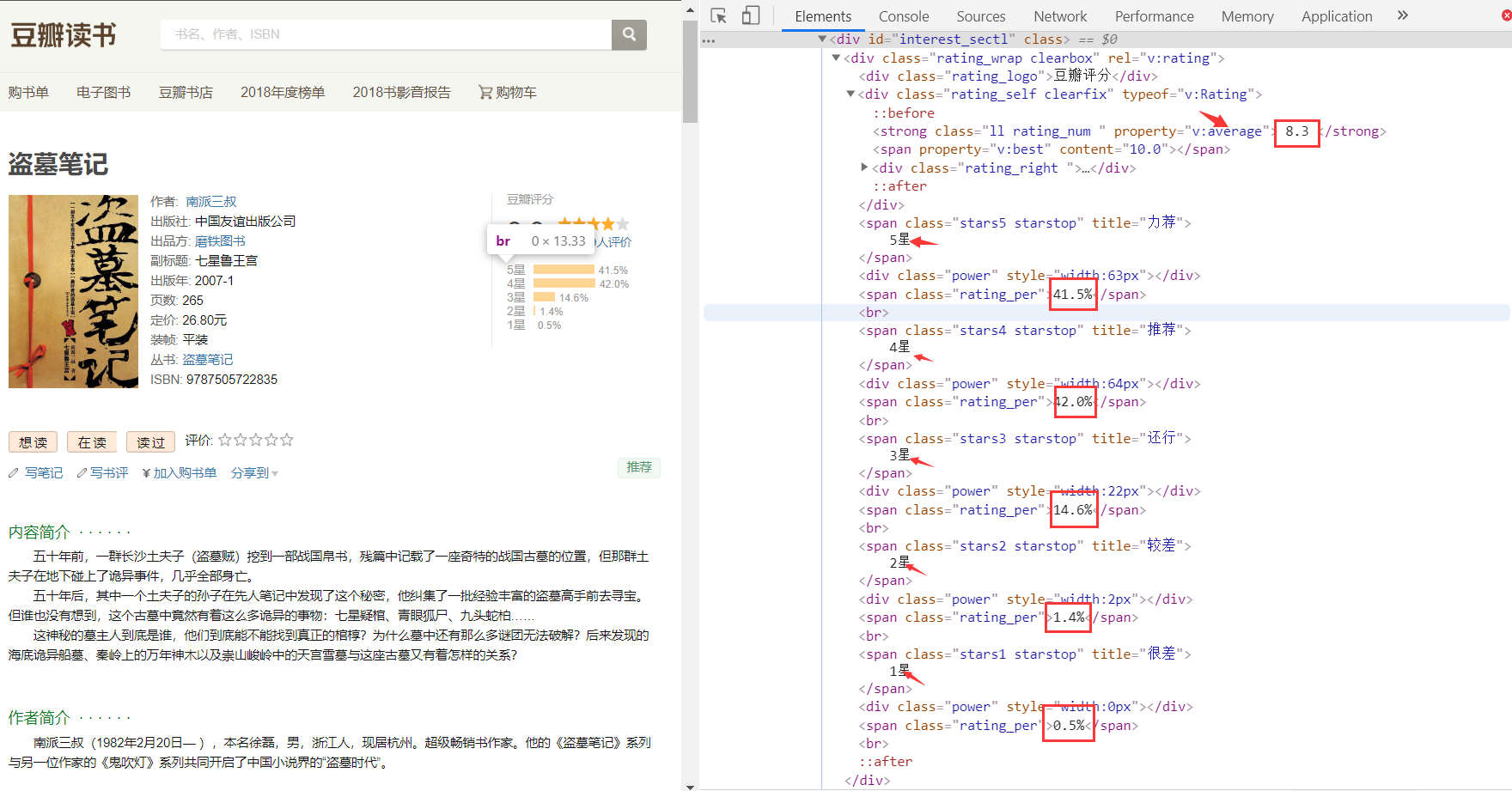
In this way, we can use regular expressions and bs4 library to match the data we need. (try to be pure and regular. It's hard to write. It doesn't work.)
Look at the code below
1 # -*- coding: utf-8 -*- 2 # @Author : yocichen 3 # @Email : yocichen@126.com 4 # @File : doubanBooks.py 5 # @Software: PyCharm 6 # @Time : 2019/11/9 11:38 7 8 import re 9 import openpyxl 10 import requests 11 from requests import RequestException 12 from bs4 import BeautifulSoup 13 import lxml 14 import time 15 import random 16 17 def get_one_page(url): 18 ''' 19 Get the html of a page by requests module 20 :param url: page url 21 :return: html / None 22 ''' 23 try: 24 head = ['Mozilla/5.0', 'Chrome/78.0.3904.97', 'Safari/537.36'] 25 headers = { 26 'user-agent':head[random.randint(0, 2)] 27 } 28 response = requests.get(url, headers=headers) #, proxies={'http':'171.15.65.195:9999'} 29 if response.status_code == 200: 30 return response.text 31 return None 32 except RequestException: 33 return None 34 35 def get_request_res(pattern_text, html): 36 ''' 37 Get the book info by re module 38 :param pattern_text: re pattern 39 :param html: page's html text 40 :return: book's info 41 ''' 42 pattern = re.compile(pattern_text, re.S) 43 res = re.findall(pattern, html) 44 if len(res) > 0: 45 return res[0].split('<', 1)[0][1:] 46 else: 47 return 'NULL' 48 49 def get_bs_res(selector, html): 50 ''' 51 Get the book info by bs4 module 52 :param selector: info selector 53 :param html: page's html text 54 :return: book's info 55 ''' 56 soup = BeautifulSoup(html, 'lxml') 57 res = soup.select(selector) 58 # if res is not None or len(res) is not 0: 59 # return res[0].string 60 # else: 61 # return 'NULL' 62 if res is None: 63 return 'NULL' 64 elif len(res) == 0: 65 return 'NULL' 66 else: 67 return res[0].string 68 69 # Get other info by bs module 70 def get_bs_img_res(selector, html): 71 soup = BeautifulSoup(html, 'lxml') 72 res = soup.select(selector) 73 if len(res) is not 0: 74 return str(res[0]) 75 else: 76 return 'NULL' 77 78 def parse_one_page(html): 79 ''' 80 Parse the useful info of html by re module 81 :param html: page's html text 82 :return: all of book info(dict) 83 ''' 84 book_info = {} 85 book_name = get_bs_res('div > h1 > span', html) 86 # print('Book-name', book_name) 87 book_info['Book_name'] = book_name 88 # info > a:nth-child(2) 89 author = get_bs_res('div > span:nth-child(1) > a', html) 90 if author is None: 91 author = get_bs_res('#info > a:nth-child(2)', html) 92 # print('Author', author) 93 author = author.replace(" ", "") 94 author = author.replace("\n", "") 95 book_info['Author'] = author 96 97 publisher = get_request_res(u'Press:</span>(.*?)<br/>', html) 98 # print('Publisher', publisher) 99 book_info['publisher'] = publisher 100 101 publish_time = get_request_res(u'Year of publication:</span>(.*?)<br/>', html) 102 # print('Publish-time', publish_time) 103 book_info['publish_time'] = publish_time 104 105 ISBN = get_request_res(u'ISBN:</span>(.*?)<br/>', html) 106 # print('ISBN', ISBN) 107 book_info['ISBN'] = ISBN 108 109 img_label = get_bs_img_res('#mainpic > a > img', html) 110 pattern = re.compile('src="(.*?)"', re.S) 111 img = re.findall(pattern, img_label) 112 if len(img) is not 0: 113 # print('img-src', img[0]) 114 book_info['img_src'] = img[0] 115 else: 116 # print('src not found') 117 book_info['img_src'] = 'NULL' 118 119 book_intro = get_bs_res('#link-report > div:nth-child(1) > div > p', html) 120 # print('book introduction', book_intro) 121 book_info['book_intro'] = book_intro 122 123 author_intro = get_bs_res('#content > div > div.article > div.related_info > div:nth-child(4) > div > div > p', html) 124 # print('author introduction', author_intro) 125 book_info['author_intro'] = author_intro 126 127 grade = get_bs_res('div > div.rating_self.clearfix > strong', html) 128 if len(grade) == 1: 129 # print('Score no mark') 130 book_info['Score'] = 'NULL' 131 else: 132 # print('Score', grade[1:]) 133 book_info['Score'] = grade[1:] 134 135 comment_num = get_bs_res('#interest_sectl > div > div.rating_self.clearfix > div > div.rating_sum > span > a > span', html) 136 # print('commments', comment_num) 137 book_info['commments'] = comment_num 138 139 five_stars = get_bs_res('#interest_sectl > div > span:nth-child(5)', html) 140 # print('5-stars', five_stars) 141 book_info['5_stars'] = five_stars 142 143 four_stars = get_bs_res('#interest_sectl > div > span:nth-child(9)', html) 144 # print('4-stars', four_stars) 145 book_info['4_stars'] = four_stars 146 147 three_stars = get_bs_res('#interest_sectl > div > span:nth-child(13)', html) 148 # print('3-stars', three_stars) 149 book_info['3_stars'] = three_stars 150 151 two_stars = get_bs_res('#interest_sectl > div > span:nth-child(17)', html) 152 # print('2-stars', two_stars) 153 book_info['2_stars'] = two_stars 154 155 one_stars = get_bs_res('#interest_sectl > div > span:nth-child(21)', html) 156 # print('1-stars', one_stars) 157 book_info['1_stars'] = one_stars 158 159 return book_info 160 161 def write_bookinfo_excel(book_info, file): 162 ''' 163 Write book info into excel file 164 :param book_info: a dict 165 :param file: memory excel file 166 :return: the num of successful item 167 ''' 168 wb = openpyxl.load_workbook(file) 169 ws = wb.worksheets[0] 170 sheet_row = ws.max_row 171 sheet_col = ws.max_column 172 i = sheet_row 173 j = 1 174 for key in book_info: 175 ws.cell(i+1, j).value = book_info[key] 176 j += 1 177 done = ws.max_row - sheet_row 178 wb.save(file) 179 return done 180 181 def read_booksrc_get_info(src_file, info_file): 182 ''' 183 Read the src file and access each src, parse html and write info into file 184 :param src_file: src file 185 :param info_file: memory file 186 :return: the num of successful item 187 ''' 188 wb = openpyxl.load_workbook(src_file) 189 ws = wb.worksheets[0] 190 row = ws.max_row 191 done = 0 192 for i in range(868, row+1): 193 src = ws.cell(i, 1).value 194 if src is None: 195 continue 196 html = get_one_page(str(src)) 197 book_info = parse_one_page(html) 198 done += write_bookinfo_excel(book_info, info_file) 199 if done % 10 == 0: 200 print(done, 'done') 201 return done 202 203 if __name__ == '__main__': 204 # url = 'https://book.douban.com/subject/1770782/' 205 # html = get_one_page(url) 206 # # print(html) 207 # book_info = parse_one_page(html) 208 # print(book_info) 209 # res = write_bookinfo_excel(book_info, 'novel_books_info.xlsx') 210 # print(res, 'done') 211 res = read_booksrc_get_info('masterpiece_books_src.xlsx', 'masterpiece_books_info.xlsx') # Read src file, storage file to write book information 212 print(res, 'done')
Note: if you want to use it directly, all you need to do is give parameters. The first is the src file obtained in the previous step. The second is the file that needs to store book information (you need to create it in advance)
III. persistent storage of book information (Excel)
Using Excel to store the src list of books and the specific information of books needs to use openpyxl library to read and write excel. The code is in the write * / read * function above.
Effect
src of Novels
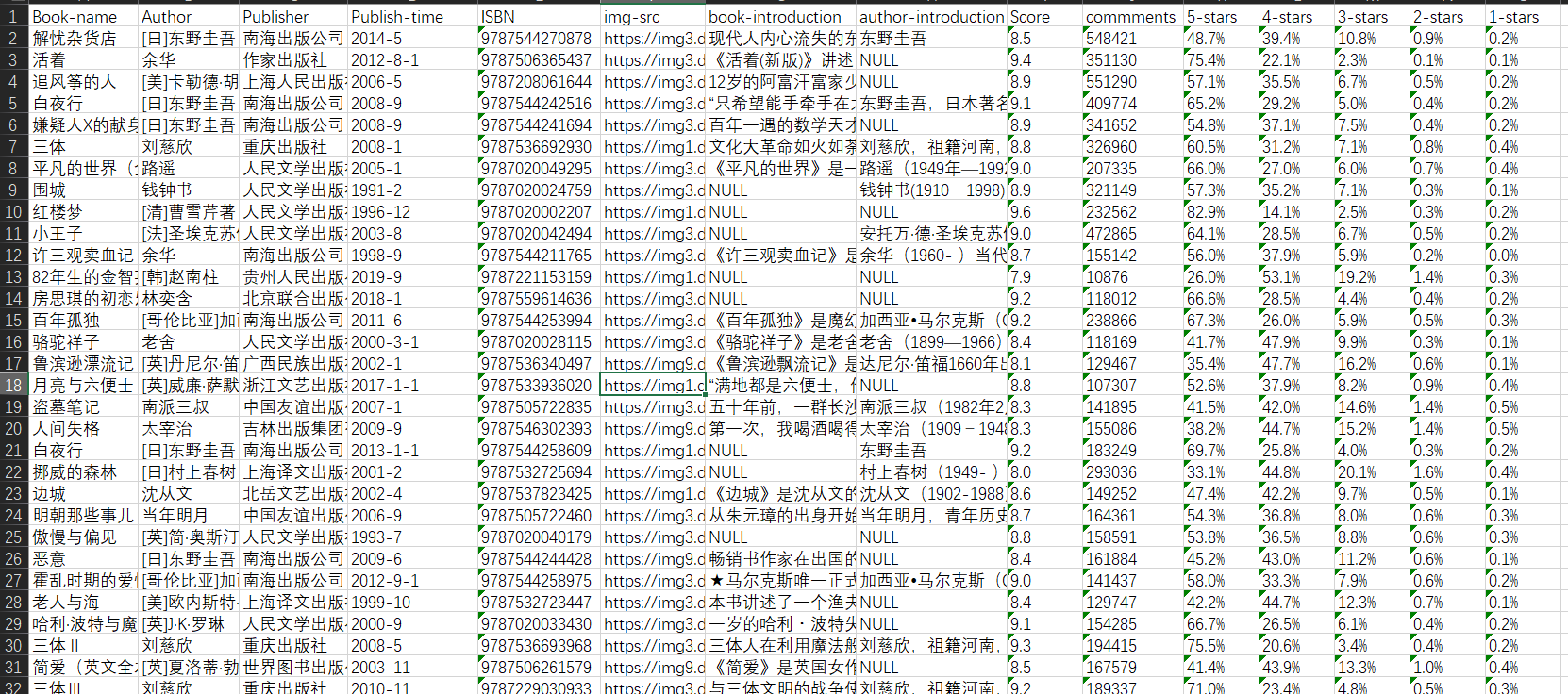
Details of the books you crawled to
Epilogue
It to ok about two days before and after writing this. The work that the crawler has to do is more detailed. It needs to analyze HTML pages and write regular expressions. In other words, it's really simple to use bs4. You only need to copy the selector, which can greatly improve the efficiency. In addition, single thread crawlers are stupid. There are many deficiencies (such as irregular code, not robust enough), welcome to correct.
Reference material
[1] Douban robots.txt https://www.douban.com/robots.txt
[2]https://blog.csdn.net/jerrygaoling/article/details/81051447
[3]https://blog.csdn.net/zhangfn2011/article/details/7821642