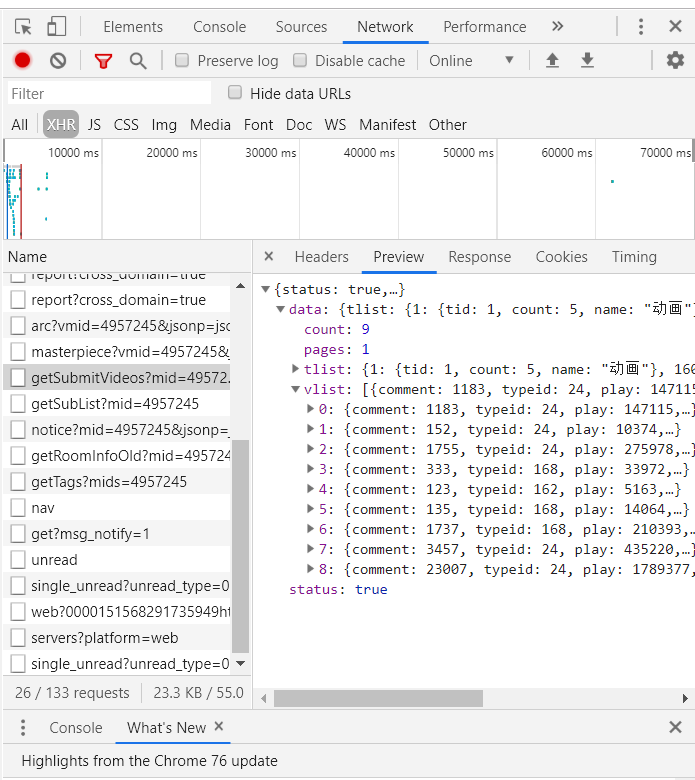
It is not difficult to climb the barrage of station b. To get all of the up master video curtains, we first go to the up master video page, that is, the up master video page. https://space.bilibili.com/id/video This page. Press F12 to open the developer menu and refresh it. There is a getSubmitVideo file in the xhr file of the network. This file has the Video av number we need. If you crawl the page directly, you can't get it, because the video is loaded asynchronously.
Under the data tag in this file, there is a count which is the total number of videos, pages which are pages, vlist is the video information we are looking for, and the AIDS in it is the AV number of each video. Its request link is https://space.bilibilibili.com/ajax/member/getSubmitVideos?Mid=av number&pagesize=30&tid=0&page=1&keyword=&order=pubdate. PageSize is how many video messages are transmitted at a time.
After we get all the Video av numbers, we open the video page. Also press F12 to open the developer menu and refresh it. There are two files in xhr of network, one starts with pagelist and the other starts with list.so. These two files, the first contains CID video, the second is based on CID to get the bullet screen file. Similarly, we access the request url of the first file according to the Video av number, get cid, and then access the second request url according to cid.
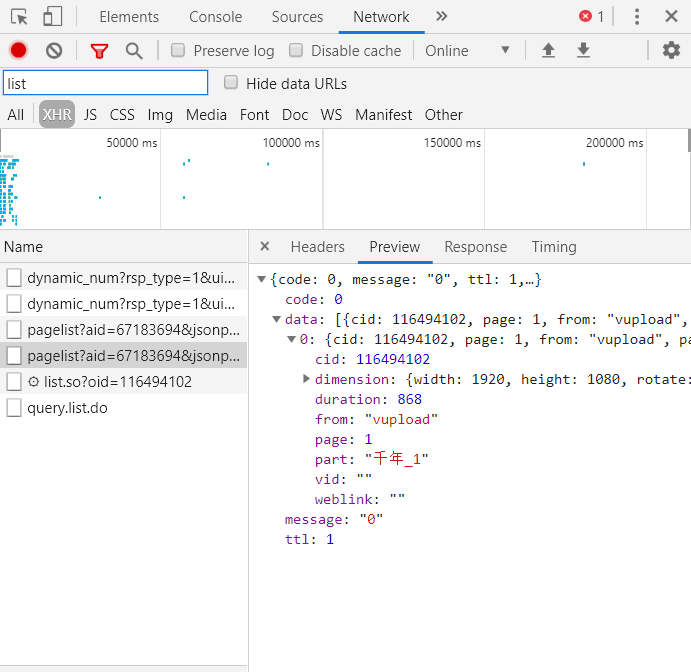
Finally, we have properly sorted out the bullet-curtain documents we have obtained. It mainly extracts the bullet caption text from the < d > tag in the file, then weighs, counts and stores it in the file.
import requests
from lxml import etree import os import json from bs4 import BeautifulSoup from requests import exceptions import re import time def download_page(url): headers = {
'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"
} data = requests.get(url, headers=headers) return data def get_video_page(space_num): base_url = "https://www.bilibili.com/av" url = "https://space.bilibili.com/ajax/member/getSubmitVideos?mid={}&pagesize=99&tid=0&page=1&keyword=&order=pubdate".format(space_num) data = json.loads(download_page(url).content)['data'] total = data['count'] page_num = int(total/99) + 1 video_list = data['vlist'] video_url = [] for video in video_list: video_url.append(base_url + str(video['aid'])) for i in range(2, page_num+1): time.sleep(1) url = "https://space.bilibili.com/ajax/member/getSubmitVideos?mid={}&pagesize=99&tid=0&page={}&keyword=&order=pubdate".format(space_num, i) data = json.loads(download_page(url).content)['data'] video_list = data['vlist'] for video in video_list: video_url.append(base_url + str(video['aid'])) return video_url def get_barrage(name, space_num): video_list = get_video_page(space_num) aid_to_oid = 'https://api.bilibili.com/x/player/pagelist?aid={}&jsonp=jsonp' barrage_url = 'https://api.bilibili.com/x/v1/dm/list.so?oid={}' for url in video_list:
# Reduce crawling speed to prevent prohibition time.sleep(1) aid = re.search(r'\d+$',url).group()
# Sometimes there's an inexplicable mistake. try: oid = json.loads(download_page(aid_to_oid.format(aid)).content)['data'][0]['cid'] barrage = download_page(barrage_url.format(oid)).content except requests.exceptions.ConnectionError: print('av:',aid) continue if not os.path.exists('barrage/{}'.format(name)): os.makedirs('barrage/{}'.format(name)) with open('barrage/{}/av{}.xml'.format(name,aid),'wb') as f: f.write(barrage) def reorganize_barrage(name): results = {} for filename in os.listdir('barrage/{}'.format(name)): html = etree.parse('barrage/{}/{}'.format(name,filename), etree.HTMLParser())
# Extracting text from < d > tag in xml file barrages = html.xpath('//d//text()') for barrage in barrages:
# Some barrages have carriage return marks. barrage = barrage.replace('\r', '') if barrage in results: results[barrage] += 1 else: results[barrage] = 1 if not os.path.exists('statistical result'): os.makedirs('statistical result') with open('statistical result/{}.txt'.format(name), 'w', encoding='utf8') as f: for key,value in results.items(): f.write('{}\t:\t{}\n'.format(key.rstrip('\r'),value)) if __name__ == '__main__':
# In the space list.txt file, I store it in the format of "up main name: id". with open('space list.txt', 'r') as f: for line in f.readlines(): name, num = line.split(': ') print(name) get_barrage(name, space_number) reorganize_barrage(name)