Preface
The text and pictures in this article are from the Internet. They are for study and communication only. They do not have any commercial use. The copyright is owned by the original author. If you have any questions, please contact us in time for processing.
Author: Effort and effort
Crawl qq music artist data interface data
https://y.qq.com/portal/singer_list.html
This is the address of the singer list
Analyzing Web Pages
- The f12 Developer Option finds asynchronously loaded data in the network if you don't know it yet.You can go to the small edition of Python communication first.Skirt: After a long period of fighting and thinking (numerical homophonic) conversion can be found, there is the latest Python tutorial project available, more communication with the people inside, progress is faster!
- Refresh to see the data
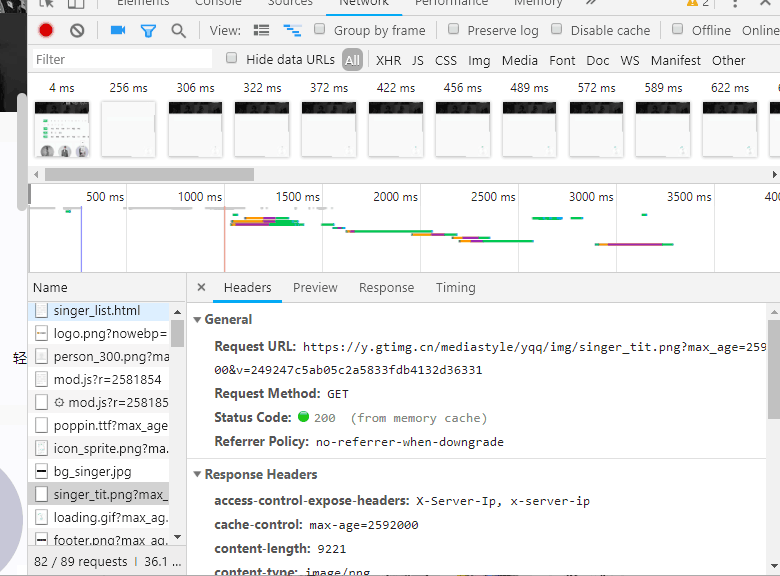
Look at their response
https://u.y.qq.com/cgi-bin/musicu.fcg?-=getUCGI20652690515538596&g_tk=944669952&loginUin=1638786338&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0&data={"comm"%3A{"ct"%3A24%2C"cv"%3A0}%2C"singerList"%3A{"module"%3A"Music.SingerListServer"%2C"method"%3A"get_singer_list"%2C"param"%3A{"area"%3A-100%2C"sex"%3A-100%2C"genre"%3A-100%2C"index"%3A-100%2C"sin"%3A0%2C"cur_page"%3A1}}}
There will be a web address response Is the list of singers or the above web address Remember this web address and then ask for it
- Paste Source First
import jsonpath
import json
import requests
import csv
import time
def writecsv(content):
with open('spider2.csv','a+',encoding='utf-8',newline='') as filecsv:
writer = csv.writer(filecsv)
writer.writerow(content)
writecsv(['Singer Name','Singer Area','singer id','Singer picture'])
def getHtml(url):
response=requests.get(url)
response.encoding='utf-8'
html=response.text
html=json.loads(html)
print(html)
singname=jsonpath.jsonpath(html,'$..singerList..singer_name')
singcountry=jsonpath.jsonpath(html,'$..singerList..country')
singer_mid=jsonpath.jsonpath(html,'$..singerList..singer_mid')
singer_pic=jsonpath.jsonpath(html,'$..singerList..singer_pic')
print(singer_mid)
for index,i in enumerate(singname):
writecsv([i,singcountry[index],singer_mid[index],singer_pic[index]])
index=0
for i in range(0,801,80):
index=index+1
getHtml('https://u.y.qq.com/cgi-bin/musicu.fcg?-=getUCGI01616088836276819&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0&data={"comm":{"ct":24,"cv":0},"singerList":{"module":"Music.SingerListServer","method":"get_singer_list","param":{"area":-100,"sex":-100,"genre":-100,"index":-100,"sin":%(no)d,"cur_page":%(page)d}}}'% {'no':i,'page':index})
time.sleep(3)
# index=0
# for i in range(0,801,80):
# index=index+1
# print(i)
# print(index)It's convenient and practical to use json jsonpath and save it in csv format at the end. If you're not familiar with this, you can go to the small edition of Python to communicate first. Skirt: After a long period of fighting and thinking (homophonic number) conversion, you can find it. There are the latest Python tutorial items available, communicate with the people inside more, and progress is faster!
html=json.loads(html) Here you can save the web page data in JSON format and parse the JSON file jsonpath through jsonpath syntax similar to xpath to see the tutorial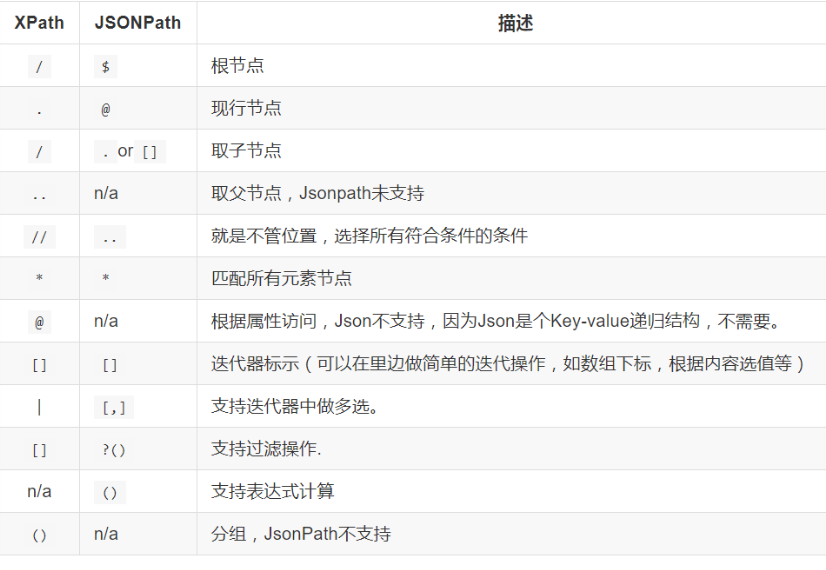
Parse data in json format using jsonpath.jsonpath()$Is the root node cannot be lost
singname=jsonpath.jsonpath(html,'$..singerList..singer_name')
{
"singerList": {
"data": {
"area": -100,
"genre": -100,
"index": -100,
"sex": -100,
"singerlist": [
{
"country": "Mainland",
"singer_id": 5062,
"singer_mid": "002J4UUk29y8BY",
"singer_name": "Xue Zhiqian",
"singer_pic": "http://y.gtimg.cn/music/photo_new/T001R150x150M000002J4UUk29y8BY.webp"
},
{
"country": "Mainland",
"singer_id": 1199300,
"singer_mid": "0013RsPD3Xs0FG",
"singer_name": "Banyang",
"singer_pic": "http://y.gtimg.cn/music/photo_new/T001R150x150M0000013RsPD3Xs0FG.webp"
},
Here...singer_name under //singlist representing absolute where there is a match equal to xpath is good to find. You can print out the errors first, then the countries of singers and singers in turn, because their numbers are the same. Write each line in csv format by enumeration
With open ('spider2.csv','a+', encoding='utf-8', newline='). as filecsv: the first parameter is the file name, the second parameter is the append-read method, the third parameter is the encoding method to avoid scrambling, the fourth is to control empty lines to delete empty lines, which will automatically generate this CSV file after success to see if there are any more CSV files open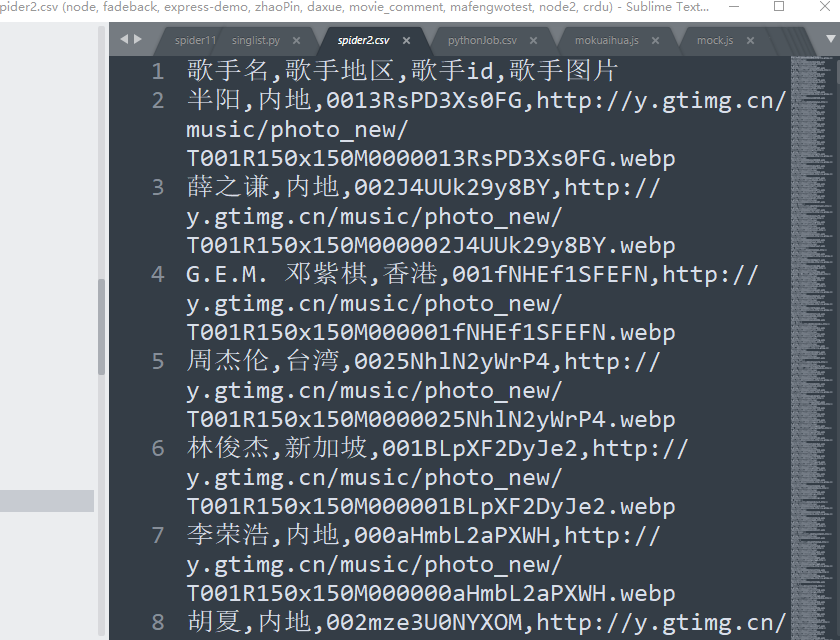
Such a simple asynchronously loaded data crawl is successful