Preface
The text and pictures in this article are from the Internet. They are for study and communication only. They do not have any commercial use. The copyright is owned by the original author. If you have any questions, please contact us in time for processing.
Author: GitPython
PS: If you need Python learning materials for your child, click on the link below to get them
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
1. Get url links to pictures
First, open the first page of Baidu Pictures, notice the index in the url below
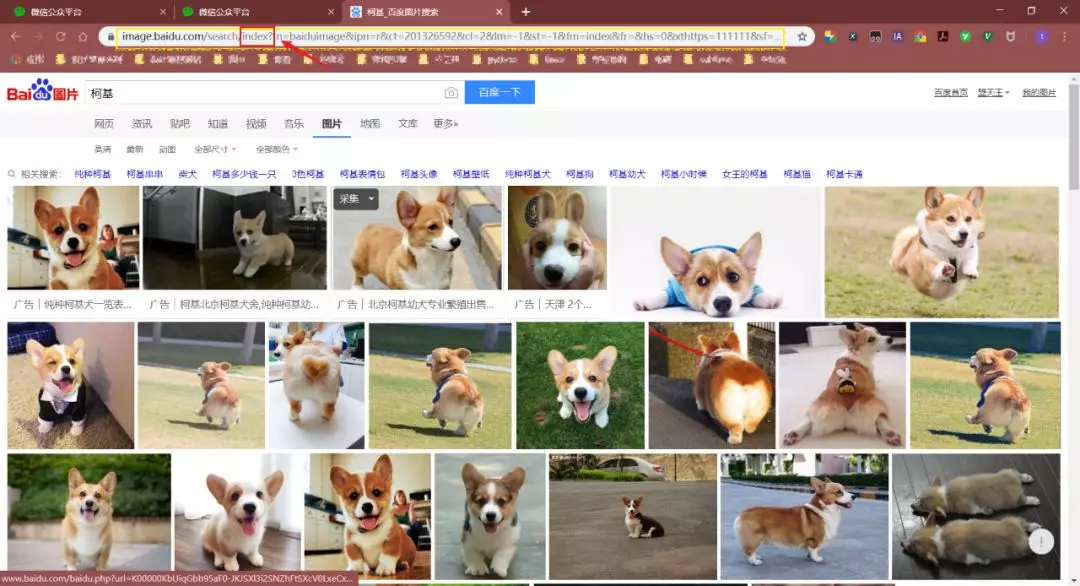
Next, switch the page to a traditional flip, because it's good for us to crawl pictures!
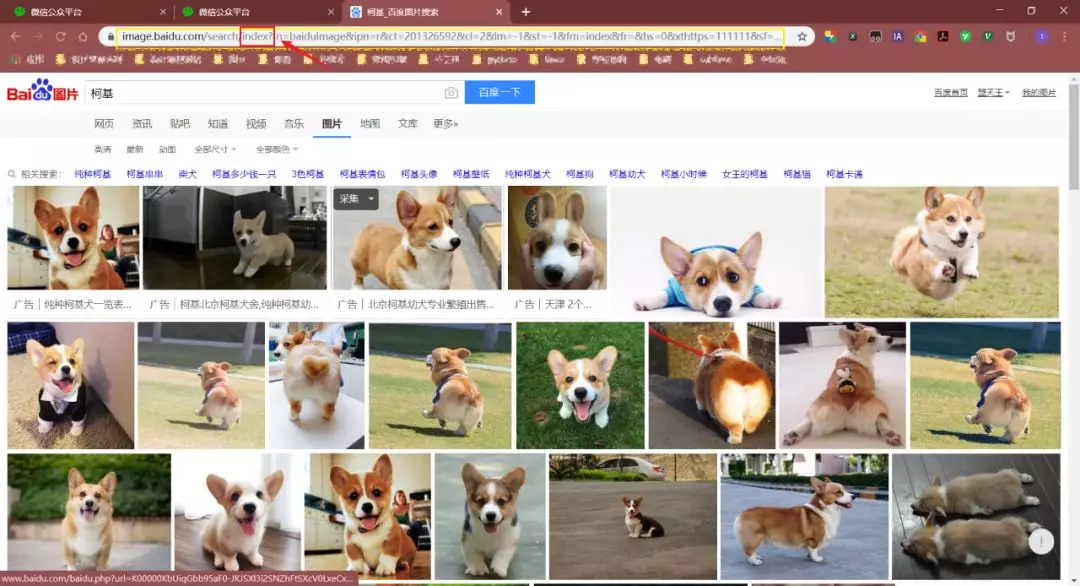
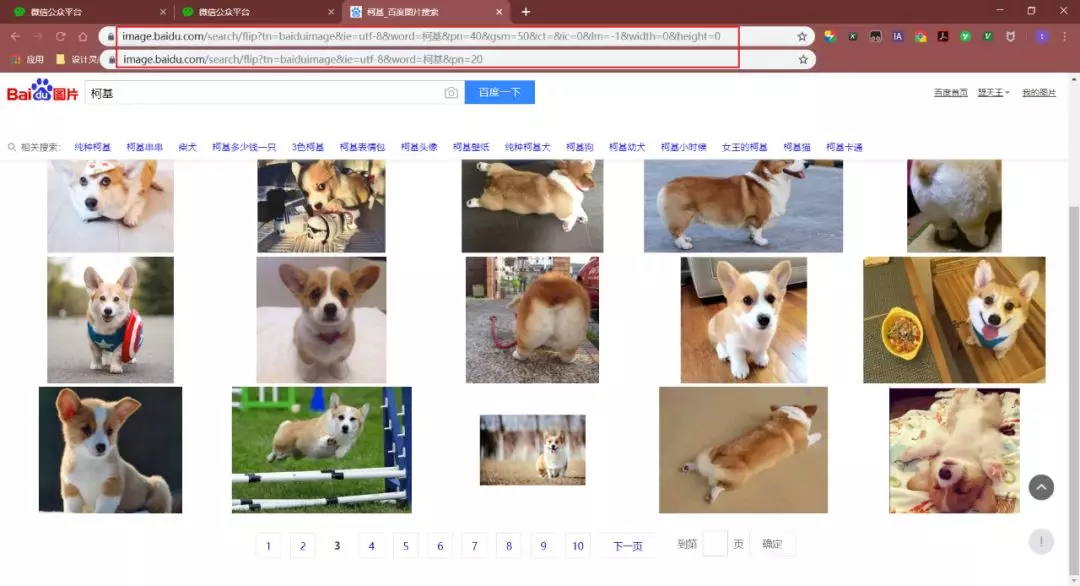
Comparing several url s, it is found that the pn parameter is the number requested.By modifying the pn parameter and observing the data returned, it is found that each page can only have up to 60 pictures.
Note: The gsm parameter is a hexadecimal representation of the pn parameter, so it is possible to remove it
Then, right-click the source code of the page and search objURL directly (ctrl+F)
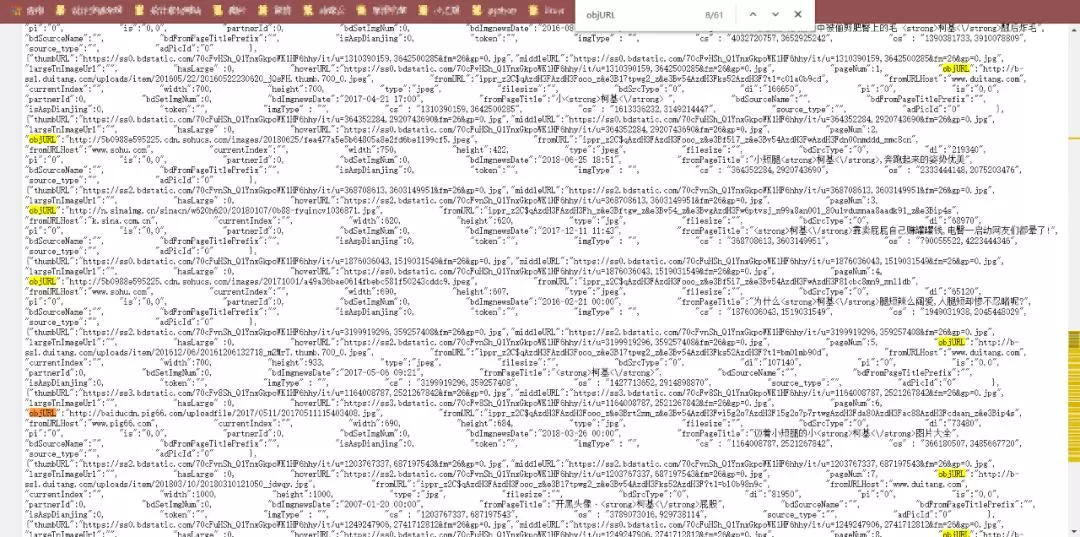
In this way, we find URLs that need pictures.
2. Save picture links locally
Now, all we have to do is crawl out this information.
Note: There are objURLs, hoverURL s in the web page...But we're using objURL because this is the original image
So, how do I get the objURL?Use regular expressions!
So how do we do that with regular expressions?Actually, only one line of code is needed...
results = re.findall('"objURL":"(.*?)",', html)
Core Code:
1. Get the picture url code:
1 # Get Pictures url Connect 2 def get_parse_page(pn,name): 3 4 for i in range(int(pn)): 5 # 1.Get Web Page 6 print('Getting #{}page'.format(i+1)) 7 8 # Baidu Picture Home Page url 9 # name Is the keyword you want to search for 10 # pn Is the number of pages you want to download 11 12 url = 'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%s&pn=%d' %(name,i*20) 13 14 headers = { 15 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.4843.400 QQBrowser/9.7.13021.400'} 16 17 # Send the request and get the corresponding 18 response = requests.get(url, headers=headers) 19 html = response.content.decode() 20 # print(html) 21 22 # 2.Regular Expression Parsing Web Page 23 # "objURL":"http://n.sinaimg.cn/sports/transform/20170406/dHEk-fycxmks5842687.jpg" 24 results = re.findall('"objURL":"(.*?)",', html) # Return to a list 25 26 # Save the picture locally based on the link to the picture you get 27 save_to_txt(results, name, i)
2. Save the picture to the local code:
1 # Save Picture to Local 2 def save_to_txt(results, name, i): 3 4 j = 0 5 # Create folder under directory 6 if not os.path.exists('./' + name): 7 os.makedirs('./' + name) 8 9 # Download Pictures 10 for result in results: 11 print('Saving section{}individual'.format(j)) 12 try: 13 pic = requests.get(result, timeout=10) 14 time.sleep(1) 15 except: 16 print('Current picture cannot be downloaded') 17 j += 1 18 continue 19 20 # Ignorable, this code has bug 21 # file_name = result.split('/') 22 # file_name = file_name[len(file_name) - 1] 23 # print(file_name) 24 # 25 # end = re.search('(.png|.jpg|.jpeg|.gif)$', file_name) 26 # if end == None: 27 # file_name = file_name + '.jpg' 28 29 # Save Pictures to Folder 30 file_full_name = './' + name + '/' + str(i) + '-' + str(j) + '.jpg' 31 with open(file_full_name, 'wb') as f: 32 f.write(pic.content) 33 34 j += 1
3. Main function code:
1 # Principal function 2 if __name__ == '__main__': 3 4 name = input('Enter the keywords you want to download:') 5 pn = input('You want to download the first few pages (60 pages per page):') 6 get_parse_page(pn,
Instructions:
1 # Configure the following modules 2 import requests 3 import re 4 import os 5 import time 6 7 # 1.Function py source file 8 # 2.Enter the keywords you want to search for, such as "Kirky", "Teddy", etc. 9 # 3.Enter the number of pages you want to download, such as 5, which is download 5 x 60=300 Picture